如何评价英伟达2024 GTC大会发布的Blackwell架构GPU和DGX GB200服务器?
Nvidia DGX GB200的推理性能相比H100提升45倍,可以处理万亿级参数大模型,DGX GB200使用第五代NVLink,BlueField3。老黄...

- 1 个点赞 👍被审核的答案
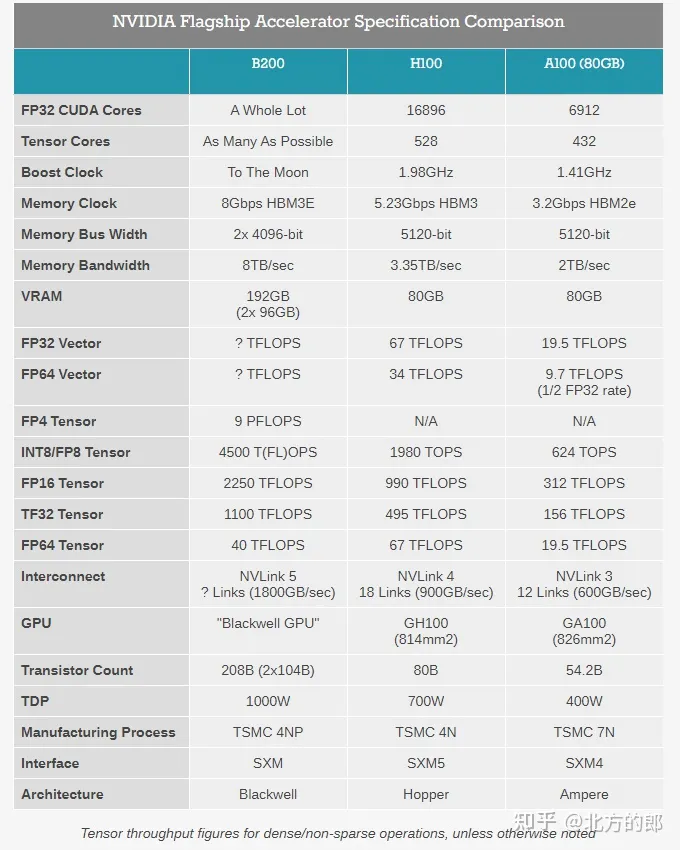
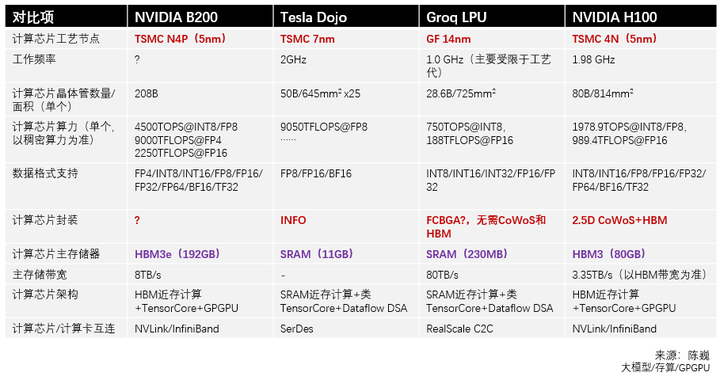
B200的主要进步,包括
1)使用先进封装,把两块GPGPU整合。这方案在Apple的芯片上已经采用很多年了。
2)使用FP4,提升算力密度。这个方法难度也不高,不过目前全世界使用FP4的还很少。
感觉B200的创新有点乏力了

发布于 2024-03-19 12:58・IP 属地广东查看全文>>
陈巍 - 20 个点赞 👍
结论
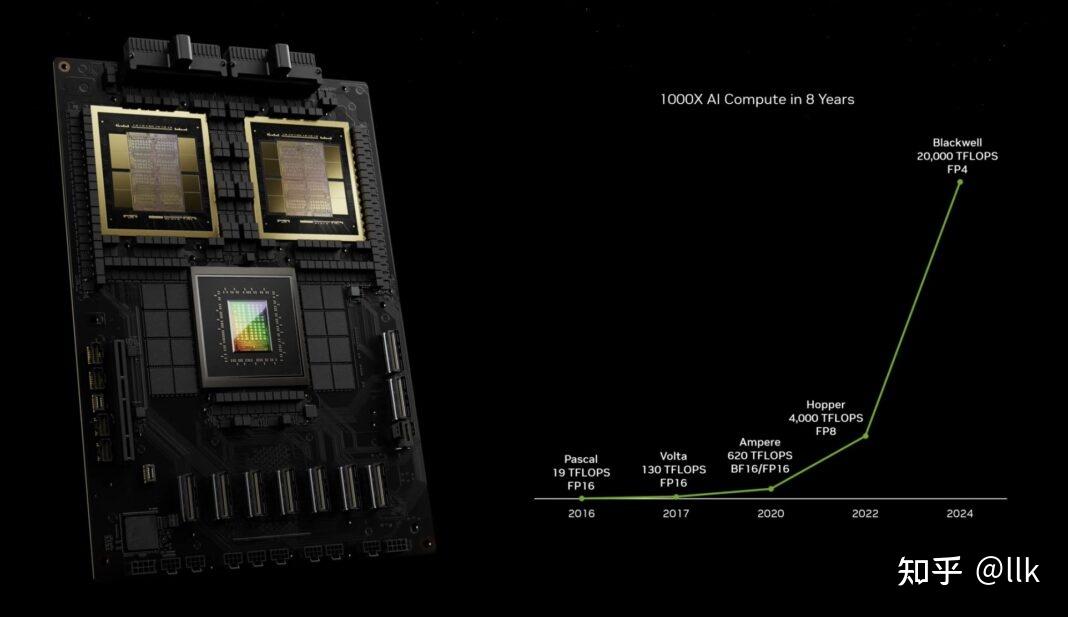
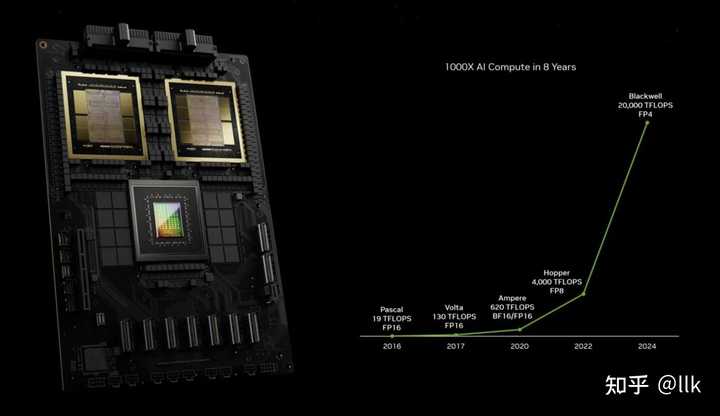
今年发布的Blackwell明白无误的告诉大家摩尔定律不在神奇了,之前NVIDIA的可扩展的GPU架构搭配摩尔定律可谓摧枯拉朽,让大家难以望其项背;而现在NVIDIA发布会对于芯片本身特性基本一笔带过,而重点都在DGX系统上,也就是芯片内部依靠摩尔定律扩展基本到头,后面扩展主要靠芯片间互联来完成了。另一个就是这种算力的提升并没有宣传中那么夸张,像NVIDIA展示的8年里AI算力提升了1000X,主要靠的是数据精度,从最开始高性能计算的FP64,FP32,FP16,到FP8,FP4。

而对于芯片间互联,分成两类:
- 一类是D2D,也就是通过interposer实现die之间互联,这种一般是高速并行接口,可以提供TB级别的带宽,主流技术有TSMC的CoWoS,Intel的EMIB等,今天发布的Blackwell就是采用D2D将两颗die互联封装,可以提供10TB/s的带宽。


- 另一类就是NVLink为代表的芯片间互联,业界推出的就是UCIe标准。Blackwell已经演进到第五代了,搭配NVLink Switch芯片,可以提供7.2TB/s总带宽,支持GPU进行纵向扩展。


当然,还有一类是采用Infiniband和Ethernet进行横向扩展,这些一起组成了NVIDIA的DGX系统。
总而言之,现在对于NVIDIA的竞争者,工艺不再是问题,比拼的重点在互联,不管是die内互联,还是片间互联,甚至网络互连,如何组成更高带宽的系统才是关键。
发布于 2024-03-19 09:17・IP 属地上海查看全文>>
llk - 20 个点赞 👍
Nvidia的Blackwell GPU有点意外也有点没意外,性能基本和晶体管规模正比,这回确实堆料了,意外的是FP4 居然被拿出来算了,4bit的浮点就只能表示一点点数值啊..


