英伟达宣布推出最强 AI 芯片,成本和能耗较前代改善 25 倍,哪些信息值得关注?

- 1 个点赞 👍被审核的答案
台积电董事长刘德音去年9月时所说的一句话,让CoWoS技术再一次成为全球关注焦点:
现在AI芯片短缺,缺的不是芯片,而是缺CoWoS封装(如下所示)产能。
Chip-on-Wafer-on-Substrate (CoWoS) - TSMC 时间回到今年3月中旬,日月光高级副总裁Ingu Yin Chang在其分享的《异构集成加速人工智能经济发展》主题演讲中有了更为详细的表述:
世界正在向AI时代迈进,人工智能和数据将继续推动半导体创新,AI芯片于智能手机、自动驾驶、自动化机器人等应用,带动半导体需求成长,到2030年及以后,其指数级增长将塑造全新的生活方式。
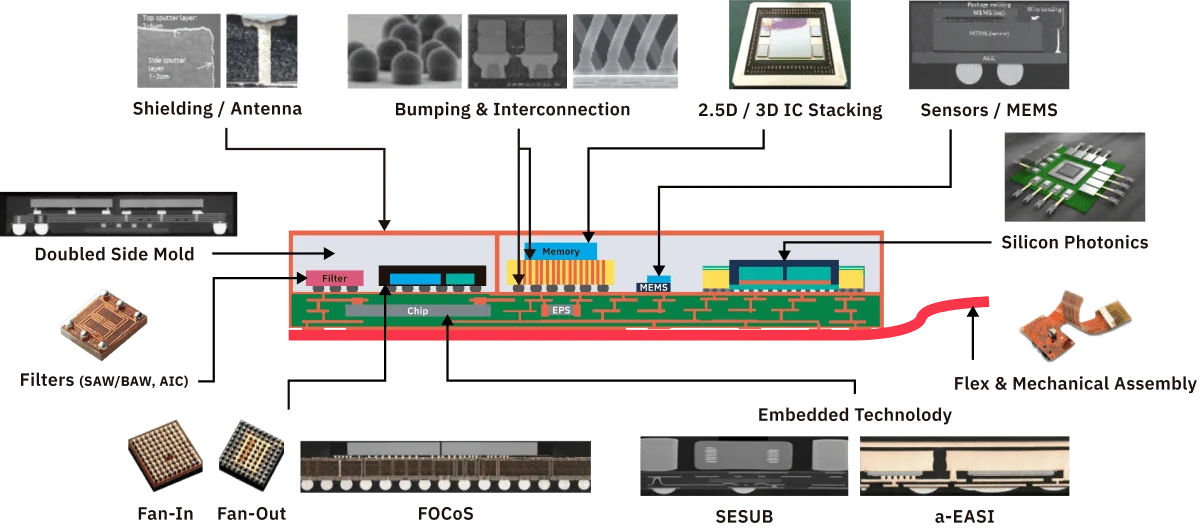
半导体行业正在通过异构集成加速人工智能经济一体化发展;创新的封装方式能够使多个Chiplet、SiP和模块无缝集成到一个封装中,以增强功能性能和操作特性。针对二位的发言,我们不难看出:一场由CoWoS技术为代表的异质集成技术,或将成为本次AI芯片算力革命的关键节点。
异质集成技术成为AI芯片算力革命关键节点的主要原因在于:它能够解决传统单一芯片设计在性能提升、能效比优化和空间利用率上遇到的物理和技术瓶颈。

异构集成的技术(HI)构建模块,图片来自:ASE 或许正是由于以下几个因素共同作用,使得异质集成技术成为了本次AI芯片算力革命的关键节点:
提高计算效率:
异质集成允许将专门的加速器直接集成到处理器旁边,如AI加速器、图形处理单元(GPU)、数字信号处理器(DSP)等,这些加速器可以针对AI算法进行特殊优化,从而显著提高特定任务的计算效率。
例如:TPU(Tensor Processing Unit)就是专为加速机器学习算法而设计的,可以提供比传统CPU更高的性能。符合低功耗和小型化的需求:
在AI应用中,尤其是在边缘设备上,功耗是一个非常重要的考虑因素。异质集成技术通过优化芯片内部的数据流,减少了数据在不同处理单元间的传输距离,从而降低了功耗。
此外,能够将特定任务交给最适合处理该任务的单元,避免了在不需要时运行高功耗的处理单元,进一步降低了整体功耗。
将不同的处理单元集成到一个芯片上,可以显著减少芯片所需的总面积,这对于需要将大量功能集成在有限空间内的移动设备和穿戴设备尤为重要;这种集成还减少了需要额外封装的独立芯片数量,进一步节省了空间。提高带宽和减少延迟:
异质集成技术通过在芯片内部创建更短的连接路径,提高了处理单元之间的通信带宽,减少了数据传输延迟。
例如,通过使用硅通孔(Through-Silicon Vias, TSVs)技术,可以在堆叠的芯片层之间直接建立连接,这对于需要高速数据交换的AI应用至关重要。除上述工技类提升所带来的直观突破外,在AI芯片的发展中,异质集成技术也因以下三点为AI芯片的高度定制化铺平了道路:
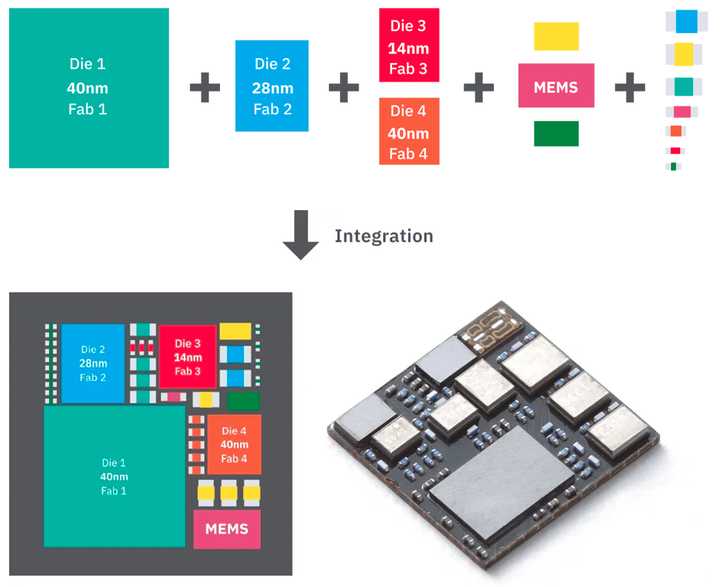

图片来自:ASE 针对特定算法和应用的优化:
AI领域涵盖了广泛的应用和算法,每种应用对芯片的要求各不相同。异质集成技术允许在同一芯片或封装内集成专为特定任务优化的加速器(如神经网络处理器NPUs、图形处理器GPUs等),以及针对特定算法优化的逻辑电路。
这意味着可以为深度学习、图像识别、自然语言处理等不同的AI任务定制硬件,从而在算法层面上实现最佳的性能和能效比。模块化设计:
异质集成技术支持模块化的设计理念,使得芯片设计更加灵活。设计师可以根据最新的技术进展或市场需求,选择最适合的处理单元和存储模块进行集成。
这种模块化设计不仅加快了产品的开发周期,还能在产品发布后快速响应市场变化,通过替换或升级特定模块来提升产品性能或降低成本。支持多技术节点集成:
异质集成技术使得可以在同一封装中集成不同技术节点的芯片。这意味着即使是使用较老工艺制造的组件(如I/O或模拟信号处理器),也可以与使用先进制程技术制造的高性能计算核心(如CPU、GPU)集成在一起。
这种跨技术节点的集成为产品设计提供了更大的灵活性,使得开发者能够根据性能需求和成本考虑,选择最适合的技术组合。最近几年,随着异质集成技术的不断发展,异质集成技术或早已落地生花。
美东时间4月9日周二,在今年举办的客户与合作伙伴大会Intel Vision 2024期间,Intel正式发布第三代Intel AI加速器Gaudi 3也被大众视为异质集成技术的再一次应用落地。


图片来自:Intel Gaudi 3采用5纳米工艺制造,专为高效的大规模 AI 计算而设计,其具有64个第五代张量处理核心和8个矩阵计算引擎,采用128GB 速率达 3.7TB / s 的 HBM2e 内存和 96MB 速率达 12.8TB / s的SRAM,还具有24个200 Gbps以太网RDMA NIC以及最高 16 条 PCIe 5.0 总线。
对比英伟达的芯片H100,如果应用于7B和13B参数的Meta Llama2 模型以及175B参数的OpenAI GPT-3模型中,Gaudi 3预计可以让这些模型的训练时间平均缩短50%。
应用于7B和70B参数的Llama以及180B参数的Falcon模型时,Gaudi 3的推理速度相比英伟达H200提高30%。不光Intel,异质集成技术或早已成为多个大厂看门绝技,尤其在多个芯片高速互连集成中表现突出:
NVIDIA:NVIDIA使用异质集成技术开发了一系列高性能的GPU和AI加速器,如NVIDIA Tesla V100和A100。这些产品采用NVIDIA的NVLink技术,可以将多个GPU通过高速互连集成在一起,提供前所未有的并行计算能力。
Google :Google的Tensor Processing Unit(TPU)是专为加速机器学习应用而设计的AI处理器。TPU采用异质集成技术将高性能的计算核心与大量的内存集成在一起,以优化机器学习任务的处理速度和能效。
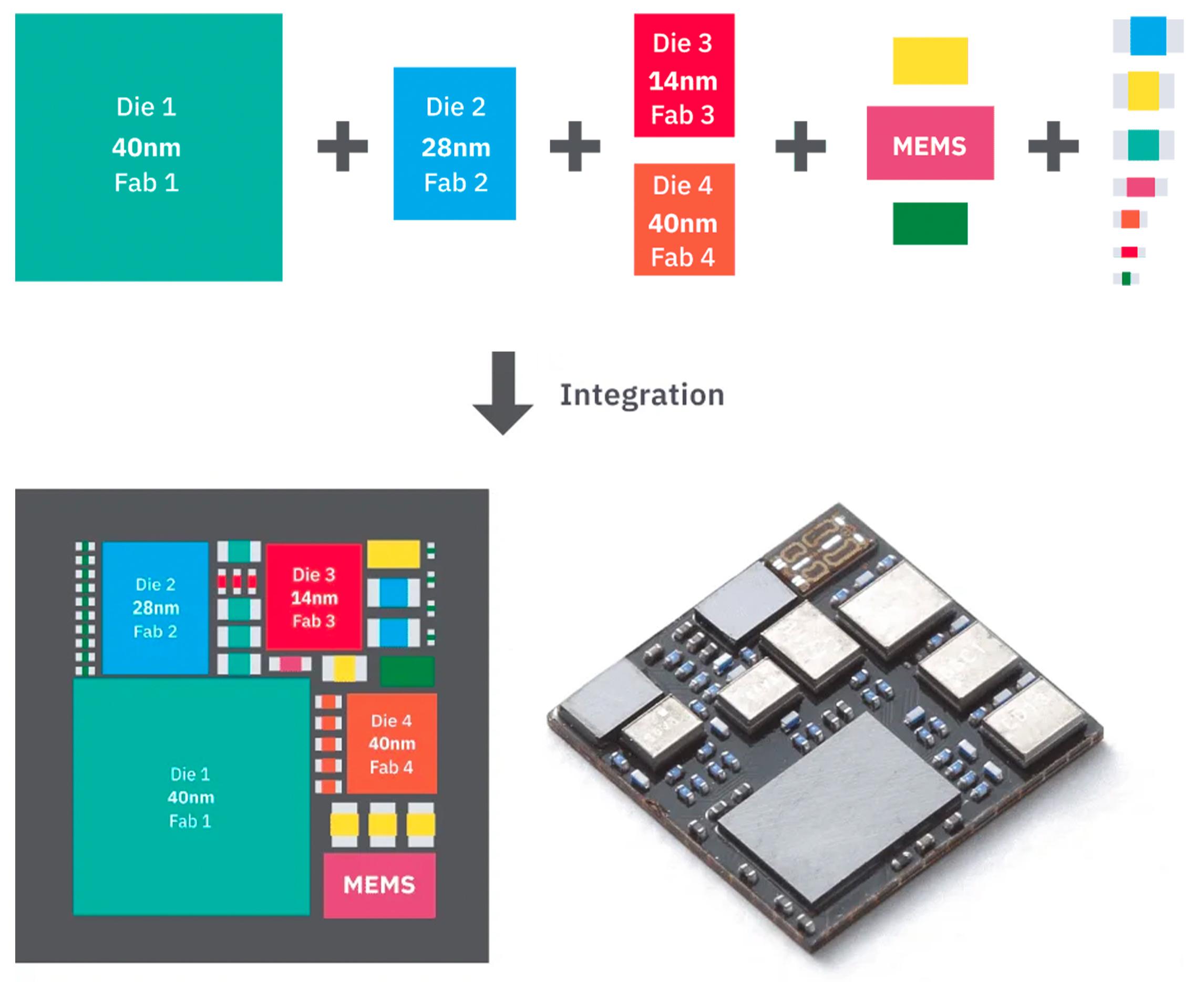
AMD的芯片封装技术:AMD采用了类似的异质集成技术,在其Ryzen和EPYC处理器中集成了多个计算核心芯片,以及用于高速缓存和I/O的单独芯片,通过Infinity Fabric互连技术实现高效通信。与此同时,或许就在今天,异质集成技术的发展也促进了芯片设计领域一个重要转变:即从传统的通用处理器设计向客户和终端应用定制化设计的转移。
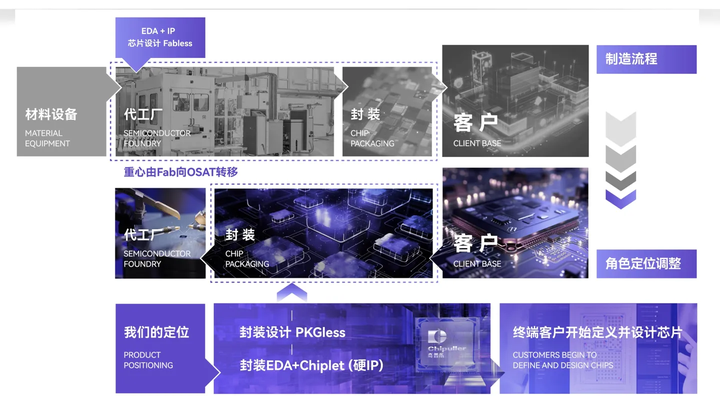

