

$NVDA在这届位于San Jose SAP Center的GTC会议上,发布了几款更大规格的硬件、更激进的DSA化计算范式,以及更大规模的软件栈,甚至发布了几十项AIGC应用。尤其核心的是Blackwell硬件,分别从芯片、Interconnect C2C/in Rack/R2R、DGX整机、集群Pod和多层组网拓扑等方面俯视性展示了黄氏全家桶的排场。
如下总结并评论一下GTC 2024的发布内容和硬件基本的SPEC:
关于制造和封装工艺 :
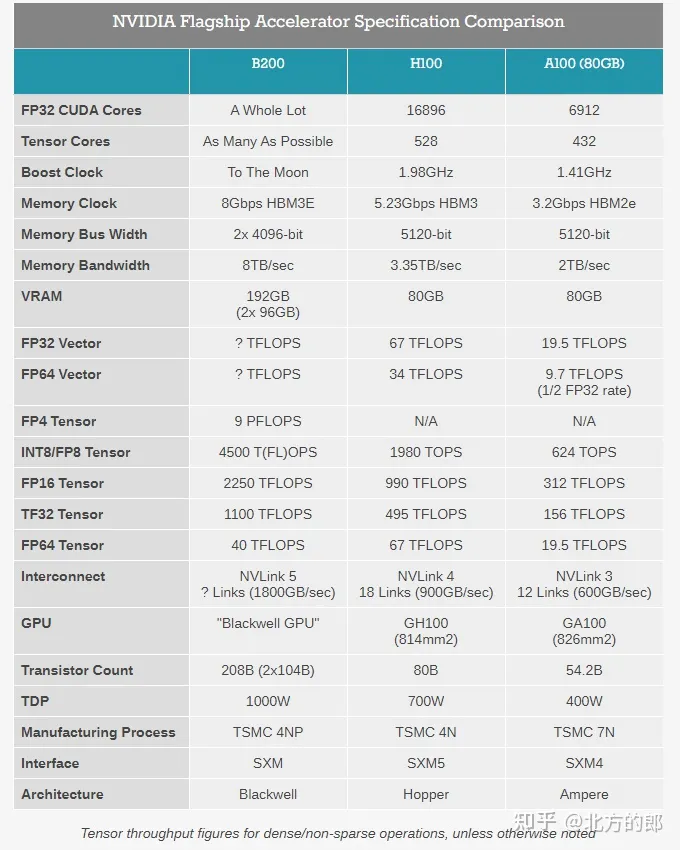
首先是Blackwell硬件,值得一提的是:B100型号似乎被跳过了,发布首个GPU型号即B200;
MCM双片合封的晶体管密度为2080亿(2*104B);晶圆制造的工艺节点选用TSMC N4P 5nm(H100所用N4节点的高性能改良);TSMC官方称N4P节点相比N5可提升11%的微电性能,或提升22%的能效、6%的晶体管密度,以及对比N4可提升6.6%的微电性能;且由于N4P会多次重用reticle而反而让工艺复杂度降低了(官方并未披露单卡B200的TDP数据,但提供了两种规格的机架,即针对风冷DGX和液冷NVL72)。
虽然NV并未披露单芯片的die size,但参考H100 814mm2的规格可以想象Blackwell必然是一颗reticle-sized产物,single-die-size同样接近reticle边缘尺寸,这是N4P 5nm节点的掩膜版极限。由dual GPU die通过10TB/s高速接口桥接并合封而成的单一GPU板卡;算是Chiplets标准的一种类型,近似于AppleSilicon UltraFusion的桥接合封,单卡AI性能达到20PetaFLOPS(相比H100提升4倍);更值得关注的是两颗GPU die之间的I/O,可提供10TB/s的高带宽(单向5TB/s),这也是整个集群系统中速率最高的interlink。另外GB200机内提供GPU <-> Grace CPU双向900GB/s带宽(相比PCIe 64GB/s高很多)。
NV官方对于die2die 10TB/s双向带宽命名为NV-HBI接口(NV-High Bandwidth Interface),其带宽能力已经远高于以AMD MI300为首的Chiplets常规互连带宽,HBI桥接链路及接口将会高度依赖于先进封装,需要更多的布线和引脚,尚不清楚是TSMC哪一类工艺,也许是定制的CoWoS-xxx吧 ...

