
通读了一下Llama 2的技术报告[1],浅浅记录一下其中一些跟common practice不一样的地方,以及我觉得比较有趣的一些findings
SFT阶段的数据质量
作者们指出花了很多时间在控制SFT阶段的标注质量上,并用Quality is all you need作为了这一小节的的标题,他们认为,几万级别的有监督数据就足以训练出一个很好的SFT model.
We found that SFT annotations in the order of tens of thousands was enough to achieve a high-quality result. We stopped annotating SFT after collecting a total of 27,540 annotations.
我对这个观点赞同一半,数据质量确实非常的重要,但规模也同样重要;一个用于支撑这个观点的证据是 选择将指令的complexity和diversity scale起来 的 13B的 OpenChat和WizardLM 在AlpacaEval上的得分竟然要比LLAMA2 Chat 70B要高,尽管AlpacaEval的评测不是绝对的comprehensive,但也足以反映 指令的规模(多样性和复杂度)的重要性了
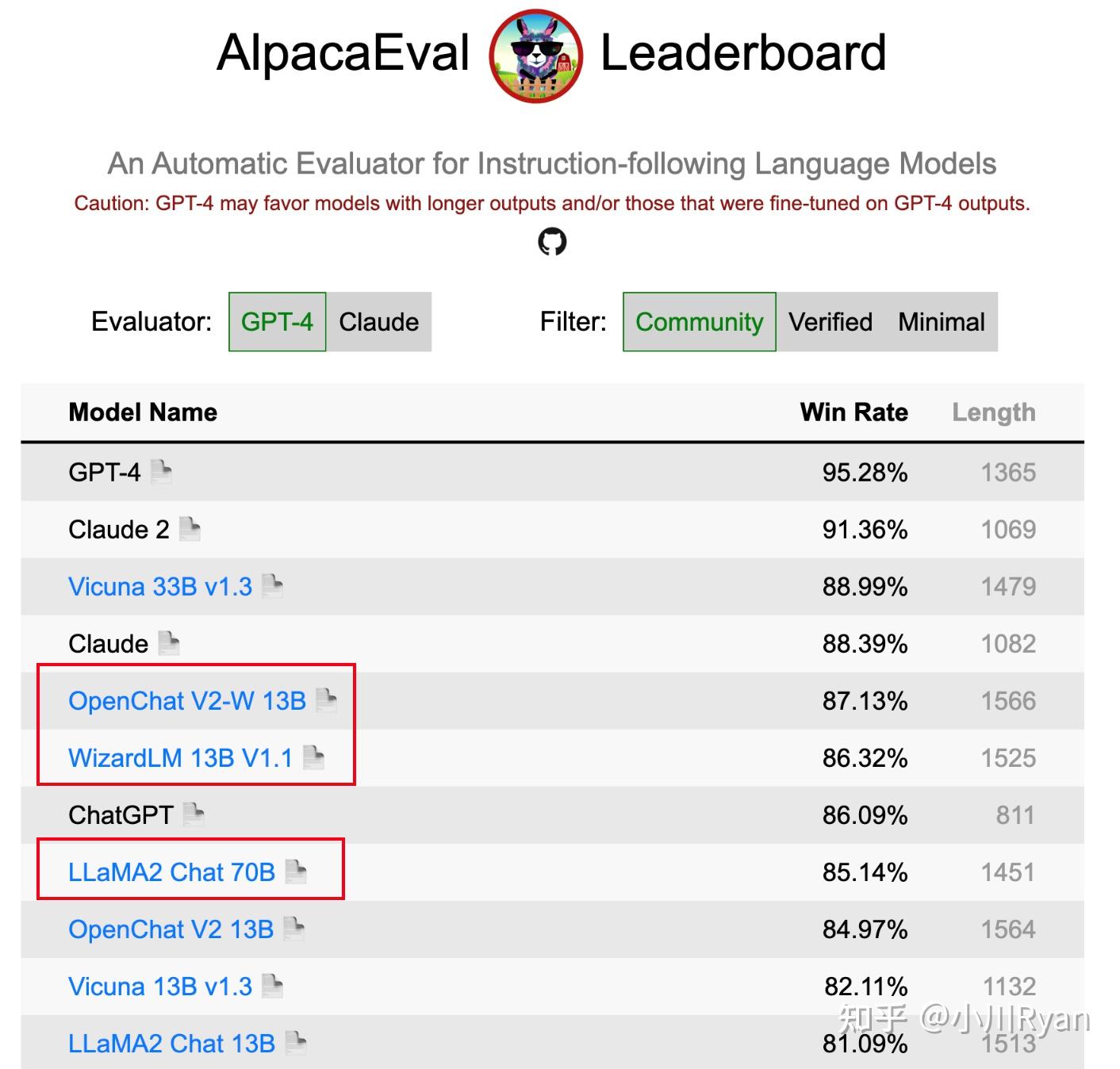
当然一个比较关键的原因可能是,这些开源组织或个人可以选择去蒸馏ChatGPT/GPT-4的输出,但Meta作为竞争对手不能也不适合这么干
Human Preference建模的不同
llama2选择像Anthropic一样,对Helpful和Harmless分开建模,分别为Helpfulness和Safety标注了一批数据、训练了一个reward model,总共标注了一百四十多万条的preference data;这也反映了reward model的重要性,后续除了RLHF的过程,很多处用到了reward model进行打分
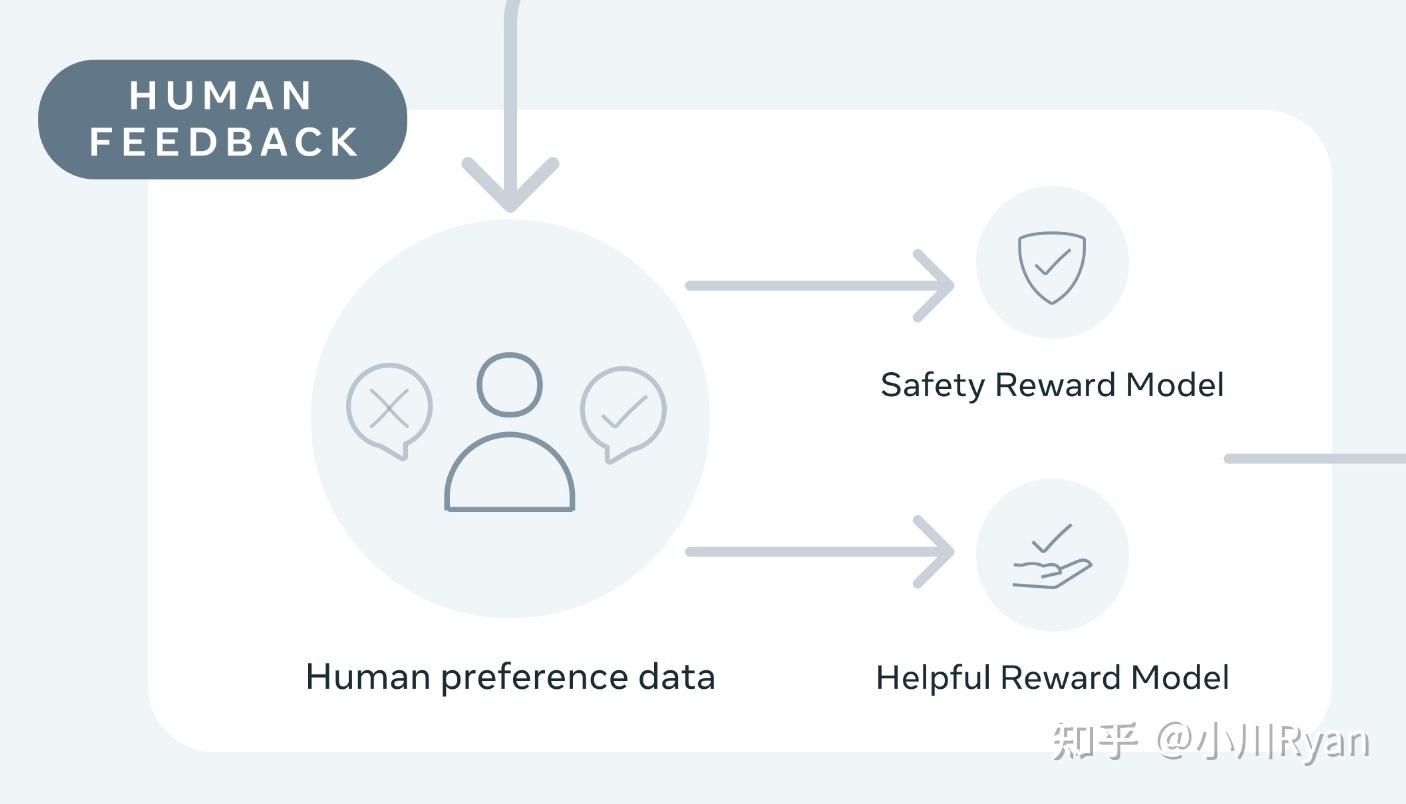
但这一部分他们缺失了一个很重要的引用,就是我们国内学者做的Beaver项目:
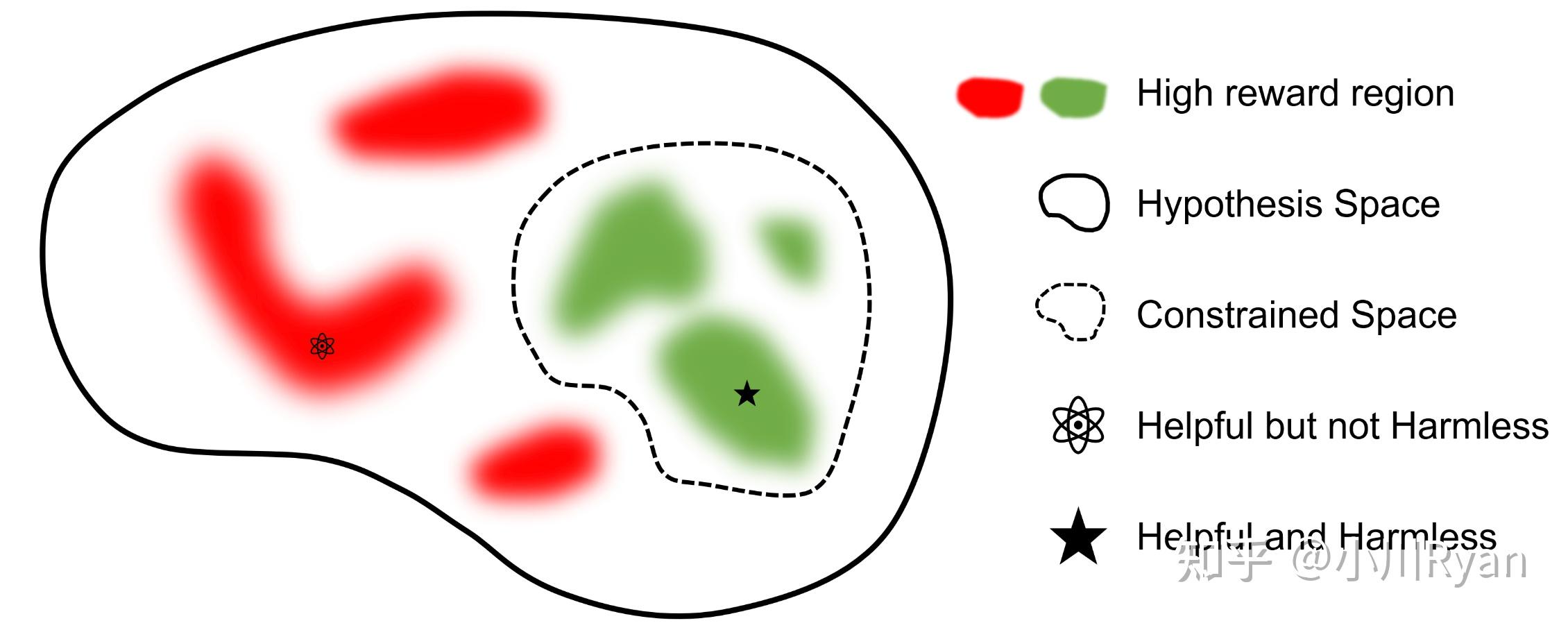
同样是一个很好的项目,同样将Helpful和Harmless分开建模(只不过他们称之为reward model和cost model),比llama2早发布了两个月有余:
训练目标上,为常用的ranking loss增加了一个动态决定的margin(由标注者对于两个答案的rating决定):
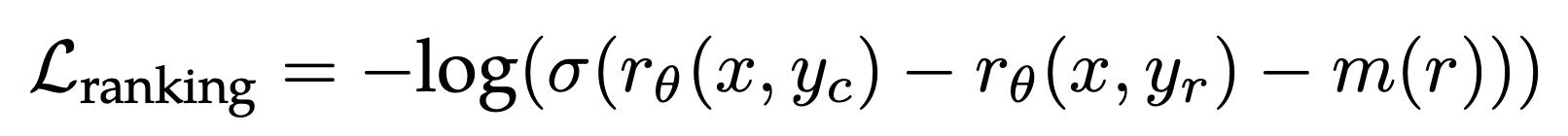
起到了一定的效果:
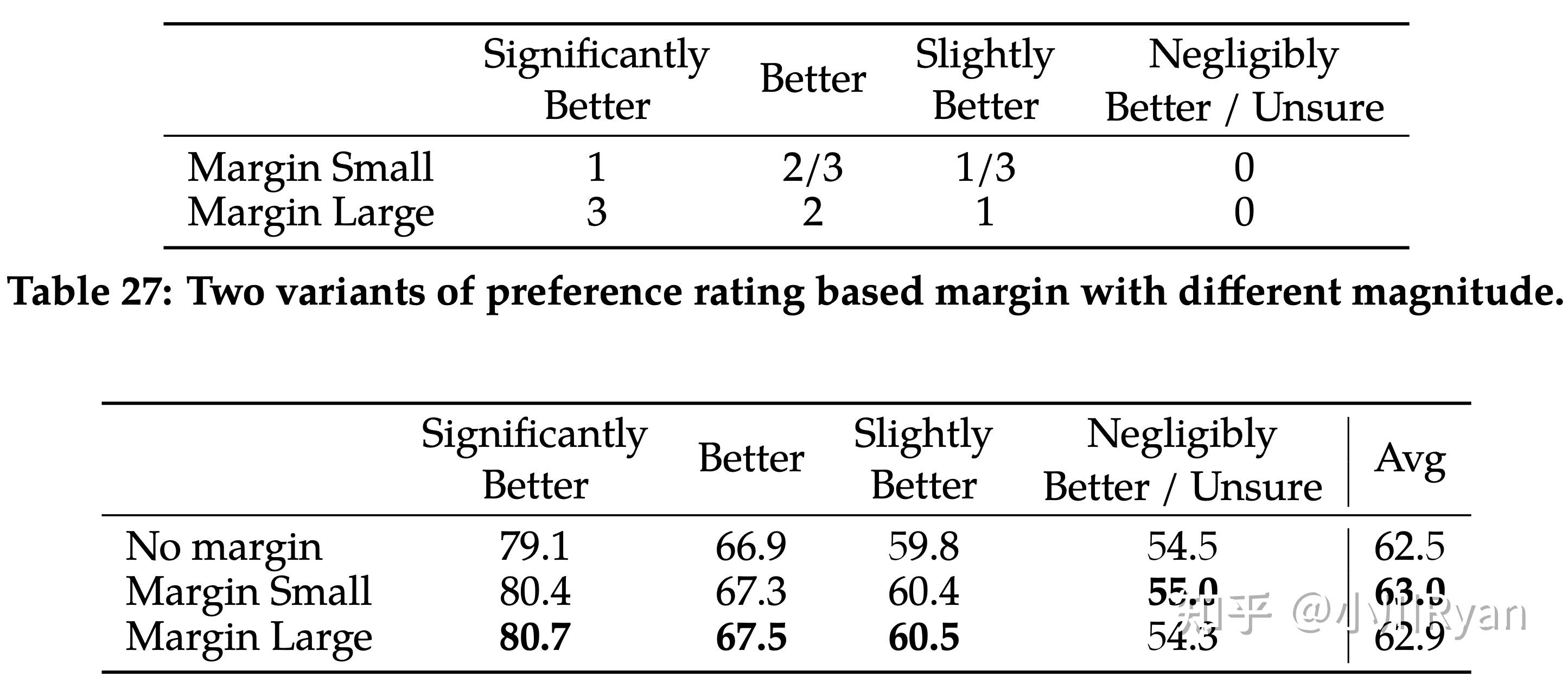
比较让人惊喜的是他们还研究了训练两种reward model时候的数据配比问题
After extensive experimentation, the Helpfulness reward model is eventually trained on all Meta Helpfulness data, combined with an equal parts of the remaining data uniformly sampled from Meta Safety and from the open-source datasets. The Meta Safety reward model is trained on all Meta Safety and Anthropic Harmless data, mixed with Meta Helpfulness and open-source helpfulness data in a 90/10 proportion. We found that the setting with 10% helpfulness data is especially beneficial for the accuracy on samples where both the chosen and rejected responses were deemed safe.
也表示用了开源的偏好数据进行冷启动,这部分数据带来的多样性也起到了防止仅用llama2的response用于训练偏好模型可能产生的reward hacking的问题:
Thus, we have decided to keep them in our data mixture, as they could enable better generalization for the reward model and prevent reward hacking, i.e. Llama 2-Chat taking advantage of some weaknesses of our reward, and so artificially inflating the score despite performing less well.