图片来自:Chipuller,Chiplet技术的探索者之一 这种转变体现在芯片设计不再仅仅追求通用性和广泛适用性,而是越来越多地考虑到特定应用需求、性能优化、能效比提升和成本效益。
众所周知,Chiplet技术作为异质集成技术的集大成者,它的应用使得芯片的开发周期大大缩短,进一步加速了产品的生产时间;在此之上,例如Chipuller(奇普乐)自研的Chipuller 1.0等芯片设计平台,已经可以支持终端用户在Web端体验一个简单而高效的定制流程。在面向多元化的应用设计方面:
异质集成技术通过将具有不同功能的组件(如CPU、GPU、DSP、AI加速器等)集成到同一芯片或封装中,使得设计师可以针对特定应用或任务优化芯片。
这种优化不仅涉及提高计算效率和处理速度,也包括能耗、热管理和成本。因此,芯片设计开始更多地从终端应用和客户需求出发,而非仅仅基于技术可行性。当然这种由异质集成技术所带来的新理念,或许也有着降本增效的作用:
在传统芯片设计中,技术迭代和升级往往需要重大的时间和成本投入;而异质集成技术使得在现有设计框架内部署新技术或更新组件变得更加容易和经济。
这种快速迭代能力不仅加速了技术发展,也使得终端产品能够更快地适应市场变化和技术进步,提供给客户更多的选择和更好的性能。综上所述,我们不难看出:异质集成技术不仅是一种技术进步,也代表了芯片设计哲学的转变。
它将客户和终端应用的需求置于设计的核心,通过提供高度定制化和灵活的解决方案,推动了个性化和功能特定化的产品开发。这种设计思想的转变有望进一步推动技术创新,为用户带来更多高效能、低功耗且功能强大的电子产品。
由于篇幅受限,本次异质集成技术就先介绍这么多......
想了解更多半导体行业动态,请您持续关注我们。
奇普乐将在每周,不定时更新~


最后的最后,借由歌德的一句名言:
大胆的见解就好比下棋时移动的一颗棋子,它可能被吃掉,但它却是胜局的起点。
愿每一位半导体从业者可以——
铎己以新,不以足己!
发布于 2024-04-11 14:44・IP 属地广东查看全文>>
奇普乐芯片 - 0 个点赞 👍被审核的答案
查看全文>>
知乎用户QQ - 156 个点赞 👍
我只能说,国内外(主要是指中美)的算力差距在禁售下越来越大了。


英伟达皮衣黄在GTC上发布的BlackWell芯片B200,和其它芯片比大概是这样的:
1、B200: 2080亿晶体管 ,8位精度算力9P FLOPS。(不卖给兔子)
2、H100: 800亿晶体管,8位精度算力1513T FLOPS。(不卖给兔子)
3、A100: 283亿晶体管,8位精度算力642T FLOPS。(不卖给兔子)
4、民用3090:8位精度算力35.6T FLOPS。(芯片不给你,只能买成品)
注:1PFLOPS=1024TFLOPS 1TFLOPS=1024GFLOPS
国内典型的算力如下(台积电是不是给代工不知道,反正壁仞在23年10月被制裁,华为不说了)
1、壁刃 104P ,8位精度算力 1024T FLOPS,BR—100OAM数据2048T。
2、著名的昇腾910A,8位精度算力 640T FLOPS
3、赛武纪思元370,8位精度算力 256T FLOPS
差距有多大呢?B200上市以后,我们的非超算单卡算力和老美的单卡算力差距4-9倍左右,壁刃大概1P—2P ,B200 9P 。
有人问,国内超算中心可以有算力吗?可以啊,但要经过复杂适配。国家超级计算天津中心的《面向生成式智能的国产算力创新环境》一文表示,我们超算也提供人工智能算力,但是多少没说。
对了,当年阿尔发狗算力大概3P,天河一号算力大概2.566P,现在人家一张卡搞定。
如果皮衣黄把B200成本降下来,老美的算力就超我们很多了。
如果差距继续拉开,最后老美在做实时大模型生成,我们这里大部分情况还只能异步后台生成。
强大的算力没有,再好的结果也出不来。。。
有评论说,我们可以设计更高级的GPU。可以啊,比如海思,但问题是高性能要高制程,我们7nm设备没有,台积电是不是可以代工还不好说,要看老美的脸色。
所以,中国集成电路的卡脖子问题还真的限制了AI产业的发展。
苦。
编辑于 2024-03-19 17:57・IP 属地上海查看全文>>
知乎用户 - 82 个点赞 👍
总结一下昨天大会的核心内容
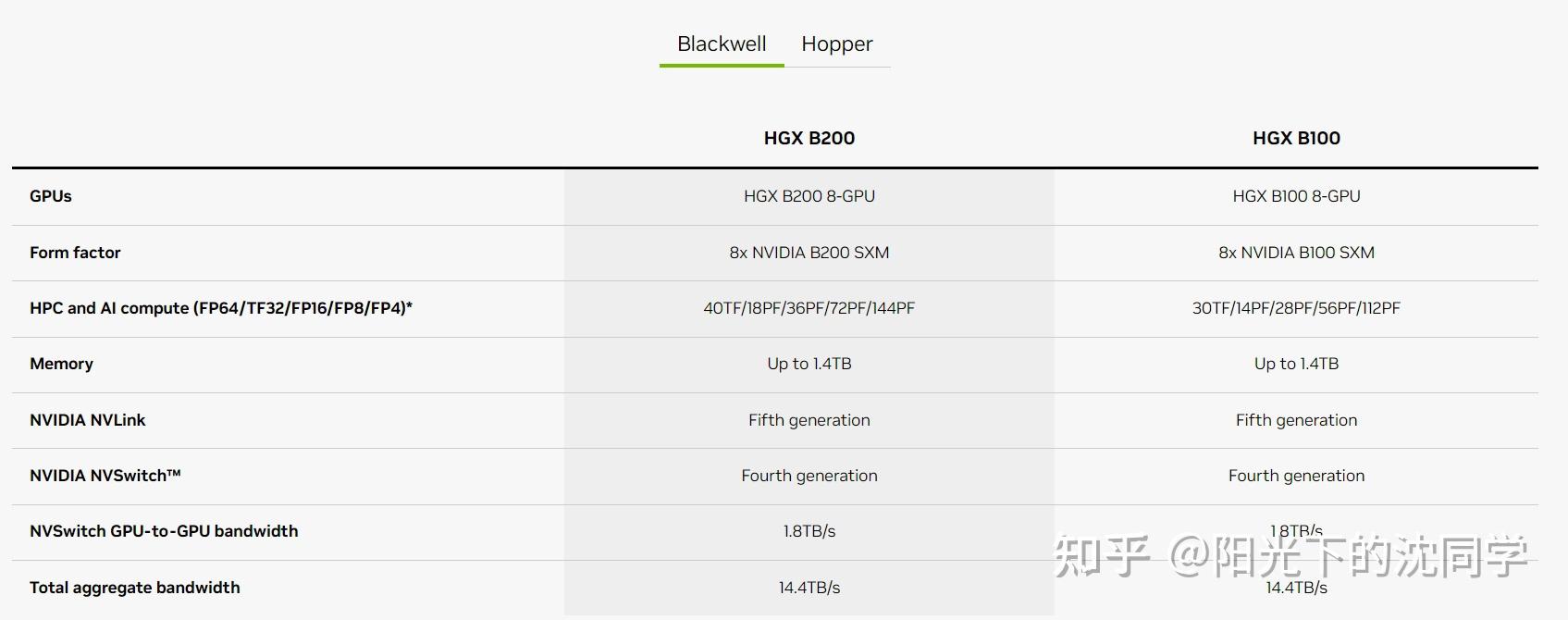
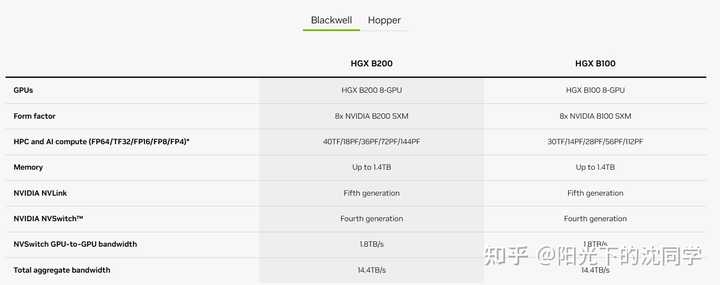
1,英伟达推出全球最强大芯片Blackwell
Blackwell的出现标志着在短短8年内,英伟达AI芯片的计算能力实现了提升1000倍的历史性成就
2016 年,“Pascal”芯片的计算能力仅为19 teraflops,而今天Blackwell的计算能力已经达到了 20000 teraflops
老黄在演讲中举例称,如果要训练一个1.8万亿参数量的GPT模型,需要8000张Hopper GPU,消耗15兆瓦的电力,连续跑上90天
但如果使用GB200 Blackwell GPU,只需要2000张,同样跑90天只消耗四分之一的电力
不只是训练,生成Token的成本也会随之显著降低
Blackwell由2080亿个晶体管组成,采用台积电4nm制程
支持多达10万亿参数的模型进行AI训练和实时大语言模型(LLM)推理
两个reticle极限GPU裸片将10TB/秒的芯片到芯片链路连接成单个统一的GPU
Blackwell 将通过新的4位浮点AI支持双倍的计算和模型大小推理能力
亚马逊、微软、谷歌和甲骨文在首批提供Blackwell支持的云服务商之列
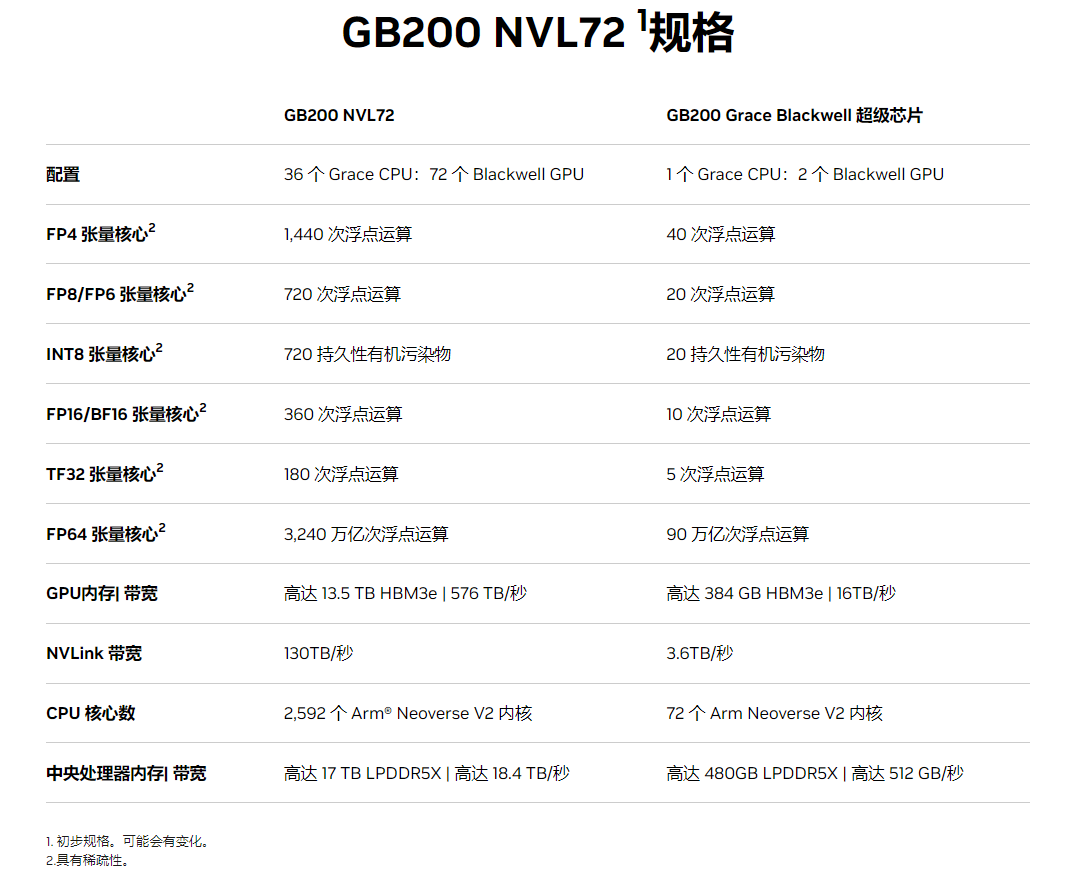
GB200 Grace Blackwell超级芯片,是由2个B200芯片(4个die)和Grace CPU组合而来
相较于H100,大语言模型性能提升30倍,同时能耗只有25分之一
2,英伟达推出AI项目Project GR00T助力人形机器人
3,台积电和Synopsys将采用英伟达计算光刻技术
4,英伟达推出新软件NIM,让用户更容易利用已有英伟达GPU进行AI推理


