
原文链接:
瞎BB两句
夜深人静,LLaMA2来了,你的老羊驼突然出现!
Meta真不愧是开源之光,可以说现在开源大模型的一大半边天都是LLaMA撑起来的,现在LLaMA2来了!
老规矩,先进waitlist再说!
哇,很快呀!
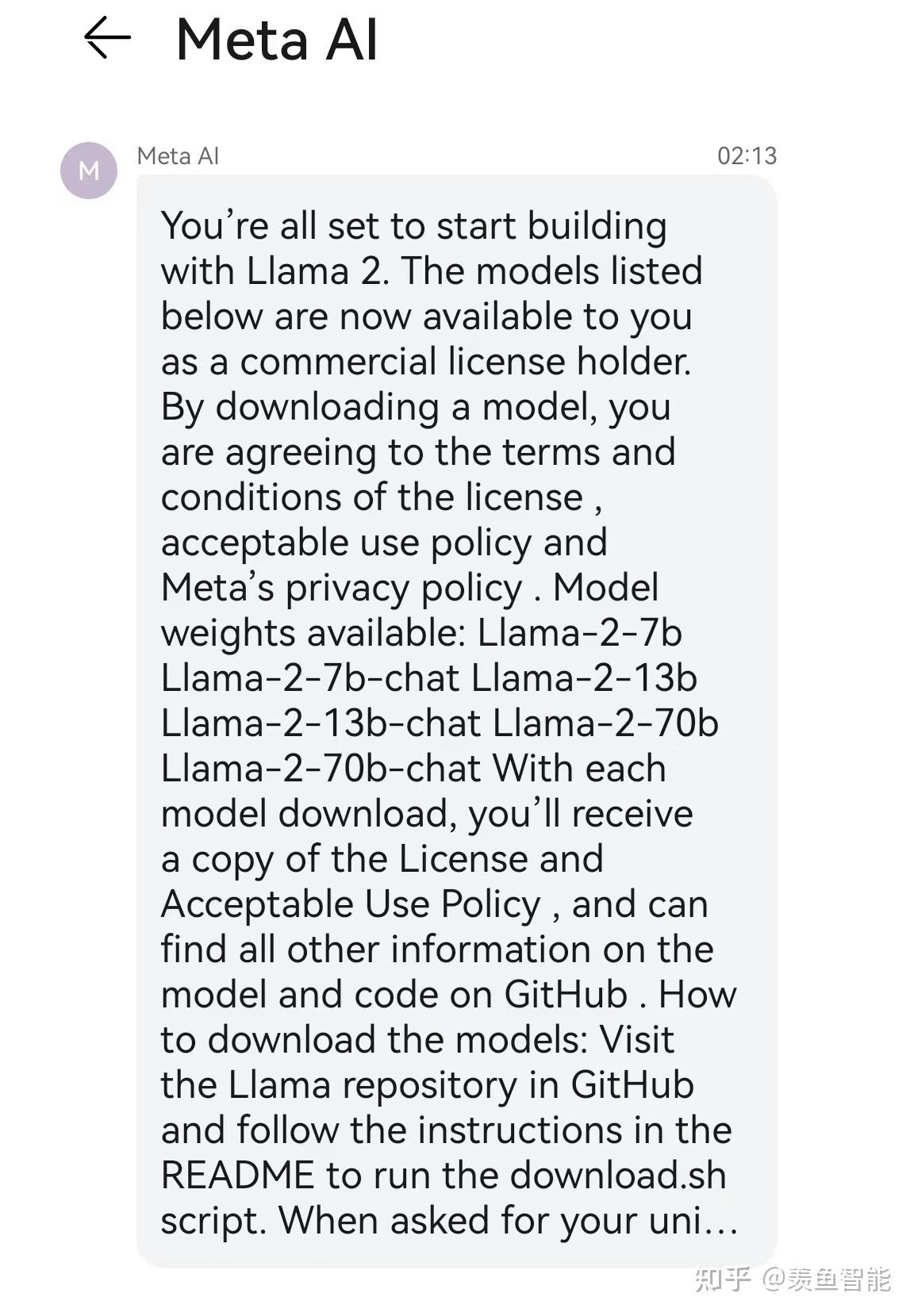
LLama2
先去官网喽一眼:

要点
- 今天,我们将介绍 Llama 2 的可用性,它是我们的下一代开源大型语言模型。
- Llama 2 可免费用于研究和商业用途。
- Microsoft 和 Meta 正在扩大他们的长期合作伙伴关系,其中 Microsoft 是 Llama 2 的首选合作伙伴。
- 我们在科技界、学术界和政策领域的众多公司和人士的支持下开放了 Llama 2,他们也相信当今人工智能技术的开放创新方法。
- 我们致力于负责任地构建,并提供资源来帮助那些使用 Llama 2 的人也这样做。
微软好像在搞事情啊:

模型速览
https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
主要进步
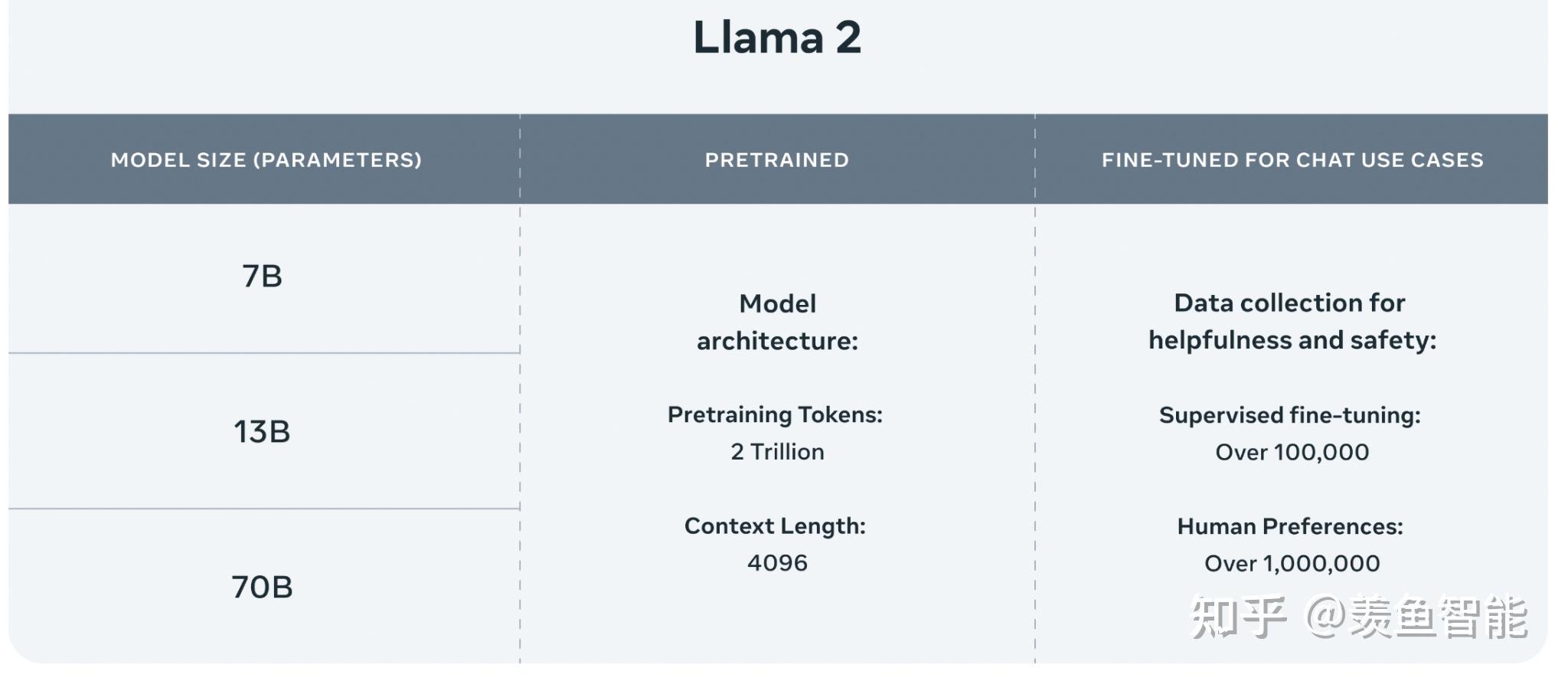
1.相比一代,llama2使用了多40%的训练数据,拥有双倍的上下文长度(4096)。
“Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.”

