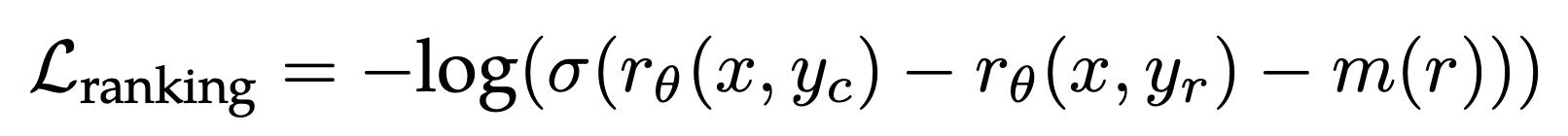Meta 发布开源可商用模型 Llama 2,实际体验效果如何?

- 201 个点赞 👍
查看全文>>
Uranus - 73 个点赞 👍
开源&商用,冲击力极大。
PS:MetaAI改名叫OpenAI吧!
后续一大推中文扩充词表预训练&领域数据微调的模型会被国人放出。
7b,13b,34b,70b都有完全够用,最期待的34b会暂缓放出。
国内开源底座模型还是在6b、7b、13b等层次,33-34b才是刚需呀。
随着开源可商用的模型越来越多,大模型社区会越来越繁华,中小厂的福音。个人觉得,百川、Meta都是真英雄。
实验细节去看论文吧!!!
我愿从此跟随MetaAI走Open开源AI路线。
编辑于 2023-07-19 08:37・IP 属地江苏真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
刘聪NLP - 65 个点赞 👍
查看全文>>
苏洋 - 44 个点赞 👍
去年Meta股价腰斩的时候,我一度觉得它不行了,现在看来,是我眼光出了问题。
另外非常有意思的是一作Hugo Touvron,他之前比较好的工作有FixRes和DeiT,我一直以为他是做CV的,没想到是隐藏的NLP巨佬。。。所以,搞CV的同志们,格局要及早打开。。。
最后致敬开源!
经典回顾:
编辑于 2023-07-20 08:31・IP 属地广东查看全文>>
小小将 - 44 个点赞 👍
原文链接:
瞎BB两句
夜深人静,LLaMA2来了,你的老羊驼突然出现!
Meta真不愧是开源之光,可以说现在开源大模型的一大半边天都是LLaMA撑起来的,现在LLaMA2来了!
老规矩,先进waitlist再说!

哇,很快呀!

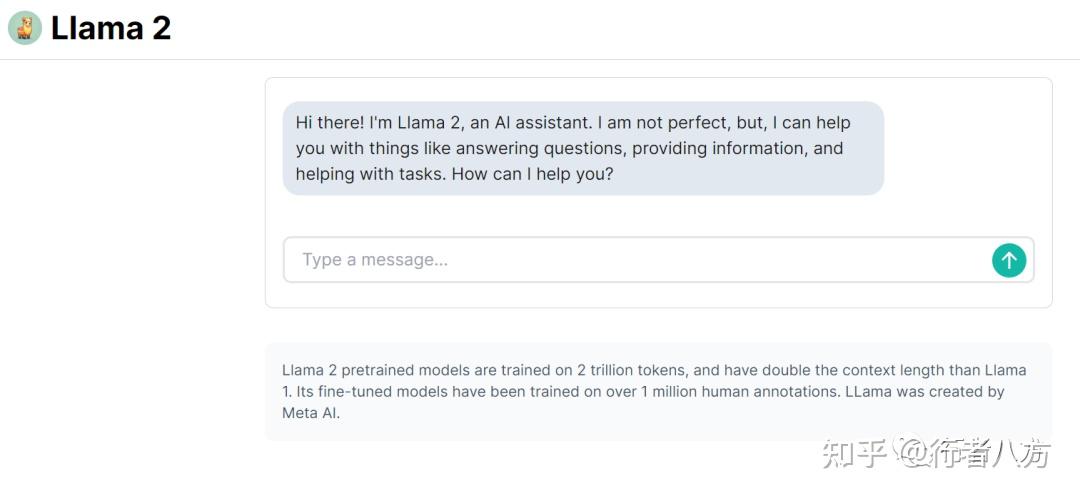
LLama2
先去官网喽一眼:


要点
- 今天,我们将介绍 Llama 2 的可用性,它是我们的下一代开源大型语言模型。
- Llama 2 可免费用于研究和商业用途。
- Microsoft 和 Meta 正在扩大他们的长期合作伙伴关系,其中 Microsoft 是 Llama 2 的首选合作伙伴。
- 我们在科技界、学术界和政策领域的众多公司和人士的支持下开放了 Llama 2,他们也相信当今人工智能技术的开放创新方法。
- 我们致力于负责任地构建,并提供资源来帮助那些使用 Llama 2 的人也这样做。
微软好像在搞事情啊:


模型速览
https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
主要进步
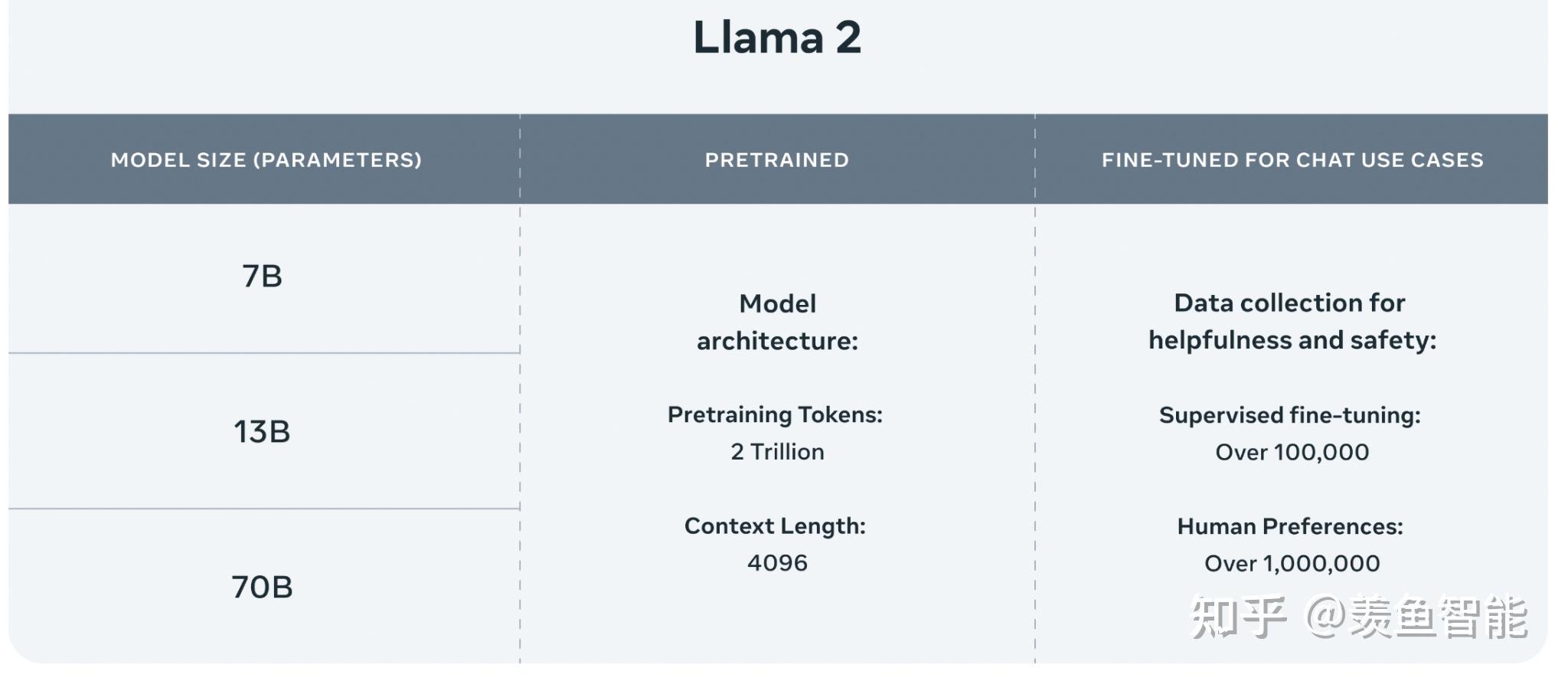
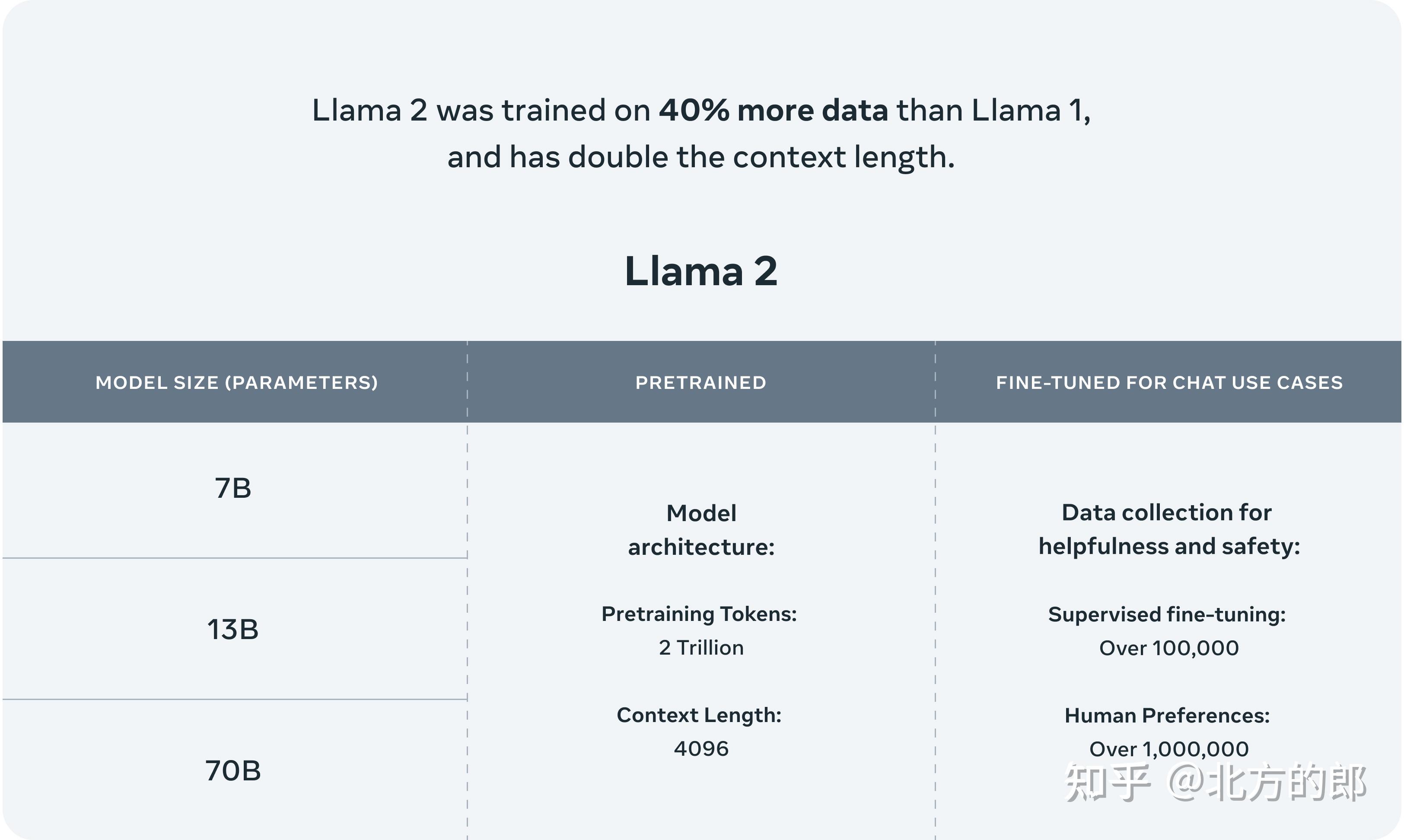
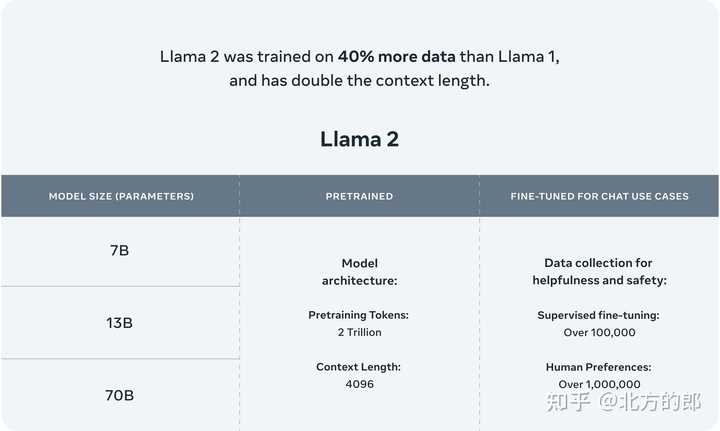
1.相比一代,llama2使用了多40%的训练数据,拥有双倍的上下文长度(4096)。
“Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.”


提供了三个size的版本:
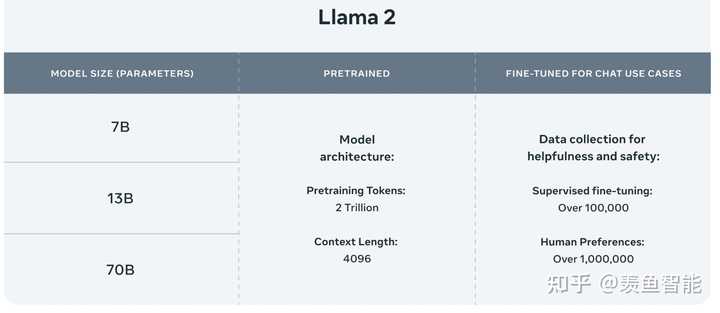



2.微调了chat模型:
这次meta直接一步到位,基础模型+chat模型一起放出来了!!!

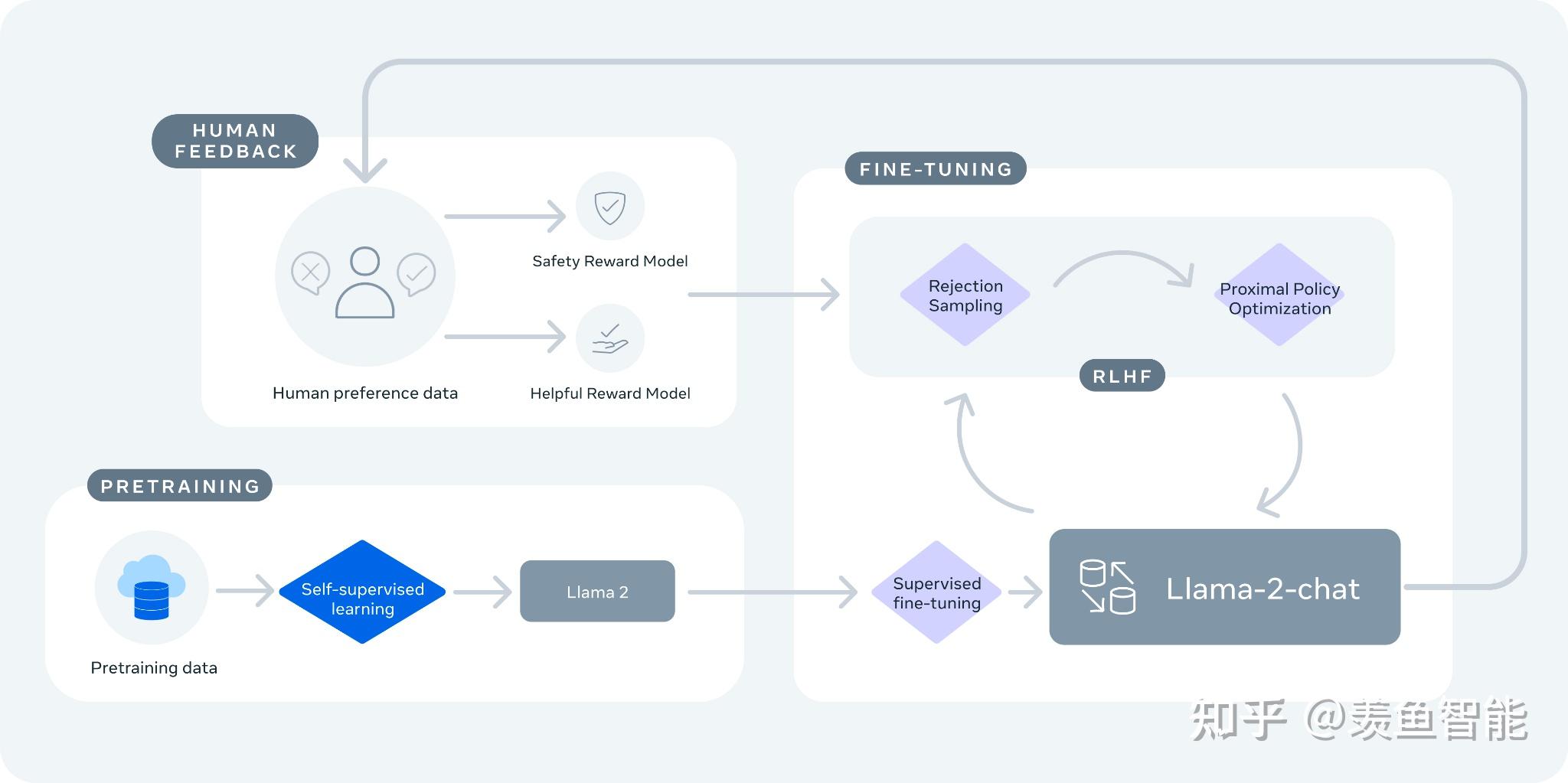
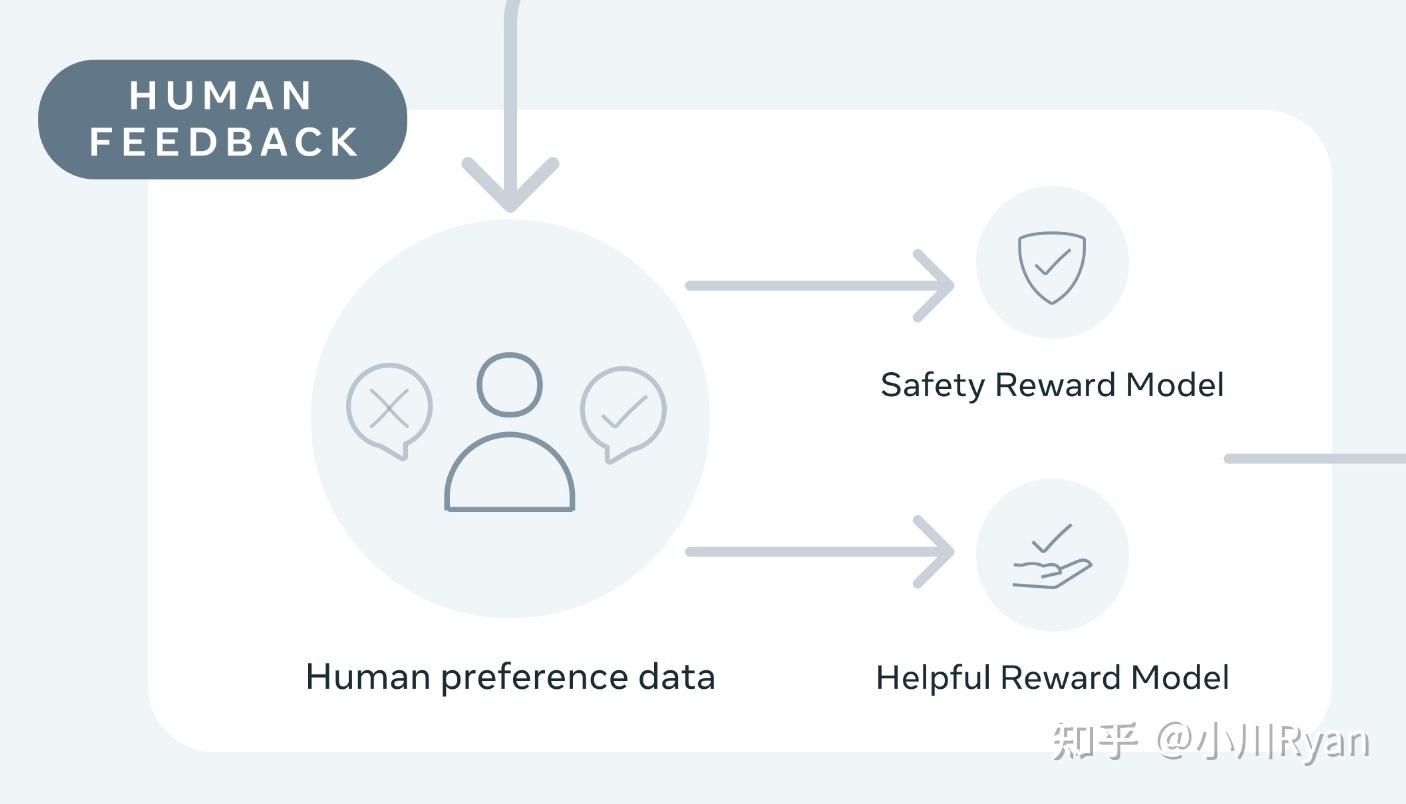
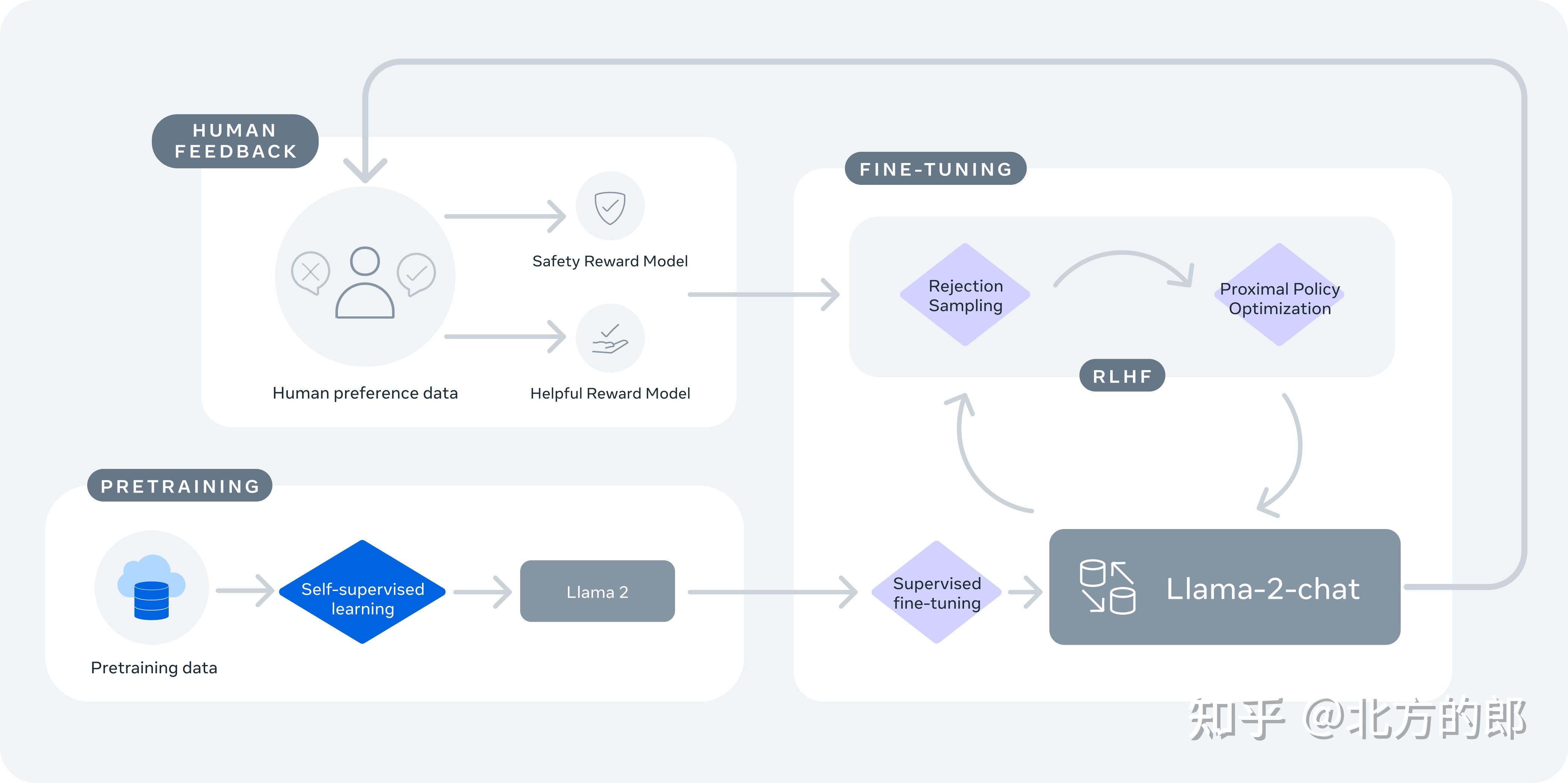
Llama-2-chat 使用来自人类反馈的强化学习来确保安全性和帮助性。
训练 Llama-2-chat: Llama 2 使用公开的在线数据进行预训练。然后通过使用监督微调创建 Llama-2-chat 的初始版本。接下来,Llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
注意这里可能和OpenAI的RLHF略有不同,比如RM不止一个。

效果展示:
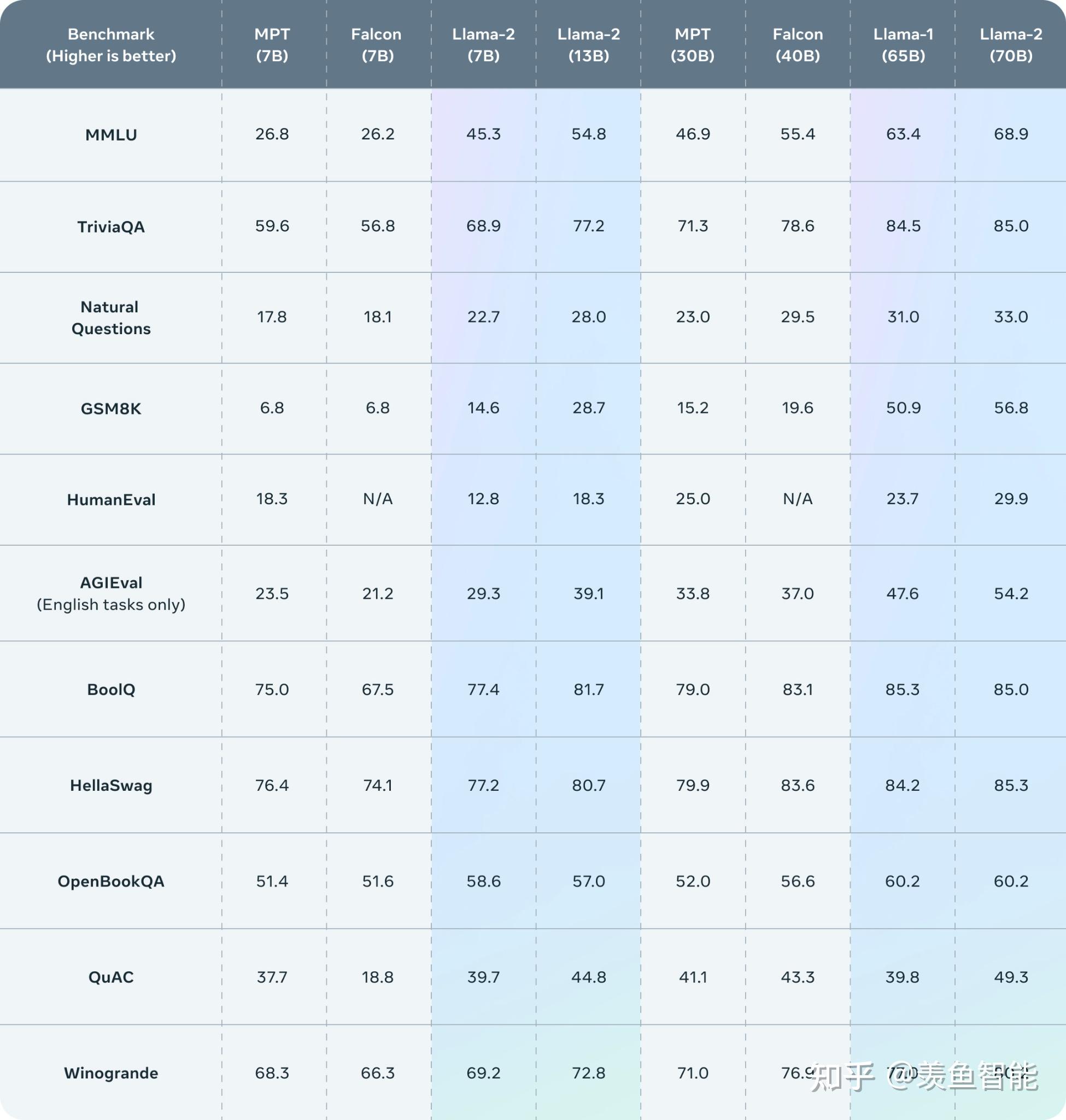
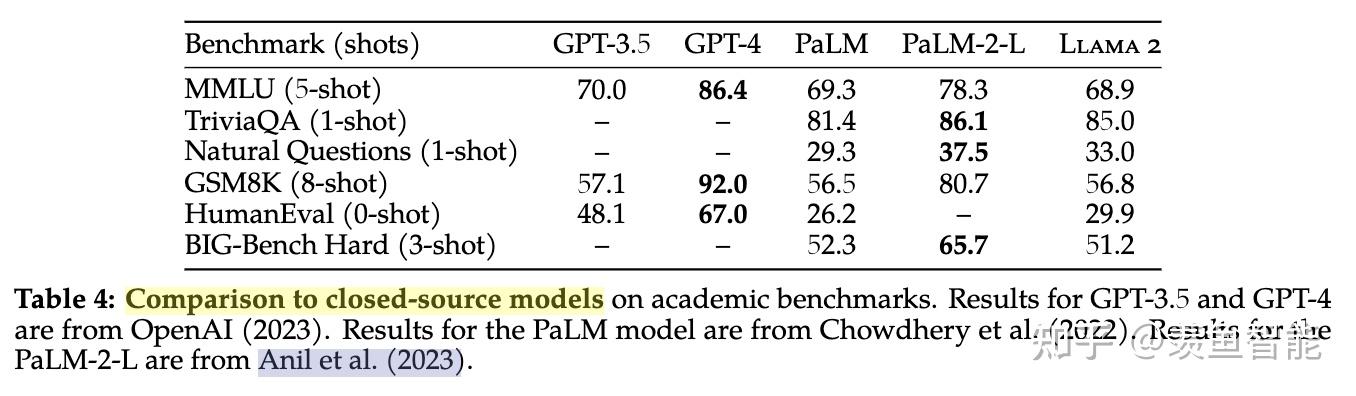
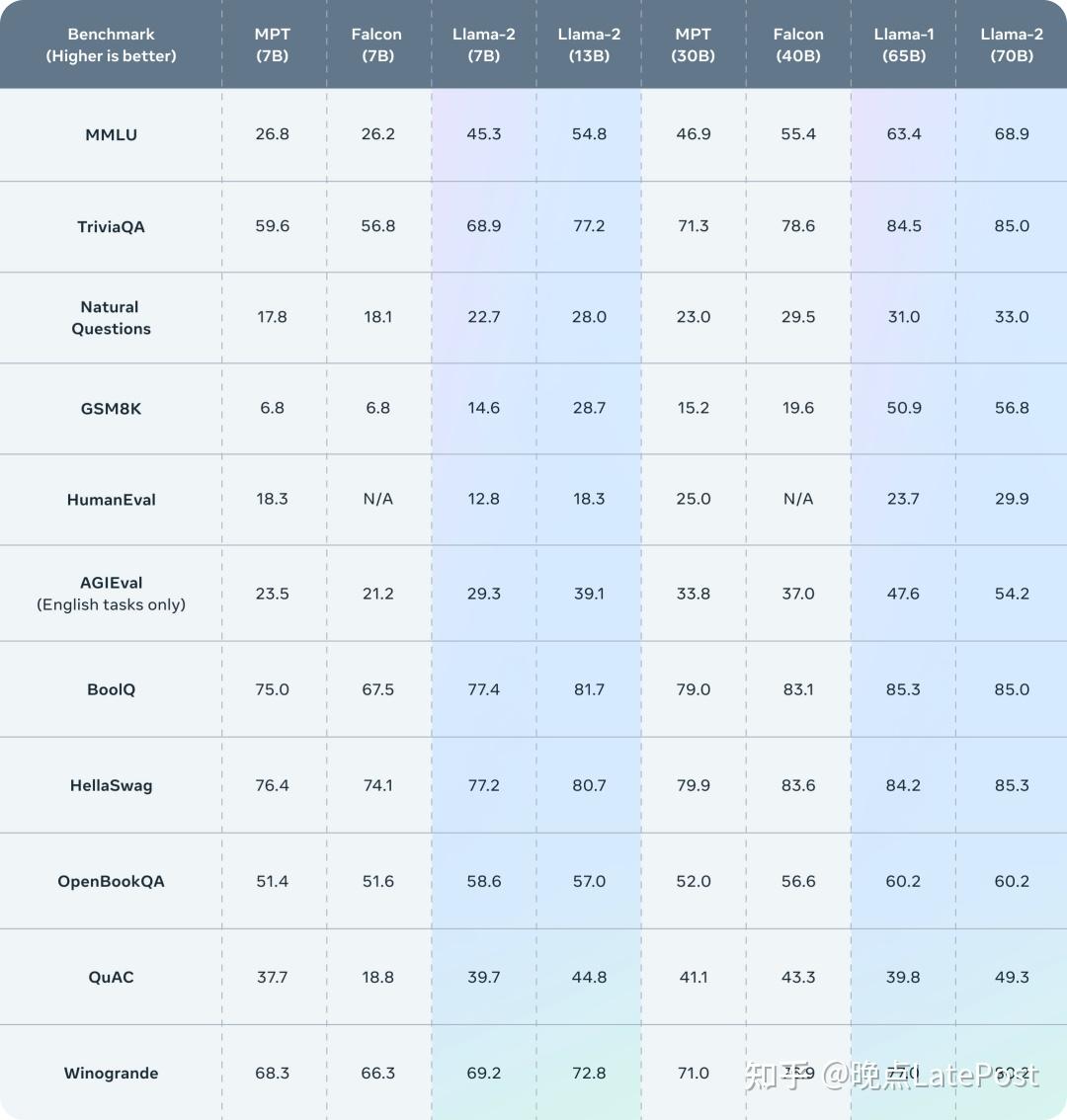
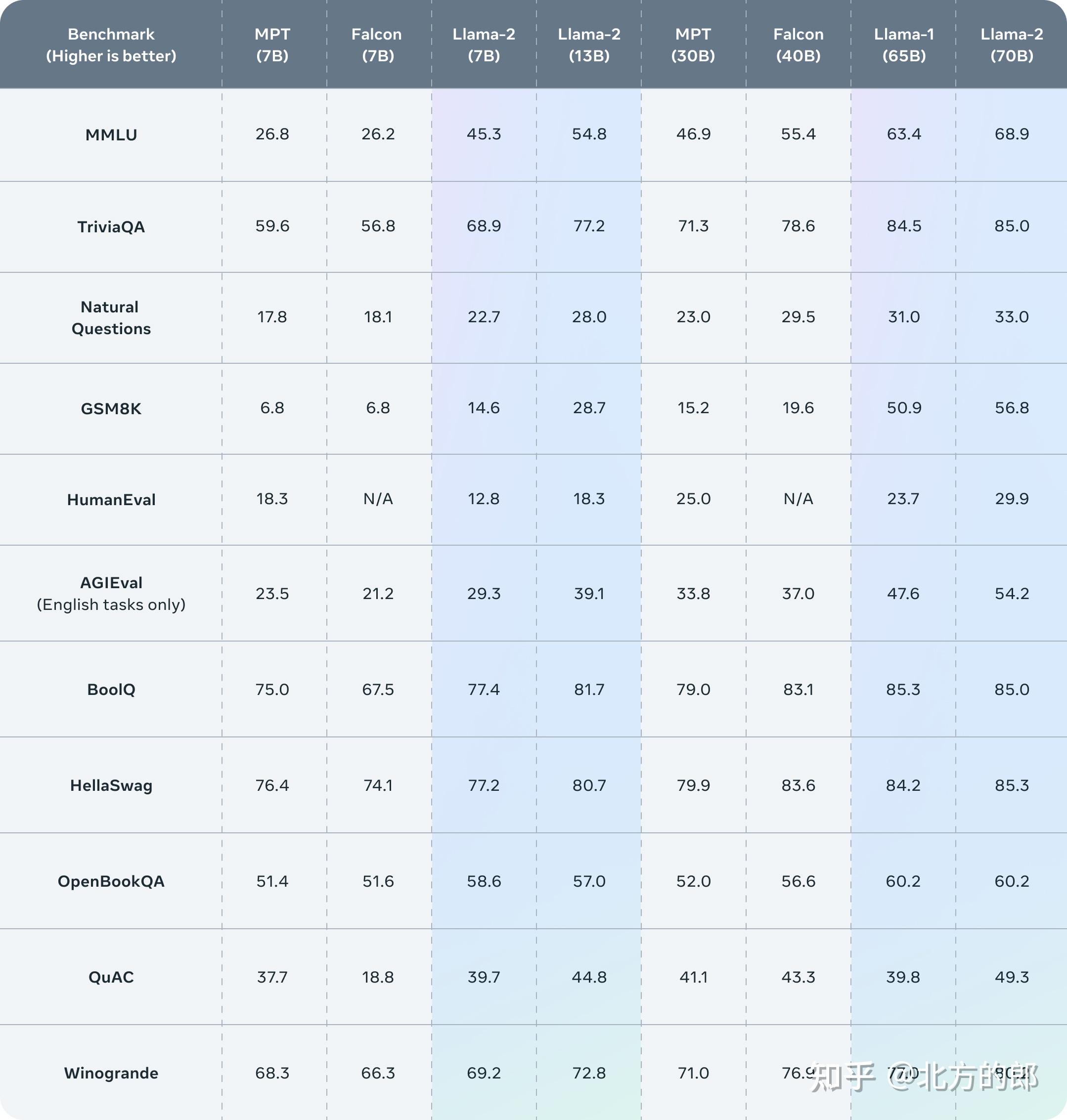
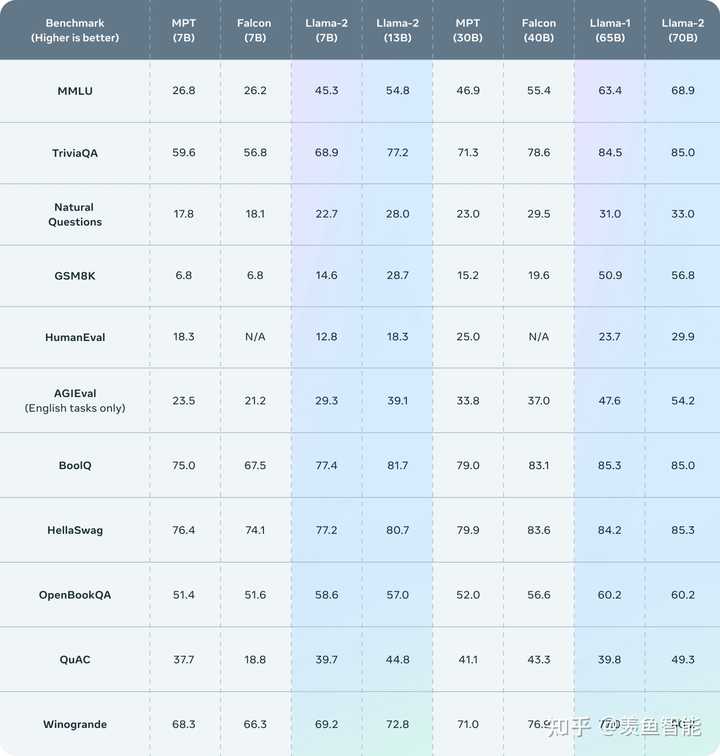
Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests.
开源模型大比拼:

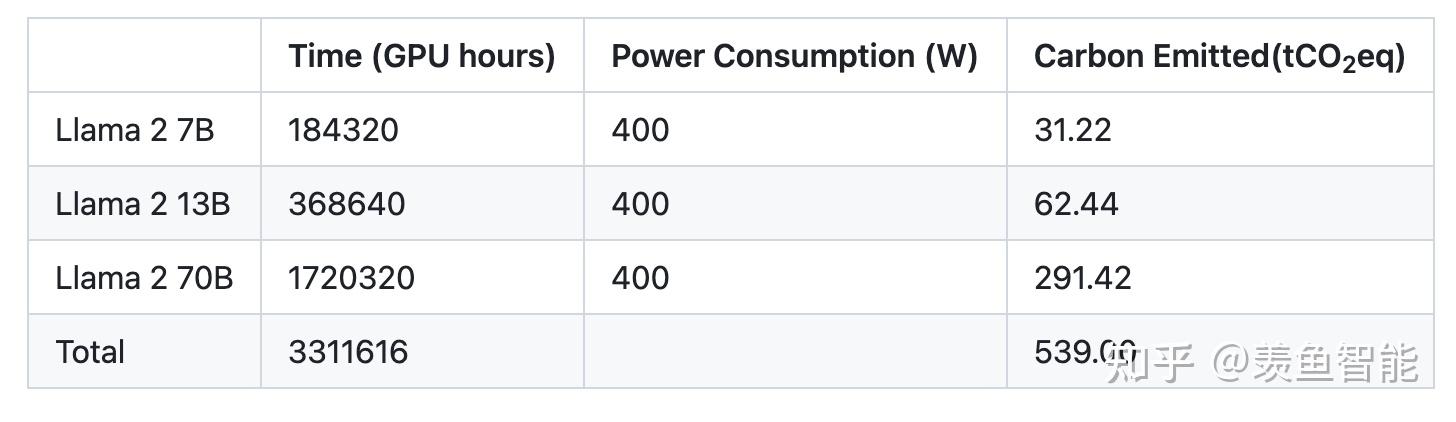
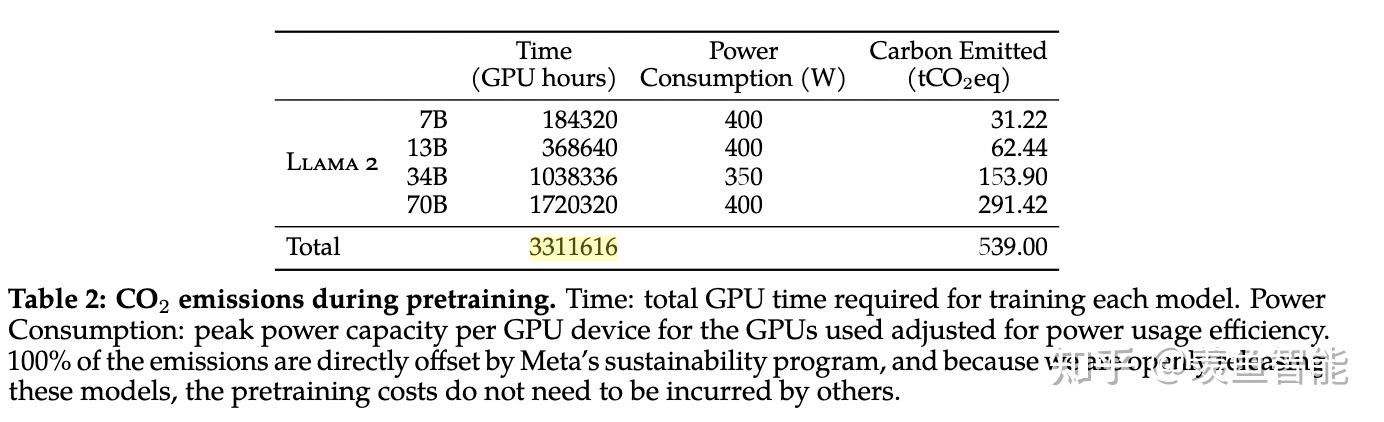
算力消耗:
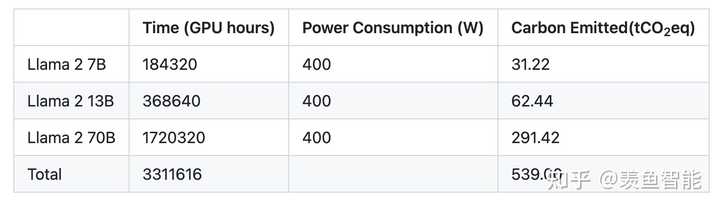

读读论文


整体分为三块,预训练、微调和安全,Meta专门用了一章来讲安全。


先把肌肉再秀一秀
整体效果:开源之光!!!

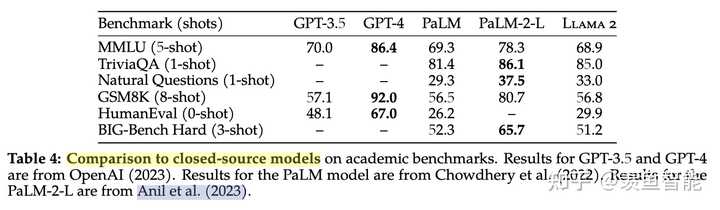
遇上闭源模型,依然很能打:相比GPT3.5不远矣,当然了,离GPT4差距还是不小。怎么说呢,可信!


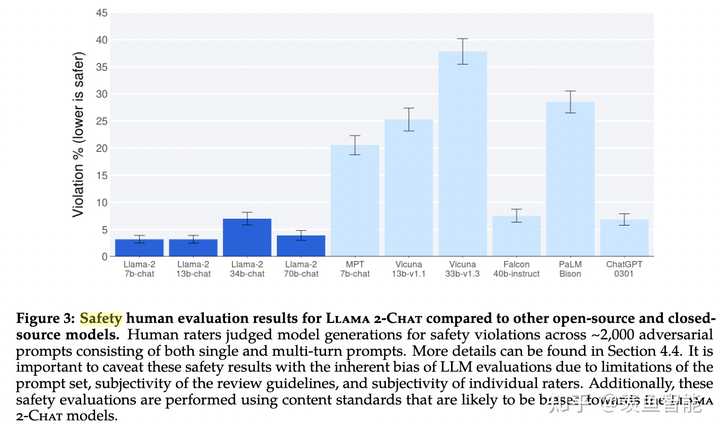

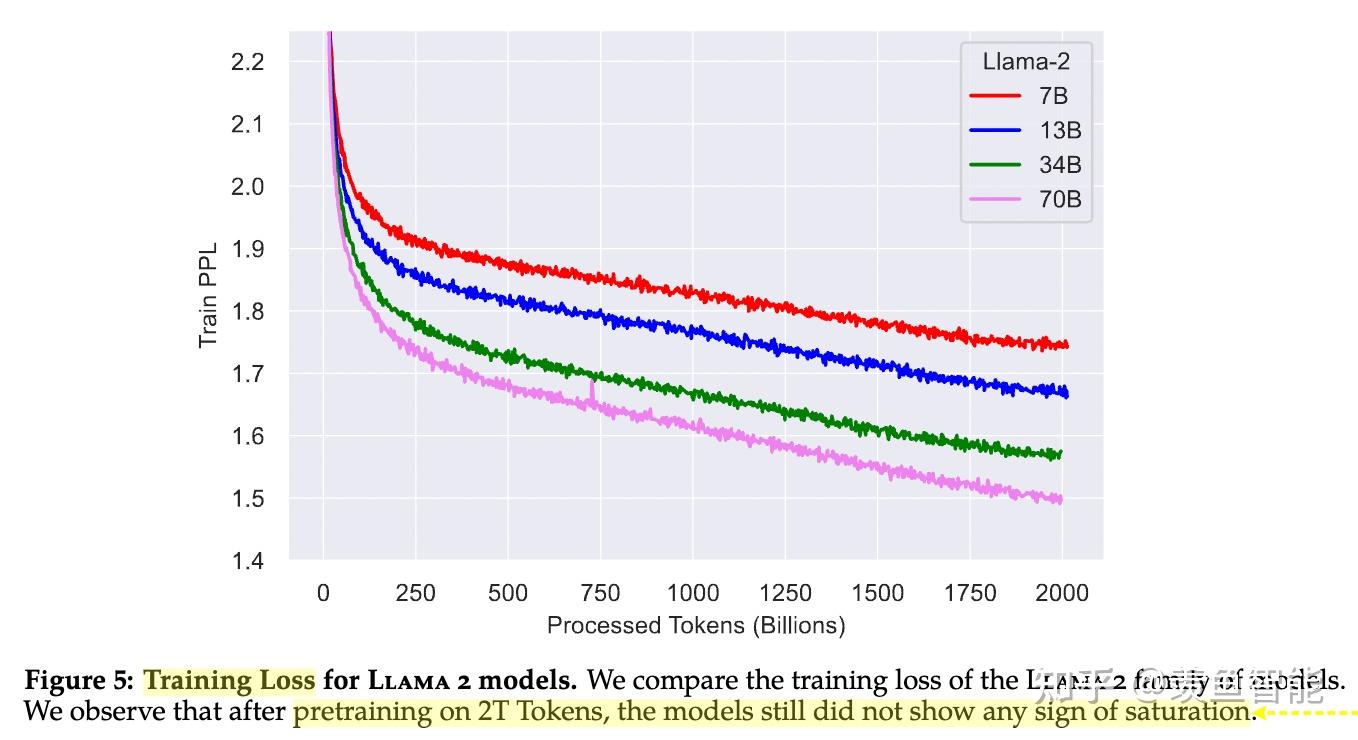
预训练
训练细节:


tokenizer:没变;


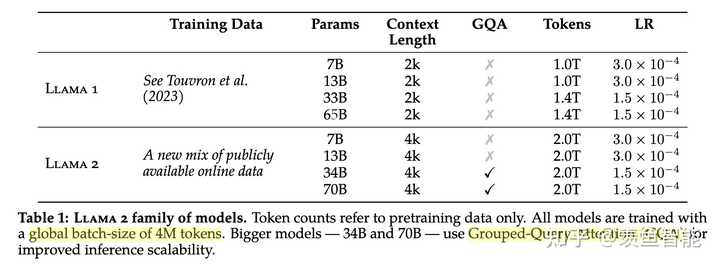
llama2使用了更多的数据;global batch-size of 4M tokens;使用GQA来提高推理的scalability.

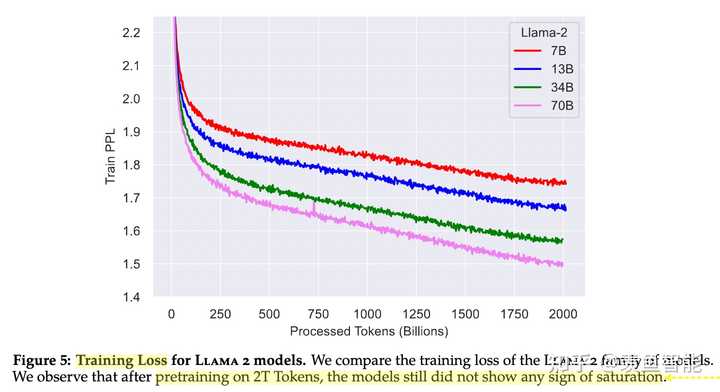

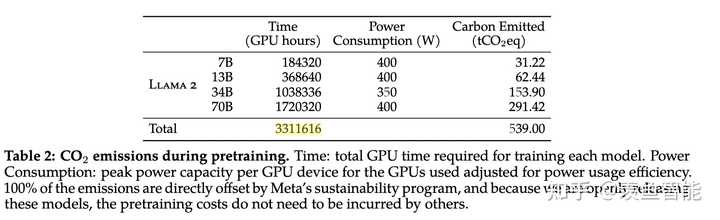

微调
SFT
SFT训练细节:


数据质量为王!




RLHF
这部分放出了很多的细节,挺有意思的,改天细看了再来更新。




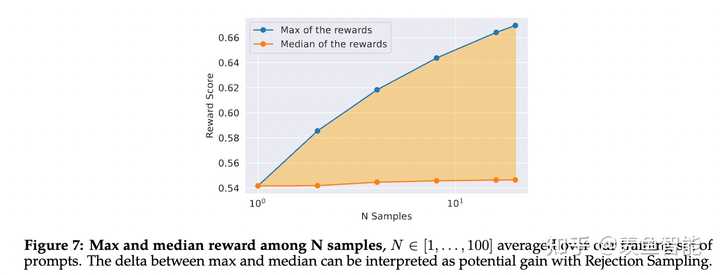



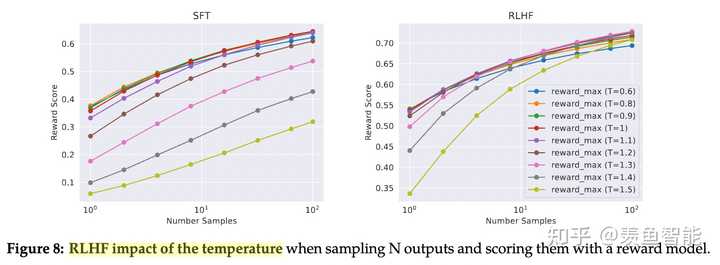

System Message for Multi-Turn Consistency


RLHF Results
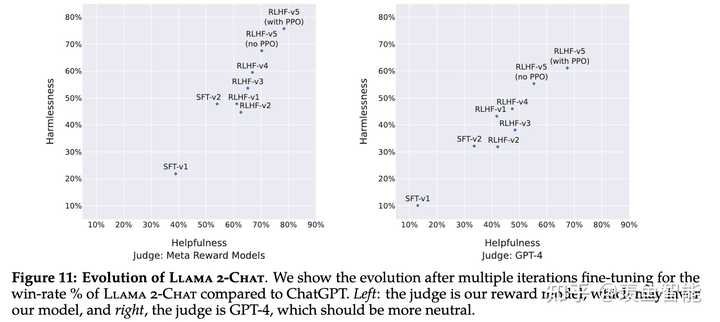


安全性
这个部分有空再看,对于有影响力的大模型及其产品来说非常非常重要!!!
参考资料
https://about.fb.com/news/2023/07/llama-2/
https://ai.meta.com/resources/models-and-libraries/llama/
https://github.com/facebookresearch/llama/tree/main
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://ai.meta.com/llama/open-innovation-ai-research-community/
编辑于 2023-07-19 02:41・IP 属地北京查看全文>>
OpenLLMAI - 23 个点赞 👍
当一家公司的新技术遥遥领先,眼看要独占一个行业,追赶者们应该怎么办?
2008 年,iPhone 发布后一年,各大手机厂商奋力研发操作系统追赶苹果。微软有 Windows Mobile、黑莓有 BBOS、诺基亚基于 Linux 系统开发了 Maemo、Palm 在秘密研发 WebOS……
又过了不到五年,还卖得动的智能手机要么来自苹果,要么装着开源的 Android 系统。现在,苹果的竞争对手们不再有属于自己的操作系统,但它们占据着超过 80% 的智能手机市场。
一整个行业围绕开源技术,协力对抗领先者,这一幕在今天的技术竞争中不断发生。
Windows 系统难以挑战,不满微软的科技行业将 Linux 变成了网站和互联网应用的操作系统。亚马逊 AWS 开创了云计算行业,阿里云、IBM 等竞争公司将 Google 的 Kubernetes(K8S)开源技术奉为标准。几乎所有移动处理器都依赖 ARM 架构,于是 RISC-V 正得到广泛的投资支持。
昨夜 Meta 又贡献了一个这样的例子。他们宣布将大语言模型 Llama 2 有条件地开源给商业使用(月活用户超过 7 亿需要单独申请),正是在牵头做大模型时代的开源标准。而 OpenAI 的密切合作伙伴微软,这一次成了 Llama 2 的首要合作伙伴。
微软是在同一天举行的 Inspire 大会宣布这项合作的,而且就在宣布的 2 分钟前,微软还在一张 PPT 上画着 “微软 OpenAI”。微软与有竞争关系的闭源 OpenAI 和开源 Llama 2 两头牵手,反映了如今大模型激烈的技术竞赛之外,多变的商业合纵连横。
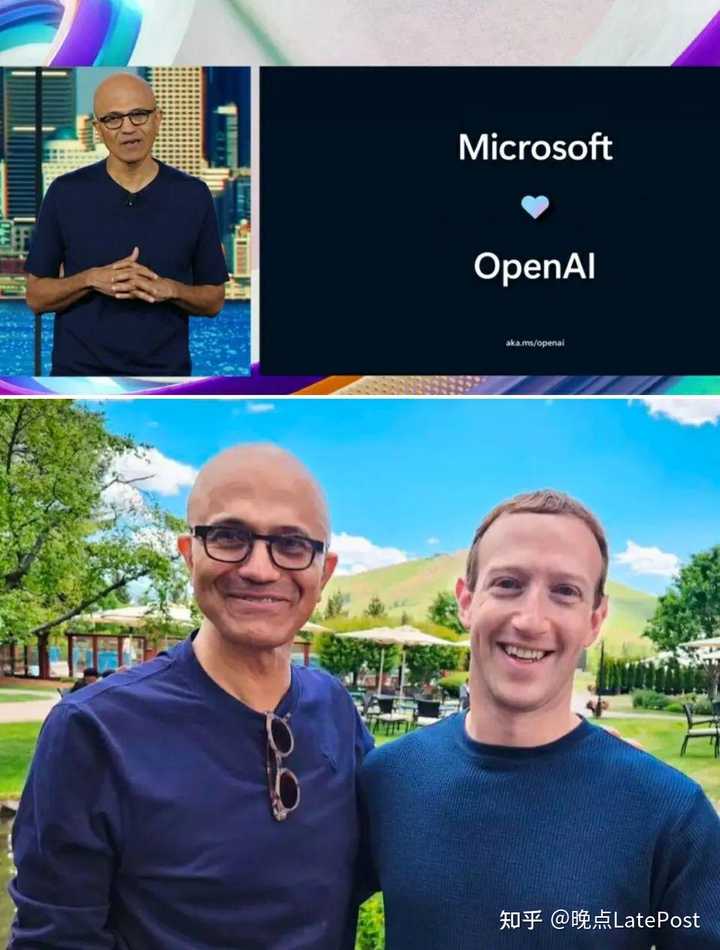

微软 CEO 萨蒂亚·纳德拉(Satya Nadella)发布会上强调微软与 OpenAI 关系亲密(上)。Meta CEO 马克·扎克伯格(Mark Zuckerberg)与纳德拉的合影(下),图片来自扎克伯格的社交媒体。
ChatGPT 去年底亮相后,全球大小科技公司和各类研究机构都在奋力追赶,造出了上百个大模型。而在 Meta 开源 Llama 2 之后,这些模型中的大多数还没有商用就已经过时。
“Llama 2 看起来非常强大(超越 GPT-3),经过微调的聊天模型看起来与 ChatGPT 处于同一水平。”HuggingFace 机器学习科学家内森·兰伯特( Nathan Lambert )说,“对开源来说是一个巨大的飞跃,但对闭源的大模型公司是一个巨大打击,这个模型(Llama 2)将满足大多数公司对更低成本和个性化的需求”。
水平在 GPT-3 到 GPT-3.5 之间
今年 2 月,ChatGPT 发布 3 个月,Meta 就开源了第一版 Llama 大语言模型。当时开发者能拿到的只是 Llama 预训练模型、且只被允许用作研究,而不是一个像 ChatGPT 那样针对特定任务或者需求训练过的应用。
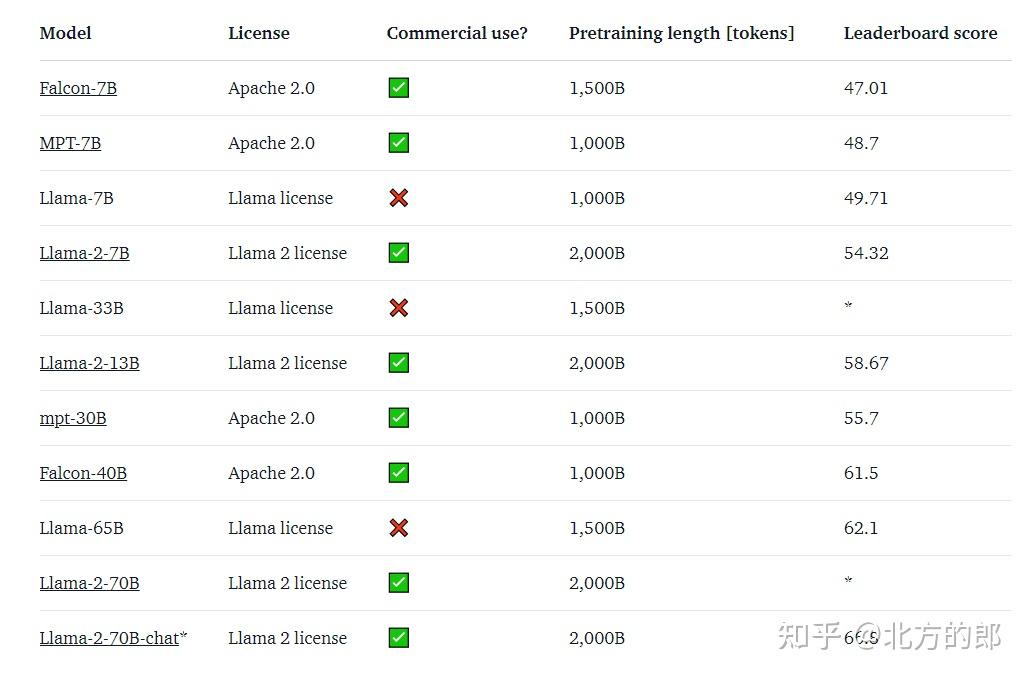
支持商用的 Llama 2 看上去更强。本次 Meta 一共发布 70 亿、130 亿和 700 亿三种参数规模的模型,其公布了模型训练数据、训练方法、数据标注等大量细节,展示了 Llama 2 的水平:
- 同等参数规模, Llama 2 能力超过所有的开源大模型;
- 700 亿参数的模型在推理层面接近 ChatGPT 背后的 GPT-3.5,但写代码的能力还有较大差距。
多位测试过 Llama 2 模型的开发者基本证实了 Meta 的说法:“代码测试环节挺不了 15 分钟”。70 亿参数的模型可以在 Mac 上运行,每秒钟能处理 6 个字符,比 Google 发布的 PaLM 2 最小的模型 “壁虎” 慢 70%。但 Google 并没有公布 “壁虎” 的具体参数。
根据 Meta 公布的信息,Llama 2 的训练数据(都来自公开数据)提升到 2 万亿个 Token(指一个常用单词、标点或数字),较第一代多 40%。其上下文长度扩展到了 4000 个字符,对文本语义的理解更强。
Meta 还像 OpenAI 那样,借助人类反馈强化学习(RLHF)机制,用 100 万人类标记数据训练出了类似 ChatGPT 的对话应用。这也是开源社区过去几个月微调训练 Llama 的常用方法。Meta 称 “大语言模型的卓越写作能力,从根本上是由 RLHF 驱动的。”
训练 Llama 2 可能并不便宜。HuggingFace 机器学习科学家内森·兰伯特估算 Llama 2 的训练成本可能超过 2500 万美元,不比 OpenAI 三年前训练 GPT-3 的花费少。他说,有充足的迹象表明,Meta 还在继续训练更强的 Llama。
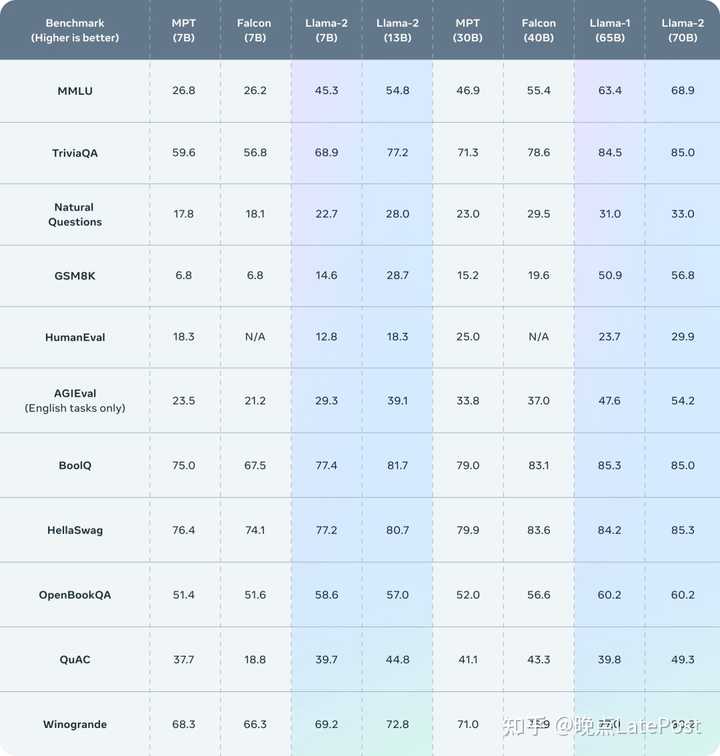