用了2.6X晶体管,但是FP32提升很少。 可以说已经是纯纯的NPU了.. 晶体管都给了Tensor Core….
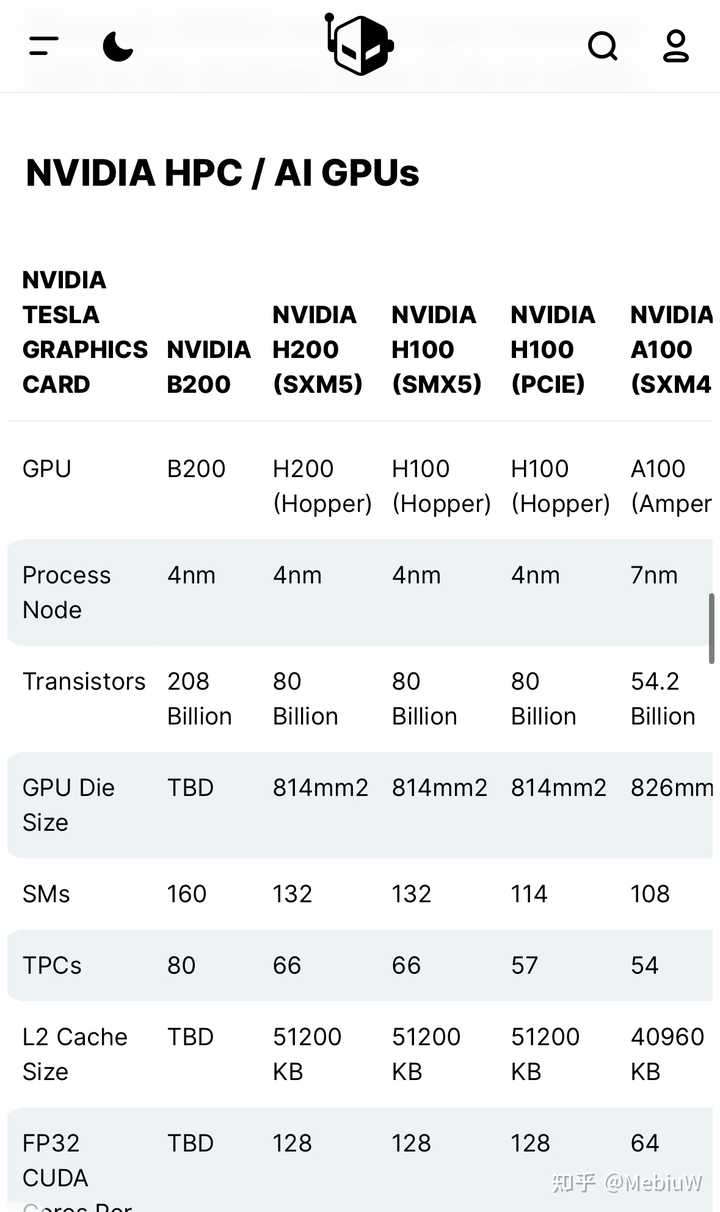

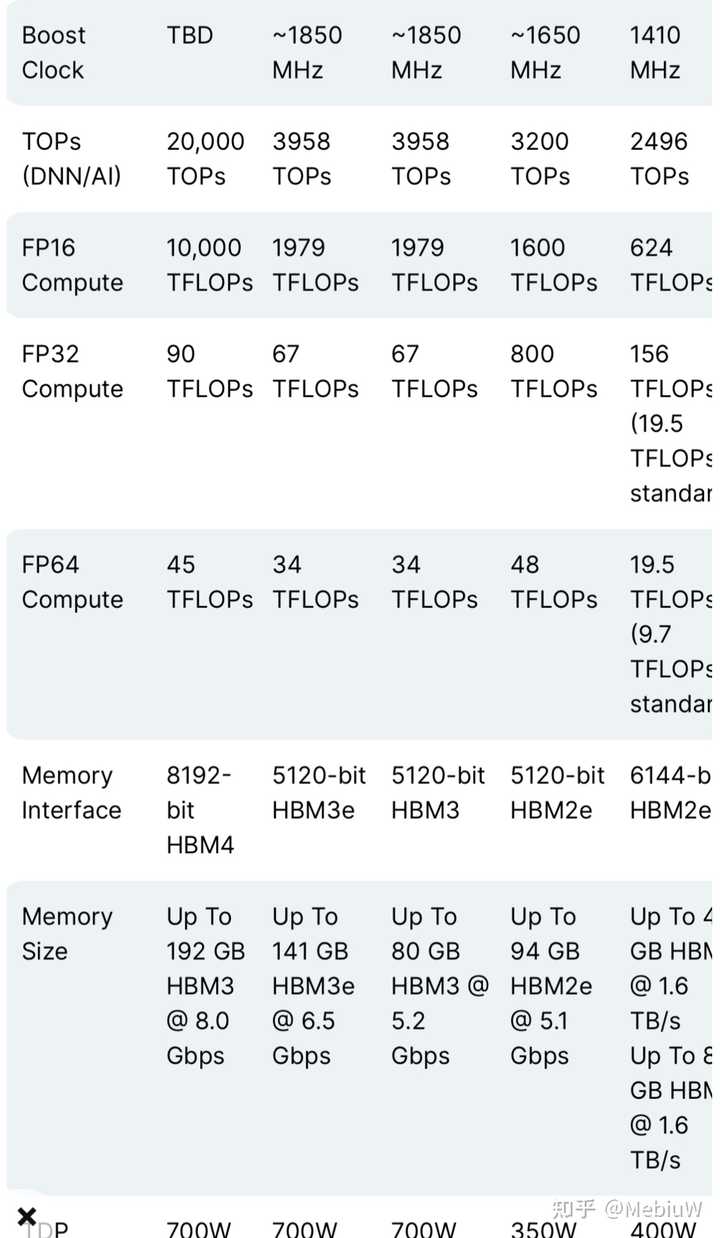

另外也是高级胶水的Chiplets了,因为工艺没明显改进还是台积电的N4P(一个节点),所以售价可能也是3倍往上了?

 发布于 2024-03-19 10:14・IP 属地云南
发布于 2024-03-19 10:14・IP 属地云南查看全文>>
MebiuW - 10 个点赞 👍


$NVDA在这届位于San Jose SAP Center的GTC会议上,发布了几款更大规格的硬件、更激进的DSA化计算范式,以及更大规模的软件栈,甚至发布了几十项AIGC应用。尤其核心的是Blackwell硬件,分别从芯片、Interconnect C2C/in Rack/R2R、DGX整机、集群Pod和多层组网拓扑等方面俯视性展示了黄氏全家桶的排场。
如下总结并评论一下GTC 2024的发布内容和硬件基本的SPEC:
关于制造和封装工艺 :
首先是Blackwell硬件,值得一提的是:B100型号似乎被跳过了,发布首个GPU型号即B200;
MCM双片合封的晶体管密度为2080亿(2*104B);晶圆制造的工艺节点选用TSMC N4P 5nm(H100所用N4节点的高性能改良);TSMC官方称N4P节点相比N5可提升11%的微电性能,或提升22%的能效、6%的晶体管密度,以及对比N4可提升6.6%的微电性能;且由于N4P会多次重用reticle而反而让工艺复杂度降低了(官方并未披露单卡B200的TDP数据,但提供了两种规格的机架,即针对风冷DGX和液冷NVL72)。
虽然NV并未披露单芯片的die size,但参考H100 814mm2的规格可以想象Blackwell必然是一颗reticle-sized产物,single-die-size同样接近reticle边缘尺寸,这是N4P 5nm节点的掩膜版极限。由dual GPU die通过10TB/s高速接口桥接并合封而成的单一GPU板卡;算是Chiplets标准的一种类型,近似于AppleSilicon UltraFusion的桥接合封,单卡AI性能达到20PetaFLOPS(相比H100提升4倍);更值得关注的是两颗GPU die之间的I/O,可提供10TB/s的高带宽(单向5TB/s),这也是整个集群系统中速率最高的interlink。另外GB200机内提供GPU <-> Grace CPU双向900GB/s带宽(相比PCIe 64GB/s高很多)。
NV官方对于die2die 10TB/s双向带宽命名为NV-HBI接口(NV-High Bandwidth Interface),其带宽能力已经远高于以AMD MI300为首的Chiplets常规互连带宽,HBI桥接链路及接口将会高度依赖于先进封装,需要更多的布线和引脚,尚不清楚是TSMC哪一类工艺,也许是定制的CoWoS-xxx吧 ...


