
关于这个问题,在解答之前,我想我们需要明白MLP为什么这么受欢迎?
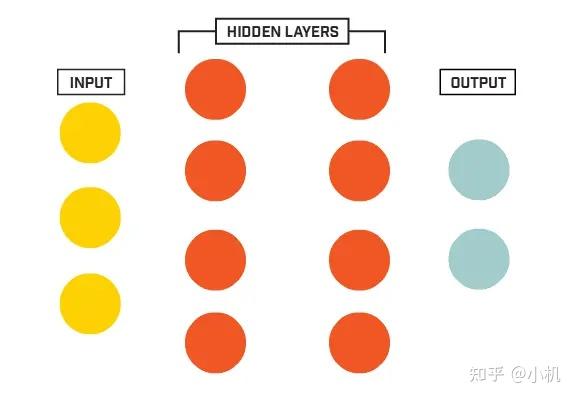
多层感知器(MLP)是一种前馈人工神经网络,它在神经网络的领域中有着广泛的应用。MLP的主要优点包括:
- 非线性激活函数:MLP使用非线性激活函数(如ReLU、Sigmoid、Tanh等),这使得它能够学习和模拟复杂的非线性关系和模式。
- 万能逼近定理:理论上,MLP可以逼近任何连续函数到任意精度,只要提供足够的隐藏层神经元和训练数据。
- 易于理解和实现:与更复杂的网络结构相比,MLP的结构相对简单,易于理解和实现。这使得它在教学中和初学者中非常受欢迎。
- 广泛的应用:MLP被广泛应用于各种机器学习任务,包括分类、回归、异常检测等。
- 可扩展性:可以通过增加隐藏层的数量和神经元的数量来增加模型的复杂度,以适应更复杂的任务。
- 并行处理能力:MLP可以通过在GPU上进行训练来利用并行处理能力,这使得训练大规模网络成为可能。
- 成熟和广泛的研究:由于MLP在神经网络的历史中占有重要地位,因此它有着成熟和广泛的研究基础,许多优化和改进技术都是针对MLP开发的。
说完MLP的优点,我们再来看看他的局限性:
- 容易过拟合:过拟合是指模型在训练数据上表现良好,但在新的、未见过的数据上表现不佳。这种情况通常发生在模型过于复杂,拥有大量参数时,导致模型“记住”了训练数据中的噪声和细节,而未能捕捉到数据的真实分布。解决过拟合的方法包括使用正则化技术(如L1或L2正则化)、减少模型复杂性、采用数据增强或集成学习等。
- 训练速度可能较慢:模型的训练速度受多种因素影响,包括模型的复杂性、数据集的大小、硬件性能等。一个复杂的模型,如深度神经网络,通常需要较长的训练时间。此外,大规模的数据集也会增加训练时间。为了提高训练速度,可以采用优化算法(如Adam、RMSprop)、使用更高效的硬件(如GPU)、进行批量归一化、使用预训练模型等技术。