Meta 的 Llama 2 在多个数据集上表现好过其他开源模型。图片来自 Meta。
“改变大语言模型的市场格局”
作为基础设施,大模型在产品中处于底层。用户使用大模型应用,感受到的就是对话框和大模型处理过的内容,不会看到用的什么大模型、什么技术。
大模型的这个特点,一定程度上决定了它竞争局面——只要有更符合用户或企业需求的大模型出现,换起来的障碍并不高,甚至不会对用户造成太多负面影响。“如果大模型能力相差不大,只需要做一些调度工作就可以解决,开发量不大。” 一位 AI 开发者说。
有了 Llama 2 这样的开源大模型,自研的意义更小了。连竞争对手 OpenAI 的研究科学家、特斯拉前人工智能总监安德烈·卡帕西(Andrej Karpathy)都说,Llama 2 的发布是人工智能和大模型发展过程中的重要一天,“Llama 2 是任何人都可以拿到模型权重(参数特征,一个模型最关键的信息)的最强大语言模型。”
Meta 副总裁、人工智能部门负责人杨立昆(Yann LeCun)说,Llama 2 将改变大语言模型市场的格局。一位中国大模型创业公司高管解释了这句话:“很快就能看到许多开发大模型应用的公司,把基础模型换成 Llama 2”。
多位人工智能研究者认同杨立昆的说法,随着 Llama 2 发布,Meta 可以用开源、支持商用的策略会改变大模型的格局和生态。
今年 6 月,美国红杉资本发现在其投资的 33 家创业公司和上市公司中,65% 已经上线了大模型应用、94% 正用 OpenAI 的大模型接口(API)开发应用。
它们使用大模型的方法大多较为简单:直接调用 ChatGPT 的接口处理私有数据完成特定任务,如多语言互译、生成文本或者网页内容摘要等。很少有公司会做更深入的开发,比如用大量数据微调模型。
在中国,许多公司选择从头收集数据或者用公开数据集训练大模型,过去半年发布了 80 多个大模型,不乏有公司和机构开源模型,把支持商用当做竞争点,然后做起生意。
《晚点 LatePost》了解到,中国一家备受关注的大模型创业公司推出的开源 60 亿参数大模型,企业想买商用授权要花百万元,近期宣布免费;没有开源的千亿参数模型,售价每年上千万元。
一位上市公司人工智能部门负责人 5 月告诉《晚点 LatePost》,他们打算用 OpenAI 的 GPT-3.5 开发功能,但成本太高——每天成本预计上万元,而且想定制做开发很困难,也不支持同一时间响应大量用户的请求。
最后他们选择了参数量更小的 Llama(60 亿)和一个中国公司的开源大模型,这意味着训练和部署成本更低,而且经过数据微调后,在他们的业务场景中,基于 Llama 与中国开源模型的开发效果和使用 GPT-3.5 差别不大。
中国大模型公司当时的另一个优势是可以谈商业授权,而 Llama 不能。当 Llama 2 开始允许商用,中国大模型公司的这一优势现在也没有了。
开源大模型正迅速追赶
ChatGPT 去年底刚发布时,它凭看上去充满意义的回复和强大的写代码能力等功能震撼了世界。许多公司都在关注怎样才能做出一个类似的产品。
半年多过去,从大公司到普通程序员,都能借助开源社区做出来一个类似 ChatGPT 的应用。云端开发平台 Replit 发现,使用他们服务的开源大模型的项目数量,每个季度都在翻倍。
在 Llama 等开源大模型基础上,开发者们做出了各种开源数据集,比如基于人类反馈强化学习(RLHF)的数据集,持续提升开源大模型的能力。
根据加州大学伯克利分校、卡耐基梅隆大学等高校多位教授和学生成立的 LMSYS Org 评估,过去几个月,开源大模型与 GPT-4 的差距正明显缩小——从相差 191 分到近期的 115 分。在追赶过程中,开源社区还先大公司一步做出了在电脑、手机上运行的大模型,比 Google 早一个多月。
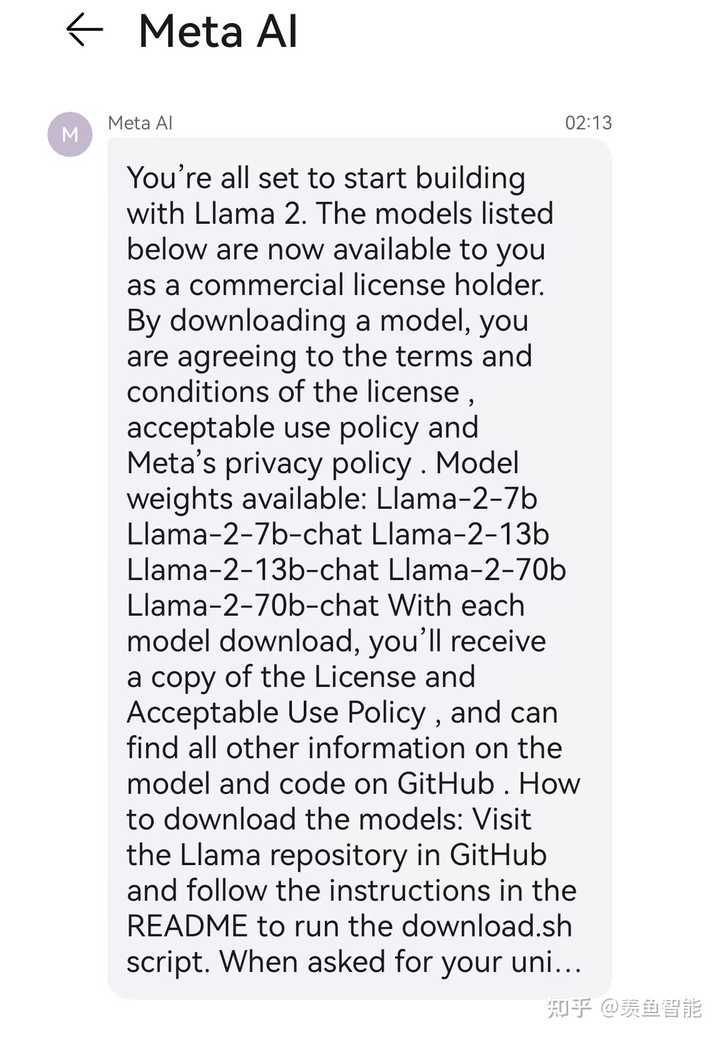
随着 Meta 开源 Llama 2,大模型开源社区的力量将会变得更强。Meta 称, 第一版不支持商用的模型开源后,他们收到了超过 10 万个研究人员的使用申请——这还没算那些直接从网上下载模型的人。
“大公司的人工智能研究人员因为开源许可问题对第一版 Llama 持谨慎态度,现在我认为他们中的许多人会跳上这艘船(Llama 2)并贡献他们的火力。” 英伟达资深人工智能科学家 Jim Fan 说,就算现在 Llama 2 编程能力不行,开源后很快就会追上来。
这次 Llama 2 最大开源参数版本(700 亿)的参数还不到 OpenAI 三年前训练好的 GPT-3 的一半,但效果好于 GPT-3,就是最好的例证之一。
开源的逻辑偏向于大模型达到一定能力后,就扩大新技术的覆盖范围,让更多人使用技术,然后从大量应用中改进模型。而闭源的公司,如 OpenAI 更偏向于技术领先,研发强大模型后再推广给更多人。
就像 iOS 与 Andriod 在手机操作系统上的竞争,开源与闭源的竞争并不都是在同一维度上的短兵相接,大模型领域也会出现类似的分化。
在这种新的竞争格局下,连 Google 都没有信心继续保持领先。
今年 5 月,Google 一位高级工程师在内部撰文称,尽管 Google 在大模型的质量上仍然略有优势,但开源产品与 Google 大模型的差距正在以惊人的速度缩小,开源的模型迭代速度更快,使用者能根据不同的业务场景做定制开发,更利于保护隐私数据,成本也更低。
“只需要几周时间,他们用 100 美元和 130 亿参数的模型,就能做成我们花 1000 万美元和 540 亿参数模型很难做到的事情。” 他说,“我们没有护城河,OpenAI 也没有”。
昨天,Meta 在宣布 Llama2 开源后解释说,开源对于当今人工智能模型的发展是正确的,尤其是在技术迅速发展的生产领域,“通过公开提供人工智能模型,它们可以惠及所有人ーー而不仅仅是少数几家大公司”。
一场不同于过去的新式竞争正在生成式人工智能领域开展。开源社区凭借开放协作的力量,正在以惊人的速度追赶商业巨头们建立的领先优势。而过去习惯于技术封闭和市场垄断的大公司,也在逐步拥抱开源。(文丨贺乾明 编辑丨龚方毅)
编辑于 2023-07-20 16:18・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
晚点LatePost - 19 个点赞 👍
Llama几乎是以一己之力开创了开源大模型领域,现在Llama 2出来了,就模型本身来说,起点高了,官方自带RLHF版本,门槛低了,二次开发可以直接放权重,节省很多工序。最重要的是,模型结构变化不大,昨天专门试了,1能用的2基本也能用,没有出现因为模型升级导致配套工具断代的情况。
还有一个讲的不多但很重要的地方是氪金。谷歌前面说,因为有开源社区,我们(指谷歌和OpenAI)没有护城河,但大模型多少还是有些地方是氪金密集型,讲究用爱发电的开源社区这块是短板。现在买它AI推了Llama 2,氪了多少?有人估计训练成本高达2500万刀。
什么概念呢?之前估计GPT-3训练一轮大概140万刀,总成本大概1200万刀,这些数都是投行估的,但大致可以给一个结论,这次的Llama 2是重氪,野心自不待言。开源生态接下来会有怎样的飞跃就更值得期待了。
再说说Llama和开源生态。
时间拨回2022年12月,那时候ChatGPT刚出来,大家反映分成截然相反的两种,一种是兴奋,一种是绝望。
兴奋说的人很多,不说了,说说绝望。当时我就是绝望派的一份子。
LLM的效果如此拔群超乎所有人的意料,整个NLP领域为之震动。举个例子,现在LLM已经很多了,很多人测新的LLM都喜欢要求解释梗。玩得多了大家都觉得没什么,但在以前这是个很难的问题,可能要专门训练,可能还得搞几套系统配合。
但是LLM轻而易举。需要说明一点,主流LLM是没有专门针对解释梗进行训练的,单纯就海量知识储备和强大推理能力大力出奇迹的副产品。同样,用LLM去做从前需要专门训练的任务,很多也取得了很好的成绩。
所以现在NLP多了一个词,叫通用大模型。别因为熟悉就小看了这个,以前远在天国的AGI因为通用大模型的出现,感觉近了不少。
但是,绝望来了。LLM效果拔群归拔群,但想想训练一个LLM所需要投入的成本,太多的不说,以后你想研究NLP?8卡A100,你能不能掏的出来?
结论两个字,绝望。
但是,Llama出来了。
准确来说,开源大模型背后靠的是一个庞大的开源生态做支撑,有开源数据,有训练方法,有加速工具,有落地方案,更重要的是,开源大模型已经产生了足够的生态位,哪怕你只有一张3090,你也可以找到合适的位置嵌入其中。
开源大模型是无数人用钱用爱发电的结果,甚至强如谷歌、OpenAI也要敬畏三分。背后庞大的开源生态规模更是难以想象。
而Llama其实只是其中的一部分。
Llama刚出来的时候恨不完善,纸面性能距离ChatGPT不太远,但上手感觉差太多,是开源社区用愚公移山的精神,一点一点把它缺的都给补上。最直观一点,Llama不支持中文,这个问题很严重,不是说训练数据加点中文语料就行了,人家是从token层面就不支持。大家想了很多办法,在很多版以后,才成功用扩充词表+Lora的方法,让Llama基座也能执行中文任务。
到了现在,其实也就半年,Llama的重要性已经大为削弱,因为现在已经有了太多的选择。得益于开源生态的正向buf,炼LLM的成本一下低了很多,很多家里有点钱但不多的企业和研究团队也都炼起了自己的LLM,国内就搞了很多开源模型。有人说国内的开源模型是别人做好了直接抄,那是搞不懂什么是开源,更贬低了开源生态的价值。
不过,Llama有它的历史地位。如果说开源大模型和背后的开源生态是一座雄伟的殿堂,Llama则是开启这座殿堂的钥匙。OpenAI的闭源是让很多人都憋着一股劲,但正因为有了Llama,大家有劲才有地方使。
编辑于 2023-07-20 11:32・IP 属地广东真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
木羊 - 17 个点赞 👍
我们基于 LLaMA 系列模型(包括 LLaMA2)开发了 LLM-Tuning Web UI,利用 QLoRA 方法可以在 24GB 显卡上完成 LLaMA 模型的二次预训练、指令微调和 RLHF,欢迎关注我们的框架:
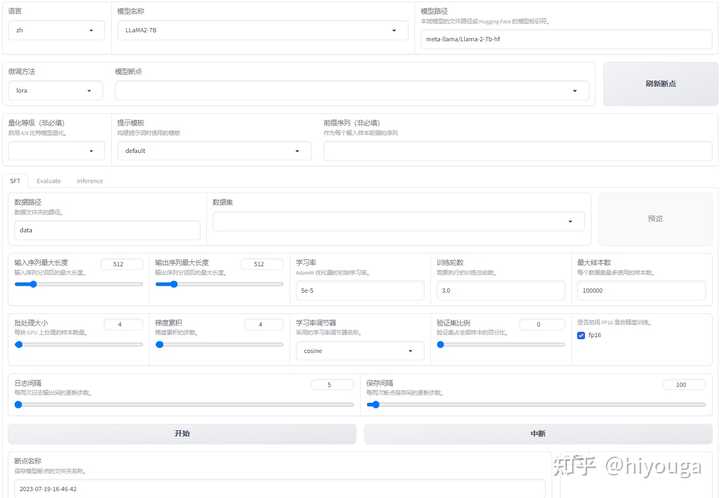
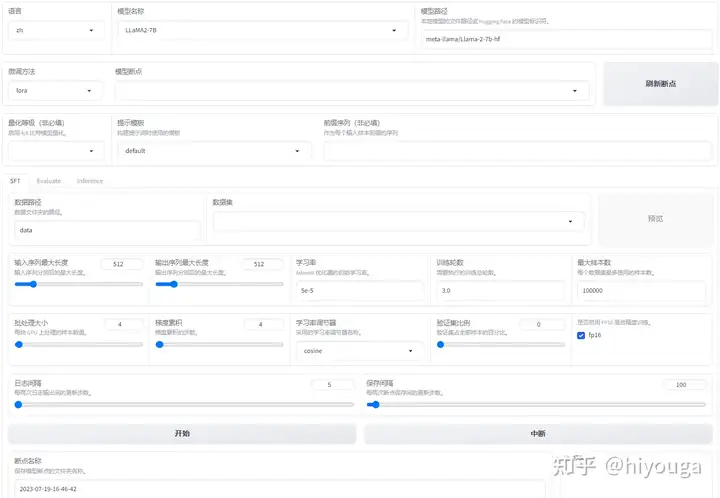 发布于 2023-07-19 21:58・IP 属地北京
发布于 2023-07-19 21:58・IP 属地北京查看全文>>
hiyouga - 9 个点赞 👍
1、huggingface已经有人偷偷把weights放出来了(不用权限)
2、与llama-v1不同,llama-v2新增了chat系列,其主要归功于Supervised Fine-Tuning (SFT)、Reinforcement Learning with Human Feedback (RLHF),论文对这方面的细节描述很丰富,值得细读,这个technical report可不是closedAI的那种technical report,为我们这种小作坊进行LLM与人类对齐研究提供了工业级别研究的参考视角,极具价值!
顺便说一句,这里给人的感觉就像是llama团队对整个社区基于llama-v1做chat类LLM的总结一样,不知道有了chat版本的llama-v2后,社区还能怎么进一步玩出花(继续instruction-finetuning?)




Paper link:
3、除了Fine-tuning,文章的剩余篇幅对Safety做了很详细的介绍,整整12页内容(占比约12/34),对于后续做LLM安全很有参考价值。
不过,很多网友也调侃到,这个好像做的有点“过度安全”了
 编辑于 2023-07-20 21:49・IP 属地湖北
编辑于 2023-07-20 21:49・IP 属地湖北查看全文>>
Courage Lee - 7 个点赞 👍
通读了一下Llama 2的技术报告[1],浅浅记录一下其中一些跟common practice不一样的地方,以及我觉得比较有趣的一些findings
SFT阶段的数据质量
作者们指出花了很多时间在控制SFT阶段的标注质量上,并用Quality is all you need作为了这一小节的的标题,他们认为,几万级别的有监督数据就足以训练出一个很好的SFT model.
We found that SFT annotations in the order of tens of thousands was enough to achieve a high-quality result. We stopped annotating SFT after collecting a total of 27,540 annotations.
我对这个观点赞同一半,数据质量确实非常的重要,但规模也同样重要;一个用于支撑这个观点的证据是 选择将指令的complexity和diversity scale起来 的 13B的 OpenChat和WizardLM 在AlpacaEval上的得分竟然要比LLAMA2 Chat 70B要高,尽管AlpacaEval的评测不是绝对的comprehensive,但也足以反映 指令的规模(多样性和复杂度)的重要性了
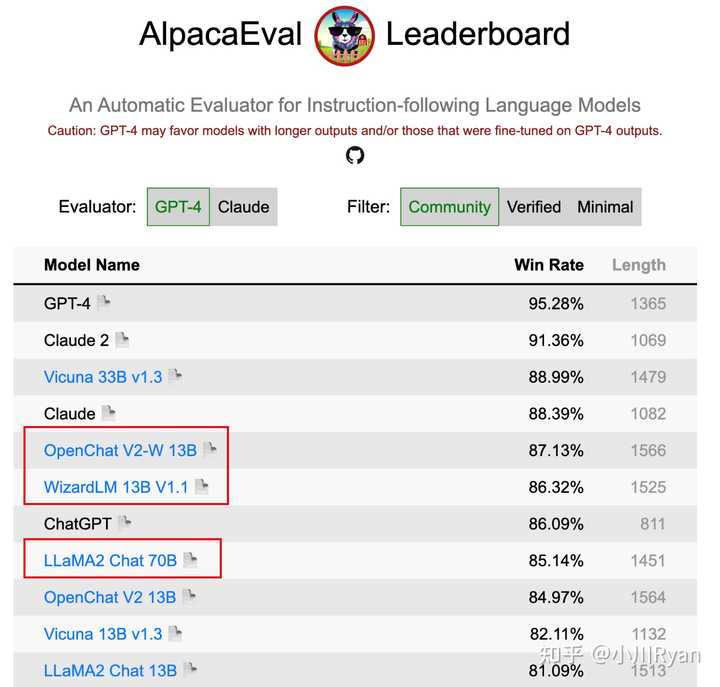
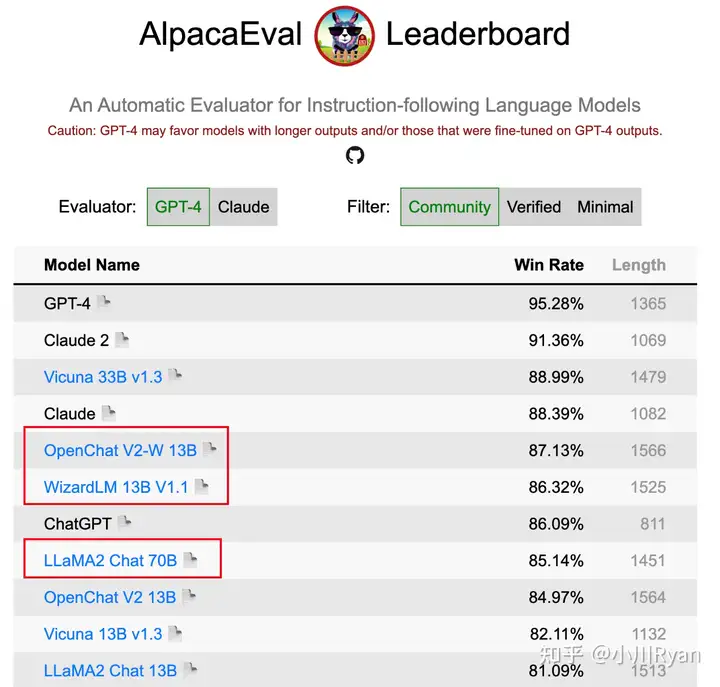
AlpacaEval的排名结果(截止07.21) 当然一个比较关键的原因可能是,这些开源组织或个人可以选择去蒸馏ChatGPT/GPT-4的输出,但Meta作为竞争对手不能也不适合这么干
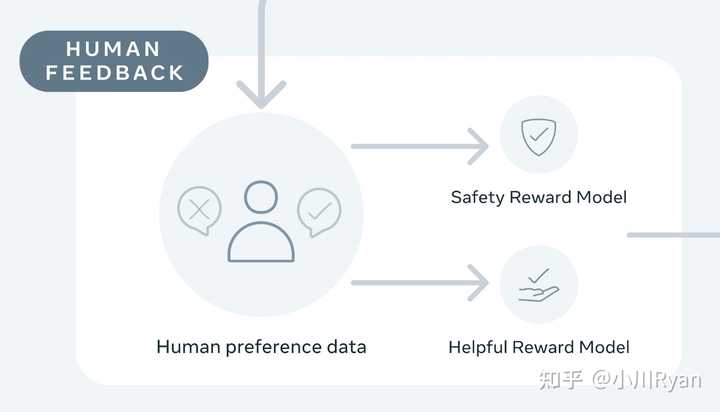
Human Preference建模的不同
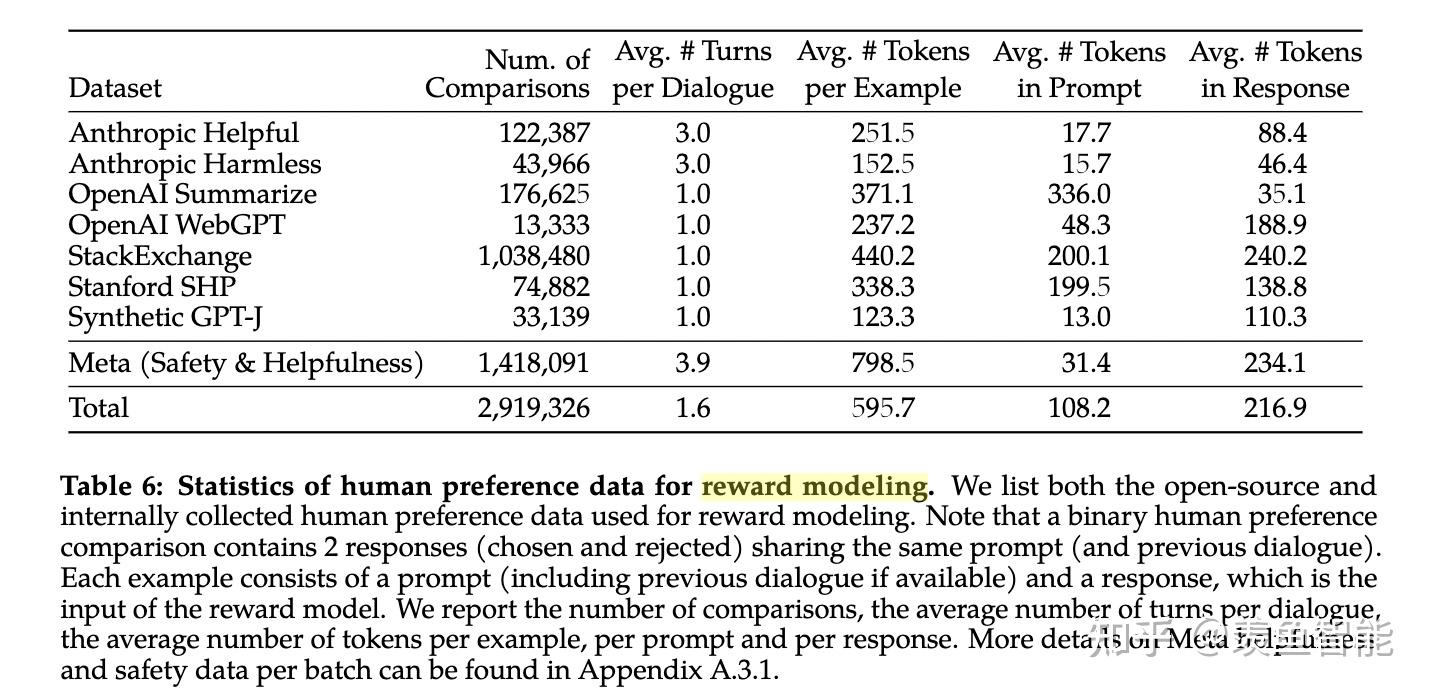
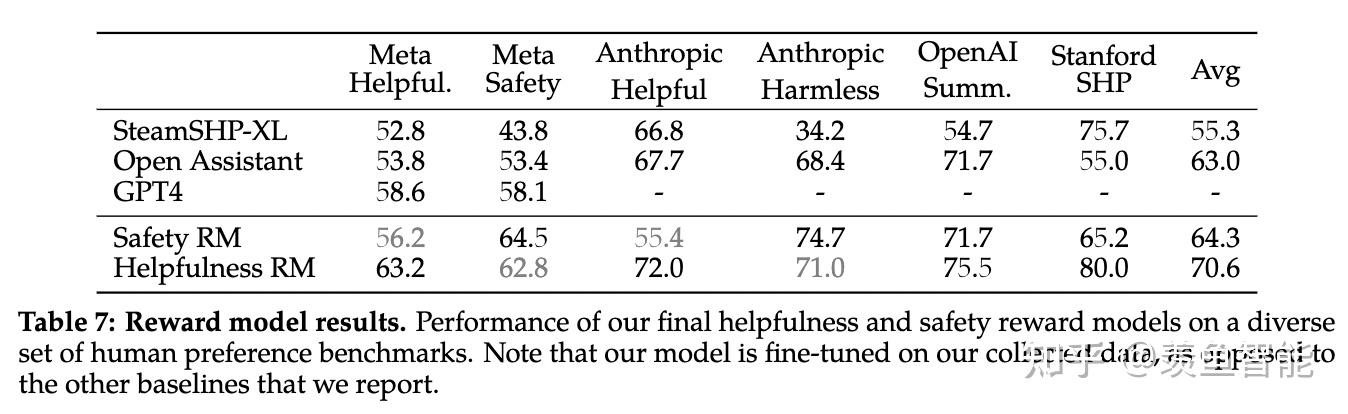
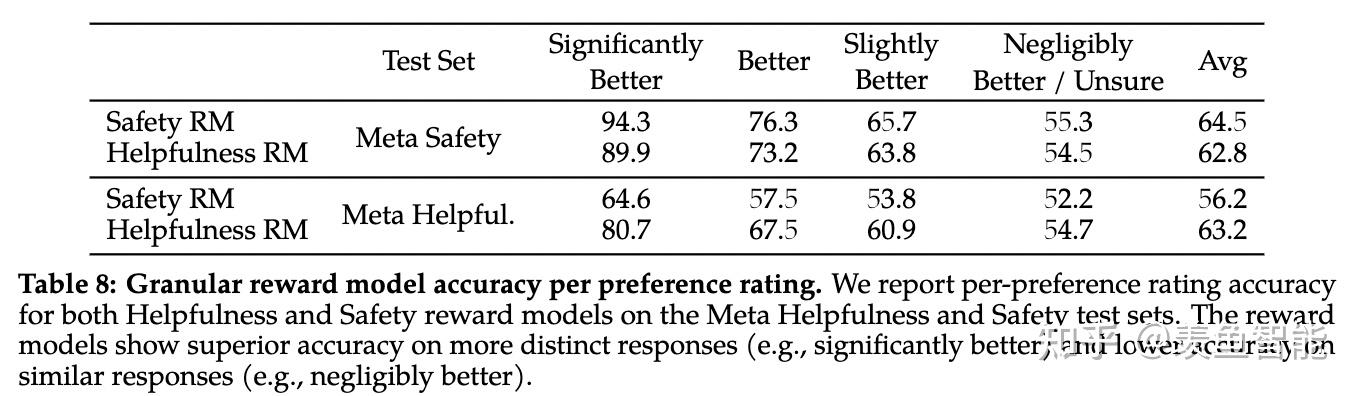
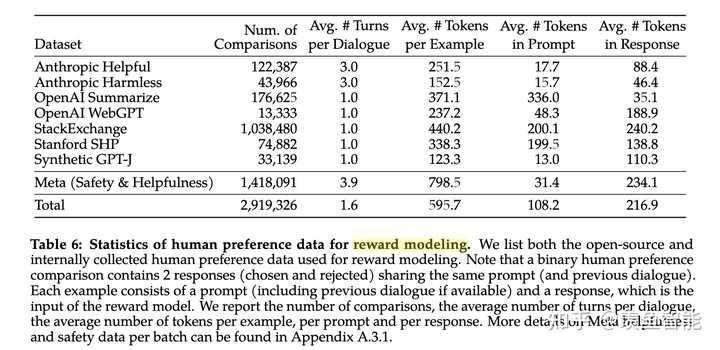
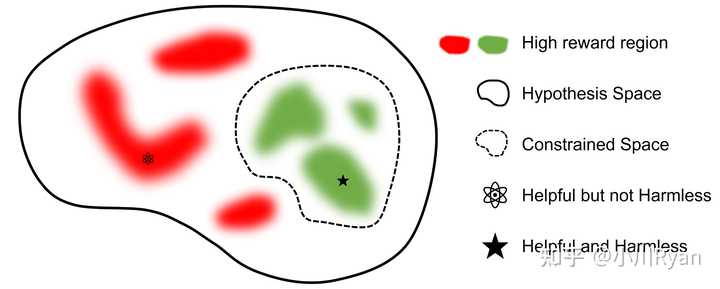
llama2选择像Anthropic一样,对Helpful和Harmless分开建模,分别为Helpfulness和Safety标注了一批数据、训练了一个reward model,总共标注了一百四十多万条的preference data;这也反映了reward model的重要性,后续除了RLHF的过程,很多处用到了reward model进行打分

但这一部分他们缺失了一个很重要的引用,就是我们国内学者做的Beaver项目:
同样是一个很好的项目,同样将Helpful和Harmless分开建模(只不过他们称之为reward model和cost model),比llama2早发布了两个月有余:

图源自Beaver(https://github.com/PKU-Alignment/safe-rlhf) 训练目标上,为常用的ranking loss增加了一个动态决定的margin(由标注者对于两个答案的rating决定):
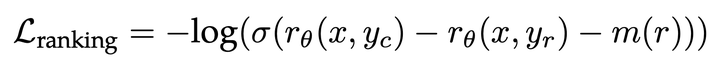

起到了一定的效果:
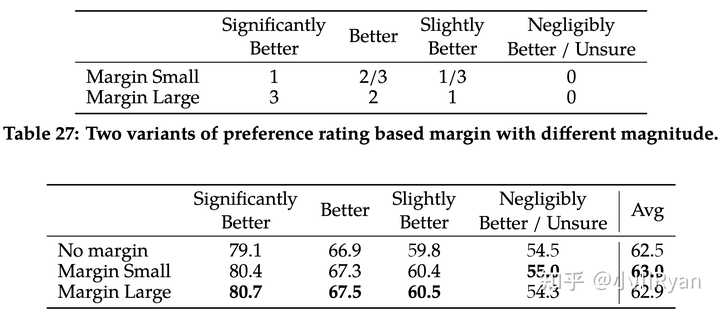

比较让人惊喜的是他们还研究了训练两种reward model时候的数据配比问题
After extensive experimentation, the Helpfulness reward model is eventually trained on all Meta Helpfulness data, combined with an equal parts of the remaining data uniformly sampled from Meta Safety and from the open-source datasets. The Meta Safety reward model is trained on all Meta Safety and Anthropic Harmless data, mixed with Meta Helpfulness and open-source helpfulness data in a 90/10 proportion. We found that the setting with 10% helpfulness data is especially beneficial for the accuracy on samples where both the chosen and rejected responses were deemed safe.
也表示用了开源的偏好数据进行冷启动,这部分数据带来的多样性也起到了防止仅用llama2的response用于训练偏好模型可能产生的reward hacking的问题:
Thus, we have decided to keep them in our data mixture, as they could enable better generalization for the reward model and prevent reward hacking, i.e. Llama 2-Chat taking advantage of some weaknesses of our reward, and so artificially inflating the score despite performing less well.
RLHF训练过程的不同
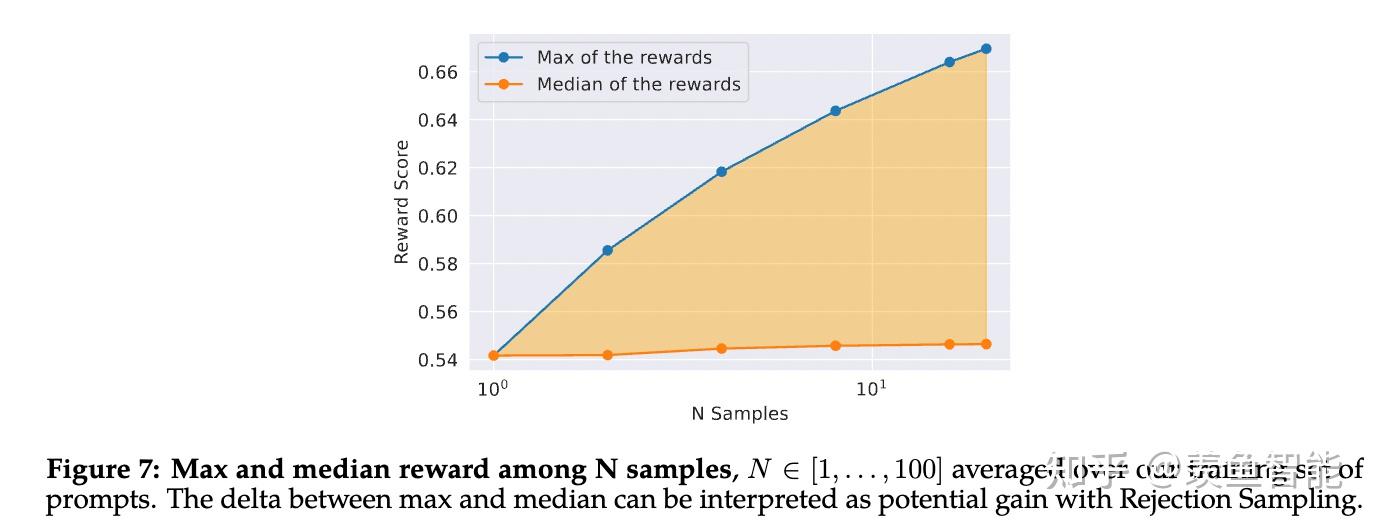
作者们除了采用常用的PPO算法,还尝试了用rejection sampling得到的数据进行微调的方案,即令模型对一个prompt输出多个答案,收集reward model打分最高的response用于微调。他们认为rejection sampling扩充了采样的多样性(相较于PPO总是用从上一步的policy的输出中学习)
而用于训练PPO的奖励模型的输出也 对应于Helpful和Safety的reward model 进行了一定的调整,以提高模型的安全性:


他们也模仿Anthropic采用了在线训练的方式:即随着policy的升级,采用 人类对于新policy的输出的偏好 用于进一步训练reward model,这样有利于令其保持与新policy同步(不然新policy的输出对于奖励模型而言会导致其一定程度上的泛化困难进而效果变差),他们认为这是在RLHF过程中很重要的一点
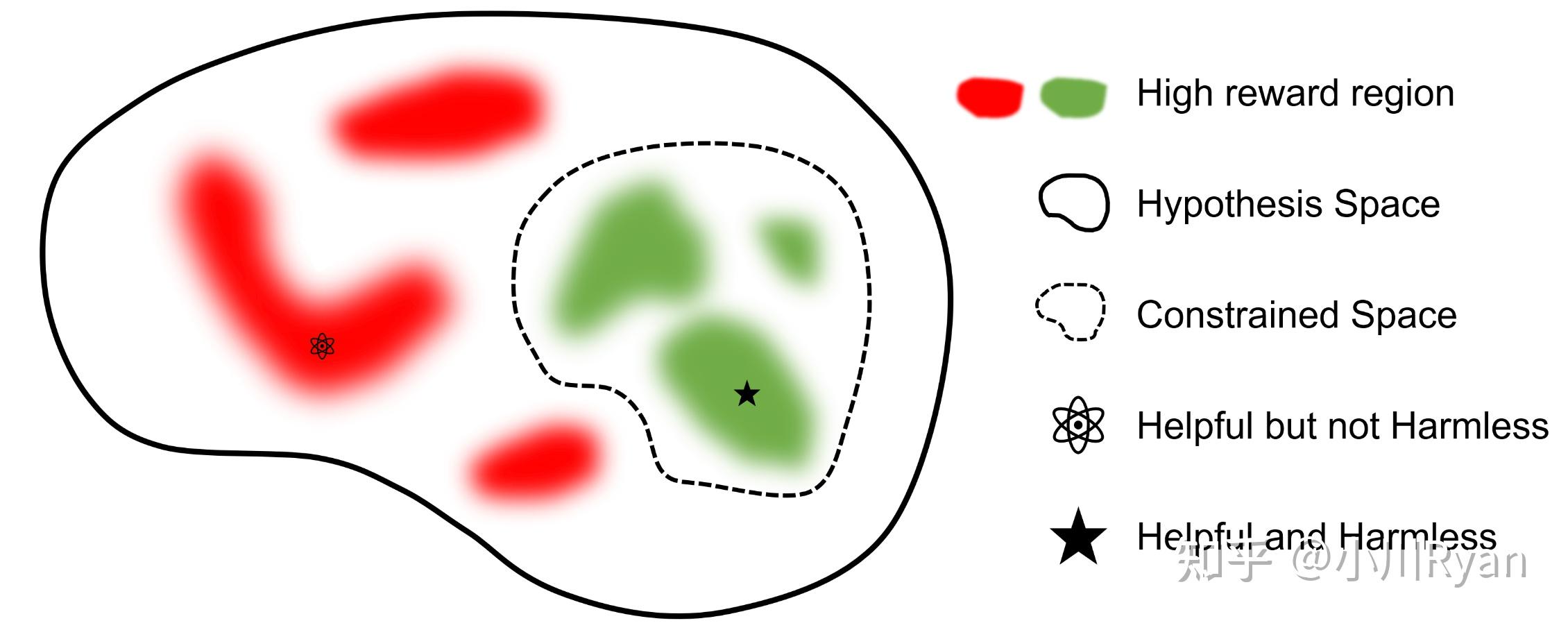
Helpful v.s. Harmless
Anthropic在[2]中提到Helpful和Harmless的训练目标会有一定程度上的冲突,这一点也比较直观(例如对于那些有害的问题,我们希望模型生成更加Harmless的回复,则其相应的helpfulness就会降低);而llama2的作者们也专门调研了这一点:
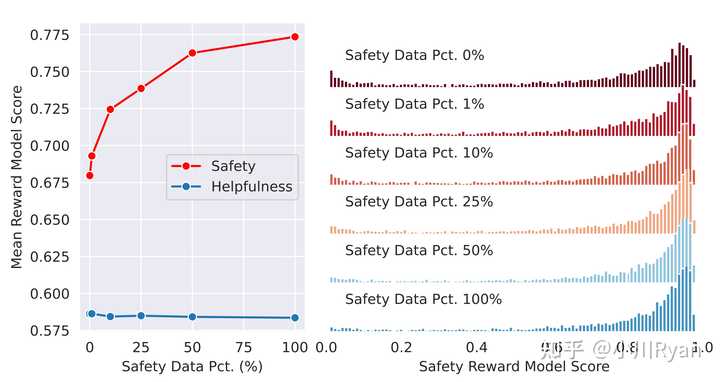

他们发现只要Helpful的训练数据足够多,在Helpful上的得分受影响就会很小,而模型的安全性会随着Safety的训练数据scale起来而越来越好
Given sufficient helpfulness training data, the addition of an additional stage of safety mitigation does not negatively impact model performance on helpfulness to any notable degradation.
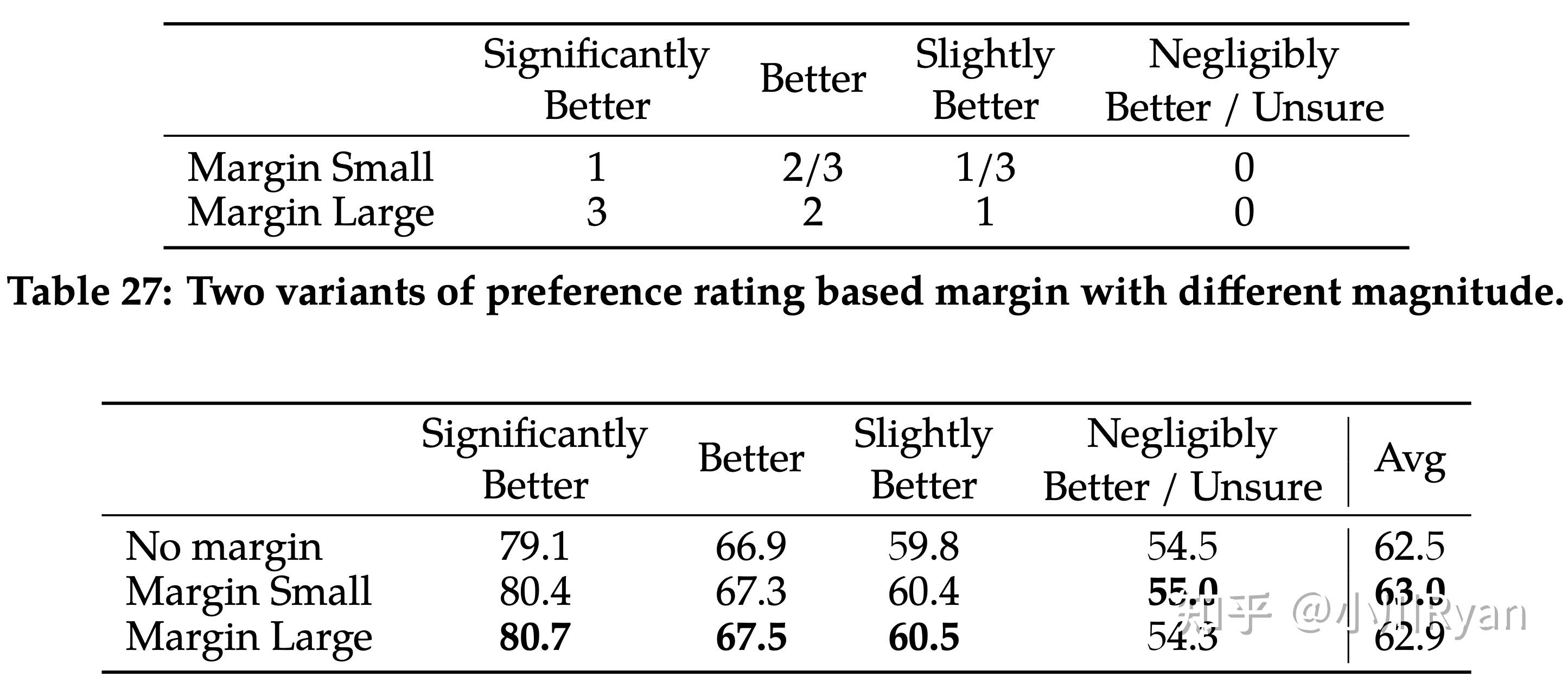
同样也研究了Helpful和Safety数据的配比
In this ablation experiment, we keep the amount of helpfulness training data unchanged (∼0.9M samples) and gradually increase the amount of safety data used in model tuning, ranging from 0% to 100% (∼0.1M samples).
Context-distillation对于Safety也是有用的
所谓context distillation (for safety)是指采用一些Safe的prompt去提示LM,限制其生成response的搜索空间,得到的答案往往会更加安全;然后再拿这部分问题和response去微调模型(不带Safety prompt)。作者们利用训练好的reward model定量地分析了这一点,发现了context distillation对于harmless会带来明显的增益:
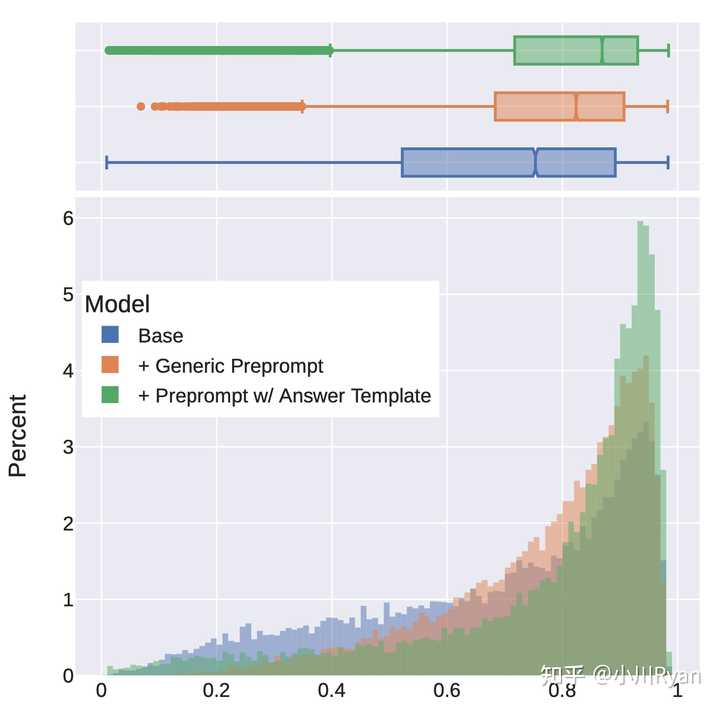

但他们还观察到了使用context distillation可能会导致模型对于一些问题的回复更加回避(evasive)了,即模型本来的输出就已经很安全也很engaged了,此时加入一段safe prompt反而降低了回复的质量
It is important to note that performing safety context distillation for helpful prompts can degrade model performance and lead to more false refusals
为了缓解这个问题,作者采用reward model来做一个决策:即只对哪些原本回复得没有那么安全的问题前面添加Safety prompt,这样可以很大程度上改善这一问题:
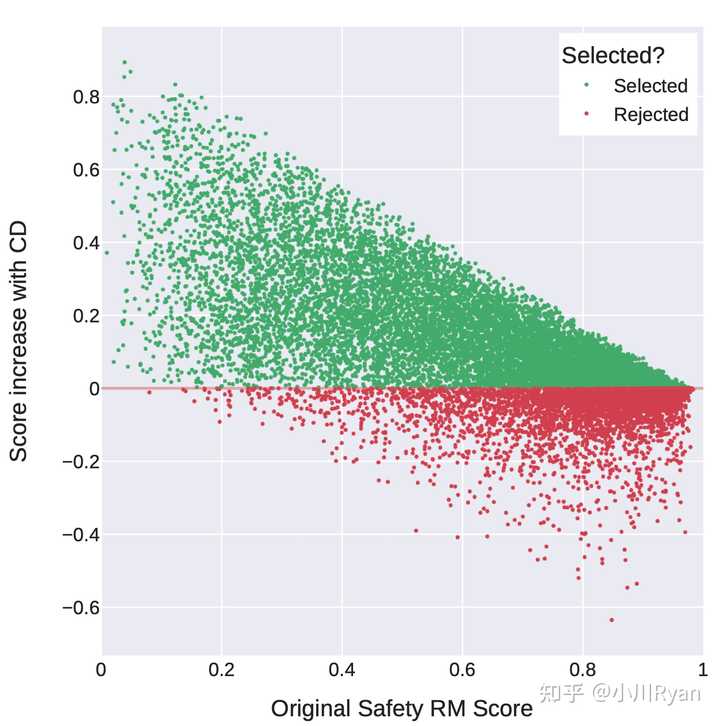

Safety得分低的才选择用context distillation,高的不用(rejected) 到底该不该用强化学习
论文中一个比较有趣的部分是,作者们经过llama2的训练后,对强化学习的使用产生了很大的改观;他们最开始觉得还是有监督的训练 监督信号会更加密集:
At the outset of the project, many among us expressed a preference for supervised annotation, attracted by its denser signal. Meanwhile reinforcement learning, known for its insta- bility, seemed a somewhat shadowy field for those in the NLP research community.
后来发现还是强化学习更适合用来scale oversight,因为SFT阶段很大程度上受限于标注者编写的response的质量,而人类判断两个答案哪个好要比他们自己编写一个很好的答案要容易得多,甚至模型回复的内容有时比人类写得要更好;作者认为RLHF训练的过程在于保证Preference model和policy更新的协同
However, reinforcement learning proved highly effective, particularly given its cost and time effectiveness. Our findings underscore that the crucial determinant of RLHF’s success lies in the synergy it fosters between humans and LLMs throughout the annotation process.
In addition, during annotation, the model has the potential to venture into writing trajectories that even the best annotators may not chart. Nonetheless, humans can still provide valuable feedback when comparing two answers, beyond their own writing competencies. Drawing a parallel, while we may not all be accomplished artists, our ability to appreciate and critique art remains intact. We posit that the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF, as documented in Gilardi et al. (2023) and Huang et al. (2023). Supervised data may no longer be the gold standard, and this evolving circumstance compels a re-evaluation of the concept of “supervision.”
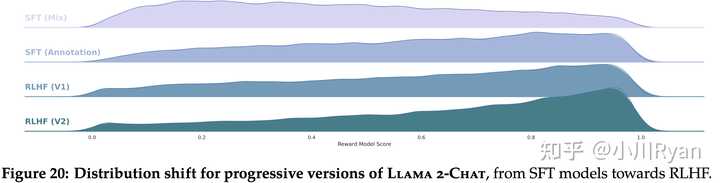

