
这个问题非常好,其实其本质就是如何理解具备一定语料的未知语言,也就是与一门已知语言建立联系。
这是语言学的一大话题,比如田野语言学需要记录方言乃至从未认知过的语言,历史语言学可能要根据死语言有限的材料尽可能破译信息,比如罗塞塔石碑,或者线性文字AB等。语言学奥林匹克竞赛(National Linguistics Olympiad,NOL)的题目完全就是根据一些未知语言和已知语言的对应关系来推断出未知语言的词汇含义和语法。语言的可能空间非常大,单纯靠暴力猜词是很难搜索到正确结果的。
当然题目的设定其实和上述设定有两点不同。第一点是语料数量。题目中提到这门语言有一亿本书,这其实是田野语言学和死语言解读完全无法想象的数量,比如田野语言学只能从语言老师那里获得有限的几百句话和几百个单词,而罗塞塔石碑甚至只有一块小小的碑文。这是题目设定有利的地方。

第二点则是无显著的平行语料。平行语料指的是未知语言以及其已知语言的翻译,比如“apple”对应苹果,“天気がいい”对应天气很好。在田野语言学中,我们可以问掌握未知语言的语言老师“这个东西是什么”,那么获得的语料天然具有注释。语言学奥赛也会给出一些词汇的解释。而罗塞塔石碑同时记录了三种内容相同的文字:希腊文,古埃及草书文,古埃及象形文,其中希腊文是人们非常熟悉的。有了平行语料,人们可以根据一些对应关系猜测词汇的含义,比如频率高的词可能有语法作用,人名相应的拼写可能差不多等等。如果一点没有平行语料没有,对我们的破译会非常不利。当然如果使用这门未知语言的人会学外语,那么可能会有一些书籍记录了外语和该语言的对应关系。可是这就需要挖掘了。
考虑这两个特点,我们应该怎么解决这个问题呢?其实我们可以使用现在非常火的语言模型。
语言模型
虽然有蹭热度以及拿着锤子找钉子的嫌疑(doge),但语言模型其实是非常适合题目的设定的。最通俗地理解语言模型,就是给一句话,模型输出这句话之后什么词有多少可能出现,比如让模型看“苹果很”这句话,那么可能“甜”这个词的可能是 0.8,而“罗纳尔多”的可能是0.001,如此类推。“什么词有多少可能出现”其实就是一个分布,语言模型实际上是把语言看作一个巨大的概率分布。这个分布很有用,比如我们可以从分布中用一些方法选词,这样就能生成文本了。
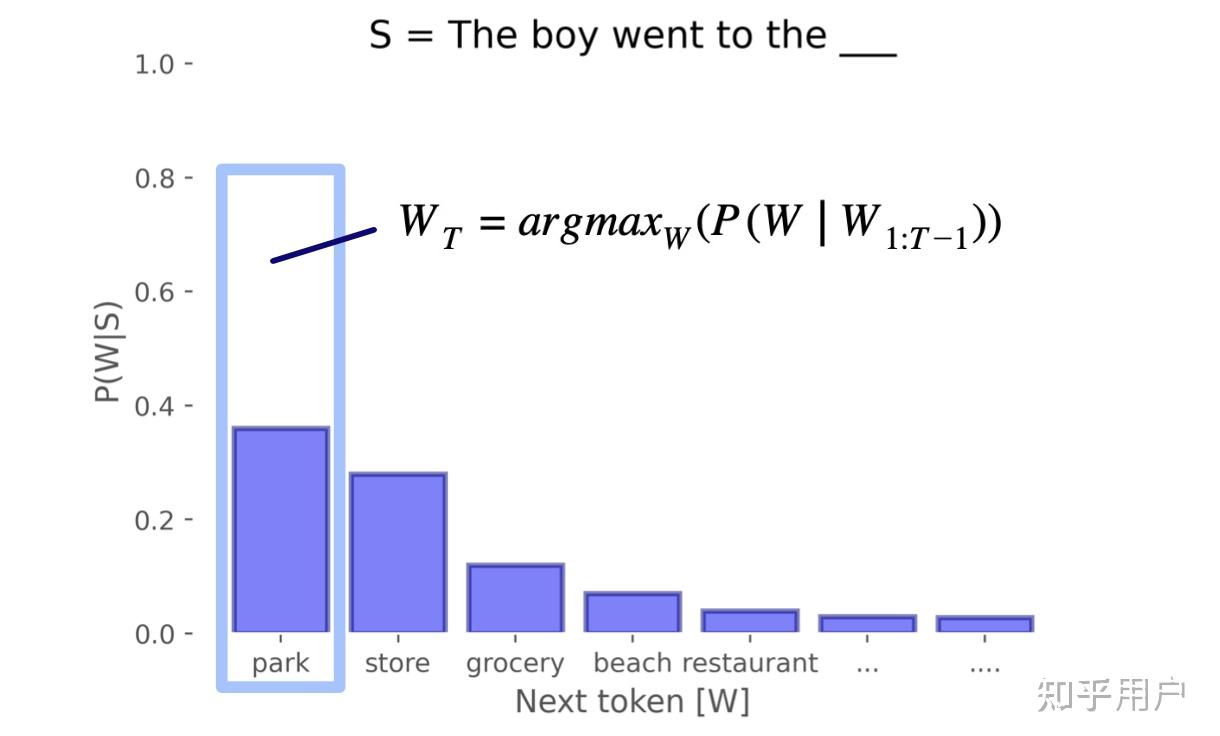
为了构建语言模型,也就是训练语言模型,我们需要让模型不断根据前文推断出下一个词的分布,然后计算模型的预测和真实值的差距(损失),然后根据损失调整模型。这是目前最流行的神经网络语言模型的主要流程,此外还有传统的 ngram 模型等,在此不讨论。
语言模型有两个特点很适合题目的场景。第一个特点从上面的文字其实可以看到,就是训练一个模型只需要文本自身就可以了,不需要其他信息,也就是说语言模型是自监督(Self-Supervised)的。最简单的语言模型只需要闷头一个词接一个词地预测,然后“对答案”就好了,不需要语法知识或者其他语言的信息。这就天然解决了无平行语料的问题。