Blackwell就是英伟达最新推出的AI图形处理器【GPU】,今年可能下半年会发货
Blackwell平台能够在万亿参数级的大型语言模型(LLM)上构建和运行实时生成式 AI,而成本和能耗比前代改善25倍,这个是最大的看点
在拥有1750亿参数的GPT-3大模型基准测试中,GB200的性能是H100的7倍,训练速度是H100的4倍
B200GPU的重要进步之一,是采用了第二代Transformer引擎它通过对每个神经元使用4位(20 petaflops FP4)而不是8位,直接将计算能力、带宽和模型参数规模翻了一倍
DGX Grace-Blackwell GB200:单个机架的计算能力超过1 Exaflop
黄仁勋交付给OpenAI的第一台DGX是0.17 Petaflops
GPT-4的1.8T参数可在2000个Blackwell上完成90天的训练

大概率这款芯片使用是192GB的HBM3E内存


英伟达最近还在投资AI制药
英国公司Relation Therapeutics开发了一个通过读取DNA以更好理解基因的大型语言模型,而这是创造新药的关键步骤
这个公司宣布获得3500万美元的新种子轮融资,由DCVC和NVIDIA(英伟达)的风险投资部门 NVentures 联合领投
英伟达还表示未来会重点投资通用机器人,让人形机器人能够将文本、语音、视频甚至现场演示作为输入那日,并对其进行处理,采取特定的通用操作
英伟达在大会上说的Project GR00T由英伟达Isaac 机器人平台工具的帮助下开发的
黄仁勋称,由Project GR00T平台提供支持的机器人将被设计为,通过观察人类行为来理解自然语言并模仿动作,使它们能快速学习协调性、灵活性和其他技能,从而适应现实世界并在与之互动,绝对不会产生机器人起义
英伟达投资的AI衍生行业非常多,很多企业都有英伟达的投资
英伟达在全面发力+投资AI


而且大家要知道,大多数的AI新创都奠基于英伟达的CUDA平台
英伟达的策略就是让平台衍生出庞大的软件生态,让后者难以突破
英伟达在其软件领域面临着巨大的进入壁垒,CUDA 是其中的重要组成部分,但即使CUDA的替代品出现,Nvidia 提供软件和库的方式也有利于他们构建一个非常可靠的生态系统
英伟达企业的护城河比想象的深
现在1GPU已经从仅仅比CP 更快地运行游戏的设备发展成为通用加速器
为全球的工作站、服务器和超级计算机提供动力
在三十年前,CPU和其他专用处理器几乎处理所有计算任务
在那个时代的显卡有助于加快 Windows和应用程序中2D形状的绘制速度,但没有其他用途
但现在GPU已经成为业界最具主导地位的芯片之一
机器学习和高性能计算严重依赖于GPU的处理能力
GPU的发展非常超预期
英伟达之前认为AMD,英特尔,华为、博通,高通,亚马逊和微软等云计算公司都是竞争对手
AMD在2022年6月,就推出CPU+GPU架构的Instinct MI300,正式进军AI训练端
在去年6月,又公布了MI300X与MI300A两款AI加速器
英特尔在去年年底首次展示了用于深度学习和大规模生成人工智能模型的Gaudi3系列AI 加速器,预计将于2024年上市
华为在去年8月正式发布了“昇腾910”AI芯片及“MindSpore”全场景AI计算框架
微软在2023年推出了两款定制设计的芯片和集成系统:针对人工智能 (AI) 任务和生成式 AI 进行优化的 Microsoft Azure Maia AI 加速器
亚马逊从2013年推出首颗Nitro1芯片至今,AWS是最先涉足自研芯片的云端厂商,已拥有网路芯片、伺服器芯片、人工智慧机器学习自研芯片3条产品线
英伟达需要不断的努力才能不被众多竞争对手超越,才能一直保持领先优势
不过从目前来看,英伟达的AI芯片暂时没有对手
发布于 2024-03-19 14:15・IP 属地江西查看全文>>
阳光下的沈同学 - 35 个点赞 👍
为知友们提供更多信息:
重磅!“我们需要更大的GPU”,英伟达宣布推出最强AI芯片,成本和能耗较前代改善25倍
每经编辑 毕陆名
号称今年全球头号人工智能(AI)领域开发者大会的英伟达2024 GTC AI大会于美东时间3月18日周一拉开帷幕。今年是英伟达时隔五年首次让年度GTC重回线下,也是此前分析认为英伟达要“拿出点真家伙”的AI盛会。
当地时间周一下午,英伟达创始人兼CEO黄仁勋在美国加州圣何塞SAP中心进行主题为“面向开发者的1#AI峰会”(1#AI Conference for Developers)演讲。黄仁勋介绍了运行AI模型的新一代芯片和软件。英伟达正式推出名为Blackwell的新一代AI图形处理器(GPU),预计将在今年晚些时候发货。
Blackwell平台能够在万亿参数级的大型语言模型(LLM)上构建和运行实时生成式AI,而成本和能耗比前身低25倍。
另据媒体报道,英伟达CEO黄仁勋在GTC宣布,将在其企业软件订阅中增加一款名为NIM的新产品。NIM可以更容易地使用旧的英伟达GPU进行推理,并允许公司继续使用他们已经拥有的数亿个英伟达GPU。该产品将使新人工智能模型的初始训练推理所需的算力更少。该公司的策略是让购买英伟达服务器的客户注册英伟达企业版,每个GPU每年收取费用4500美元。黄仁勋表示,该软件还将帮助在配备GPU的笔记本电脑上运行人工智能,而不是在云服务器上运行。
此外,英伟达CEO黄仁勋宣布推出下一代人工智能超级计算机,英伟达还发布6G研究云平台,以便用AI技术推进无线通信。
英伟达推新AI芯片
据外媒报道,英伟达于周一宣布推出新一代人工智能芯片和用于运行人工智能模型的软件。该公司在美国圣何塞举行的开发者大会上宣布了这一消息,正值这家芯片制造商寻求巩固其作为人工智能公司首选供应商的地位。
自OpenAI的ChatGPT于2022年末掀起人工智能热潮以来,英伟达的股价上涨了五倍,总销售额增长了两倍多。英伟达的高端服务器GPU对于训练和部署大型AI模型至关重要。微软和Meta等公司已经花费了数十亿美元购买这些芯片。