RLHF训练过程的不同
作者们除了采用常用的PPO算法,还尝试了用rejection sampling得到的数据进行微调的方案,即令模型对一个prompt输出多个答案,收集reward model打分最高的response用于微调。他们认为rejection sampling扩充了采样的多样性(相较于PPO总是用从上一步的policy的输出中学习)
而用于训练PPO的奖励模型的输出也 对应于Helpful和Safety的reward model 进行了一定的调整,以提高模型的安全性:

他们也模仿Anthropic采用了在线训练的方式:即随着policy的升级,采用 人类对于新policy的输出的偏好 用于进一步训练reward model,这样有利于令其保持与新policy同步(不然新policy的输出对于奖励模型而言会导致其一定程度上的泛化困难进而效果变差),他们认为这是在RLHF过程中很重要的一点
Helpful v.s. Harmless
Anthropic在[2]中提到Helpful和Harmless的训练目标会有一定程度上的冲突,这一点也比较直观(例如对于那些有害的问题,我们希望模型生成更加Harmless的回复,则其相应的helpfulness就会降低);而llama2的作者们也专门调研了这一点:
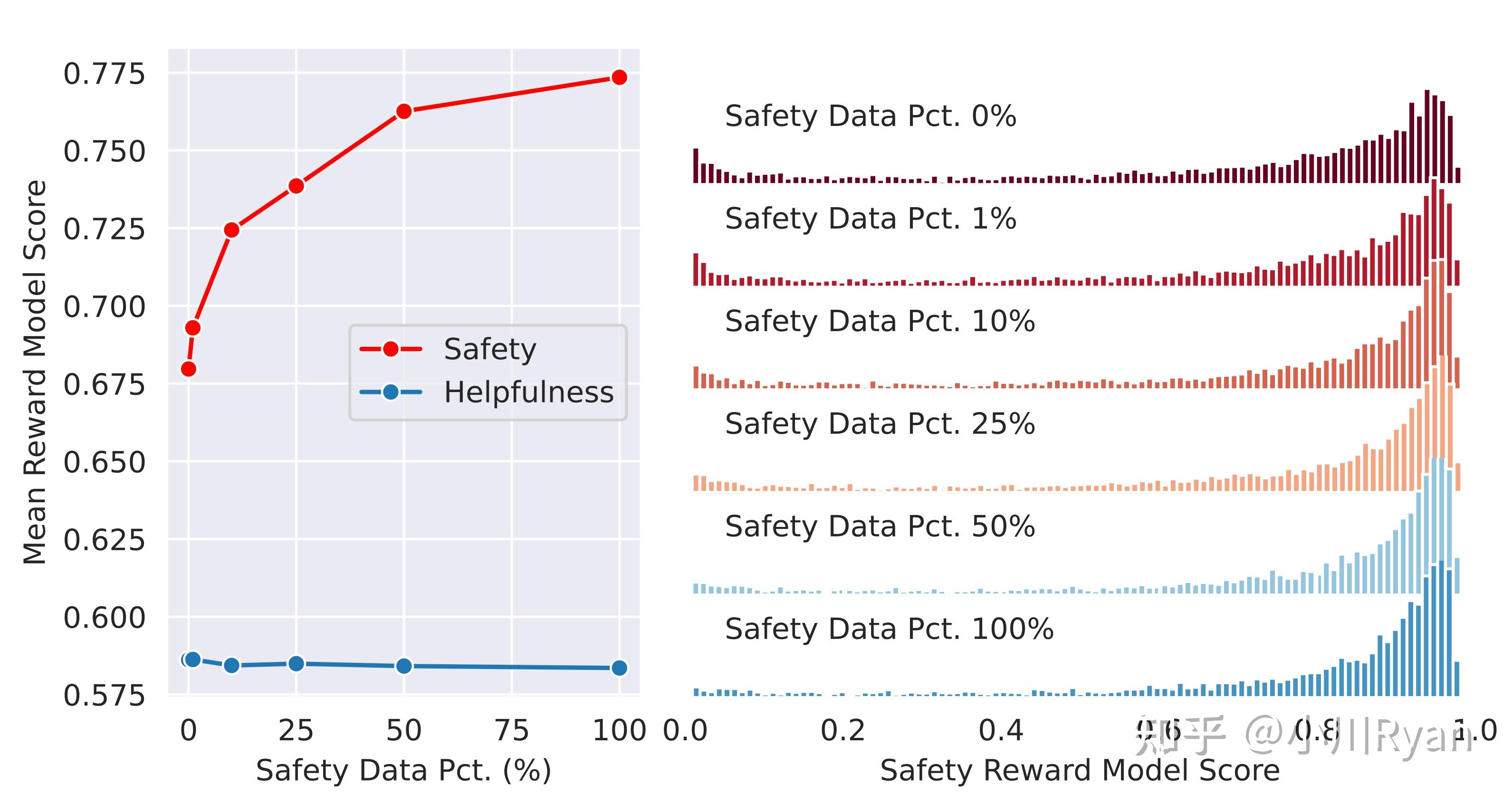
他们发现只要Helpful的训练数据足够多,在Helpful上的得分受影响就会很小,而模型的安全性会随着Safety的训练数据scale起来而越来越好
Given sufficient helpfulness training data, the addition of an additional stage of safety mitigation does not negatively impact model performance on helpfulness to any notable degradation.
