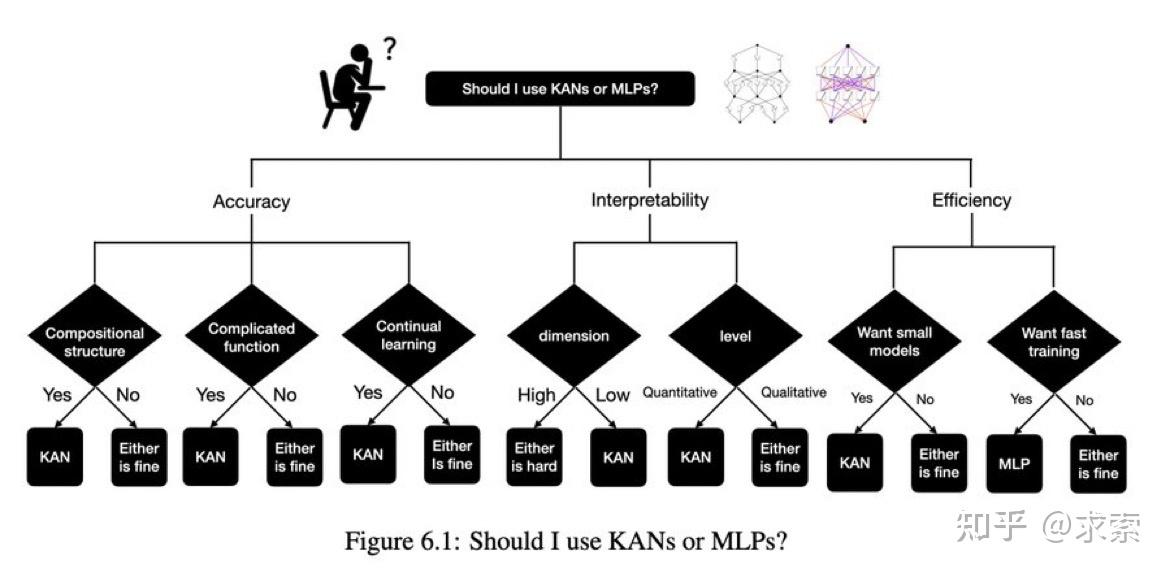
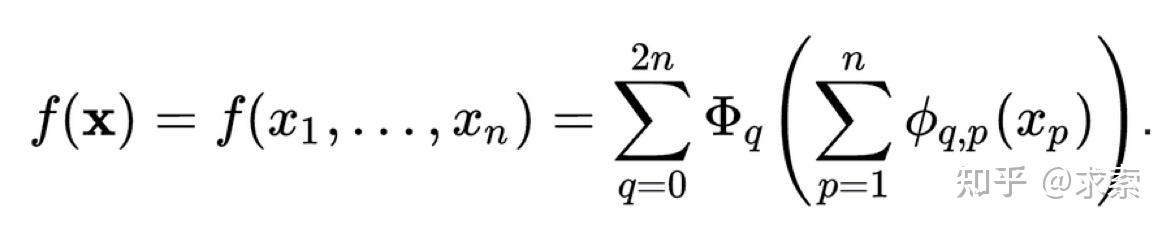如何评价Kolmogorov-Arnold Networks,MLP真的被干掉了吗?
KAN: Kolmogorov-Arnold Networks

- 381 个点赞 👍
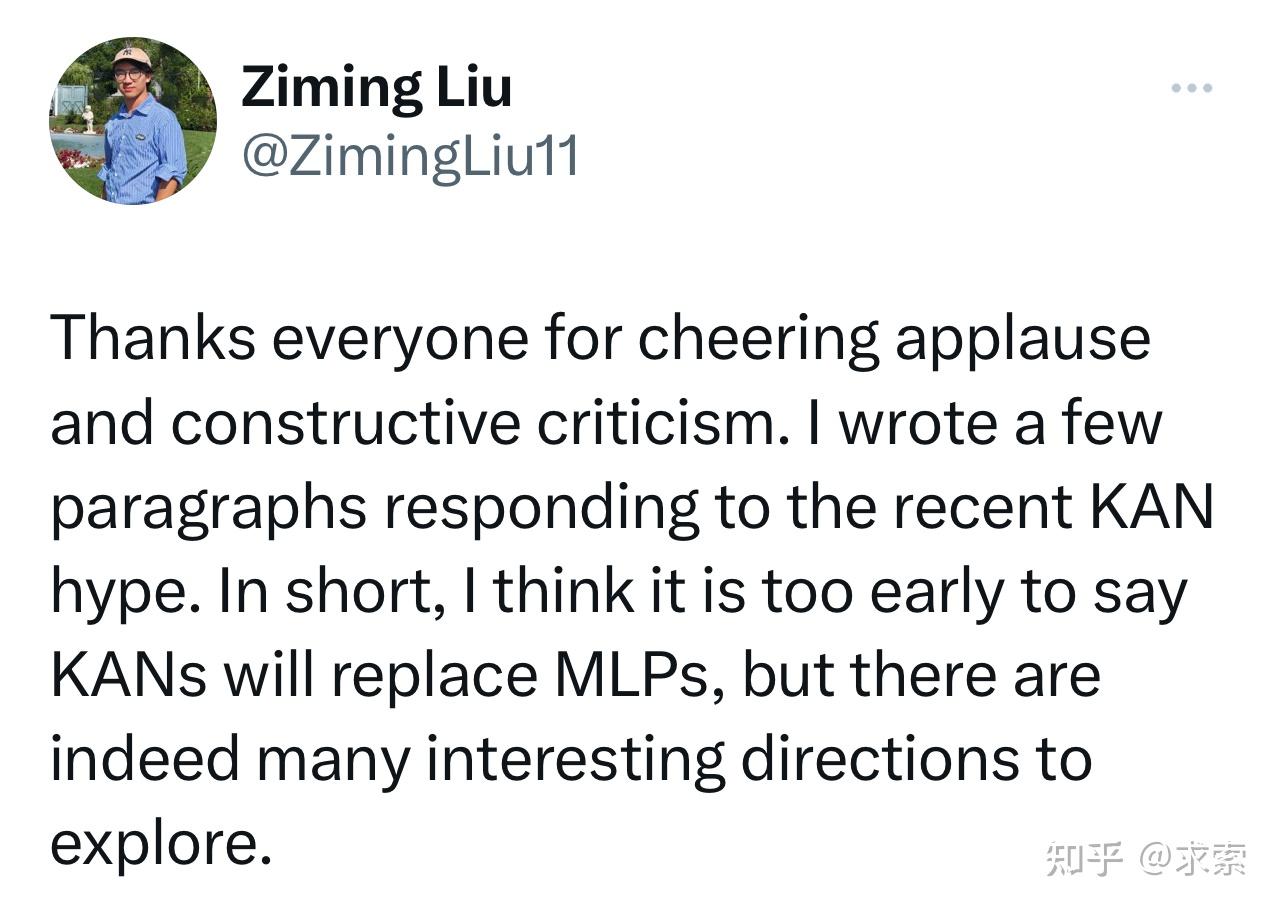
看到了好多大家的夸奖和批评(知乎上批评居多哈哈),受宠若惊。
我设计网络和编程的时候,脑子里面想的都是数学物理的应用,所以模块化/效率等等就没有太怎么考虑,请大家多多包涵。然后也没有想到AI/ML大家这么关注。我的目标受众本来是做科学发现的群体,比较小众的。大家还是理性看待吧,什么是公众号的噱头什么真的只有自己试了才知道。欢迎大家多多尝试,探索KAN的边界在哪里,它和MLP的关系是什么,存不存在更大的框架可以包含两者。KAN/MLP肯定是各有优缺点的,看应用场景了。另外,我的默认参数都是我在文章的数学物理场景的例子中调的,不一定可以直接迁移到其它场景,可能需要仔细调调,尤其是优化部分。当然也有可能其它场景(比如大规模计算),KAN现阶段就是不如MLP合适。KAN更适合高精度和可解释的计算和科学发现。了解到大家的负面结果我也会很开心,因为能让我更好理解KAN的局限。理解大家喷喷,但也更希望大家去GitHub提提有建设性的建议。
发布于 2024-05-03 13:13・IP 属地美国查看全文>>
善良的摩羯小明 - 81 个点赞 👍
总感觉现在喷的人和当年喷NN没用, 喷transformer就是CNN的是同一拨人
一个有意思的新工作出来不应该看看到底有没有potential去做更有意思的事情。上来就是拒绝的态度能搞什么原创的research?发现真的有用还有你口汤喝么?
再补两句,在一个已知work很好的backbone上twist来twist去,在已知work很好的benchmark上刷点,搞A+B+C就有价值了?
喷之前先看看自己做的是不是epsilon水平工作,评价别人的时候的标准倒变成1/epsilon”了
现在的人真是幽默,以为自己读了多少paper就好像别人啥也不懂一样。你自己做了啥epsilon的结果拿出来让大家评价评价?
编辑于 2024-05-04 04:54・IP 属地美国查看全文>>
Sifan - 79 个点赞 👍
大概扫了一眼实在没啥亮点。
而且没看出来和这篇2019年的NIPS区别有多大Weight Agnostic Neural Networks:
https://proceedings.neurips.cc/paper/2019/file/e98741479a7b998f88b8f8c9f0b6b6f1-Paper.pdf
MLP有Universal funciton approximator的理论支持,整那些花里胡哨的没几把用,大家看看热闹就好。
发布于 2024-05-02 21:34・IP 属地新加坡查看全文>>
太捉急 - 73 个点赞 👍
略微有点吃惊,这种有些偏冷门的网络设计以及只在小数据集验证的工作会有这么高的热度。
ddpm刚出来的时候都没几个人讨论过,到22年scale up了才真正火起来。
这是research taste演化了?: D
编辑于 2024-05-05 02:05・IP 属地中国香港查看全文>>
思悥 - 67 个点赞 👍
这年头被干的有点频繁,还没被manba干明白呢又来一位
我先且听龙吟一手
What KAN I say, mamba out
KAN KAN NEED: Two KANS is all you need to replace a FFN layer in transformer除了玩梗之外,这玩意和我之前做的还真有相关性,只能说马上开始挖坑,再且听龙吟一手
编辑于 2024-05-05 20:31・IP 属地江苏查看全文>>
知乎用户 - 51 个点赞 👍
"Kolmogorov-Arnold Networks" 这件事不管是不是闹剧,它的热度,以及ssm,mamba,都可以印证舆论和学术界对于底层方法的突破的渴望。新的representation 假若成功,又让一堆人可以水不少文章了。
另外一边nerf 和 gaussian splatting 的演变亦是如此。
所以如果说要做更有关注度的工作,搞大新闻,不如在nerf->gs->? 这个角度去思考。
发布于 2024-05-03 15:51・IP 属地中国香港查看全文>>
知乎用户 - 45 个点赞 👍
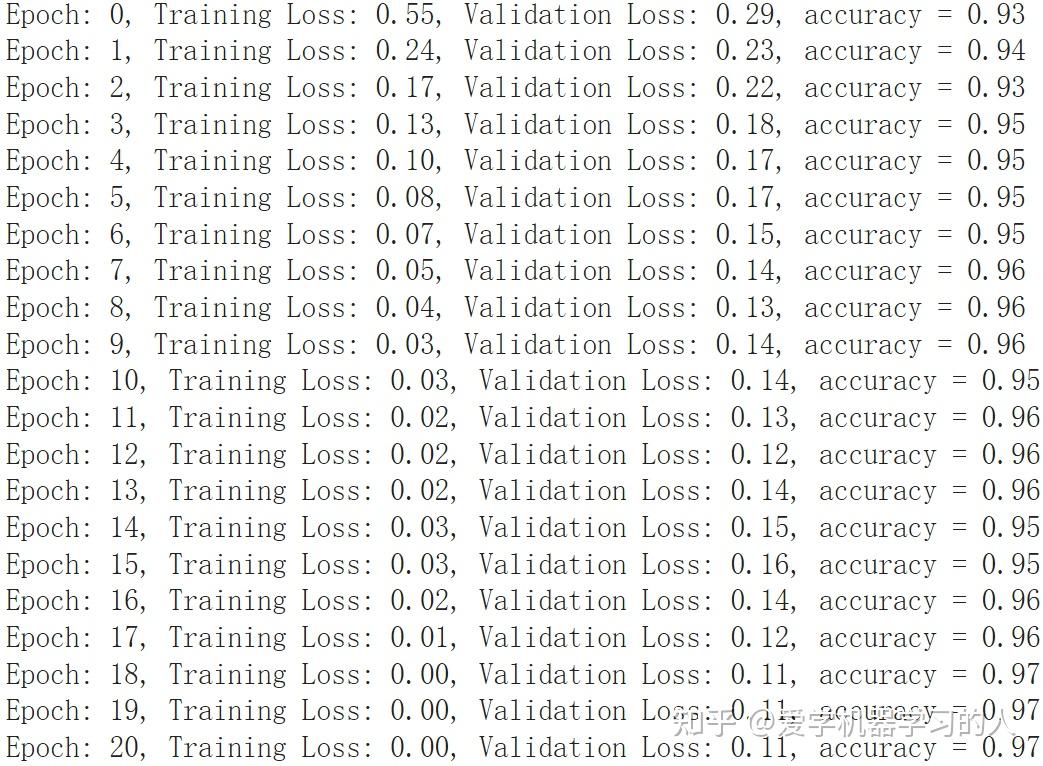
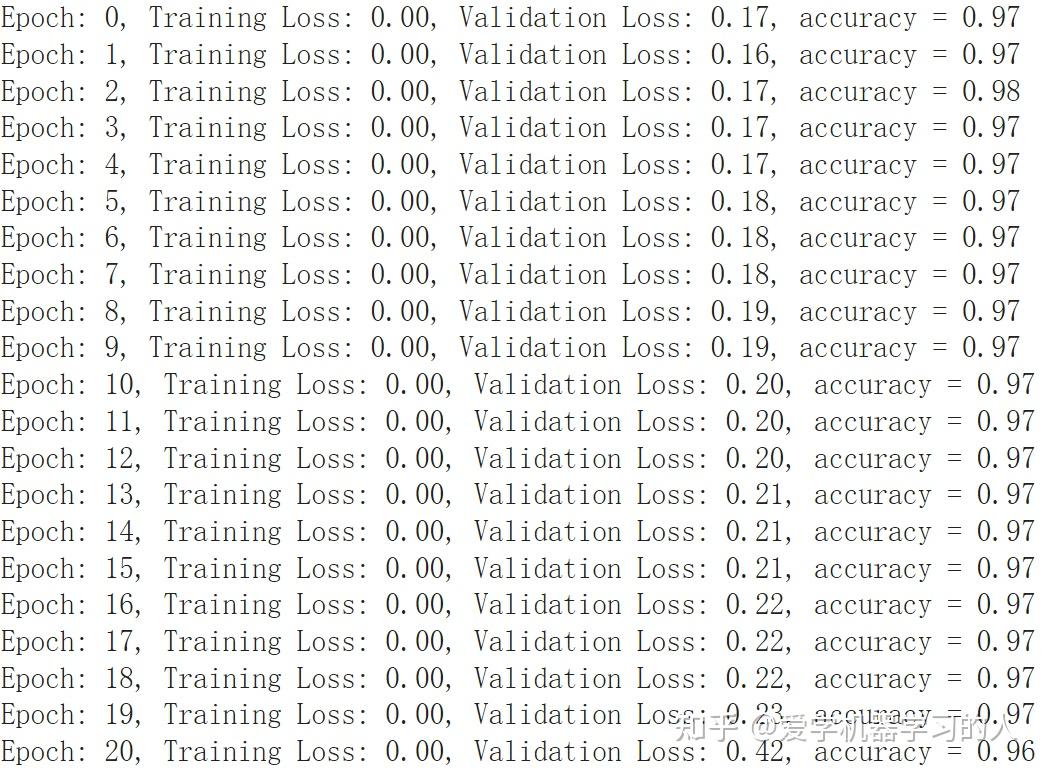
看到这个这么火,忍不住也来试了一下,Google colab自带的mnist数据集测试,
KAN设计对比MLP,优化器什么的都一样,adam默认值,学习率0.0001
#KAN inputdim = 784 hidden = 128 outdim = 10 gridsize = 3 device = "cuda:0"#"cpu" #"cuda" fkan1 = NaiveFourierKANLayer(inputdim, hidden, gridsize).to(device) fkan2 = NaiveFourierKANLayer(hidden, outdim, gridsize).to(device) #MLP self.ly1=nn.Sequential( nn.Linear(784,128), nn.GELU(), nn.Linear(128,10), )