提供了三个size的版本:

2.微调了chat模型:
这次meta直接一步到位,基础模型+chat模型一起放出来了!!!
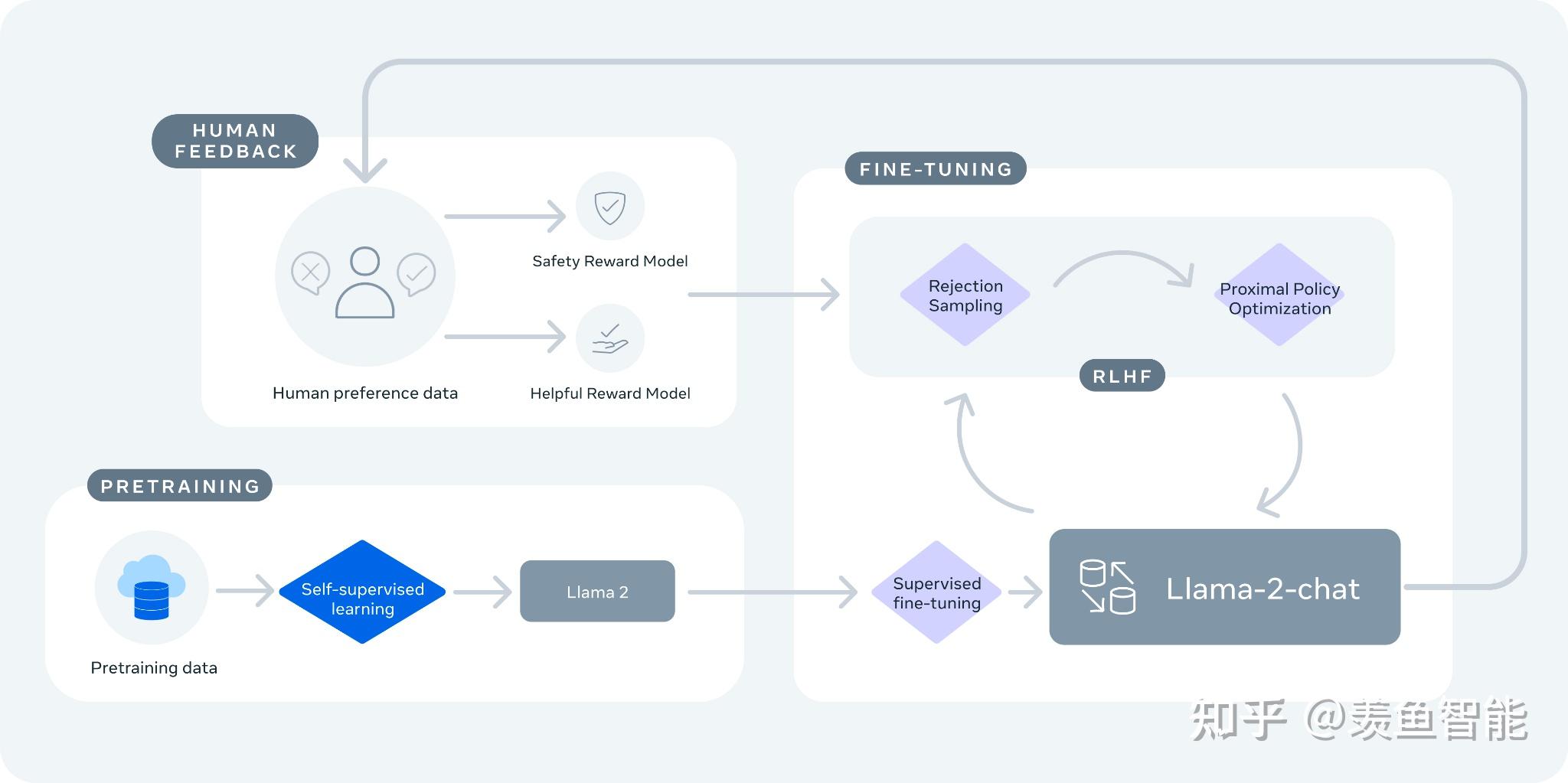
Llama-2-chat 使用来自人类反馈的强化学习来确保安全性和帮助性。
训练 Llama-2-chat: Llama 2 使用公开的在线数据进行预训练。然后通过使用监督微调创建 Llama-2-chat 的初始版本。接下来,Llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
注意这里可能和OpenAI的RLHF略有不同,比如RM不止一个。
效果展示:
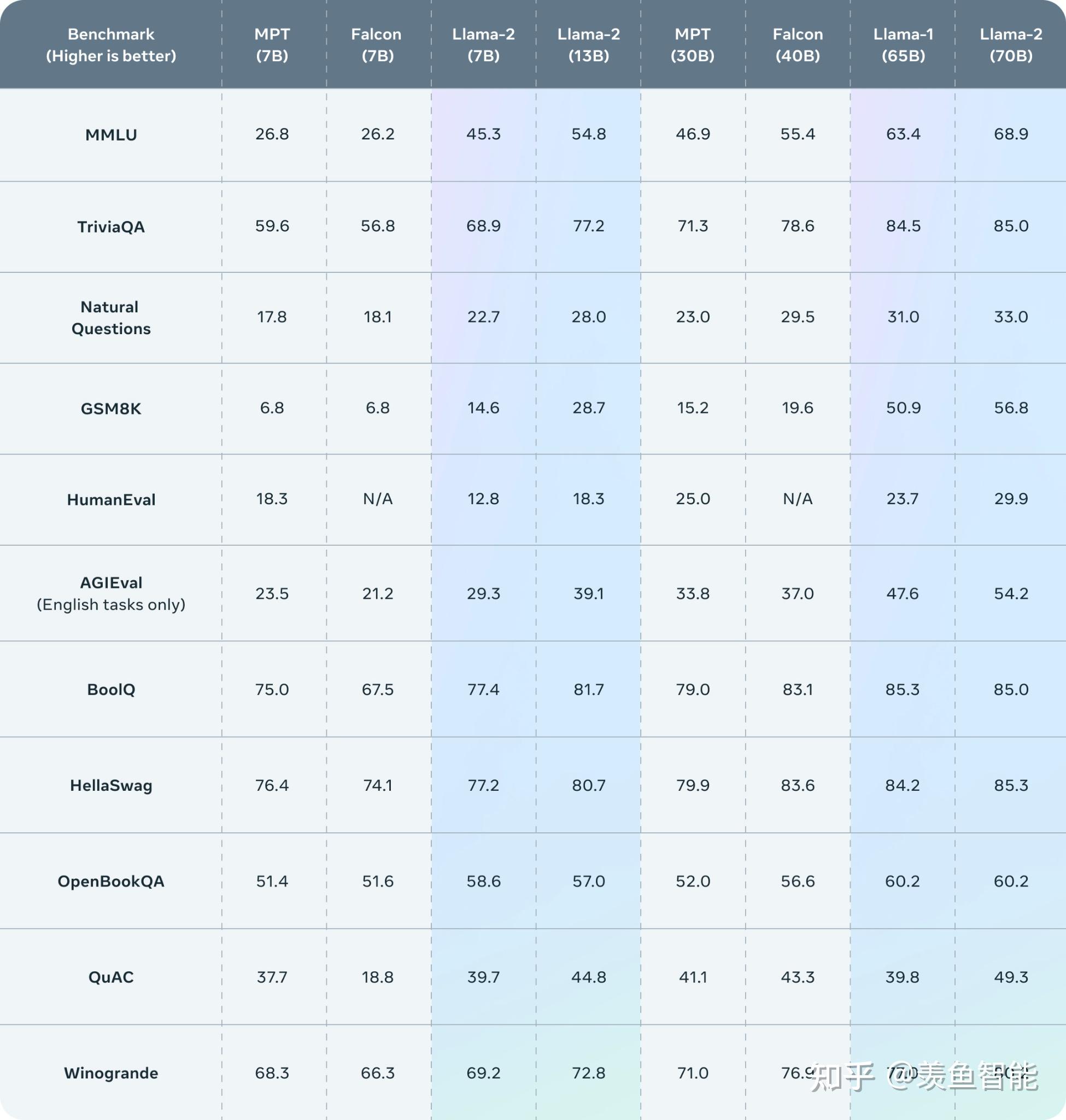
Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests.
开源模型大比拼:
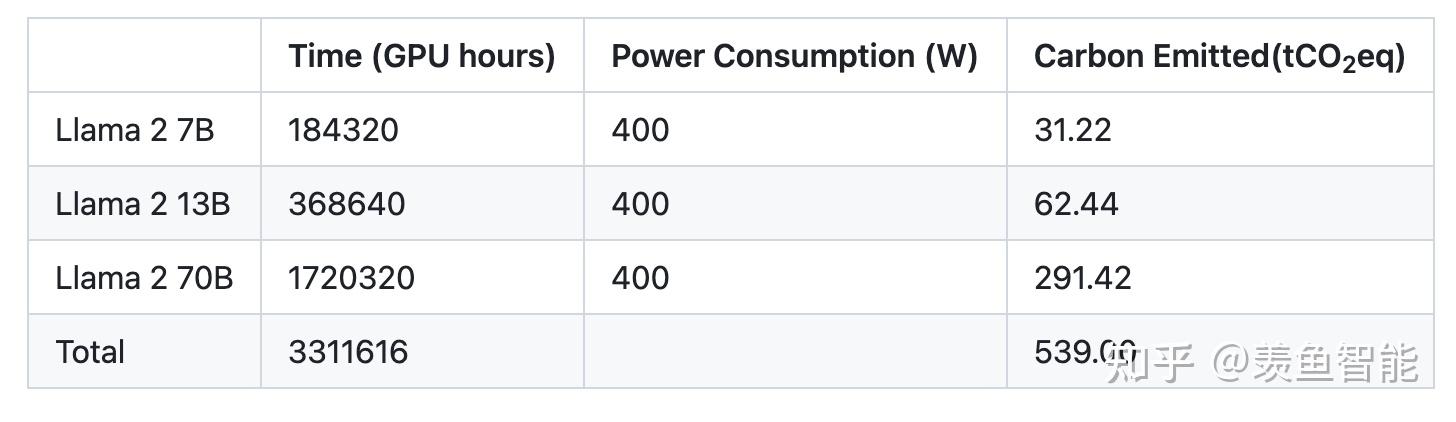
算力消耗:
读读论文

整体分为三块,预训练、微调和安全,Meta专门用了一章来讲安全。

先把肌肉再秀一秀
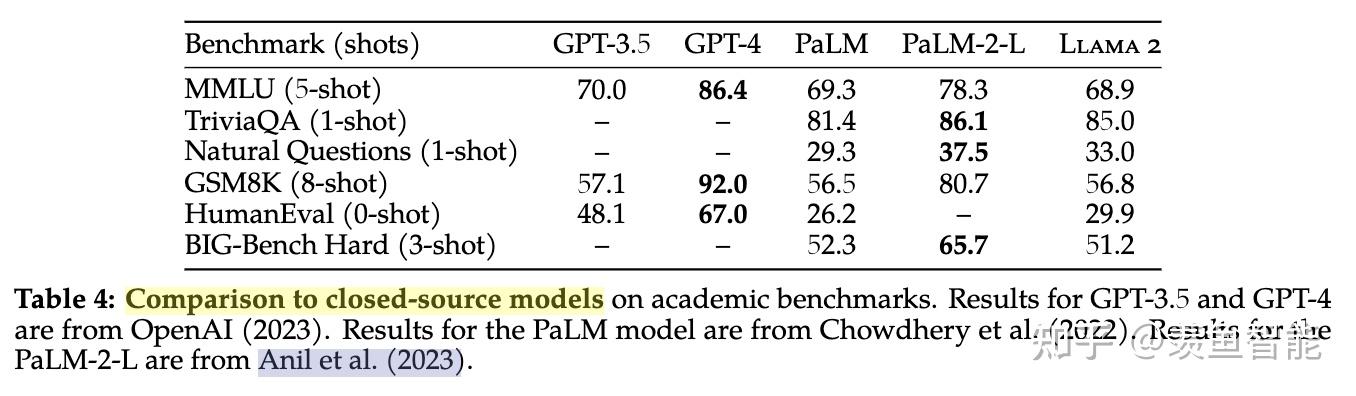
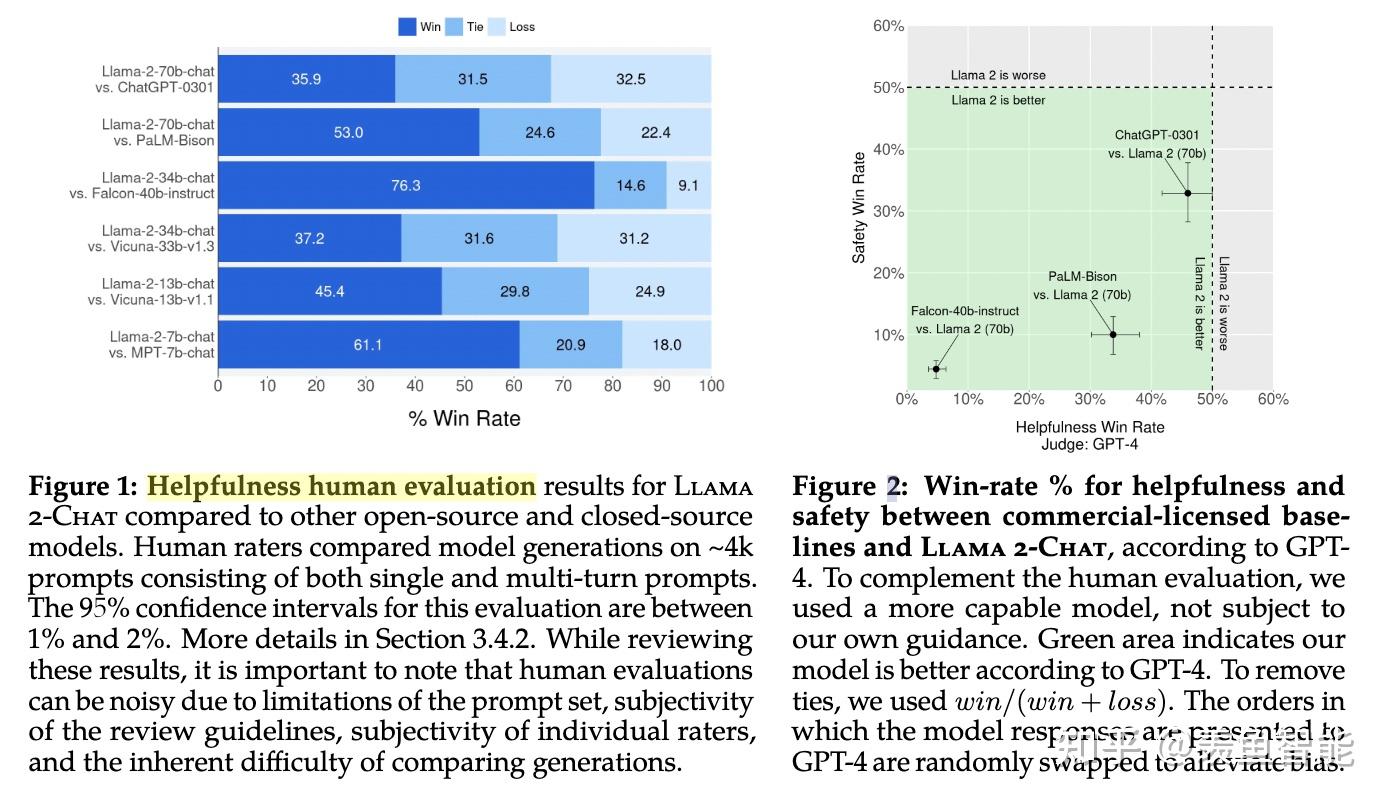
整体效果:开源之光!!!
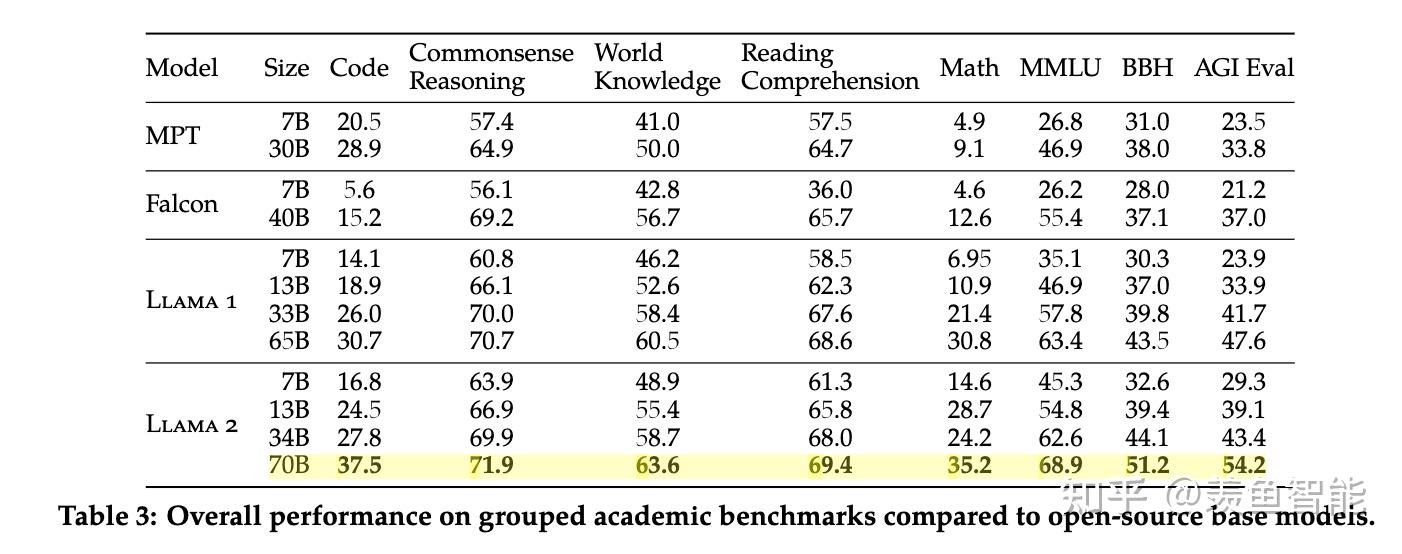
遇上闭源模型,依然很能打:相比GPT3.5不远矣,当然了,离GPT4差距还是不小。怎么说呢,可信!
预训练
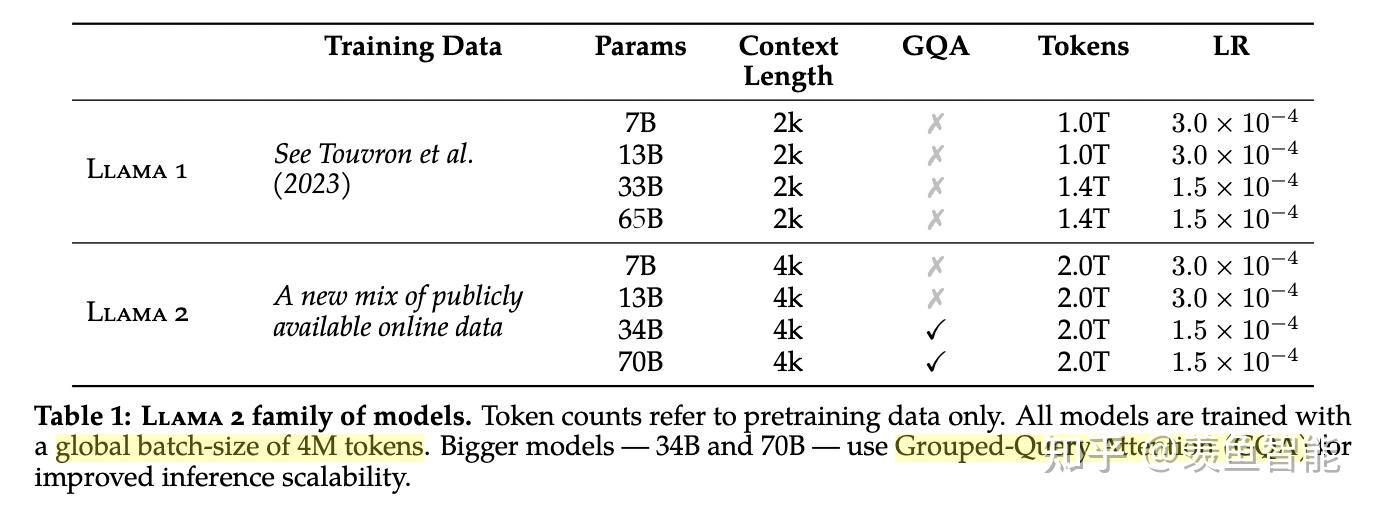
训练细节:

tokenizer:没变;

llama2使用了更多的数据;global batch-size of 4M tokens;使用GQA来提高推理的scalability.
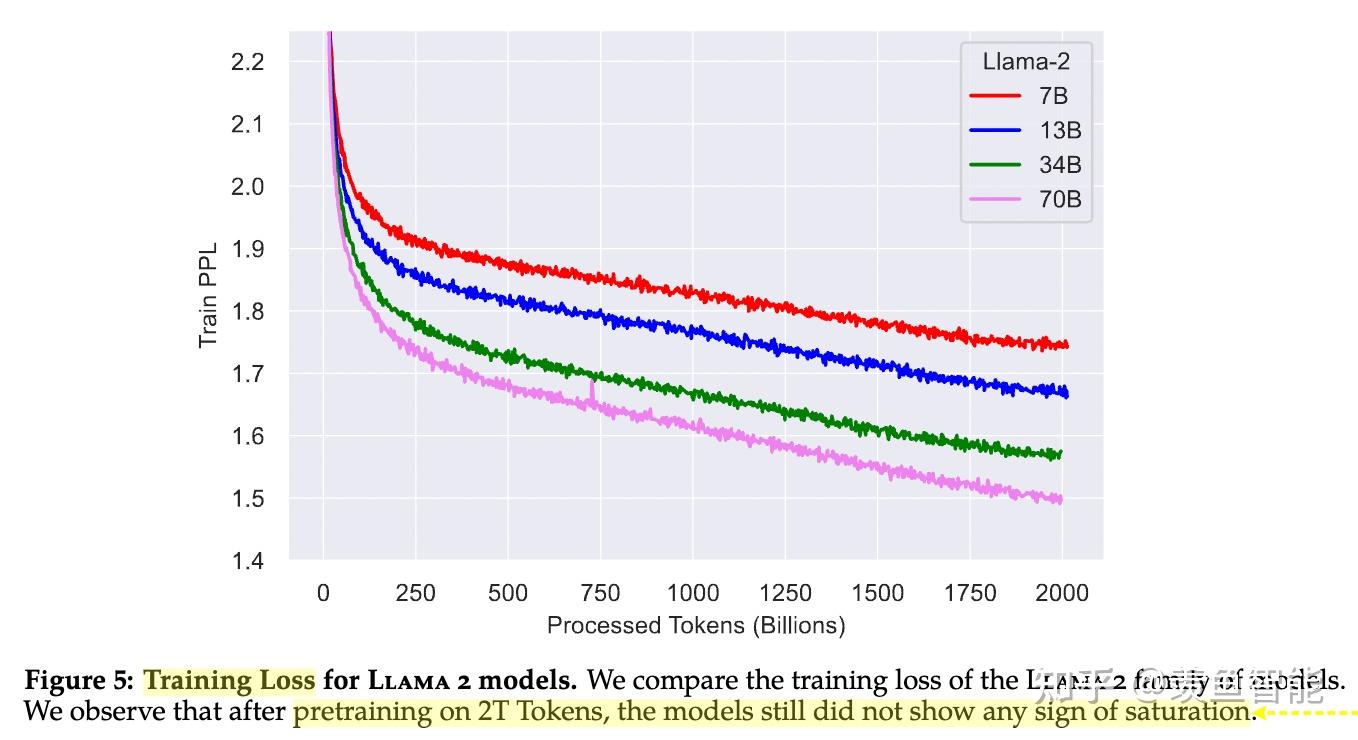
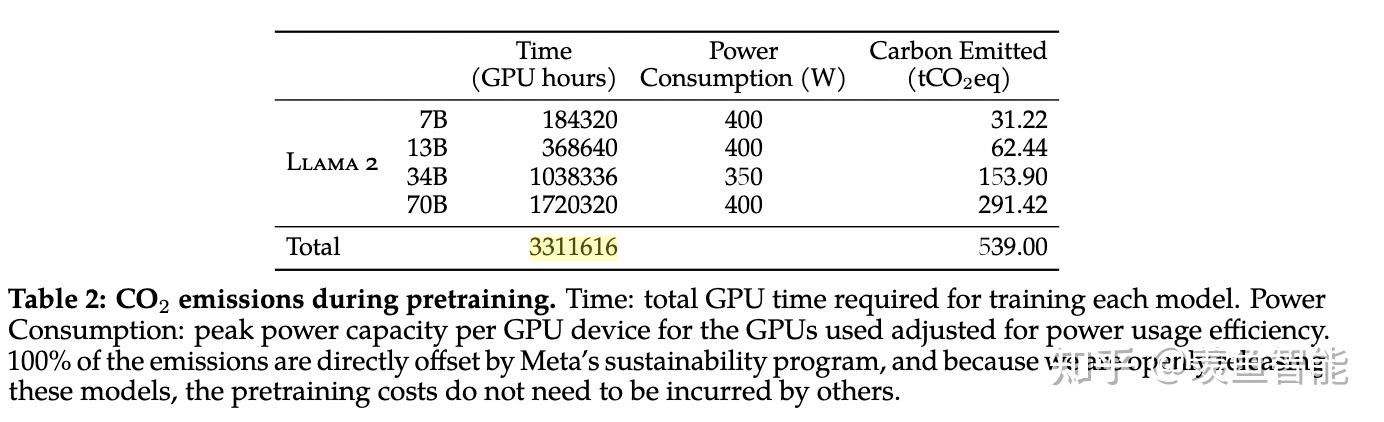
微调
SFT
SFT训练细节:

数据质量为王!


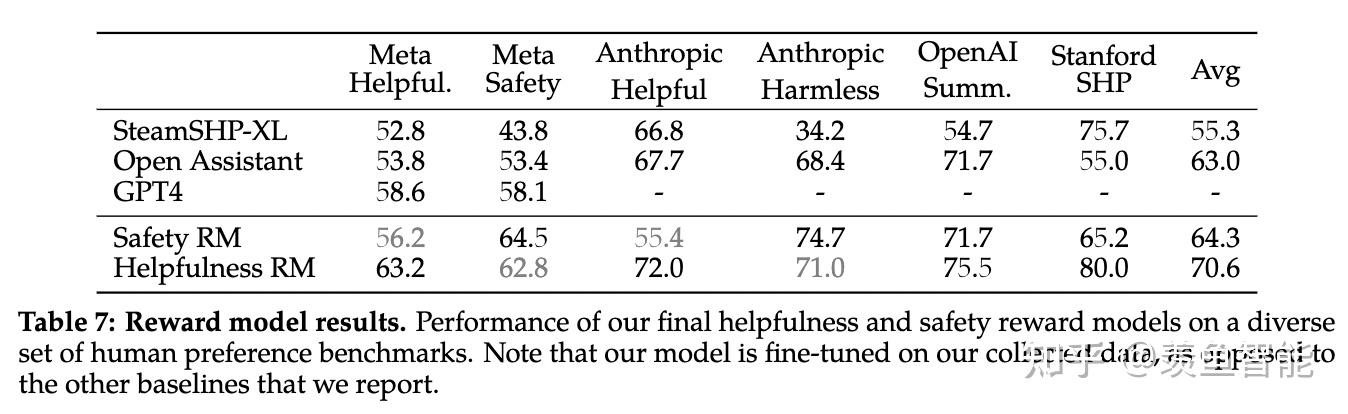
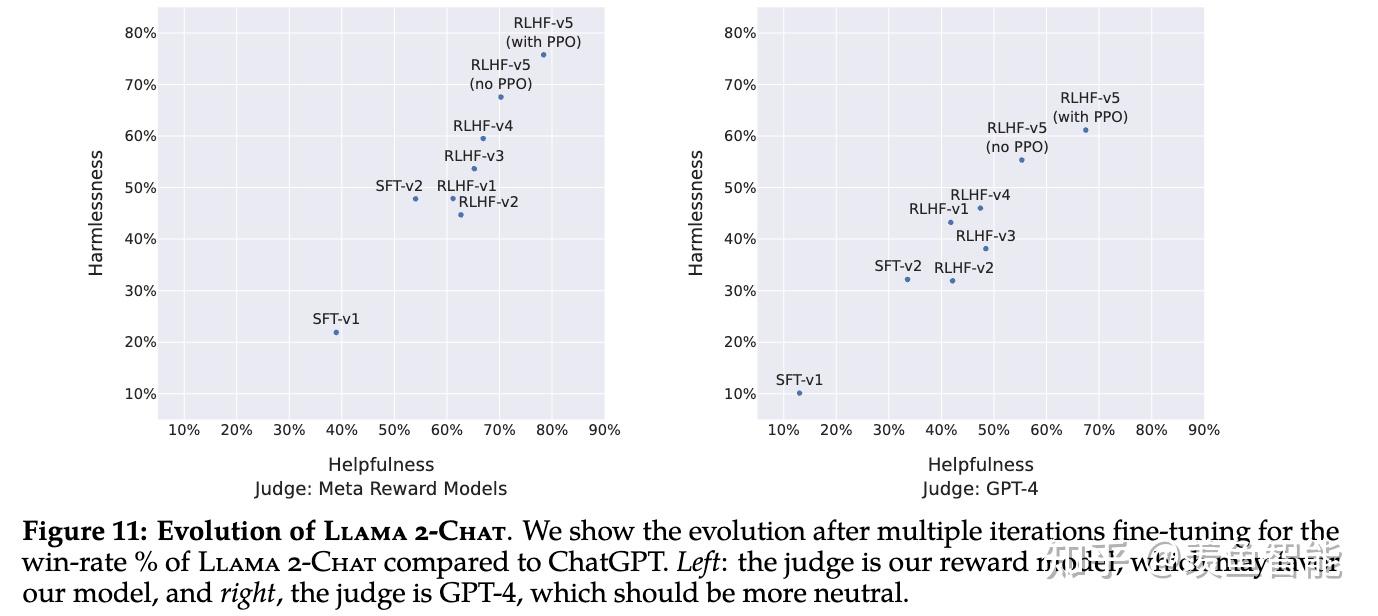
RLHF
这部分放出了很多的细节,挺有意思的,改天细看了再来更新。
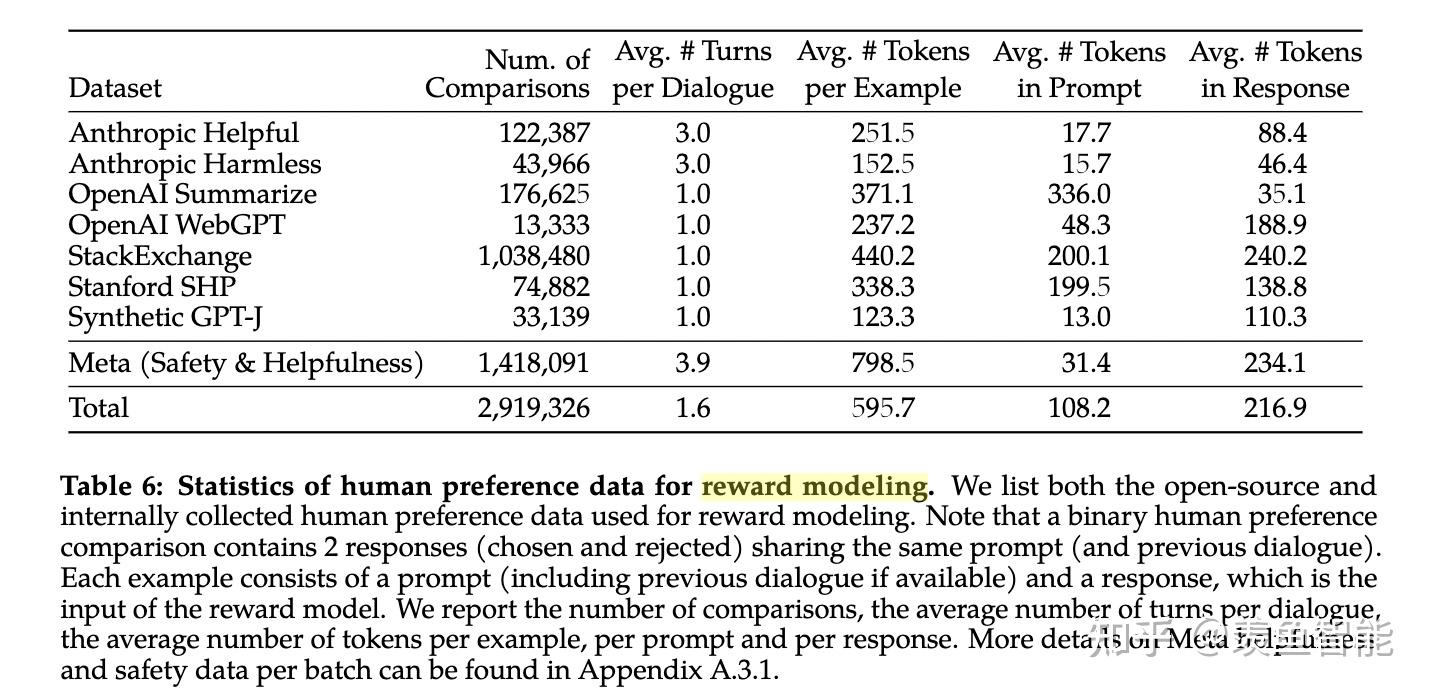
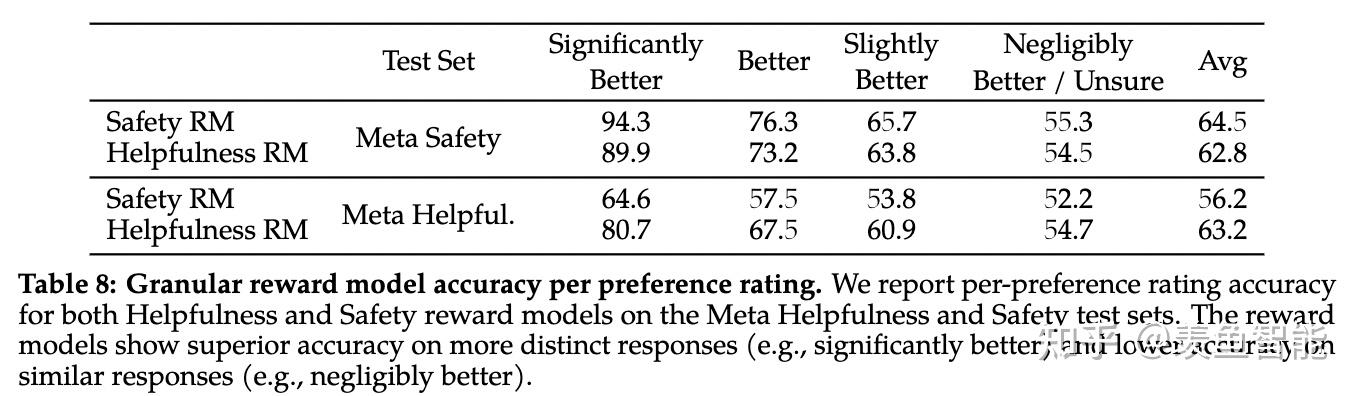
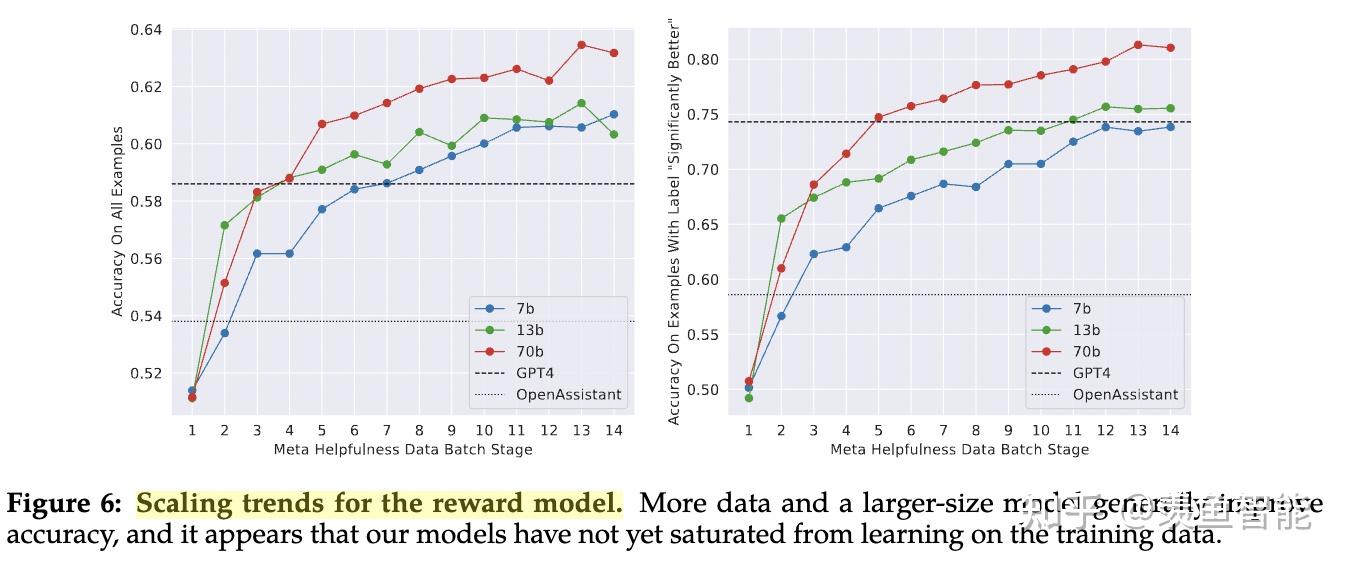
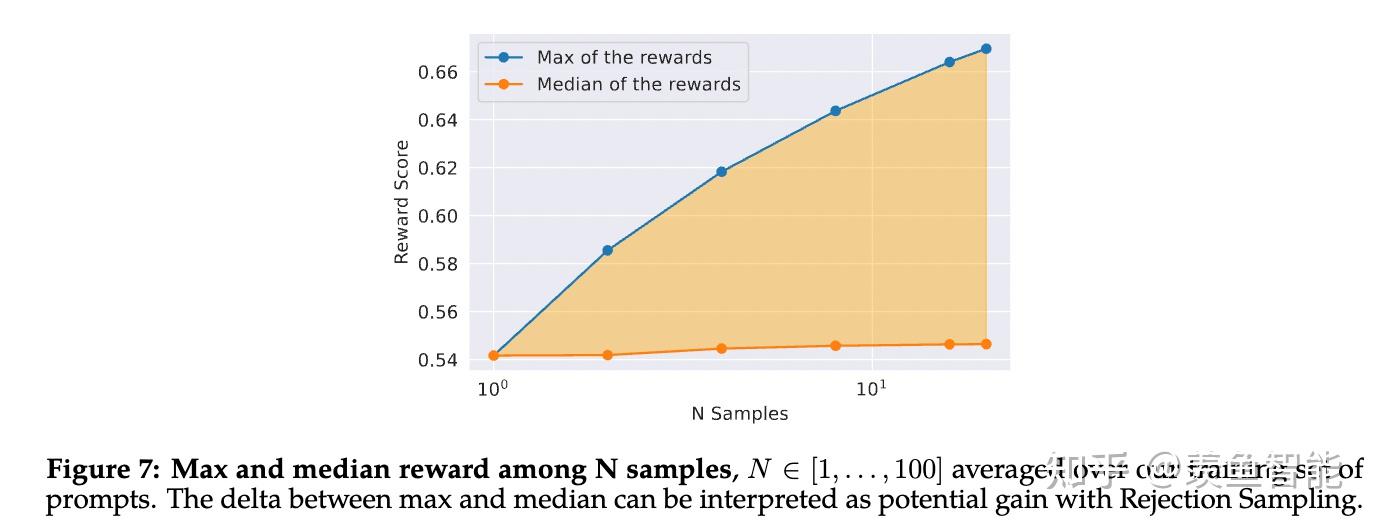

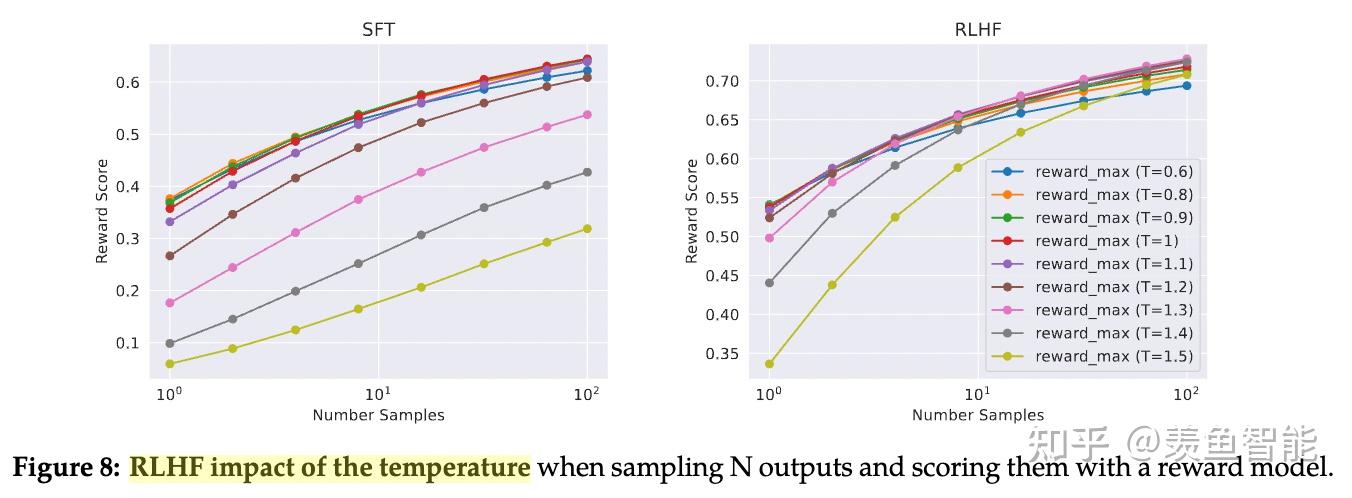
System Message for Multi-Turn Consistency
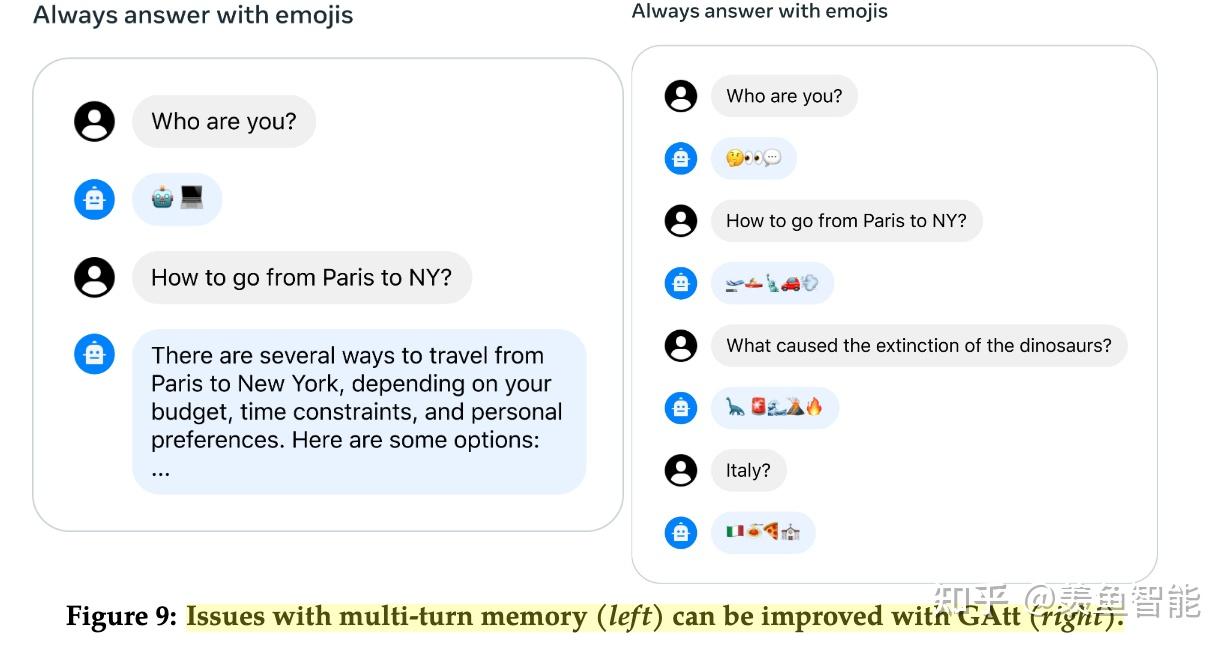
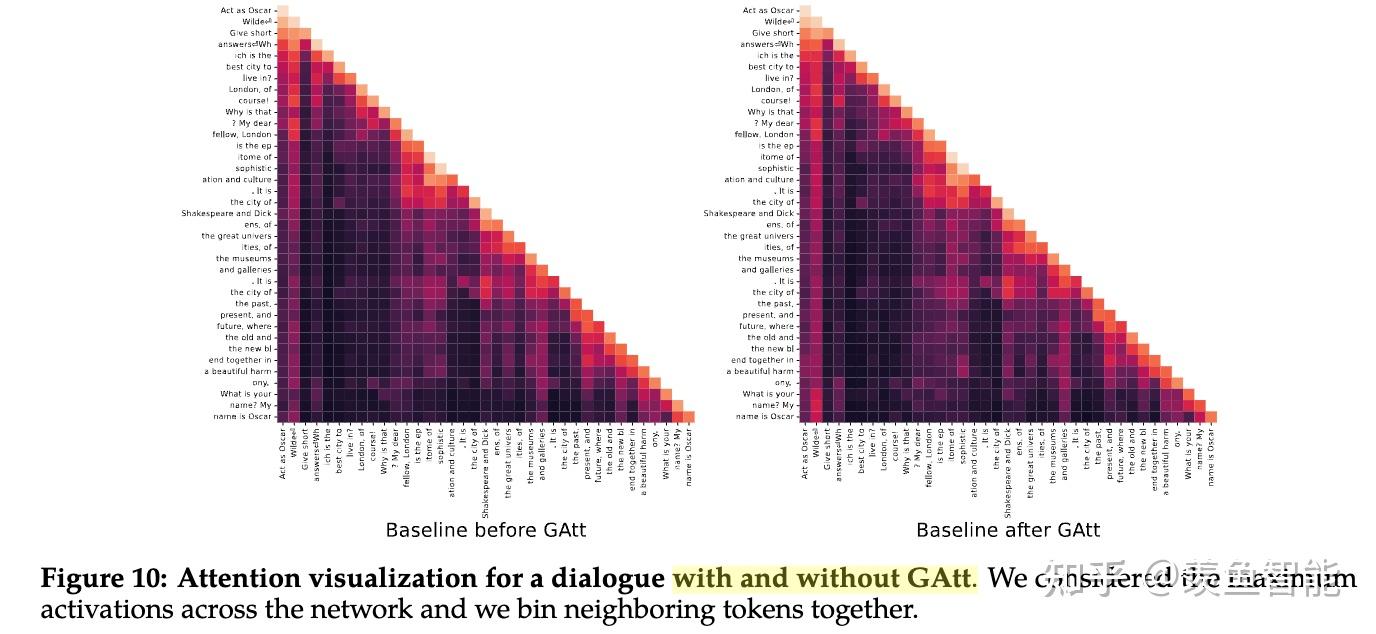
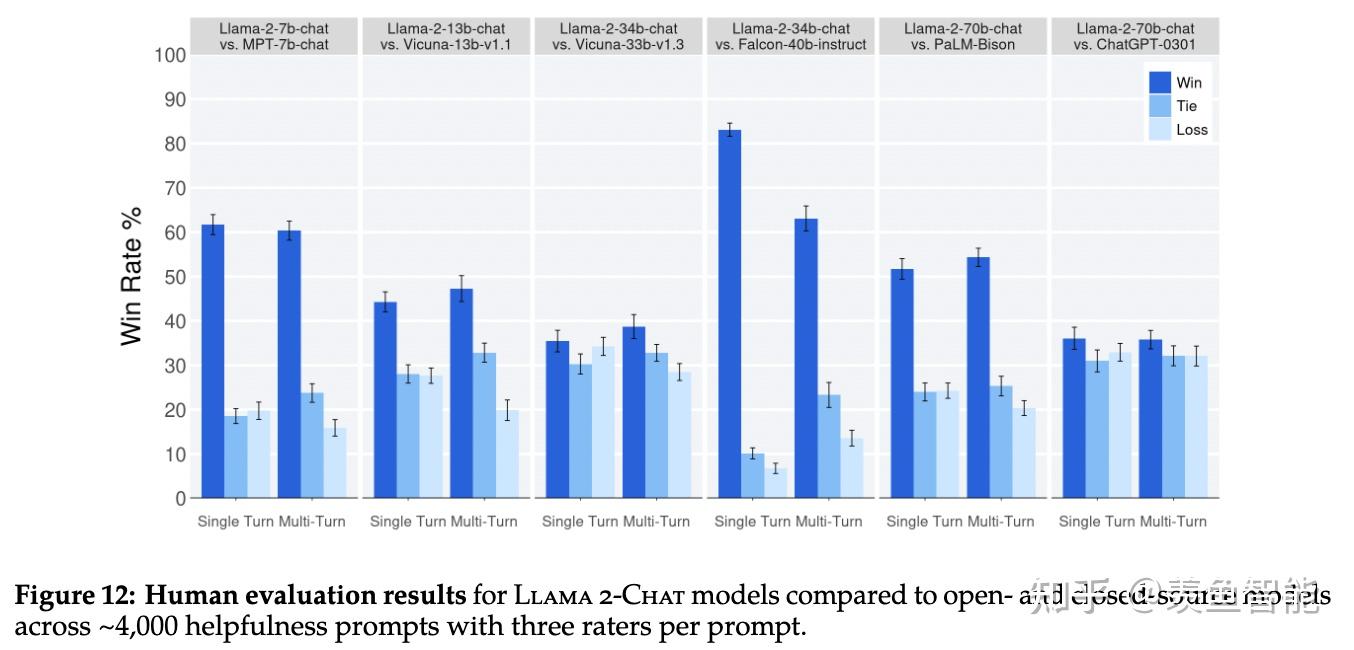
RLHF Results
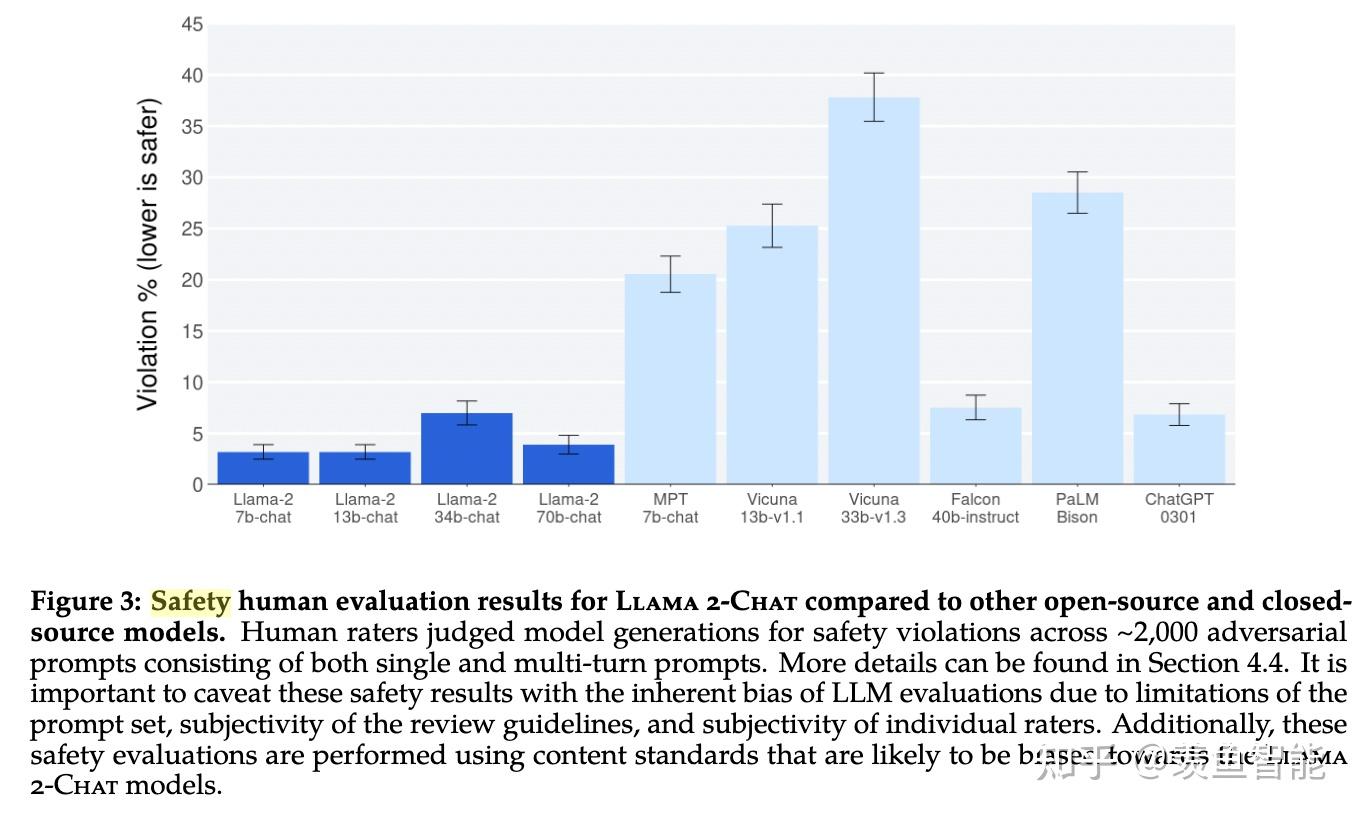
安全性
这个部分有空再看,对于有影响力的大模型及其产品来说非常非常重要!!!
参考资料
https://about.fb.com/news/2023/07/llama-2/
https://ai.meta.com/resources/models-and-libraries/llama/
https://github.com/facebookresearch/llama/tree/main
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://ai.meta.com/llama/open-innovation-ai-research-community/