同样也研究了Helpful和Safety数据的配比
In this ablation experiment, we keep the amount of helpfulness training data unchanged (∼0.9M samples) and gradually increase the amount of safety data used in model tuning, ranging from 0% to 100% (∼0.1M samples).
Context-distillation对于Safety也是有用的
所谓context distillation (for safety)是指采用一些Safe的prompt去提示LM,限制其生成response的搜索空间,得到的答案往往会更加安全;然后再拿这部分问题和response去微调模型(不带Safety prompt)。作者们利用训练好的reward model定量地分析了这一点,发现了context distillation对于harmless会带来明显的增益:
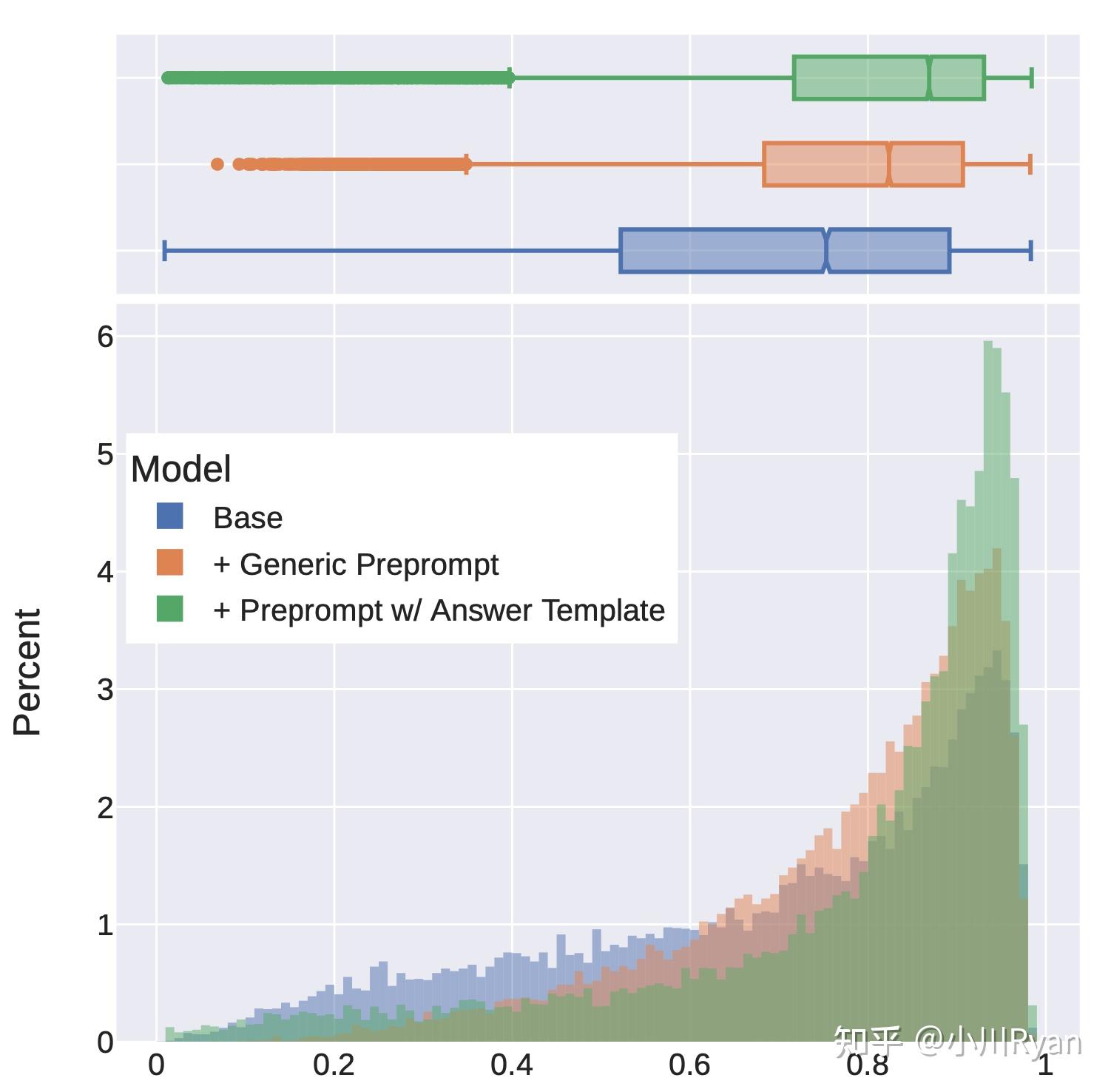
但他们还观察到了使用context distillation可能会导致模型对于一些问题的回复更加回避(evasive)了,即模型本来的输出就已经很安全也很engaged了,此时加入一段safe prompt反而降低了回复的质量
