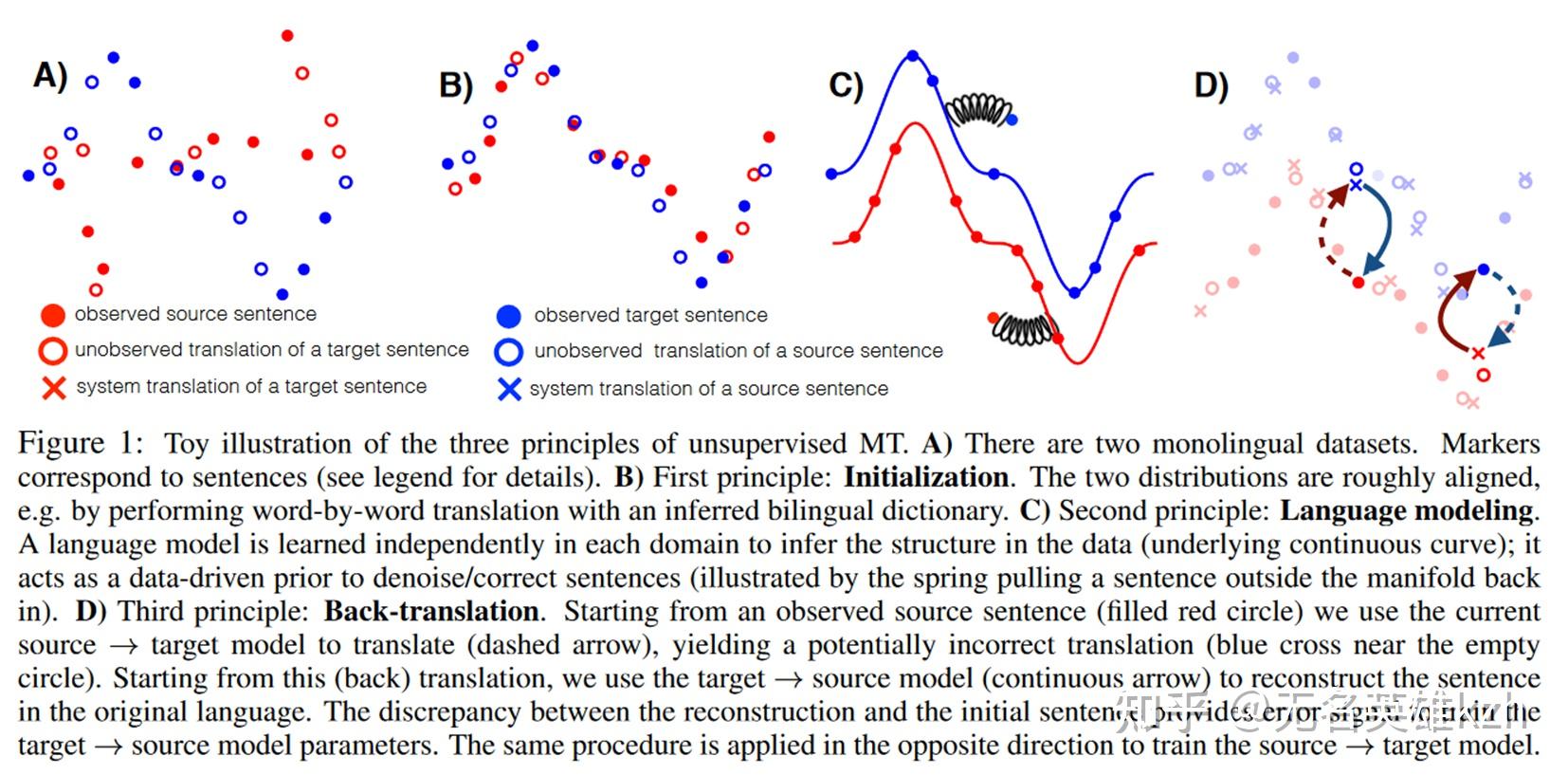
假如有一种未破译灭绝语言,有关于这种语言的一亿本书,能不能用超级计算机把这门语言用套的方式破译出来?
比如说,这一次假设这个词语是“红色”的意思,那个词语是“树”的意思。发现无法使所有的文本逻辑通顺然后继续假设这个词语是“一”的意思,那个词语是“他们”的意思,发...

- 145 个点赞 👍
让我想起了密码学里那个经典故事。
玛丽女王意图谋反,但她被囚禁监视了,想和外面写信磋商谋反大计,怎么办呢?
她用了23个符号来代替英文字母(不包括j、v、w),另有36个符号来代替单词或词组。此外,还有4个虚元(不代表任何字母,像空格一样不具任何意义的符号),以及一个用来表示下一个符号代表两个字母的重复符号。
简单来说就是字母替换法,之后再解译它们的内容,就可以得到原文了。
可惜替换字母有个致命的缺陷,要知道在绝大部分的文章中,各个字母的出现频率是有规律的。替换法并不能改变这一点。
所谓频率分析法,首先,我们必须分析一长篇甚至数篇普通的英文文章,以确立每个英文字母的出现频率。据统计,英文字母中出现频率最高的是e,接下来是t,然后是a……再来,检视我们要处理的密码文,也把每个字母的出现频率整理出来。假设密码文内出现频率最高的字母是O,那么它很可能就是e的替身;如果密码文内出现频率次高的字母是X,那它可能就是t的替身;如果密码文内出现频率第三高的字母是P,那它可能就是a的替身。
在此情况下,我们需要一种更精细的频率分析法,才能有把握地继续下去,判别出这3个最常用的字母O、X、P的真实身份。我们可以把观察焦点转向它们跟其他字母相邻的频率上。例如,字母O是否出现在许多字母之前或之后?还是它只出现在某些特定的字母旁边?这些问题的答案可以进一步告诉我们O所替代的字母是元音还是辅音。如果O所替代的字母是元音,跟它相邻的字母应该很多;如果它所替代的是辅音,有很多字母可能没有机会跟它相邻。例如,字母e几乎可以出现在任何字母的前面或后面,但字母t就不太可能与b、d、g、j、k、m、q、v相邻。
一旦破译出几个字母后,密码分析的工作就可以快速地开展下去了。
玛丽在7月17日函复贝平顿时,实质上等于签下了自己的死刑判决书。她于信中提到这个“计划”,尤其希望他们在刺杀伊丽莎白时,她基本就没有然后了。
所以题目中的这个问题,是完全有可能的,甚至不需要超级计算机,手机就够了。
所以多会一门语言还是挺重要的,要是玛丽女王会中文,至少这种破解工作会难的多,不至于那么快把命送了。
发布于 2024-05-05 08:52・IP 属地福建查看全文>>
DBinary - 81 个点赞 👍
这个问题非常好,其实其本质就是如何理解具备一定语料的未知语言,也就是与一门已知语言建立联系。
这是语言学的一大话题,比如田野语言学需要记录方言乃至从未认知过的语言,历史语言学可能要根据死语言有限的材料尽可能破译信息,比如罗塞塔石碑,或者线性文字AB等。语言学奥林匹克竞赛(National Linguistics Olympiad,NOL)的题目完全就是根据一些未知语言和已知语言的对应关系来推断出未知语言的词汇含义和语法。语言的可能空间非常大,单纯靠暴力猜词是很难搜索到正确结果的。
当然题目的设定其实和上述设定有两点不同。第一点是语料数量。题目中提到这门语言有一亿本书,这其实是田野语言学和死语言解读完全无法想象的数量,比如田野语言学只能从语言老师那里获得有限的几百句话和几百个单词,而罗塞塔石碑甚至只有一块小小的碑文。这是题目设定有利的地方。


罗塞塔石碑,从上到下分别是象形文字,草书体,古希腊文 第二点则是无显著的平行语料。平行语料指的是未知语言以及其已知语言的翻译,比如“apple”对应苹果,“天気がいい”对应天气很好。在田野语言学中,我们可以问掌握未知语言的语言老师“这个东西是什么”,那么获得的语料天然具有注释。语言学奥赛也会给出一些词汇的解释。而罗塞塔石碑同时记录了三种内容相同的文字:希腊文,古埃及草书文,古埃及象形文,其中希腊文是人们非常熟悉的。有了平行语料,人们可以根据一些对应关系猜测词汇的含义,比如频率高的词可能有语法作用,人名相应的拼写可能差不多等等。如果一点没有平行语料没有,对我们的破译会非常不利。当然如果使用这门未知语言的人会学外语,那么可能会有一些书籍记录了外语和该语言的对应关系。可是这就需要挖掘了。
考虑这两个特点,我们应该怎么解决这个问题呢?其实我们可以使用现在非常火的语言模型。
语言模型
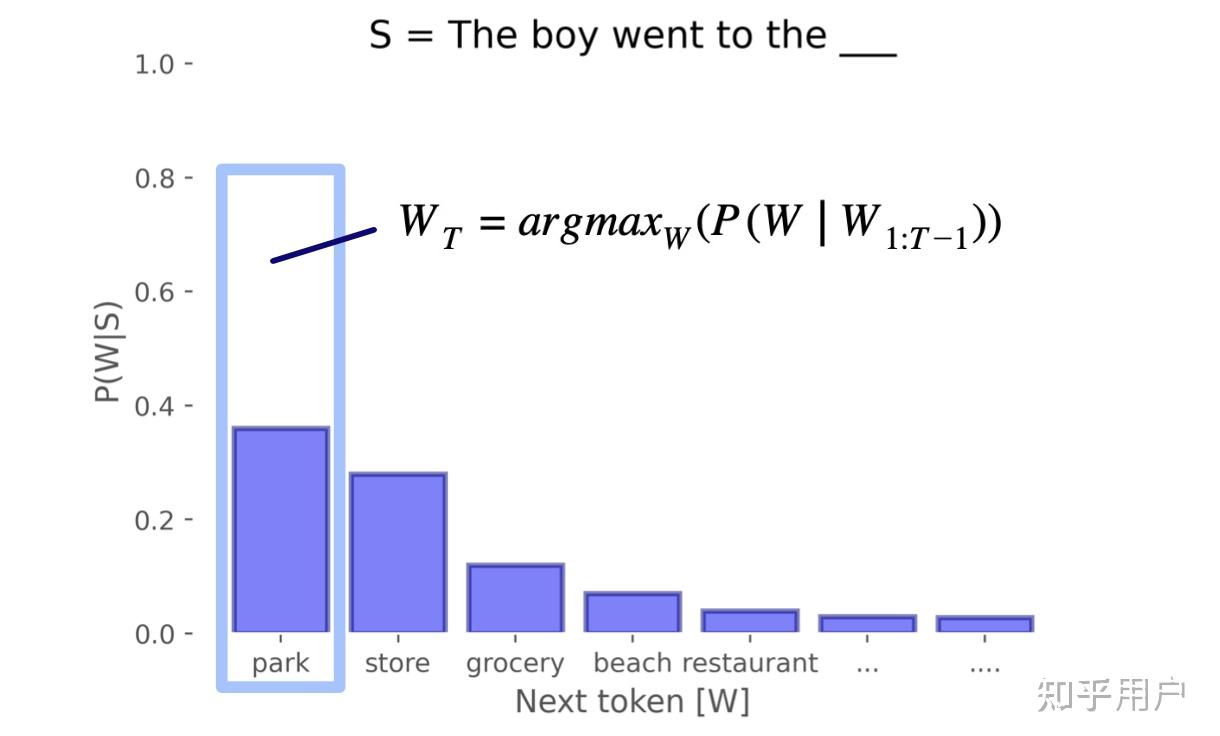
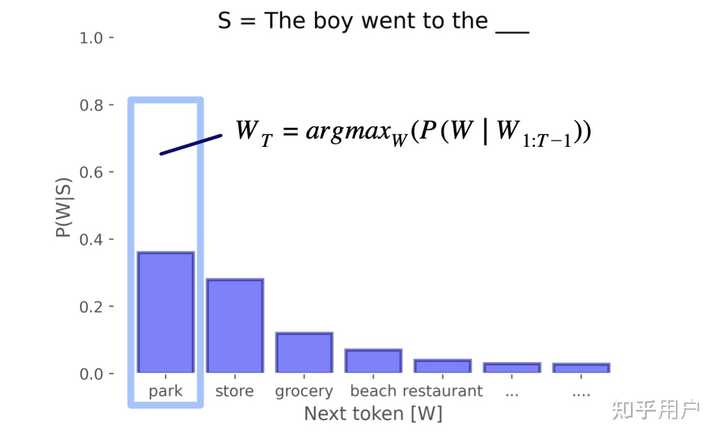
虽然有蹭热度以及拿着锤子找钉子的嫌疑(doge),但语言模型其实是非常适合题目的设定的。最通俗地理解语言模型,就是给一句话,模型输出这句话之后什么词有多少可能出现,比如让模型看“苹果很”这句话,那么可能“甜”这个词的可能是 0.8,而“罗纳尔多”的可能是0.001,如此类推。“什么词有多少可能出现”其实就是一个分布,语言模型实际上是把语言看作一个巨大的概率分布。这个分布很有用,比如我们可以从分布中用一些方法选词,这样就能生成文本了。

为了构建语言模型,也就是训练语言模型,我们需要让模型不断根据前文推断出下一个词的分布,然后计算模型的预测和真实值的差距(损失),然后根据损失调整模型。这是目前最流行的神经网络语言模型的主要流程,此外还有传统的 ngram 模型等,在此不讨论。
语言模型有两个特点很适合题目的场景。第一个特点从上面的文字其实可以看到,就是训练一个模型只需要文本自身就可以了,不需要其他信息,也就是说语言模型是自监督(Self-Supervised)的。最简单的语言模型只需要闷头一个词接一个词地预测,然后“对答案”就好了,不需要语法知识或者其他语言的信息。这就天然解决了无平行语料的问题。
第二个特点其实是神经网络语言模型的特点,就是训练数据越多,模型表现就越好。这被称为 Scaling Law。在题目设定的情况下,假如有一亿本书,假设每本书有九万个单词(GPT-4说的成人小说平均单词量),那么就有九万亿个单词可以训练模型,即使里面可能有些数据不好,假设有四万亿本书质量不行,那么也有五万亿个token。用来训练模型绰绰有余了。
