
就昨天凌晨,微软和Meta宣布Llama2大模型开源且进一步放开商用,一下朋友圈刷屏。要知道,开源界最强大的模型就是过去Meta开源的Llama,而现在Llama2更强大,又开放商用,更有微软大模型霸主企业撑腰(微软既投资大模型界的IOS——ChatGPT,又联合发布大模型的Android——Llama2),开源大模型的确如当年的Android一样要流行起来了。
国产大模型“百花齐放”
反观国内,大模型也是最热的话题,前几天有人整理了一份现在国内发布大模型的企业和名称,笑称“中国古代的名词快不够用了”,我大概数了数大概114个大模型,但是其实这些只能叫做拥有自己业务适配的大模型企业,而不是真的中国有114个原创大模型。

大模型“百花齐放”的奥妙
中国有这么多的大模型的奥妙隐藏下面的这张图里:
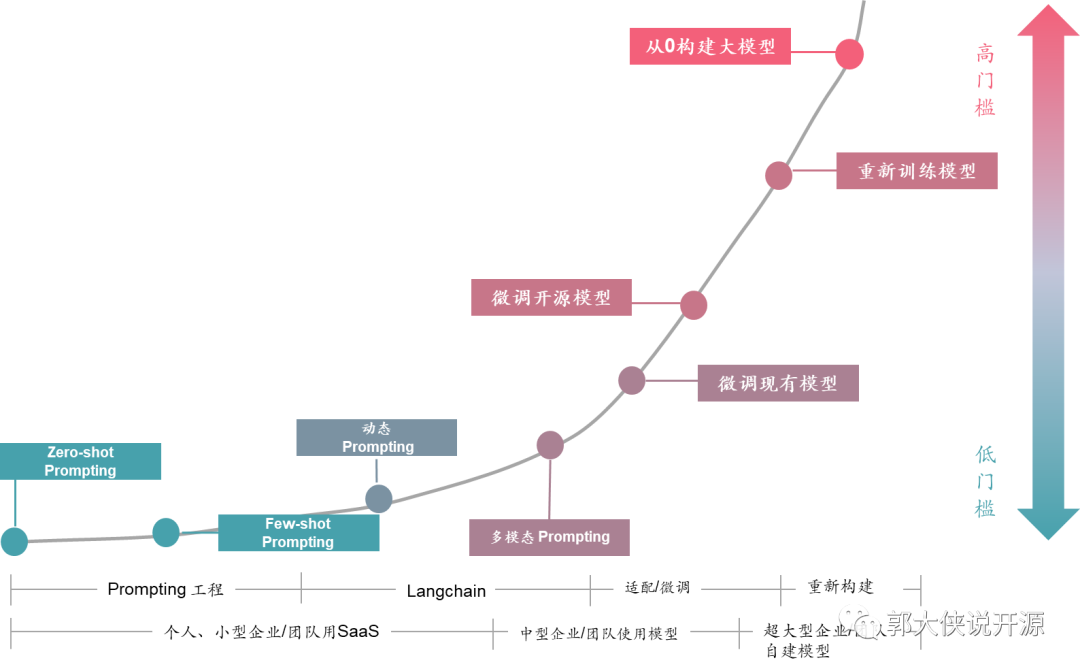
在这个图里你会发现,企业使用大模型其实有几种方法,常见的就是个人和小企业,直接使用线上ChatGPT、Claude、Bard或者类似的服务,至多可以用Prompt或者Langchain来Embedding一些预置场景和信息给线上大模型服务。但此时,你所有的数据都在公网上的,而且你也不是真正的让这个大模型适配你的业务知识库和业务逻辑,所以遇到复杂的处理场景或者使用企业内部数据的时候线上大模型服务就无法满足要求。
此时,基于开源大模型的FineTune(优化)出现了,也就是过去有不少企业在网上开放了自己训练的大模型(例如Llama),让大家基于这个模型可以再次优化训练自己的业务模型。这样训练的模型可以解决公网大模型的数据私密问题和深度理解自己业务场景的问题,一下子解决很多问题。不过受限于还有一定的技术门槛,所以,能使用和优化开源大模型的企业还不多。不过也有不少大型企业和实体做了开源大模型优化,并把这个模型再次开发出来,这就成为了国产大模型“百花齐放”的景象。
但是,其实真的从0开始构建大模型,难度是非常非常非常大的,看ChatGPT烧掉那么多钱让GPU训练,Llama2都需要微软这样的大佬背后支撑就知道,真的能做出来中国自主大模型的企业凤毛麟角。