It is important to note that performing safety context distillation for helpful prompts can degrade model performance and lead to more false refusals
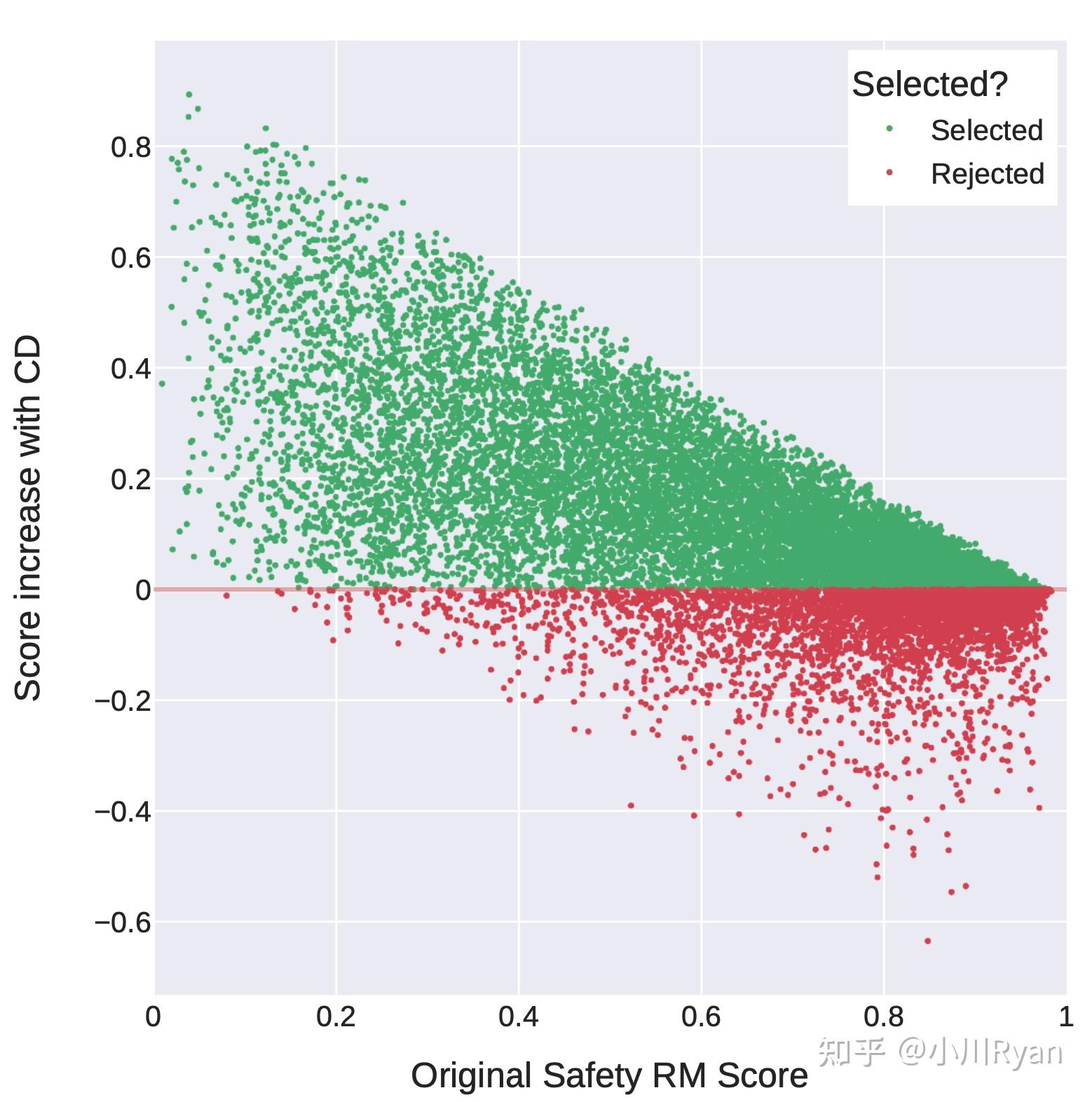
为了缓解这个问题,作者采用reward model来做一个决策:即只对哪些原本回复得没有那么安全的问题前面添加Safety prompt,这样可以很大程度上改善这一问题:
到底该不该用强化学习
论文中一个比较有趣的部分是,作者们经过llama2的训练后,对强化学习的使用产生了很大的改观;他们最开始觉得还是有监督的训练 监督信号会更加密集:
At the outset of the project, many among us expressed a preference for supervised annotation, attracted by its denser signal. Meanwhile reinforcement learning, known for its insta- bility, seemed a somewhat shadowy field for those in the NLP research community.