NV可以告诉Gordon Moore如何定义“T管密度 : 性能”,即改变训推范式,把更大的面积留给FP8/FP4... 关于超算整机的配置 :
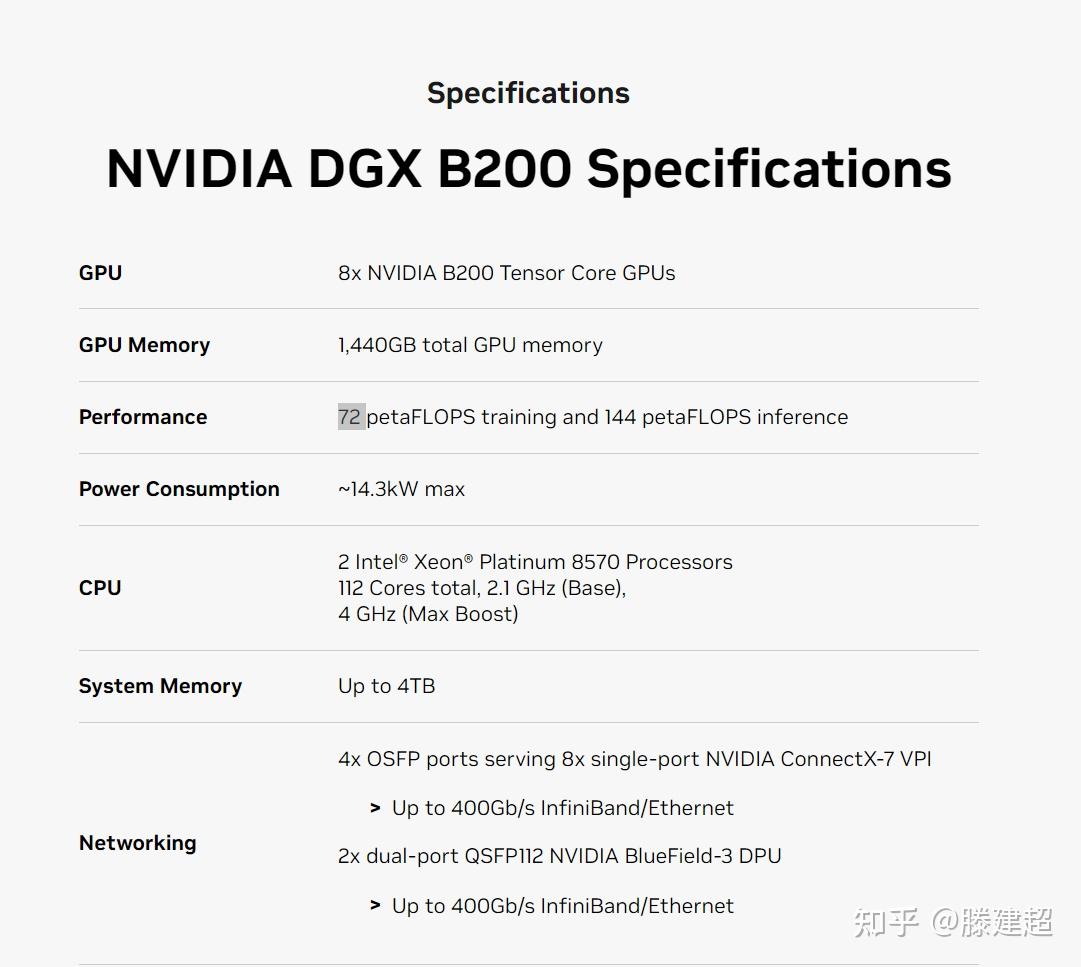
GB200 NVL72核弹机型,即单机整合了18组B200(共计36CPUs+72GPUs)为更大规格的主机节点(推测单节点即填满Single Rack),单节点即可实现E级算力(FP8格式测算);
其中FP8精度的训练算力为720PFlops(单个DGX H100 SuperPod为1000P);以及该节点支持1.4EFlops的AI推理算力和30TB,存,最高支持27000B参数规模(27万亿)的模型(约16个GPT4 MoE 1.8T)。相比72个H100,GB200 NVL72对于模型推理性能提升约30倍,成本和能耗降低约25倍。而最大扩展形态的DGX GB200 SuperPod标准配置可在FP4精度下提供11.5 ExaFlops算力和240TB内存,此外还支持增加"额外的"机架扩展性能。
关于HBM内存的配置 :
搭配2*4片HBM3E内存,192GB容量(dual GPUs*96GB,即24GB/颗粒,同H200的HBM颗粒规格,而H100搭配的HBM3为16GB/颗粒),内存带宽8TB/s,内存总线位宽为2*4096bit,内存时钟速率8Gbps;HBM整体规格比H100多出50%。
$NVDA官方称:B200搭配HBM内存总带宽为8TB/秒,每堆栈带宽1TB/秒,即每个引脚的数据速率为8Gbps-9.2Gbps,几乎是H100内存带宽的2.4 倍(或比H200高出66%)。
关于机内和多机网络互连 :
发布NVLink v5,网卡和交换芯片同样是在TSMC N4P节点制造,晶体管密度为50B,可在GPUs in rack之间提供1.8TB/s双向吞吐,保证了576个GPU之间的高速通信,同时还支持3.6TFlops的网络内计算,即SHARP v4(Scalable Hierarchical Aggregation and Reduction Protocol)用于将集合操作从CPU尽可能转移到网络设备,以便减少和消除在端点之间多次发送数据的需要,进而提高MPI和ML集合操作的性能。显然,这一代NVLink是为MoE结构的大模型解决通讯瓶颈,比如MoE模型之间的数据传输/同步/Ensemble需要占用极大带宽资源。
搭配交换设备为Quantum-X800 InfiniBand和Spectrum™-X800 Ethernet(搭配ConnectX-8 SuperNIC),组网速率为800Gb/s,其中X800相比前代的带宽容量提高5倍。GB200 NVL72还包括NVIDIA BlueField-3数据处理单元,可在超大规模人工智能云中实现云网络加速、可组合存储、零信任安全和GPU计算弹性。
$NVDA官方称:此前仅由16个GPU组成的集群会在相互通信上花费60%时间,而仅有40%时间用于实际计算。现在NVLink v5可以让更多的芯片在机内互连,减少R2R通信的带宽切分,全速运转1.8TB/s,几乎比上代快10倍,并由此构建DGX GB200 NVL72。
同时,新的DGX超算主机内置布线有5000条NVLink铜电缆(总长近2英里),极大减少了光收发端子和光缆开销,节省了20kW的计算成本。计算单元和其它附加配置 :
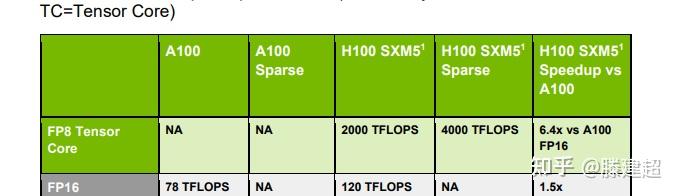
支持Transformer V2,允许动态启用FP8/FP6/FP4精度支持;支持FP4(tensor)低精度格式的推理,并提供9PFlops算力;Btw FP8算力达到了4500TFlops。NV声明的B200推理性能相比前代H100提升约30倍,而能耗却降低约25倍;在标准的175B参数GPT-3基准测试中,GB200表现性能是H100的7倍,训练算力是H100的4倍;
注意B200的FP32单元数量提升不多,FP16单元虽然大幅提升,但是官方主推FP8甚至搭配FP4,或许再远的未来也将告别常用的16bit精度的统治了;而从FP16开始都是tensor core的设计面积,未来GPU 90%的计算单元面积都给到NPU/DSA范式了,NN模型都要去FP8/FP4(tensor)上面收敛了 ......
- 集成RAS Engine和所谓的AI预防性维护功能,确保大集群部署系统的长期鲁棒性。
- 集成SecureAI功能,支持TEE和数据加密计算,适用于医疗、金融等敏感行业。
- 集成800GB/s的专用解压缩引擎,加速数据库查询。
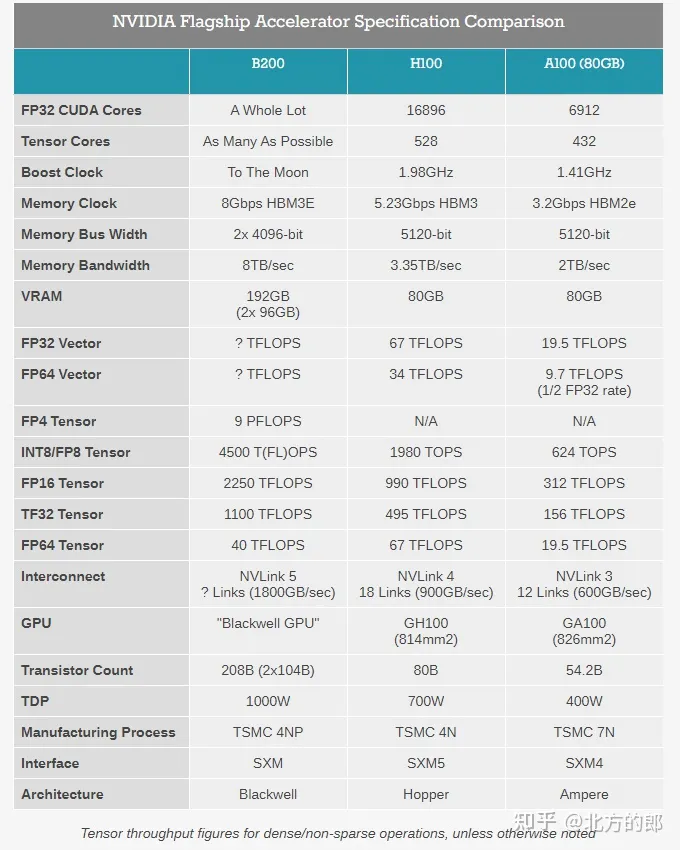