当然,满足了这两个特点只能说明语言模型能用于这个情景,但是语言模型真的能够解决我们的问题,构建未知语言到已知语言之间的关系吗?
语言模型的跨语言迁移
这就要说到语言模型的第三个特点,语言模型的跨语言迁移能力(Cross-lingual Transfer)了。如果模型已经学习了一门语言 A 的很多资料,仅仅学习少量用另一门语言 B 编写的内容,语言模型也能非常好地掌握语言 B 的相关能力,并利用语言 A 内容里面的知识。
GPT-2[1] 是 OpenAI 于 2019 年训练的 Transformer 语言模型,其训练材料大部分是英语,他们在整理训练数据集时特意使用了语言分类器来过滤非英语的内容。当然这种过滤不是完美的,比如训练数据里有 10MB 的法语内容,听起来很多,但 GPT-2 整个训练集有 40GB 之大,这就像 OpenAI 把一整个书店的书拿去训练模型,其中只有几本书是法语书。然而即便是这样,GPT-2 在 WMT-14 法译英任务上的表现,也远远超过了拿多得多的法语材料训练的模型的能力。英译法的能力稍微差一点,但是也超过了基线。
RWKV 是彭博研发的一系列 RNN 语言模型,RNN 和 Transformer 是两种不同的神经网络架构,当然其差异对于本文来说不重要。RWKV-v5 [2]在很多多语言任务上表现非常出色,比如因果推理,句子翻译等等,但是它并没有特意在这些语言上训练这些任务,只是在训练时见过各种语言的数据而已。
以上模型的语言迁移能力比较意外,而另外一些模型是瞄准着多语言能力来训练的,比如 mBERT 和 XLM 等。mBERT 由 Google 推出,在 104 种语言的维基百科数据上面训练,所有语言都共享一套参数。BERT 系列模型采用掩码语言模型,也就是在材料种挖空,让模型补全挖空。XLM 模型来自 Facebook,其预训练任务中增加了翻译语料的任务。
对于这些模型来说,这些少量的其他语言的数据就像题目中的未知语言一样。通过预测下一个词,模型就能神奇地做各种相关任务了。所以我们就可以确定方向了:
- 选择一个掌握了语言 A (比如英语)或者多种语言的语言模型,比如 GPT-2 / Llama 3 / RWKV-v5
- 用未破译语言 X 的数据训练语言模型
- 让语言模型做 X 翻译到 A 的任务,胜利!
有一些技术细节需要考虑,比如如果语言 X 的书写系统不是拉丁文,那么可能需要修改语言模型的词表,涵盖语言 X 的单词;第三步的任务需要给一段初始序列也就是提示词(prompt)来让模型开始做翻译任务,GPT-2 的法译英任务用了 "<法语句子>=<英语句子>...<法语句子>="的格式,其中前面是英语法语句子对,让模型“进入状态”,最后一句法语句子是需要翻译的。
跨语言迁移背后的理论解释
上述做法很粗暴,没有任何高深精妙的理论,但是很奏效(doge)。但是怎么理解呢?首先我们还要回到语言模型的训练目标:预测下一个词。这种做法其实很深刻,用一种训练目标统一了非常多的任务:
- 如果给模型的材料是,”英文:Thank you,中文:谢谢你。“那么预测“谢谢你”的过程,本质上就是在学习如何翻译 Thank you。
- 如果给模型的材料是“我讨厌 perfume 这个词,Burr 说。法语里的说法更好听:parfum”,模型也会掌握如何翻译 perfume。
- 如果材料是“圆周率的值是3.1415926”,那么预测“3.1415926”其实就掌握了圆周率的大小的这一知识。
- 如果材料是百度贴吧里的帖子:“A:<一些观点>B: 啰啰嗦嗦的,不就是……”,那么模型其实在学习如何总结材料。
上面三个例子其实也有层次,第一个例子格式很规整,清晰地展示了英文和中文的对应;第二个例子也比较清楚但没那么格式化,第三个例子和则非常随意,但是里面潜藏了一些能力。第一个例子的数据很少,需要可以收集,但第二个和第三个例子这种非结构化数据则遍地都是。其实这些材料都是某种意义上的平行语料,将不同任务都转化为了A与B的对应关系,通过预测下一个词,模型自行挖掘了数据中潜在的平行语料,而反向传播强迫模型必须学习背后的规律。因此之前提到的方法取决于有多少平行语料。
语言之间的共通性
但是潜在的平行语料终究是整体语言材料的一小部分,剩下的能力是怎么构建的呢?我们需要再深入理解语言模型为什么能学习语言,在这其中分布假说(Distributional Hypothesis)扮演了很重要的角色,也是语言模型能建模为概率分布的基础。一个词的含义是怎么决定的?并不是委员会开个会把几万个词都一一设定意思;一个词的含义是由其他相伴的词决定的。比如“苹果”相伴的词有“红”“吃”“酸甜”“水果”“市场”等等,这些词与苹果之间的共同出现就形成了苹果这个词的意思。那么对于两种不同的语言,如果两个词的相关的词都是类似的,那么这两个词的意思就相近。
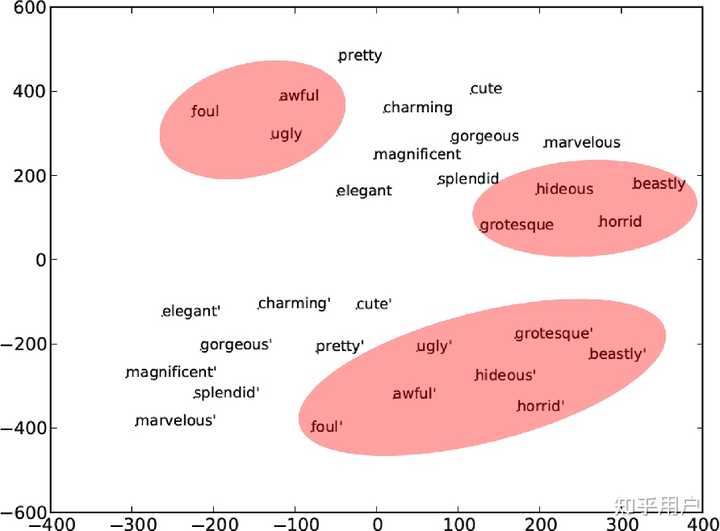

最简单的分布假说往往只考虑临近的几个词,但是Transformer为代表的语言模型能够考虑相距上千乃至上万个词之间的联系,这就能更加合理的建模词语之间的关系,进而建模词语的含义了。
不仅词义之间有相似之处,语法之间也有相似之处。自然语言有上千种,但是语法结构大抵都是相似的,比如语序上主谓宾和主宾谓语言占据了大部分,语法上则有主宾或者作通等少数几套非常通用的系统。观察到这些现象,Noam Chomsky 提出了共通语法(Universal Grammar)的概念,认为所有语言背后有一套相同的结构支撑。其依据则是刺激贫乏(Poverty of the Stimulus),即人类童年接受的数据不足以让人类掌握其语言的所有组分,但大部分人还是能掌握母语的绝大部分语法,说明人脑有一些天生的通用机制来掌握语言。当然这个假说是有比较多的争议的,不过也能从侧面佐证语言的共通性。
语言模型不同模态之间的迁移
下一个问题,这些材料中可能不只有文字,还可能有图像,表格等等,或者如果这个语言还有音频资料,怎么利用这些信息呢?
