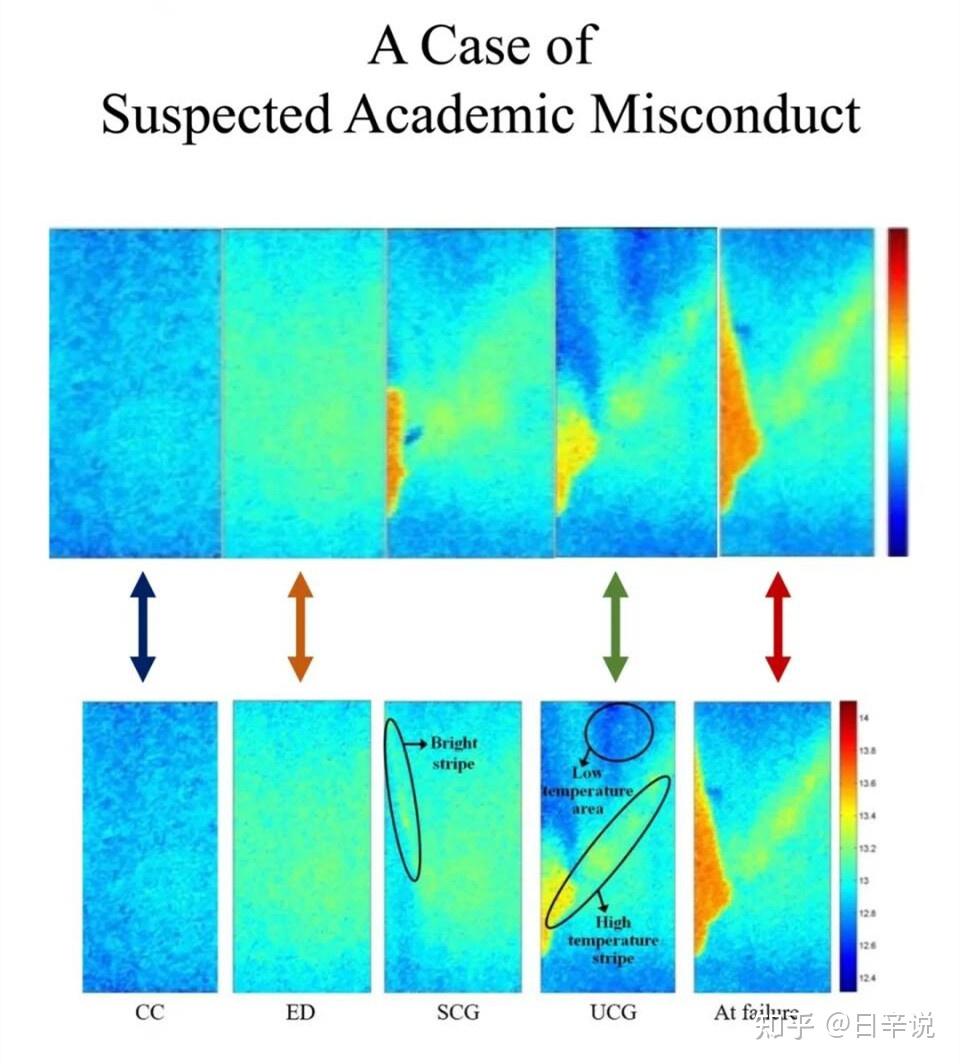
如何看待不开源代码的论文?

- 779 个点赞 👍
查看全文>>
匿名用户 - 607 个点赞 👍
查看全文>>
匿名用户 - 134 个点赞 👍
国内高校署名 + 不开源代码 + 一堆故弄玄虚的公式与模块 ====> 一律按造假看待
论文作者当然可以选择不开源,但是读者也有理由不相信、不引用该成果。
编辑于 2023-03-06 08:56・IP 属地北京查看全文>>
匿名用户 - 95 个点赞 👍
我们这边投论文(非AI方向),基本是审稿期间会放一个二进制文件(或者docker image)给大家试用,同时不涉嫌保密的数据也会放出来。源码会在论文接受之后整理公布。主要有几个原因吧
- 自己代码写的太难看了。我自己跑个实验可能一次要跑五六个脚本(而且可能是不同语言写的)才能出结果。这种直接开源出来可能会被认为故意刁难审稿人/不想让审稿人轻松验证。所以一般直接放个docker image,你也别管我里面咋跑的,结果能输出,还行,就完事了。
- 二进制可以加壳。。。防止论文没中的情况下idea被窃取
- 等论文中了,有充足的时间整理代码了,就算从notification到camera ready少说也有小半个月。而论文投出去(毕竟投稿前两天可能还在改代码)到公布数据啥的,可能只有两三天。
发布于 2023-03-06 14:33・IP 属地新加坡查看全文>>
匿名用户 - 88 个点赞 👍
列举一些假开源:
计算机视觉
[1] Xiangtai Li, Hao He, Yibo Yang, Henghui Ding, Kuiyuan Yang, Guangliang Cheng, Yunhai Tong, and Dacheng Tao. "Improving video instance segmentation via temporal pyramid routing." IEEE Transactions on Pattern Analysis and Machine Intelligence (2022).
https://github.com/lxtGH/TemporalPyramidRouting
Where are your codes?


