
随着大语言模型在许多领域产生应用价值,基础模型也备受人们关注。最近,许多机构都提出了中文基础模型,例如ChatGLM、baichuan等,这些开源模型使用了大量算力构建,他们的公开也为社区研究者们提供了极大便利。
同时,也有许多具有代表性的模型都主要基于英文训练(例如LLaMA-1&2、Falcon),虽然他们在英文上能力强大,但是在其他语言上的性能较弱。为了向社区提供更多模型的选择,以及为其他小语种提供训练方案,“伶荔”项目团队提供了一种跨语言迁移方法,基于英文 LLM,使用相比从头预训练很少的计算量,获得高性能的中文模型。
在此之前,我们已经发布了基于LLaMA-1、Falcon等模型的中文迁移版本,最近,我们在LLaMA-2上进行了中文化训练和质量评估,本文将介绍我们中文LLaMA2模型的训练方案和细节。
模型下载地址:https://github.com/CVI-SZU/Linly
训练数据
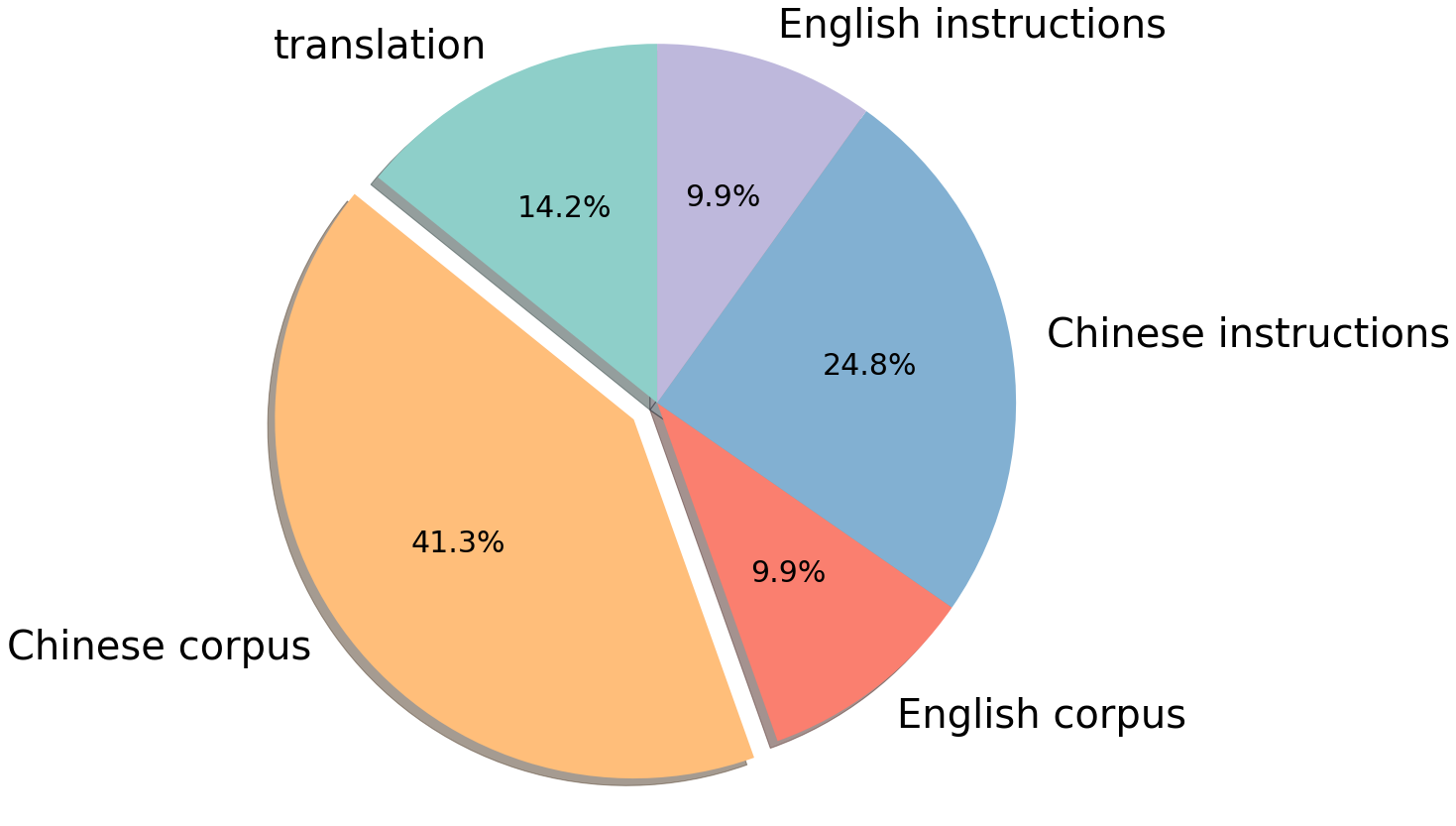
为了简化训练流程,快速为模型提供中文知识,我们在中文训练数据中融合了有监督数据与无监督语料。其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含 SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如 BELLE、Alpaca、Baize、InstructionWild 等;使用人工 prompt 构建的数据例如 FLAN、COIG、Firefly、pCLUE 等。语料的分布如图所示:
词表扩充与初始化
LLaMA-2 沿用了 LLaMA-1 的词表,因此依然面临缺乏中文词的问题。在 Linly-LLaMA-2 中,我们直接扩充了 8076 个常用汉字和标点符号,在模型 embedding 和 target 层使用这些汉字在原始词表中对应 tokens 位置的均值作为初始化。