第二个特点其实是神经网络语言模型的特点,就是训练数据越多,模型表现就越好。这被称为 Scaling Law。在题目设定的情况下,假如有一亿本书,假设每本书有九万个单词(GPT-4说的成人小说平均单词量),那么就有九万亿个单词可以训练模型,即使里面可能有些数据不好,假设有四万亿本书质量不行,那么也有五万亿个token。用来训练模型绰绰有余了。
当然,满足了这两个特点只能说明语言模型能用于这个情景,但是语言模型真的能够解决我们的问题,构建未知语言到已知语言之间的关系吗?
语言模型的跨语言迁移
这就要说到语言模型的第三个特点,语言模型的跨语言迁移能力(Cross-lingual Transfer)了。如果模型已经学习了一门语言 A 的很多资料,仅仅学习少量用另一门语言 B 编写的内容,语言模型也能非常好地掌握语言 B 的相关能力,并利用语言 A 内容里面的知识。
GPT-2[1] 是 OpenAI 于 2019 年训练的 Transformer 语言模型,其训练材料大部分是英语,他们在整理训练数据集时特意使用了语言分类器来过滤非英语的内容。当然这种过滤不是完美的,比如训练数据里有 10MB 的法语内容,听起来很多,但 GPT-2 整个训练集有 40GB 之大,这就像 OpenAI 把一整个书店的书拿去训练模型,其中只有几本书是法语书。然而即便是这样,GPT-2 在 WMT-14 法译英任务上的表现,也远远超过了拿多得多的法语材料训练的模型的能力。英译法的能力稍微差一点,但是也超过了基线。
RWKV 是彭博研发的一系列 RNN 语言模型,RNN 和 Transformer 是两种不同的神经网络架构,当然其差异对于本文来说不重要。RWKV-v5 [2]在很多多语言任务上表现非常出色,比如因果推理,句子翻译等等,但是它并没有特意在这些语言上训练这些任务,只是在训练时见过各种语言的数据而已。
以上模型的语言迁移能力比较意外,而另外一些模型是瞄准着多语言能力来训练的,比如 mBERT 和 XLM 等。mBERT 由 Google 推出,在 104 种语言的维基百科数据上面训练,所有语言都共享一套参数。BERT 系列模型采用掩码语言模型,也就是在材料种挖空,让模型补全挖空。XLM 模型来自 Facebook,其预训练任务中增加了翻译语料的任务。
对于这些模型来说,这些少量的其他语言的数据就像题目中的未知语言一样。通过预测下一个词,模型就能神奇地做各种相关任务了。所以我们就可以确定方向了:
- 选择一个掌握了语言 A (比如英语)或者多种语言的语言模型,比如 GPT-2 / Llama 3 / RWKV-v5
- 用未破译语言 X 的数据训练语言模型
- 让语言模型做 X 翻译到 A 的任务,胜利!