- 对特征缩放敏感:特征缩放是指将数据集中的特征转换到相似的尺度。某些算法(如梯度下降)对特征缩放非常敏感,因为如果特征尺度差异很大,模型可能会在迭代过程中产生不必要的震荡,导致收敛速度慢甚至无法收敛。常用的特征缩放方法包括标准化(将特征缩放到均值为0,标准差为1)和归一化(将特征缩放到特定范围,如0-1)。正确的特征缩放可以显著提高模型的性能和训练速度。
简单介绍完MLP,我们再来看看KAN。
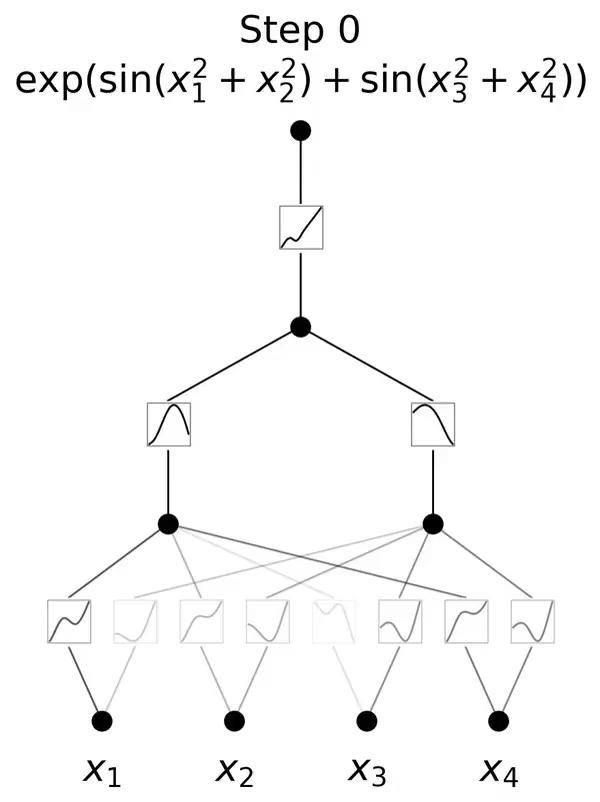
KAN的灵感来源于数学中的Kolmogorov-Arnold表示定理。这一定理在数学界具有深远的影响,它揭示了函数表示与神经网络之间的深刻联系。
KAN通过将这一理论应用于神经网络设计,实现了对传统MLP架构的突破。
与传统的MLP相比,KAN的一个主要不同点在于其对激活函数的处理。
在MLP中,激活函数是作用于每个神经元上的,而在KAN中,激活函数被转移到了权重上。这意味着在KAN中,权重本身是可学习的,而不仅仅是传递信号的媒介。
这种设计使得KAN在处理复杂函数时表现出更高的灵活性和效率。
其架构设计使其在函数逼近能力上具有显著优势。
由于权重本身可以学习激活函数的特性,KAN能够更有效地逼近复杂的非线性函数,这对于处理现实世界中的复杂问题至关重要。
在训练效率方面,KAN也展现出其优越性。
由于其权重的可学习性,KAN在训练过程中可以更快地收敛,减少了所需的迭代次数,从而提高了训练效率。
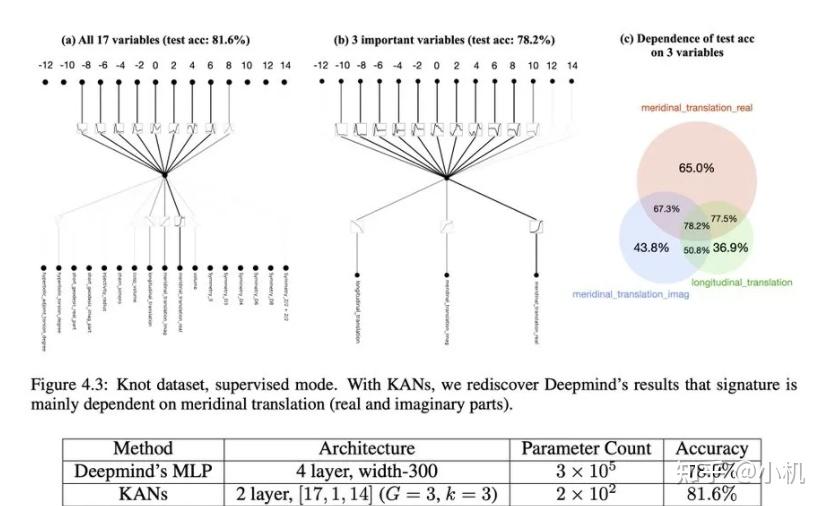
KAN的另一个亮点是其强大的泛化能力。
在处理未见过的数据时,KAN能够更好地保持其性能,这在实际应用中尤为重要。
KAN神经网络架构以其独特的创新点和优异的性能,确实具有挑战MLP地位的潜力。
然而,是否能够完全取代MLP,我只能说,时间会说明一切。
发布于 2024-05-06 12:46・IP 属地四川