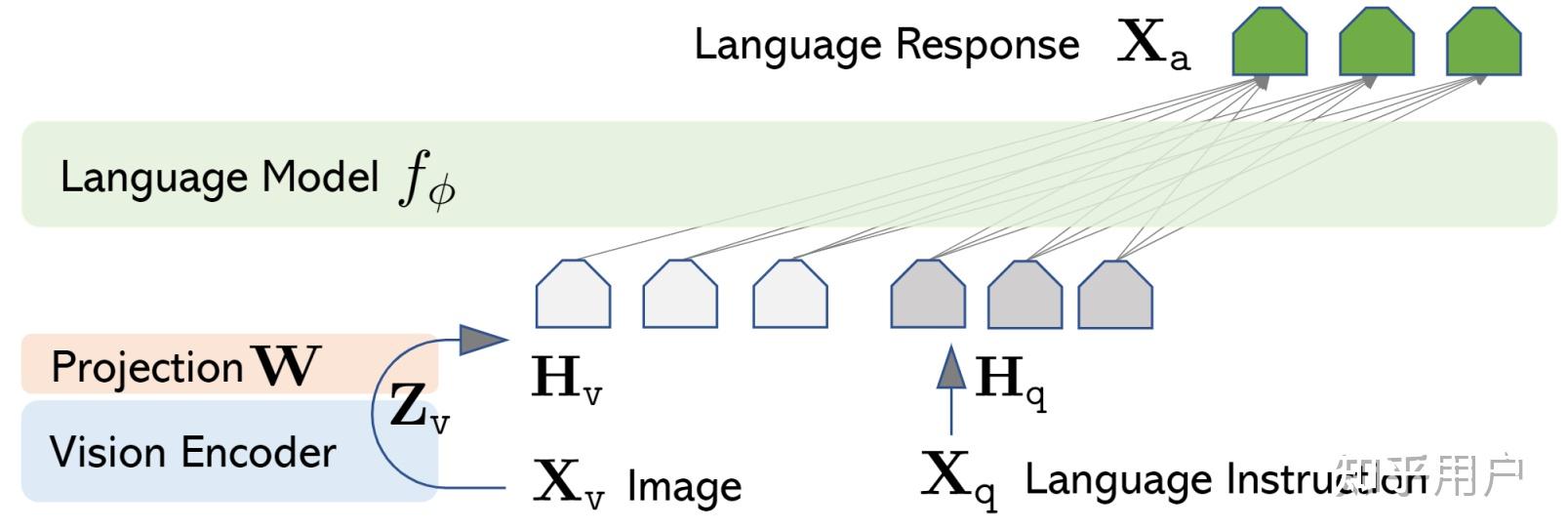
其实语言模型经过微调后也能利用这些信息,这就是神经网络的神奇之处(doge)。最简单的结构可以参考 LLaVA[3],通过一个视觉编码器将图片转化成一系列 token,之后让整套模型来自行学习如何处理视觉 token 和文字token。
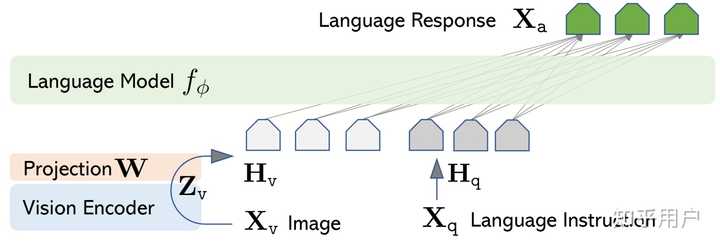

语言模型不仅能在不同语言之间迁移,也能在不同模态之间迁移。比如有人用语言模型分类图片,学习蛋白质的折叠,一个经过充分语言训练的模型便能取得不错的表现,达到和在这些任务上单独训练的模型的效果[4]。
结语:通用智能与压缩
从物理学的牛顿定律到语言学中通用语法,从机器学习早期手动构建特征到 Transformer 语言模型一通四方,人类一直在追求通用的模型。通用意味着压缩,找出繁杂现象背后的普适规律,用最短的序列传递最多的信息量。开普勒将数以万计的观测数据压缩成三条定律,牛顿又将数以百计的实验定律压缩成三条定律,这个过程与神经网络将万亿的语言数据压缩成区区几十G的权重,进而服务于破译语言,总结问答等等任务,其实是殊途同归。
参考
- ^GPT-2 paper https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- ^https://zhuanlan.zhihu.com/p/659872347
- ^https://llava-vl.github.io/
- ^https://www.semanticscholar.org/paper/Frozen-Pretrained-Transformers-as-Universal-Engines-Lu-Grover/3aa2c10dd6c72267ea8a622c8f30b3c9240d5fab?sort=relevance&page=4&citedSort=relevance&citedPage=2
发布于 2024-05-05 15:06・IP 属地中国香港查看全文>>
知乎用户 - 37 个点赞 👍
不好说。
文字破译基本都有一个前提是知道它是什么意思,经典的例子:
- 有了罗赛塔石碑,破译古埃及圣书体;
- 有了贝希斯敦铭文,破译楔形文字;
- 甲骨文本身是汉字的直接祖先,而且中国一直保留了对“古文”“大篆”的记载,大部分被破译;
- 西夏文,出土了《重修凉州护国寺感通塔碑》《番汉合时掌中珠》等文献,与汉文对照破译;
- 线形文字 B 没有任何对照,但本身是记载的是希腊语,而且出现了流传到后世的地名,被破译。
玛雅文不是死文字,失传是因为玛雅文书籍都被西班牙人烧了,但凭着还活着的玛雅人口头语言以及烧书前的一些研究,玛雅文还是被破译了大半,复活节岛的朗格朗格文就没这么好运,目前无法破译。
即使材料本身带有图,有时也很难破译,像《伏尼契手稿》那样,几个疑似破译的说法也是基于某种已有语言的
就题目而言,最有利的情况是信息本身就是设计出来让人易于破解的,像阿雷西博信息和旅行者号搭载的信息那样,或者与人类已知文字对照,那很快能破解。
如果待破译的材料里有大量的人类能理解的内容,比如能理解的图画,那应该能解读出一些词语,但对于这种文字的语法破译起来难度依然很大。甚至于如果这种文字有一些很复杂的特征,比如名词在各种情况下变化很大,那能否解读出词语都难说。
如果待破译的材料里有很多科学内容,包含很多公式和数学,那很有希望解读出来,还很有希望获得一些目前未知的观点。
如果待破译的材料都是纯文字的抽象内容,比如哲学,法律,伦理,历史这些,那破译起来难度极大。
发布于 2024-05-06 00:31・IP 属地北京查看全文>>
被子飞了 - 23 个点赞 👍
逻辑通顺不是一个有效的判据,所以这个方案不可行。
“天是蓝的”,这句话逻辑通顺。但是当上下文是晚霞时,后面那两个字可能表示红色。
又比如大方鼎上的几个字,原译作“司母戊”,后译作“后母戊”,都能说得通,意思差距很大。
实际上,人类语言相当简单,模式非常固定,几万字的一篇文章就可以完成翻译工作。前提是,这篇文章有一个内容相同的翻译版本,类似汉摩拉比法典。或者大体上知道它在说什么,比如中国甲骨文的破译。
发布于 2024-05-05 09:46・IP 属地四川查看全文>>
黄亮anthony - 23 个点赞 👍
查看全文>>
游民 - 16 个点赞 👍
当然不能……因为你不知道这门语言的语法,而自然语言的语法可以有无穷多种。
即使你可以枚举出所有的语法,然后穷搜,你也不能保证结果收敛到一个点上啊。
甚至,别说一亿本书,即使你有无穷多的样本,你也不能保证它收敛啊。
不过,这里我们可以提一个有趣的问题:如何构造一门这样的语言,可以在多项式时间内被接受,而攻击者(概率上)无法在多项式时间内达成攻击?
在密码学上有个概念叫indistinguishibility,直译过来叫不可区分性。比如说,有两个分布系综 E_1=\{X_i\}_{i\in\mathbb{N}} 和 E_2=\{Y_i\}_{i\in\mathbb{N}} ,你在这两个集合上跑任何验证算法 A:\{0,1\}^n\to\{0,1\} , 对某个给定的 n 都有 \left| Pr[A(X_n)=1]-Pr[A(Y_n)=1] \right| \le \epsilon(n) ,那么 E_1 和 E_2 就是计算上不可区分的。也就是说对于所有长度为 n 的字符串而言,这俩集合上跑任何验证算法得到的结果都是差不多的。
基于这个概念,我们可以搞一个不可区分混淆算法,简单地说,一个pp(概率多项式时间)的算法 iO ,长度为 m 的密码分布系综 \{C_i\}_{i\in\mathbb{N}} 满足:
- \forall c \in C_m,x \in X_n,Pr[c(x) = iO(c)(x)]=1
- \forall c_1,c_2 \in {C_m}, |Pr[A(iO(c_1))=1]-Pr[A(iO(c_2))=1]| < \epsilon(n)
由2,iO(c) 不可区分,所以理论上判死刑,不可能(在多项式时间内)攻击 c 。
那你可能要问了,这么厉害的东西为什么我们不用呢?因为首先,我们还不知道有没有这种 iO 算法存在,其次,就算知道了,你得搞一个实际能用的pp算法出来……
发布于 2024-05-06 02:04・IP 属地浙江查看全文>>
知乎用户 - 14 个点赞 👍
不知道为什么这么多答案说不行,还有些答案扯到LLM上去了,实际上这个问题早在LLM时代之前就有成熟的方案了。
通过语言学手段,其实已经能解决大多数失传文字,例如甲骨文、古埃及文字、古巴比伦文字这些的破译工作。题目所说的能否基于计算机通过大量语料进行破译,实际上就是NLP中的无监督机器翻译问题,这一块也早就有大量的研究工作。
Word2Vec时代
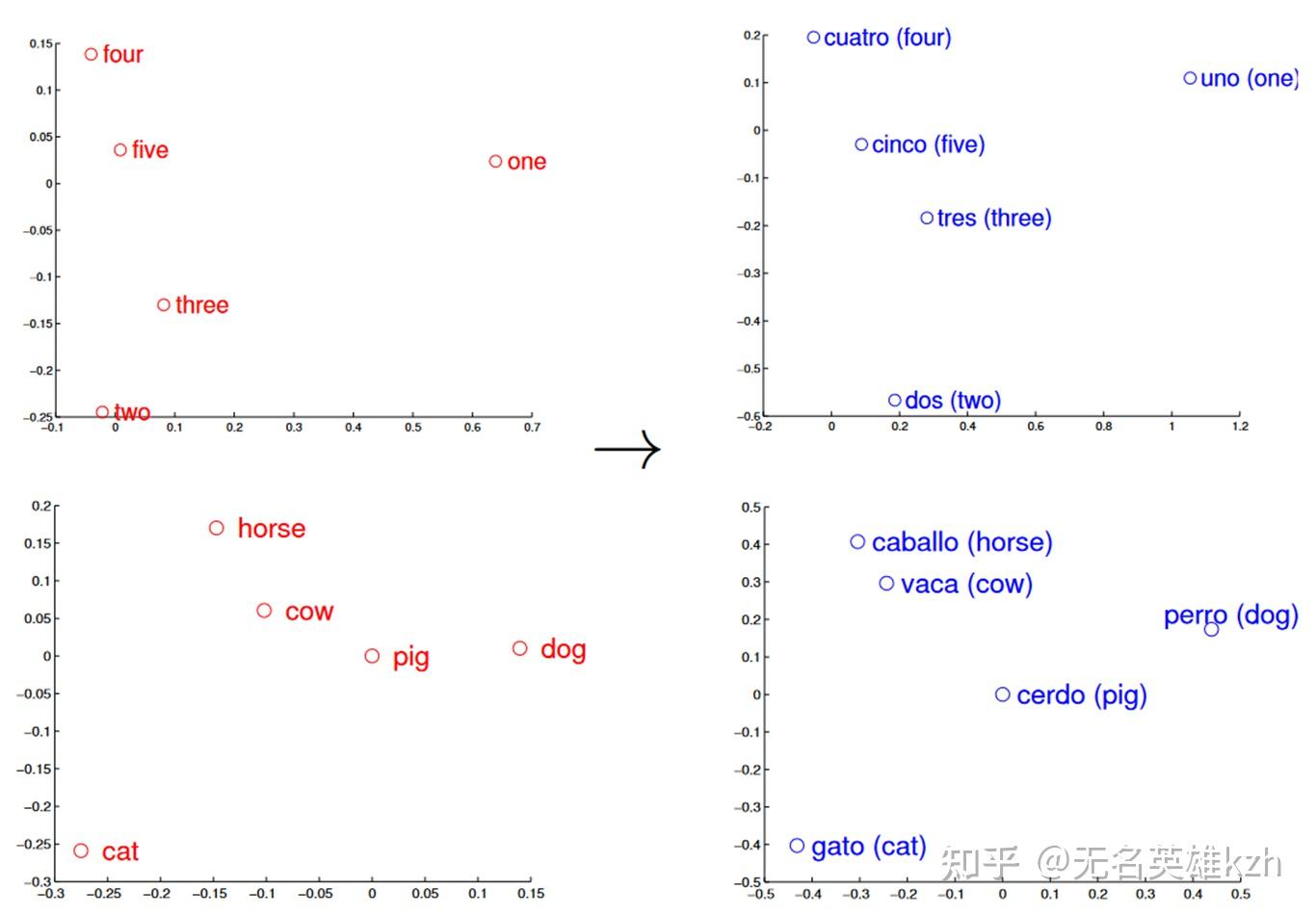
从Word2Vec开始,词袋模型告诉我们词向量大致是满足线性规律的,例如我们单词可以在Embedding空间中进行这些计算:
\text{one} + \text{two} \approx \text{three}
\text{king} + \text{woman} \approx \text{queen}
\text{French} - \text{Paris} \approx \text{England} - \text{London}
就在提出Word2Vec之后,还是2013年,Mikolov就给出了利用词向量模型在不同语言间进行无监督翻译的方法。对于不同的语言而言,同样语义词汇之间的相对关系依然不变,例如我们换到中文里还是会满足:
\text{一} + \text{二} \approx \text{三}
\text{国王} + \text{女人} \approx \text{女王}
\text{法国} - \text{巴黎} \approx \text{英国} - \text{伦敦}
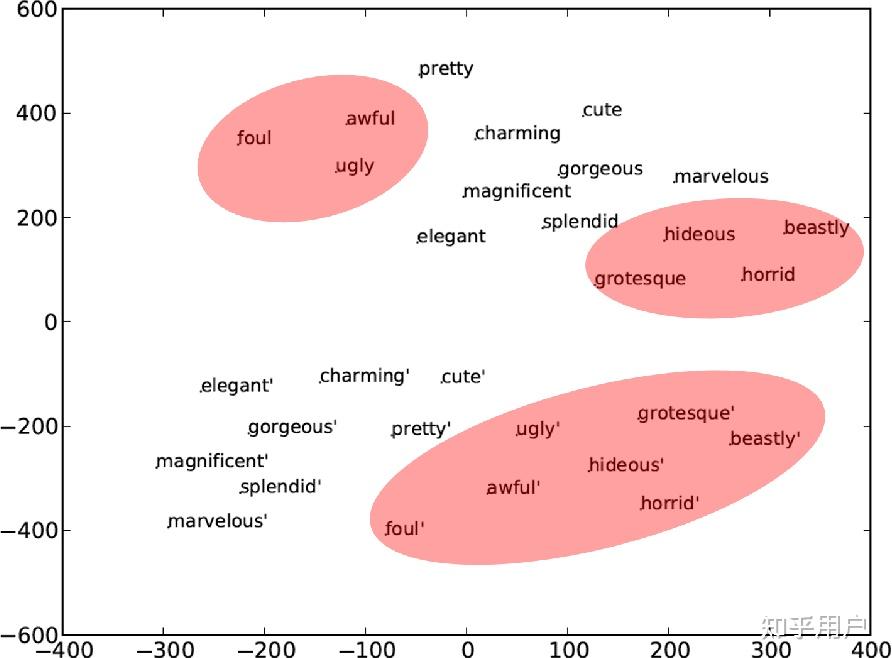
即不同语言中,描述同种事物的词汇之间的相对关系保持不变。一种挖掘这种关系的方式是PCA降维,PCA的本质是对样本的协方差阵进行特征值分解,从而拆解出一个旋转矩阵和一个基矩阵。
而我们已经知道不同语言中的词汇相对关系是一致的,只不过词汇的表示不一致,也就是说两种语言的词向量矩阵是相似的——两个矩阵仅相差一个旋转变换。利用PCA降维将这个旋转变换去除掉后,两个矩阵也就得到了对齐。
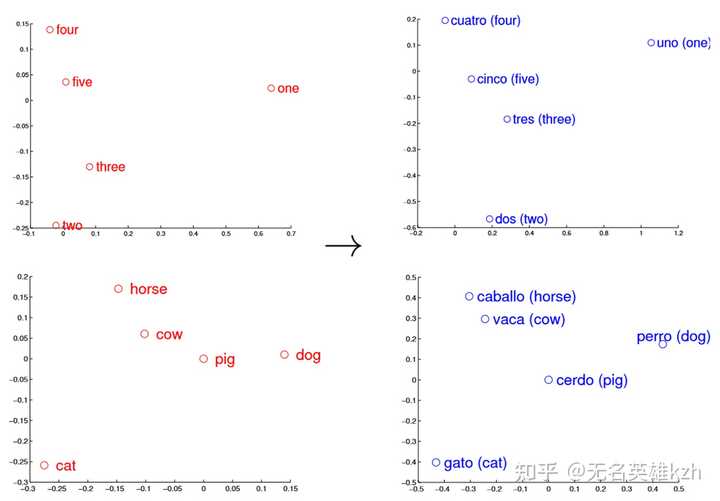

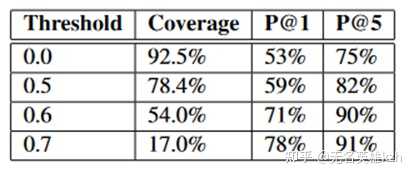
英语(左)和西班牙语(右)词向量在PCA下的可视化 在论文中实际仅学习了一个映射关系 \min_{W} \| WX-Z \|^2 ,其中X是源语言,Z是目标语言,W就是映射矩阵,这么一个简单的方法就能对大多数词达到53%的准确率,考虑top5结果能达到75%,高置信度部分甚至能达到91%。

英语->西班牙语映射准确率 Transformer时代
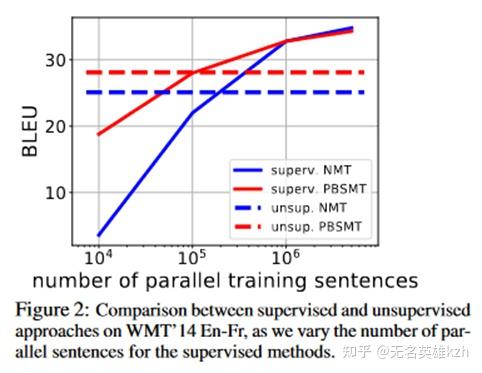
跨入Transformer时代后,无监督翻译更牛逼了,这里就介绍下比较经典的回译(back-translation)的做法。
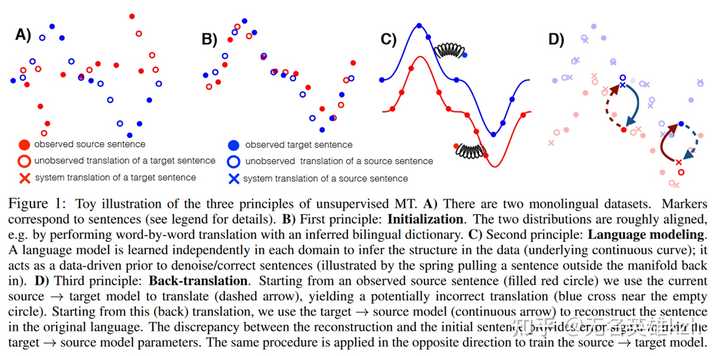

回译步骤 回译的做法相当巧妙,它妙在利用了译文的译文等于原文这一点,从而脱开了对平行语料的依赖。具体步骤如下:
- 先搞一个粗对齐的语料,比如收集两种语言大量的语料,然后利用上面的方法先把词汇对齐了,然后简单按词翻译一下,差不多就行。
- 用两种语言的语料建立两个语言模型,然后再用粗对齐语料初始化 f(源语言)->目标语言 和 g(目标语言)->源语言 两个翻译模型。
- 回译训练
- 从源语言拿出一条句子x,计算f(x)作为一条x的伪翻译
- 再计算g(f(x))将伪翻译结果翻回源语言
- 由于g(f(x))是x翻译的翻译,因此 x=g(f(x)),这就是回译的损失函数
- 然后再从目标语言拿一条句子y再来一遍 f(g(y))=y
论文在英法翻译上的实验结果表明,使用回译的无监督学习差不多相当于使用10万条平行语料进行有监督学习的结果,这个结果还是相当可观的。
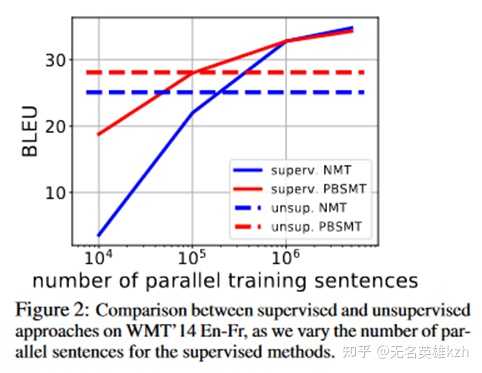

监督翻译与无监督翻译性能对比 LLM时代
在LLM时代,模型拥有了和人类一样的学习理解能力,更加毋庸置疑我们具有这样的翻译能力。我们可以做一个思想实验,拥有无限语料的LLM学习,就好像将一个盲人小孩扔到一个全新语言环境中学习,那么他显然如同大多数先天性视障人群是可以学会语言的,此时我们将他又扔到一个新的语言环境,保持学习能力不变,他依然可以学会一种新的语言。那么此时的他,会因为没有对照表就不知道两种语言怎么对应了吗?显然不会。
我们之所以拥有这种跨语言的翻译能力,本质上是因为我们有着相似的生活环境和生活方式,比如我们都需要数字进行计数,那就可以根据数字的大小关系建立映射,我们都要在说话的时候进行指代,“你我他这那”就总是有相似的出现规律。这种来源于世界本身的相似性保证了语言语义结构的相似性,也就保证了我们只需要去求解某种最小化的映射,就能保证翻译结果八九不离十。
那么这种翻译只会在一种情况下失效,也就是对面文明和我们的生存环境大不相同,他们平时不数数、不运动,没有视觉和听觉感官,思维混沌无法理解。那面对这种克系语言,我觉得应该确实没有什么办法在两者之间建立映射,毕竟此时是否存在合理的映射都难以保证了。
参考文献:
[1] T. Mikolov, Q. V. Le, and I. Sutskever, “Exploiting Similarities among Languages for Machine Translation,” arXiv:1309.4168 [cs], Sep. 2013, Accessed: [Online]. Available: http://arxiv.org/abs/1309.4168
[2] G. Lample, M. Ott, A. Conneau, L. Denoyer, and M. Ranzato, “Phrase-Based & Neural Unsupervised Machine Translation,” arXiv:1804.07755 [cs], Aug. 2018, Accessed: [Online]. Available: http://arxiv.org/abs/1804.07755
编辑于 2024-05-09 01:18・IP 属地浙江查看全文>>
无名英雄kzh - 12 个点赞 👍
突然发现自己的问题已经被收公无法编辑了,在此补充几个条件吧
前提:有强证据指向一个事实(主要是书中的一些图片):使用这种语言的文明已经至少到达了蒸汽机时代
1:这些书并不集中于某一个学科,而是分布在各个领域(文学,数学,物理,化学,生物学,生态学,地质学,医学,历史,社会学,人类学,哲学,行政,军事,音乐,绘画,建筑,雕塑,体育,电影,旅游,烹饪,新闻,杂志,故事书,统计档案,生活常识,娱乐八卦,日记,信件,早教......)(外语教育书籍除外)
2:这些书中有一部分是图文并茂的,至少不低于所有书的10%
3:这本书不使用拉丁字母,阿拉伯数字,西方乐谱,国际数学符号等大家熟知的符号标志。整个社会使用的符号标志自成一体。全部用一种独立文字写成(可以确定不是一种简单的纯拼音或者音节文字)
4:这一亿本书中没有任何外语教学书籍,所有书籍没有出现关于已知语言的任何字符(打个补丁,避免钻空子)
5:这门语言虽然未必来自地球,但是已知这个文明拥有和地球文明基本相似的社会生活图式(吃饭,睡觉,国家,政府
查看全文>>
Montaigne - 7 个点赞 👍
