
总结放前面:
- B100相对H100在 单die上提升总体约25%。 计算单元tpc数量提升10%。通过双芯组成MCM形态将性能叠加到2.5倍。
- 显存颗粒单die配备由6颗减少为4颗, 在MCM形态下配备8颗显存。 颗粒数量提升33%. 由于HBM3e容量为24G,相较 HBM3 16G颗粒提升 50%。单卡显存容量从80/96GB 提升到192GB. 未在首发使用36GB颗粒,未来有较大可能升级出288GB版本。 (288G可解锁130B fp16模型推理)
- 性能提升主要贡献来自拼装2die为单die。 显存容量提升主要来自颗粒存储行业单片容量的提升。
- 引入了新的fp6和fp4特性。
看图猜规格1:
按照镁光给出的HBM3e大小为参照物,估算尺寸。 die size应该是单die 800mm2,单片由两个die缝合, 约1600mm2面积。
单die和上一代大小基本一致(800-814mm). 尺寸没有新的突破。
双die缝合为一个芯片, 硅基板的尺寸>2000mm, 应该是目前已知最大的CoWos封装。
首发配备的应当是24GB的颗粒。
单片MCM显存应当有192GB和288GB两个规格。
A/B两个区域不对称, 排除3die 4die配置出现的可能。
H100 晶体管数为80billion. B100晶体管数量为208(单die 104). 在同样800mm2的情况下, 晶体管数量从80B提高到104B, 密度提升约30%。 同样使用TSMC 4N, 但在制程上或是设计上有改进。
从第一张图上的dieshot观察, tpc数量从72个提升到80。 预计SM数量160单die, 一共320SM。如fp32 和H100 1:1 按照H100的CUDA Core算法 ,双Die MCM形态下 40960个CUDA Core.
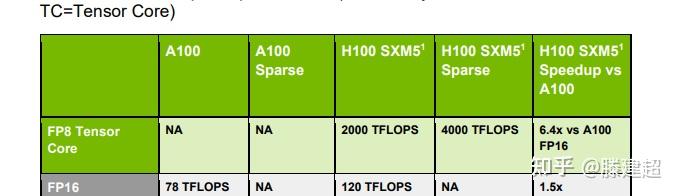
算力在fp8上单片是H100的 2.5倍,单die应当是h100的125%(与晶体管增加量基本匹配), 也就是2500TFLOPS fp8. 由此可以推断GPU频率与H100系列大致相当,参考TPC数量的提升,最大提升10%频率,应小于1850MHz。
2die封装后拼装为5p fp8的算力(非稀疏)。 或者10p fp4算力.
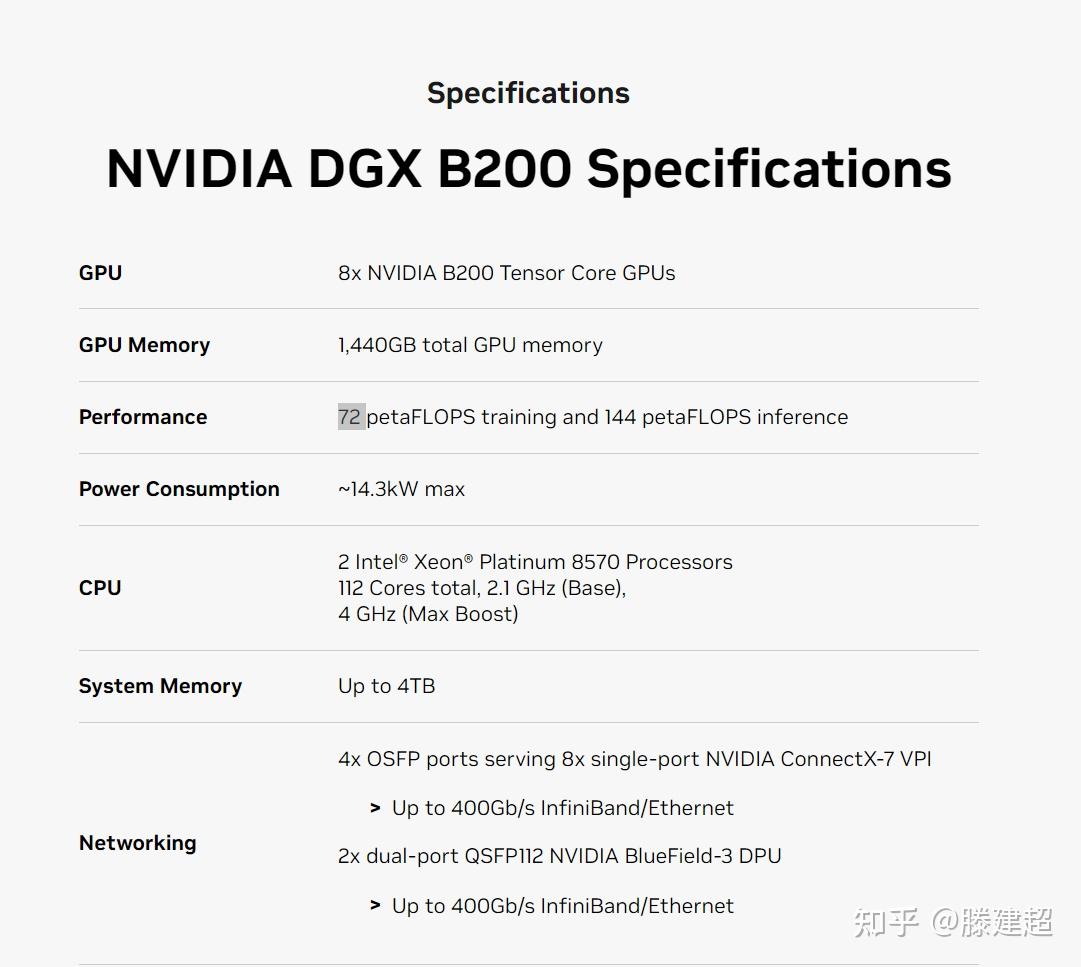
DGX形态下的8GPU的 B200 首发显存1440GB, 后期可以最大释放到2304GB,单节点可推理>1000B的 fp16模型. 单卡可完成130B fp16模型推理。



编辑于 2024-03-20 01:03・IP 属地上海