这是KAN的 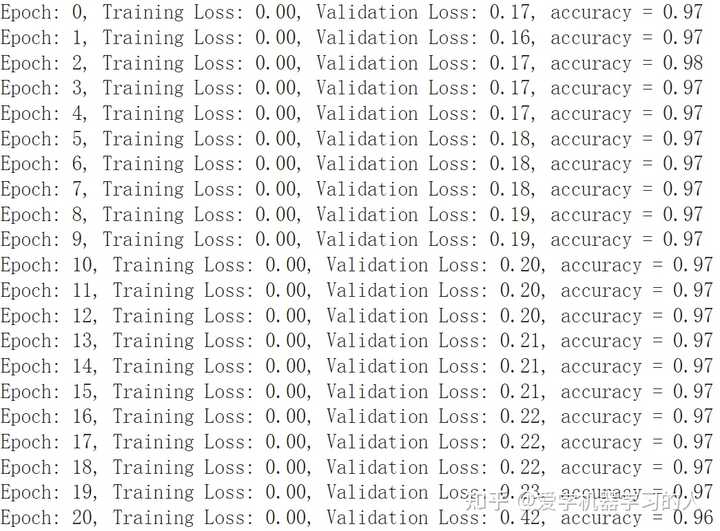

这是MLP MLP收敛速度快,训练速度也快,最终准确率差不多。
有朋友提到MLP过拟合严重,验证损失一直在上升,我想说这看怎么来理解这件事情了,这只是一个非常简单的数据集,可以看出就算是最简单的MLP表示能力也比kan强,不然也没法太过拟合,在复杂数据集上表示能力强是好事情。一个优秀的模型应该是表示能力超强,这样的话在简单数据集上在没有任何防止过拟合手段的情况下过拟合肯定会相当严重。
编辑于 2024-05-07 13:42・IP 属地江苏查看全文>>
爱学机器学习的人 - 42 个点赞 👍
对于做PINN和Neural Operator的本人而言,这篇论文还是有些启发的。由于PINN模型设计有诸多限制,虽然针对一些或一类求解问题有一些新的框架体系[1],但是基于MLP的通用性框架仍然被大量使用。
在保证MLP大结构不变的情况下,从激活函数入手的想法在PINN研究中并不少见,例如Adaptive Activation[2] 。这类方法虽然或多或少有效,但是总体而言仍不是突破性的,依然是在原有设计上的改良。KAN给我最为直观的感受就是捅破了这层窗户纸,从手动设计激活函数迈向了自动学习。从这个角度来看,KAN显然是有意义的,后续我大概也会关注这个方向的动向。
当然. Talk is cheap. Show me the code. 无论怎么吹,还是得拿效果说话。PINN这边,两个头疼的PDE类型:一个是高频,一个是高维。既然KAN在一般拟合和求解中这么有效,那自然希望它在这两个头疼的问题上能表现不俗。
最近,我比较关注的是高频这块。因此基于一个经典问题(一维阻尼谐振)进行了简单实验。通过设置不同的力常数评估模型性能。代码和详细结果可参考我的repo。总体而言,如下几个初步结论:
- 在实验中,当待求解的原函数频率较低时,MLP和KAN都有很高的精度,并且KAN的精度更高,收敛较快;
- 当待求解的原函数频率提高时,MLP和KAN都更难收敛,精度均下降,两个模型的精度差异减小;
- KAN的计算代价相较而言高很多(均是CPU计算);
从实验来看,KAN并没有在高频问题中展现出远超MLP的结果,但是其精度确实有一定优势。更详细的分析还需要进一步实验和调参。
综上,KAN显然是取得了一些突破,但说完全取代MLP仍需要慎重。其有效性和边界需要更大范围的实验和证明才行。这波NeurIPS赶完后可能考虑更深入的探索KAN。
参考
- ^Esmaeilzadeh, S., Azizzadenesheli, K., Kashinath, K., Mustafa, M., Tchelepi, H. A., Marcus, P., ... & Anandkumar, A. (2020, November). Meshfreeflownet: A physics-constrained deep continuous space-time super-resolution framework. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-15). IEEE.
- ^Jagtap, A. D., Kawaguchi, K., & Karniadakis, G. E. (2020). Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. Journal of Computational Physics, 404, 109136.
编辑于 2024-05-04 08:28・IP 属地北京查看全文>>
Koolo - 42 个点赞 👍
查看全文>>
化院本马院博 - 38 个点赞 👍
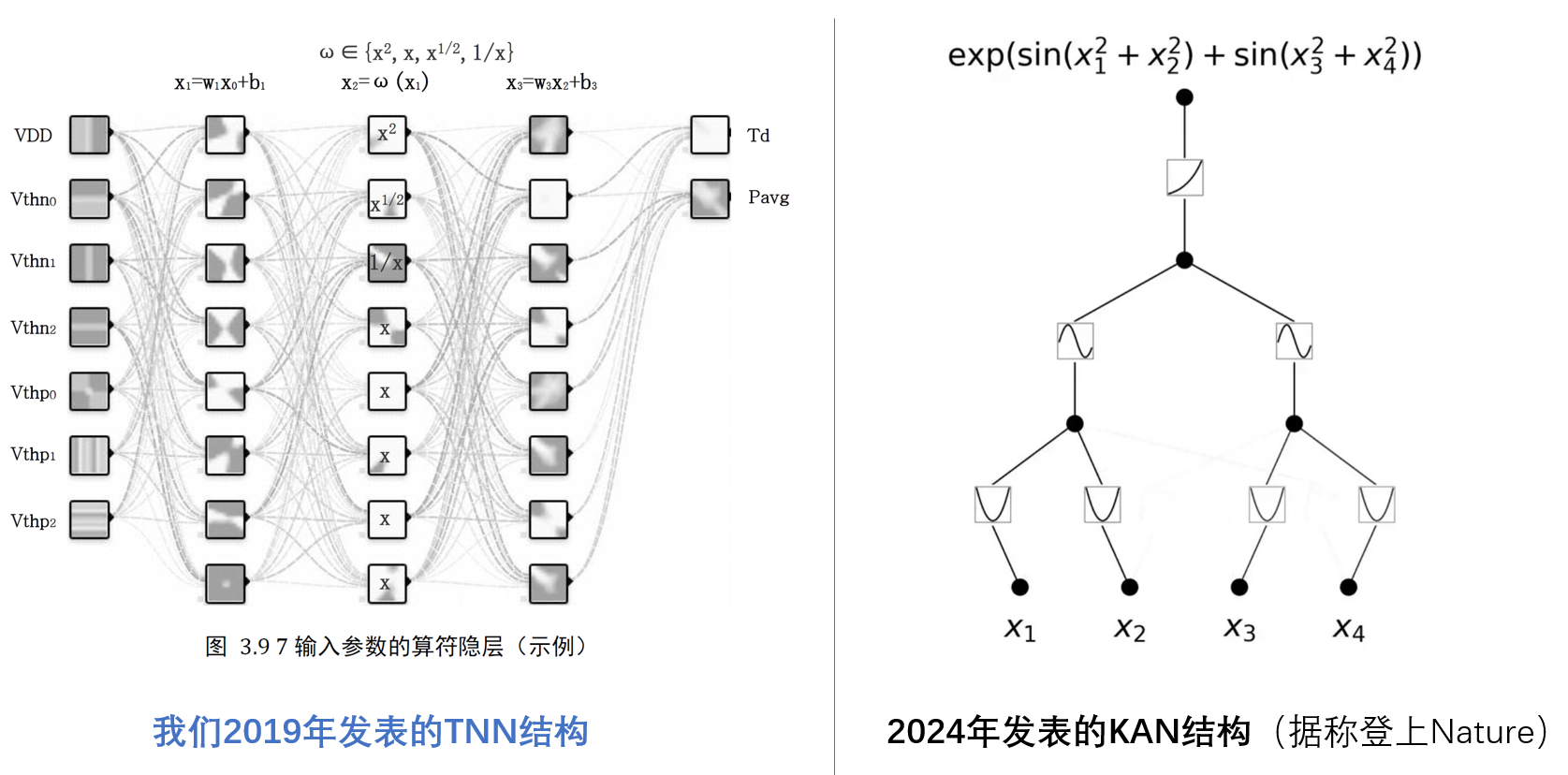
谈MLP被干掉,还为时过早。我们对于KAN的主要观点:
1)精度比传统MLP更高;
2)训练算力要求更高,训练难度更高;
3)现在看起来toy的主要原因是因为Training的算力完全跟不上。
关于KAN的详细解读,可以看我们团队的长文:
由于训练算力限制,到大模型这类主流应用还是有很长的路要走,短期看KAN还是很难代替MLP的。类似当年Encoder-Decoder架构可能看起来比Decoder only要好,但实际上Encoder-Decoder的训练代价导致GPT这类Decoder only架构成为现在的主流。长远看KAN可能逐渐在数学物理研究中广泛采用,然后逐渐进入主流舞台。
顺带说下,我们团队在5年前就发表了相近工作(我们称为TNN),在传统MLP中加入算符隐层,并奠定了使用非线性算子的核心思路。
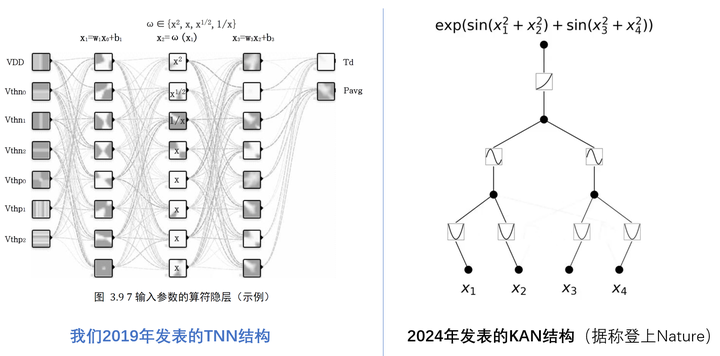

其优势是使用非线性算子(典型的是多项式或样条)可以更快的逼近任意函数,难度在于训练的算力要求过高。这个工作的本质是借鉴了MLP及SVM Kernel Function的思路。
关键点有2个:
1)构造算子空间,提升表征能力。把原来的MLP实数空间扩展到“实数+算子”的泛函空间,将算子/核函数视为空间中的离散元素,将MLP中的乘法扩展为算子空间的元素。
2)参考泰勒展开,减小算子空间元素数量。参考泰勒展开的思路,可以使用多项式(非线性函数)累加做任意实数函数的逼近。这也就解释了为什么TNN和KAN这类方法可以很好的应用于数学计算。
发布于 2024-05-04 12:10・IP 属地广东查看全文>>
陈巍 博士 - 36 个点赞 👍
在Mnist数据集上简单测了一下最近几个KAN模型。这边就直接RUN了,感兴趣的试试看:
KAN paper: [Kolmogorov-Arnold Networks](KAN: Kolmogorov-Arnold Networks)

KANs(以下为参考的项目,上文的项目集成了以下模型):
- [KANs](https://github.com/KindXiaoming/pykan)
- [Efficient-KAN](https://github.com/Blealtan/efficient-kan)
- [FourierKAN](https://github.com/GistNoesis/FourierKAN)
- Two-layer MLP (Toy Version)
经验设置
- 对于KAN,较大的初始学习率可能更有效。(你可以试试' lr = 1e-2 ')
- 在我的实验中,KAN确实比MLP收敛得更快。
编辑于 2024-05-05 22:08・IP 属地江苏查看全文>>
炼丹门下废猫 - 25 个点赞 👍
查看全文>>
盛见者 - 23 个点赞 👍
两个问题,谁难训练,谁推理速度更慢。
如果,虽然训练难,但是推理速度快,那么参数量小的优势就明显,可以用于嵌入式系统,还可以复用并行计算机浮点计算的多年积累。
但是,还是需要实证。
看intel的动作吧。如果intel有动作,就等六个月,应该有初步实验结果。
发布于 2024-05-03 00:33・IP 属地湖北查看全文>>
知乎用户 - 19 个点赞 👍
这个问题关注度比较高?
论文似乎并没有提供KAN结构的ablation study
个人尝试在MNIST上修改了一下,在本人架构上收敛更快了。下面是一个epoch的结果
MLP: 96.6
原KAN: 84.1
新KAN: 97.5
新KAN 2: 98.1
编辑于 2024-05-05 14:09・IP 属地河北查看全文>>
tensor - 18 个点赞 👍
查看全文>>
懵萌檬 - 18 个点赞 👍
关于这个问题,在解答之前,我想我们需要明白MLP为什么这么受欢迎?


多层感知器(MLP)是一种前馈人工神经网络,它在神经网络的领域中有着广泛的应用。MLP的主要优点包括:
- 非线性激活函数:MLP使用非线性激活函数(如ReLU、Sigmoid、Tanh等),这使得它能够学习和模拟复杂的非线性关系和模式。
- 万能逼近定理:理论上,MLP可以逼近任何连续函数到任意精度,只要提供足够的隐藏层神经元和训练数据。
- 易于理解和实现:与更复杂的网络结构相比,MLP的结构相对简单,易于理解和实现。这使得它在教学中和初学者中非常受欢迎。
- 广泛的应用:MLP被广泛应用于各种机器学习任务,包括分类、回归、异常检测等。
- 可扩展性:可以通过增加隐藏层的数量和神经元的数量来增加模型的复杂度,以适应更复杂的任务。
- 并行处理能力:MLP可以通过在GPU上进行训练来利用并行处理能力,这使得训练大规模网络成为可能。
- 成熟和广泛的研究:由于MLP在神经网络的历史中占有重要地位,因此它有着成熟和广泛的研究基础,许多优化和改进技术都是针对MLP开发的。
说完MLP的优点,我们再来看看他的局限性:
- 容易过拟合:过拟合是指模型在训练数据上表现良好,但在新的、未见过的数据上表现不佳。这种情况通常发生在模型过于复杂,拥有大量参数时,导致模型“记住”了训练数据中的噪声和细节,而未能捕捉到数据的真实分布。解决过拟合的方法包括使用正则化技术(如L1或L2正则化)、减少模型复杂性、采用数据增强或集成学习等。
- 训练速度可能较慢:模型的训练速度受多种因素影响,包括模型的复杂性、数据集的大小、硬件性能等。一个复杂的模型,如深度神经网络,通常需要较长的训练时间。此外,大规模的数据集也会增加训练时间。为了提高训练速度,可以采用优化算法(如Adam、RMSprop)、使用更高效的硬件(如GPU)、进行批量归一化、使用预训练模型等技术。
- 对特征缩放敏感:特征缩放是指将数据集中的特征转换到相似的尺度。某些算法(如梯度下降)对特征缩放非常敏感,因为如果特征尺度差异很大,模型可能会在迭代过程中产生不必要的震荡,导致收敛速度慢甚至无法收敛。常用的特征缩放方法包括标准化(将特征缩放到均值为0,标准差为1)和归一化(将特征缩放到特定范围,如0-1)。正确的特征缩放可以显著提高模型的性能和训练速度。
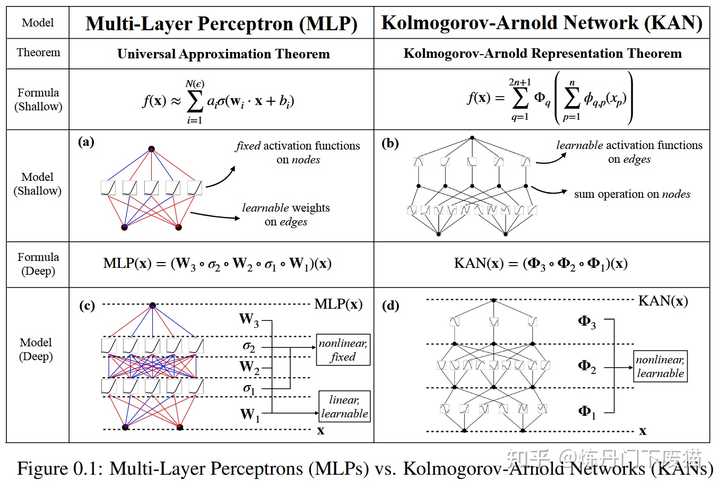
简单介绍完MLP,我们再来看看KAN。
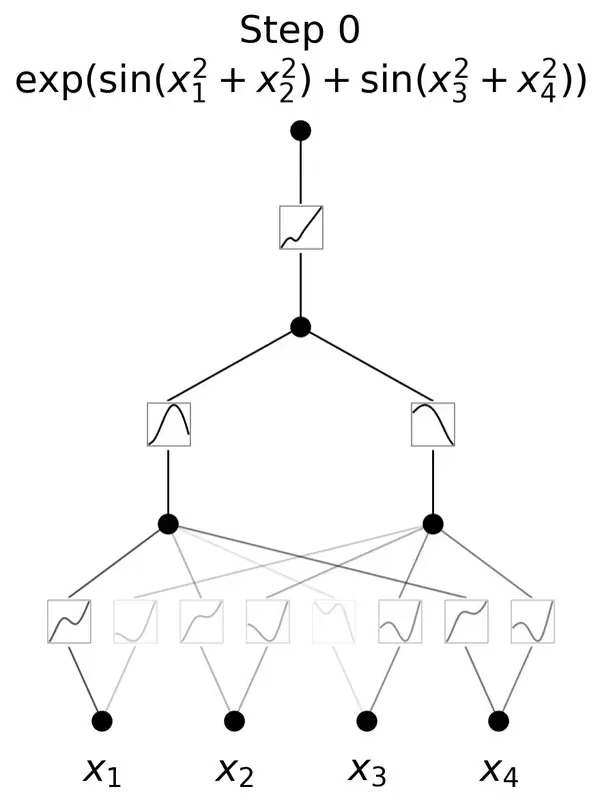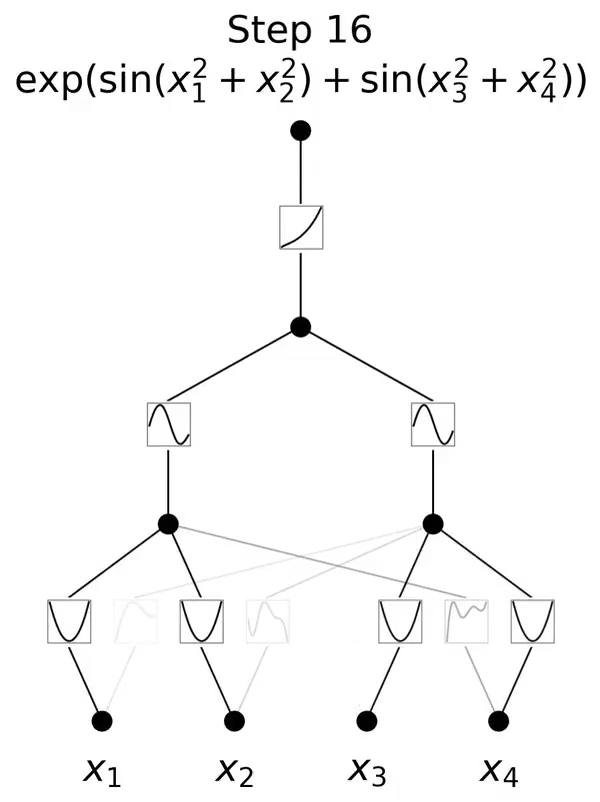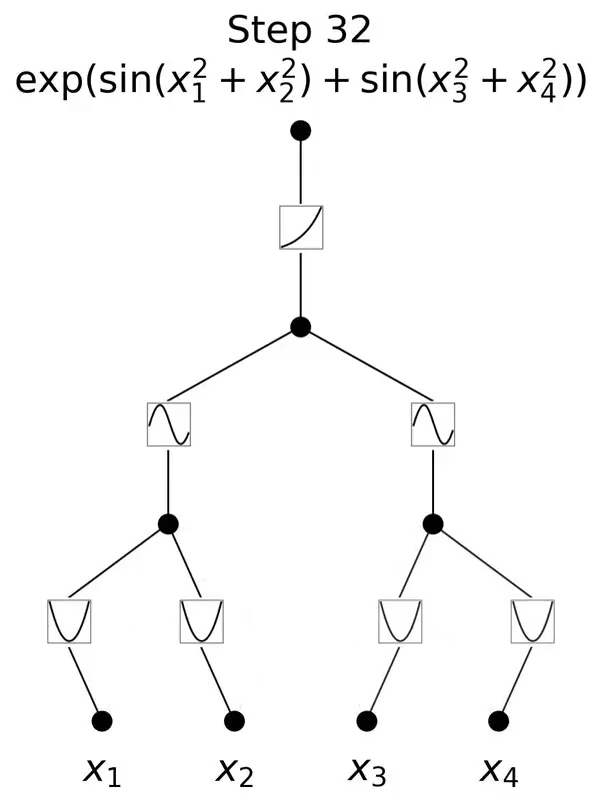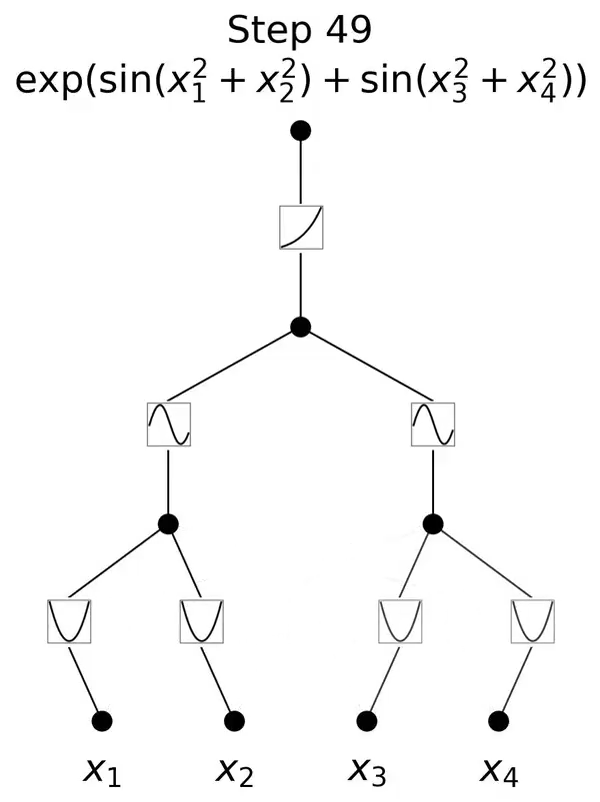

KAN的灵感来源于数学中的Kolmogorov-Arnold表示定理。这一定理在数学界具有深远的影响,它揭示了函数表示与神经网络之间的深刻联系。
KAN通过将这一理论应用于神经网络设计,实现了对传统MLP架构的突破。
与传统的MLP相比,KAN的一个主要不同点在于其对激活函数的处理。
在MLP中,激活函数是作用于每个神经元上的,而在KAN中,激活函数被转移到了权重上。这意味着在KAN中,权重本身是可学习的,而不仅仅是传递信号的媒介。
这种设计使得KAN在处理复杂函数时表现出更高的灵活性和效率。
其架构设计使其在函数逼近能力上具有显著优势。
由于权重本身可以学习激活函数的特性,KAN能够更有效地逼近复杂的非线性函数,这对于处理现实世界中的复杂问题至关重要。
在训练效率方面,KAN也展现出其优越性。
由于其权重的可学习性,KAN在训练过程中可以更快地收敛,减少了所需的迭代次数,从而提高了训练效率。

KAN的另一个亮点是其强大的泛化能力。
在处理未见过的数据时,KAN能够更好地保持其性能,这在实际应用中尤为重要。
KAN神经网络架构以其独特的创新点和优异的性能,确实具有挑战MLP地位的潜力。
然而,是否能够完全取代MLP,我只能说,时间会说明一切。
发布于 2024-05-06 12:46・IP 属地四川查看全文>>
小机 - 14 个点赞 👍
谢邀。
Kolmogorov-Arnold Networks (KANs) 基于柯尔莫哥洛夫-阿诺德定理,相比传统的MLP(多层感知机),KANs在多个领域表现出了更优秀的性能,特别是在函数逼近和偏微分方程求解等任务中。
但是,说MLP已经被“干掉”可能为时尚早。
MLP由于其简单性和灵活性,在很多应用中仍然非常有效且不可替代。
手把手升级ChatGPT4.0 Turbo详细步骤教程(2024年4月)
而KANs虽然在理论与实验上都显示了巨大潜力,其在实际应用中的广泛性和效率,特别是在神经网络模型中取代MLP层的可能性,还有待观察和深入研究。
KAN具体内容参考之前发布的文章:


关键的挑战包括对KANs参数的优化问题,以及在当前硬件上的计算效率问题。
另外,从技术发展的角度看,每一种新技术的出现不仅仅是为了取代旧有技术,更重要的是为了扩展我们解决问题的能力。
因此,KAN的出现不应该被视为对MLP的简单取代,而是应该看作是机器学习领域中的一个补充和进化,提供了更多的可能性和选择。
项目地址:Welcome to Kolmogorov Arnold Network (KAN) documentation!
通过github安装
git clone https://github.com/KindXiaoming/pykan.git cd pykan pip install -e . # pip install -r requirements.txt # install requirements通过 PyPI 安装
pip install pykan开始使用 KAN
初始化KAN
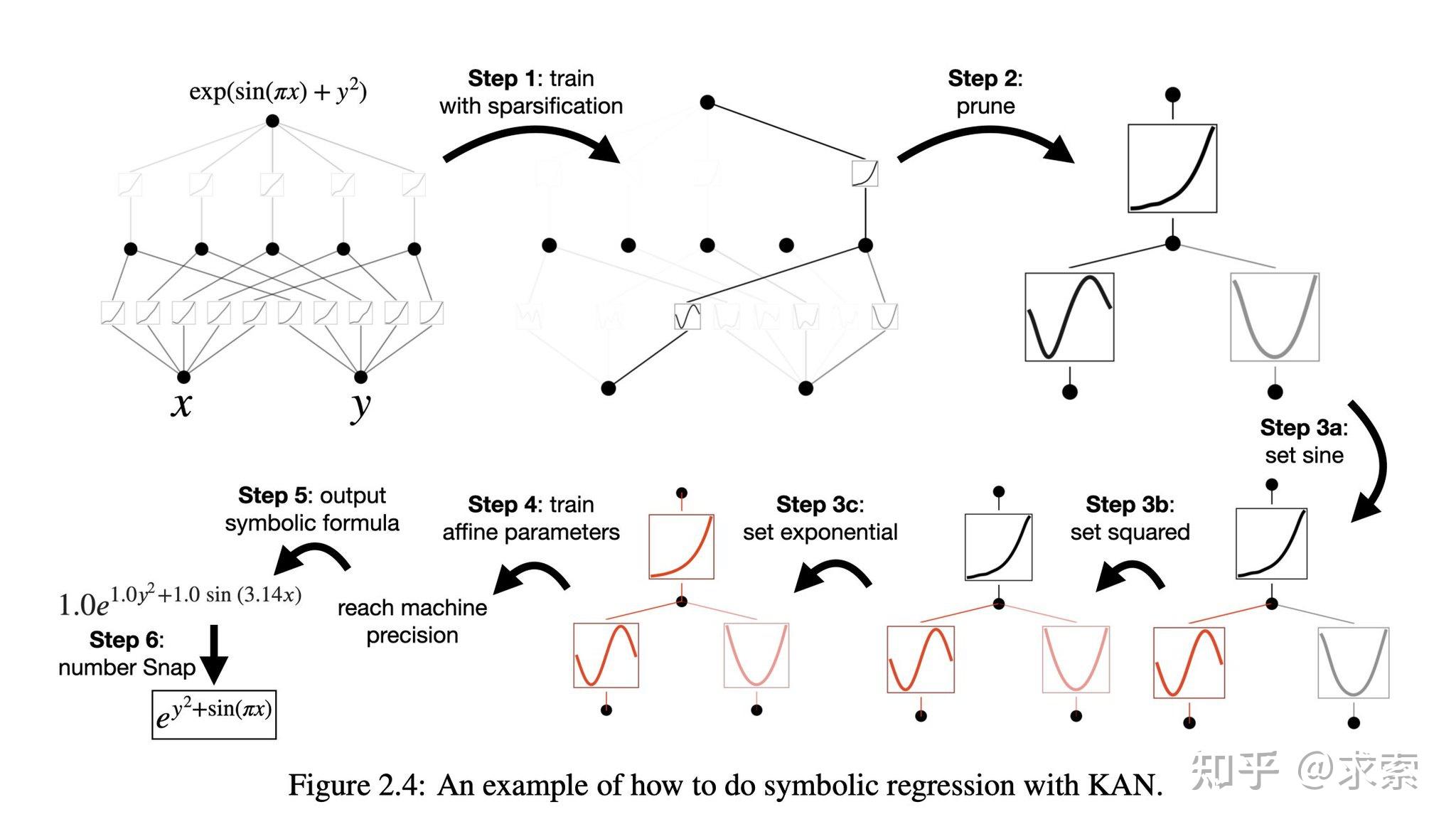
from kan import * # create a KAN: 2D inputs, 1D output, and 5 hidden neurons. cubic spline (k=3), 5 grid intervals (grid=5). model = KAN(width=[2,5,1], grid=5, k=3, seed=0)创建数据集
# create dataset f(x,y) = exp(sin(pi*x)+y^2) f = lambda x: torch.exp(torch.sin(torch.pi*x[:,[0]]) + x[:,[1]]**2) dataset = create_dataset(f, n_var=2) dataset['train_input'].shape, dataset['train_label'].shape(torch.Size([1000, 2]), torch.Size([1000, 1]))初始化时绘制 KAN
# plot KAN at initialization model(dataset['train_input']); model.plot(beta=100)

推荐文章:
AI教母李飞飞首创业,瞄准“空间智能”! | 斯坦福AI教母首次创业,将学术休假两年,瞄准“空间智能”方向!!!
编辑于 2024-05-06 15:19・IP 属地山东查看全文>>
知乎用户 - 13 个点赞 👍
这篇论文给我印象最深的一句话:
The language of science is functions.
根据问题特点,设计解决方案。
专才优于通才。
分工合作,合作共赢。
KAN甚至不一定需要考虑在NLP、CV上面的性能。
Kolmogorov-Arnold Networks (KAN)随想
发布于 2024-05-04 09:17・IP 属地加拿大查看全文>>
Yuxi Li - 13 个点赞 👍
干不干的掉,我不知道。但是谢谢标题党的亲__肯定不保。把激活函数也换成可以学习的话。肯定计算量指数级增加,还不知道有没有效果。感觉会有?但没有单纯的激活函数性价比高?
标题越来越离谱了,200参数量,200顶30万。533万那不是顶80亿。这也太离谱了哥。
编辑于 2024-05-03 19:49・IP 属地江西查看全文>>
卡基 - 12 个点赞 👍
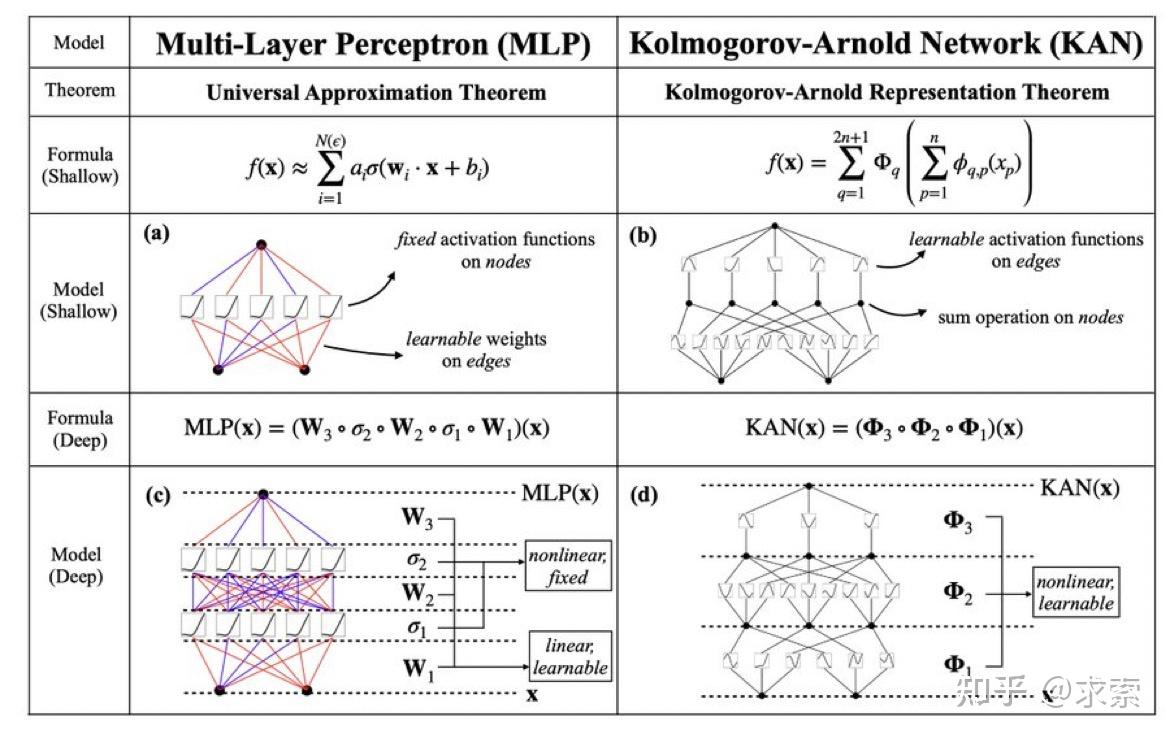
Kolmogorov-Arnold Networks(KANs)是一种受Kolmogorov-Arnold表示定理启发的网络结构,它作为多层感知器(MLPs)的一个有希望的替代品被提出。KANs与MLPs的主要区别在于激活函数的位置:KANs在边上有激活函数,而MLPs在节点上有激活函数。这种简单的改变使得KAN在准确性和可解释性方面优于MLPs。
尽管如此,MLP仍然是一个重要的研究领域,并且在不同的应用场景中都有其独特的优势。例如,MLP和CNN之间的关系表明,MLP实际上是CNN的一个特例,这意味着MLP本身也具有CNN的一些特性。此外,MLP在2021-2022年期间的发展显示了其在特定任务上的有效性,如结合卷积层和MLP层可以实现最佳性能。
虽然KANs提供了一种可能优于MLPs的新结构,但MLP并没有被“干掉”。相反,MLP仍然是神经网络研究和应用中的一个重要组成部分,特别是在需要考虑长程依赖和局部特征提取的复杂任务中。此外,MLP的财务可持续性问题、与其他架构如CNN和Transformer的竞争,以及对超参数和模型理解的需求,都表明MLP仍然是一个活跃且不断发展的研究领域。
KANs作为一种新的网络结构,为MLPs提供了有希望的替代方案,但在当前阶段,MLP并没有被完全取代。MLP和KANs各有优势,它们在不同的应用场景和研究方向上都有其独特的价值和潜力。因此,我们不能简单地说MLP已经被“干掉”,而是应该看到它与新兴技术之间的互补和发展。
2. tensorflow源码MLP对比- 1.1 CNN卷积神经网络
3. KAN: Kolmogorov-Arnold Networks - 智源社区论文
4. Transformer要变Kansformer?用了几十年的MLP迎来挑战 ...
5. 归纳偏置多余了?靠“数据堆砌” 火拼Transformer,MLP 架构 ...
7. r - Difference between "mlp" and "mlpML" - Stack Overflow
9. Welcome to Kolmogorov Arnold Network (KAN) documentation!
发布于 2024-05-05 14:47・IP 属地上海查看全文>>
AI真绘动 - 7 个点赞 👍
由于万能近似定理的存在,你得证明KAN确实大幅提高在给定训练成本下的表达能力,也就是通过适当增加MLP的深度和宽度所不能表达的东西。换言之,除非KAN能普遍大幅减少MLP的训练成本,不然你就难言非A即B的取代。
编辑于 2024-05-06 15:29・IP 属地北京查看全文>>
Steven Tan - 7 个点赞 👍
查看全文>>
大宋提辖鲁 - 6 个点赞 👍
我刚看到前几页,没看懂这里为什么
这里第4页说ka表示定理,那些函数Φ可能非光滑,所以理论上不适合在ml里面使用
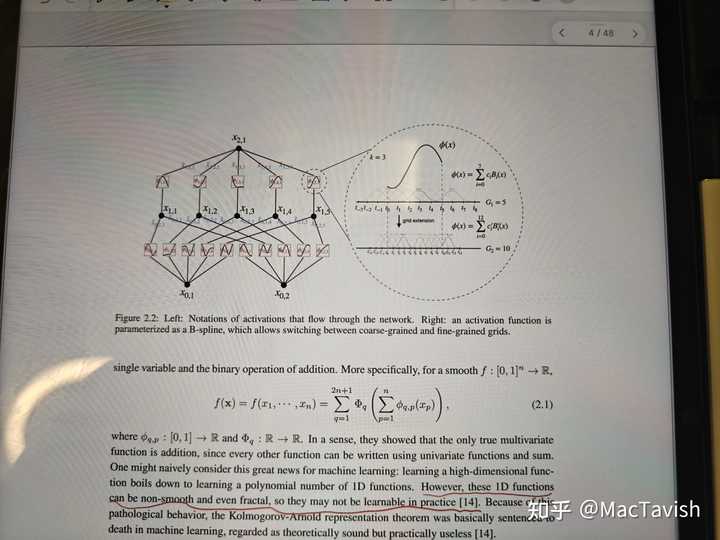