后来发现还是强化学习更适合用来scale oversight,因为SFT阶段很大程度上受限于标注者编写的response的质量,而人类判断两个答案哪个好要比他们自己编写一个很好的答案要容易得多,甚至模型回复的内容有时比人类写得要更好;作者认为RLHF训练的过程在于保证Preference model和policy更新的协同
However, reinforcement learning proved highly effective, particularly given its cost and time effectiveness. Our findings underscore that the crucial determinant of RLHF’s success lies in the synergy it fosters between humans and LLMs throughout the annotation process.
In addition, during annotation, the model has the potential to venture into writing trajectories that even the best annotators may not chart. Nonetheless, humans can still provide valuable feedback when comparing two answers, beyond their own writing competencies. Drawing a parallel, while we may not all be accomplished artists, our ability to appreciate and critique art remains intact. We posit that the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF, as documented in Gilardi et al. (2023) and Huang et al. (2023). Supervised data may no longer be the gold standard, and this evolving circumstance compels a re-evaluation of the concept of “supervision.”
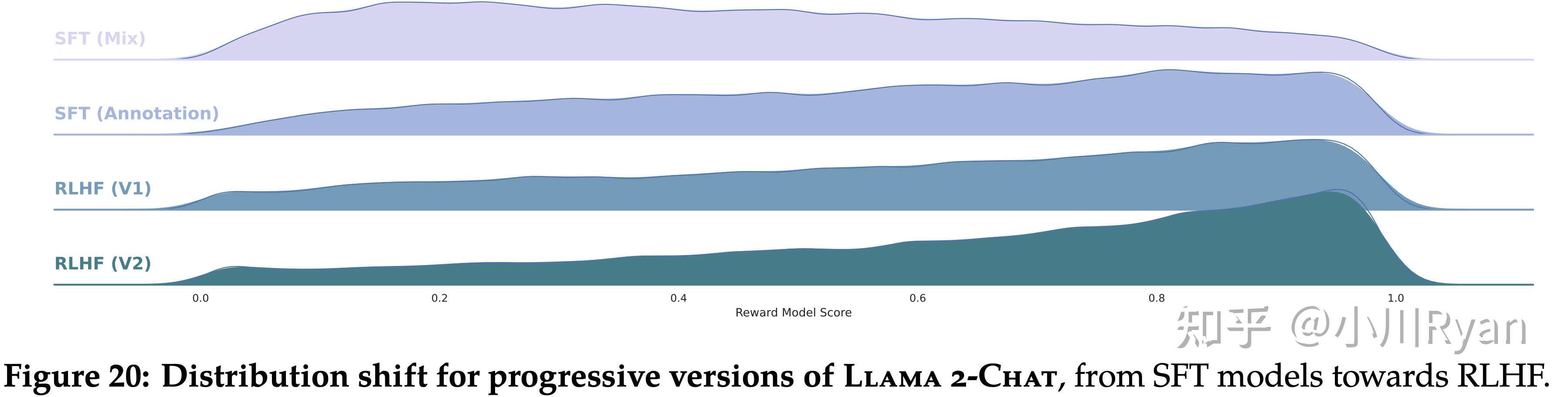
当然除了这些,文章还提供了很多关于Safety的评测、red-teaming的最佳实践等等,很惊喜作为一个开源模型会把这么多的精力放在harmless上。并且meta终于体面了一回,把所有模型都开源了(虽然有时候也会小小地期待它能不能彻底体面一次,把SFT和Preference data也彻底开源出来,meta你听得到吗)
另一个感受是还是公司更擅于集中力量干大事,可以把劲都使到一块儿去。至于大家比较关注的代码能力和中文能力,可能手速佬明天就甩出来一个代码性能double的版本,同时也已经有很多大佬在做中文适配了。
参考
- ^https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- ^(Bai et al., arxiv2022) Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback