
看到这个这么火,忍不住也来试了一下,Google colab自带的mnist数据集测试,
KAN设计对比MLP,优化器什么的都一样,adam默认值,学习率0.0001
#KAN
inputdim = 784
hidden = 128
outdim = 10
gridsize = 3
device = "cuda:0"#"cpu" #"cuda"
fkan1 = NaiveFourierKANLayer(inputdim, hidden, gridsize).to(device)
fkan2 = NaiveFourierKANLayer(hidden, outdim, gridsize).to(device)
#MLP
self.ly1=nn.Sequential(
nn.Linear(784,128),
nn.GELU(),
nn.Linear(128,10),
)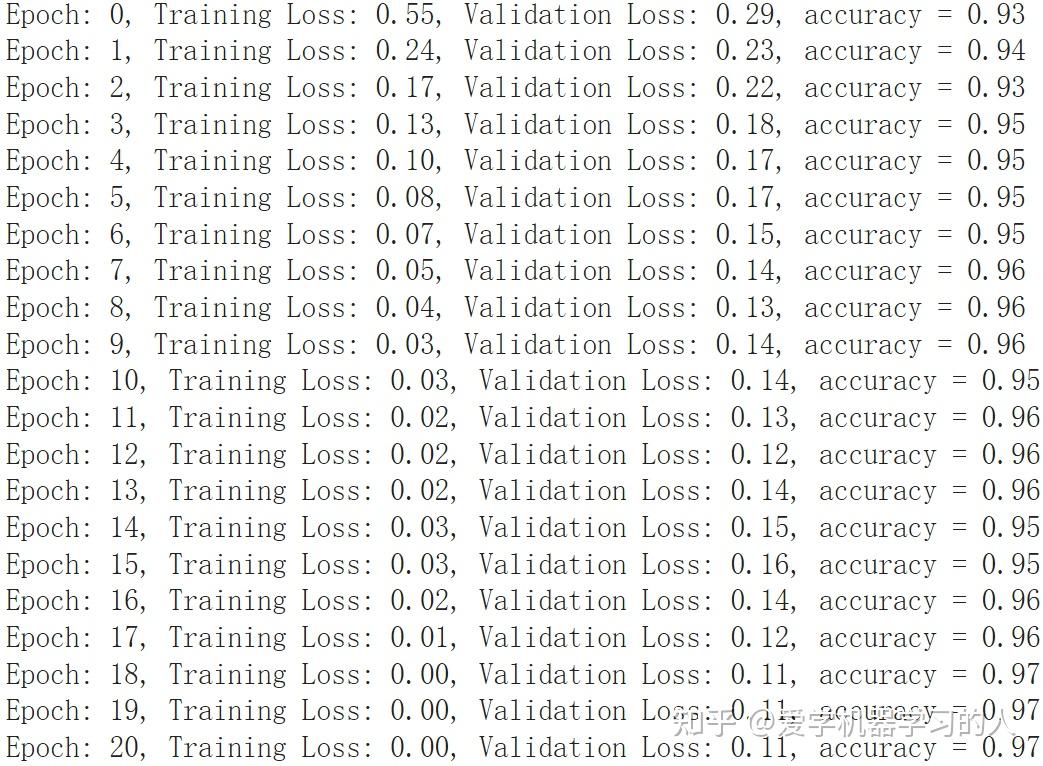
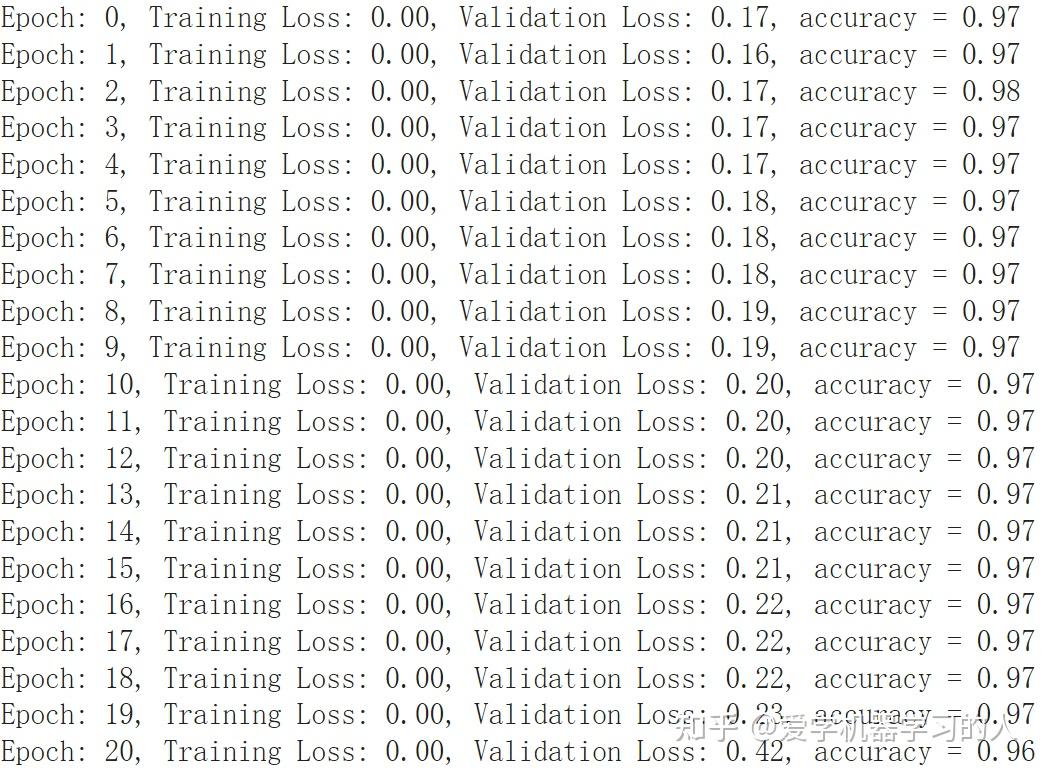
MLP收敛速度快,训练速度也快,最终准确率差不多。
有朋友提到MLP过拟合严重,验证损失一直在上升,我想说这看怎么来理解这件事情了,这只是一个非常简单的数据集,可以看出就算是最简单的MLP表示能力也比kan强,不然也没法太过拟合,在复杂数据集上表示能力强是好事情。一个优秀的模型应该是表示能力超强,这样的话在简单数据集上在没有任何防止过拟合手段的情况下过拟合肯定会相当严重。
编辑于 2024-05-07 13:42・IP 属地江苏