图片来源:视频截图 新一代AI图形处理器命名为Blackwell。首款Blackwell芯片名为GB200,将于今年晚些时候发货。英伟达正在用更强大的芯片吸引客户,以刺激新订单。例如,各公司和软件制造商仍在争相抢购当前一代的“Hopper”H100芯片及类似产品。
“Hopper很棒,但我们需要更大的GPU,”英伟达首席执行官黄仁勋周一在该公司于加利福尼亚州举行的开发者大会上表示。不过,周一盘后交易中,英伟达股价下跌超过1%。该公司还推出了名为NIM的创收软件,该软件将简化AI的部署,为客户提供了在日益增多的竞争者中坚持使用英伟达芯片的另一个理由。
英伟达高管表示,该公司正从一个唯利是图的芯片提供商转变为更像微软或苹果的平台提供商,其他公司可以在此基础上构建软件。
“Blackwell不仅仅是一款芯片,而是一个平台的名称,”黄仁勋表示。
英伟达企业副总裁Manuvir Das在接受采访时表示:“可销售的商业产品是GPU,而软件则是为了帮助人们以不同的方式使用GPU。当然,我们现在仍然这样做。但真正改变的是,我们现在真的有了商业软件业务。”
Das表示,英伟达的新软件将更容易在任何英伟达GPU上运行程序,甚至是那些可能更适合部署而不是构建AI的老旧GPU。“如果你是开发者,你有一个有趣的模型,你希望人们采用它,如果你把它放入NIM中,我们会确保它可以在我们所有的GPU上运行,这样你就可以覆盖很多人,”Das说道。
Blackwell拥有六项革命性技术
英伟达每两年更新一次其GPU架构,实现性能的飞跃。过去一年发布的许多AI模型都是在该公司的Hopper架构上训练的,该架构被用于H100等芯片,于2022年宣布推出。


图片来源:视频截图 据悉,英伟达称,Blackwell拥有六项革命性的技术,可以支持多达10万亿参数的模型进行AI训练和实时LLM推理:
全球最强大的芯片:Blackwell架构GPU由2080亿个晶体管组成,采用量身定制的台积电4纳米工艺制造,两个reticle极限GPU裸片将10 TB/秒的芯片到芯片链路连接成单个统一的GPU。
第二代Transformer引擎:结合了Blackwell Tensor Core技术和TensorRT-LLM和NeMo Megatron框架中的英伟达先进动态范围管理算法,Blackwell将通过新的4位浮点AI支持双倍的计算和模型大小推理能力。
第五代NVLink:为提高数万亿参数和混合专家AI模型的性能,最新一代英伟达NVLink为每个GPU提供了突破性的1.8TB/s双向吞吐量,确保最复杂LLM之间多达576个GPU之间的无缝高速通信。
RAS引擎:Blackwell支持的GPU包含一个专用引擎,实现可靠性、可用性和服务性。此外,Blackwell架构还增加了芯片级功能,利用基于AI的预防性维护进行诊断和预测可靠性问题。这可以最大限度地延长系统正常运行时间,并提高大部署规模AI的弹性,使其能连续运行数周甚至数月,并降低运营成本。
安全人工智能:先进的机密计算功能可在不影响性能的情况下保护AI模型和客户数据,并支持新的本机接口加密协议,这对于医疗保健和金融服务等隐私敏感行业至关重要。
解压缩引擎:专用解压缩引擎支持最新格式,加快数据库查询,提供数据分析和数据科学的最高性能。未来几年,在企业每年花费数百亿美元的数据处理方面,将越来越多地由GPU加速。


图片来源:视频截图 Blackwell GPU体积庞大,将两个单独制造的晶粒组合成一个由台积电制造的芯片。它还将作为一款名为GB200 NVLink 2的整个服务器提供,该服务器结合了72个Blackwell GPU和其他旨在训练AI模型的英伟达部件。
亚马逊、谷歌、微软和甲骨文将通过云服务提供对GB200的访问。GB200将两个B200 Blackwell GPU与一个基于Arm的Grace CPU配对。英伟达表示,亚马逊网络服务将构建一个包含20000个GB200芯片的服务器集群。
英伟达没有提供新款GB200或其使用系统的成本。据分析师估计,英伟达基于Hopper的H100芯片成本在2.5万至4万美元之间,而整个系统的成本高达20万美元。
英伟达推理微服务
英伟达还宣布,将在其英伟达企业软件订阅中添加一款名为NIM(英伟达推理微服务)的新产品。NIM让使用较旧的英伟达GPU进行推理(或运行AI软件的过程)变得更加简单,并允许公司继续使用其已经拥有的数亿个英伟达GPU。与新AI模型的初始训练相比,推理所需的计算能力较少。对于那些希望运行自己的AI模型,而不是从OpenAI等公司购买AI结果作为服务的企业来说,NIM无疑是他们的得力助手。
英伟达的策略是吸引购买基于英伟达的服务器的客户注册英伟达企业版,每个GPU每年的许可费为4500美元。
英伟达将与微软或Hugging Face等AI公司合作,确保他们的AI模型能够在所有兼容的英伟达芯片上运行。随后,开发者可以使用NIM在自有服务器或基于云端的英伟达服务器上高效运行模型,无需繁琐的配置过程。
“在我原本调用OpenAI的代码中,我只需替换一行代码,将其指向从英伟达获取的NIM即可。”Das说道。
英伟达表示,该软件还将助力AI在配备GPU的笔记本电脑上运行,而非仅限于云端服务器。
每日经济新闻综合第一财经、公开消息
免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。
发布于 2024-03-19 10:12・IP 属地四川查看全文>>
每日经济新闻 - 12 个点赞 👍
查看全文>>
出云 - 10 个点赞 👍
B100系列的强大是大家有预期的,不过不用慌。


就看升腾920能多大程度上不被落下了,少输当赢了这下。
弄出来tsmc n3级别的工艺,确实还得几年。把升腾的那堆生态搞好,也得一段时间。
好在目前来看AI的差距还造不成太大的战略上的被动,那就先用空间换时间好了。
发布于 2024-03-19 19:44・IP 属地四川查看全文>>
Eidosper - 2 个点赞 👍
成本改善25倍,应该就是我理解的性能x功耗是前代的25倍。不过一般芯片都有能效曲线,看来看题目没啥用,我翻出去看原发布会。
一会更。
果然,这题目写得真牛啊。
我先列下原发会介绍的。
B200 拥有2080亿个晶体管,前一代H100、H200系列芯片只有800亿个。B200采用台积电4NP工艺制程,可以支持10万亿参数级的AI模型。相比之下,OpenAI的GPT-3仅为1750亿个参数组成,可以说英伟达的新款芯片,继续零跑行业数个身位。B200单个芯片能提供20 petaflops的AI性能,是前代H100的5倍。
英伟达每两年换架构,这次架构是以一位数学家姓名来命名。叫BIackwell架构。产品有B200与GB200。
英伟达还表示 GB200 包含了两个 B200 Blackwell GPU 和一个基于 Arm 的 Grace CPU 组成,推理大语言模型性能比 H100 提升 30 倍,成本和能耗降至 25 分之一
老黄还举个例子
如果要训练一个1.8万亿参数量的GPT模型,需要8000张Hopper GPU,消耗15兆瓦的电力,连续跑上90天。但如果使用Blackwell GPU,只需要2000张,跑90天只要4兆瓦
实话说,我没看懂,这玩意儿怎么降低25倍的?
按老黄的例子,能耗提升不是15/4=3.75倍吗?
除非价格降了。
而h100是台n4,800亿晶体管。Gb200是两个B200+一个ARM GPU由台积电N4工艺,共2080亿晶体管。
2080/800=2.6。晶体管翻了2.6倍。性能翻了2.5倍。
价格呢?就算台积电工艺成熟了,代工价格下降,估计上天也就20-30%,按30%算。买等价性能时打7折。
3.75再除于0.7也就是5.35。那成本下降只有25的零头。
当然,我也翻到了。写25倍的
除了核心的芯片发布环节外,英伟达还发布了GB200 NVL72 液冷机架系统。其中包含 36 颗 GB200 Grace Blackwell 超级芯片。英伟达表示,与用于推理用途的相同数量的 H100 Tensor Core 图形处理单元相比,GB200 NVL72 性能提升高达 30 倍,成本和能耗降低多达 25 倍。
我翻译一下。36颗GB200,包含了72颗B200。与相同数量的H100(36张),成本与能耗降低最高25倍。
真是好家伙。这个不等式怎么比?
既然如此。我宣布
GB200比H100成本与能耗改善多达25倍。
后面的人请按B200比H100能耗降低25倍来宣传
编辑于 2024-03-19 23:57・IP 属地广东真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
火山冲塔 - 1 个点赞 👍
英伟达官方报告:训练一个 1.8 万亿个参数的模型以前需要8000 个 Hopper GPU 和 15 兆瓦的电力。如今,Nvidia 首席执行官表示,2000 个 Blackwell GPU 就能完成这项工作,耗电量仅为4 兆瓦
新GPU包含了3个芯片,从8000降到2000大概提升4倍
耗电从15MW降到4MW,提升不到4倍
发布于 2024-03-19 19:28・IP 属地广东查看全文>>
谢凌成 - 1 个点赞 👍
查看全文>>
Xiaoxiao Liu律师 - 1 个点赞 👍
对万亿参数模型的兴趣是什么?我们知道当今的许多用例,由于承诺增加以下能力,人们的兴趣正在增长:
- 自然语言处理任务,如翻译、问答、抽象和流利。
- 保持长期背景和对话能力。
- 结合语言、视觉和语音的多模式应用程序。
- 讲故事、诗歌生成和代码生成等创意应用程序。
- 科学应用,如蛋白质折叠预测和药物发现。
- 个性化,能够培养一致的个性并记住用户上下文。
好处很大,但训练和部署大型模型可能计算成本高昂且资源密集型。计算高效、具有成本效益和节能的系统,旨在提供实时推理,对于广泛部署至关重要。新的NVIDIA GB200 NVL72就是这样一个可以完成任务的系统。
为了说明,让我们考虑专家混合(MoE)模型。这些模型有助于在多个专家之间分配计算负载,并使用模型并行性和管道并行性在数千个GPU上进行训练。使系统更高效。
然而,新水平的并行计算、高速内存和高性能通信可以使GPU集群使技术挑战易于处理。NVIDIA GB200 NVL72机架规模架构实现了这一目标,我们将在以下帖子中详细介绍。
超大规模AI超级计算机的机架式设计
GB200 NVL72的核心是NVIDIA GB200 Grace Blackwell超级芯片。它将两个高性能的NVIDIA Blackwell Tensor Core GPU和NVIDIA Grace CPU与NVLink芯片到芯片(C2C)接口连接起来,该接口提供900 GB/s的双向带宽。使用NVLink-C2C,应用程序可以连贯地访问统一的内存空间。这简化了编程,并支持万亿参数LLM、多模态任务的变压器模型、大规模模拟模型和3D数据的生成模型的更大内存需求。
GB200计算托盘基于新的NVIDIA MGX设计。它包含两个Grace CPU和四个Blackwell GPU。GB200具有用于液体冷却的冷板和连接,PCIe gen 6支持高速联网,以及用于NVLink电缆盒的NVLink连接器。GB200计算托盘提供80 petaflops的AI性能和1.7 TB的快速内存。


最大的问题需要足够数量的突破性的Blackwell GPU才能高效并行工作,因此它们必须以高带宽和低延迟进行通信,并保持忙碌。
GB200 NVL72机架式系统使用带有9个NVLink交换机托盘的NVIDIA NVLink交换机系统以及连接GPU和交换机的电缆盒,促进了18个计算节点的并行模型效率。
NVIDIA GB200 NVL36和NVL72
GB200在NVLink域中支持36和72个GPU。每个机架根据MGX参考设计和NVLink交换机系统托管18个计算节点。它具有GB200 NVL36配置,一个机架中有36个GPU和18个单个GB200计算节点。GB200 NVL72在一个机架中配置了72个GPU和18个双GB200计算节点,或者在两个机架中配置了72个GPU,有18个单个GB200计算节点。
GB200 NVL72使用铜缆墨盒密集包装和互连GPU,以简化操作。它还使用液体冷却系统设计,降低成本和能耗降低25倍。