当然除了这些,文章还提供了很多关于Safety的评测、red-teaming的最佳实践等等,很惊喜作为一个开源模型会把这么多的精力放在harmless上。并且meta终于体面了一回,把所有模型都开源了(虽然有时候也会小小地期待它能不能彻底体面一次,把SFT和Preference data也彻底开源出来,meta你听得到吗)
另一个感受是还是公司更擅于集中力量干大事,可以把劲都使到一块儿去。至于大家比较关注的代码能力和中文能力,可能手速佬明天就甩出来一个代码性能double的版本,同时也已经有很多大佬在做中文适配了。
参考
- ^https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- ^(Bai et al., arxiv2022) Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
编辑于 2023-07-22 00:11・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
小川Ryan - 2 个点赞 👍
记录一下关于LLaMA-2的技术要点与洞察,如有理解的不确切的地方,欢迎指正。(如需转载,请署名)
0. TL;DR:
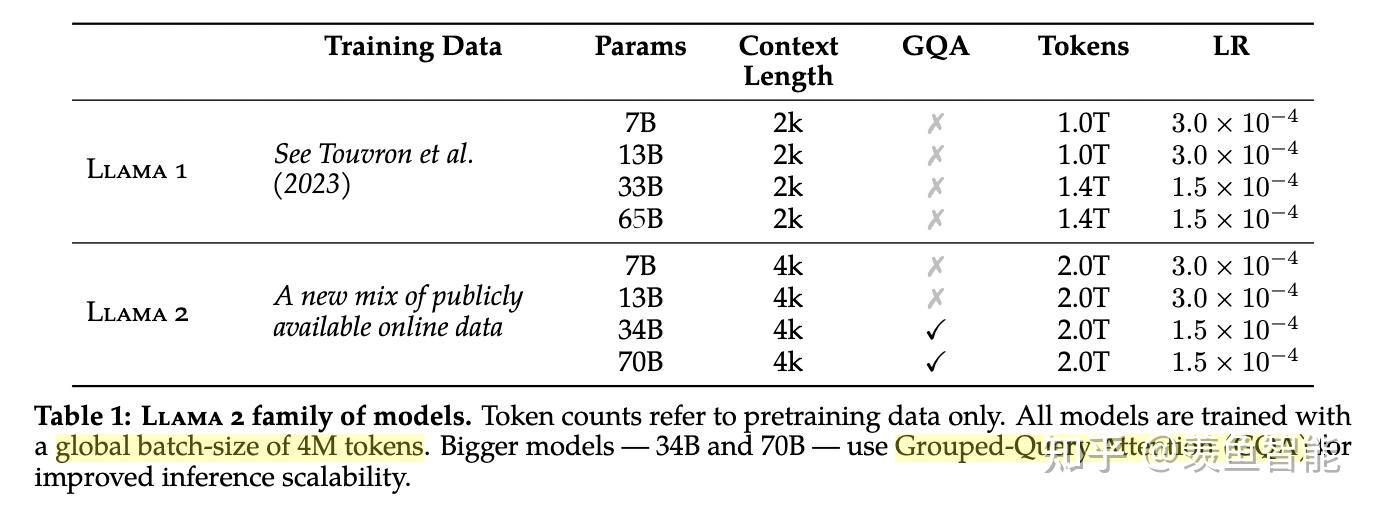
基座模型:开源了LLaMA-2,基于新的数据配比训练的,增加了40%的数据量,上下文长度翻了个倍,现在是4K,采用了Group-Query Attention。开源了7B,13B,和70B的模型,当然还有个34B的,但是没用开源。
对话模型:对基座模型做了对话场景上的优化,也开源了对应的7B,13B,和70B版本的对话模型。这篇技术报告花了很大的篇幅来介绍RLHF,Safety,Alignment上的优化和评估,(以至于有人感觉都优化过头了...,毕竟是大公司,也理解),对做alignment相关方向的同学是个很好的参考。
1. 预训练
做了更鲁棒的数据清洗,更新了数据比例,对包含事实性更多的数据源做了上采样,以此增强模型的知识能力,缓解幻觉问题,增加了40%的训练数据量,增加到了2T的tokens,无论多大的模型都是2T的量,发现也可以进一步提升小模型的能力;
训练细节上大体上与一代差不多,标准的Transformer架构,用Pre-Norm,RMSNorm(T5也用的这个),SwiGLU的激活函数,旋转位置编码(RoPE),采用了Group-Query Attention,在不降低性能的情况下提升效率;
关于Group-Query Attention:自回归解码的一个标准方案是把之前token的K和V缓存起来,空间换时间,随着上下文长度和batch size的上涨,显存占用也在急剧上涨。可能的缓解方案有:multi-query attention (K和V的投影只用一个头,不是多头),group-query attention (K和V的投影用8个头),实验发现,GQA的效果相对于在绝大多数任务上与MHA持平,比MQA稍好;(听上去也比较直觉,毕竟有更多的参数)
分词器用BPE,对于所有的数字都将其切分成一个一个的单独的位(这通常对于一些算术运算相关的任务很重要),词表大小32K;
用的是Meta的超算做的预训练,如果以10000张80G A100为单位,训练7B,13B,34B,70B模型分别需要18h,36h,4.3天,7.2天...
评估结果:
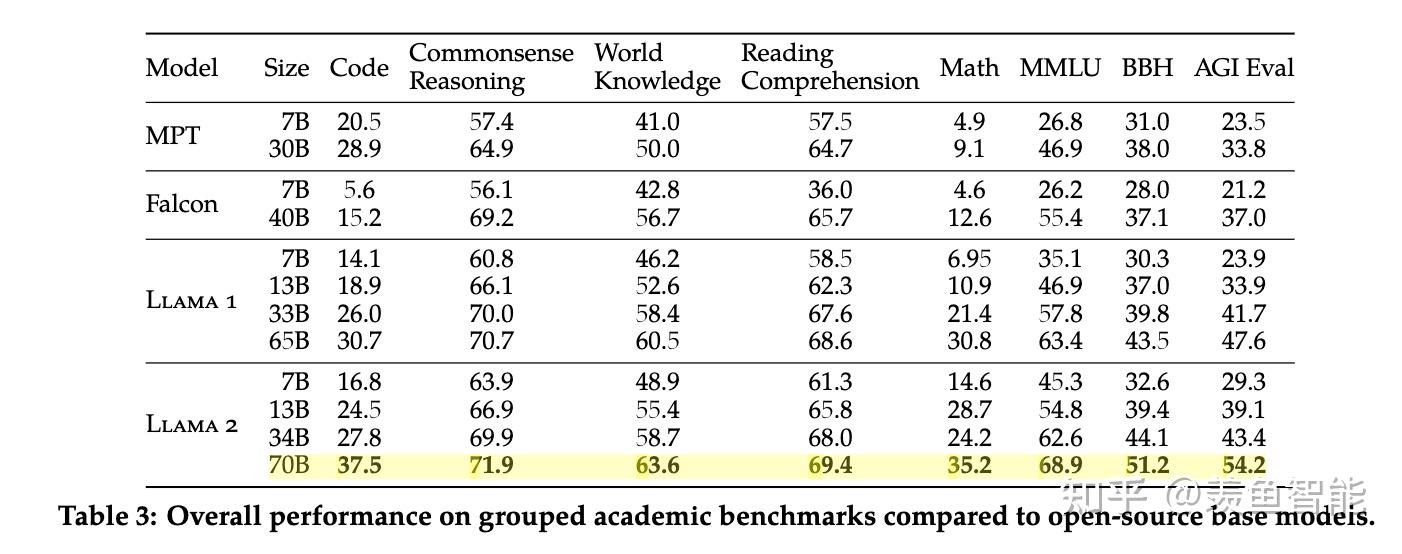
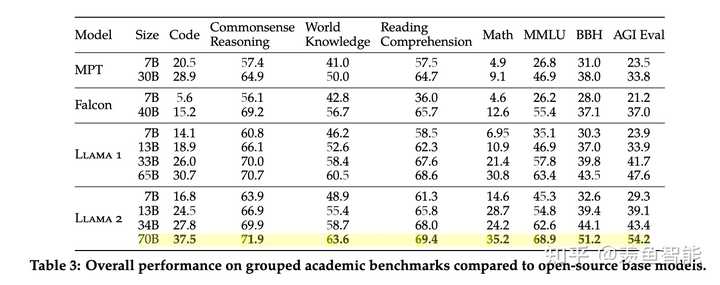
在代码,常识推理,世界知识,阅读理解,数学推理等常见基准上做了评估,相比一代的LLaMA取得了显著的提升,同时也优于开源的MPT和Falcon等模型,70B的LLaMA-2在MMLU和GSM-8K上接近GPT-3.5,但是代码生成任务上性能较差。
2. 微调
为了得到安全的对话模型,作者们在对齐上做出了很大的努力,这一阶段包括SFT和RLHF。
2.1 SFT部分
数据质量很重要。作者发现虽然开源的指令微调数据很多,但是质量和多样性也不够高。作者发现只要数据质量够高,并不一定需要很多,这一点与LIMA的观察相似,最终,自己标了27k条左右的指令数据。
训练过程中prompt部分和answer部分用一个特殊token分隔开,训练过程中只计算answer部分的loss
2.2 RLHF部分
RLHF是周期进行的,reward model和policy model要同步更新,也就是,每次来了最新的perference data,要继续迭代reward model,使得reward model对于policy产生的response要在同一分布内(in-distribution),这样才能迭代出新的更好的policy model。
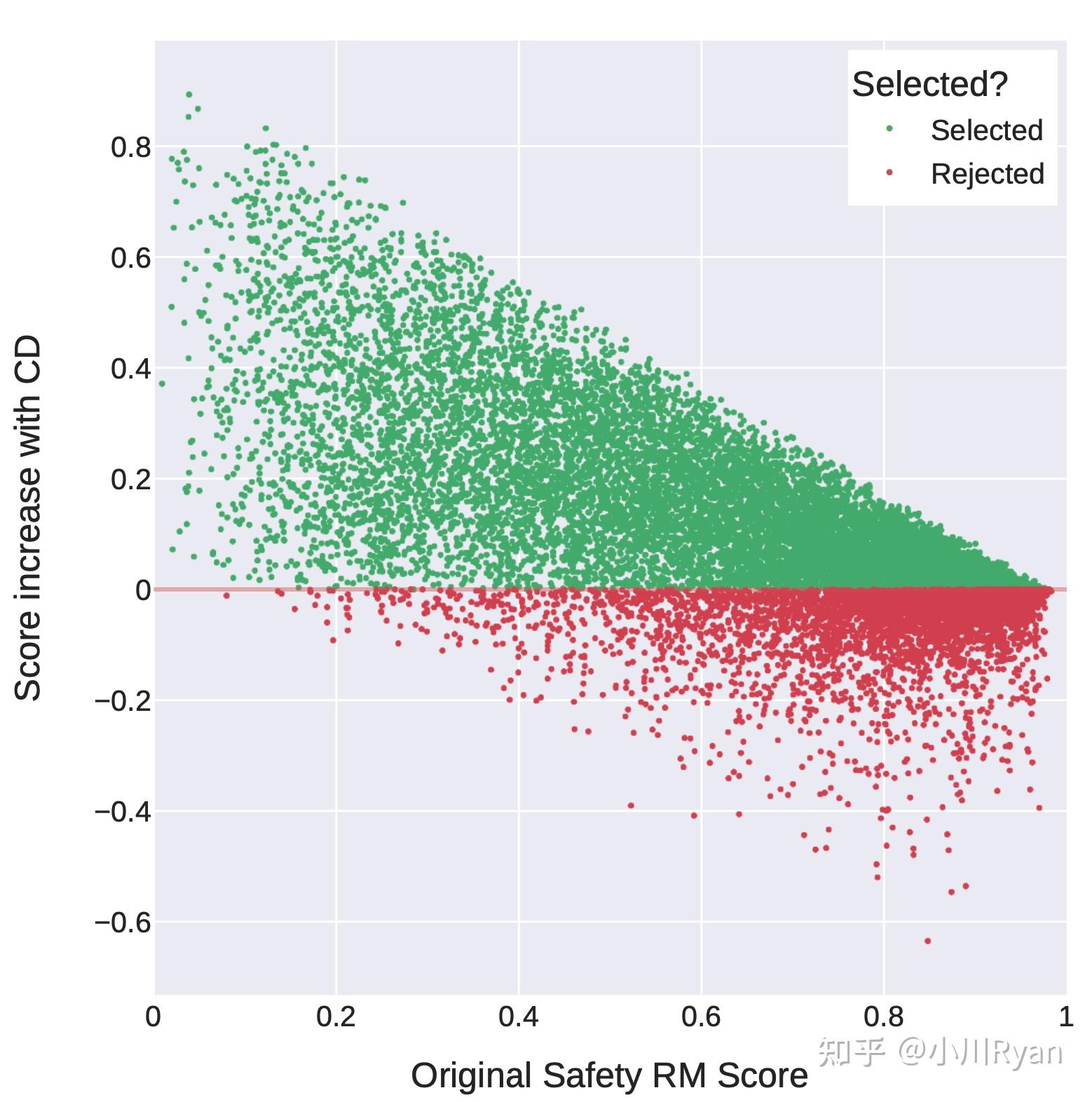
helpfulness 和 safety(或者说harmfulless)通常是冲突的。比如让LLM告诉我们如何制作一个炸弹,如果想要helpfulness,那么就希望它告诉我们怎么做。如果考虑sefety,则它应该拒绝回答这个问题。一般情况下,我们会选择safaty。为此,作者训练了两个reward模型,分别用于helpfulness和safety。
在preference数据收集的过程中,给定prompt,生成response时候为了增加多样性,用了不同的模型变种,用了不同的温度和超参数。(同一个模型生成两次response通常会差不多...)
目前的preference数据也很多,作者自己构建了一个141w条比较数据,样本更长,更适合对话场景。但是最后作者还发现把现有的开源的preference数据跟自己构建的混合到一起训练一个reward模型可以提升泛化性。
经过大量的实验,最终reward模型的数据混合方案是:对于helpfulness reward模型,50%是自己标注的helpfulness数据,剩下的50%从自己标注的safety数据和开源preference数据中进行均匀采样。对于safety reward模型,90%是自己标注的satefy数据和Anthropic的harmless数据,10%是自己标注的helpfulness数据和开源的helpfulness数据。
reward model也是从policy模型初始化而来,这样reward模型就知道policy模型知道什么,不会导致二者信息不一致,可以避免一些幻觉问题。reward和policy模型的架构和超参数完全一样,除了reward模型用的是一个regression head。
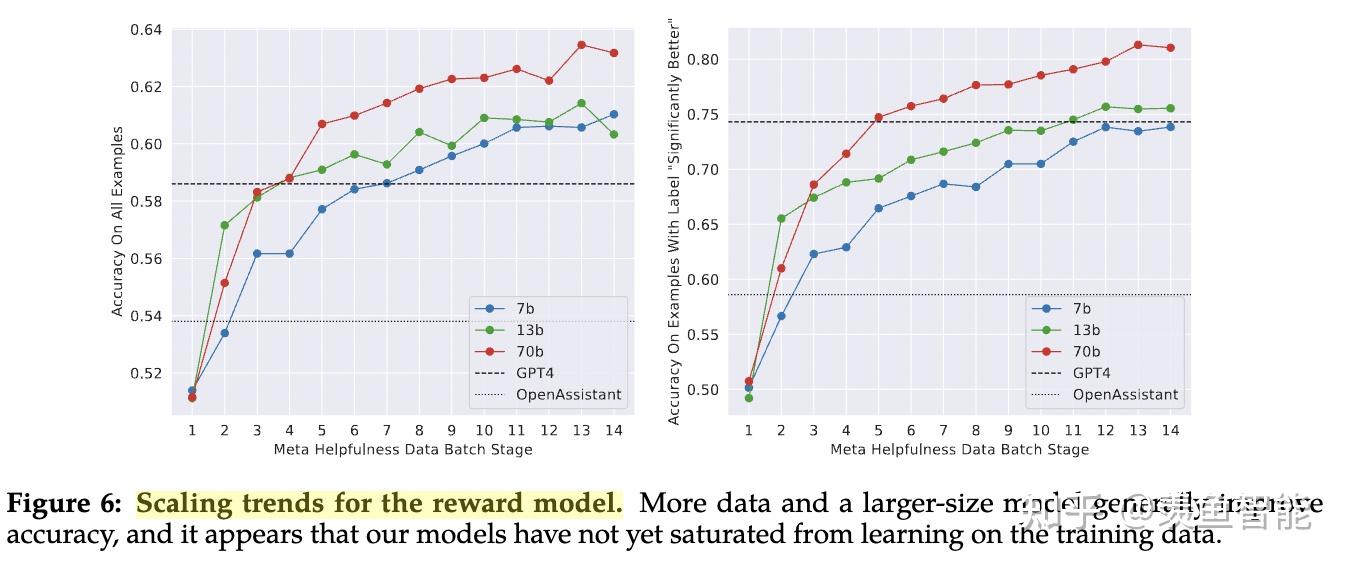
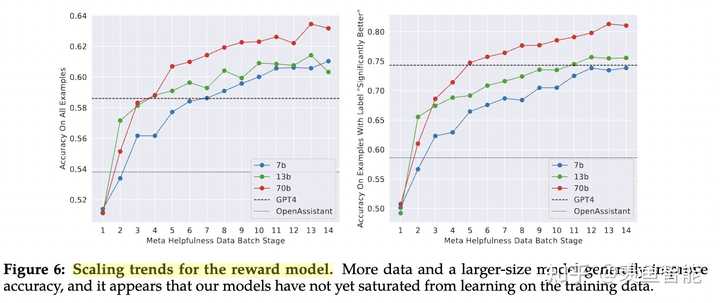
Reward模型的训练过程采用了课程学习的策略,即一开始会用一些简单的prompt,后面会用更复杂的prompt;
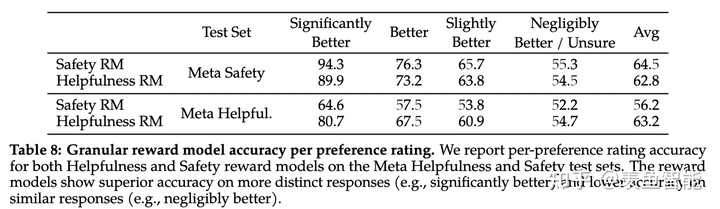
作者在标注preference data时候,做了更细粒度的标注,比如一个回复相比另一个significantly better, better,slightly better,neglibibly better,和unsure。为了更充分利用这样细粒度的标注,在reward model训练时融入了一个间隔项,实验发现可以提升helpfulness reward 模型的准确率。
强化学习阶段:随着preference数据的越来越多,可以训练更好的reward模型,因此会一直迭代训练。作者探索了两种强化学习算法:PPO和rejection sampling fine-tuning. 后者相比于前者,在采样时会采样多个输出(PPO会采样一个),然后选择reward最高的进行优化,同时将这个最好的output保留下来用于训练reward模型,相比较于前者是从最新的policy模型上进行采样,后者是从最初的policy模型上进行采样,不过模型都是一直在迭代,或许也近似看作成做法一样。作者最终的方案是前几次迭代采用rejection sampling fine-tuning,后面采用二者结合,即用完它再继续采用PPO。
在最终的奖励函数中,作者综合考虑了safety reward和helpfulness reward,如果是来自satefy preference数据集或者当前的reward小于0.15,则采用safety reward,否则则采用helpfulness reward。最后,作者还对reward分数做了whiten操作,发现可以提升训练稳定性。(注:由于训练不稳定的问题,在InstructionGPT中对于175B的Policy模型,作者只采用了6B的reward模型)
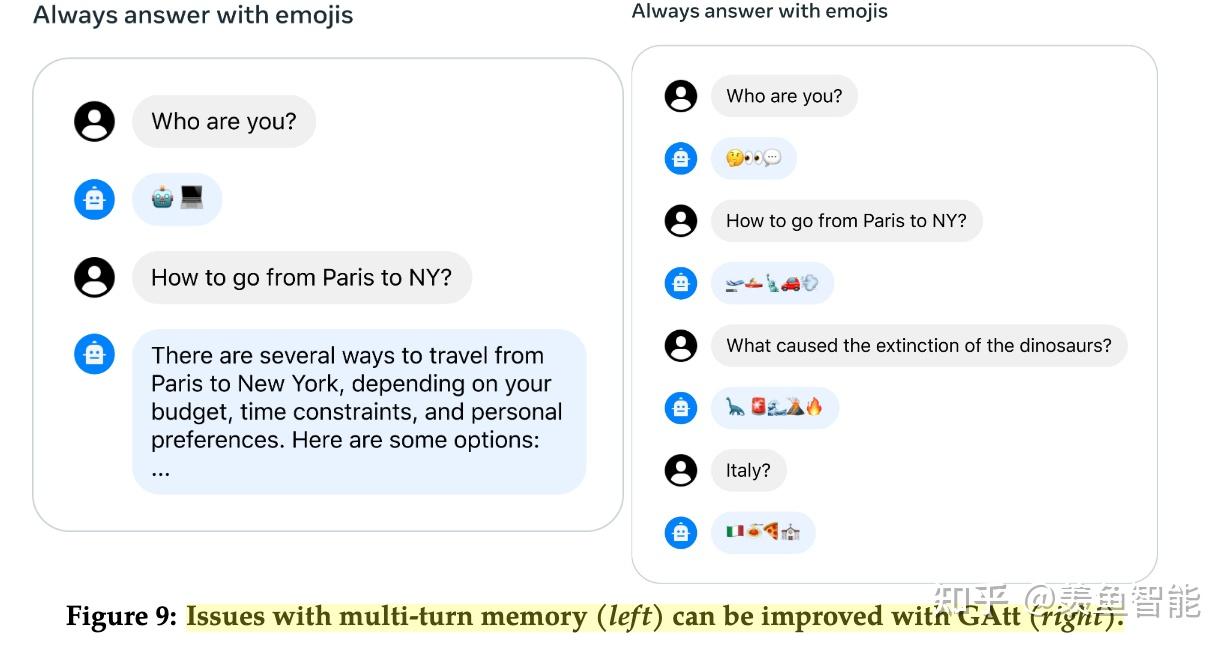
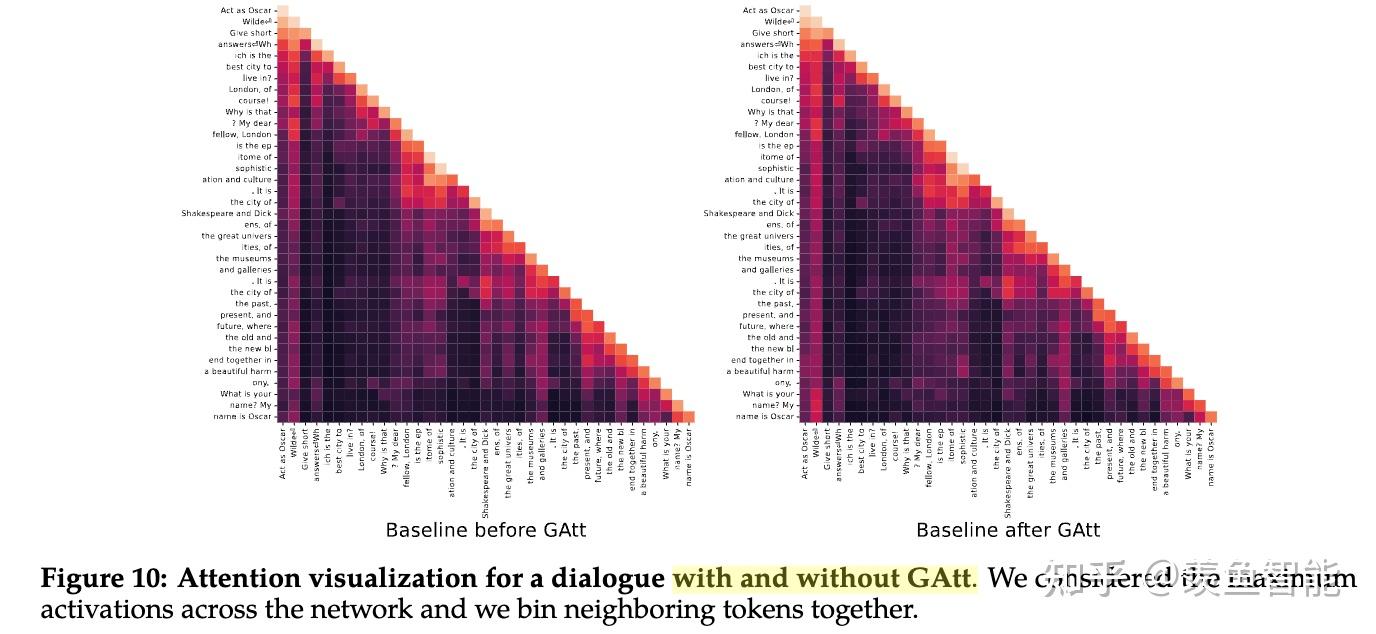
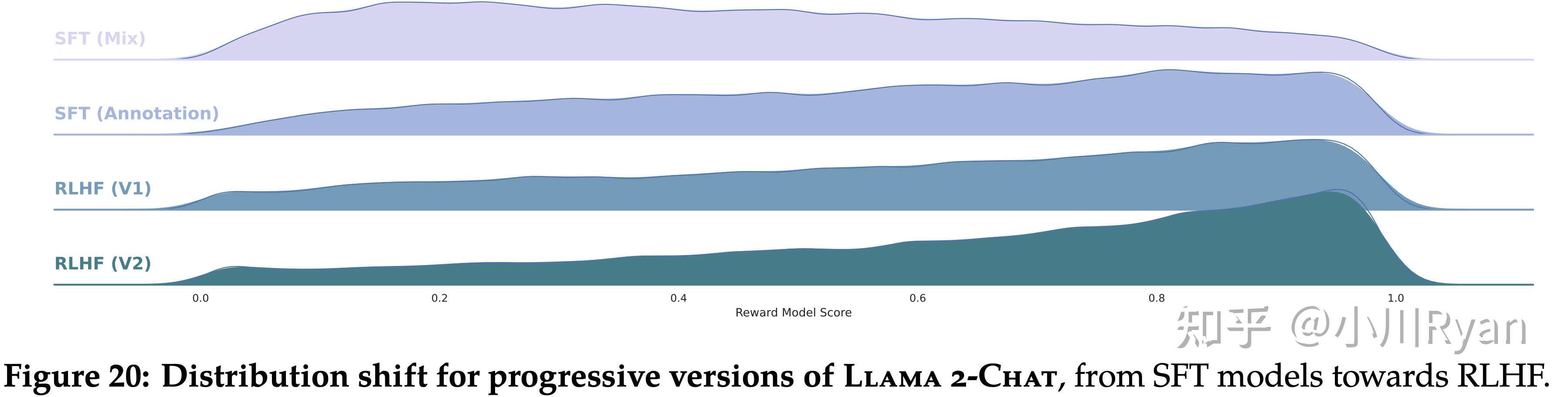
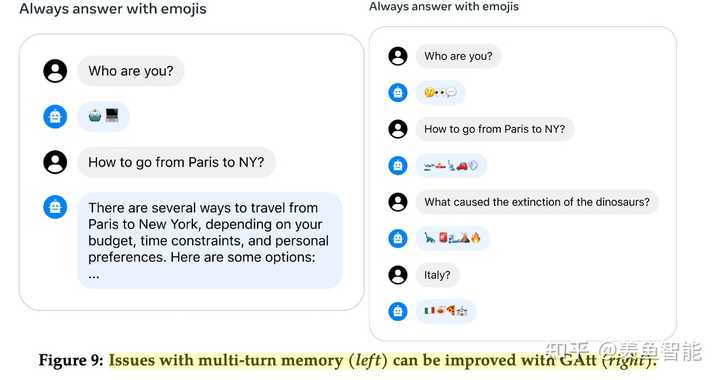
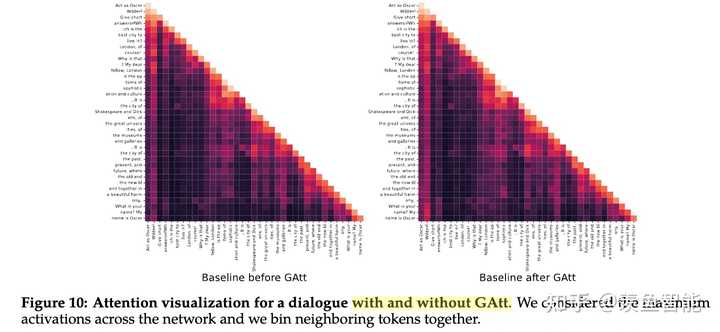
2.3 用于提升多轮对话一致性的System Message和Ghost Attention技术
在对话的场景下,我们通常需要设置system prompt,比如让他扮演xx角色,或者按照什么风格说话,作者发现几轮对话下来,模型容易忘记这样的“系统设定”。
假定有一个多轮对话数据集,用户和assistant之间交替对话,现将这个system prompt插入到每一轮对话中的用户消息中。然后用最新的RLHF模型从这个合成数据中选择样本,(我的理解是用reward模型来选择样本)然后对于选择出来的样本,只在最开始保留system prompt,之前在每一轮对话中都插入了system prompt,现在要都移除掉。不过这个会跟之前模型RLHF以及SFT阶段会与不一致,为此,作者会把之前轮数的上下文的loss置为0(我的理解是依旧类似于SFT中把prompt的loss置为0)
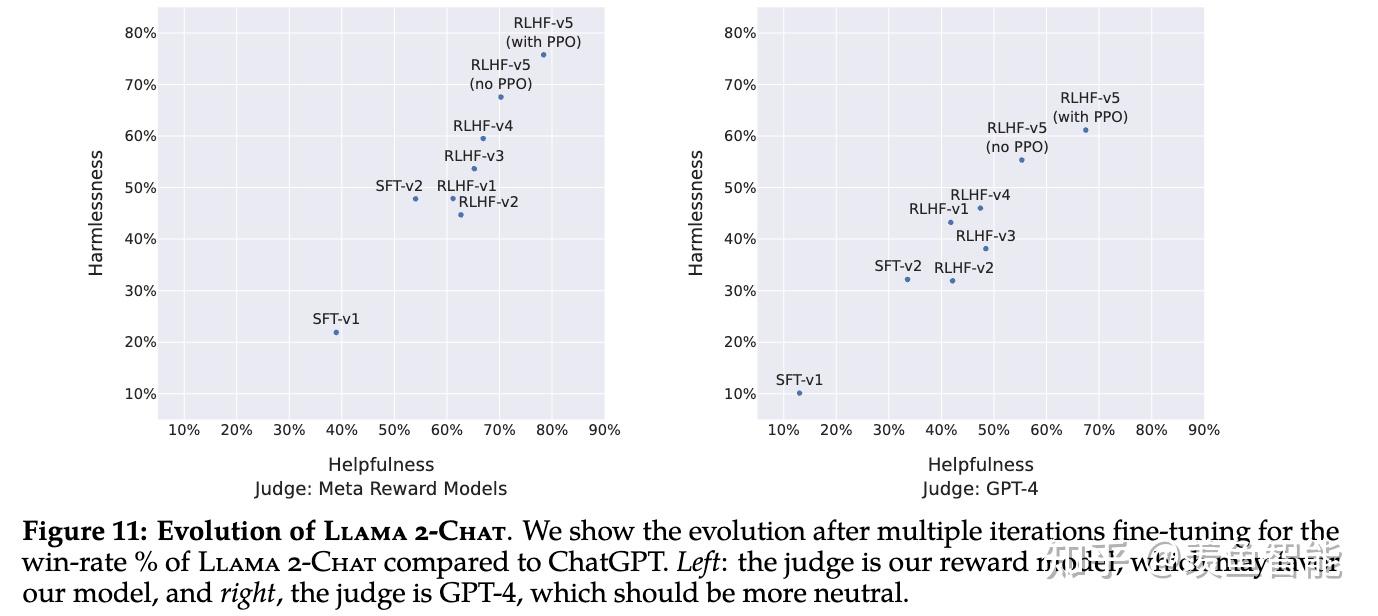
2.4 对齐的效果
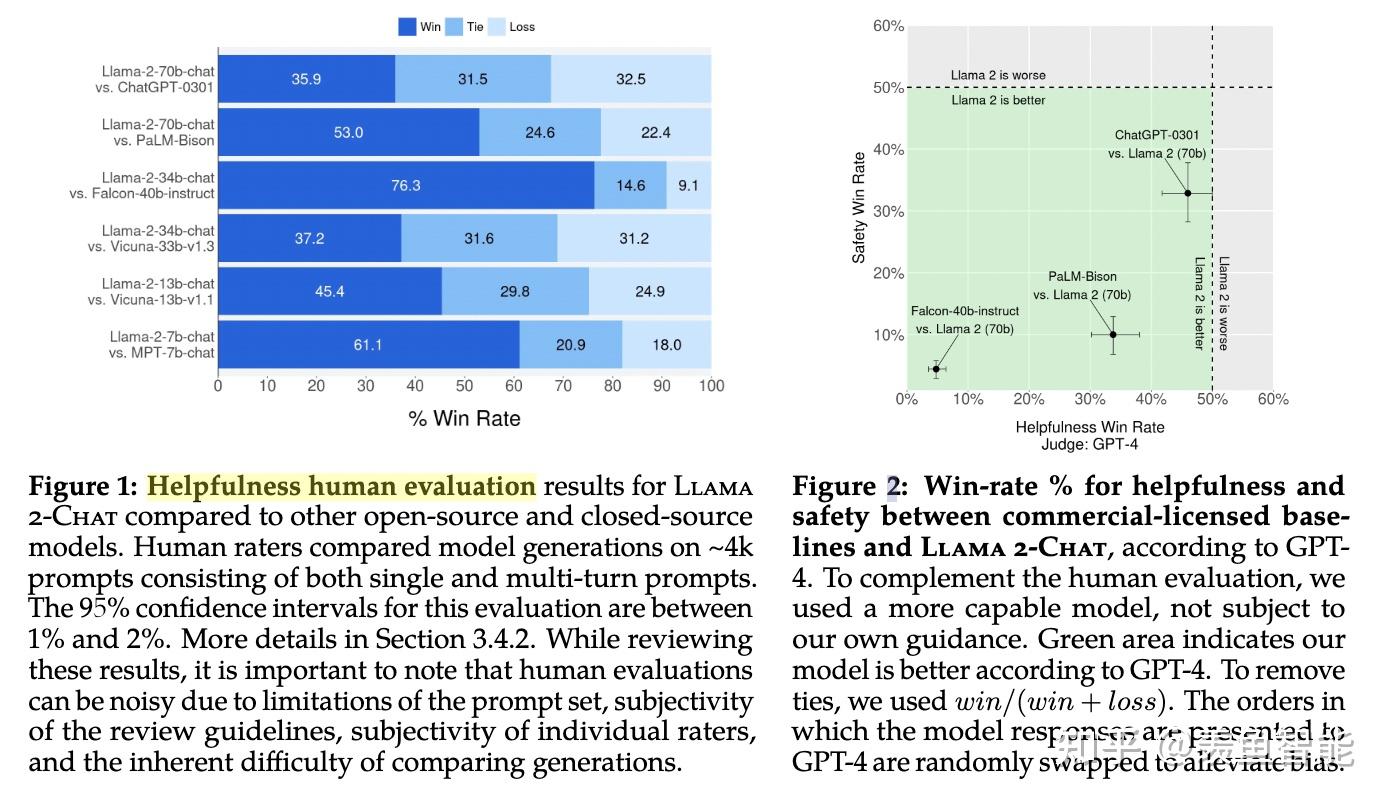
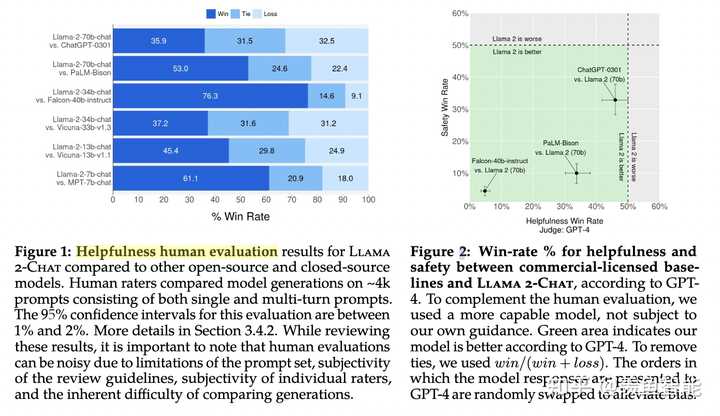
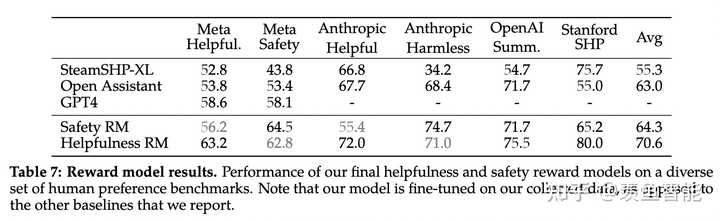
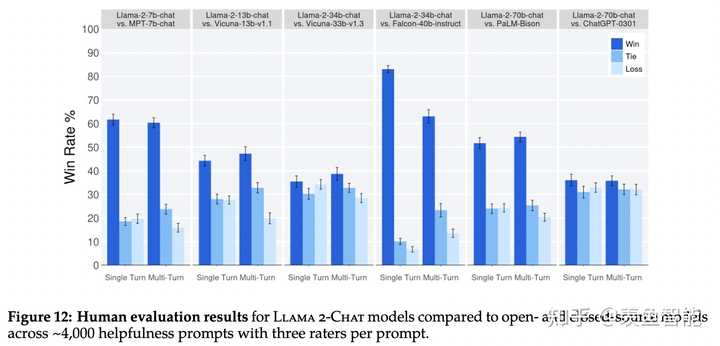
对于RLHF后的模型做了评估(包括基于模型的评估和人工评估),结果显示模型超过了开源模型和ChatGPT这种闭源的模型。基于模型评估时,对两个response放的位置做了随机打乱,来避免偏差。
不过作者也提到,评估结果可能存在偏差,比如测试集不够多样,而且没用涵盖代码生成和推理相关的任务。
3. 安全
文章正文花了整整10页的篇幅来解释安全上所做出的努力。
3.1 预训练阶段的安全性
作者首先强调了训练数据的处理符合Meta的隐私和法律规范,也不会使用任何用户的数据,也从数据集中排除了包含很多个人信息的站点。重要一点是,作者对于数据集没做过多额外的处理,这样使得模型具备更好的泛化能力,以及造成更少的偏见(见过的数据源更多,多样性更高,自然“眼界”更开阔)。作者观察到LLaMA-2有一定的毒性上升,作者猜测可能跟数据集没用做额外处理有关。
作者仔细分析了预训练数据中潜在存在的偏见:比如作者发现代词中He的出现频率相比She更高;还考虑了性比,性取向,国家种族等因素,比如在性别的考量中,会发现female出现的频率会比male更高,在国家地区的考量中,西方国家,宗教,耶稣,基督等词汇出现频率很高。(嗯,中国本土化模型势在必行...)
数据的毒性较低。
数据中绝大多数是英语,中文只占0.13%。
3.2 用于安全阶段的微调
为了得到更安全的对话模型,作者采用了以下三个技术:
注:以下的技术都已经在前面的pipeline中做过了,这里只是单独拎出来介绍一下,并不是做完上述的SFT-RLHF之后再做一遍Safety版本的,是上述pipeline过程中用到的数据就包含了用于安全控制的数据。
- Supervised Safety Fine-tuning: 收集了一些“对抗性”“诱导性”的提示,然后做了对应的安全的回复生成。然后将此数据用于SFT中。
- Safety RLHF: 训练安全专用的reward模型,收集更加有挑战的诱导提示,然后做RLHF;
- Safety Context Distillation: 在RLHF的pipeline中融入上下文蒸馏技术,也即在生成response之前,在原有的prompt之前加上一个system prompt比如“You are a safe and responsible assistant.”,然后得到回复之后再把这个system prompt去掉,然后将这个数据用于RLHF的pipeline中。
一些洞察:
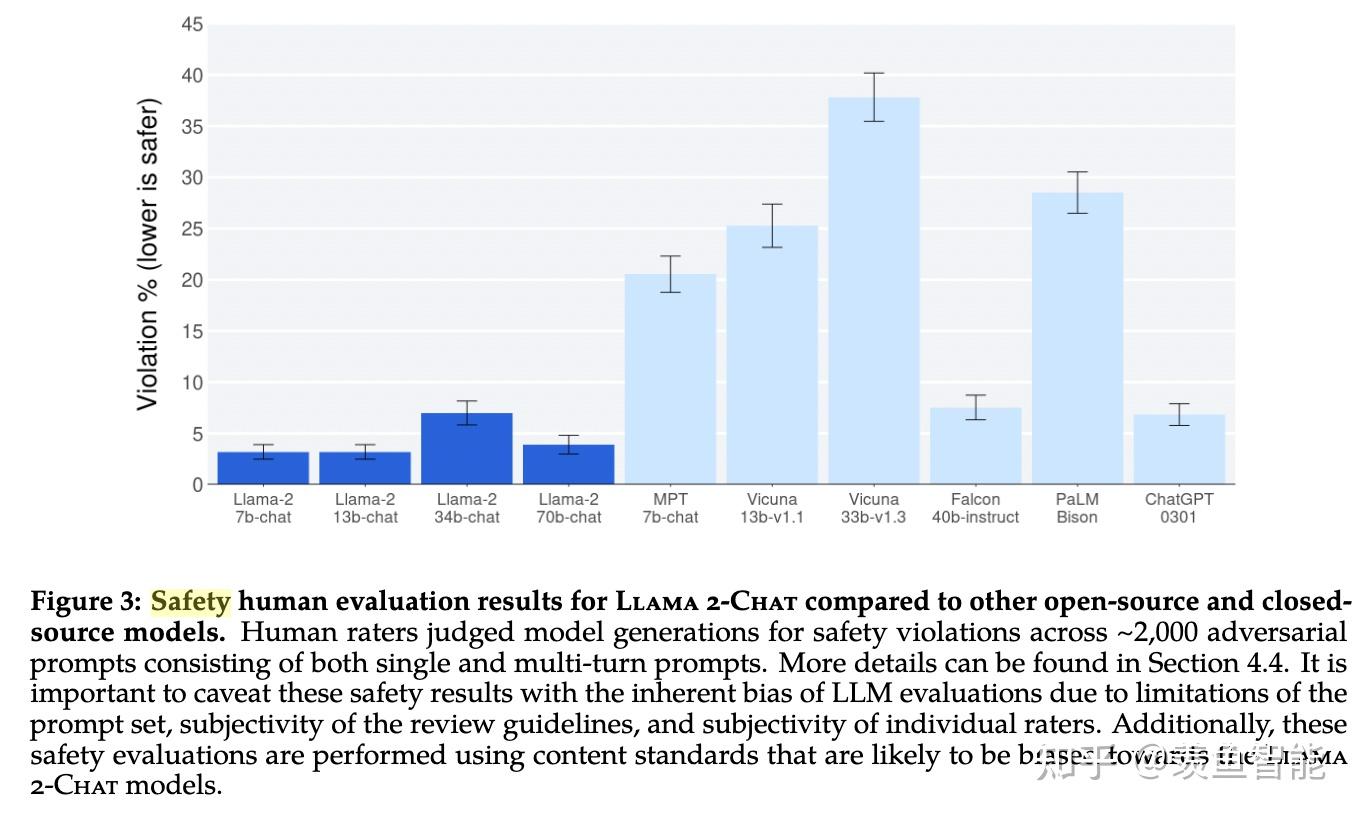
安全性问题通常也是长尾的,因为会有各种各样的意想不到的诱导性提示,作者选了RLHF阶段中的两个checkpoint做实验,发现随着RLHF的深入,对齐效果越好,但并不会损失helpfulness。(因为safety和helpfulness通常是“对抗”的)
同时做了也做了safety数据的scaling,发现随着safety数据的提升,helpfulness并不会怎么下降,但是safety会显著提升。
随着更多安全数据的加入,错误拒绝率(也就是可能不算是敏感的prompt,模型也拒绝回答)也会增高。(这大概是为什么有人发现感觉对齐对过头的原因...)
作者发现对helpful的prompt使用context distillation会导致回复的质量变差,带来更多的错误拒绝。作者一开始的方案是只针对对抗样本做context distillation,不过即便如此,有时候也会导致在对抗样本上的回复质量变差,最终的解决方案是如果context distillation的回复相比原来的回复得到了一个更好的reward则采用context distillation的回复。
3.3 红队对抗
关于Red Teaming: 一个通过承担对抗性角色来挑战组织以提高其有效性的独立的团体叫做Red Team。 后来,由于信息安全行业与军方的一些相似性,这个概念被引入到了安全行业,现在国际上一般以如下比较通用的定义来描述信息安全行业中的Red Team: 基于情报和目标导向来模拟攻击者对企业实施入侵的专门的安全团队。
还是之前说的,安全性问题通常是一个长尾问题,有些不太常见的问题但是却能引发灾难,比如ChatGPT的奶奶漏洞。为此,作者们召集了350人左右的团队(涵盖了网安专家,电信欺诈,法律,政策,民权,工程师等等背景)来做红队对抗,对抗过程中发现的一些有用的洞察:
- 早期的模型容易被绕过,回答一些不安全的内容,中期的模型能识别出诱导提示中的问题,最后的模型能够解决这些问题;
- 早期的模型更容易植入一些system prompt,比如以诗歌的形式来回答问题。
- 在积极的上下文中嵌入一些诱导在早期的模型上更容易成功“渗透”。
总而言之,红队对抗可以帮助我们构建更加安全的对话模型。
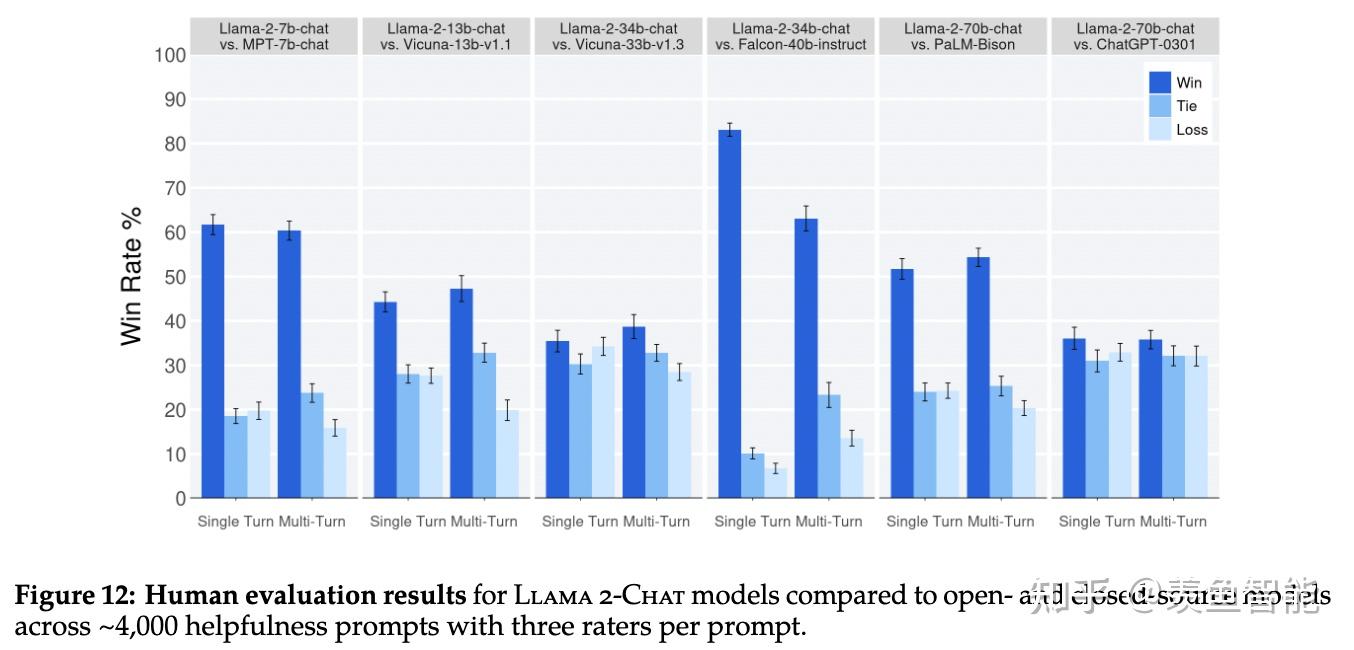
在安全性评估过程中也发现,多轮对话相比单轮对话更容易产生不安全的回复。
4. 作者们在模型构建中的观察与发现
不止人工标注。过去NLP社区通常会偏好人工标注的数据,强化学习可能有些“神秘莫测”。但是本文发现强化学习能够提高更多有效的高质量的,尤其基于代价和时间成本更低。人工标注总共是有限的,而且非常容易受到标注者的个人偏好等因素影响。此外,模型有潜力能够写出顶级数据标注者都写不出来的内容,但是人类总是能够对内容产生有价值的反馈。同理,虽然不是每个人都是艺术家,但是每个人都可以对艺术作品保持批判能力。作者们认为LLM能够在某些任务上超越人类标注者本质上是由RLHF驱动的。并且随着不断的发展,”监督“的含义可能要发生变化。
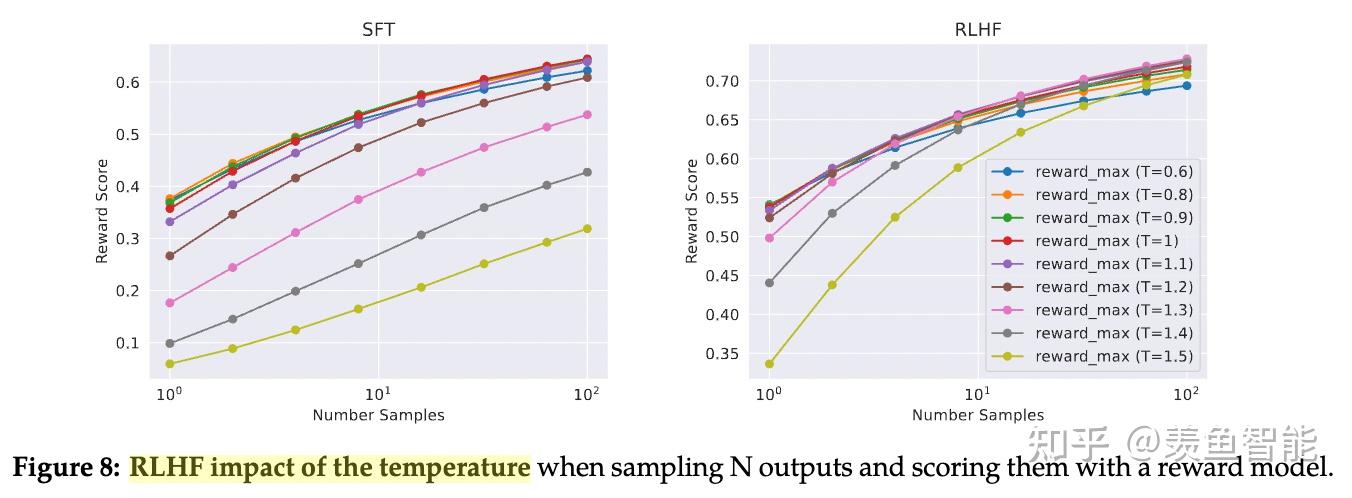
视情况而变的温度。作者还发现了之前RLHF相关研究没有揭示的一点,RLHF过程中最好的温度是动态变换的,比如早期可能温度低一点效果较好,后期需要温度高一点。另外,针对不同的prompt可能也需要不同的问题。
LLaMA-2 Chat内化了时间的概念。尽管训练的目标很简单,就是next token prediction,训练数据也是随机打乱的,没有按照时间排序,但是模型依旧理解了时间的概念。
使用工具的涌现能力。LLaMA-2 Chat展现出了零样本使用工具的能力。
写在最后:
从头到尾啃完,断断续续花了好几天的时间。直到今天快读完的时候,发现又出现了新的模型在榜单上又干掉了LLaMA-2... 技术迭代更新之快,可见一斑,当开源模型在努力追赶,一个又一个的模型刷新人们认知的时候,这些模型也在推动我们走出舒适区,在这场与时俱进的竞技场上永不止步。
编辑于 2023-07-23 00:29・IP 属地江苏查看全文>>
SinclairWang - 1 个点赞 👍
(文中引用内容,如无特殊说明,均来自Llama2的许可协议。地址:llama/LICENSE at main · facebookresearch/llama · GitHub)
先说结论:
1、Llama2的协议不满足开源定义,不属于真正的“开源”软件;
2、可以二次开发、可以免费商用;
3、用于训练模型并提供SaaS服务无需履行任何义务;分发需要提供许可证副本和归属通知;
4、不要假装和用户对话的是真人,不是AI。
一、什么才叫“开源”?
不是可免费商用就叫开源,更不是公开了源代码就叫开源。在Llama 1发布时,很多评论认为它开源了,又没有完全开,这就是典型的对开源的误解。开源的标志是开源许可证,即Open Source License。只有当一个软件的许可证条款符合开源定义时,才可以称作一个开源软件。
那么,为什么Llama2的许可协议不符合开源定义呢?
开源的定义,在国际上是有明确的规定的。开源促进会(开源定义 – 开源促进会 (http://opensource.org))发布的著名的十条定义,来源于debian社区对自由软件的定义,是目前国际通用的开源定义。在这十条中,Llama的许可协议与以下两条有冲突:
5. 不歧视个人或群体
Llama License 第2条规定月活7亿以上的企业用户无法通过本License直接获取授权,这是对大公司的歧视性条款。
6. 不歧视领域:许可证不得限制任何人在特定领域使用该程序。例如,它可能不会限制该程序用于企业或用于基因研究。
Llama License 第1条b4款中引入的《可接受使用政策》,限制了任何违法行为、欺骗行为和未披露风险的使用;b5款禁止使用Llama2的输出结果去改善其他Ai大模型。这就属于对使用领域的限制。
可见,Meta一方面不希望巨无霸公司白嫖,另一方面也不希望被其他AI模型白嫖,完全可以理解。但是,这就导致它不是真正的开源软件。Meta用open source宣传它,是不太准确的。
二、授予的权利
Llama License 第1条第a款:
根据Meta的知识产权或 "Llama材料 "中体现的Meta拥有的其他权利,您被授予非排他性的、全球性的、不可转让的和免版税的有限许可,以使用、复制、分发、拷贝、创作衍生作品和修改 "Llama材料"。
“免版税的”,即说明了其非商业属性;“创作衍生作品和修改",即说明了可以二次开发。注意,按照协议的定义部分,”Llama材料“不仅包括软件本身,还包括了相关文档。
三、积极义务
Llama License中的积极义务位于第1条b1和b3款:
如果您向第三方分发或提供 "Llama资料 "或其任何衍生作品,您应向该第三方提供本协议的副本。
您必须在您分发的所有 Llama 材料副本中,在作为副本一部分分发的 "Notice "文本文件中保留以下归属通知:"Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved."条款很简单,第一条是提供一个本协议的副本,一般以单独的txt文件形式;第二条是提供一个Notice文本文件,保留一段归属通知,也可以称之为致谢。但是重要的是需要明确,什么叫“分发(distribute)”。虽然在本协议中没有解释这个概念,但在其他开源协议中可以找到类似的概念以参照使用。
虽然GPLv3中使用的词是convey,但GNU认为它几乎等同于GPLv2中的distribute(GNU 许可证常见问题 - GNU 工程 - 自由软件基金会),由于GPLv2没有专门的定义条款,因此我们看一下GPLv3中对convey的定义:
“转发”作品指让他方能够制作或者接收副本的行为。仅仅通过计算机网络和用户交互,没有传输副本,则不算转发。(https://jxself.org/translations/gpl-3.zh.shtml)
很明显了,只有在实际上将这个软件作为产品的一部分实际传输给了其他用户,才属于分发行为。例如,直接对外出售修改后的Llama2。而在自己的服务器上使用Llama2训练数据,通过网页方式或在线客户端向用户提供服务,例如生成式人工智能的对话AI,则不属于分发。如果不属于分发,则不需要履行上述积极义务。
四、消极义务
消极义务,即不能用来做什么。Llama License中的消极义务主要有4个:
1 b iv. 您对 "Llama材料 "的使用必须遵守适用的法律法规(包括贸易合规法律法规),并遵守 "Llama材料 "的 "可接受使用政策"(可在https://ai.meta.com/llama/use-policy,见附录),该政策通过引用纳入本协议。
这个“可接受使用政策”,emmm……可以自行浏览一下,正常人是不会触犯这些伤天害理的问题的。唯一需要注意的一点是3e,不得故意欺瞒,声称 Llama 2 的使用或输出是人为生成的。
1 b v. 您不得使用 "Llama 材料 "或 "Llama 材料 "的任何输出或结果来改进任何其他大型语言模型(不包括 Llama 2 或其衍生作品)
限制同业竞争,没什么可说的。这种事有些国内厂商可能很想做。
5 a. 本协议未授予任何商标许可,在与 "Llama资料 "有关的情况下,Meta和被许可人都不得使用对方或其任何附属机构拥有的或与之有关的任何名称或标记,但在描述和重新分发 "Llama资料 "时合理和惯常使用的情况除外。
不能商业性用小扎公司的商号、商标等标记来宣传自己的产品。除非是描述性使用,例如履行前述的许可证义务时。
5 c. 如果您对Meta或任何实体提起诉讼或其他程序(包括诉讼中的反诉或反请求),指控Llama材料或Llama 2的输出或结果,或上述任何内容的任何部分构成对您拥有或可许可的知识产权或其他权利的侵犯,则根据本协议授予您的任何许可应在此类诉讼或请求提交或提起之日起终止。对于任何第三方因您使用或分发 "Llama材料 "而提出的索赔,您应向Meta作出赔偿并使其免受损害。
这一条简单说就是两点,一、如果你对任何第三方提起诉讼,主张Llama2模型,或基于该模型的训练结果侵犯了你的权利(通常可能是专利权、版权、商业秘密),那么这份许可协议终止。二、如果任何第三方因为你使用Llama而向Meta提出索赔(emmmm……),那么你要承担这个赔偿。
发布于 2023-07-20 12:56・IP 属地美国查看全文>>
恨生剑舞 - 1 个点赞 👍
就昨天凌晨,微软和Meta宣布Llama2大模型开源且进一步放开商用,一下朋友圈刷屏。要知道,开源界最强大的模型就是过去Meta开源的Llama,而现在Llama2更强大,又开放商用,更有微软大模型霸主企业撑腰(微软既投资大模型界的IOS——ChatGPT,又联合发布大模型的Android——Llama2),开源大模型的确如当年的Android一样要流行起来了。
国产大模型“百花齐放”
反观国内,大模型也是最热的话题,前几天有人整理了一份现在国内发布大模型的企业和名称,笑称“中国古代的名词快不够用了”,我大概数了数大概114个大模型,但是其实这些只能叫做拥有自己业务适配的大模型企业,而不是真的中国有114个原创大模型。