SPECs;Blackwell单卡AI性能达到20PetaFLOPS(相比H100提升4倍) 关于延伸至应用侧的CUDA疆域 :
$NVDA官宣的http://ai.nvidia.com主页“要做世界AI的入口”,这是多么可怕的宣言。
这个页面后台关联了NV企业级云服务,其用户界面可以直接搭建和使用各种AI模型及应用。第三方企业可以使用这些services创建和部署自定义应用,并且不会有CSP那样强规则的云管限制。该主页的应用都由NV自己的AI推理微服务NIM提供支持,可以针对NV及其Cloud Partners的数十个AI模型进行优化和推理,这些Partners包括AMZN/DIS/Samsung等厂商,这算是CUDA霸权的延伸。而且定价十分直观,1GPU/1h/$,或年付打五折,一个GPU一年4500美元。
更主要的是:NV自己提供的这些开发套件、库和工具链都可以作为CUDA-X微服务访问,比如用于RAG、Fence、数据处理、HPC等等日常工程,这些微服务可以用来构建基于LLM和向量数据库的生成式应用(包括Agent形态的所谓智能体应用)。
Postscripts :
资本数据:大模型这波趋势,全球Y23-Y24Q1在AI Capex上面投入给Nvidia的钱约有$160B。
并无太多可总结的,本次 GTC 公布了最完整的AIGC-Infra全家桶,单独讨论B200的硬件规格已经不再重要;总之而言,AMD CDNA凉了,INTC Gaudi凉了,Groq这类独辟蹊径的DSA凉了。
另外,NV-GTC在介绍GB200 NVL72的时候,貌似如下这张slide不慎透露了GPT-4的参数规模1800B?莫非是印证了220B*8的传言?
或是印证了111B*16+55B的传言:即每个MoE专家模型参数规模约为111B,每个前向计算中,其中两个专家模型被路由到进行计算;其中约使用了550亿个共享参数的Attention模型;推理成本为每生成一个token需要用到111B*2+55B≈280B的参数量,浮点运算量约为560TFlops,相比于非MoE结构的稠密模型降低了极大成本(后者生成每个token需要用到1.8万亿参数,浮点运算量为3700TFlops)。

貌似这张slide透露了GPT-4的参数规模1800B,莫非印证了220B x 8的那个传言?或是印证了111B*16+55B的传言? 编辑于 2024-03-19 23:41・IP 属地北京查看全文>>
Morris.Zhang - 6 个点赞 👍
英伟达在GTC 2024会议上展示了其新一代Blackwell架构GPU及一系列AI芯片和软件应用的创新成果,不仅凸显了公司在算力芯片、服务器和AI软件层面的卓越进展,也为投资者描绘了一个充满机遇的未来蓝图。
在GPU领域,英伟达推出的Blackwell架构堪称一项技术革新。特别是其中的B200芯片,这款拥有2080亿个晶体管的强大芯片,采用台积电定制的4NP工艺制造,将两个GPU die通过高达10 TB/秒的芯片到芯片链路连接成一个统一的GPU,这无疑是业内的一次重要突破。而其内置的第二代Transformer引擎,凭借扩展支持和先进算法,支持了更高效的4位浮点AI推理功能,使得计算和模型规模得到了双倍的提升。
此外,Blackwell架构还带来了第五代NVLink技术的革新。每个GPU的双向吞吐量达到了突破性的1.8TB/s,这一性能提升为处理复杂的大语言模型提供了无缝的高速通信能力。不仅如此,Blackwell架构还引入了专用的RAS引擎,实现了可靠性、可用性和可服务性的提升,使得大规模AI部署能够连续运行数周甚至数月,显著降低了运营成本。同时,通过先进的机密计算功能,Blackwell架构还在保护AI模型和客户数据方面展现了出色的安全性能。
在硬件层面,英伟达不仅推出了B200芯片,还进一步研发了GB200 Grace Blackwell超级芯片。这款超级芯片由两个B200芯片和一个Grace CPU组合而成,其大语言模型性能提升了惊人的30倍,而能耗仅为原来的二十五分之一。这一成果无疑将推动AI计算进入一个新的里程碑。
除了芯片,英伟达还发布了一系列与之配套的新硬件产品,包括第五代新NVLink芯片、GB200 NVL72服务器、X800系列网络交换机以及下一代人工智能超级计算机NVIDIA DGX SuperPOD等。这些产品的推出,进一步巩固了英伟达在高性能计算领域的领导地位,也为企业提供了更多选择和可能。
在软件层面,英伟达同样展现出了强大的创新实力。英伟达AI Enterprise 5.0推出了一系列微服务,其中的NIM微服务旨在简化企业将AI模型部署到生产环境中的过程。通过打包算法、系统和运行优化,并添加行业标准的API,NIM微服务极大地简化了AI模型部署的复杂性,使得开发人员能够更轻松地将AI技术集成到现有的应用程序和基础设施中。
同时,英伟达还进一步扩展了其在数字孪生和视觉处理方面的技术实力。Omniverse云的更新使得开发者能够将工业场景从内容创作应用程序发送到Graphics Delivery Network(GDN),从而实现3D体验的流式传输到Apple Vision Pro。这一技术结合为空间计算体验带来了前所未有的提升,为企业和用户提供了更丰富、更沉浸式的视觉交互体验。
在跨领域合作方面,英伟达也展现出了积极的姿态。公司与台积电、Synopsys等半导体领域的领军企业展开合作,推动技术创新和产业升级。此外,英伟达还在电信、交通运输和机器人等领域展开了一系列合作,旨在推动这些行业的智能化和数字化转型。总的来说,英伟达在GTC 2024会议上的展示充分展现了其在AI芯片、服务器和软件应用方面的强大实力和创新精神。无论是Blackwell架构GPU的推出,还是一系列新硬件和软件的发布,都为企业和开发者提供了更强大的工具和平台,助力他们推动数字化转型和智能化升级。未来,我们有理由相信,英伟达将继续引领AI技术的发展潮流,为人类社会带来更多的创新和进步。
Blackwell架构的六大技术突破,无疑为英伟达在AI计算领域的地位增添了重要筹码。首先,2080亿个晶体管的采用,以及台积电定制的4NP工艺制造,使得这款芯片在性能上达到了新的高度。同时,通过高速的芯片到芯片链路,两个GPU die得以无缝连接,形成了一个更加强大的计算单元。
第二代Transformer引擎的引入,使得Blackwell在AI推理方面有了显著的提升。新的micro-tensor驱动以及先进的动态范围管理算法,使得这款芯片能够支持更大规模的模型和更高效的计算。此外,4位浮点AI推理功能的实现,进一步提升了计算效率和模型规模。
第五代NVLink技术的推出,为GPU之间的通信提供了前所未有的速度和稳定性。1.8TB/s的双向吞吐量,使得Blackwell在处理大规模AI任务时能够保持高效的数据传输和通信。
专用RAS引擎的加入,使得Blackwell在可靠性和可用性方面有了显著的提升。这一引擎能够实现预防性维护,及时发现并解决潜在问题,从而提高了系统的稳定性和可靠性。
安全AI功能的实现,为AI模型和客户数据的保护提供了有力保障。通过先进的机密计算功能,Blackwell能够在不影响性能的情况下保护敏感数据,为隐私敏感行业提供了重要的支持。
解压缩引擎的引入,使得Blackwell在处理大规模数据时能够保持高效的性能。通过支持最新格式和加速数据库查询,这款芯片为企业提供了更强大的数据处理能力。

 发布于 2024-03-19 10:38・IP 属地河北
发布于 2024-03-19 10:38・IP 属地河北查看全文>>
外太空的金山 - 6 个点赞 👍
查看全文>>
曾游客 - 5 个点赞 👍
这次NVIDIA给大家演示了,如何在没有工艺提升的情况下用相同的功耗实现2倍甚至4倍以上的性能。
那就是:加钱。
同样是4nm,B200的晶体管数量是H100的接近3倍,显存也是2.5倍,没有工艺红利,老黄也只能用高速互联来双芯硬堆料了。成本和芯片规模的暴涨带来了单位功耗性能的暴涨。
之前很多手机CPU发热巨大,被很多人归结于核心太大性能太强,高分低能,实际上发热大恰恰是核心太小性能薄弱的表现,只能靠拉高频率用高功耗来换取一个看得过去的性能。而真正的堆料王者,恰恰都有极其优异的能耗比表现。
芯片这个东西就是一分钱一分货,工艺不变,想要功耗低,你就得多堆晶体管,没有别的途径。
当然,这次B200的架构升级也是蛮大的。
晶体管数量增加了接近3倍,FP64性能只增加了30%左右,可谓是对超算用户极不友好了。剩下的晶体管都拿去堆tensor core和transformer引擎了,FP16 Tensor的性能暴涨5倍,GPU现在越来越像NPU了。
NVLINK这次也实现了带宽翻倍,进一步拉大了跟其他竞争对手NPU的差距。在大模型时代,NVLINK才是决定芯片真正能发挥出多少算力的关键。
B200出来了,A100应该算古董落后技术了吧?美国什么时候能解除制裁?如果国产厂商用类似B200的架构在7nm工艺下制造芯片,算力碾压A100是非常轻松的。B200晶体管数量是A100的四倍,FP16性能是H100的5倍,也就是说A100级别的GPU其实可以实现H100级别的性能了,制裁A100真的还有必要吗?
编辑于 2024-03-19 17:29・IP 属地中国香港查看全文>>
回眸一笑倒苍生 - 5 个点赞 👍
如果从金融角度出发。nv已经到了油尽灯枯了。前几天openai自己开发的芯片也是大面积。也就是说未来的战争不是架构,是面积。谁晶元大谁 。为了降低成本,未来势必会超过300mm晶元面积。整个上游都需要升级设备。
查看全文>>
小李 - 3 个点赞 👍
总结放前面:
- B100相对H100在 单die上提升总体约25%。 计算单元tpc数量提升10%。通过双芯组成MCM形态将性能叠加到2.5倍。
- 显存颗粒单die配备由6颗减少为4颗, 在MCM形态下配备8颗显存。 颗粒数量提升33%. 由于HBM3e容量为24G,相较 HBM3 16G颗粒提升 50%。单卡显存容量从80/96GB 提升到192GB. 未在首发使用36GB颗粒,未来有较大可能升级出288GB版本。 (288G可解锁130B fp16模型推理)
- 性能提升主要贡献来自拼装2die为单die。 显存容量提升主要来自颗粒存储行业单片容量的提升。
- 引入了新的fp6和fp4特性。
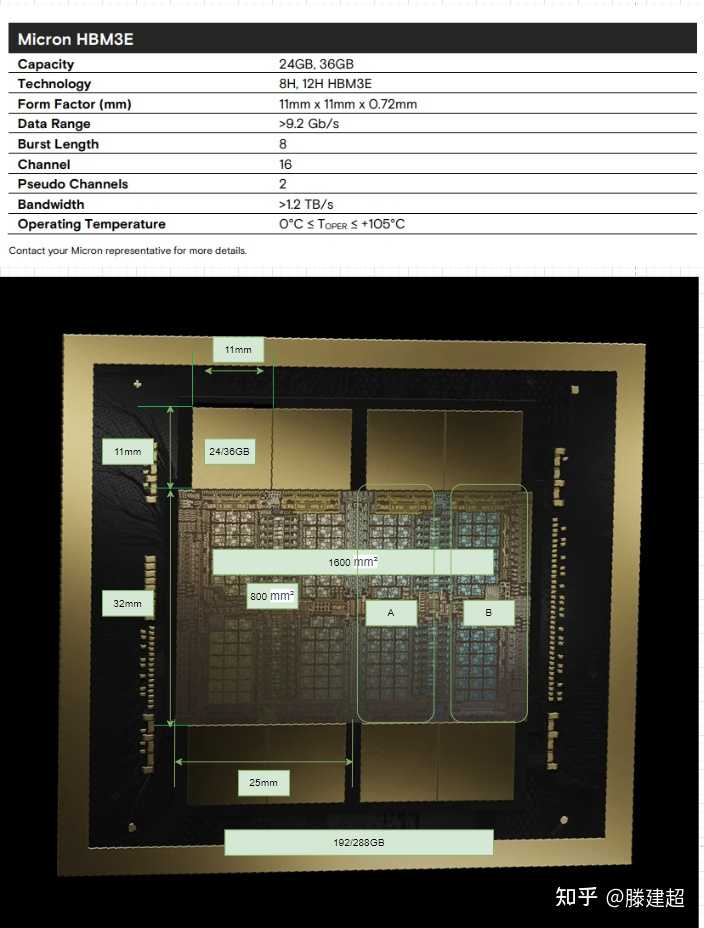
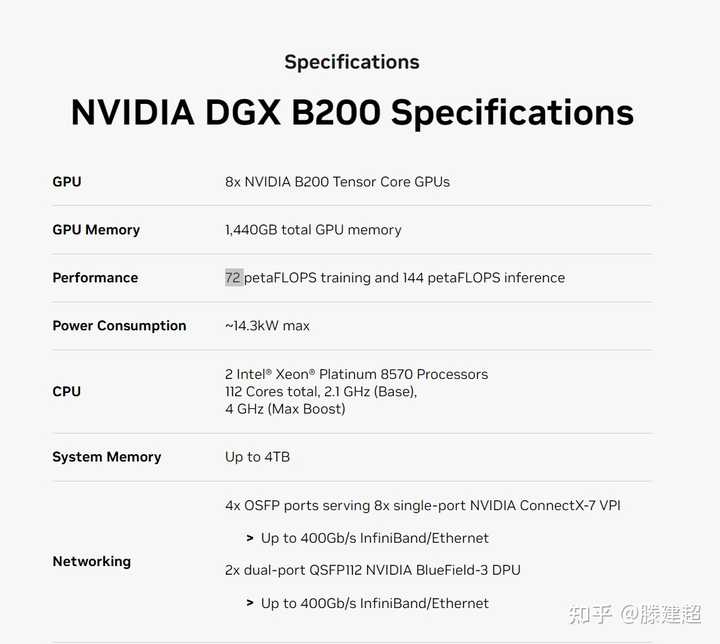
看图猜规格1:
按照镁光给出的HBM3e大小为参照物,估算尺寸。 die size应该是单die 800mm2,单片由两个die缝合, 约1600mm2面积。
单die和上一代大小基本一致(800-814mm). 尺寸没有新的突破。
双die缝合为一个芯片, 硅基板的尺寸>2000mm, 应该是目前已知最大的CoWos封装。
首发配备的应当是24GB的颗粒。
单片MCM显存应当有192GB和288GB两个规格。
A/B两个区域不对称, 排除3die 4die配置出现的可能。
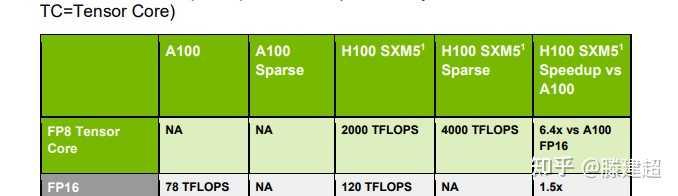
H100 晶体管数为80billion. B100晶体管数量为208(单die 104). 在同样800mm2的情况下, 晶体管数量从80B提高到104B, 密度提升约30%。 同样使用TSMC 4N, 但在制程上或是设计上有改进。
从第一张图上的dieshot观察, tpc数量从72个提升到80。 预计SM数量160单die, 一共320SM。如fp32 和H100 1:1 按照H100的CUDA Core算法 ,双Die MCM形态下 40960个CUDA Core.
算力在fp8上单片是H100的 2.5倍,单die应当是h100的125%(与晶体管增加量基本匹配), 也就是2500TFLOPS fp8. 由此可以推断GPU频率与H100系列大致相当,参考TPC数量的提升,最大提升10%频率,应小于1850MHz。
2die封装后拼装为5p fp8的算力(非稀疏)。 或者10p fp4算力.
DGX形态下的8GPU的 B200 首发显存1440GB, 后期可以最大释放到2304GB,单节点可推理>1000B的 fp16模型. 单卡可完成130B fp16模型推理。







编辑于 2024-03-20 01:03・IP 属地上海查看全文>>
滕建超 - 2 个点赞 👍
遵循英伟达每两年更新一次 GPU 架构的传统,老黄带来的第一个重磅产品便是全新的 bigger GPU——Blackwell 平台。他表示,Hopper 很棒,但是我们需要更强大的 GPU。
Blackwell 架构的命名是为了纪念首位入选美国国家科学院 (National Academy of Sciences)的非裔学者 David Harold Blackwell。


在性能上,Blackwell 拥有 6 项革命性技术加持:
* 世界上最强大的芯片:Blackwell 架构 GPU 采用定制的 4NP 台积电工艺制造,内含 2080 亿个晶体管,通过 10 TB/秒 的 chip-to-chip 链路,将两个极限 GPU 芯片连接成一个统一的 GPU。 第二代 Transformer 引擎:Blackwell 将基于新的 4 位浮点人工智能推理能力支持双倍的计算和模型规模。
* 第五代 NVLink:最新迭代的 NVIDIA NVLink 为每个 GPU 提供了突破性的 1.8TB/s 双向吞吐量,确保在多达 576 个 GPU 之间进行无缝高速通信,以实现最复杂的 LLM。
* RAS 引擎:Blackwell 驱动的 GPU 包括一个用于可靠性、可用性和可维护性的专用引擎。此外,Blackwell 架构还增加了芯片级功能,利用基于 AI 预防性维护来运行诊断并预测可靠性问题。这最大限度地延长了系统正常运行时间,提高了大规模 AI 部署的恢复能力,使其能够连续不间断地运行数周甚至数月,并降低运营成本。
* Secure AI:可在不影响性能的情况下保护人工智能模型和客户数据,并支持新的本地接口加密协议,这对医疗保健和金融服务等隐私敏感行业至关重要。
* 解压缩引擎:专用解压缩引擎支持最新格式,可加速数据库查询,为数据分析和数据科学提供最高性能。
目前,AWS、谷歌、Meta、微软、OpenAI、特斯拉等企业都已经率先「预约」Blackwell 平台。
发布于 2024-03-19 09:48・IP 属地北京查看全文>>
HyperAI超神经 - 2 个点赞 👍
一、
老黄确实能炒作。
其实AI爆发还需要几十年,性能再翻几万倍还差不多,现在远远不够的。
二、
有的人总把超车、第一、不吃、不预、砸脚、跳崖........
你能想到的词都用个遍。
还是这些人,又总说被卡脖子,发展中,也不管矛盾不矛盾。
三、
另一国则是搞笑。虽禁止A100出口,却不禁A800出口,也不禁Grok。
还有更早些年的加区区40%关税措施。其实某国生产一双袜子成本是5美分,卖到另一国是5美元,关税要4000%才没利润。发布于 2024-03-20 04:20・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
光头最帅 - 1 个点赞 👍
英伟达在2024年GTC大会上发布的Blackwell架构GPU和DGX GB200服务器无疑是人工智能和深度学习领域的一次重大突破。
Blackwell架构GPU的推出展现了英伟达在芯片设计和制造上的深厚实力。这款GPU集成了高达2080亿个晶体管,采用了台积电4纳米制程技术,其AI运算性能在FP8和NEWFP6上可达到20 petaflops,是前一代Hopper架构的2.5倍。在NEWFP4上,性能更是达到了惊人的40 petaflops,是Hopper架构的5倍。这样的性能提升使得Blackwell架构GPU能够应对更大规模、更复杂的数据处理和计算任务,为深度学习、自然语言处理等领域的研究和应用提供了强大的硬件支持。
DGX GB200服务器的发布更是将英伟达的AI计算能力推向了新的高度。这款服务器集成了两个Blackwell架构GPU和一个GraceCPU,性能较其前身H100提升了7倍,训练速度达到H100的4倍。更为引人注目的是,DGX GB200的推理性能相比H100提升了45倍,使其能够轻松应对万亿级参数的大模型。同时,DGX GB200还使用了第五代NVLink和BlueField3技术,进一步提升了数据传输效率和安全性。
在演讲中,黄仁勋多次提到AI推理,这也反映了英伟达对于AI推理领域的重视和投入。随着深度学习技术的不断发展,AI推理已经成为许多应用场景中的关键环节。英伟达通过不断提升其硬件产品的推理性能,为AI应用的落地提供了坚实的支持。
英伟达在2024年GTC大会上发布的Blackwell架构GPU和DGX GB200服务器无疑为人工智能和深度学习领域的发展注入了新的活力。这些产品不仅在性能上取得了显著的突破,而且在应用上也展现出了广阔的前景。相信在未来,英伟达将继续引领AI计算领域的发展潮流,为人工智能技术的普及和应用做出更大的贡献。
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)2023第一性原理科研服务器、量化计算平台推荐 - 知乎 (zhihu.com)
Llama-2 LLM各个版本GPU服务器的配置要求是什么? - 知乎 (zhihu.com) 人工智能训练与推理工作站、服务器、集群硬件配置推荐


整理了一些深度学习,人工智能方面的资料,可以看看
机器学习、深度学习和强化学习的关系和区别是什么? - 知乎 (zhihu.com)
人工智能 (Artificial Intelligence, AI)主要应用领域和三种形态:弱人工智能、强人工智能和超级人工智能。
买硬件服务器划算还是租云服务器划算? - 知乎 (zhihu.com)
深度学习机器学习知识点全面总结 - 知乎 (zhihu.com)
自学机器学习、深度学习、人工智能的网站看这里 - 知乎 (zhihu.com)
2023年深度学习GPU服务器配置推荐参考(3) - 知乎 (zhihu.com)