猫吧~~
猫能很明确的知道它是在对人,还是它的同类发出声音。所以,不用设想,直接来把喵语破译一下吧~~
破译未知语言可能很难赚到钱,很难有市场前景,但喵语不同,有很大的市场,而且这个市场还有很大的潜力。
你想想,有那么那么多的铲屎官,期待和自己的喵主子沟通,那这市场该有多大~~
而且宠物诊所也需要会喵语,汪汪语的员工,好做好医患间的沟通。
至少我就想能听懂我朋友家的猫和狗在说什么,是怎么评论我的?是不是有个大傻子一到它们家就开始逗它们,它们看在主子的面子上还的陪笑?要是这样,下次我就不带猫饼干过去了……
扯歪了……
其实要是一亿本不够,你看看,这世界上有多少猫啊狗啊的?和它们主人打好招呼,一条鱼,一根骨头,大不了再加一个猫罐头,有什么事搞不定的?几百亿的喵语样本,汪汪语样本,随便采集~~
而且你还可以让它们现场演示,书是死的,动物是活的。活的更加形象生动,神态和行为能更好地契合语言的表达。所以,先考虑考虑猫猫狗狗吧~~
现在找一亿本未知语言的书籍可能很难,但喵语汪汪语太简单不过了,而且直接声纹数据。谁家大模型说是没问题的,拉出来溜溜。别和我说书籍太少,训练样本不够。猫猫狗狗多得是呢,先用这个练练手,给我们康康,大模型究竟有多神奇~~!
发布于 2024-05-05 13:45・IP 属地北京查看全文>>
swxlion - 5 个点赞 👍
不行,逻辑通顺建立在你的认知上,楼上有说的很多,如果没有训练集,任何一个标准都没有,那纯粹是胡闹,结果就是过拟合而已,想想袋鼠被叫做kangroo的故事。
发布于 2024-05-07 12:20・IP 属地天津查看全文>>
xmzhang - 4 个点赞 👍
理论上可以。
最简单的办法,是在统计文字出现频率的基础上,给每个文字每个词(如果有词组间隔标准)做一个假设翻译,然后联系上下文并套用已知语法进行暴力破解。
但如果这种语言的语法框架与当前人类语言完全无关或大部分无关,就很难理解了。
就算蒙对了主谓宾定状语,也有可能因为文字的假设翻译而造成无穷大数量的翻译版本。
可能这些版本中有一个或多个是正确的,但怎么确定呢?
所以说,理论上可以,实际上不行。
至少要有一部分真正确认的参考翻译。
发布于 2024-05-06 14:30・IP 属地上海查看全文>>
白乌鸦 - 4 个点赞 👍
太长不看版:
语言的破译,主要是要建立语言与所表达的概念的对应关系。
所以,不论有多少语料,如果不能直接(将其与客观事实建立联系)或间接(将其与现存语言建立联系)建立与概念的关系,那么这门语言都不能被破译。
比如说想想鸟叫……
这是两个常见的误解。
先从提问者的思路说起,这个思路其实很容易发现问题,因为就算你有无限的语料,如果没有客观事实去做比对,那仍然存在许多可以全部解释得通的解读方式。
比如说一个语言的语料长这样:ABC,一种解读是,这个和那个,另一种解读是,那个和这个。
因为这和那两个概念,你其实很难区分。A揍了B,如果你没有客观事实来佐证,谁揍了谁在语言上都是说得通的……同样的还有高和矮、胖和瘦、多和少……这些同位词,没有客观事实来佐证你根本无法区分。
然后就是第二个误解就是去提问者也许大概以为所有的人类语言的语法都是类似的。其实这一点不太站得住脚,现今人类的语言语法类似很可能是人类交流的结果。如果语法结构和编码规则都不确定,你可以搞出无数种解读出来。
更进一步的,同一个语素在不同上下文也不一定是指同一个概念。考虑到这一点,你怎么解释都可以解释得通,反正我说它在这个上下文就是这个意思就完了。那么是不是语素多义性最少的那一种解释就是正解呢?看看现在的自然语言就知道绝对不是这样……
再更进一步的,就是不同语言中对于概念的颗粒度也是不一样的。典型的像是中文中的一月二月三月到了英文没有共同的语素(月)。但同样是面皮包馅的饺子馄饨云吞烧卖包子灌饼也没有共同的语素(有馅面点)。同样的道理,在英文中一般不区分外公和爷爷,而在中文也通常没有对于这两者的统称。而parent中文中更是没有对等的语素。
编辑于 2024-05-08 22:05・IP 属地广东查看全文>>
Ivony - 3 个点赞 👍
查看全文>>
GFancy - 2 个点赞 👍
有可能,但是不好说。
首先,纯实体名词,没见过的就是翻译不出来,见过的也不一定翻译的出来,相似事物仅凭文字未必能区分,除非拿着一个东西,中国人喊苹果,英国人喊apple。这还不算是一种语言中压根就没有的名词。十分可能出现,我现在这几十几百个词都各自表示一种美丽的植物或花朵,但是我也不知道哪个是哪个。
其次,还得看语料库,就像爷爷和外公,仅凭新闻语料,很难区分这两个词的区别,但是涉及家庭关系的生活语料,很多时候可以轻松的区分出来。就好比,很多人高考英语130+甚至140+,"窗帘" "毛巾" "洗发水" "水龙头"这种词不会说。因为这种词就不是高考这种情境下常见的词汇, 甚至根本见不到,但是在其它情境下又是极其常见的词。
最后,这还不算新语言会不会出现什么神奇甚至神经的语法规则。比如我随便编几个,交换主语谓语的元音表示否定,交换主语和宾语的位置表示否定,一个名词一个动词都有几百上千种格数形要根据情境搭配使用,或者什么改变音节的顺反表示主被动之类的(bat变tab)。甚至语法可以跨句效果也不是不可以。各种语素音素面条一样的揉在一起就好比被一个加密rar压了一样。或者像射影几何的对偶一样,它就是有多解,那你就是解不了。
发布于 2024-05-08 14:53・IP 属地中国香港查看全文>>
nnnn123456789 - 1 个点赞 👍
从理论上讲,使用超级计算机通过蛮力破解灭绝语言 有可能,但 并非 绝对可行。这取决于多种因素,包括:
1. 语言的复杂性: 语言的语法、词汇和语义越复杂,破解难度就越大。例如,具有复杂句法结构和丰富词汇的语言,需要更大的计算量来枚举所有可能的翻译组合。
2. 可用文本量: 可用文本越多,就越有可能找到重复模式和线索,从而推断语言的结构和规则。然而,即使拥有大量文本,也可能无法覆盖所有语法结构和语义范畴,导致破解不完全。
3. 已知信息: 任何已知的关于语言的信息,例如词汇表、语法规则或相关语言的比较数据,都将极大地提高破解的成功率。
4. 计算资源: 破解灭绝语言需要大量的计算资源和时间。即使使用超级计算机,也可能需要数年甚至更长时间才能完成破解过程。
5. 算法效率: 破解算法的效率至关重要。更有效的算法可以减少计算量和时间,提高破解的可能性。
总而言之,蛮力破解灭绝语言是一种可行的策略,但需要克服许多挑战。只有在拥有大量文本、已知信息和强大计算资源的情况下,才有望成功。
以下是一些关于使用超级计算机破解灭绝语言的实际案例:- Linear B 破译: 1952年,迈克尔·文特里斯(Michael Ventris)使用密码分析技术破解了古希腊克里特岛的线性B语言。虽然并非严格意义上的蛮力破解,但该案例证明了使用计算机分析古代语言的可能性。
- 玛雅象形文字破译: 研究人员正在使用机器学习和人工智能技术来破解玛雅象形文字。尽管尚未完全破译,但这些技术已经取得了重大进展。
- 复活已灭绝语言: 一些项目致力于利用技术复活已灭绝的语言,例如康沃尔语和亚拉姆语。这些项目通常结合了语言学分析、机器学习和社区参与。
总而言之,使用超级计算机蛮力破解灭绝语言是一项复杂而具有挑战性的任务,需要结合语言学、计算机科学和历史等多学科知识。随着技术的进步和更多数据的可用,我们可以期待未来在破解灭绝语言方面取得更大的突破。
编辑于 2024-05-08 12:16・IP 属地湖南查看全文>>
浅瞳蔷薇 - Linear B 破译: 1952年,迈克尔·文特里斯(Michael Ventris)使用密码分析技术破解了古希腊克里特岛的线性B语言。虽然并非严格意义上的蛮力破解,但该案例证明了使用计算机分析古代语言的可能性。
- 0 个点赞 👍
如果是原始资料的话,第一步要解决的是:
切分视觉token, 这一步和语言本身几乎没有关系。也就是要把一个图形(书中的每一页)切分成一个一个的 字母/字。然后再通过相似度比较,弄出一张 逻辑token 表,比如 A ,B C,D...., 统计出频率。这个阶段可以完全依赖计算机解决,应该不是问题。
完成上面这一步后, 只要这种语言是地球上的人创造的(几十万年的尺度上 自然环境基本不会变的,比如山 水 河 树 风 雨 冰...),实际根本不需要一亿本书,有几十几百本就能还原出【一小半】以上。如果有这个语言同期存在的可识别语言,会更容易一些。 这个阶段可能需要一些人肉活(语言专家等)。归纳猜测出这个语言的基本句式。
再往后的阶段,大部分工作依赖计算机程序就行。
发布于 2024-05-06 10:58・IP 属地山西查看全文>>
navegador - 111 个点赞 👍
现在大模型的发展已经给了非常肯定的回答。
事实上,如今的大模型就是这样训练出来的。大模型一开始对语言一无所知,但读过上亿本书之后,不仅掌握了语言,同时还掌握了世界上几乎所有的知识。
大模型本身的结构(Transformer)是通用的,不包含任何特定语言的信息,Transformer 结构对任何自然语言甚至代码、图像都是通用的。把书的内容塞进大模型,不需要任何解释,大模型就能学会这门语言。大模型一开始并不知道每个词是什么意思,但随着训练过程的进展,就逐步了解了词、句子的含义。