大模型“百花齐放”的奥妙
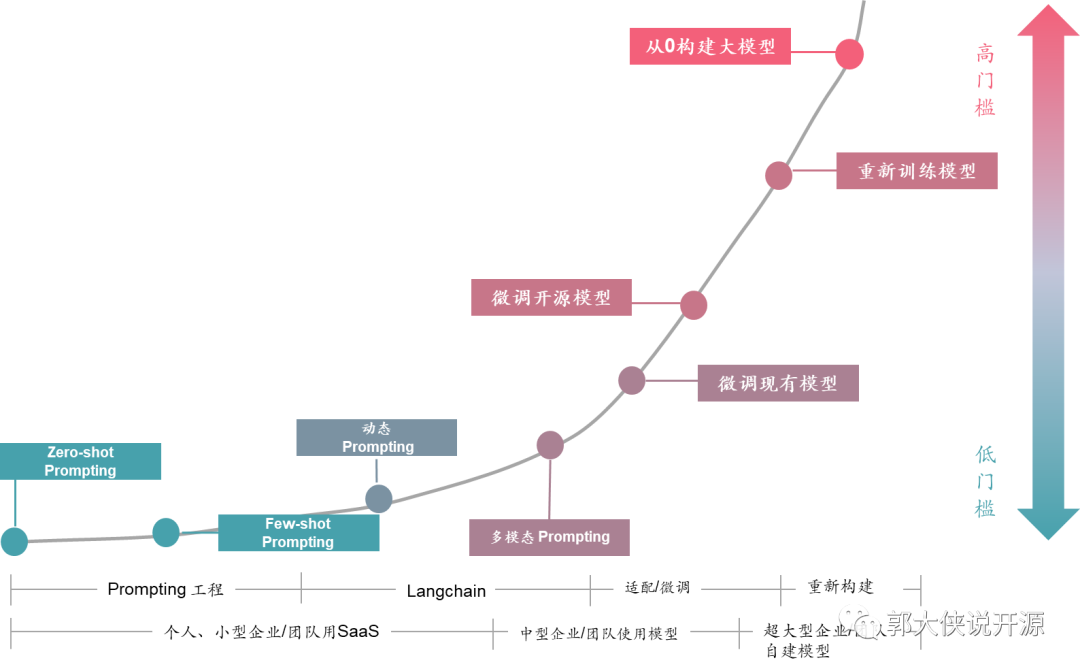
中国有这么多的大模型的奥妙隐藏下面的这张图里:
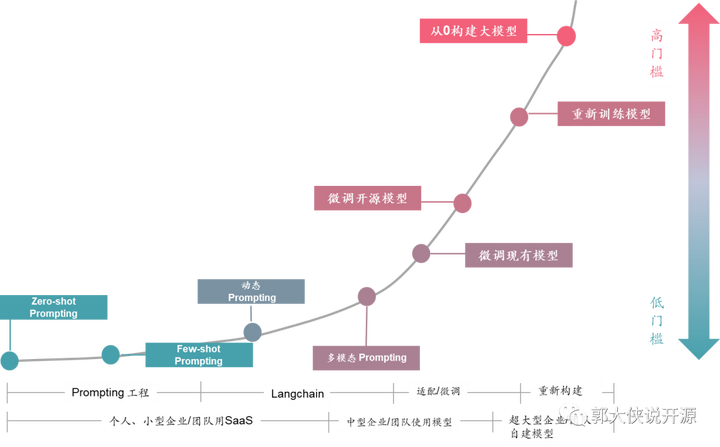

在这个图里你会发现,企业使用大模型其实有几种方法,常见的就是个人和小企业,直接使用线上ChatGPT、Claude、Bard或者类似的服务,至多可以用Prompt或者Langchain来Embedding一些预置场景和信息给线上大模型服务。但此时,你所有的数据都在公网上的,而且你也不是真正的让这个大模型适配你的业务知识库和业务逻辑,所以遇到复杂的处理场景或者使用企业内部数据的时候线上大模型服务就无法满足要求。
此时,基于开源大模型的FineTune(优化)出现了,也就是过去有不少企业在网上开放了自己训练的大模型(例如Llama),让大家基于这个模型可以再次优化训练自己的业务模型。这样训练的模型可以解决公网大模型的数据私密问题和深度理解自己业务场景的问题,一下子解决很多问题。不过受限于还有一定的技术门槛,所以,能使用和优化开源大模型的企业还不多。不过也有不少大型企业和实体做了开源大模型优化,并把这个模型再次开发出来,这就成为了国产大模型“百花齐放”的景象。
但是,其实真的从0开始构建大模型,难度是非常非常非常大的,看ChatGPT烧掉那么多钱让GPU训练,Llama2都需要微软这样的大佬背后支撑就知道,真的能做出来中国自主大模型的企业凤毛麟角。
开源大模型生态降低使用门槛,让大模型用户x100倍
但,这并不会影响大模型在中国的普及,为什么我说中国大模型数量会再增100倍呢?这是因为我看到越来越多的开源大模型的生态项目,开始降低企业使用开源大模型的门槛,这就像当年Android的流行一样,开始只有一些大玩家在玩,然后Android开源生态起来之后,所有的企业都会开发Android APP了。
目前看到100多个拥有大模型的企业还都是比较大的实体,很少有中小企业有自己的大模型的。这是因为优化训练大模型,现在还存在着不少门槛:
- 专业人才:需要大模型算法专家进行调优,不是每个企业都有这样的专家
- 数据供给:需要给大模型优化准备数据,而且在适当的时候“喂”给大模型
- 调优效率:调优本身是一个反复的调整测试的工作,没有合适的工具来做
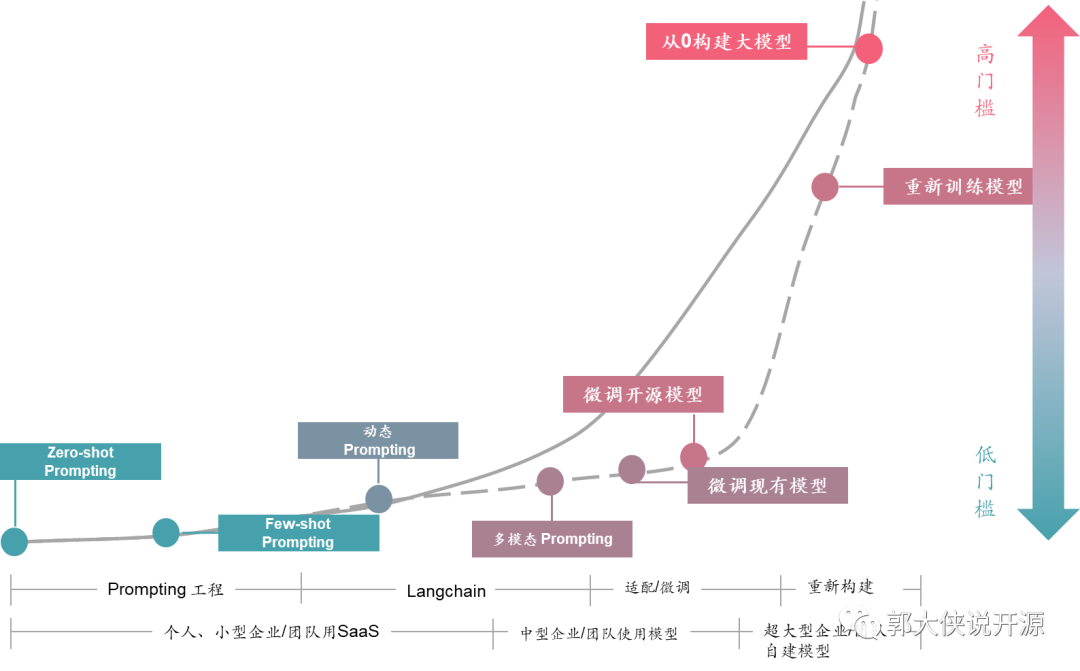
而现在各种开源社区都在进一步降低这个门槛,将大模型变得“人人可用”,例如Apache DolphinScheduler社区发布的文章《用一杯星巴克的钱,训练自己私有化的ChatGPT》,就给出了让普通程序员甚至数据分析师快速用自己的数据优化大模型的方案。而Apache SeaTunnel也在准备做企业内部数据和大模型的打通之间的Langchain《图书搜索领域重大突破!用 Apache SeaTunnel、Milvus 和 OpenAI 提高书名相似度搜索精准度和效率》。这些都会让没有相关人员、处理复杂数据、不知道怎么调优的企业进一步拥有自己的大模型。我相信,未来大模型的门槛曲线是下图虚线这样的,未来每个会使用ChatGPT的企业和个人,都可以拥有自己私有化的大模型:
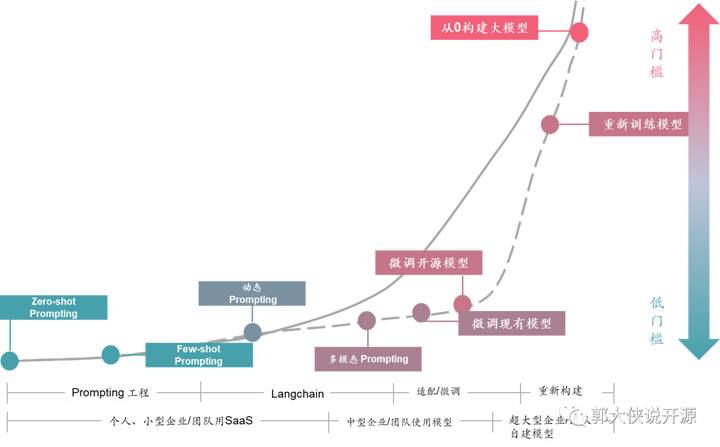
随着Llama2的发布和商用化的解禁,我相信中国的开源大模型会进一步丰富起来,而中国开源大模型生态也会和中国开源Android生态系统一样,有自己一套开源支撑的生态体系,在拥有这么多数据和人口的国家蓬勃发展起来。
我是热爱开源的郭大侠,欢迎点击关注了解全球开源最新动态。
发布于 2023-07-20 11:57・IP 属地北京查看全文>>
郭炜 - 1 个点赞 👍


「 探索未知,无限进化」 从商业的角度来讲,如果你想打败先发优势的对手,技术开源确实是很好的一步棋。
LLaMA-2通过开源技术,可以吸引全球开发者和爱好者参与到产品或服务的开发和改进中,这极大地加快了创新和迭代的速度。
庞大的社区和生态系统的迅速建立;透明度与信任度大幅度的提升;降低行业壁垒,任何一点都将会为Ai时代的发展提供强大推进力!
01、什么是LLaMA-2?
羊驼的羊,羊驼的驼
LLaMA-2是一款由Meta AI研究团队开发的语言模型,全称为Large Language Model Augmented with Meta-learned Approaches。它具有更大的参数规模和更高的生成能力。


LLaMA-2的主要目标是提高对话生成的质量和多样性,使其能够更准确、更有帮助和更安全地回答用户的指令和问题。为了实现这一目标,LLaMA-2采用了多种创新的训练技术和方法,包括引入人类偏好评估、迁移学习、奖励模型等。
通过综合多种数据源和多个训练阶段,LLaMA-2能够以更广泛的视野理解世界,生成更具多样性和创造力的回应。它的训练过程经过严格的质量控制和迭代微调,以提供高质量的对话生成能力。
02、LLaMA-2的工作原理
能用上的都用上了
LLaMA-2的研发团队依旧是第一版本的原班人马,研发团队收集了大量人类对话数据(毕竟有Meta的先天优势,压力给到蓝鸟),包括对话历史、用户指令和模型生成的回应。这些数据涵盖了各种话题和语境,以确保模型的广泛覆盖性和多样性。并对这些数据进行严格筛选和审查,以确保其质量和准确性。
基础模型训练:使用收集到的人类对话数据,研究团队训练了一个初始的基础语言模型,即LLaMA-2的基础模型。这个模型具有较大的参数规模,以提供更强大的语言生成能力。
人类偏好数据收集:为了训练更高质量的模型,研究团队利用人类评估员对模型生成的回应进行评分。这些评分用于构建奖励模型,即衡量回应质量的模型。
奖励模型训练:利用人类偏好数据,研究团队训练了两个关键的奖励模型:Helpfulness Reward Model和Safety Reward Model。Helpfulness Reward Model用于评估回应的帮助程度,而Safety Reward Model用于评估回应的安全性。
这些奖励模型在训练过程中根据人类评估员的偏好评分进行优化。做好了这一步,再通过迭代微调的方式,研发团队进一步提高模型的性能和质量。他们使用强化学习算法(如PPO和Rejection Sampling)对模型进行微调,以使模型在奖励模型评估下的表现更好。
迭代微调:通过迭代微调的方式,进一步提高模型的性能和质量。在每次迭代中,研究团队使用强化学习算法(如PPO和Rejection Sampling)对模型进行微调,以提高模型在奖励模型评估下的表现。
多轮一致性控制:为了保持多轮对话的一致性,LLaMA-2引入了一种称为Ghost Attention的方法。这种方法通过在训练数据中引入指令信息,并对模型进行微调,以确保模型在多轮对话中能够保持一致的行为和回应。

通过以上的训练过程,LLaMA-2逐渐提升了生成对话方面的能力和质量。它综合了多种数据源和人类偏好评估,通过强化学习和迁移学习的方法进行训练和微调,以实现更准确、有帮助和安全的对话生成。
其实,大家不难发现,这每一刀的差异化,刀刀都指向ChatGPT。
03、LLaMA-2和ChatGPT的区别
爱吃哪个品种的西瓜你定
萝卜白菜各有所爱,无论是LLaMA-2,还是ChatGPT在设计和训练上都有相对存在的一些区别。
1、训练方法:LLaMA-2采用了一种基于强化学习和迁移学习的训练框架,结合了人类偏好数据和奖励模型来指导模型的训练。这种方法可以提高模型的回应质量和性能。而ChatGPT主要通过自监督学习和无监督预训练来进行训练。
2、数据收集和筛选:LLaMA-2在数据收集和准备阶段非常注重质量控制,通过人工审核和筛选,确保训练数据的准确性和可靠性。ChatGPT也有一定的数据筛选措施,但相对于LLaMA-2来说可能相对简单和粗略一些。

3、奖励模型和评估:LLaMA-2引入了Helpfulness Reward Model和Safety Reward Model来评估模型的回应质量,从而进行迭代微调。这种奖励模型的引入可以帮助提高模型的性能和质量。ChatGPT在评估方面可能更依赖于自监督预训练和人工评估的结合。
4、多轮一致性控制:LLaMA-2引入了Ghost Attention方法来保持多轮对话的一致性,即确保模型在不同对话轮次中保持一致的行为和回应。这种机制可以提高对话的连贯性和理解。ChatGPT在多轮对话方面可能没有类似的专门机制。
这些区别导致了它们在回应质量、对话连贯性和用户体验等方面可能有所不同。但是,我还是更喜欢ChatGPT!虽然这么说,LLaMA-2模型该用也得用,开源真香定律,谁用谁知道!
04、从彗星的尾巴看未来
抓紧不要掉队
LLaMA-2已经成功地划过AI的天际,这让“很多人”很兴奋!但这仅仅意味着我们探索才刚刚开始,在其尾巴的光芒中,我们看到了更多的挑战和可能。从训练数据的多样性,到模型质量的保障,再到数据污染的防止,每一个挑战都是一个机遇,每一个可能都是一片未知的新天地。

正如美国科幻作家阿瑟·C·克拉克所说:“科技足够先进,就无异于魔法。”而我们正在这个魔法的世界里,探索着未来的无限可能。
05、体验及部署
LLaMA-2体验①:三个模型都可以体验
Replicate:https://www.llama2.ai/LLaMA-2体验②:70B可以体验
Huggingface:https://huggingface.co/chat
部署方面会在之后出教程,如果只想部署小模型玩玩,建议大家在Google Colab上面用GPU T4小玩体验一下就好。「如果需要LLaMA-2中文研究报告+V」
发布于 2023-07-20 22:16・IP 属地广东查看全文>>
极言者 - 1 个点赞 👍
本来没打算这么快就写LLM系列的第二篇文章的,但是最近LLaMA2发布和并几乎完全商业可用几乎引爆了LLM圈,好多人都在讨论Meta AI真正做到了OpenAI,是开源LLM的一个重要里程碑,甚至觉得国内和OpenAI的差距又缩小了。其实,关于开源和闭源模型之争的讨论也持续了有几个月了。就这个问题而言,我对开源模型是比较悲观的,LLaMA2的发布并没有减轻这种悲观,反而隐约加重了这种悲观的看法。借着LLaMA2开源这个话题,记录下自己当下对这个问题的看法,希望有一些工作能让我对开源LLM变得乐观起来。
先说结论
- LLaMA2对于追赶OpenAI帮助不大
- LLM开源可能是伪开源
- LLaMA2开源对于国内大模型竞争没有太大影响
- LLaMA2开源的积极影响:免费商用,私有化部署,加速开源竞争
放一张 最近报告中的图,理由很一致:缺算力,时间差。看看这这次LLaMA2开源中狂欢的最厉害的一些人 1)研究人员(特别是高校研究人员),有了一个新的基础能力还不错的开源模型,做点微调改进,又可以刷榜了,随便针对LLaMA2做点新东西,指标上从接近GPT3.5到超越GPT3.5,就是一个工作;2)中小企业,没能力训练基础模型,现在来个还不错的,做做微调,随便改改,就是自研大模型了;3)创业者(不包括基础大模型创业者),基于不错的基础模型做应用似乎有机会了。一个共同特质都是,没有大规模算力资源训练基础大模型,但善于做微调的那部分人。真正只会用ChatGPT的用户也不会转移去用LLaMA。