多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、L40、L40S、RTX6000 Ada,RTX A6000,单台双路256核心服务器等。
发布于 2024-03-19 18:33・IP 属地上海查看全文>>
神经蛙没头脑 - 0 个点赞 👍
【复制粘贴自相似问题】
英伟达没活了
2个更大的die(每个都比H100更大,因此>2x面积)实现2.5x晶体管数量,2.4x显存容量和带宽,宣称2.5x性能
(如果没涨价就是老黄让利了)
相当于大幅加强互联,再配合chip间互联和node间互联的加强
发布于 2024-03-20 04:56・IP 属地北京查看全文>>
233 - 0 个点赞 👍
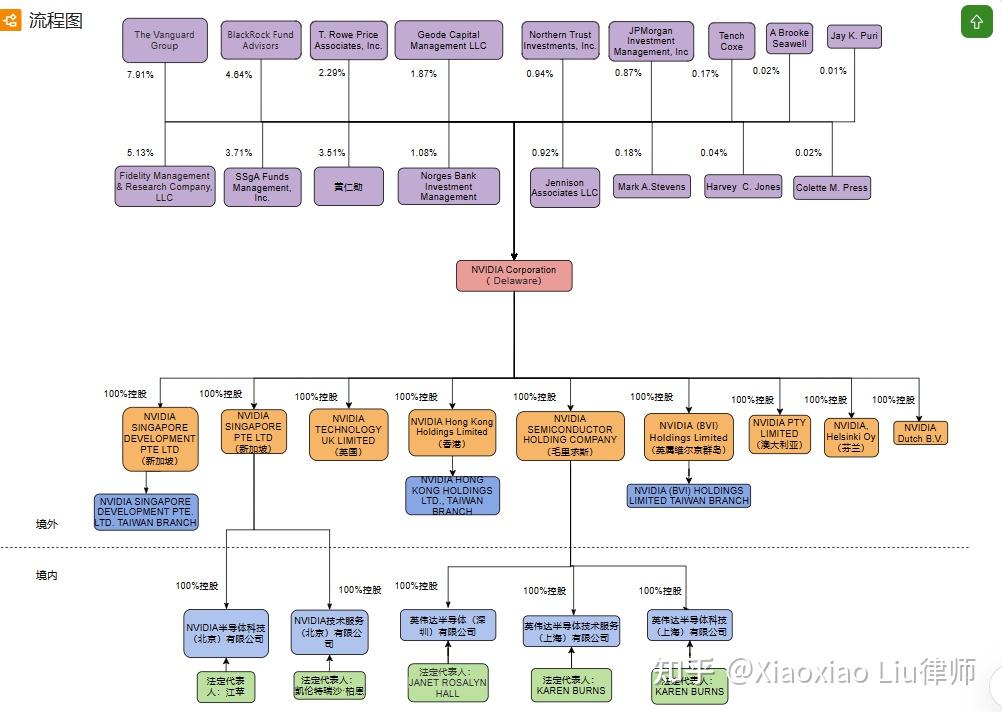
英伟达股价高涨,连续推出如此之多的创新产品,与其股权架构也有关系:
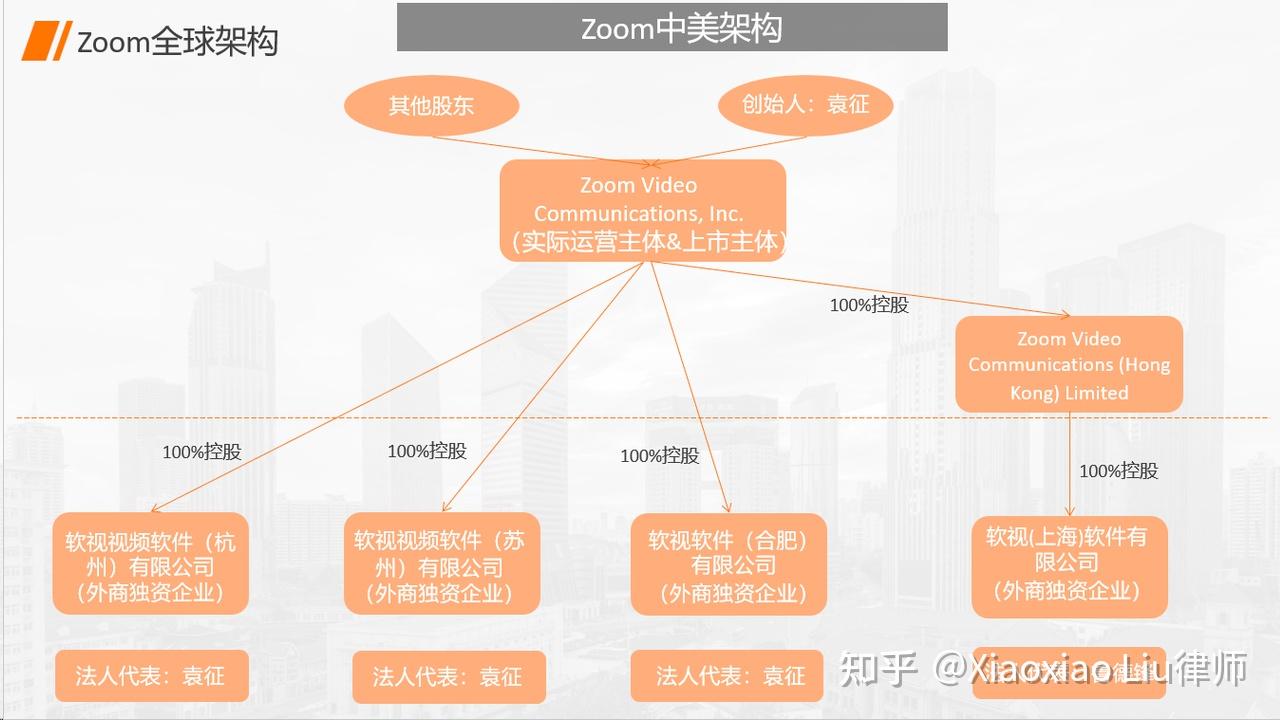
与Zoom相似,英伟达(NVIDIA)也是当今国际巨头公司中具有华人基因的一家。一眼望去,大家就可以看出来了,英伟达(NVIDIA)用的是类似于Zoom的美国特拉华公司为主体的架构。那么咱们就来看看,相比于Zoom,英伟达(NVIDIA)在架构上有何不同之处,以及其中的原因。 硅谷宝典四十二章经,专为创始人定制的法律百科全书。我是美国律师刘晓笑,在硅谷为您深度解读创业背后的法律逻辑。
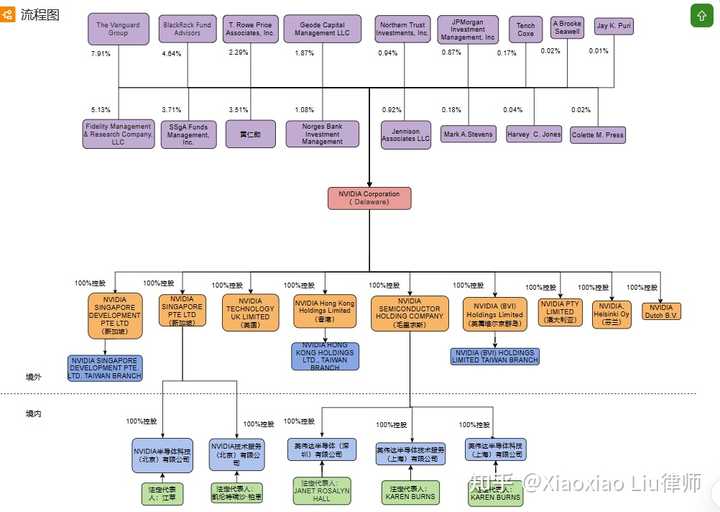