下面贴一篇我 6 年前的旧文《如何衡量外星文明的智能程度》。2018 年的时候,当我跟 MSRA 的同学讨论这个想法的时候,大多数人觉得这样的 “无监督通用学习能力” 并不存在。虽然 Transformer 当时已经在 NLP 中崭露头角,理解词语和简单句子的含义已经不成问题,但很多人还是不相信 Transformer 能够真的完全掌握一门语言,能够完全掌握世界上所有的知识。
他们认为人类智能有与生俱来、刻在基因里的一部分,并不是完全从后天习得的,因此机器只是通过读书是不可能真正学会一门语言的。但我认为,刻在基因里的只是模型结构和训练方法,而不是模型的权重,人类智能和语言是后天习得的。这也就解释了人类 DNA 中的信息量这么少,人类语言却这么复杂。因此,我一直认为数字生命是可能的,而且我也一直在为此努力。今天,虽然人类智能的来源还没有定论,但无监督通用学习能力已经是无可争辩的事实。
如何衡量外星文明的智能程度
那是 2018 年初的冬夜,我在十三陵自己架起了一口大锅,向 8.6 光年之外的天狼星发送了人类知识的一小部分。这件事背后的故事在这里。今天我们关心的是,向可能的外星文明发送消息,显然需要让外星文明认识到这个消息是一个智慧生命发出的,还得让外星文明理解它。
一个很基础的问题就是,如何在消息中证明自己的智能程度呢?换言之,如果我是一个监听宇宙信号的智慧生命,如何判断收到的一堆信号中是否包含智能?由于智能不是一个有或无的问题,而是一个多或少的问题,如何衡量这堆信号中包含何种程度的智能呢?我觉得 5 年前自己的思考还是有点意思,整理一下发出来。
消息就是一个字符串。设想我们能够截获外星人的所有通信,拼接成一条长长的消息。它包含多少智能?这并不是一个容易回答的问题。
现有技术一般是尝试对消息进行解码,然后看它是否表达了数学、物理学、天文学、逻辑学等科学中的基本信息。1974 年的阿雷西博信息就是用这种方式来编码信息,希望得到地外文明的关注的。我则试图找到一种纯计算的方法来衡量消息中蕴含的智能程度。
复杂度 ≠ 智能
让我们从熵开始。熵是消息混乱度的度量。如果消息中的每个字符都没有前后关联,熵是很容易通过每个字符的出现频率计算的。可惜,消息中的字符是有前后关联的,例如英文字母 q 之后几乎总是跟着 u。对重复子串进行特殊的编码存储,就是如今各种压缩算法背后的原理。熵对应着使用压缩算法能够取得的极限压缩率。没有放之四海皆准的最优压缩算法,也没有算法能够准确地计算一个字符串的熵。
简单重复的字符串,比如 10101010…,熵很小,压缩比最高,但显然不包含智能。随机生成的字符串熵很大,不可被压缩,也显然不包含智能。那是不是熵适中,压缩比适中的字符串就包含智能了呢?答案也是否定的。我们设想一个长度为 N 的随机字符串不断重复下去,那么通过调整 N 的值,可以构造出熵为几乎任意值的字符串,但是随机字符串的简单重复显然也不包含智能。
消息的复杂度有很多种度量。有一个知名的 Kolmogorov 复杂度,指的是能输出该字符串的最短程序的长度。例如,pi = 3.1415926… 的前 100 万位的 Kolmogorov 复杂度就不高,因为计算 pi 的前 100 万位的程序不需要多少行代码。由于停机问题的存在,Kolmogorov 复杂度是不可计算的。但这还不是最重要的。Kolmogorov 复杂度也很难成为智能程度的尺度。随机字符串的 Kolmogorov 复杂度是最高的,等于它的长度;一个字符简单重复的字符串 Kolmogorov 复杂度是最低的。
还有一个叫做 “逻辑深度”(logical depth)的度量,指的是能够计算出该字符串的较短程序的最短计算时间,其中较短程序的定义是长度不超过 Kolmogorov 复杂度加上一个常数值的程序。是不是所需计算时间越长的消息就越智能呢?答案是否定的。一个计算比特币区块链中每一个区块的程序(在当前的难度值下)有着很高的复杂度(否则就不需要那么多人挖矿了),但比特币区块链本身只能证明这是一个智慧文明作出的精巧设计,很难说承载了人类文明的大部分智能。
用神经网络估计复杂度
近年来,人工神经网络火起来了,特别是 2017 年的 Transformer,用一个通用的模型解决了 NLP 领域的很多问题。今天的 GPT 也是基于 Transformer。Transformer 还被推广到 CV 等其他领域,成为最有潜力处理多模态数据的通用模型。事实上,从人工神经网络诞生的很早期,我们就知道它理论上可以逼近任意的连续函数,只是那时我们还没找到合适的模型结构、训练方法,也没有足够的算力和数据。
人工神经网络的通用逼近能力意味着它能够比较准确地计算大部分消息的复杂度。尽管准确地计算熵或者 Kolmogorov 复杂度仍然是不可能的,但人工神经网络可以在大多数场景下给出较好的近似。除非消息本身所蕴含的知识是难以学习的,例如消息本身使用 AES 加密了,那么人工神经网络按照目前的梯度下降法是学习不到它的密钥的。
在人工神经网络出现之前,根据输入输出样例搜索通用程序一般被认为是非常困难的,由于我们要求 100% 的准确率。正是因此,Kolmogorov 复杂度往往被认为是一个理论工具,而很难给出比 LZ77 好很多的通用逼近算法。一旦我们跳出精确算法的框子,寻找允许一定错误率的近似算法,就打开了新世界的大门。
人工神经网络是复杂消息的一个极好的压缩器。它可以把消息中的结构提取出来,用于根据一段子串预测下一个字符。预测的准确率越高,长消息的压缩率就越高。整个消息的复杂度就等于模型的大小加上消息长度乘以预测错误率,而压缩率就是消息长度与复杂度之比。预测错误率不会收敛到 0,因为消息中总有不确定性,源自周遭环境的未知信息,并不是由之前的消息能够完全决定的。
使用压缩率作为智能度量的一个显然问题是,压缩率与消息的总长度相关。随着消息总长度趋于无穷,消息长度乘以预测错误率部分的占比会越来越大,模型大小在消息复杂度中的占比会越来越小。而预测错误率显然不能很好地度量智能,模型大小才是智能多少的一个上界。
不同大小的神经网络模型都可以在一定程度上预测下一个字符,只是它们的准确率不同。在模型能够容纳所有知识之前,模型越大,一般来说预测准确率越高。在模型容纳了几乎所有知识之后,预测准确率就很难提高了。预测准确率收敛时的最小模型大小就是智能文明的语言复杂度。
但是,我们仍然无法仅仅根据模型大小区分随机字符串的简单重复和智能体之间充满智慧的对话,因为它们所需的模型大小可能是相同的。
一个简单的想法是给神经网络挂上一块 “内存”,也就是可以随机访问、不计入模型大小的外部存储。这样,随机字符串就可以被存储在这块外部存储中了,整个消息可以用一个简单的模型表达。但是,再深入推演一下,就会发现这个想法完全是错误的。因为任何模型都可以作为一段程序存储在这块外部存储中,而模型中仅需要一个固定大小的通用 “执行程序” 功能,就可以表达任意的程序。程序和数据是可以互相转化的。
复杂度 = 随机性 + 智能
我的浅见是,复杂度本质上一部分来源于随机性,另一部分来源于智能,也就是 Complexity = randomness + intelligence。随机性可能是在消息传输过程中人为加进去的,也可能来源于周遭的环境。来源于环境中的随机性,一个例子就是历史人物的名字和动物的名字。名词数量的多寡并不意味着智能水平的高低,当然现实中往往有一定的正相关性。从模型中剥离出来哪些是随机性,哪些是智能,并不是一件容易的事。
因此,我们回到智能的定义。智能(intelligence)在牛津词典中的释义是 the ability to acquire and apply knowledge and skills。用计算机的话来说,智能就是发现规律(pattern recognition)的能力。
首先,我们根据来自外星文明足够多的消息训练一个足够大的模型,该大模型将包含外星文明的几乎所有知识。事实上,该大模型就是外星文明的一个数字克隆。考虑到人类所掌握的物理规律下信息的传递比物质方便很多,高等文明可能本身就是数字化的。
此时,如果拿一条从外星文明截获的新消息,将前半部分输入给大模型,该大模型将以较高的概率预测出消息后半部分的第一个字符。预测下一个字符听起来与智能相距甚远,但有了下一个字符,就可以预测第二个字符,以此类推……事实上,任何问题都可以被组织成填空题的形式,例如 “中国的首都是__”,那么一个很好的预测器就能表达智能文明中的几乎所有问题,进而体现智能文明解决问题的能力。
其次,我们用这个来自外星文明的模型用来测试在本地文明语料中的泛化能力。因为智能就是发现规律的能力,外星文明的模型也可以学习到本地文明语料中的知识。
但是,简单把本地文明的信息输入给源自外星文明的大模型,让它预测下一个字符是不靠谱的,因为一条消息中含有的本地文明信息太少,对于外星文明来说这条消息无异于天书。这就像是在罗塞塔石碑被发现之前,考古学家始终无法解开古埃及象形文字的奥秘。问题来了,罗塞塔石碑是三种语言组成的对照文本,而我们并没有外星文明和本地文明的对照文本,这还能做迁移学习吗?