关于超算整机的配置 :
GB200 NVL72核弹机型,即单机整合了18组B200(共计36CPUs+72GPUs)为更大规格的主机节点(推测单节点即填满Single Rack),单节点即可实现E级算力(FP8格式测算);
其中FP8精度的训练算力为720PFlops(单个DGX H100 SuperPod为1000P);以及该节点支持1.4EFlops的AI推理算力和30TB,存,最高支持27000B参数规模(27万亿)的模型(约16个GPT4 MoE 1.8T)。相比72个H100,GB200 NVL72对于模型推理性能提升约30倍,成本和能耗降低约25倍。而最大扩展形态的DGX GB200 SuperPod标准配置可在FP4精度下提供11.5 ExaFlops算力和240TB内存,此外还支持增加"额外的"机架扩展性能。
关于HBM内存的配置 :
搭配2*4片HBM3E内存,192GB容量(dual GPUs*96GB,即24GB/颗粒,同H200的HBM颗粒规格,而H100搭配的HBM3为16GB/颗粒),内存带宽8TB/s,内存总线位宽为2*4096bit,内存时钟速率8Gbps;HBM整体规格比H100多出50%。
$NVDA官方称:B200搭配HBM内存总带宽为8TB/秒,每堆栈带宽1TB/秒,即每个引脚的数据速率为8Gbps-9.2Gbps,几乎是H100内存带宽的2.4 倍(或比H200高出66%)。
关于机内和多机网络互连 :
发布NVLink v5,网卡和交换芯片同样是在TSMC N4P节点制造,晶体管密度为50B,可在GPUs in rack之间提供1.8TB/s双向吞吐,保证了576个GPU之间的高速通信,同时还支持3.6TFlops的网络内计算,即SHARP v4(Scalable Hierarchical Aggregation and Reduction Protocol)用于将集合操作从CPU尽可能转移到网络设备,以便减少和消除在端点之间多次发送数据的需要,进而提高MPI和ML集合操作的性能。显然,这一代NVLink是为MoE结构的大模型解决通讯瓶颈,比如MoE模型之间的数据传输/同步/Ensemble需要占用极大带宽资源。
搭配交换设备为Quantum-X800 InfiniBand和Spectrum™-X800 Ethernet(搭配ConnectX-8 SuperNIC),组网速率为800Gb/s,其中X800相比前代的带宽容量提高5倍。GB200 NVL72还包括NVIDIA BlueField-3数据处理单元,可在超大规模人工智能云中实现云网络加速、可组合存储、零信任安全和GPU计算弹性。
$NVDA官方称:此前仅由16个GPU组成的集群会在相互通信上花费60%时间,而仅有40%时间用于实际计算。现在NVLink v5可以让更多的芯片在机内互连,减少R2R通信的带宽切分,全速运转1.8TB/s,几乎比上代快10倍,并由此构建DGX GB200 NVL72。
同时,新的DGX超算主机内置布线有5000条NVLink铜电缆(总长近2英里),极大减少了光收发端子和光缆开销,节省了20kW的计算成本。
计算单元和其它附加配置 :
支持Transformer V2,允许动态启用FP8/FP6/FP4精度支持;支持FP4(tensor)低精度格式的推理,并提供9PFlops算力;Btw FP8算力达到了4500TFlops。NV声明的B200推理性能相比前代H100提升约30倍,而能耗却降低约25倍;在标准的175B参数GPT-3基准测试中,GB200表现性能是H100的7倍,训练算力是H100的4倍;
注意B200的FP32单元数量提升不多,FP16单元虽然大幅提升,但是官方主推FP8甚至搭配FP4,或许再远的未来也将告别常用的16bit精度的统治了;而从FP16开始都是tensor core的设计面积,未来GPU 90%的计算单元面积都给到NPU/DSA范式了,NN模型都要去FP8/FP4(tensor)上面收敛了 ......
- 集成RAS Engine和所谓的AI预防性维护功能,确保大集群部署系统的长期鲁棒性。
- 集成SecureAI功能,支持TEE和数据加密计算,适用于医疗、金融等敏感行业。
- 集成800GB/s的专用解压缩引擎,加速数据库查询。
关于延伸至应用侧的CUDA疆域 :
$NVDA官宣的http://ai.nvidia.com主页“要做世界AI的入口”,这是多么可怕的宣言。
这个页面后台关联了NV企业级云服务,其用户界面可以直接搭建和使用各种AI模型及应用。第三方企业可以使用这些services创建和部署自定义应用,并且不会有CSP那样强规则的云管限制。该主页的应用都由NV自己的AI推理微服务NIM提供支持,可以针对NV及其Cloud Partners的数十个AI模型进行优化和推理,这些Partners包括AMZN/DIS/Samsung等厂商,这算是CUDA霸权的延伸。而且定价十分直观,1GPU/1h/$,或年付打五折,一个GPU一年4500美元。
更主要的是:NV自己提供的这些开发套件、库和工具链都可以作为CUDA-X微服务访问,比如用于RAG、Fence、数据处理、HPC等等日常工程,这些微服务可以用来构建基于LLM和向量数据库的生成式应用(包括Agent形态的所谓智能体应用)。
Postscripts :
资本数据:大模型这波趋势,全球Y23-Y24Q1在AI Capex上面投入给Nvidia的钱约有$160B。
并无太多可总结的,本次 GTC 公布了最完整的AIGC-Infra全家桶,单独讨论B200的硬件规格已经不再重要;总之而言,AMD CDNA凉了,INTC Gaudi凉了,Groq这类独辟蹊径的DSA凉了。
另外,NV-GTC在介绍GB200 NVL72的时候,貌似如下这张slide不慎透露了GPT-4的参数规模1800B?莫非是印证了220B*8的传言?
或是印证了111B*16+55B的传言:即每个MoE专家模型参数规模约为111B,每个前向计算中,其中两个专家模型被路由到进行计算;其中约使用了550亿个共享参数的Attention模型;推理成本为每生成一个token需要用到111B*2+55B≈280B的参数量,浮点运算量约为560TFlops,相比于非MoE结构的稠密模型降低了极大成本(后者生成每个token需要用到1.8万亿参数,浮点运算量为3700TFlops)。
