
不知道为什么这么多答案说不行,还有些答案扯到LLM上去了,实际上这个问题早在LLM时代之前就有成熟的方案了。
通过语言学手段,其实已经能解决大多数失传文字,例如甲骨文、古埃及文字、古巴比伦文字这些的破译工作。题目所说的能否基于计算机通过大量语料进行破译,实际上就是NLP中的无监督机器翻译问题,这一块也早就有大量的研究工作。
Word2Vec时代
从Word2Vec开始,词袋模型告诉我们词向量大致是满足线性规律的,例如我们单词可以在Embedding空间中进行这些计算:
\text{one} + \text{two} \approx \text{three}
\text{king} + \text{woman} \approx \text{queen}
\text{French} - \text{Paris} \approx \text{England} - \text{London}
就在提出Word2Vec之后,还是2013年,Mikolov就给出了利用词向量模型在不同语言间进行无监督翻译的方法。对于不同的语言而言,同样语义词汇之间的相对关系依然不变,例如我们换到中文里还是会满足:
\text{一} + \text{二} \approx \text{三}
\text{国王} + \text{女人} \approx \text{女王}
\text{法国} - \text{巴黎} \approx \text{英国} - \text{伦敦}
即不同语言中,描述同种事物的词汇之间的相对关系保持不变。一种挖掘这种关系的方式是PCA降维,PCA的本质是对样本的协方差阵进行特征值分解,从而拆解出一个旋转矩阵和一个基矩阵。
而我们已经知道不同语言中的词汇相对关系是一致的,只不过词汇的表示不一致,也就是说两种语言的词向量矩阵是相似的——两个矩阵仅相差一个旋转变换。利用PCA降维将这个旋转变换去除掉后,两个矩阵也就得到了对齐。
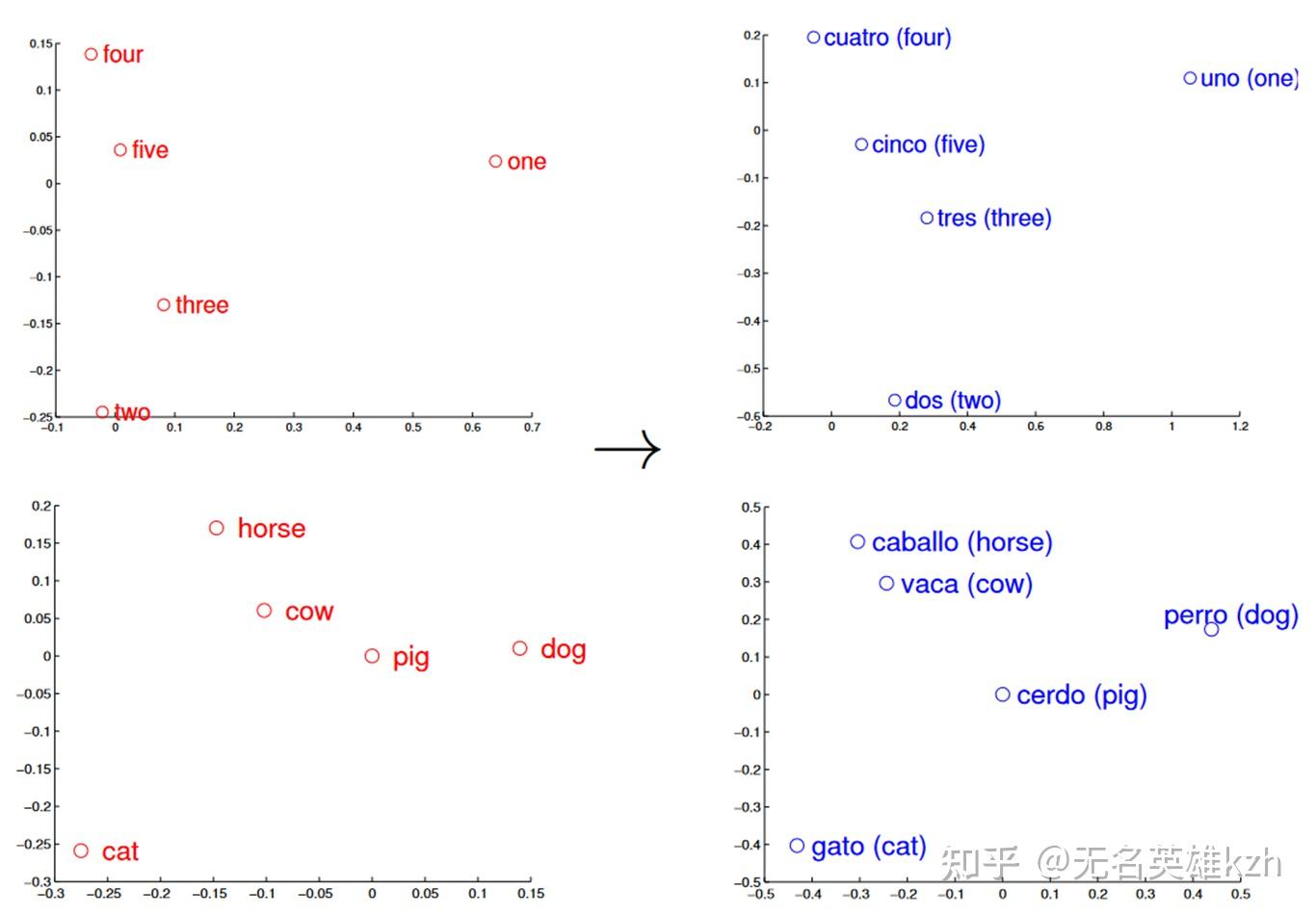
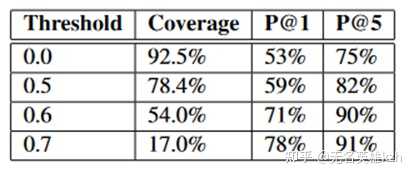
在论文中实际仅学习了一个映射关系 \min_{W} \| WX-Z \|^2 ,其中X是源语言,Z是目标语言,W就是映射矩阵,这么一个简单的方法就能对大多数词达到53%的准确率,考虑top5结果能达到75%,高置信度部分甚至能达到91%。
Transformer时代
跨入Transformer时代后,无监督翻译更牛逼了,这里就介绍下比较经典的回译(back-translation)的做法。
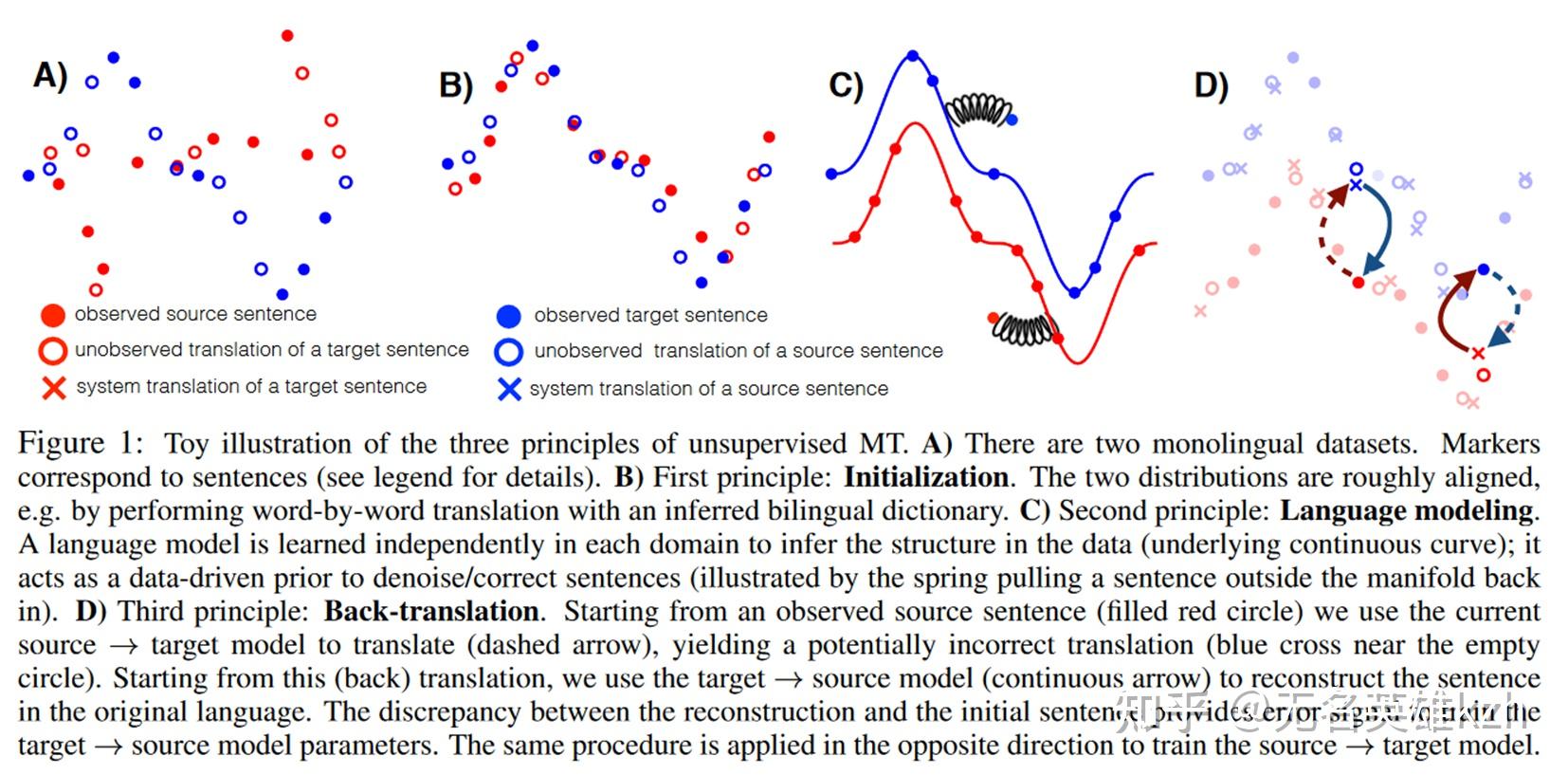
回译的做法相当巧妙,它妙在利用了译文的译文等于原文这一点,从而脱开了对平行语料的依赖。具体步骤如下:
- 先搞一个粗对齐的语料,比如收集两种语言大量的语料,然后利用上面的方法先把词汇对齐了,然后简单按词翻译一下,差不多就行。
- 用两种语言的语料建立两个语言模型,然后再用粗对齐语料初始化 f(源语言)->目标语言 和 g(目标语言)->源语言 两个翻译模型。
- 回译训练
- 从源语言拿出一条句子x,计算f(x)作为一条x的伪翻译
- 再计算g(f(x))将伪翻译结果翻回源语言
- 由于g(f(x))是x翻译的翻译,因此 x=g(f(x)),这就是回译的损失函数
- 然后再从目标语言拿一条句子y再来一遍 f(g(y))=y
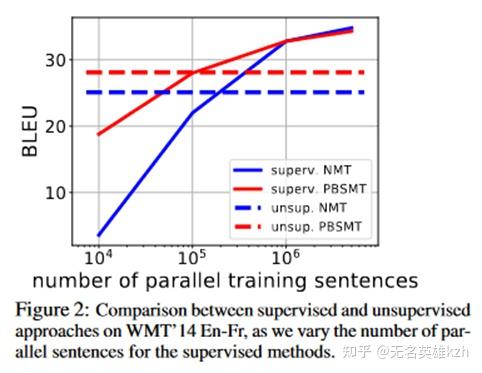
论文在英法翻译上的实验结果表明,使用回译的无监督学习差不多相当于使用10万条平行语料进行有监督学习的结果,这个结果还是相当可观的。
LLM时代
在LLM时代,模型拥有了和人类一样的学习理解能力,更加毋庸置疑我们具有这样的翻译能力。我们可以做一个思想实验,拥有无限语料的LLM学习,就好像将一个盲人小孩扔到一个全新语言环境中学习,那么他显然如同大多数先天性视障人群是可以学会语言的,此时我们将他又扔到一个新的语言环境,保持学习能力不变,他依然可以学会一种新的语言。那么此时的他,会因为没有对照表就不知道两种语言怎么对应了吗?显然不会。
我们之所以拥有这种跨语言的翻译能力,本质上是因为我们有着相似的生活环境和生活方式,比如我们都需要数字进行计数,那就可以根据数字的大小关系建立映射,我们都要在说话的时候进行指代,“你我他这那”就总是有相似的出现规律。这种来源于世界本身的相似性保证了语言语义结构的相似性,也就保证了我们只需要去求解某种最小化的映射,就能保证翻译结果八九不离十。
那么这种翻译只会在一种情况下失效,也就是对面文明和我们的生存环境大不相同,他们平时不数数、不运动,没有视觉和听觉感官,思维混沌无法理解。那面对这种克系语言,我觉得应该确实没有什么办法在两者之间建立映射,毕竟此时是否存在合理的映射都难以保证了。
参考文献:
[1] T. Mikolov, Q. V. Le, and I. Sutskever, “Exploiting Similarities among Languages for Machine Translation,” arXiv:1309.4168 [cs], Sep. 2013, Accessed: [Online]. Available: http://arxiv.org/abs/1309.4168
[2] G. Lample, M. Ott, A. Conneau, L. Denoyer, and M. Ranzato, “Phrase-Based & Neural Unsupervised Machine Translation,” arXiv:1804.07755 [cs], Aug. 2018, Accessed: [Online]. Available: http://arxiv.org/abs/1804.07755