第五代NVLink和NVLink交换机系统
NVIDIA GB200 NVL72引入了第五代NVLink,它在一个NVLink域中连接了多达576个GPU,总带宽超过1 PB/s,内存超过240 TB。每个NVLink交换机托盘提供100 GB的144个NVLink端口,因此9个交换机在72个Blackwell GPU上完全连接18个NVLink端口中的每个端口。
革命性的每个GPU1.8 TB/s的双向吞吐量是PCIe Gen5的14倍,为当今最复杂的大型机型提供了无缝的高速通信。


图3。高速NVLink交换机互连为GPU提供1 PB/s的总带宽 几代人的NVLink
NVIDIA行业领先的高速低功耗SerDes创新推动了GPU到GPU通信的进步,从引入NVLink开始,以高速加速多GPU通信。NVLink GPU到GPU的带宽为1.8 TB/s,是PCIe带宽的14倍。第五代NVLink比2014年推出的第一代速度为160 GB/s快12倍。NVLink GPU到GPU通信有助于在AI和HPC中扩展多GPU性能。
GPU带宽的进步加上NVLink域大小的指数扩张,自2014年以来,将576 Blackwell GPU NVLink域的总带宽增加了900倍,达到1 PB/s。
用例和性能结果
GB200 NVL72的计算和通信能力是前所未有的,给AI和HPC带来了巨大的挑战。
人工智能培训
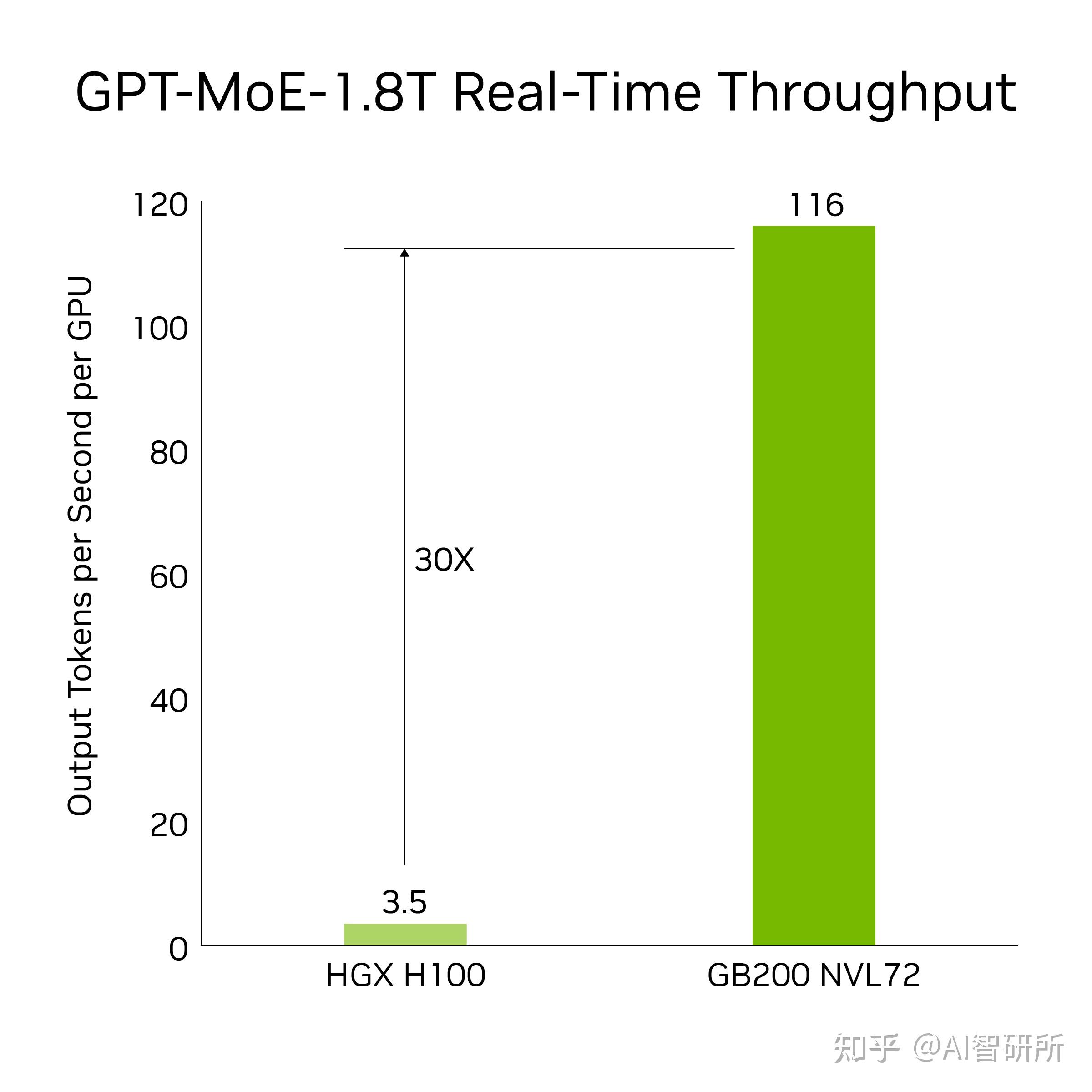
GB200包括一个更快的第二代变压器发动机,具有FP8精度。与相同数量的NVIDIA H100 GPU相比,它为GPT-MoE-1.8T等大型语言型号提供32k GB200 NVL72的训练性能快4倍。
人工智能推断
GB200引入了尖端功能和第二代变压器发动机,可加速LLM推理工作负载。与上一代H100相比,它为1.8T参数GPT-MoE等资源密集型应用程序提供了30倍的加速。新一代张量核心使这一进步成为可能,该核心引入了FP4精度和第五代NVLink的许多优势
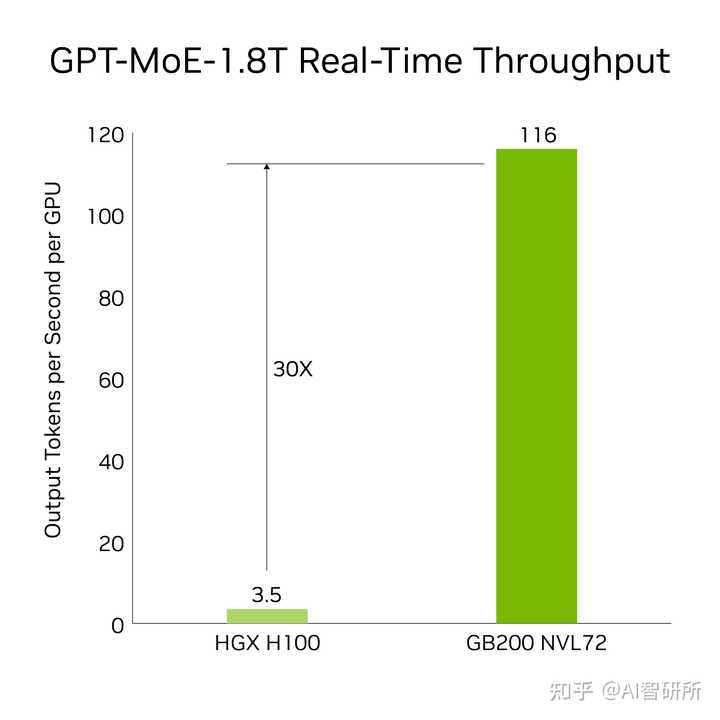

图4。与H100相比,GB200提供30倍的实时吞吐量 结果基于令牌到令牌延迟= 50毫秒;实时,第一个令牌延迟= 5,000毫秒;输入序列长度= 32,768;输出序列长度= 1,024输出,8x八向HGX H100风冷:400 GB IB网络与18 GB200超级芯片液冷:NVL36,每个GPU性能比较。预计性能可能会发生变化。
30倍的加速将64个NVIDIA Hopper GPU与使用GPT-MoE-1.8T的GB200 NVL72的32个Blackwell GPU相比,在8路NVLink和InfiniBand上进行了扩展。
数据处理
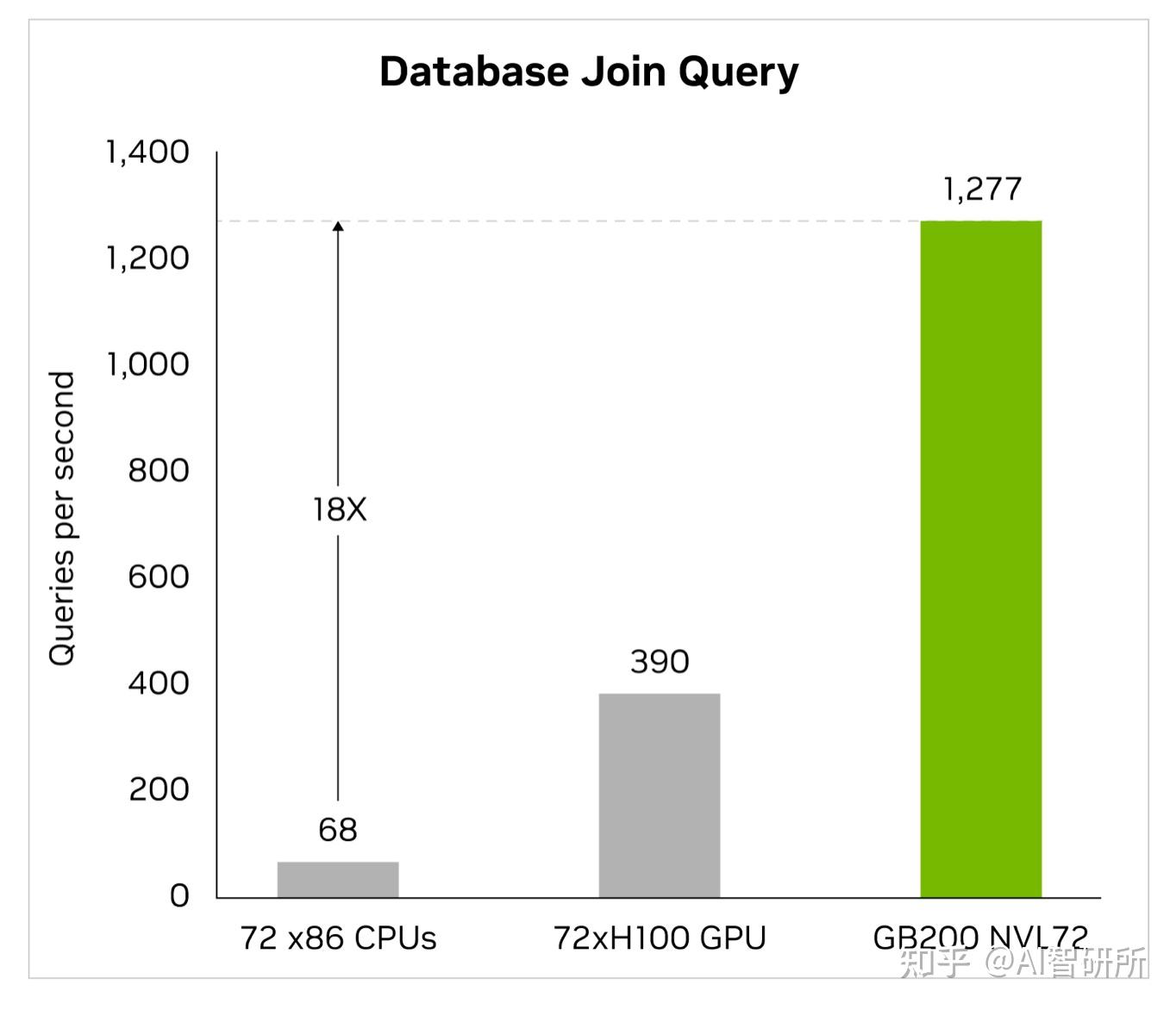
大数据分析帮助组织解锁洞察力并做出更明智的决策。组织持续大规模生成数据,并依靠各种压缩技术来缓解瓶颈并节省存储成本。为了在GPU上高效处理这些数据集,Blackwell架构引入了硬件解压缩引擎,可以原生大规模解压缩压缩数据,并加快端到端分析管道的速度。解压缩引擎原生支持使用LZ4、Deflate和Snappy压缩格式解压缩数据。
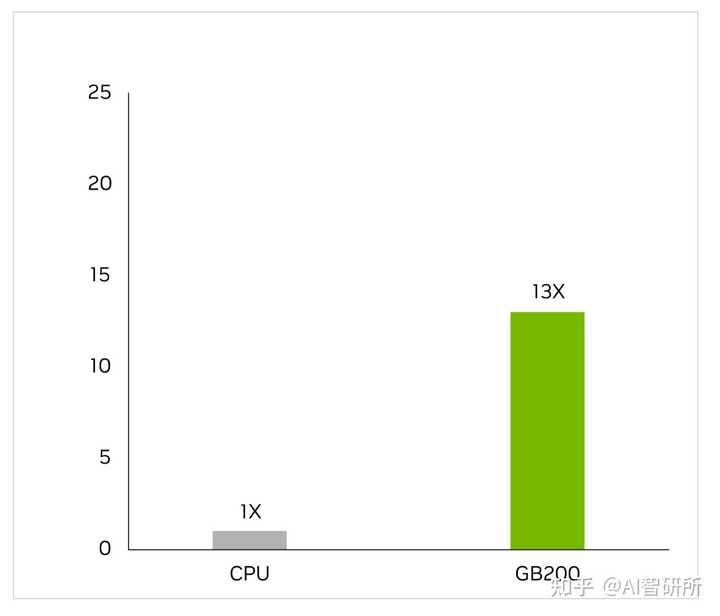
解压引擎加快了内存绑定内核操作。它提供高达800 GB/s的性能,并使Grace Blackwell的性能比CPU(Sapphire Rapids)快18倍,比NVIDIA H100 Tensor Core GPU快6倍,用于查询基准测试。
凭借惊人的8 TB/s高内存带宽和Grace CPU高速NVlink-Chip-to-Chip(C2C),该引擎加快了数据库查询的整个过程。这导致数据分析和数据科学用例的一流性能。这使组织能够快速获得见解,同时降低成本。