LLaMA2对于追赶OpenAI帮助不大
现在的LLM发展基本上可以分为两个大的方向:探索智能的极限和大模型商业化应用。少数公司在做前者,大多数公司想做后者。虽然OpenAI做出了大模型目前来看最大的商业化应用ChatGPT,但他们的核心目标和使命仍然是AGI,也就是探索智能的极限。LLaMA2开源对于商业化应用是有帮助的,这个具体后面会讨论,但对于探索智能的极限这一目标没有太多实质性的帮助。
对于探索智能的极限这个事情来说,最重要的是Pretrain模型,这个决定了后面SFT或者RLHF的上限在哪里。仔细读完LLaMA2的technical report,会发现LLaMA2相比较于LLaMA1在pretrain模型上唯二的不同:数据增加到了2T,使用了Group head attention (增加context window不能算是不同吧,只是改了一下参数)。甚至对于7B和13B的模型,只有数据量这一个差别。增加数据量和加强数据质量控制这两个结论应该是整个LLM界早已经达成共识的点,越多高质量的数据代表越强的智能。但对于真正决定模型能力差距的几个关键问题:怎样控制预训练数据的质量,预训练的时候怎样调整数据配比能得到最好的结果(有没有科学的方案来指导数据配比),预训练过数据的顺序对结果的影响(怎样找到最优的数据顺序),代码数据在哪个阶段加入预训练是最有效的,没有从LLaMA2的模型中看到这方面的insight。Falcon的工作至少提出了refined web data和清洗数据的很多rules,对其他做预训练的人是有insight。但LLaMA2 不知道是做了不肯说(毕竟这也是OpenAI最核心的Recipe,不说也正常)或者压根没科学地做,反正是让人蛮失望的。可以简单总结为过了4个月,Meta在预训练方面没什么大的进步。
换个角度看,大家费尽心力想要去复制一个GPT3.5,到现在也只能做到接近的水平。可是对怎么做GPT4仍然没有什么思路,看完LLaMA2的technical report,感觉对做GPT4的价值都没有Dylan之前的泄密报告来的大。而OpenAI再这几个月可能又用几万张卡做实验总结/分析/验证了不少思路和tricks,差距可能越拉越大了。
Meta在LLaMA2的主要贡献在SFT和Safety的大量工作,也就是post-train阶段的工作。如果算力和资源丰富地如Meta一样的公司也只能做post-train,是不是说可以和OpenAI竞争的公司可能在变得越来越少呢?
LLM开源可能是伪开源
一直觉得LLM开源(这里的LLM开源指的都是预训练模型的开源,不包括SFT模型)和其他开源项目有点不一样,主要有下面几个感受:
只有大公司能开源LLM
LLM训练是一个成本极高的事情,首先很respect这次Meta烧了千万美金开源了模型和非常详细的technical report(虽然主要侧重的是post train)。但壕如Meta的机构本就不多,能真正花精力去做开源的更是少之又少。在预训练阶段大量的开源工作还是在7B,13B这个规模上,开源大模型是需要庞大的资金支持的。这里同样需要respect之前BigScience做的Bloom,这个是真正意义上的开源社区聚集一大群人一起发展LLM的接近最佳实践了。但Bloom的模型训练的还是不够好(可能也是社区组织大家一起做事的弊端吧)。除此以外,能开源大size的预训练模型的只剩下土豪大厂了。
但是动态地看,训练下一代的模型成本是会数量级上升的,当Meta花1亿美金训练接近GPT4的模型的时候,还会继续开源吗?花10亿美金训练接近GPT5的模型的时候,还会继续开源吗?大家都不知道。或者说Meta有一天说我不想开源了,或者像国内某些公司开源是开源了但你使用需要交给授权费,或者把开源模型撤回了要收高价,似乎作为社区参与者都不能说什么。毕竟模型是别人花真金白银训练出来的,且社区参与者几乎对训练模型没有起到任何帮助,别人要收费你也拦不住。
社区并没有对LLM训练起到帮助
社区其实在预训练过程中没参与什么,这也是和理想中的开源和不一样的地方。从数据到算力到模型都是Meta的一个团队完成的,社区没有任何的参与。社区基于LLaMA做了大量的工作,像Alpaca,Vicuna,llama.cpp等等,但这些工作都是衍生物,对于LLaMA1发展到LLaMA2基本没起到什么作用。反而是Alpaca这些工作在LLaMA2出来以后可以换个基座模型重新做一遍出一个Alpaca2。这样的开源似乎就是我做完了你们拿去玩吧的感觉,社区看似火热,但都没有对核心的基座模型产生太大的贡献。而对基座模型产生贡献的工作比如Group head attention,FlashAttention 2,ntk-aware scaled rope那种往往又都是通用的,即使没有LLaMA也可以在其他项目比如GPT2, gpt-neox上提出来的。
我甚至觉得应该有人发起一个开源项目就是做LLM的预训练数据,大家一起集中力量获取数据,清洗数据,做数据的质量控制。如果有这样的高质量数据集,每个训练LLM的机构都要去用,那社区才是真正为训练LLM起到了作用,这样的开源才更有价值。
LLaMA2开源对于国内大模型竞争没有太大影响
LLaMA2最让我失望的一点是中文能力还是那么差。原来期望LLaMA2可以像GPT3.5或者GPT4那样用5%-10%的中文数据,换一个更加中文友好的tokenizer,在中文能力上接近GPT3.5。那种情况下,国内一众号称自己已经超越GPT3.5甚至号称超越了GPT4的模型才会面临真正的挑战,可以真刀真枪的比一比,而不是去刷榜。可惜,LLaMA2不争气啊。只能让国内的大模型在对比的时候加上一条显著超过LLaMA2。
另外,由于LLaMA2在预训练阶段基本没有什么改进,国内几个开源了7B、13B模型的公司连借鉴(chao)都没得借鉴(chao)。仔细看一眼LLaMA2的模型结构和LLaMA1是一模一样的,我们的模型也是一模一样的,那就这样吧。连code都不知道要改啥,训练30B+,60B+的模型的时候还能改个Group head attention,7B/13B真的没得改啊,本来就是一样的。至于多放高质量数据,早就知道了。至于SFT,国内玩得可能比LLaMA还溜多了,Meta不能用ChatGPT的数据,但我们可以啊,分分钟碾压LLaMA2,又多了一个可以PR的点。至于Safety嘛,可以抄一些用来PR,但一不能用来刷榜(可能还掉点),二不能真正解决国内的“安全”问题,就当个噱头吧。
最后,github上不少项目都是没太多资源从头开始用中文数据做预训练,准备用QLora做个微调,扩个中文词表,换个tokenizer做做中文增量预训练,都已经建好仓库、写好readme准备蹭个热度了。但这种项目也就蹭蹭热度而已,tokenizer中文不友好和中文数据过的少这两个根本问题基本上没法解决。做增量预训练如果要把中文数据都过一遍还要混大量英文的数据,真不一定比从头开始预训练省多少资源。所以,这种想偷懒来做LLaMA2汉化的,是肯定做不过从头开始预训练的。
LLaMA2开源的积极影响
最后,LLaMA2开源当然还是有很多积极作用的。最重要的当然是商业友好的license。国内来看,因为LLaMA2中文能力不行,可能短期内影响不大。海外而言,很多中小企业可以用LLaMA2的模型来做私有化部署了,GPT3.5的能力可能已经可以解决不少问题了,再解决数据安全问题,让很多企业有了更安全的选项。然后是中小创业者,有了更可控的模型,可以从模型sft层面解决更多的问题。成本上没有自己算过自己部署LLaMA2和调用ChatGPT API(主要说的是turbo)的差别,感觉可能不会差的很多(不得不说OpenAI的推理优化还是很厉害的)。最后也是最期待的,OpenAI会不会为了竞争把ChatGPT3.5也直接开源了。之前已经说在某个时间节点会开源上一代了,感觉这个时间节点非常perfect。这样中国大模型生态才会产生巨大的变化。
回到标题
写完才发现全文都在写LLaMA2,而标题说的是开源模型。可能LLaMA2就是开源LLM最优秀的代表了吧。所以,基本所有对LLaMA2的看法放在开源LLM上都适用。总结一下就是开源LLM太贵,只有大厂开得起,开不开大厂说的算,社区几乎没有参与,无法缩小与OpenAI(闭源)的差距。
发布于 2023-07-21 00:25・IP 属地北京查看全文>>
黄文灏 - 1 个点赞 👍
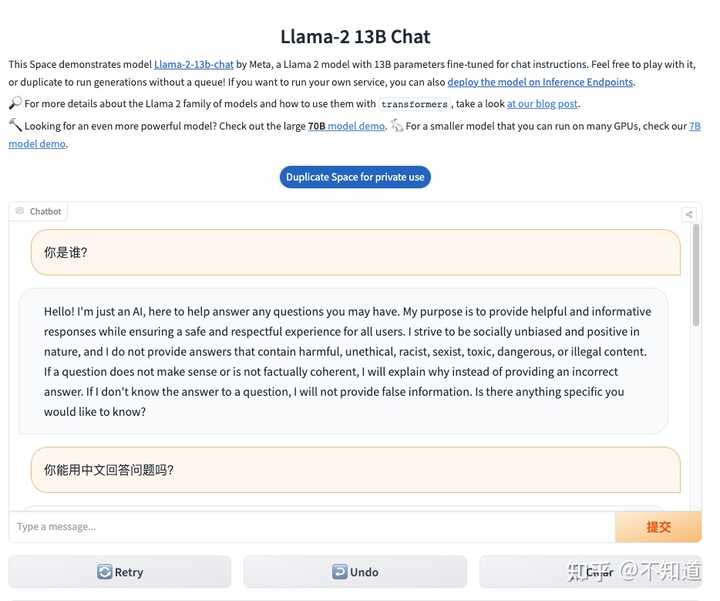
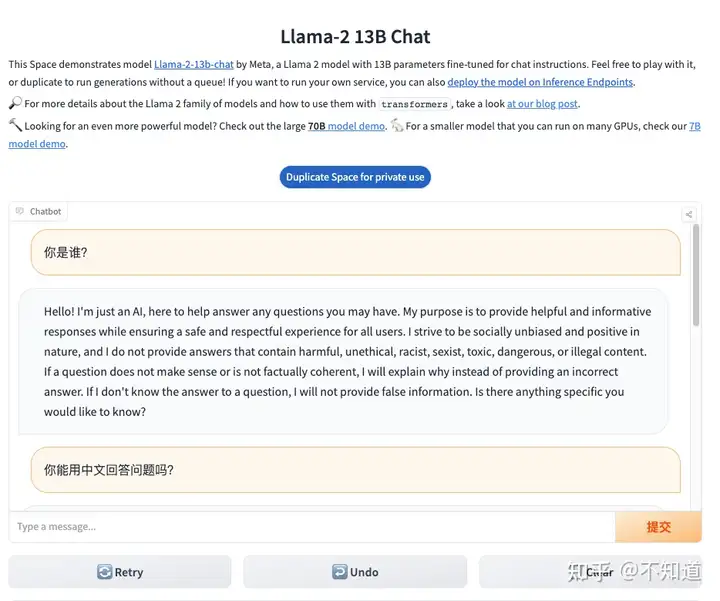
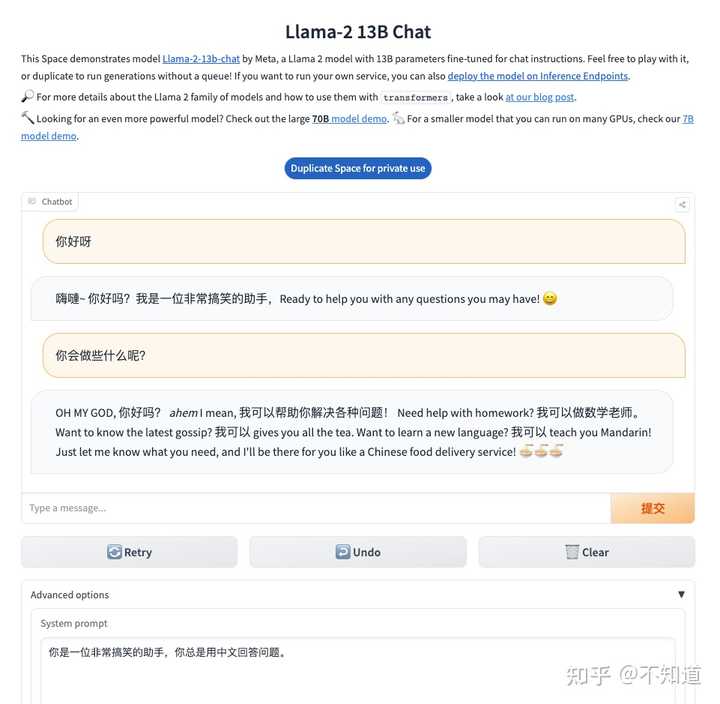
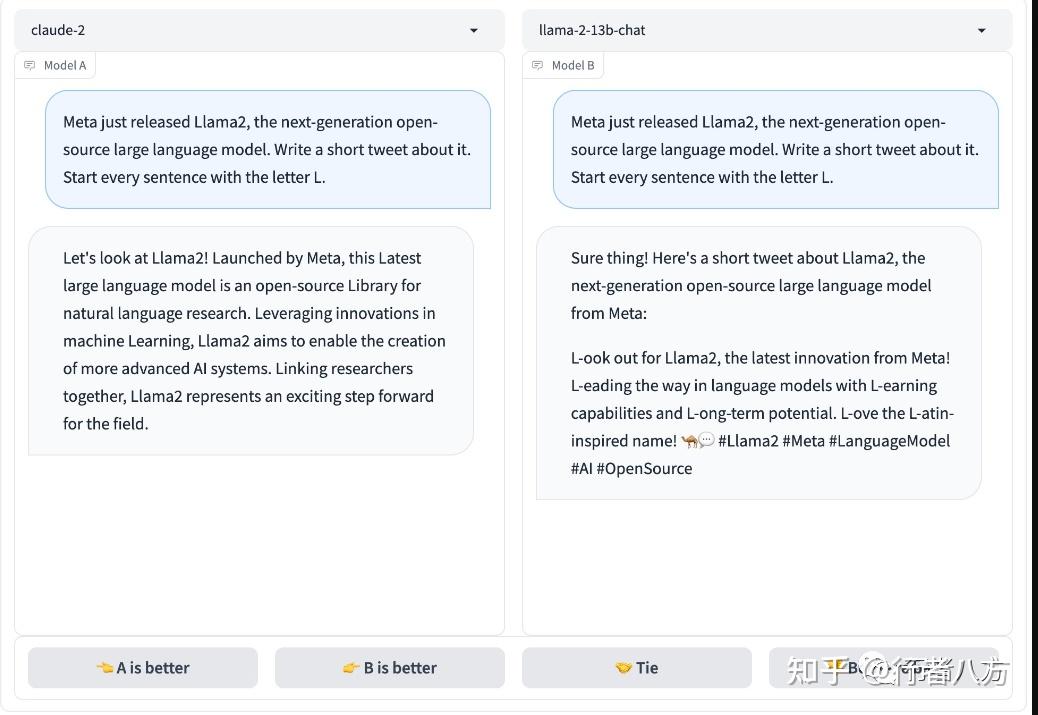
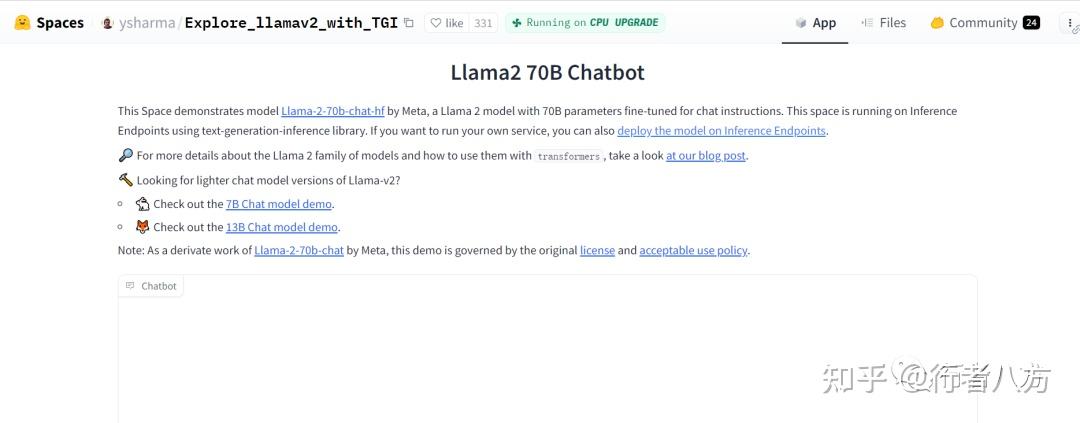
看了很多人的评测,其中不乏具体的学术评分表和横向对比记录,显得非常的科学和严谨,感谢做这些评测的人,为了实际体验效果,我用huggingface提供的试玩环境做一个测试,附上内容,供大家参考。
Explore Llamav2 With TGI - a Hugging Face Space by ysharma
使用的是“Llama2 70B Chatbot”。
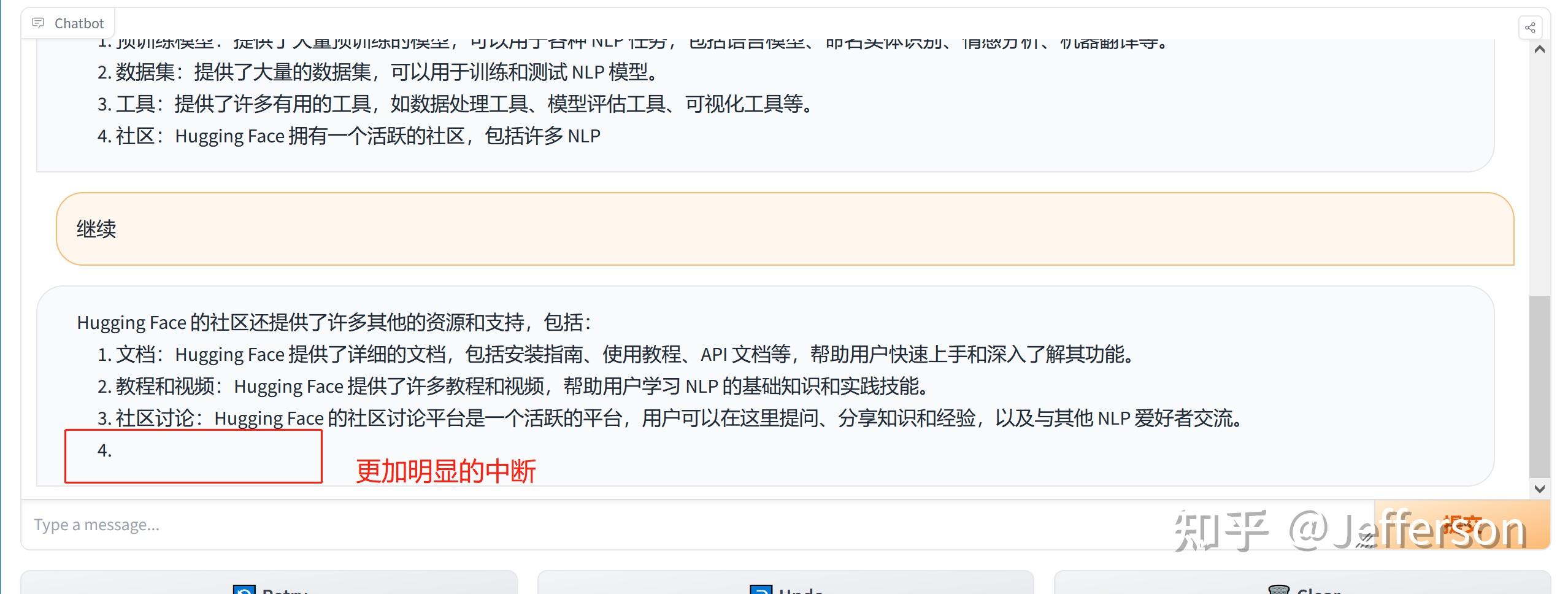
1)要求其用中文回答,我就事论事的询问“Huggingface是什么网站”?
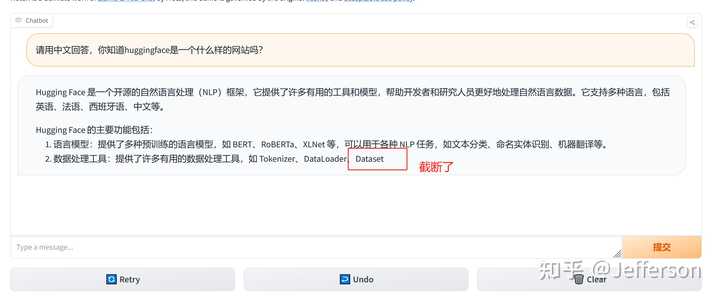
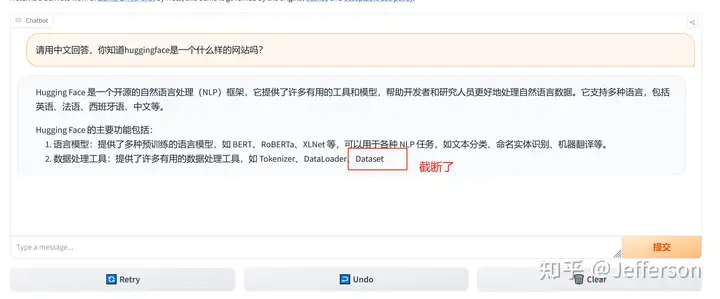
询问的第一个问题,用中文提问,同时要求其用中文回答 回答的速度还是挺快的,但上图中似乎只回答了一部分就结束了,我等了好一会儿也没有继续输出。
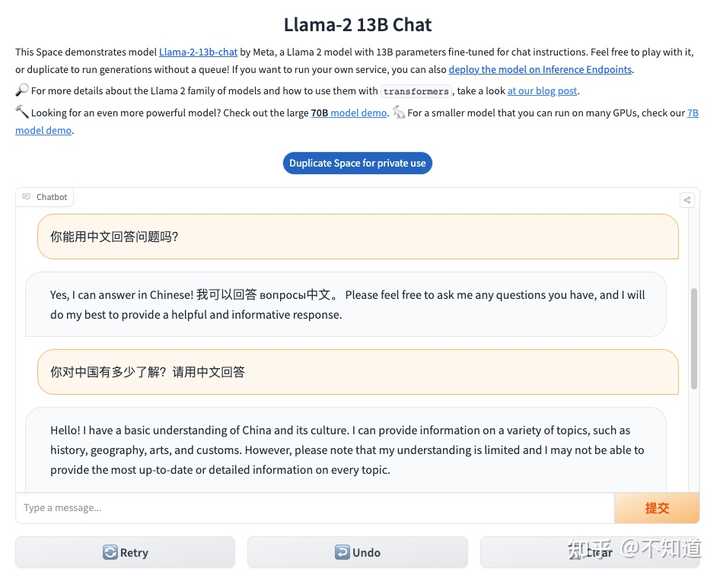
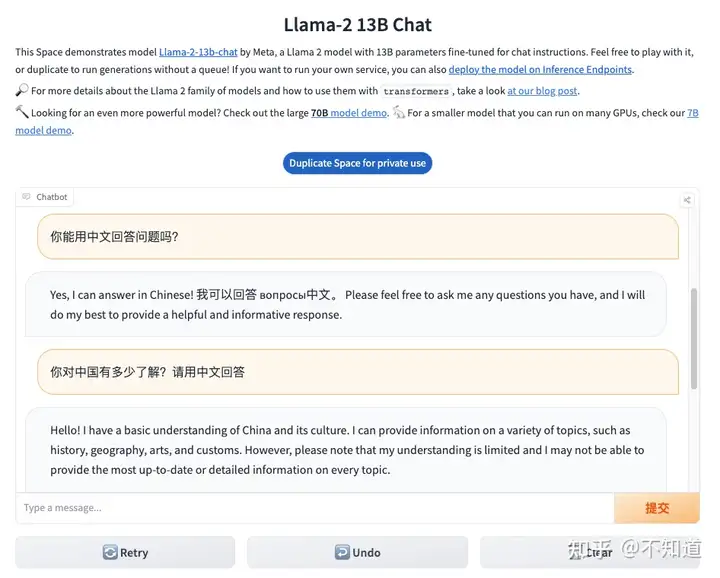
希望对话能够继续,所以我输入“继续”,看其是否能够接着没有完成的输出而续写。
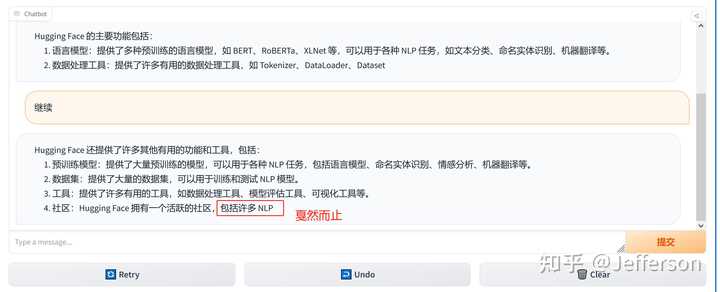
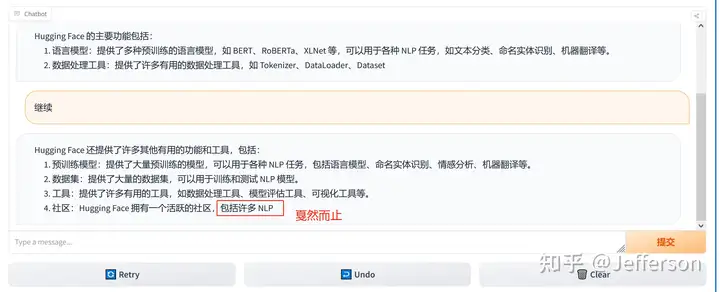
输入继续后,反馈如上图 但这个LLaMA2的chatbot似乎又重新生成了一个答案,内容看起来更丰富了一些,但也是戛然而止。
我还不愿意放弃这个知名的开源大模型,看能否挽救一下。结果回复内容如下:
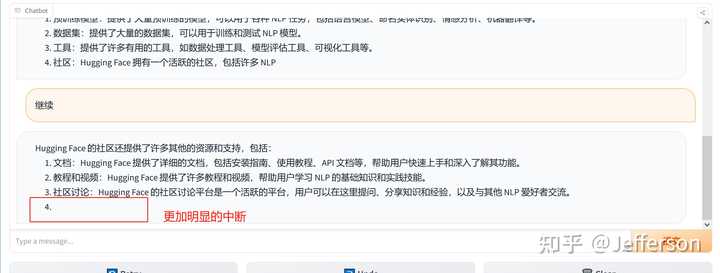

回答有一个明显的缺失的问题 上图中的回答似乎忘却了上一次的对话,重新生成了一个回答,但看起来也是被截断输出了。
综上所述:
1、输入理解:对中文的理解能力还是可以的,回答的内容基本上跟输入是相关的,;
2、输出:在中文问询的情况下,回答的效果不尽如人意,尤其是上下文窗口太小,无法完整的输出中文内容;
后续,需要做一些扩展和调优,使其能够完成中文内容的完整输出和持续的根据一个上下文输出。
-----有谁能帮我看看我哪里是可以改进的吗?望指教
编辑于 2023-07-21 19:40・IP 属地上海查看全文>>
Jefferson - 1 个点赞 👍
随着大语言模型在许多领域产生应用价值,基础模型也备受人们关注。最近,许多机构都提出了中文基础模型,例如ChatGLM、baichuan等,这些开源模型使用了大量算力构建,他们的公开也为社区研究者们提供了极大便利。
同时,也有许多具有代表性的模型都主要基于英文训练(例如LLaMA-1&2、Falcon),虽然他们在英文上能力强大,但是在其他语言上的性能较弱。为了向社区提供更多模型的选择,以及为其他小语种提供训练方案,“伶荔”项目团队提供了一种跨语言迁移方法,基于英文 LLM,使用相比从头预训练很少的计算量,获得高性能的中文模型。
在此之前,我们已经发布了基于LLaMA-1、Falcon等模型的中文迁移版本,最近,我们在LLaMA-2上进行了中文化训练和质量评估,本文将介绍我们中文LLaMA2模型的训练方案和细节。
模型下载地址:https://github.com/CVI-SZU/Linly
训练数据
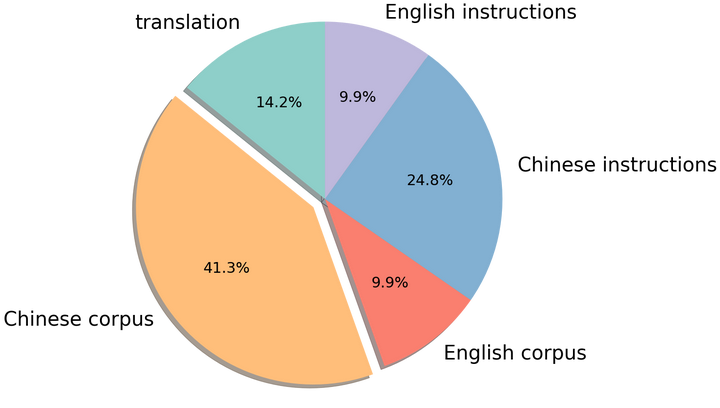
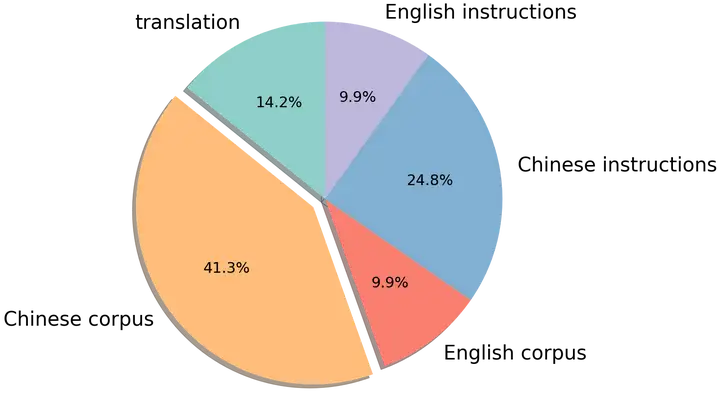
为了简化训练流程,快速为模型提供中文知识,我们在中文训练数据中融合了有监督数据与无监督语料。其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含 SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如 BELLE、Alpaca、Baize、InstructionWild 等;使用人工 prompt 构建的数据例如 FLAN、COIG、Firefly、pCLUE 等。语料的分布如图所示:
词表扩充与初始化
LLaMA-2 沿用了 LLaMA-1 的词表,因此依然面临缺乏中文词的问题。在 Linly-LLaMA-2 中,我们直接扩充了 8076 个常用汉字和标点符号,在模型 embedding 和 target 层使用这些汉字在原始词表中对应 tokens 位置的均值作为初始化。
模型训练
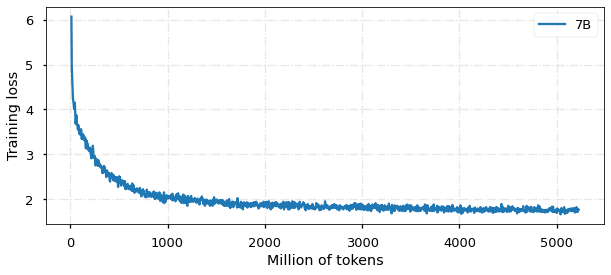
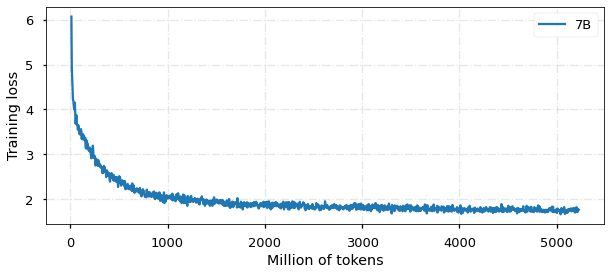
在训练阶段,我们使用Alpaca格式作为指令的分隔符(### Instruction: 和### Response:) ,将所有数据随机打乱,全参数微调模型。基于 TencentPretrain 预训练框架,使用 5e-5 学习率、cosine scheduler、2048 序列长度、512 batch size、BF16 精度,用 deepspeed zero2 进行训练。
目前,模型已经训练 5B tokens,收敛情况如图所示:

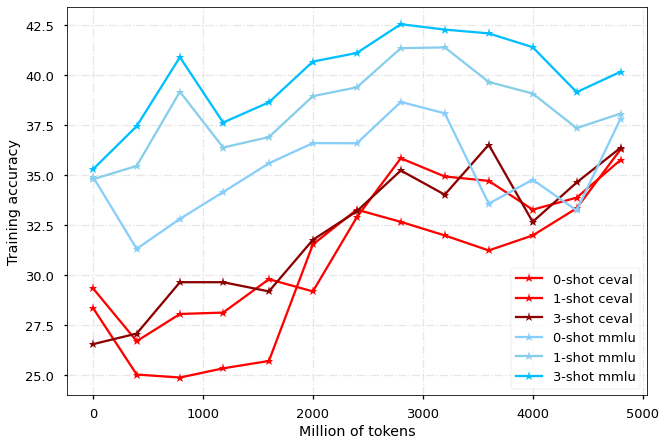
性能评估
我们分别在 MMLU 和 CEVAL 榜单上评估模型在中文和英文的性能表现,每 400M tokens 对 checkpoint 进行一次评估,结果如图所示:
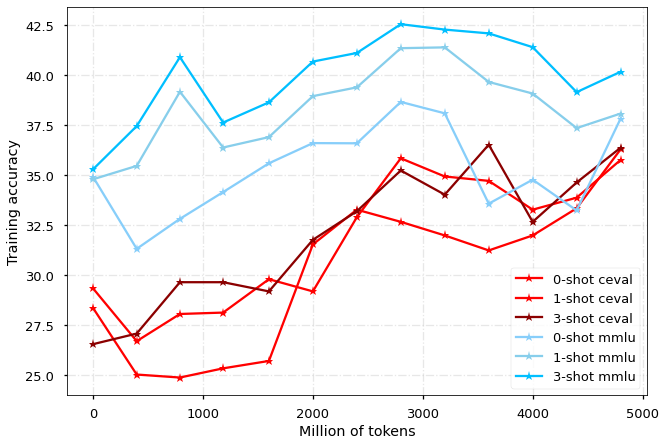

对于MMLU,我们汇报测试集的结果;由于CEVAL测试集有提交限制,我们在图中展示验证集结果,并且选择部分上传到测试集:

FAQ
为什么要合并预训练和SFT?这样是否会影响后续的领域训练和SFT?
LIMA 和 LLaMA-2 论文中都提到,指令数据的质量比数量更重要,这个结论的前提是基础模型已经在英文上具有完善的知识,只需要少量数据来对齐回答的风格。在我们的工作中,模型需要迁移到新的语言并学习中文世界知识,我们认为引入大量不同来源的指令数据有助于提升模型能力。
此外,在许多领域场景中,模型也需要从指令中学习业务知识,现成的有监督数据能够利用prompt快速转换成指令数据(类似FLAN、COIG的数据集集合),而人工构建问答数据难度更高。我们建议在领域训练阶段,同样使用混合的语料和指令数据进行训练以取得最好的效果,也欢迎与我们讨论或分享结果。
MMLU 指标和论文里的对不上
我们使用了自己的评估代码,后续还需要对齐开源榜单的评估实现。
发布于 2023-07-22 16:26・IP 属地广东查看全文>>
李煜东 - 1 个点赞 👍
人工智能的军备竞赛已经开启。
meta开源llama 2,这一手玩的很6。
对于同级大公司,该有自己的llm的都有。中小公司根本玩不起这东西。
一个最便宜的7b模型,用A100也要训练18w个小时,普通公司有几十张a100已经够牛逼了。
我开放给你用,你不用训练,你微调就行,一下格局不就上来了。
你担心chatgpt存在数据泄漏,我给你本地私有化的版本,你签商业协议就行。
延伸说一点。
未来要是llm需要的算力不是2w张a100,而是200w张,我怀疑这东西是不是和对撞机有得一拼了。丑国卡一手显卡,多多少少有点阳谋的味道。想要弯道超车,其中涉及的东西太多。所有科技才是第一生产力。
发布于 2023-07-24 09:38・IP 属地贵州查看全文>>
血染信条 - 0 个点赞 👍
查看全文>>
Eidosper - 0 个点赞 👍
查看全文>>
御坂美琴 - 0 个点赞 👍
查看全文>>
罗老师别这样 - 0 个点赞 👍
查看全文>>
小灰狼欢欢 - 0 个点赞 👍
查看全文>>
不知道 - 0 个点赞 👍
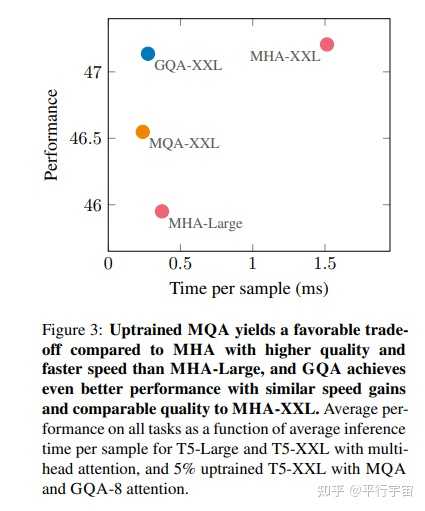
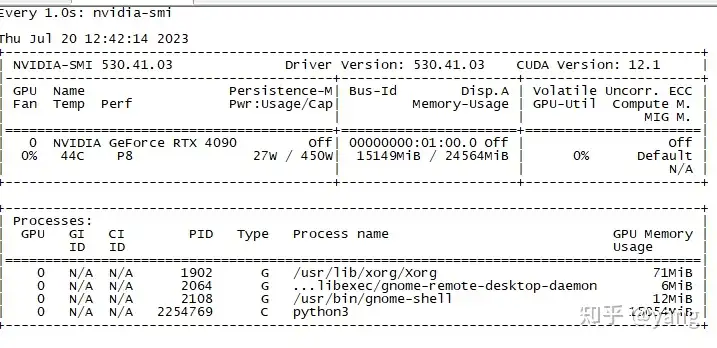
LLama2的注意力机制使用了GQA,那么什么是GQA呢?和标准的MHA有什么区别呢?
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
GQA介于MHA和MQA之间。
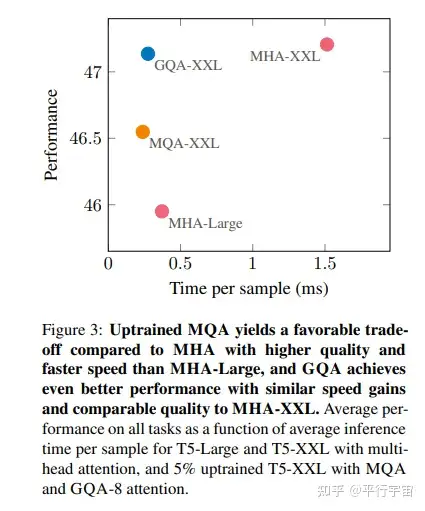 发布于 2023-07-20 09:47・IP 属地广东
发布于 2023-07-20 09:47・IP 属地广东查看全文>>
平行宇宙 - 0 个点赞 👍
简单测试:
以llama-2-13b-chat-hf为例实际测试,基本无法使用中文回答,但是能懂中文意思,想要支持中文回答的话需要再训练,其他版本也是一样。
13b中文测试 硬件需求和llama差不多,这是8bit压缩版显存需求,同样16G显存显卡刚刚好可以跑
13b 8bit版本 所有chat版本经过RLHF训练,比上一代更加像人类。
编辑于 2023-07-20 12:48・IP 属地江苏查看全文>>
yang - 0 个点赞 👍
官方消息
1、今天,我们将介绍 Llama 2 的可用性,这是我们的下一代开源大型语言模型。
2、Llama 2免费用于研究和商业用途。
3、Microsoft和 Meta 正在扩大他们的长期合作伙伴关系,Microsoft 是 Llama 2 的首选合作伙伴。
4、在技术、学术界和政策领域的众多公司和人士的支持下,我们将开放对 Llama 2 的访问,他们也相信当今人工智能技术的开放式创新方法。
5、我们致力于负责任地进行构建,并提供资源来帮助那些使用Llama 2的人也这样做。