开源大模型生态降低使用门槛,让大模型用户x100倍
但,这并不会影响大模型在中国的普及,为什么我说中国大模型数量会再增100倍呢?这是因为我看到越来越多的开源大模型的生态项目,开始降低企业使用开源大模型的门槛,这就像当年Android的流行一样,开始只有一些大玩家在玩,然后Android开源生态起来之后,所有的企业都会开发Android APP了。
目前看到100多个拥有大模型的企业还都是比较大的实体,很少有中小企业有自己的大模型的。这是因为优化训练大模型,现在还存在着不少门槛:
- 专业人才:需要大模型算法专家进行调优,不是每个企业都有这样的专家
- 数据供给:需要给大模型优化准备数据,而且在适当的时候“喂”给大模型
- 调优效率:调优本身是一个反复的调整测试的工作,没有合适的工具来做
而现在各种开源社区都在进一步降低这个门槛,将大模型变得“人人可用”,例如Apache DolphinScheduler社区发布的文章《用一杯星巴克的钱,训练自己私有化的ChatGPT》,就给出了让普通程序员甚至数据分析师快速用自己的数据优化大模型的方案。而Apache SeaTunnel也在准备做企业内部数据和大模型的打通之间的Langchain《图书搜索领域重大突破!用 Apache SeaTunnel、Milvus 和 OpenAI 提高书名相似度搜索精准度和效率》。这些都会让没有相关人员、处理复杂数据、不知道怎么调优的企业进一步拥有自己的大模型。我相信,未来大模型的门槛曲线是下图虚线这样的,未来每个会使用ChatGPT的企业和个人,都可以拥有自己私有化的大模型:
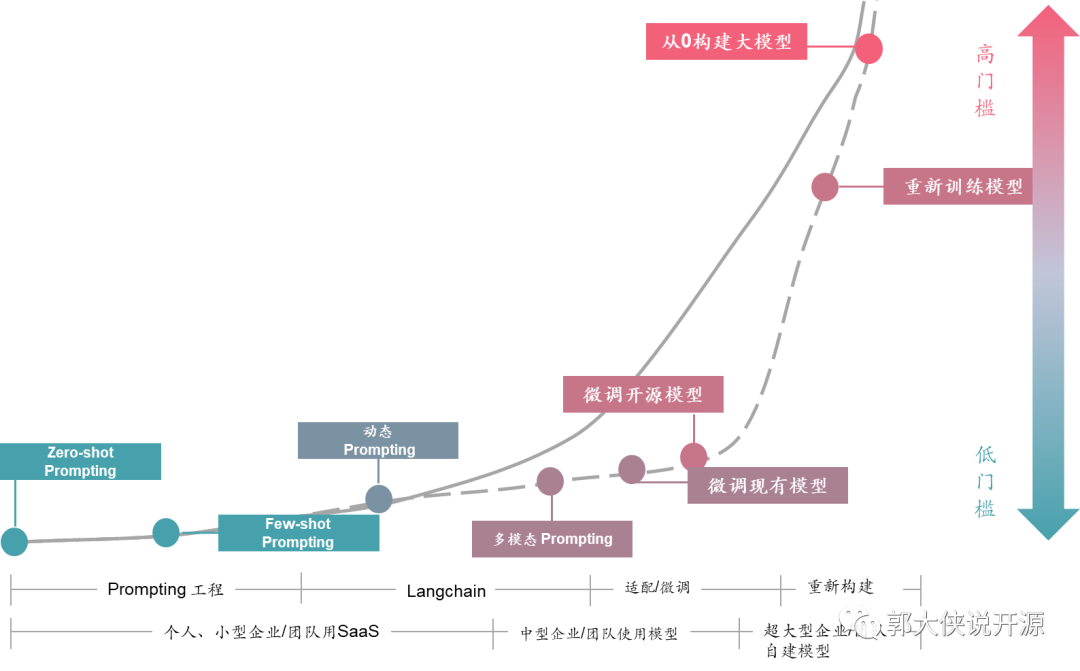
随着Llama2的发布和商用化的解禁,我相信中国的开源大模型会进一步丰富起来,而中国开源大模型生态也会和中国开源Android生态系统一样,有自己一套开源支撑的生态体系,在拥有这么多数据和人口的国家蓬勃发展起来。
我是热爱开源的郭大侠,欢迎点击关注了解全球开源最新动态。