基于物理的模拟
基于物理的模拟仍然是产品设计和开发的支柱。从飞机和火车到桥梁、硅芯片,甚至药品,通过模拟测试和改进产品可以节省数十亿美元。
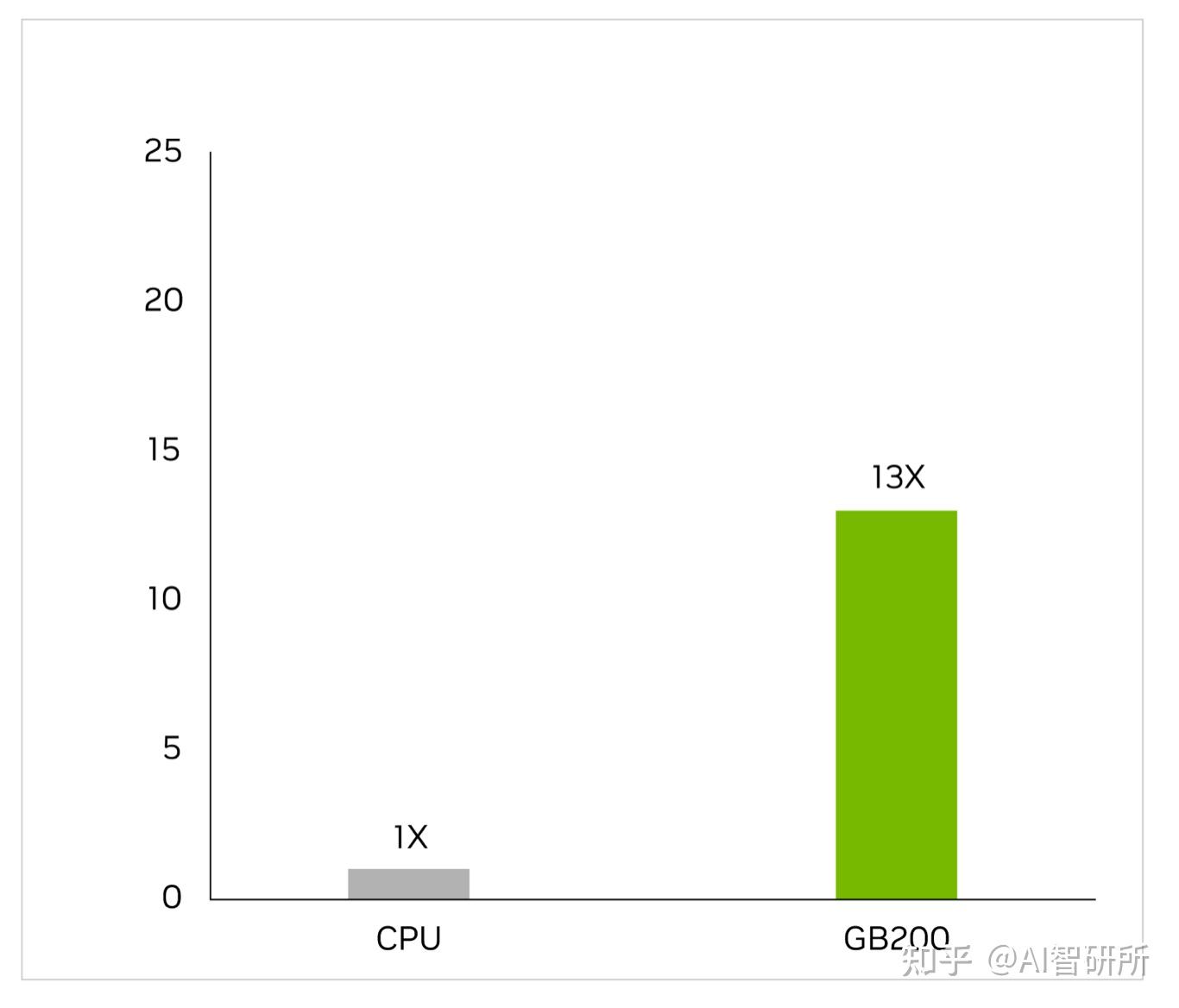
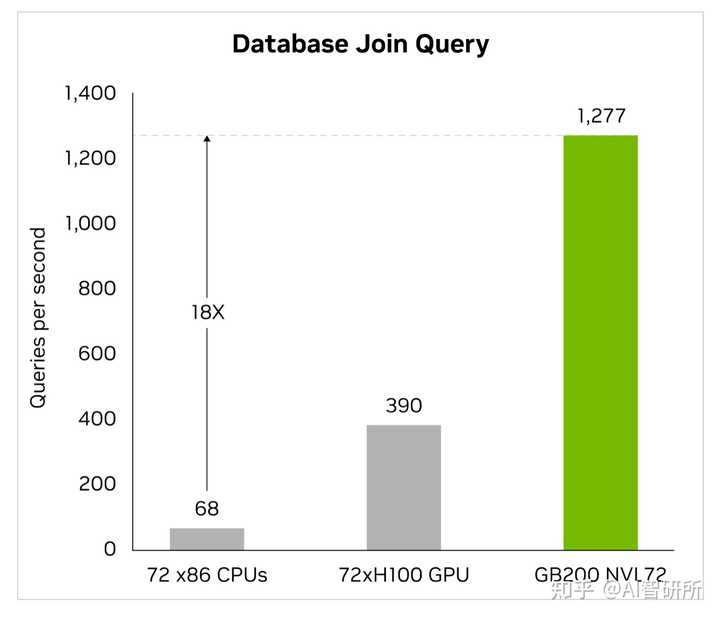
特定于应用程序的集成电路几乎完全在CPU上设计,在漫长而复杂的工作流程中,包括用于识别电压和电流的模拟分析。Cadence SpectreX模拟器是求解器的一个例子。下图显示,SpectreX在GB200上运行速度比x86 CPU快13倍。