有一些技术细节需要考虑,比如如果语言 X 的书写系统不是拉丁文,那么可能需要修改语言模型的词表,涵盖语言 X 的单词;第三步的任务需要给一段初始序列也就是提示词(prompt)来让模型开始做翻译任务,GPT-2 的法译英任务用了 "<法语句子>=<英语句子>...<法语句子>="的格式,其中前面是英语法语句子对,让模型“进入状态”,最后一句法语句子是需要翻译的。
跨语言迁移背后的理论解释
上述做法很粗暴,没有任何高深精妙的理论,但是很奏效(doge)。但是怎么理解呢?首先我们还要回到语言模型的训练目标:预测下一个词。这种做法其实很深刻,用一种训练目标统一了非常多的任务:
- 如果给模型的材料是,”英文:Thank you,中文:谢谢你。“那么预测“谢谢你”的过程,本质上就是在学习如何翻译 Thank you。
- 如果给模型的材料是“我讨厌 perfume 这个词,Burr 说。法语里的说法更好听:parfum”,模型也会掌握如何翻译 perfume。
- 如果材料是“圆周率的值是3.1415926”,那么预测“3.1415926”其实就掌握了圆周率的大小的这一知识。
- 如果材料是百度贴吧里的帖子:“A:<一些观点>B: 啰啰嗦嗦的,不就是……”,那么模型其实在学习如何总结材料。
上面三个例子其实也有层次,第一个例子格式很规整,清晰地展示了英文和中文的对应;第二个例子也比较清楚但没那么格式化,第三个例子和则非常随意,但是里面潜藏了一些能力。第一个例子的数据很少,需要可以收集,但第二个和第三个例子这种非结构化数据则遍地都是。其实这些材料都是某种意义上的平行语料,将不同任务都转化为了A与B的对应关系,通过预测下一个词,模型自行挖掘了数据中潜在的平行语料,而反向传播强迫模型必须学习背后的规律。因此之前提到的方法取决于有多少平行语料。
语言之间的共通性
但是潜在的平行语料终究是整体语言材料的一小部分,剩下的能力是怎么构建的呢?我们需要再深入理解语言模型为什么能学习语言,在这其中分布假说(Distributional Hypothesis)扮演了很重要的角色,也是语言模型能建模为概率分布的基础。一个词的含义是怎么决定的?并不是委员会开个会把几万个词都一一设定意思;一个词的含义是由其他相伴的词决定的。比如“苹果”相伴的词有“红”“吃”“酸甜”“水果”“市场”等等,这些词与苹果之间的共同出现就形成了苹果这个词的意思。那么对于两种不同的语言,如果两个词的相关的词都是类似的,那么这两个词的意思就相近。
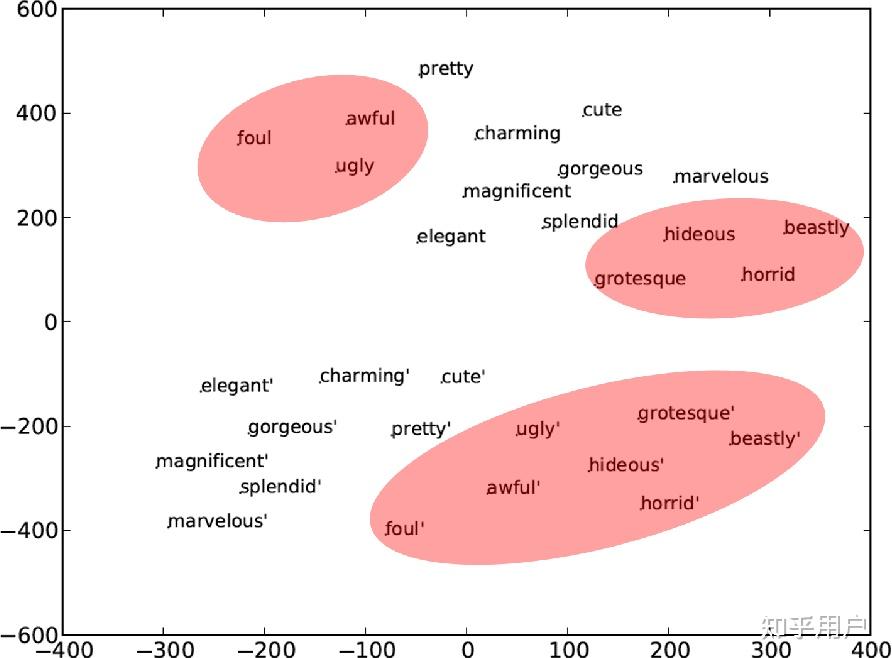
最简单的分布假说往往只考虑临近的几个词,但是Transformer为代表的语言模型能够考虑相距上千乃至上万个词之间的联系,这就能更加合理的建模词语之间的关系,进而建模词语的含义了。
不仅词义之间有相似之处,语法之间也有相似之处。自然语言有上千种,但是语法结构大抵都是相似的,比如语序上主谓宾和主宾谓语言占据了大部分,语法上则有主宾或者作通等少数几套非常通用的系统。观察到这些现象,Noam Chomsky 提出了共通语法(Universal Grammar)的概念,认为所有语言背后有一套相同的结构支撑。其依据则是刺激贫乏(Poverty of the Stimulus),即人类童年接受的数据不足以让人类掌握其语言的所有组分,但大部分人还是能掌握母语的绝大部分语法,说明人脑有一些天生的通用机制来掌握语言。当然这个假说是有比较多的争议的,不过也能从侧面佐证语言的共通性。
语言模型不同模态之间的迁移
下一个问题,这些材料中可能不只有文字,还可能有图像,表格等等,或者如果这个语言还有音频资料,怎么利用这些信息呢?