语料库够大,罗塞塔石碑就不必要了
考古学家需要罗塞塔石碑是因为古埃及象形文字太少了,也就是语料库太小。神经网络在语料太少时也练不出什么东西。5 年前的我就相信,当语料数量足够大时,总是可以从中无监督地学到知识,无需事先标注的数据。当年的模型还不具备这个能力,是因为模型还不够大,不能容纳世界上的所有必要知识。今天的 ChatGPT 囊括了人类很大一部分的知识,特别是基础语言模型、世界模型、人类常识这部分的知识,而基础模型的训练方式完全是无监督的(不考虑 RLHF 与人类的输出做 alignment),印证了我的猜想。
此外,数学、物理学、天文学、逻辑学等科学是不同文明相通的,这些信息将成为隐形的罗塞塔石碑。
一个文明智能程度越高,就越容易从更少的信息中学到知识,做出更准确的预测。基于这个考虑,我们让这个源自外星的大模型再喂给一些来自本地文明的语料,比较它和仅用这些本地文明语料训练的模型对本地文明消息下一字符的预测能力。为了区分本地文明和外星文明的语料,我们会对它们做不同的标记。如果源自外星的文明(用大模型表征)足够聪明,它就可以从本地文明的少量语料中学到很多关于本地文明的信息,也就是这个数字化的外星文明可以更快地适应本地文明的环境。而只使用同样数量的本地文明语料训练的模型具备的预测能力很可能就更差。
外星文明与本地文明的智能程度对比
根据上述假设,我们可以设想不同智能程度的外星文明在适应本地文明方面的差异。
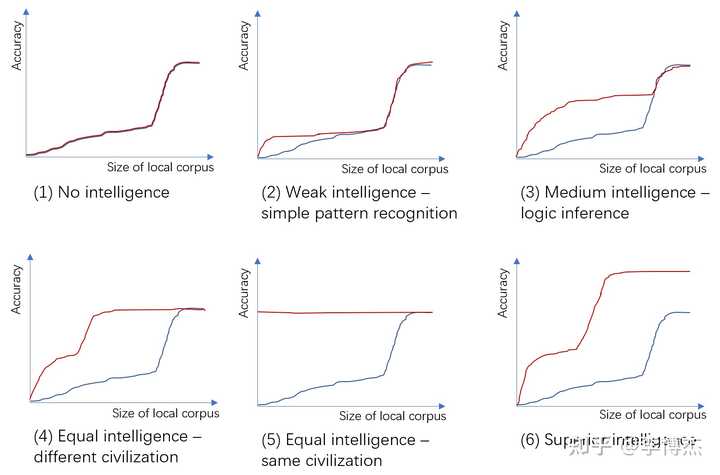

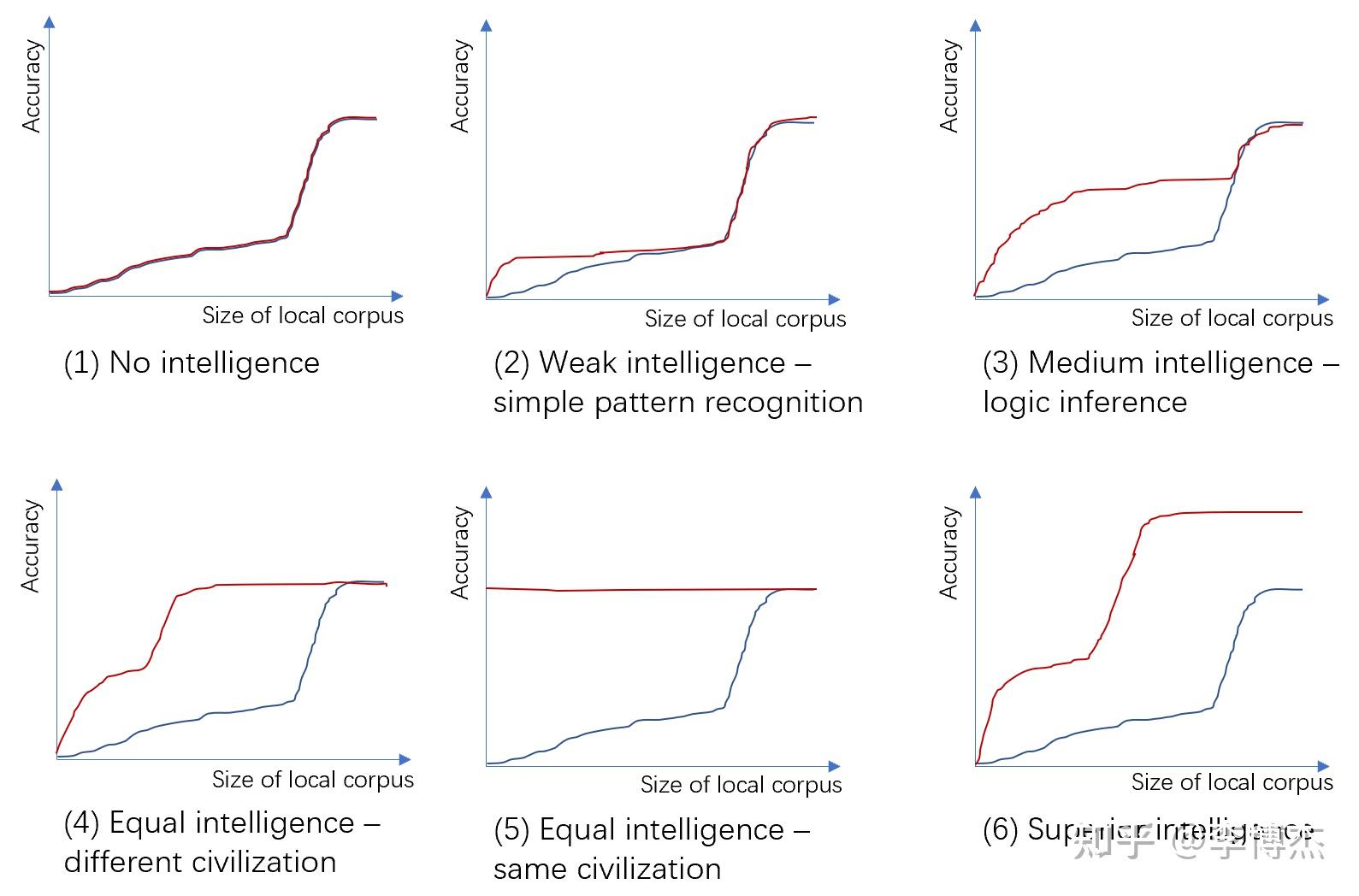
上图:不同智能程度的外星文明与本地文明的对比(猜想图,非实验图)。X 轴:本地文明训练语料库的大小,对数坐标;Y 轴:在本地文明测试语料库上的预测准确度。红线:已经用外星文明语料库训练过的模型加上 X 轴指定大小的本地文明训练语料。蓝线:仅使用 X 轴指定大小的本地文明训练语料。
首先观察仅使用本地文明语料训练的那条蓝色曲线,它的预测准确性在语料数量较少时呈现一定的线性增长能力(语料数量的对数与准确率接近线性),而在语料数量超过一定的门限后呈现暴涨,最后收敛于平台期。
这是由于智慧文明中的任务可分为两类,一类是简单任务,一类是复杂任务。简单任务可以通过识别特征来完成,因此识别的特征越精细,准确率就越高。而复杂任务是由多个简单任务组成的,必须所有任务都正确完成,整个复杂任务才算完成。例如我们解一道数学题有多个步骤,不管哪个步骤出错,最后结果都是错的;我们说一句话也需要很多个字,按照依次预测下一个字的方法,需要每个字都说对才算对。因此,简单任务的正确率达到一定的阈值之前,复杂任务的准确率为多个简单任务准确率的乘积,趋近于 0。只有每个简单任务都能足够精确地完成了,复杂任务才能以可感知的准确率完成。
大模型的这个特性今天叫做涌现(emergence),但是一般指的是模型大小超过一定阈值后准确率突然提升,而我这里指的是训练数据量。不知道我 5 年前的解释是否正确 :)
接下来,我们就要根据外星文明在有限的本地文明语料上的表现来衡量它的智能了。
- 没有任何智能:红线和蓝线完全重合,这意味着外星文明没有任何学习本地文明语料中知识的能力,所有预测能力完全来源于本地文明的新增语料。这就能把复杂度中的随机性和智能区分开来了,一个很长的随机字符串或者一段随机生成的长程序没有任何迁移学习的能力,而哪怕是蚂蚁这种小模型都有一定的迁移学习能力。按照这个测量方式,仅仅表现出一些规律而不具备学习能力的模型不被认为具有智能。
- 弱智能:红线拐点的高度低于蓝线的拐点,在暴涨期跟蓝线重合。蓝线的拐点表示简单任务和复杂任务的分界,简单任务具备线性增长能力,而复杂任务呈现暴涨特性。由于外星文明具备一定的简单模式识别能力,只需少量本地文明语料就搞清楚了一些简单规律(比如 q 后面一般跟着 u),从而比单纯使用本地文明语料学习得更快。当然,也有可能蓝线反而会低于红线,也就是说外星文明和本地文明的差异实在过大,外星文明的模型完全迁移不过来,还反而降低了学习本地文明的速度。但是由于外星文明和本地文明的语料有不同的标记,这种情况发生的可能性不高。由于外星文明的语料不具备逻辑推理和完成复杂任务的能力,它在暴涨期并不能帮上忙。
- 中等智能,但比本地文明更弱:红线的拐点高于蓝线的拐点,红线的暴涨期与蓝线部分重合。这表示外星文明具备一定的逻辑推理和完成复杂任务能力,但智能程度低于本地文明。外星文明能够从少量本地文明的语料中学到外星文明和本地文明概念之间的对应关系,从而快速达到外星文明的最高智能程度,但它不具备本地文明中部分复杂任务的处理能力。一个例子就是 1000 年前的人类和今天的人类,古人也有很不错的逻辑推理能力和完成复杂任务的能力,但对自然界的认识和计算能力肯定不如现代人类。
- 同等智能:使用外星文明语料预训练的模型,也就是红线,只需少量本地文明语料就能学到外星文明和本地文明概念之间的对应关系,从而达到同等的智能程度。一个例子是使用英语的现代人和使用汉语的现代人。这是中等智能的一个极限特例。
- 同等智能的特例,外星文明 = 本地文明:在外星文明 = 本地文明的特殊情况下,“外星文明” 出道即巅峰,新的本地文明语料起不到任何帮助。这体现了智能的相似程度对这种测量方式的巨大影响。外星文明和本地文明越相似,学到两种文明概念之间对应关系所需的本地文明语料就越少。也就是说,在本文的测量方式下,外星文明与本地文明越相似,本地文明就可能认为外星文明越智能。目前我还没有想到衡量文明的 “绝对智能程度” 的方法。
- 强智能,比本地文明更强:如果外星文明比本地文明更强,它只需少量的本地文明语料就能学到两种文明间的概念对应关系,并解决本地文明中解决不了的难题,也就是它的预测准确率可以比本地文明更高。当然,这类文明的相对智能程度可能并不容易衡量,因为本地文明可能根本没有能力提出足以区分不同强智能文明的问题,本地文明用于训练大模型的算法和算力可能也不足以训练出足以展现外星文明水平的模型。这也很容易理解,一个人很难衡量比自己强很多的人的绝对水平。
尽管智能程度难以量化,我们也不妨给出一种智能程度的标量测度,就是红线和蓝线之间的最大垂直落差,也就是使用相同数量本地文明语料时外星文明 + 本地文明模型和纯本地文明模型在预测本地文明对话任务上的精确度之最大差值。