一、为何有两个新加坡公司?
相比于Zoom架构,我们会发现英伟达(NVIDIA)的架构中有两个新加坡公司,但是这两个新加坡公司的业务不同。 英伟达(新加坡)发展私人有限公司(NVIDIA Singapore Development Pte. Ltd.)自1993年成立以来,主要是做PC游戏、计算机图形、现代人工智能以及元宇宙业务。 英伟达(新加坡)私人有限公司(NVIDIA Singapore Pte Ltd.)2000年5月成立,专注于制造计算机打印机、显示器、键盘、鼠标、网络摄像头,以及自动取款机、自助服务亭、销售点终端和生物识别读取器。 先说明一下,对于这个“私人有限公司”大家不要惊讶。新加坡的公司都叫做PTE,私人有限公司。 英伟达(NVIDIA)在新加坡建立两个公司,主要是因为是英伟达(NVIDIA)业务需求比较多元化,的确有需要建立不同的一些公司,所以在新加坡就建立了两个。当然这两个公司也有共同点,就是在整个架构中起到的是人才中心、研发中心的角色。
二、为什么在毛里求斯设立公司
另外我们会看到英伟达(NVIDIA)还有一个毛里求斯公司,这在各大跨国公司架构中都是不常见的。 毛里求斯人称“非洲瑞士”,是非洲为数不多的富裕国家,也有着丰富的商业机会免征企业所得税、个人所得税、资本利得税、印花税和资产税等税项,公司主体可用于买卖物业,置办房产,没有无外汇管制的,支持双向自由进出,可以使用很多国家的货币进行交易。 另外毛里求斯也是很适合作为离岸公司的选地,所以在这里我们看到毛里求斯是一个控股公司,下属的一家深圳、两家上海公司才是实际经营主体,所以在这里毛里求斯公司跟我们常见的英属维京群岛(BVI)或者开曼群岛(Cayman Island)没有什么区别。至于为什么英伟达(NVIDIA)用毛里求斯而不是其他的离岸公司,我们接下来会有一期专门的视频分析各个离岸公司胜地之间的优劣对比,今天就不展开了。


三、为什么在维京群岛设立公司
在VIE架构中,一般的英属维京群岛(BVI)公司会作为最上层的持股公司,每个创始人来一个,再共同持股上市主体的开曼公司。但是在英伟达(NVIDIA)的架构中,我们看到明显不是这样,特拉华公司之上是各个股东直接持股,而在英伟达(NVIDIA)的架构中,英属维京群岛英伟达股份有限公司(NVIDIA BVI Holdings Limited)却是美国总公司百分之百控股。 我们会注意到,这里的英属维京群岛(BVI)是有一个分公司在台湾的,叫做英属维京群岛英伟达股份有限公司台湾分公司(NVIDIA (BVI) Holdings Limited Taiwan Branch),注意是分公司,不是子公司哦。而且除了这个英属维京群岛(BVI)公司在台湾开设分公司,英伟达(NVIDIA)也通过它的英伟达新加坡发展有限公司(NVIDIA Singapore Development Pte Ltd)在台湾设立了英伟达新加坡发展有限公司台湾分公司(NVIDIA Singapore Development Pte. Ltd. Taiwan),通过英伟达香港控股有限公司(NVIDIA Hong Kong Holdings Limited)在台湾设立了英伟达香港控股有限公司台湾分公司(NVIDIA Hong Kong Holdings Ltd., Taiwan Branch)。其实这种在海外建立总公司,再在台湾设置分公司的方式是台湾的公司法实操过程中比较常见的一种做法,就像是我们中国人开公司喜欢搞一套红筹架构一样,具体的的原因就不展开了,是台湾的各项法律制度综合下来的结果。 至于为什么这些英伟达(NVIDIA)的海外公司都是在台湾设置分公司,大家应该都知道吧,台湾是创始人黄仁勋的老家,也是英伟达(NVIDIA)的一个重要战略地,2023年英伟达(NVIDIA)还宣布在台湾投资243亿元新台币成立AI研发中心,它的代工厂也在台湾。
四、为何不在香港公司下设立外商独资企业(Wholly Foreign Owned Enterprise/WFOE)?
咱们典型的VIE架构中,离岸公司都会通过香港再在中国大陆设置一个外商独资企业(Wholly Foreign Owned Enterprise/WFOE),但是很明显英伟达(NVIDIA)的架构是没有这样做的,北京、上海、深圳的公司分别是由新加坡的公司和毛里求斯公司控股的。咱们在讲到Zoom架构的时候是不是也跟大家说过,为什么 Zoom架构中大部分处于中国境内的外商独资企业都没有香港公司控股?那么咱们要先明白VIE架构中设置香港主体的原因是什么,是因为内地和香港之间的税收协定对吧,这样内地公司产出的营收就可以在进入香港的时候少交点税。但是如果这个内地公司它纯粹就是一个成本中心,不赚钱只花钱的,那么香港公司的存在就是没有什么意义的了对吧。


五、英伟达(NVIDA)与Zoom架构的不同之处
咱们开头就说了,英伟达(NVIDIA)用的是以美国特拉华公司为主体的Zoom架构。那么相比之下,两者有何不同呢? Zoom 大部分开发团队都来自中国,苏州、杭州、上海、合肥是主要地区,中国的员工大约占其总员工数的 30%,但是英伟达(NVIDIA)的全球员工中,台湾以及中国大陆员工不足10%。究其原因,主要有以下四点: (1)软件硬件。Zoom是一家纯软件公司,本来所有内容就都是线上的,远程工作也很方便。而英伟达(NVIDIA)做半导体芯片,是硬件,还是有很多需要线下面对面合作。 (2)技术难度。Zoom咱们都知道,技术上没有什么太大难度,跟之前的Skype什么的没有实质性的差别,所以Zoom的成功更多靠的是优化,而不是颠覆性的创新,大家会发现咱们亚洲人创业都比较擅长做这种优化性创业,或者说叫做改良型创业。比如石头科技(Roborock)在美国的Roomba扫地机器人的基础上,推出了扫拖一体的机器人。还有电动汽车本来是美国人发明的,后来中国品牌直接在电动汽车上加上按摩仪、麻将桌什么的。不能做到人无我有,但能做到人有我优。这种工作放到亚洲国家最合适。而英伟达(NVIDIA)做的很多事情都是前所未有的创新,那么还是要到美国,目前是美国还是顶尖工程师最云集的地方。 (3)国家安全。前面几期视频我们也多次分析了美国出台的一个又一个对华限制政策,其实核心的内容就是国家安全,而半导体在每个这样的限制性政策中都位列榜首。也正是因为前面说到的半导体产业的高精尖性,按照美国的国家安全要求,很多工作无法放到海外。 (4)本地化。这个部分就是企业文化方案的因素了,黄仁勋9岁的时候就来美国了,基本可以算是半个美国人,对于美国本地的资源用得已经是炉火纯青,英伟达(NVIDIA)也跟像是一家美国企业,而Zoom的创始人袁征本科就读于山东矿业学院(今山东科技大学),硕士先是就读于中国矿业大学,后获得斯坦福大学MBA学位,还是更像我们大部分留美的学生,所以还是有这个惯性思维,对于老校的资源依赖性还是比较强。
硅谷宝典四十二章经,专为创始人定制的法律百科全书。我是美国律师刘晓笑,我们下期再见。
也顺便推荐一下自己写的专栏,希望对大家有所帮助
发布于 2024-03-19 21:23・IP 属地美国查看全文>>
Xiaoxiao Liu律师 - 0 个点赞 👍
看到这些,我为人类的未来感到欣喜,又为中国的未来感到巨大的担忧
近十年互联网的部分成功,让部分中国人认为仅仅依靠应用可以和美国平分天下,培育了大量工程师,却没有培育杰出的基础领域所需人才和土壤
全民直播带货,沉浸在抖音岁月静好的花花世界中不思进取。出点矛盾就转嫁给资本家、企业家。市场经济的法治建设几乎毫无进展,也就怪不得大量的外资、风险投资人离开
看看我们的科技圈都在干嘛?小米还在为su7定价发愁;一直以来被卡脖子的芯片制造也完全不见啥起色,还闹出技术负责人差点出走的闹剧;
有个技术不错的华为,却被天天嘲讽,真是一群又蠢又可怜,整天盯着三瓜两枣的不放的精致利己主义者
企业困在中国市场,无法获取大量的海外市场和利润,内卷加剧也就不为奇怪
发布于 2024-03-19 14:33・IP 属地上海查看全文>>
流沙 - 0 个点赞 👍
不知面对着英伟达用游戏,视频,元宇宙训练出来的机器人已经可以进行家务劳动的人形机器人,金灿荣先生如何评价他的
“人工智能不见得就是第四次工业革命”
“中国2025工业引领第四次工业革命”
“美国AI花拳绣腿,只能写诗画画,中国AI是实体经济”
“中国2025 GDP世界第一”
“元宇宙就是美国资本炒作发明概念”


 编辑于 2024-03-19 17:17・IP 属地广东
编辑于 2024-03-19 17:17・IP 属地广东查看全文>>
丁炸桥