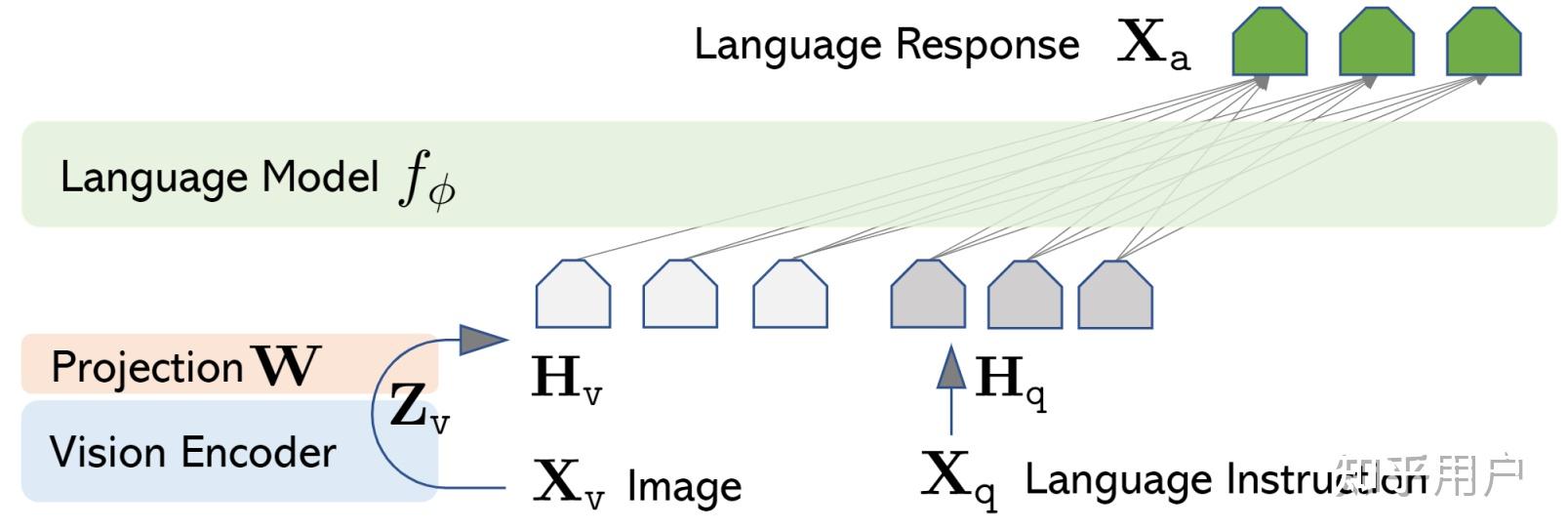
其实语言模型经过微调后也能利用这些信息,这就是神经网络的神奇之处(doge)。最简单的结构可以参考 LLaVA[3],通过一个视觉编码器将图片转化成一系列 token,之后让整套模型来自行学习如何处理视觉 token 和文字token。
语言模型不仅能在不同语言之间迁移,也能在不同模态之间迁移。比如有人用语言模型分类图片,学习蛋白质的折叠,一个经过充分语言训练的模型便能取得不错的表现,达到和在这些任务上单独训练的模型的效果[4]。
结语:通用智能与压缩
从物理学的牛顿定律到语言学中通用语法,从机器学习早期手动构建特征到 Transformer 语言模型一通四方,人类一直在追求通用的模型。通用意味着压缩,找出繁杂现象背后的普适规律,用最短的序列传递最多的信息量。开普勒将数以万计的观测数据压缩成三条定律,牛顿又将数以百计的实验定律压缩成三条定律,这个过程与神经网络将万亿的语言数据压缩成区区几十G的权重,进而服务于破译语言,总结问答等等任务,其实是殊途同归。
参考
- ^GPT-2 paper https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- ^https://zhuanlan.zhihu.com/p/659872347
- ^https://llava-vl.github.io/
- ^https://www.semanticscholar.org/paper/Frozen-Pretrained-Transformers-as-Universal-Engines-Lu-Grover/3aa2c10dd6c72267ea8a622c8f30b3c9240d5fab?sort=relevance&page=4&citedSort=relevance&citedPage=2