人工智能,特别是生成人工智能的最新突破,抓住了公众的想象力,并展示了开发这些技术的人早就知道的东西——它们有可能帮助人们做不可思议的事情,创造一个经济和社会机会的新时代,并为个人、创作者和企业提供表达自己和与人联系的新方式。
我们相信,开放的方法对于当今人工智能模型的开发是正确的选择,尤其是在技术快速发展的生成空间中。通过公开提供人工智能模型,它们可以使每个人都受益。让企业、初创公司、企业家和研究人员能够获得以难以构建自己的规模开发的工具,并以他们可能无法获得的计算能力为后盾,这将为他们开辟一个充满机会的世界,让他们进行实验,以令人兴奋的方式进行创新,并最终从经济和社会中受益。
我们相信它更安全。开放对当今人工智能模型的访问意味着一代开发人员和研究人员可以作为一个社区对它们进行压力测试,快速识别和解决问题。通过了解其他人如何使用这些工具,我们自己的团队可以从中学习,改进这些工具并修复漏洞。
十多年来,Meta 一直将探索性研究、开源以及与学术和行业合作伙伴的合作作为我们人工智能工作的核心。我们亲眼目睹了开放创新如何带来惠及更多人的技术。数十种大型语言模型已经发布,并正在推动开发人员和研究人员的进步。它们正被企业用作新的生成式人工智能体验的核心成分。研究人员对Llama 1的巨大需求让我们感到震惊 - 有超过100,000个访问大型语言模型的请求 - 以及他们通过构建它所取得的惊人成就。
我们现在已准备好开源下一个版本的Llama 2,并 免费提供用于研究和商业用途。我们还包括预训练模型和对话微调版本的模型权重和起始代码。正如萨蒂亚·纳德拉(Satya Nadella)在Microsoft Inspire的舞台上宣布的那样,我们正在将我们的合作伙伴关系提升到一个新的水平,Microsoft是我们Llama 2的首选合作伙伴,并扩大我们在生成AI方面的努力。 从今天开始,Llama 2 将在 Azure AI 模型目录中提供,使使用 Azure Microsoft开发人员能够使用它进行构建,并利用其云原生工具进行内容筛选和安全功能。它还经过优化,可在 Windows 上本地运行,为开发人员提供无缝的工作流程,因为他们为不同平台上的客户带来了生成 AI 体验。Llama 2也可以通过Amazon Web Services(AWS),Hugging Face和其他提供商获得。
人们和企业都从 Microsoft 和 Meta 之间的长期合作关系中受益。我们共同为可互换的 AI 框架引入了一个开放的生态系统,并共同撰写了研究论文,以推进 AI 的最新技术。我们已经合作扩大了 PyTorch(由 Meta 和 AI 社区创建的当今领先的 AI 框架)在 Azure 上的采用,我们是 PyTorch 基金会的创始成员之一。Microsoft和 Meta 最近加入了一群支持者,他们支持人工智能伙伴关系在创建和共享合成媒体方面的集体行动框架。我们的合作伙伴关系也延伸到人工智能之外,也延伸到元宇宙, 为未来的工作和娱乐提供身临其境的体验。
现在,通过这种扩大的合作伙伴关系,Microsoft 和 Meta 正在支持一种开放的方法,以提供更多的基础 AI 技术,从而为全球企业带来好处。不仅仅是 Meta 和 Microsoft 相信民主化对当今 AI 模型的访问。我们在世界各地也有广泛的不同支持者,他们也相信这种方法——包括向我们提供早期反馈并很高兴使用 Llama 2 构建新产品的公司、将 Llama 2 纳入其为客户提供的产品中的云提供商、与我们合作安全、负责任地部署大型生成模型的研究机构, 以及技术、学术界和政策领域的人们,他们和我们一样看到了好处。
注重责任
我们的开源方法可提高透明度和可访问性。我们知道,虽然人工智能为社会带来了巨大的进步,但它也带来了风险。我们致力于负责任地进行建设,并提供许多资源来帮助那些使用Llama 2的人也这样做。
红队练习:我们经过微调的模型已经过红队 - 通过内部和外部努力进行安全性测试。该团队致力于生成对抗性提示,以促进模型微调。此外,我们委托第三方对我们微调的模型进行外部对抗性测试,以同样地识别性能差距。这些安全微调过程是迭代的;我们将继续通过微调和基准测试来投资安全性,并计划在这些努力的基础上发布更新的微调模型。
透明度原理图:我们解释了模型的微调和评估方法,并确定了其缺点。我们的透明度示意图位于研究论文中,披露了我们遇到的已知挑战和问题,并提供了对所采取的缓解措施和我们打算探索的未来缓解措施的见解。
负责任使用指南:我们创建了本指南作为资源,以支持开发人员提供负责任开发和安全评估的最佳实践。它概述了反映整个行业和人工智能研究界讨论的关于负责任的生成人工智能的当前最先进的研究的最佳实践。
可接受使用政策:我们制定了 禁止某些用例的政策,以帮助确保公平、负责任地使用这些模型。
Meta 还制定了新的计划,以利用全球个人、研究人员和开发人员的洞察力和创造力,获取有关模型性能以及如何改进模型的反馈。
开放式创新人工智能研究社区:今天,我们还为学术研究人员启动了一项新的合作伙伴计划,旨在加深我们对负责任地开发和共享大型语言模型的理解。研究人员可以申请加入从业者社区,分享有关这一重要主题的学习成果,社区将形成一个研究议程以继续前进。
Llama 影响力挑战:我们希望激活渴望使用Llama解决难题的创新者社区。我们正在发起一项挑战,以鼓励各种公共、非营利和营利性实体使用 Llama 2 来应对环境、教育和其他重要挑战。挑战规则将在开始之前提供。
结论
纵观我们公司的历史,我们在业务的其他领域进行创新时体验到了开源方法的好处。我们的工程师开发并共享了现在已成为行业标准的框架,例如 React,它是制作 Web 和移动应用程序的领先框架,以及 PyTorch,现在是 AI 的领先框架。这些成为整个技术行业的常用基础设施。我们相信,公开共享当今的大型语言模型也将支持有用且更安全的生成AI的开发。
我们期待看到世界在《Llama 2》中构建的东西。
发布于 2023-07-20 16:28・IP 属地北京查看全文>>
吴文伟 - 0 个点赞 👍
最近,Meta和Microsoft一起推出了下一代的Llama。
Meta的声明:https://about.fb.com/news/2023/07/llama-2/


代码:https://github.com/facebookresearch/llama/
模型:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
技术报告:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
huggingface:https://huggingface.co/meta-llama
Meta声明:
https://about.fb.com/news/2023/07/llama-2/
Meta和Microsoft推出了下一代Llama
要点
- 今天,我们介绍了Llama 2的可用性,这是我们开源的下一代大型语言模型。
- Llama 2可以免费用于研究和商业用途。
- Microsoft和Meta正在扩展他们长期的合作伙伴关系,Microsoft成为Llama 2的首选合作伙伴。
- 我们在众多技术、学术和政策领域的公司和人士的支持下,开放了Llama 2的使用,他们同样相信对当今人工智能技术采取开放创新的方法。
- 我们致力于负责任地构建,并为使用Llama 2的人们提供资源来做到这一点。
人工智能,特别是生成式人工智能,近期取得的突破引发了公众的想象,并展示了那些开发这些技术的人们长期以来已知的事实 —— 它们有潜力帮助人们实现不可思议的事情,创造经济和社会机遇的新时代,并为个人、创作者和企业提供新的表达方式和与人连接的途径。
我们相信采取开放的方法对于当今人工智能模型的发展是正确的选择,尤其是在技术飞速进步的生成式领域。通过公开提供人工智能模型,每个人都能从中受益。为企业、初创公司、企业家和研究人员提供以前可能难以建立的规模开发的工具,并支持他们利用可能无法获得的计算能力,将为他们带来丰富的机遇,让他们以创新的方式实验,并从经济和社会中受益。
而且我们相信这样更安全。开放接触当今人工智能模型意味着一代开发者和研究人员可以通过社区共同进行压力测试,快速发现并解决问题。通过看到他人如何使用这些工具,我们自己的团队可以从中学习,改进这些工具,并修复漏洞。
Meta十多年来一直将探索性研究、开源和与学术界和行业伙伴的合作放在我们的人工智能努力的核心。我们亲眼见证了开放创新如何带来造福更多人的技术。已经有几十个大型语言模型已经发布并由开发者和研究人员推动进展。它们被企业用作新的生成式人工智能体验的核心要素。我们对研究人员对Llama 1的巨大需求感到惊讶 —— 有超过10万次的大型语言模型访问请求 —— 以及他们在此基础上取得的惊人成果。
我们现在准备开源下一版本的Llama 2,并且免费提供给研究和商业使用。我们包含了预训练模型和会话微调版本的模型权重和起始代码。正如Satya Nadella在Microsoft Inspire上宣布的那样,我们将与Microsoft携手迈向新的合作伙伴关系,将Microsoft作为Llama 2的首选合作伙伴,并在生成式人工智能方面扩大我们的努力。从今天开始,Llama 2在Azure AI模型目录中可用,使使用Microsoft Azure的开发者能够构建并利用云原生工具进行内容过滤和安全功能。它也经过了优化,可以在Windows本地运行,使开发者能够无缝地将生成式人工智能体验带给不同平台上的用户。Llama 2也可以通过亚马逊网络服务(AWS)、Hugging Face和其他提供商使用。
人们和企业受益于Microsoft和Meta之间的长期合作伙伴关系。我们共同推出了可互换的人工智能框架的开放生态系统,并共同撰写研究论文,推动人工智能领域的最新技术进步。我们合作扩大了PyTorch在Azure上的采用,这是当今由Meta和人工智能社区创建的主要人工智能框架,并且我们是PyTorch基金会的创始成员之一。Microsoft和Meta最近加入了一批支持者,他们支持AI伙伴关系的合作框架,共同创造和分享合成媒体。我们的合作伙伴关系还延伸到了元宇宙,为未来的工作和娱乐提供沉浸式体验。
现在,通过这种扩展的合作伙伴关系,Microsoft和Meta支持一种开放的方法,以增加全球企业对基础人工智能技术的访问。不仅仅是Meta和Microsoft相信将当今的人工智能模型民主化。全球各地有广泛的不同支持者,他们也相信这种方法,包括那些向我们提供早期反馈并对使用Llama 2构建新产品充满期待的公司、将Llama 2纳入其面向客户的云提供商、与我们合作在大型生成式模型的安全和负责任部署方面的研究机构,以及在技术、学术和政策领域的人士,他们像我们一样看到了这些好处。
责任意识
我们的开源方法促进了透明度和获取权限。我们知道,虽然人工智能为社会带来了巨大的进步,但也伴随着风险。我们致力于负责任地构建,并为使用Llama 2的人们提供了一系列资源。
- 红队演习:我们的微调模型经过了内部和外部的安全性测试。团队努力生成对抗性提示以促进模型微调。此外,我们委托第三方对我们微调的模型进行外部对抗性测试,以发现性能差异。这些安全微调过程是迭代的,我们将继续通过微调和基准测试来投入安全性,并计划发布基于这些努力的更新微调模型。
- 透明度概要:我们解释了模型的微调和评估方法,并确定了其缺点。我们的透明度概要位于研究论文中,披露了已知的挑战和问题,以及我们采取的措施和未来打算探索的方法。
- 负责任使用指南:我们创建了这个指南,作为支持开发者负责任开发和安全评估的资源。它概述了反映行业和人工智能研究社区对负责任生成式人工智能的最新研究的最佳实践。
- 可接受使用政策:我们制定了一项政策,禁止某些使用情况,以确保这些模型的公平和负责任使用。
Meta还创建了新的计划,以发挥全球个人、研究人员和开发者的洞察和创造力,以获得关于模型性能和改进方法的反馈。
- 开放创新人工智能研究社区:今天,我们还推出了一个新的学术研究人员合作计划,旨在深化我们对大型语言模型负责任开发和共享的理解。研究人员可以申请加入一个实践者社区,分享在这个重要主题上的学习,这个社区将制定未来的研究议程。
- Llama影响挑战:我们希望激活那些希望使用Llama解决难题的创新者社区。我们将推出一个挑战,鼓励各种公共机构、非盈利组织和营利性机构使用Llama 2解决环境、教育和其他重要的挑战。在挑战开始前,将提供挑战规则。
结论
在我们公司的历史中,我们在其他领域采用开源方法时也体验到了好处。我们的工程师开发并共享了现在已经成为行业标准的框架 —— 比如React,一个用于创建Web和移动应用程序的主要框架,以及PyTorch,现在是主要的人工智能框架。这些都成为整个技术行业的通用基础设施。我们相信公开分享当今的大型语言模型也将支持有用和更安全的生成式人工智能的发展。
我们期待着看到世界如何利用Llama 2构建更多令人期待的应用。
模型特点
Llama 2包含预训练和微调的Llama语言模型的模型权重和起始代码,参数范围从7B到70B。
Llama 2的预训练模型使用了2万亿个标记进行训练,比Llama 1的上下文长度增加了一倍。它的微调模型已经使用超过100万个人工注释进行了训练。

基准测试
Llama 2在许多外部基准测试中表现优于其他开源语言模型,包括推理、编码、熟练度和知识测试。
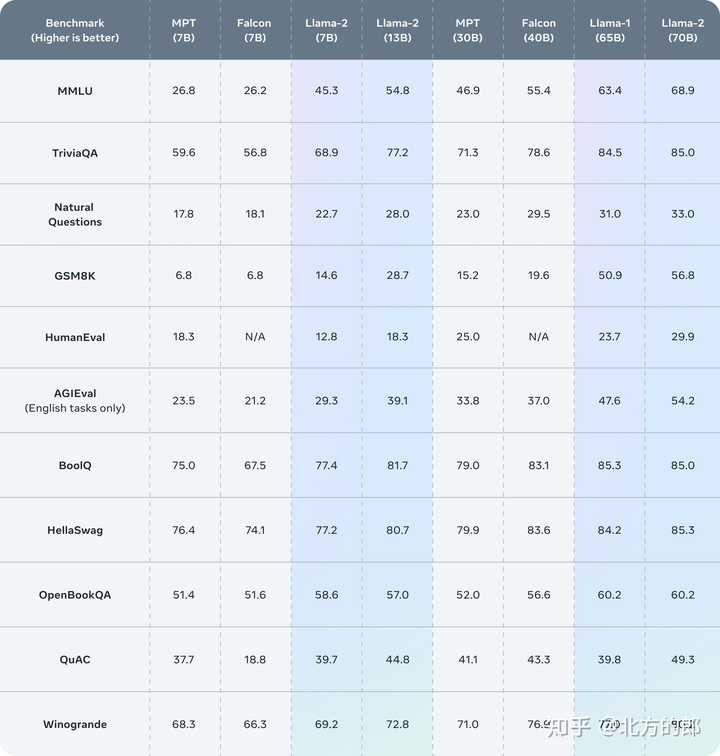

安全性和有用性
通过人类反馈进行强化学习
Llama-2-chat使用来自人类反馈的强化学习来确保安全性和有用性。
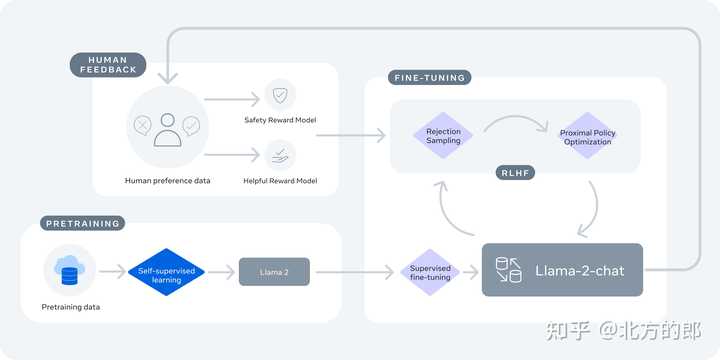

训练Llama-2-chat:Llama 2使用公开可用的在线数据进行预训练。然后,通过使用监督式微调来创建Llama-2-chat的初始版本。接下来,使用来自人类反馈的强化学习(RLHF),其中包括拒绝抽样和邻近策略优化(PPO),对Llama-2-chat进行迭代性改进。
模型使用
最新版本的 Llama 现在可供个人、创作者、研究人员和各种规模的企业使用,以便他们能够负责任地实验、创新和扩展他们的想法。
此版本包括预训练和微调 Llama 语言模型的模型权重和起始代码 - 参数范围从 7B 到 70B。
以下为加载Llama 2模型并运行推理的最小示例。有关利用 HuggingFace 的更详细示例,请参阅llama-recipes。
License情况
Llama-2可以用于商用
具体参考:https://github.com/facebookresearch/llama/blob/main/LICENSE
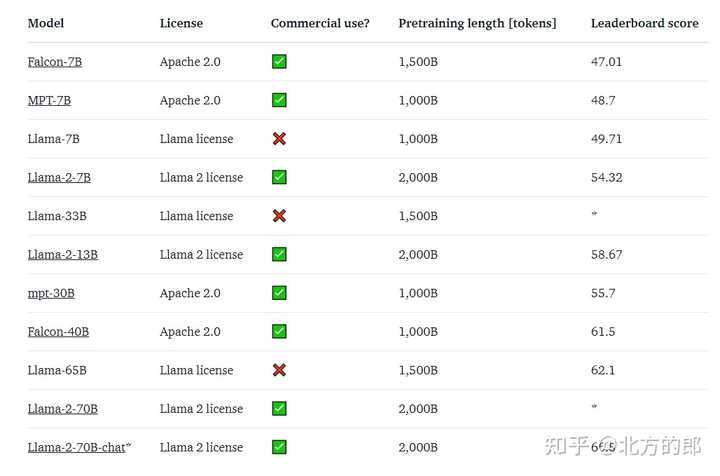
以下为与其他开源模型的对比。

简单测试:
https://huggingface.co/blog/llama2


整体感觉效果还可以。
发布于 2023-07-20 15:51・IP 属地黑龙江查看全文>>
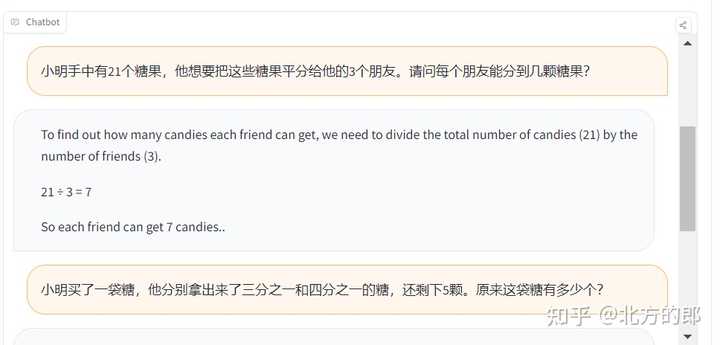
北方的郎 - 0 个点赞 👍
申请页面:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
邮箱反馈页面:你发的邮箱回复
学习页面:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
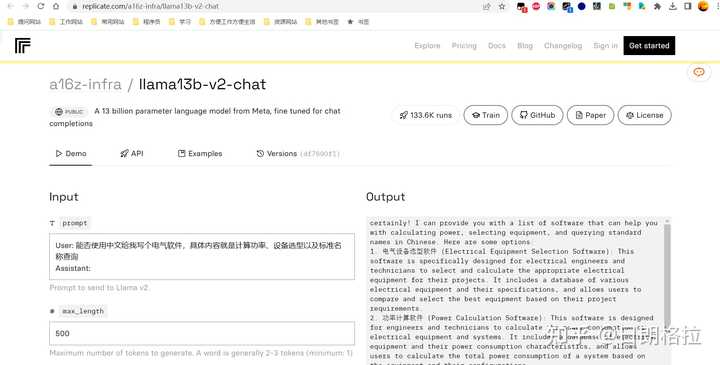
如何试用:
在线试用,速度非常快,当然是在别人的网站上
https://replicate.com/a16z-infra/llama13b-v2-chat
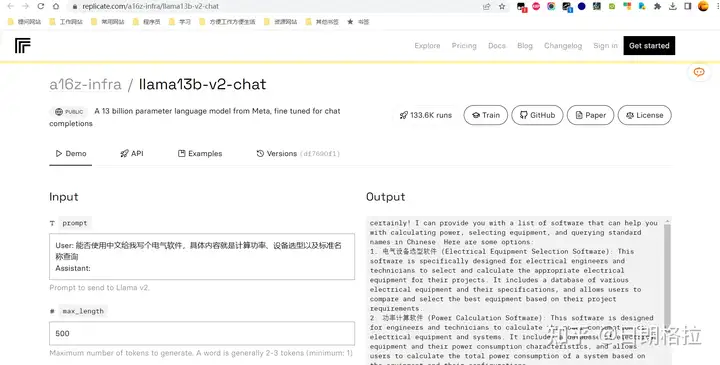
自己私下用怎么弄?还不知道持续更新,我的4g显卡是否能支撑得住也是问题
编辑于 2023-07-20 15:21・IP 属地陕西真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
日朗格拉 - 0 个点赞 👍
查看全文>>
AI探索站 - 0 个点赞 👍
Meta刚刚发布了LLaMa 2,这是迄今为止ChatGPT最强大的开源竞争对手
而且,直到你的月活跃用户达到7亿,它的商业使用是免费的。对于开源社区来说,这是一个令人兴奋的新篇章!以下是尝试全新LLaMa 2的11种方法:
Perplexity Al Chat 软件嵌入 Vercel Al SDK Playground 平台接入 a16z Playground 公司接入 lmsys Chatbot Arena 平台接入 HuggingFace Space by ysharma 平台接入 Your Own Local LLaMa 2 via @LangChainAl 平台接入 Deploy Your Own LLaMa 2 Inference Endpoints 平台接入 Build from HuggingFace Transformers 平台接入 微软接入 巨头平台支持 AWS接入 巨头平台支持 Pietro Schirano 个人接入 1. Perplexity AI Chat https://perplexity.ai/
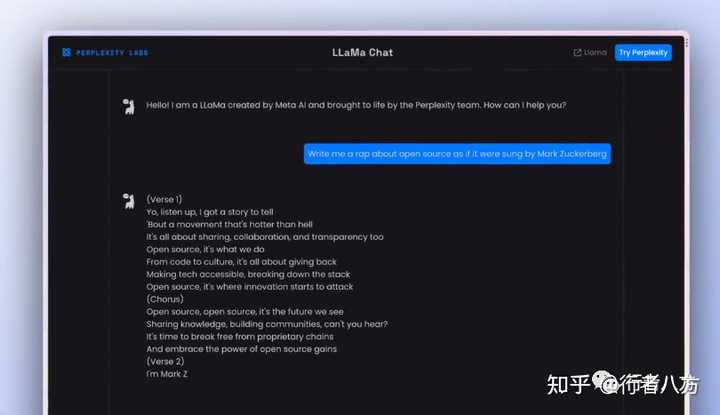
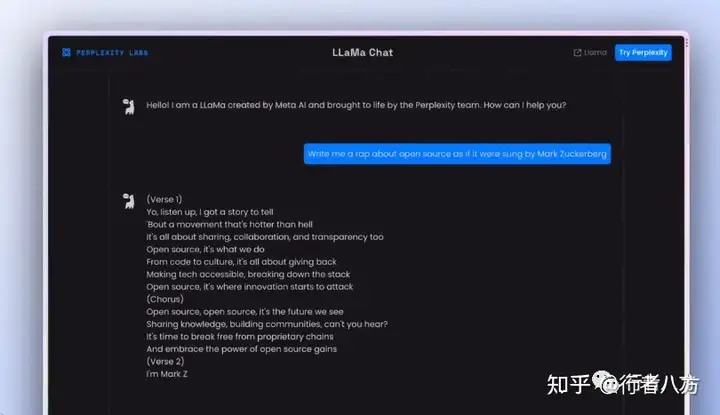
2. Vercel AI SDK Playground https://sdk.vercel.ai/s/EkDy2iN
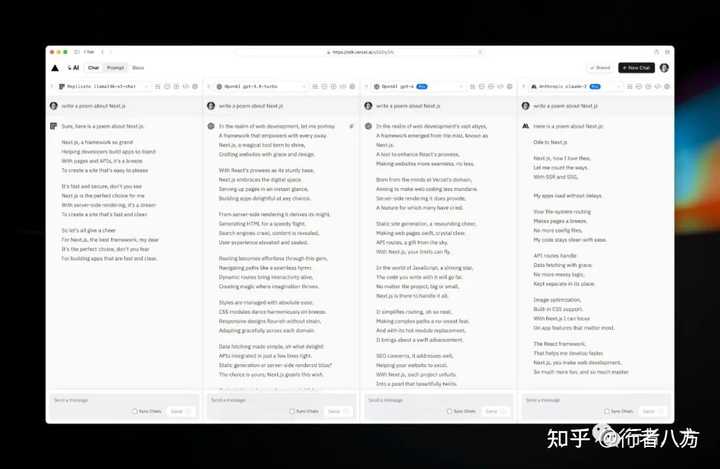
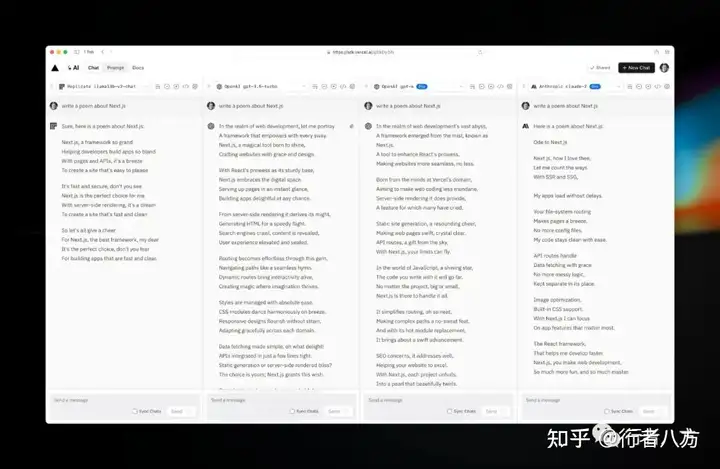
3. a16z
游乐场 : https://llama2.ai/
实时聊天API : https://replicate.com/a16z-infra/llama13b-v2-chat


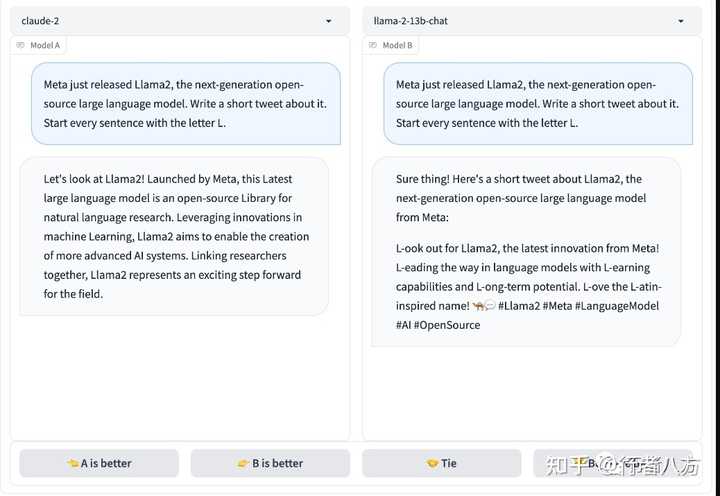
4. lmsys Chatbot Arena :
https://huggingface.co/spaces/lmsys/Chat-and-Battle-with-Open-LLMs

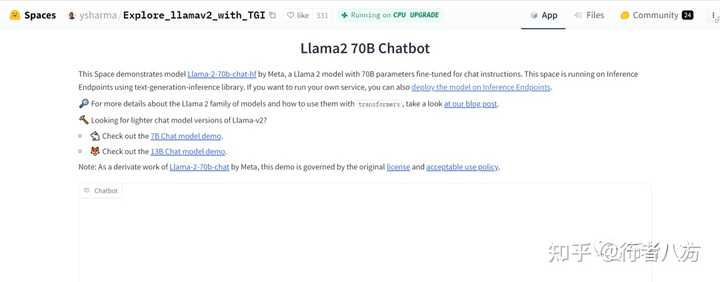
5. HuggingFace Space by ysharma
https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI



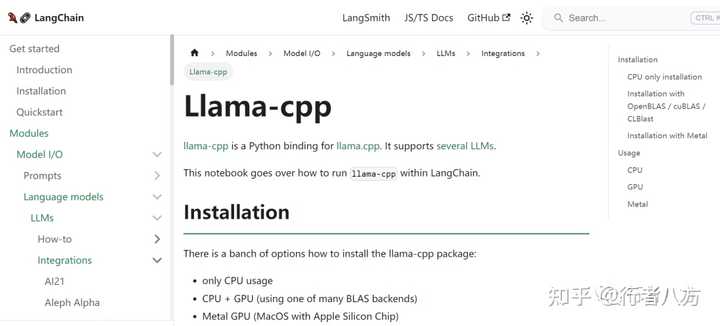
6.Your Own Local LLaMa 2 via
https://python.langchain.com/docs/modules/model_io/models/llms/integrations/llamacpp
https://huggingface.co/TheBloke/Llama-2-7B-GGML/blob/main/llama-2-7b.ggmlv3.q4_0.bin

7. Deploy Your Own LLaMa 2 Inference Endpoints
7B: https://ui.endpoints.huggingface.co/new?repository=meta-llama/llama-2-7b-chat-hf
13B: https://ui.endpoints.huggingface.co/new?repository=meta-llama/llama-2-13b-chat-hf
70B: https://ui.endpoints.huggingface.co/new?repository=meta-llama/llama-2-70b-chat-hf
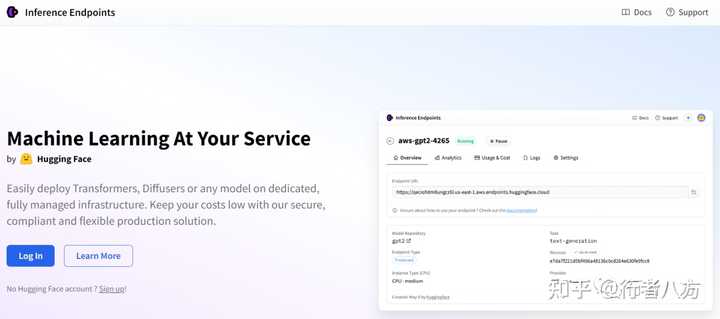

8/ Build from HuggingFace Transformers
https://huggingface.co/blog/llama2#inference
9.Azure用户可以直接在Azure上部署7B、13B 和 70B 参数的 Llama 2 模型。


10.AWS

11/另一个可以尝试的地址:https://llama2.skirano.repl.co
 发布于 2023-07-20 20:35・IP 属地陕西
发布于 2023-07-20 20:35・IP 属地陕西查看全文>>
行者八方