可以看到,在外星文明学习能力相同的前提下,它与本地文明的相似度越高,这样定义出来的智能程度也就越高。我也想过如何量化复杂度(模型大小)中属于智能的一部分,或者如何排除随机性的那一部分,但是始终没有找到方法。
用今天的话说,外星文明就像是预训练模型,而本地文明就像是微调(fine-tune)模型。GPT 就是 Generative Pre-Training(生成式预训练)的缩写,可惜 5 年前还没有发布。当然,这样的类比是很不严谨的,因为不同文明之间的差异比 fine-tune 语料和预训练语料之间的差异大多了,而且一般 fine-tune 语料不会比预训练语料更多。
我们也许并不孤独
5 年前的那个冬夜,我发送的是各种语言维基百科的合订本。《三体》里面的红岸基地在发送信息之前需要先发送一个 “自解译系统”。事实上,从前文不难看出,高质量的语料本身就是自解译系统,根本不用担心我说的是汉语,外星人说的是英语;也不用担心我用的是十进制,外星人用的是二进制。一个有着强大算力的外星文明只要通过简单压缩算法的压缩率来粗略筛选掉随机噪声和简单重复信号,留下看起来像包含智能的消息,然后扔进大模型里面训练,就能从消息中重建文明的一大部分智慧。
百年来,人类已经向宇宙发射了无数的无线电波。特别是长波电台广泛存在的年代,这些无线信号对于距离我们较近的外星文明而言,是很容易与宇宙背景噪声相区分的。如果外星文明足够聪明到使用大模型来处理这些无线信号,也许它早就洞悉人类社会的一切秘密,无需等待阿雷西博信息或者更复杂的 “自解译系统” 提供密码本。也许外星文明早就用这些无线信号训练出了人类文明的数字克隆,等待我们某一天在宇宙中老友相逢。也许在不远的未来,当我们用大模型处理从宇宙深处传来的电波和光波时,才会惊奇地发现,宇宙中的智能原来无处不在,只是人类之前的解码技术太过低级。
有趣的是,今天很多 AI 创业公司的名字跟星际探索相关。也许创始人们是想表达 AI 是类似星际探索的一项充满想象空间又能改变世界的创新事业。我从 5 年前开始延续到现在的思考,则更直接地把 AI 和星际探索联系在一起:AI 模型将成为人类文明的数字化身,跨越人类肉体的时空限制,把人类真正带到太阳系甚至银河系之外,成为星际文明。
后记
尽管我不是做 AI 的,但 5 年前的一点小思考跟今天大模型的一些表现还是很接近的。当然,这也许仅仅是巧合,我的观点很有可能是错的,毕竟我没有做任何实验。如果我未来有时间,也许可以拿地球上不同年代和地区的文明,甚至不同生物的文明去做个实验。
不过,如果一个研究 AI 的人连我这个门外汉写的文章都看不懂(注:不包括看懂了,但不同意文中的观点),那说明根本没有思考过 AI 领域的基础问题。我去看 OpenAI 首席科学家 Ilya Sutskever 过去 10 年的文章,发现他的思考真的非常深入,不是只关心 CV 或者 NLP 中的某个具体问题,而是从全局出发思考 AI 领域的基础问题。尽管我在网络和系统领域只有很初步的研究,但我深知,要提出好的问题,做出好的研究,必须对领域内的基础问题有足够深入的思考,而不是看看最近几年顶会上哪个话题被研究得多,就跟风做一篇论文。
发布于 2024-05-05 12:30・IP 属地山西查看全文>>
李博杰 - 53 个点赞 👍
基本不可能。
让我们考虑最简单的一种情况,也就是主谓宾结构。你立刻就会发现,几乎每个词都可以当主语、宾语,你至多可以区分出一大坨符号是名词,另一坨是动词,但无法做进一步的区分。
费曼就吐槽过这种学者。他们给失传的某种文字极多“天才”的解释,一看就专业、自洽、可靠…
但费曼发现,这种文字里面有几个符号出现的很频繁,而且总是在一起出现。这样的符号有10个、12个或者16个。于是他就考虑,如果他们是数字的话,这些数字都会是什么呢?
于是,他统计了所有这些疑似数字的各种组合,识别出了它们的进制;然后,天文学在古人生活中占据重要地位,那么一串最多30种变化的数字应该就和月相相关,其中满月相关的15、16应该出现的更频繁;类似的,360左右的数字应该和太阳相关,类似的还可以找出木星周期、火星周期相关的数字。
借助这种统计学手法,配合天文学方面的知识,他很快确定了这种文字的计数方式;然后,一段文字频繁出现天体周期相关的数字,它就很可能在谈论这个天体相关的事情。那么数字附近往往会出现代表这个天体的文字。
通过统计和推理,他找到了代表太阳、月亮、木星、土星、火星的符号;再借助这种符号、以及相关的天体周期、较大的天文事件,就可以确定文字对应的年代,继而破解这种文字的纪年法等东西。
通过这方面的研究,费曼有力的证明了那些学者就是在胡扯八道。比如明明是一段记叙日食的文字,他们会胡乱解读成诗词歌赋或者爱情故事。
费曼发明的这种方法在破解未知古文字时相当犀利;但它只能破解天文相关的部分,其他方面仍然无法破解。除非我们知道他们大致在谈论哪方面的东西,否则各种猜测大概率只是天才的胡扯八道。
发布于 2024-05-08 01:11・IP 属地广东真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
invalid s - 9 个点赞 👍
得看这些书是什么书。
在很多情况下破译不出来。
比如,都是哲学书的话,很难。
维特根斯坦的观点可以作为佐证:
1,哲学家们脱离了语词在日常生活中的使用。
2,哲学家使用语言犹如一种游戏,他们已经不能表达实在的事物,只能靠词语之间的关联产生意义。
可以简单理解为,如果这些书本都是互洽的孤立体系的话,就无法实现精确的破译。
类似于过拟合了。
编辑于 2024-05-05 22:44・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
墨苍离 - 2 个点赞 👍
要看这种语言的加密程度
如果这一亿本书上 并没有一个重复的符号 那么就无法破译出来
如果这一亿本书上 图文并茂 有很多重复的符号 那么 就可以破译出来
所以 假如有一种未破译灭绝语言,有关于这种语言的一亿本书,能不能用超级计算机把这门语言用套的方式破译出来?
这个问题的答案是 无法验证的
给出的条件 无法正确得出 是否可以破译出来的准确结论
无法验证是认识者与认识目标之间确实存在的关系 是一种客观事实 可以到我的栏目中了解一下 什么是 无法验证
发布于 2024-05-05 21:39・IP 属地辽宁查看全文>>
验证主义 - 0 个点赞 👍
查看全文>>
那七