但是第6页又说,如果按他们这么构建这么多层,这些就是可微的;如果是事先声明了这些所有的Φ可微,那么对于任意一个给定函数f,是否一定存在{Φ}这样的函数列使这个表达式收敛到f?
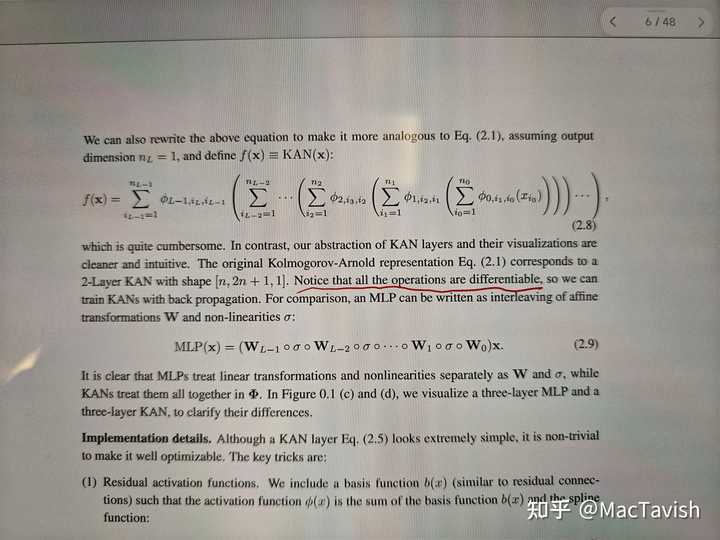
 发布于 2024-05-03 16:21・IP 属地江西
发布于 2024-05-03 16:21・IP 属地江西查看全文>>
MacTavish - 5 个点赞 👍
这篇论文比较炸裂,:麻省理工和加州理工研究人员提出了一种新型神经网络KANs,颇有“项庄舞剑,意在沛公”目标剑指MLP,这可是要动了深度学习的根基…..但要干掉MLP,KANs还有一段路要走,感兴趣可以查看如下文章:
最近麻省理工、加州理工等学校研究员发表一篇替代多层感知机MLP的论文《KAN: Kolmogorov–Arnold Networks》。
论文摘要
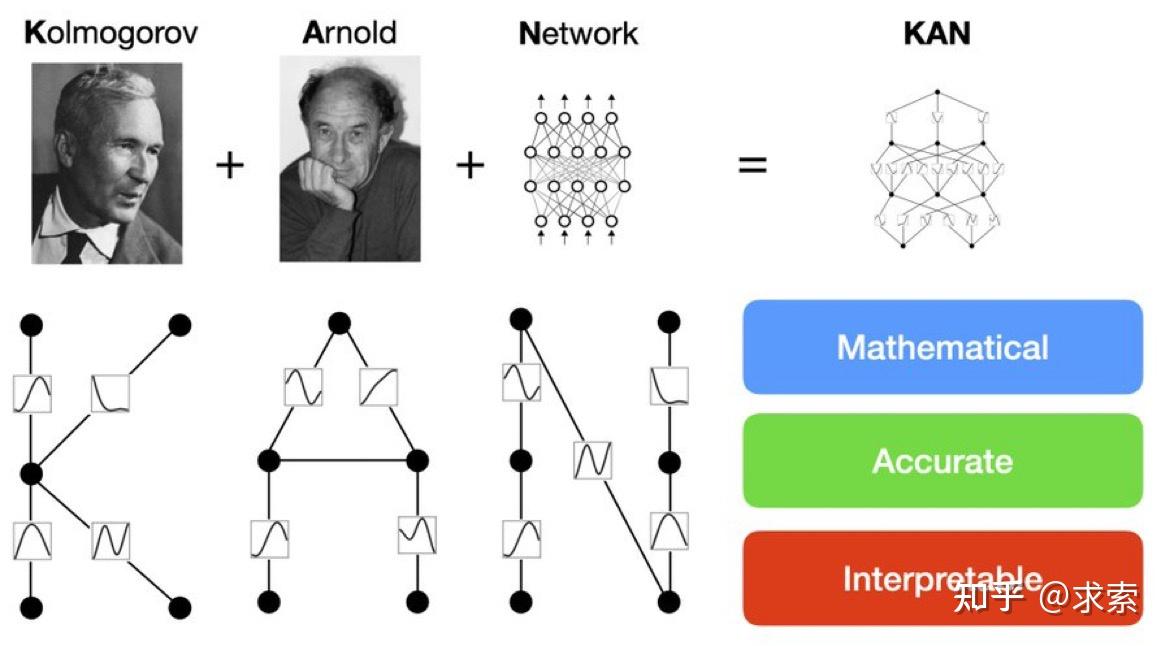
论文提出了一种新型神经网络架构——Kolmogorov-Arnold Networks(KANs)(为了纪念两位伟大的已故数学家安德烈·科尔莫戈罗夫和弗拉基米尔·阿诺德,我们称他们为科尔莫戈罗夫-阿诺德网络),它受到Kolmogorov-Arnold表示定理的启发,目标是作为多层感知器(MLPs)的替代品。
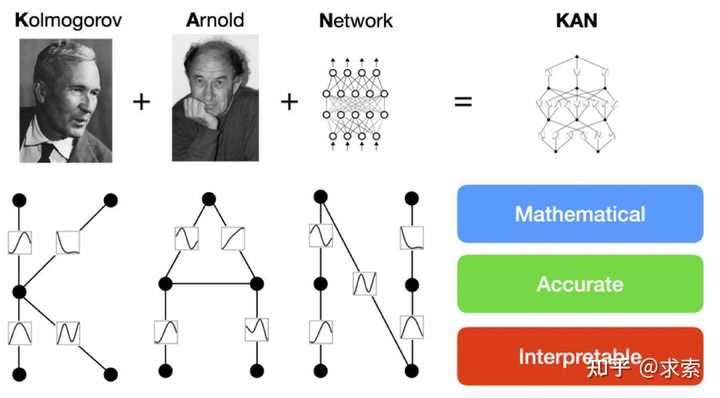

KANs的特点是将激活函数置于网络的边缘(权重),而不是传统的节点上,并且这些激活函数是可学习的,由样条函数参数化。论文开发了KANs的实现代码,并通过GitHub和pip安装包分享给研究社区,促进了进一步的研究和开发。
KANs解决了MLPs在非线性回归、数据拟合、偏微分方程求解以及科学发现中的一些限制,如固定激活函数的局限性、参数效率低、可解释性差等。
KANs通过网格扩展技术提高准确性,即通过细化样条函数的网格来提高逼近目标函数的精度。引入简化技术,包括稀疏化、可视化、剪枝和符号化,以提高KANs的可解释性。
论文核心内容
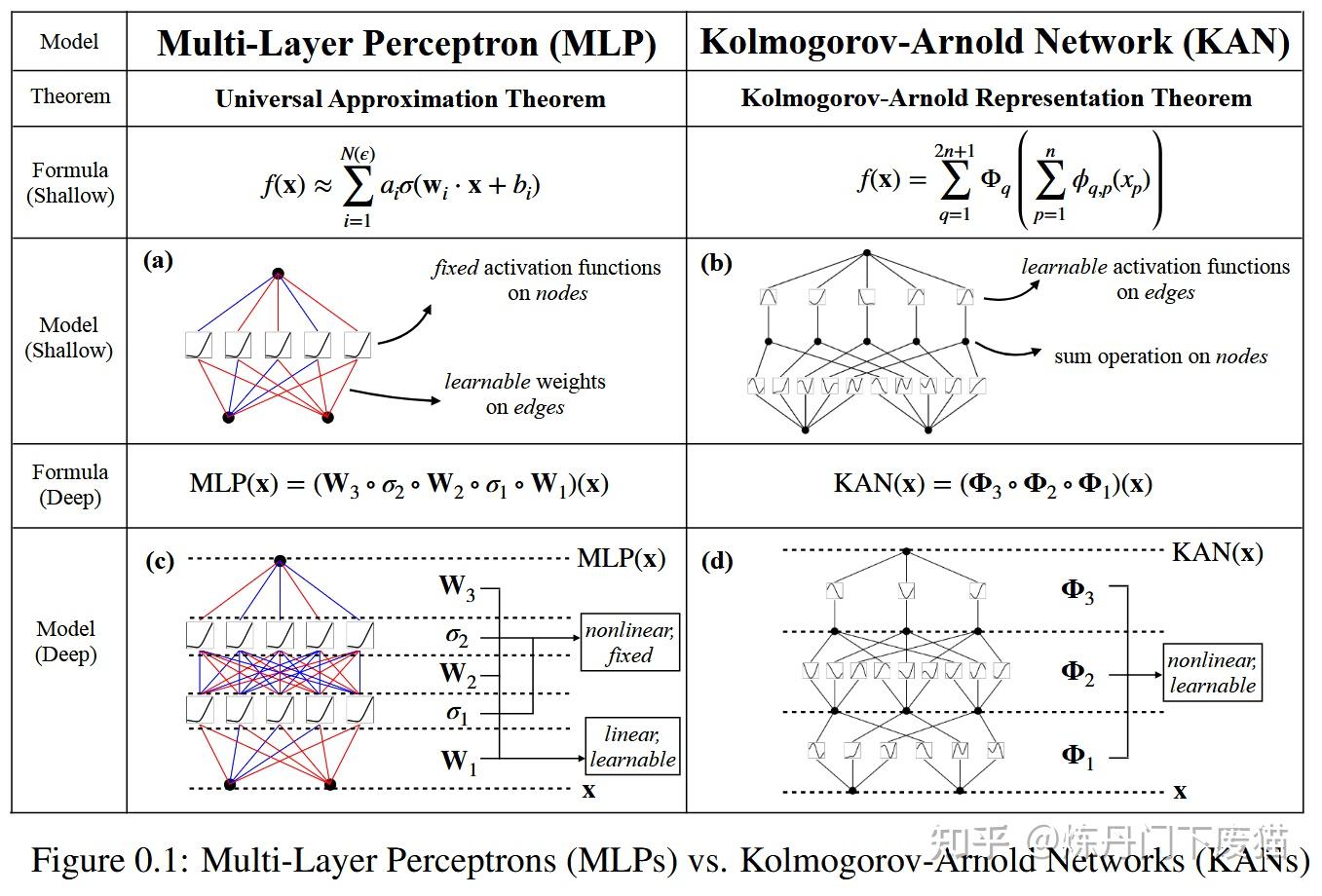
MLP 是如此基础,但还有其他选择吗?MLP 将激活函数放在神经元上,但我们是否可以将(可学习的)激活函数放在权重上?是的,KAN可以!作者提出了 Kolmogorov-Arnold 网络 (KAN),它比 MLP 更准确、更易于解释。

KANs对 MLP 进行简单的更改:将激活函数从节点(神经元)移到边缘(权重)!KANs通过将每个权重参数替换为一个一元函数,利用样条函数来近似这些一元函数。

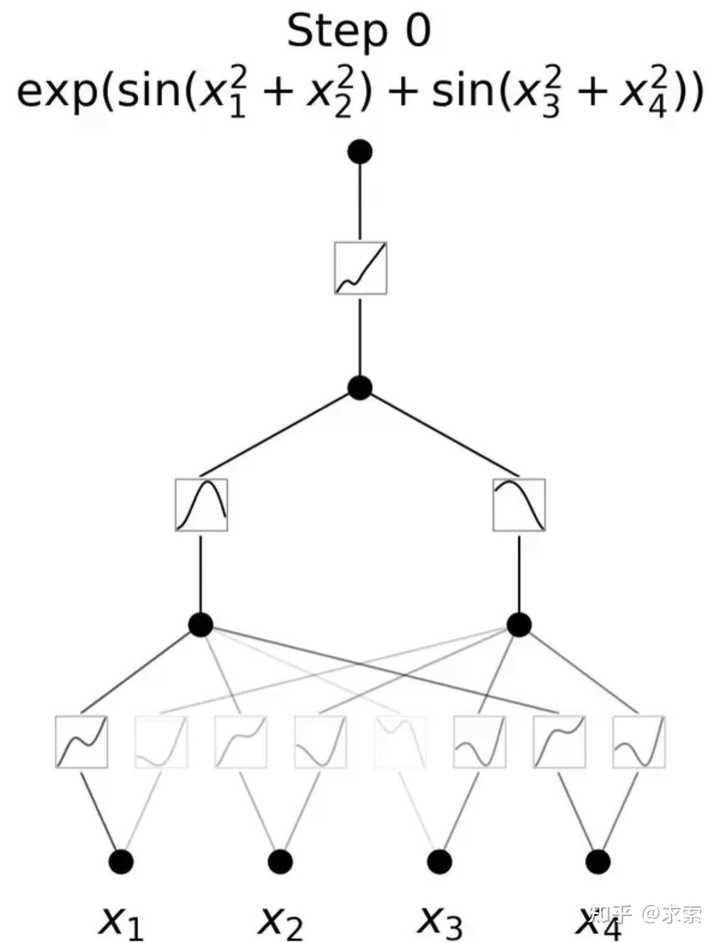
这个变化乍一听似乎有些奇怪,但其实它与数学中的近似理论有着很深的联系。事实证明,Kolmogorov-Arnold 表示对应于 2 层网络,其 (可学习) 激活函数位于边上而不是节点上。
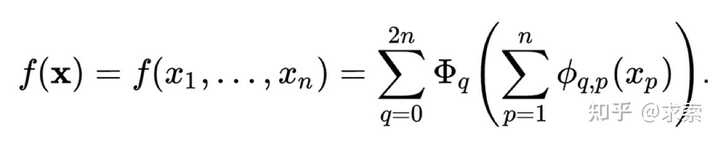

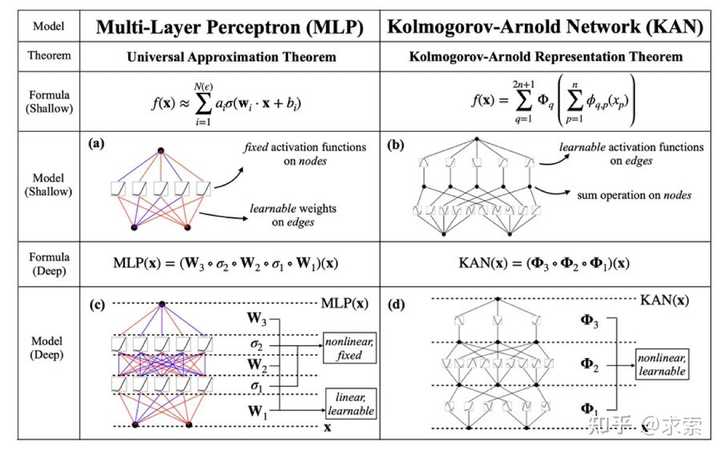
从数学角度来看:MLP 受到通用近似定理 (UAT) 的启发,而 KAN 受到柯尔莫哥洛夫-阿诺德表示定理 (KART) 的启发。网络能否以固定宽度实现无限精度?UAT 的答案是“不”,而 KART 的答案是“可以”(但有警告)。
从算法方面来看:KAN 和 MLP 是双重的,因为-- MLP 对神经元具有(通常固定的)激活函数,而 KAN 对权重具有(可学习的)激活函数。这些 1D 激活函数被参数化为样条函数。
从实际角度来看:作者发现 KAN 比 MLP 更准确、更易于解释,尽管由于 KAN 的激活函数可学习,因此训练速度较慢。
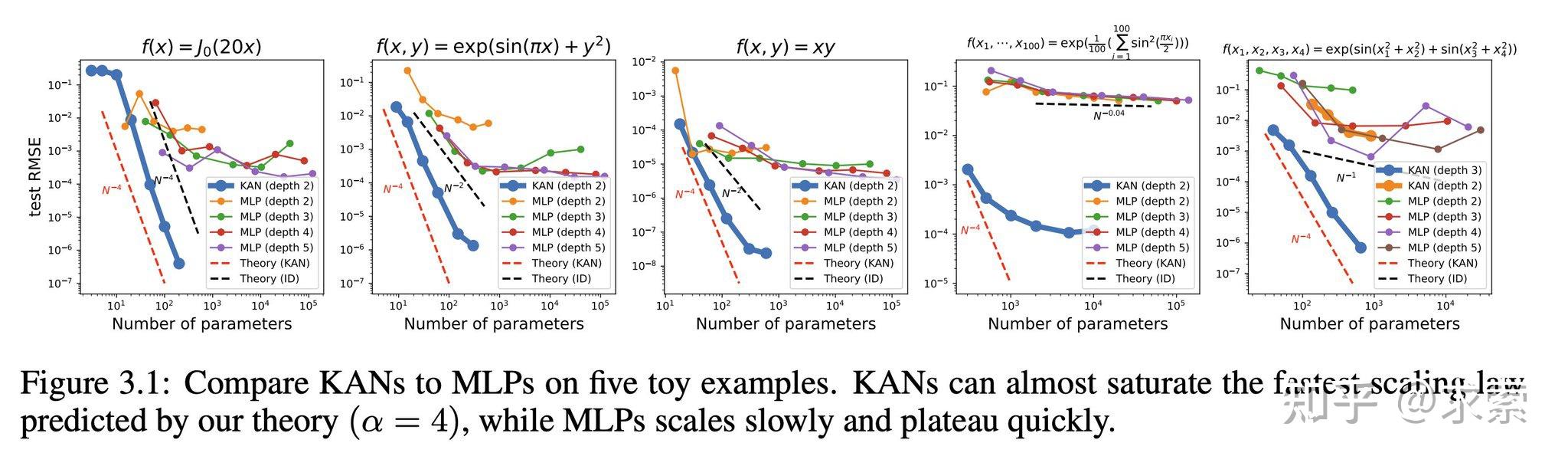
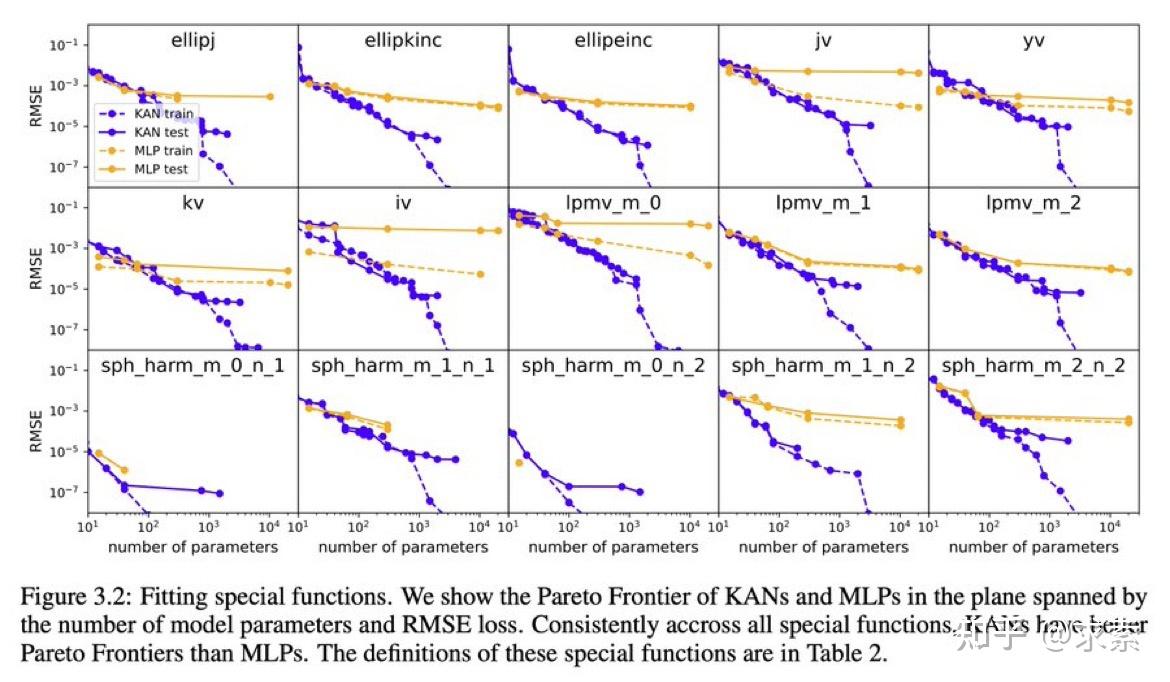
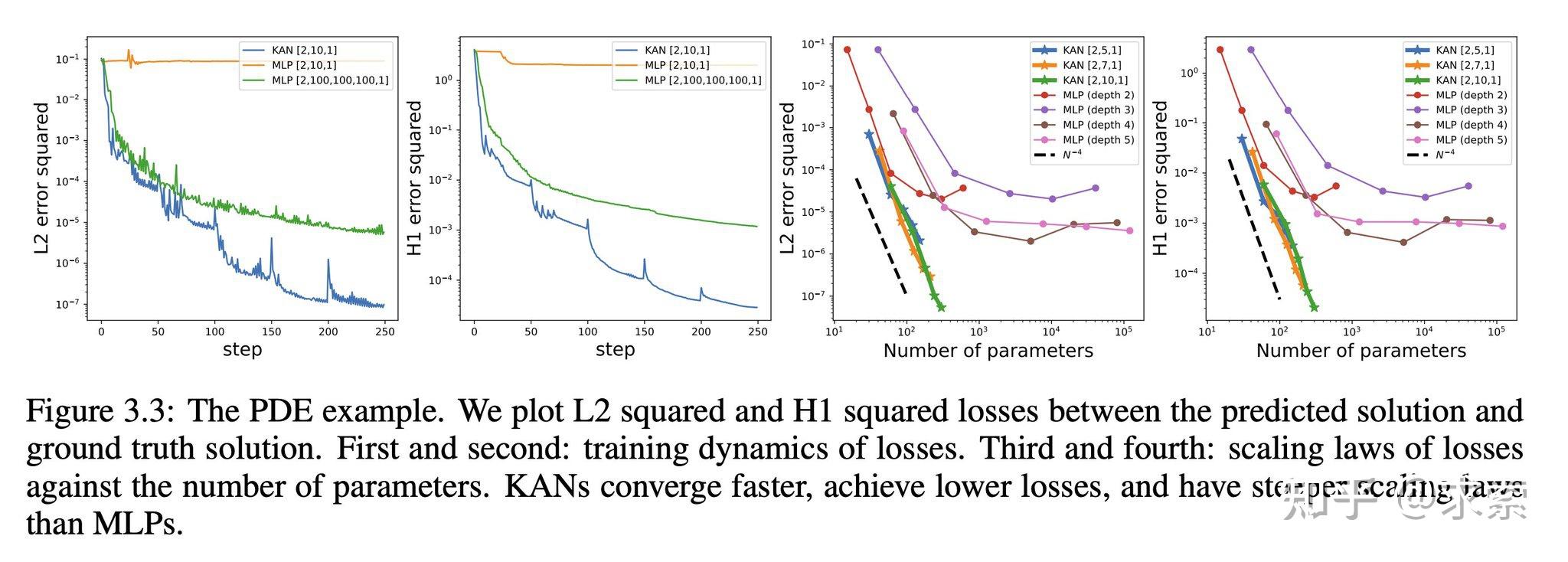
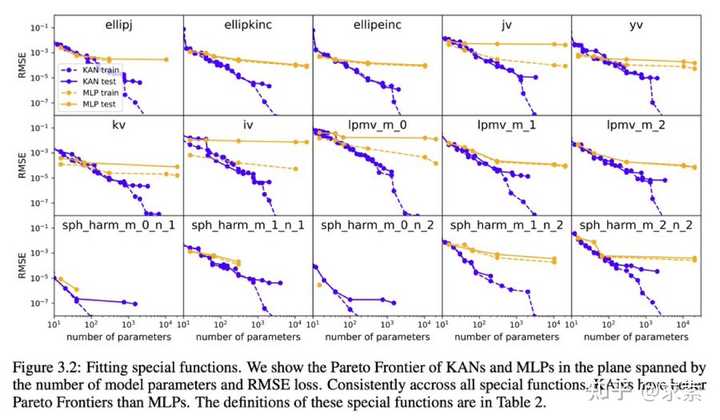
KANs在准确性上超越了MLPs,尤其是在数据拟合和PDE求解任务中,展示了更快的神经缩放法则。
KAN 的缩放速度比 MLP 快得多,这在数学上基于 Kolmogorov-Arnold 表示定理。KAN 的缩放指数也可通过经验获得。
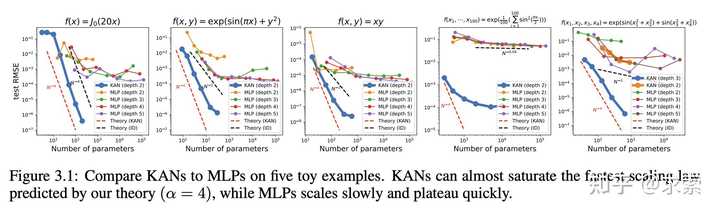

KAN 在函数拟合方面比 MLP 更准确,例如拟合特殊函数。

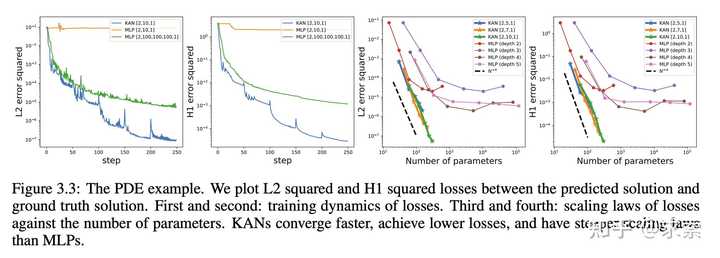
KAN在PDE求解任务上比MLP更快更准确,例如求解泊松方程。

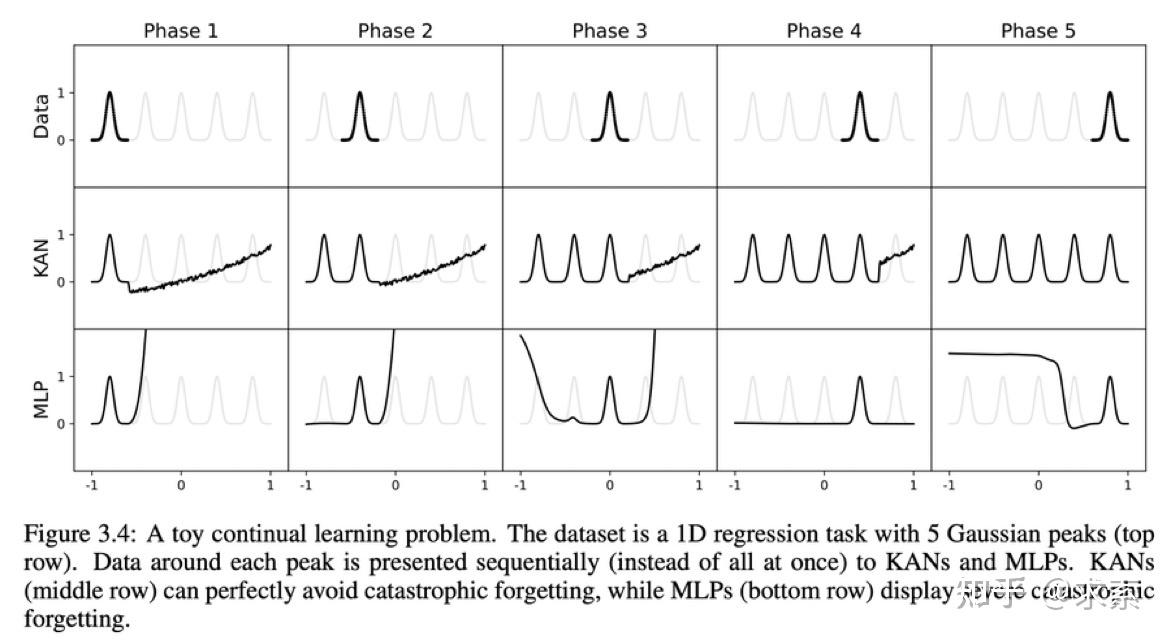
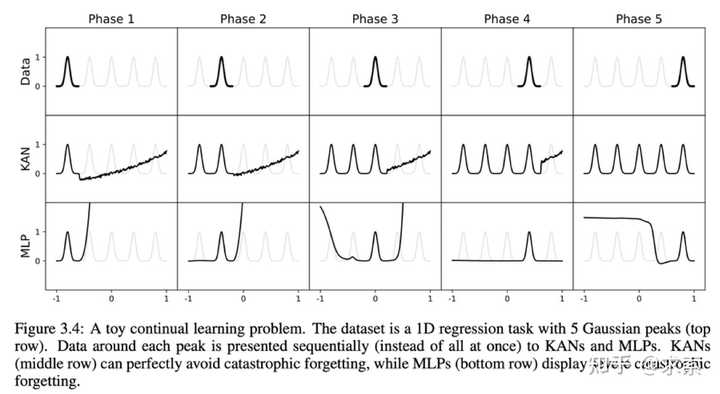
1另外,KAN 具有避免灾难性遗忘的天然能力。

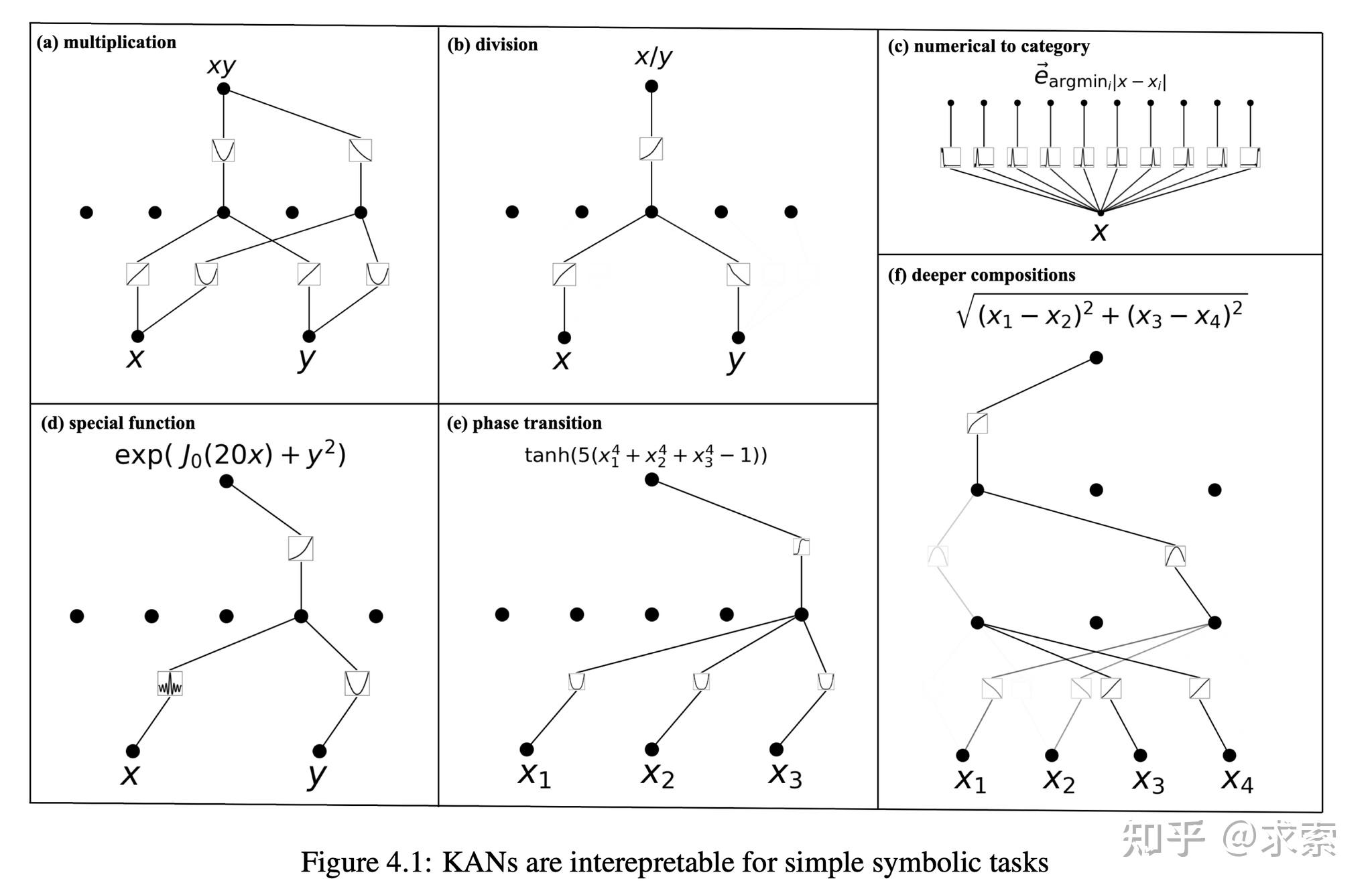
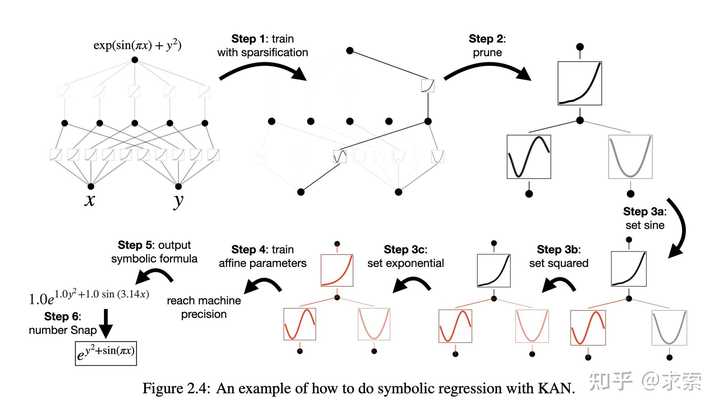
KANs提供了更好的可解释性,使得网络结构和激活函数可以直观地被理解和解释。KAN可以从符号公式中揭示合成数据集的组成结构和可变依赖性。
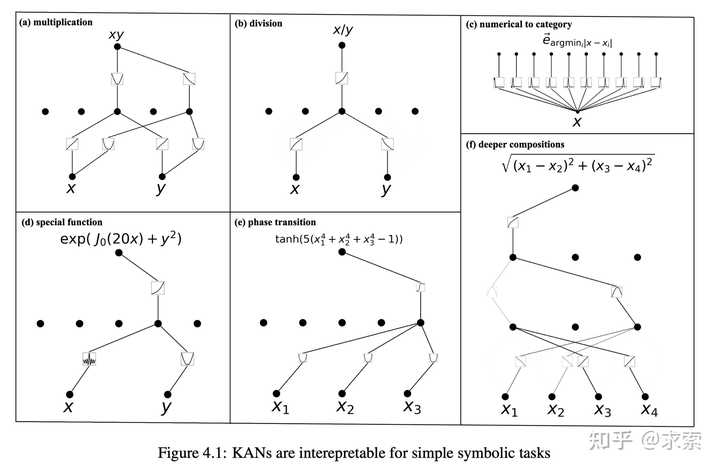

人类用户可以与 KAN 交互,使其更易于解释。将人类的归纳偏见或领域知识注入 KAN 很容易。

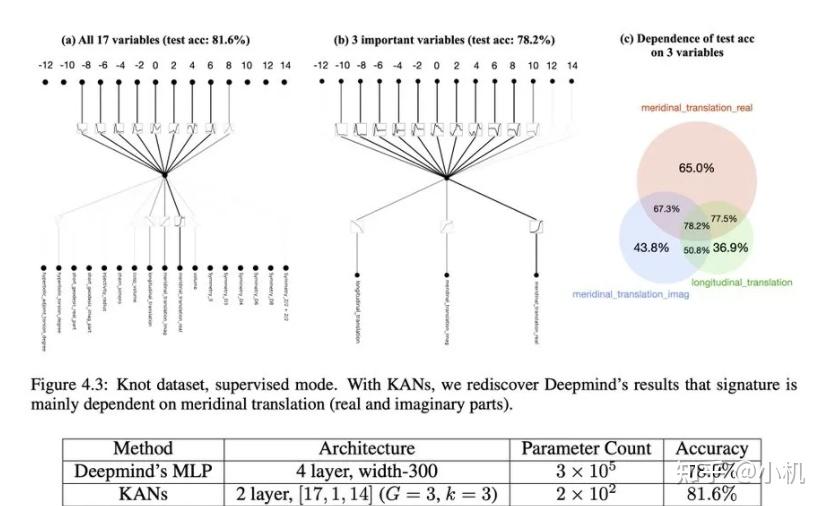
论文还探讨了KANs在科学发现中的潜力,KAN 也是科学家的得力助手或合作者。如在数学的结理论和物理的Anderson局域化中的应用。
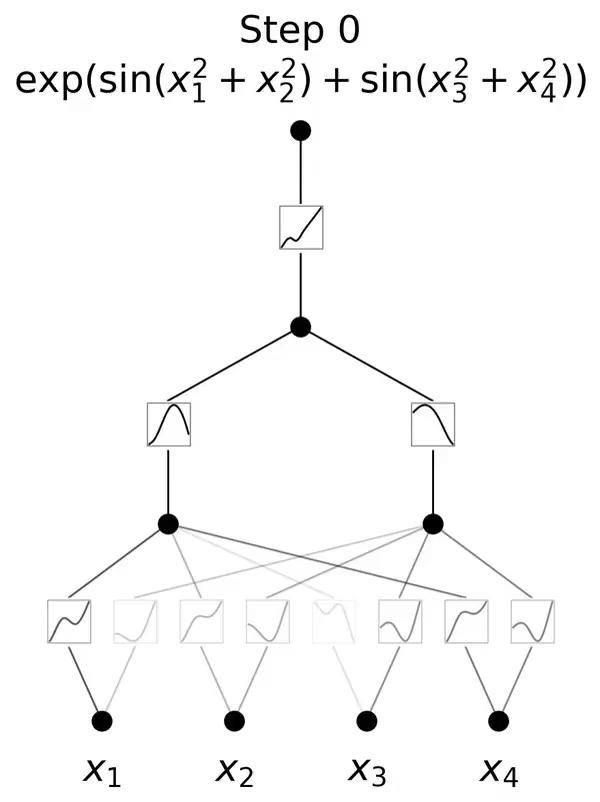
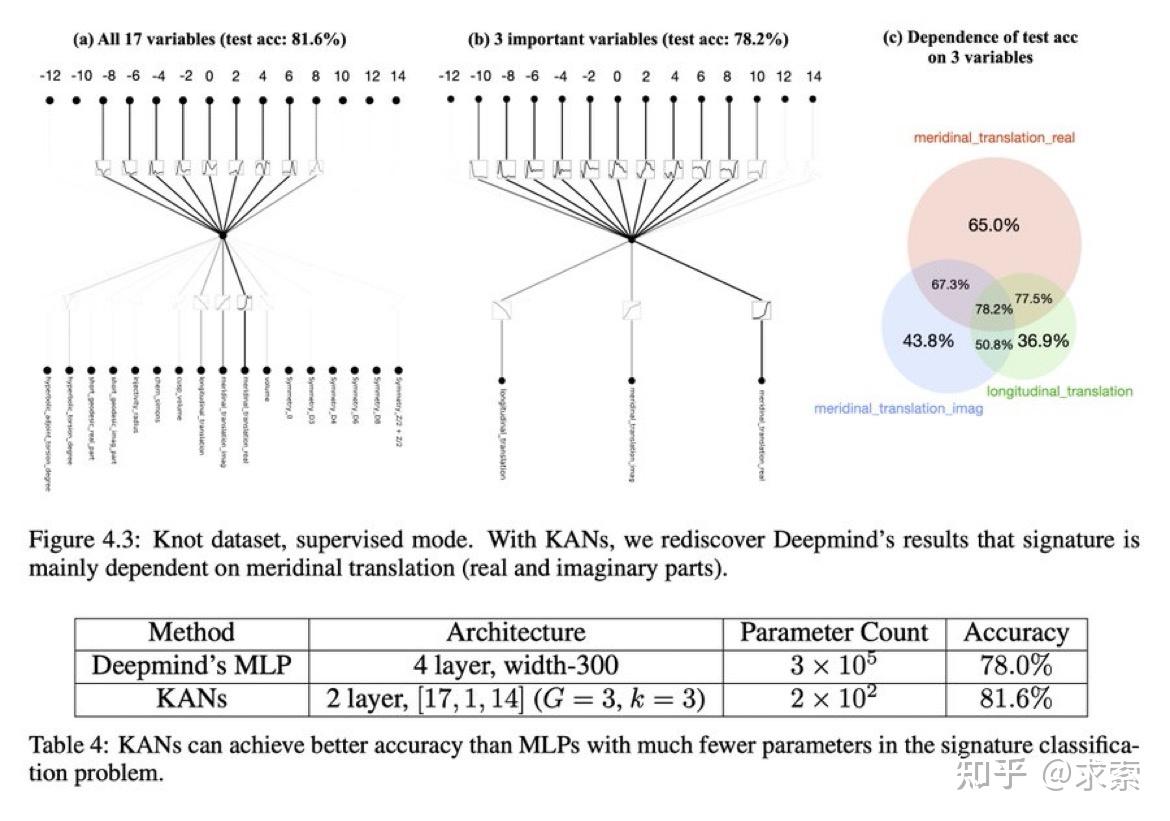
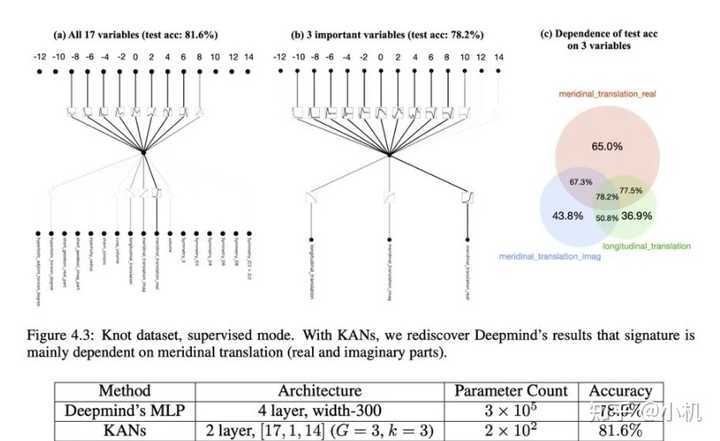
利用 KAN 重新发现了结理论中的数学定律。KAN 不仅以更小的网络和更高的自动化程度重现了GoogleDeepmind的结果,还发现了新的签名公式,并以无监督的方式发现了结不变量的新关系。
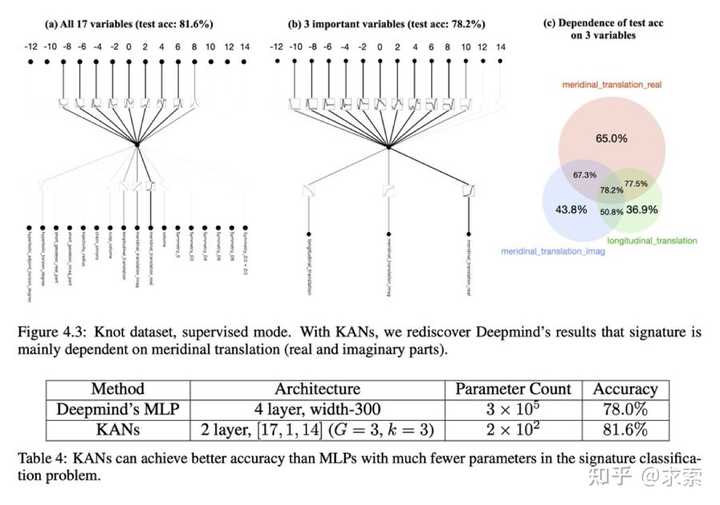

特别是,Deepmind的MLP有~300000个参数,而KAN只有~200个参数。KAN可以立即解释,而MLP需要特征归因作为后期分析。
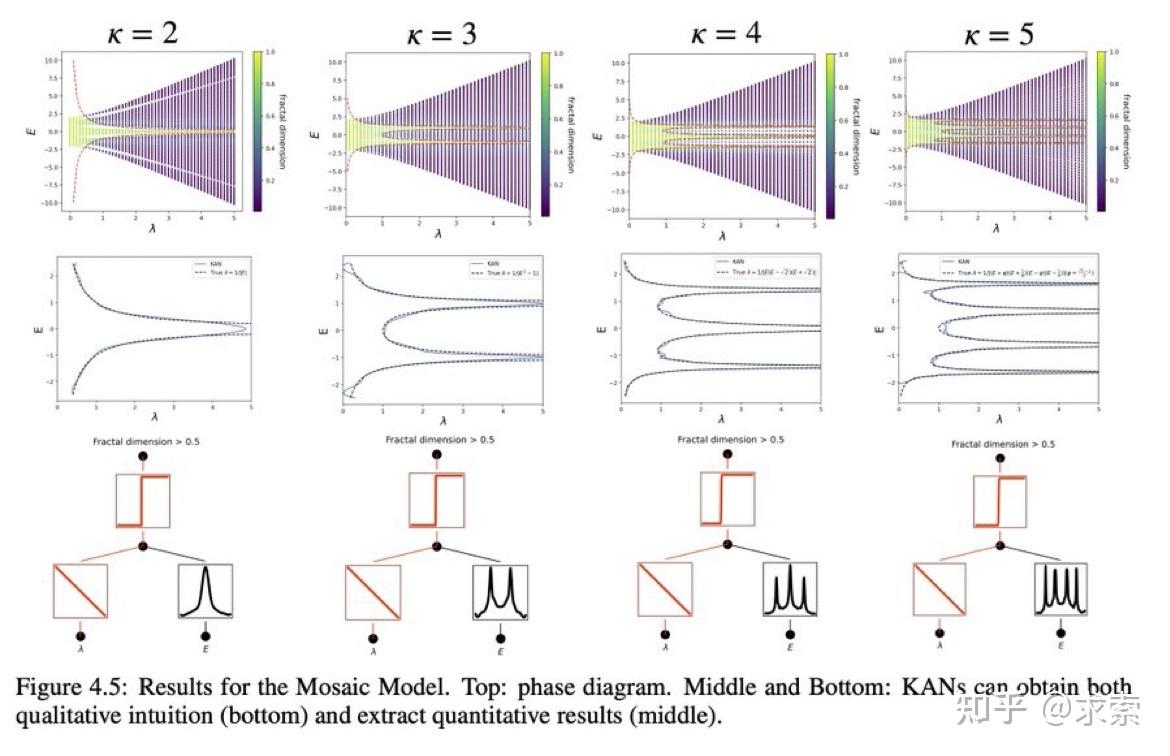
KAN 可以帮助研究 Anderson 局域化,这是凝聚态物理学中的一种相变。无论是从数值上,还是从物理上,KAN 都使迁移率边缘的提取变得非常简单。
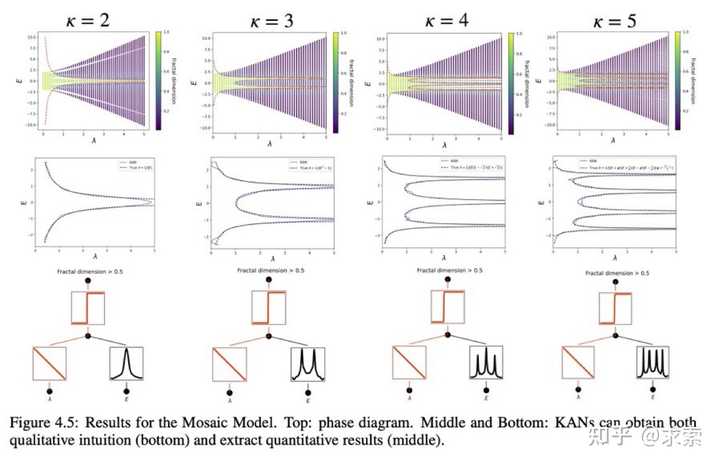

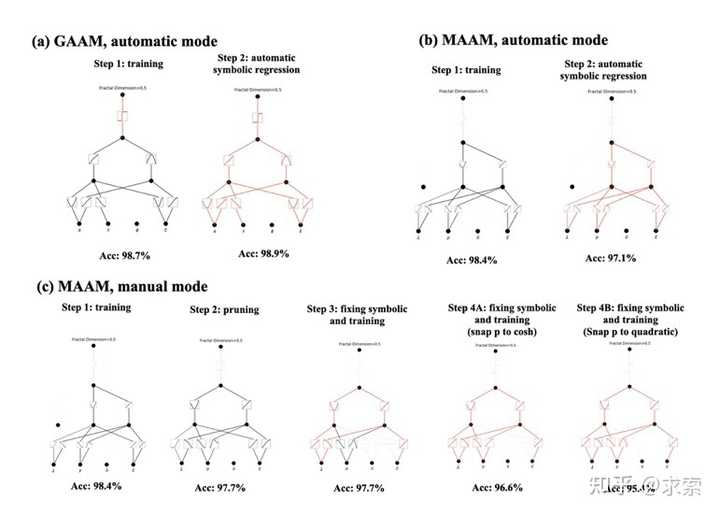



根据实证结果,KAN 将成为 AI + Science 的有用模型/工具,因为它具有准确性、参数效率和可解释性。KAN 对机器学习相关任务的实用性更具推测性,有待未来研究。

论文中的所有示例都可以在单个 CPU 上在不到 10 分钟的时间内重现(扫描超参数除外)。诚然,实验的问题规模比许多机器学习任务要小,但对于与科学相关的任务来说却是典型的。
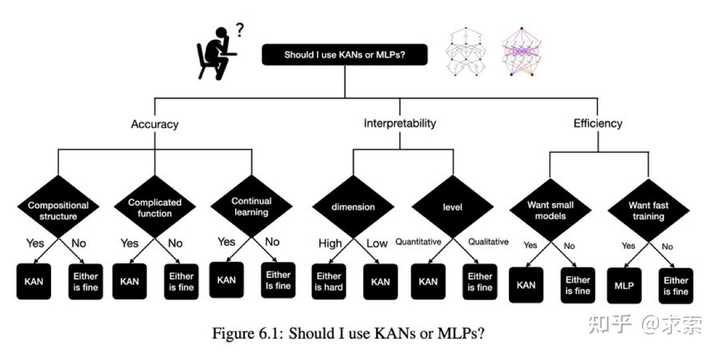
真的能替代MLP吗?
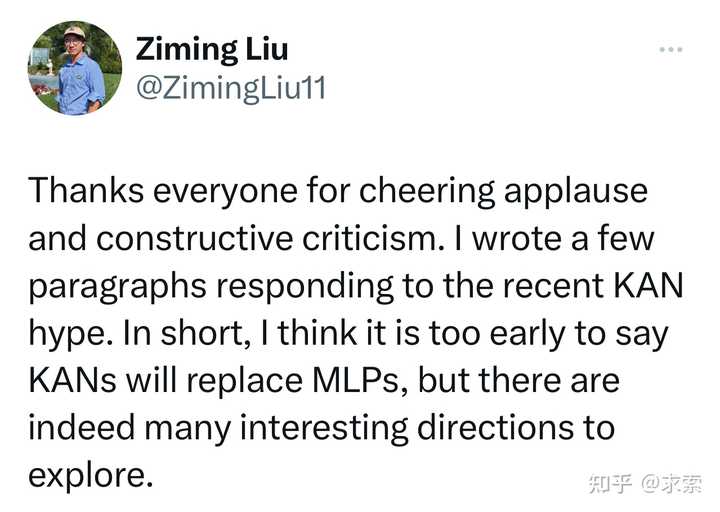
作者的回应:
感谢大家的欢呼和建设性批评。我写了几段文字来回应最近的 KAN 炒作。简而言之,我认为现在说KAN将取代MLP 还为时过早,但确实有很多有趣的方向值得探索。

为什么训练很慢?
原因 1:技术。可学习激活函数(样条函数)比固定激活函数的评估成本更高。
原因 2:个人原因。研究作者的物理学家性格会抑制程序员性格,所以没有尝试优化效率。
能适适配transformers吗?
研究作者不知道该怎么做,虽然一个简单的(但可能有效!)扩展只是用 KAN 取代 MLP。
paper:https://arxiv.org/abs/2404.19756
code:https://github.com/KindXiaoming/pykan
documentation:https://kindxiaoming.github.io/pykan/
发布于 2024-05-04 20:29・IP 属地福建查看全文>>
求索 - 4 个点赞 👍
查看全文>>
神头鬼脸 - 4 个点赞 👍
查看全文>>
过云雨 - 4 个点赞 👍
查看全文>>
知乎用户 - 3 个点赞 👍
将KAN scale up!
我们提出了Kolmogorov–Arnold Transformer (KAT),希望为Transformer带来一些新的尝试。传统的Transformer模型通常依赖多层感知机(MLP)层来混合通道间的信息,而我们这次尝试将Kolmogorov-Arnold Network (KAN) 层引入Transformer,看看能否带来新的提升。
在将KAN融入Transformer的过程中,我们遇到了三个主要挑战:
1️⃣ 基础函数(Base function):传统的B样条函数在现代硬件上的并行计算效率较低,影响了推理速度。
2️⃣ 参数与计算效率:KAN为每个输入输出对使用独立函数,导致计算量较大。
3️⃣ 权重初始化:由于KAN包含可学习的激活函数,如何有效初始化权重对模型的收敛至关重要。
✨ 为了解决这些问题,我们提出了以下解决方案:
1️⃣ 有理函数基础(Rational basis):我们用有理函数替代B样条函数,提升了与现代GPU的兼容性,并通过CUDA实现了
查看全文>>
Adam Yang - 2 个点赞 👍
kan算是一个很好的想法,可以与mlp互补
脱离基本结构谈参数量,本身没什么意义,与其谈参数量不如谈函数复杂度(function complexity),因为计算机里面本身就有时间和空间的权衡,拿时间换空间或者拿空间换时间,kan更像是前者
对可解释性问题,个人觉得kan并不一定比mlp好多少,实际上mlp里影响其基本逻辑的主要就是activation function,线性变换大同小异,当然attention中qk矩阵乘确实也影响了其函数逻辑,导致可解释性比较难,所以mlp固定的激活函数,如relu等piecewise linear function并不黑箱,比较好研究。而kan直接就是动态的激活函数,当数据很高维的时,其可解释性很难说。
mlp有他自身的缺陷,这种静态图结构,本身就有灾难性遗忘的缺陷,业界也在不断的优化,比如像MoE架构,GLU激活函数,或者gated linear network,NTM等。很显然每种任务的计算复杂度都是不一样的,动态图结构不仅仅能解决灾难性遗忘问题,也可以根据任务的难度权衡计算量,kan也是其中一个有意义的探索。动态图结构也不一定是由这种单一的模型构成,DAG这种有向图或者带个小环很难摆脱模型最大函数复杂度的限制
编辑于 2024-05-05 17:26・IP 属地四川查看全文>>
pinnacle - 2 个点赞 👍
目前来看,得出结论还为时过早。
MLP和KAN的主要区别在于其基础理论不相同,因此优化手段也不一样。KAN暂时还没有找到合适的高效优化手段,而如果想要大规模应用,就需要有人能证明KAN在实际应用中的效果。可是现在效率就制约了KAN的实用性。看来这是个鸡生蛋,蛋生鸡的问题,不知道谁愿意下场投入资源先吃螃蟹。
就论文展现出的结果看,甚至还达不到Mamba所表现出的前景效果,所以个人谨慎乐观看待。
发布于 2024-05-04 09:52・IP 属地江苏查看全文>>
知乎用户