Cadence SpectreX(香料模拟器)| CPU:16核AMD Milan 75F3数据集:KeithC Design TSMC N5 | GB200的性能预测可能会发生变化
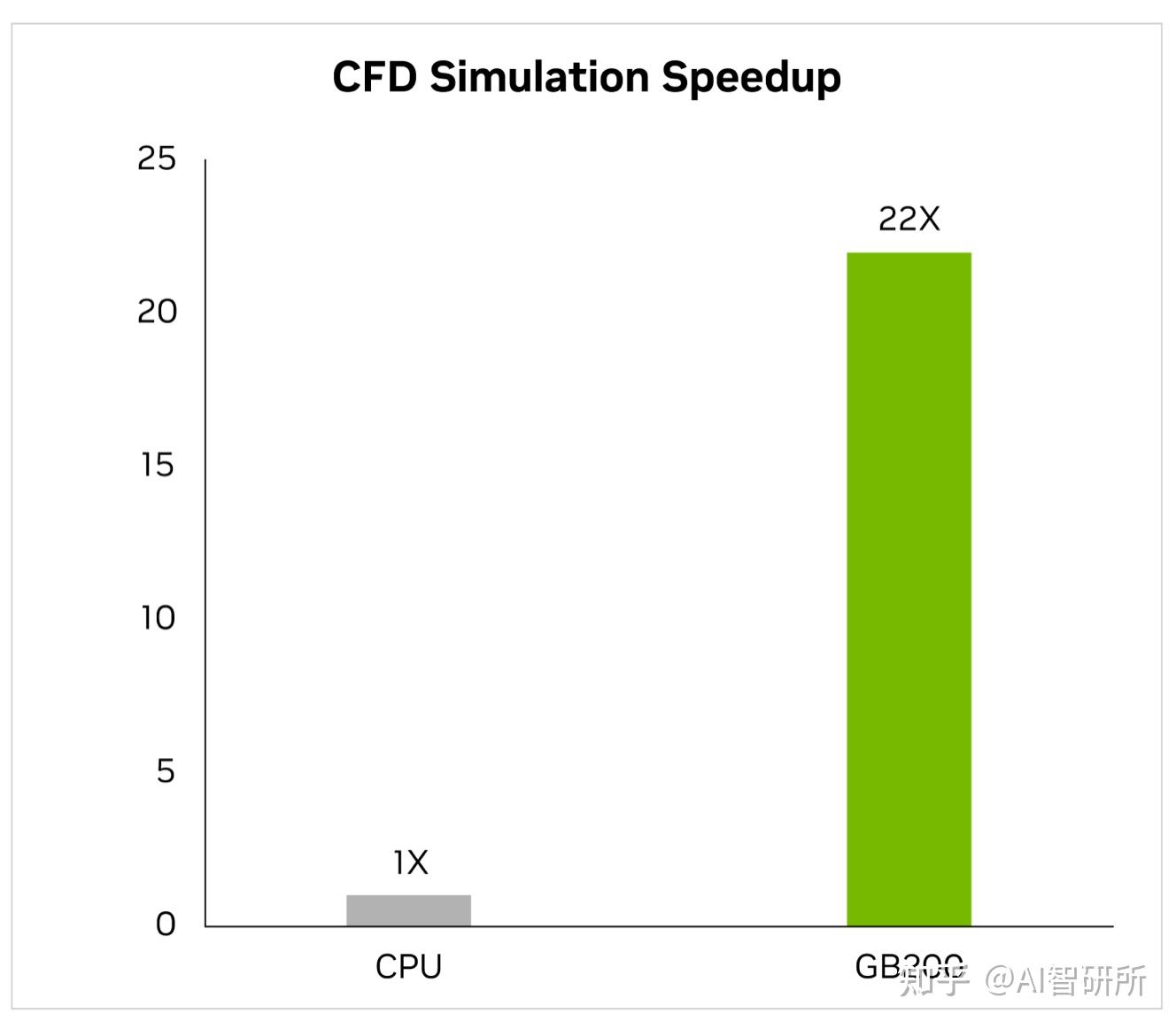
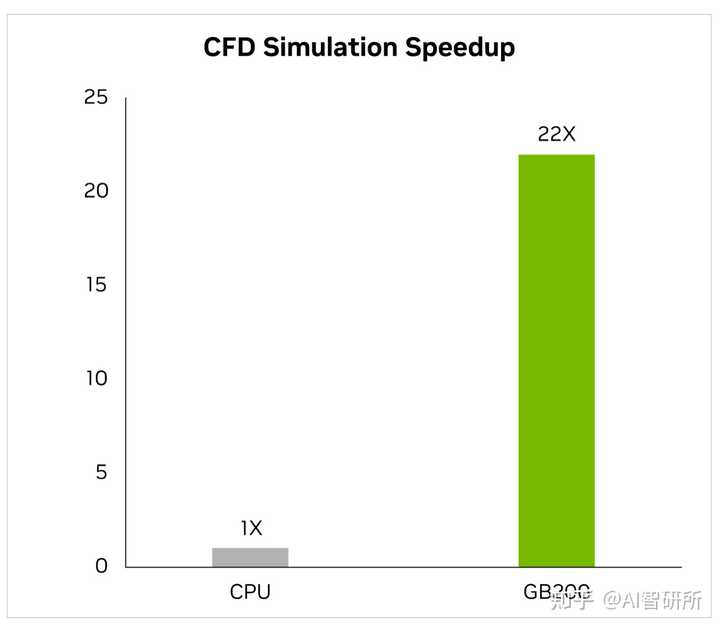
在过去的两年里,该行业越来越多地转向GPU加速计算流体动力学(CFD)作为关键工具。工程师和设备设计师使用它来研究和预测他们设计的行为。Cadence Fidelity,一个大型涡流模拟器(LES)在GB200上运行模拟的速度比x86 CPU快22倍。

Cadence Fidelity(LES CFD Solver)| CPU:16核AMD Milan 75F3数据集:GearPump 2M电池|GB200的性能预测可能会发生变化
我们期待在GB200 NVL72上探索Cadence Fidelity的可能性。凭借并行可扩展性和每个机架30 TB的内存,我们的目标是捕获以前从未捕获过的流细节。
发布于 2024-03-19 23:00・IP 属地上海查看全文>>
AI智研所 - 0 个点赞 👍
英伟达宣布推出最强 AI 芯片:关注要点解析
英伟达近日在其2024 GTC AI大会上宣布了一项重大突破,推出了名为Blackwell的新一代AI图形处理器(GPU)。这不仅是技术的一次飞跃,也预示着AI行业即将迈入一个新的里程碑。下面,我们就来深入探讨这次发布的几个关键要点。
Blackwell GPU:性能与效率的革新
首先,Blackwell GPU的推出无疑是本次大会的重头戏。它标志着英伟达在AI硬件领域的最新进展,将AI计算的性能和效率提升到一个全新的水平。最令人瞩目的是,相比前代产品,Blackwell在成本和能耗上实现了25倍的改善。这意味着,在处理万亿参数级的大型语言模型时,Blackwell不仅更快,而且更节能,更经济。


NIM软件:拓展旧GPU的生命周期
黄仁勋CEO的另一项重要宣布是NIM软件的推出。这款新产品将使企业能够更有效地利用现有的英伟达GPU资源,特别是在AI模型的推理阶段。通过订阅NIM,企业可以延长他们手头GPU的使用寿命,同时降低部署最新AI模型所需的总成本。这一策略不仅环保,还经济实惠,有助于企业更快地适应AI技术的迅速发展。


AI超级计算机与6G研究云平台
除了Blackwell GPU和NIM软件,英伟达还宣布了下一代AI超级计算机的推出,以及面向未来无线通信技术的6G研究云平台。这两项技术的推进显示了英伟达在构建整个AI生态系统方面的雄心,从硬件到软件,再到未来的通信网络,英伟达都在积极布局。

技术革新的新纪元
英伟达这一系列的宣布,不仅展示了其在AI领域的技术实力和创新能力,也为行业用户和开发者描绘了一个前所未有的AI应用前景。Blackwell GPU的革命性进步、NIM软件的实用策略,以及对未来技术的深远布局,共同预示着一个由AI驱动的全新时代即将到来。
发布于 2024-03-19 19:38・IP 属地美国真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
木心-AIGC - 0 个点赞 👍
英伟达这次推出的AI芯片,是他们家最新、最厉害的一款“大脑”芯片,专门用来处理人工智能的任务。这款芯片据说在成本和能耗上比之前的版本好了整整25倍,这听起来就让人觉得不可思议!
其实,这“成本”和“能耗”的改善可不是小事儿。成本低了,意味着买这款芯片不用花那么多钱,这对于需要用到大量AI芯片的公司和研究机构来说,可是个大大的好消息。而能耗少了,就是这款芯片工作时用的电少了,这样运行起来就更环保,也更省钱。
再来说说这芯片的性能。既然英伟达敢称它是最强的,那它肯定在某些方面有过人之处。比如,它可能处理数据更快,能同时处理更多的任务,或者能更准确地识别图像和语音等等。这些都能让AI变得更聪明、更能干。
这款芯片的应用范围也很广。无论是自动驾驶汽车、智能机器人,还是医疗诊断、游戏娱乐,都可能用到它。想象一下,如果未来的自动驾驶汽车都用上了这款芯片,那它们处理路况、做出反应的速度可能就会更快、更准确。
所以,英伟达这次推出的AI芯片在成本、能耗和性能上都有很大的提升,这对于推动人工智能的发展来说是个好消息。当然具体表现如何还得看实际应用中的效果。不过,可以肯定的是,这款芯片肯定会让AI变得更加强大和普及!未来得AI者得天下!
发布于 2024-03-19 19:24・IP 属地上海查看全文>>
飞猪猪 - 0 个点赞 👍
当地时间周一(3月18日),备受瞩目的英伟达年度GTC会议在加州圣何塞拉开帷幕。
时隔五年,英伟达再次线下举办起了年度GTC会议,故外界对此次大会期待值很高。英伟达方面也没有让大家失望,一次性介绍了多个公司的最新成果。
新一代Blackwell GPU架构
在此次大会上,最引人瞩目的就是英伟达推出的新一代Blackwell GPU架构。
官方介绍称,Blackwell可使全球机构都能够在万亿参数的大语言模型(LLM)上构建和运行实时生成式AI,其成本和能耗较上一代产品降低多达25倍。


官方表示,Blackwell GPU架构搭载六项变革性的加速计算技术:
●全球最强大的芯片:Blackwell架构GPU具有2,080亿个晶体管,采用台积电4纳米(nm)工艺制造,通过10TB/s的片间互联,将GPU裸片连接成一块统一的GPU。
●第二代Transformer引擎:得益于全新微张量缩放支持,以及集成于英伟达TensorRT™-LLM和NeMo Megatron框架中的英伟达先进动态范围管理算法,Blackwell将在新型4位浮点AI推理能力下实现算力和模型大小翻倍。
●第五代NVLink:为了提升万亿级参数模型和混合专家AI模型的性能,第五代NVLink为每块GPU提供突破性的1.8TB/s双向吞吐量,确保多达576块GPU之间的无缝高速通信,可以满足当今最复杂LLM的需求。
●RAS引擎:采用Blackwell架构的GPU包含一个用于保障可靠性、可用性和可维护性的专用引擎。此外,Blackwell架构还增加了多项芯片级功能,能够利用AI预防性维护来运行诊断并预测可靠性相关的问题。这将最大程度地延长系统正常运行时间,提高大规模AI部署的弹性,使其能够连续不间断运行数周乃至数月,同时降低运营成本。
●安全AI:先进的机密计算功能可以在不影响性能的情况下保护AI模型和客户数据,并且支持全新本地接口加密协议,这对于医疗、金融服务等高度重视隐私问题的行业至关重要。
●解压缩引擎:专用的解压缩引擎支持最新格式,通过加速数据库查询提供极其强大的数据分析和数据科学性能。未来几年,每年需要企业花费数百亿美元的数据处理将越来越多地由GPU加速。
凭借上述技术,Blackwell能够在拥有高达10万亿参数的模型上实现AI训练和实时LLM推理。英伟达表示,这些技术将助推数据处理、工程模拟、电子设计自动化、计算机辅助药物设计、量子计算和生成式AI等领域实现突破。
超大规模的超级芯片
英伟达还介绍了GB200 Grace Blackwell超级芯片。
官方称,该超级芯片是通过900GB/s超低功耗的片间互联,将两个英伟达B200 Tensor Core GPU与Grace CPU相连。
GB200是英伟达GB200 NVL72的关键组件。GB200 NVL72是一套多节点液冷机架级扩展系统,适用于高度计算密集型的工作负载。它将36个GraceBlackwell超级芯片组合在一起,其中包含通过第五代NVLink相互连接的72个Blackwell GPU和36个Grace CPU。
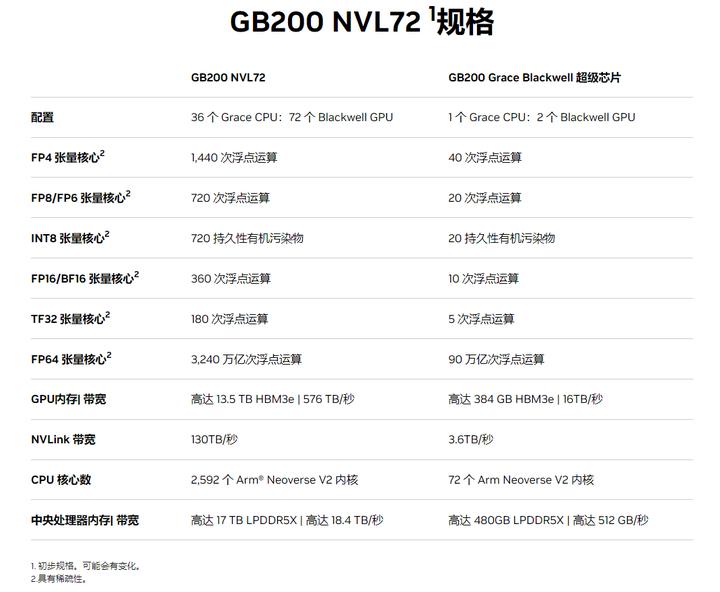

此外,GB200 NVL72还内置BlueField®-3数据处理器,可在超大规模AI云中实现云网络加速、组合式存储、零信任安全和GPU计算弹性。对于LLM推理工作负载,相较于同样数量的H100,GB200 NVL72最高可提供30倍的性能提升以及多达25倍的成本和能耗降低。
值得一提的是,该平台可作为一个单GPU,具有1.4 exaflops的AI性能和30TB的快速内存,是组成最新一代DGX SuperPOD的基础模块。
已有多家企业“属意”Blackwell架构
英伟达方面透露,其合作伙伴将从今年晚些时候开始供应采用Blackwell架构的产品。
其中,亚马逊的AWS、谷歌云、微软的Azure、甲骨文云基础设施将成为首批提供 Blackwell 驱动实例的云服务提供商。
Indosat Ooredoo Hutchinson、Nebius、Nexgen Cloud、Oracle EU Sovereign Cloud、Oracle美国/英国/澳大利亚政府云、新加坡电信等主权AI云也将提供基于Blackwell架构的云服务和基础设施。
GB200 还将通过 NVIDIA DGX™ Cloud 提供,NVIDIA DGX™ Cloud 是一个与领先的云服务提供商共同设计的 AI 平台,可为企业开发人员提供专门的基础设施和软件访问权限,使他们能够构建并部署先进的生成式 AI 模型。AWS、谷歌云和甲骨文云基础设施计划在今年晚些时候托管采用Grace Blackwell的新实例。
此外,思科、戴尔、联想和超微预计将提供基于Blackwell产品打造的各种服务器。永擎电子、华硕、Foxconn、技嘉、和硕等多家企业也将提供基于Blackwell的服务器。
此外,越来越多的软件制造商网络,包括工程仿真领域的全球领导者 Ansys、Cadence 和 Synopsys,将使用基于Blackwell的处理器来加速其用于设计和仿真电气、机械和制造系统及零件的软件。他们的客户可以更低成本、更高能效地使用生成式 AI 和加速计算,来加速产品上市。
生成式AI微服务
在GTC大会期间,英伟达推出数十项企业级生成式AI微服务,企业可以利用这些微服务在自己的平台上创建和部署定制应用,同时保留对知识产权的完整所有权和控制权。
包括Adobe、Cadence、CrowdStrike、Getty Images和SAP在内的诸多领先应用、数据和网络安全平台提供商已经率先使用了英伟达AI Enterprise 5.0中提供的这些全新生成式AI微服务。
英伟达创始人兼首席执行官黄仁勋表示:“成熟的企业平台坐拥数据金矿,这些数据可以转化为生成式AI助手。我们与合作伙伴生态系统一起创建的这些容器化AI微服务,是各行业企业成为AI公司的基石。”


NIM微服务提供基于英伟达推理软件的预构建容器,可以使开发者能够将部署时间从几周缩短至几分钟。它们为语言、语音和药物发现等领域提供行业标准API,使开发者能够使用安全托管在自己的基础设施中的专有数据,来快速构建AI应用。
NIM微服务将为谷歌、Meta、微软等多家企业的开放模型提供了快速且性能出色的生产级AI容器。
此外,为了加快AI采用,企业还可以使用CUDA-X微服务,包括用于定制语音和翻译AI的Riva、用于路由优化的cuOpt™,以及用于高分辨率气候和天气模拟的Earth-2。
英伟达表示,更多用于定制模型开发的NVIDIA NeMo™ 微服务即将陆续发布,其中包括构建用于训练和检索的简洁数据集的NeMo Curator、用于利用特定领域数据微调LLM的NeMo Customizer、用于分析 AI 模型性能的NeMo Evaluator 以及用于LLM的NeMo Guardrails。
人形机器人通用基础模型——Project GR00T
在GTC上,英伟达发布了人形机器人通用基础模型Project GR00T,为大家展示了其在机器人和具身智能方面的突破。
据官方介绍,GR00T驱动的机器人将能够理解自然语言,并通过观察人类行为来模仿动作——快速学习协调、灵活性和其它技能,以便导航、适应现实世界并与之互动。


英伟达还发布了一款基于Thor系统级芯片(SoC)的新型人形机器人计算机Jetson Thor。
该SoC包括一个带有transformer engine的下一代GPU,其采用Blackwell架构,可提供每秒800万亿次8位浮点运算AI性能,以运行GR00T等多模态生成 AI模型。凭借集成的功能安全处理器、高性能CPU集群和100GB以太网带宽,大大简化了设计和集成工作。
英伟达透露,其正在为领先的人形机器人公司开发一个综合的AI平台,如1X Technologies、Agility Robotics、波士顿动力公司、Figure AI、宇树科技等。
此外,英伟达对Isaac机器人平台也进行了重大升级。GR00T使用的Isaac工具还能够为在任何环境中的任何机器人创建新的基础模型。这些工具包括用于强化学习的Isaac Lab和用于计算编排服务的 OSMO。不过,新的Isaac平台功能要到下个季度才会推出。
关注我,每日为您带来最新的全球财经资讯!
发布于 2024-03-19 19:13・IP 属地广东查看全文>>
Hawk Insight - 0 个点赞 👍
查看全文>>
龙哥财经 - 0 个点赞 👍
英伟达宣布推出的这款最强AI芯片确实令人瞩目,其中有几个关键信息值得我们特别关注:
首先,这款AI芯片与前代相比,在成本和能耗上有了显著的改善,达到了25倍。这意味着在相同的性能下,新款芯片的运行成本更低,能源消耗更少,对于追求高效、节能的企业和个人用户来说,这无疑是一个巨大的吸引力。
其次,这款芯片被外界誉为“全球最强”的AI芯片,这足以说明其在性能上的卓越表现。从公布的数据来看,配备了Blackwell芯片的系统,其推理性能相比前代产品有了大幅提升,而功耗和成本却大幅降低。这样的性能提升和成本降低,无疑将大大推动AI技术在各个领域的应用和发展。
此外,英伟达还宣布了多家知名企业将采用这款Blackwell芯片,包括亚马逊网络服务、戴尔、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉和xAI等。这些企业的参与,不仅验证了Blackwell芯片的强大实力,也预示着AI技术将在未来得到更广泛的应用和普及。
最后,英伟达CEO黄仁勋对Blackwell芯片的看好态度也值得我们关注。他认为这款芯片将成为英伟达最成功的产品发布,并支持构建实时生成式AI。这样的信心和期望,无疑为Blackwell芯片的未来前景增添了不少光彩。
综上所述,英伟达推出的这款最强AI芯片在性能、成本、能耗等方面都有着显著的优势,并且得到了众多知名企业的支持和认可。它的推出,无疑将推动AI技术的发展和应用,为我们带来更多的可能性和机遇。
发布于 2024-03-19 23:30・IP 属地广东查看全文>>
一管窥豹 - 0 个点赞 👍
最强的AI芯片是畅销8年的麒麟710!
还有被鸿蒙优化成旗舰性能的骁龙680;
而宇宙最强的芯片,无疑是麒麟9000、s、l、w,
有这么多、这么强的国产芯片不用,非要去买美帝的芯片吗?不ai国吗?大公主受了那么多委屈,为什么不买华为芯片呢?

 发布于 2024-03-20 14:14・IP 属地山东
发布于 2024-03-20 14:14・IP 属地山东查看全文>>
十万个干什么 - 10 个点赞 👍
就一句话,民用的差距已经那么大了,凭什么让大家相信,在军用领域内,居然是东风压倒西风呢?这个世界上,民用和军用是相辅相成的,没有跛脚鸭,不可能民用烂成泥的时候,军用天下无敌。
现在外国人入境人数只是以前的零头,外资企业一个又一个关门离开中国的时候,AI芯片也出现中外差距拉得这么大的时候,诸位还相信什么“且听龙吟”就是你脑子有问题,而不是世界有问题了。
管中窥豹,从AI芯片可以以小见大,中国从现在开始与世界的距离将越拉越大,而不是距离越来越小。我想过几年,报纸媒体就该将粮食安全可以保证当作津津乐道的事情来说了。现在不就是说俄罗斯打仗是越打越富有,有石油、有粮食的俄罗斯正在看世界的笑话了。我想,再过几年,也都是这种中国看世界笑话的报道了,中国人天天都能吃饱肚子,可不就有底气笑话全世界,尤其是笑话西方美帝野心狼们连饭都吃不到,需要去零元购嘛。
发布于 2024-03-20 12:01・IP 属地中国香港真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
SNOWY - 0 个点赞 👍
以前大家印象中,英伟达不就是卖显卡的么?对显卡性能要求极高的游戏玩家、视频设计是英伟达的主流客户,4090、4070Ti super,在游戏圈讨论的热火朝天。
殊不知,显卡业务根本不是英伟达最赚钱的业务,数据中心业务才是。
说数据中心业务,大家可能觉得陌生,但一说AI芯片,大家马上会恍然大悟。
那么AI芯片和数据中心是怎么挂上钩的呢?
其实道理很简单,AI——中文人工智能,一个成功的人工智能,需要全方位学习人类掌握的知识、模仿人的思维逻辑,理解人类的情绪价值,那么就需要海量的的数据。
但是并不是有了海量的数据,就万事大吉了,人工智能还需要提取、处理、分析并最终自主生成符合人类学的交互方式,这种过程就是【训练模型】,而训练需要庞大的算力能力。
英伟达的AI芯片,恰好可以提供这种庞大的算力,这就是数据中心业务。
总算绕回来了。
那么解释明白了数据中心就是AI芯片,那么在AI芯片市场自然不可能只有英伟达一家独大。
英伟达确实是生产此类AI芯片的先驱,这在一定程度上得益于其长期研发生产用于电子游戏图形的显卡的深厚背景。
但是长期以来,在游戏显卡领域,AMD就一直是英伟达的“老对手”,AMD也拥有着自身的AI芯片系列,并与那些大型数据中心运营商有着深厚的关系。
ADM的目标也很直白,就是要在AI芯片市场拿下20%的市场份额。
除了ADM之外,英特尔也不甘落后,英特尔早在2019年就以约20亿美元收购了以色列人工智能初创公司Habana Labs,目前正在生产其芯片。而且英特尔也有自身的优势,就是除了硬件之外,还可以从软件方面提供开源代替方案,提供增值服务。
除了上述两个传统巨头之外,实力雄厚的亚马逊、谷歌,以及一众初创企业都想要在AI芯片市场分一杯羹。
英伟达虽然优势明显,但护城河并不深,其他各方都有一战之力。
至于中国,其实设计芯片的能力并不差,华为即将于今年发布的昇腾系列据说性能上就要由于英伟达向中国提供的特供版。
中国最大的阻力还是来源于外部的卡脖子政策,美方不当管制严重阻碍我国芯片及芯片设备、材料、零部件企业正常经贸往来。
未来看,国内市场可以完成国产替代还是有希望,但产品走出国门的阻力依然会很大。
但这就是现状,抱怨无用,唯有迎头赶上吧。
发布于 2024-03-20 11:32・IP 属地四川真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
小白马经略观