模型训练
在训练阶段,我们使用Alpaca格式作为指令的分隔符(### Instruction: 和### Response:) ,将所有数据随机打乱,全参数微调模型。基于 TencentPretrain 预训练框架,使用 5e-5 学习率、cosine scheduler、2048 序列长度、512 batch size、BF16 精度,用 deepspeed zero2 进行训练。
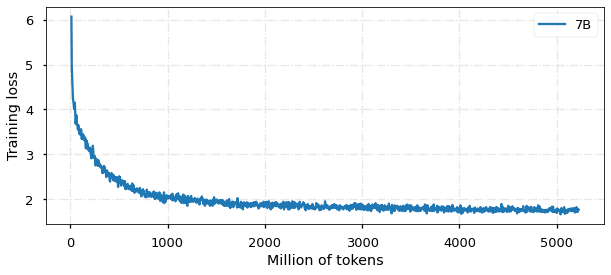
目前,模型已经训练 5B tokens,收敛情况如图所示:
性能评估
我们分别在 MMLU 和 CEVAL 榜单上评估模型在中文和英文的性能表现,每 400M tokens 对 checkpoint 进行一次评估,结果如图所示:
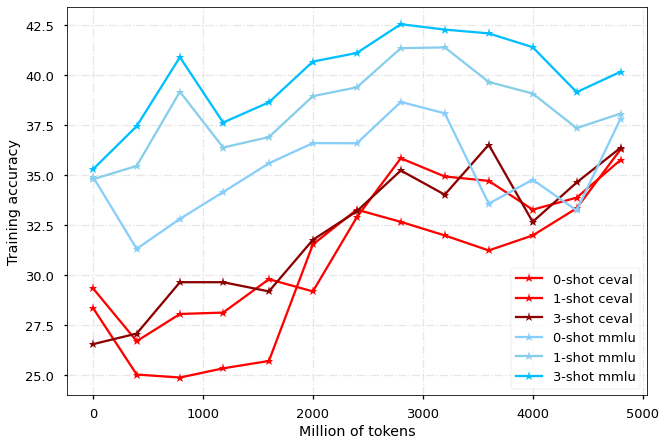
对于MMLU,我们汇报测试集的结果;由于CEVAL测试集有提交限制,我们在图中展示验证集结果,并且选择部分上传到测试集:
FAQ
为什么要合并预训练和SFT?这样是否会影响后续的领域训练和SFT?
LIMA 和 LLaMA-2 论文中都提到,指令数据的质量比数量更重要,这个结论的前提是基础模型已经在英文上具有完善的知识,只需要少量数据来对齐回答的风格。在我们的工作中,模型需要迁移到新的语言并学习中文世界知识,我们认为引入大量不同来源的指令数据有助于提升模型能力。
此外,在许多领域场景中,模型也需要从指令中学习业务知识,现成的有监督数据能够利用prompt快速转换成指令数据(类似FLAN、COIG的数据集集合),而人工构建问答数据难度更高。我们建议在领域训练阶段,同样使用混合的语料和指令数据进行训练以取得最好的效果,也欢迎与我们讨论或分享结果。
MMLU 指标和论文里的对不上
我们使用了自己的评估代码,后续还需要对齐开源榜单的评估实现。