[2] Cheng Chi, Shifeng Zhang, Junliang Xing, Zhen Lei, Stan Z. Li, and Xudong Zou. "Relational learning for joint head and human detection." In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, pp. 10647-10654. 2020.
https://github.com/ChiCheng123/JointDet


该工作已开源了!


医学图像计算
[1] Zhijie Zhang, Huazhu Fu, Hang Dai, Jianbing Shen, Yanwei Pang, and Ling Shao. "ET-Net: A generic edge-attention guidance network for medical image segmentation." In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part I 22, pp. 442-450. Springer International Publishing, 2019.
https://github.com/ZzzJzzZ/ETNet

 编辑于 2023-06-25 23:34・IP 属地中国香港
编辑于 2023-06-25 23:34・IP 属地中国香港查看全文>>
匿名用户 - 86 个点赞 👍
回答这个问题的时候,我有点怕了,都是匿名大佬,难不成......?细思极恐,我导不会发现我吧!其实对于不开源代码的论文,其实很容易看出他是不是”编“的。
01. 如果这篇论文是SCI一区二区(虽然二区也有水刊......)
偏重于”数理算法的推导与创新,纯研究”底层数学公式“的,不是简单的改进“,那么它大概率不是编的。
按照正常人的想法,你既然敢编数据,是因为你做不出来,或者没有那么强的专业知识底蕴,难道你还敢直接编理论吗?不怕专家看不懂,推导不出来?你的结果准备编什么样的?编的过于精准,超过国内外一线学术水准,你怕不怕?
恭喜我学院又出一名”年轻准院士!“,重大学术发现!
海对面某研究所知名学者:Oh,shit ! I can't even understand the first letter of this mathematical formula ! Fuck !(国外专家其实还是很有素质的,比较严谨、风趣、绅士)
很多人喜欢反推论文,比如这个课题,我找了很多篇paper,一个个看,一个个对比精度,看人家都是什么区间,用了什么方法,然后先把结果给你算出来,合理即可,从后往前反推,抄理论+模仿画图,图画的还挺精美你别说,这种有“高手”存在,而且即使专家亲自“掌眼”,也不一定都能看出来。那你说这个是真的还是假的,界定问题罢了,人家没做,但合理,就很抽象。
所以即便他不开源代码,也情有可原,这算是个人”绝活“,轻易不会让别人学去。但SCI在开源社区比例中,占比是最大的,经得起推敲,积累学术声望的大佬,往往会”不吝赐教“。不开源的不代表就是编的,自行分辨。


02.如果论文水准在三区四区这种,则需要看他做的是什么
如果这个方法很普通,但结果异常精准,两种情况,一个就是”编的,也就是修改过精度的“,另一个就是”他把实验算的最好的结果放里面了”,不足以完全代表这个方法的“有效性”,也很正常,毕竟学术二十年怪现象。
其实很多三区四区的论文,从等级上来看,没有一区二区高,但并不代表质量比他们差,很可能由于这些期刊每年发文量很少很少,审稿也很慢,一拖就是一年半载,国内很多学者由于“时间原因、评职称、加分、毕业等等”,拖不起,也就不投这个,所以因子一直没上去。
这种情况他不开源代码,一是本身“就怕你看”,结果经不起检验,而且也没非要规定“开源”,所以就钻了空子。
另一种情况就是“这篇文章是他耗费很多心血做的”,不舍得开源,很可能接下来的论文还得靠这套程序+算法,甚至连本实验室的师弟师妹都不给看,看完我还活不活了?也正常,毕竟是个人的知识劳动成果。
最后一种情况是,论文程序开源了,你可能没找到,因为他没写在文章里。最后一种情况就很慷慨了,让更多科研工作者有了参照与学习依据,行业内整体学术水平,都会潜移默化提高。过段时间,基于这种算法的中英文paper,就开始多了起来......
我见过开源没多久,论文直接写出来的,而且还见刊了!看来有时候做学术也得玩个“信息差”,受教了。


通篇“脏话”的论文 

网上谣传,编辑居然收版面费了...... 

经查找,这篇论文最后没成功见刊......还是很有意思的 03.中文期刊里,E I 这种的,很多时候没有“人脉”你发不上去
第一作者是谁?是“大牛”吗?还是“大角牛”?如果是后者,你做的再天花乱坠,该回哪去还得回哪去。如果是前者,那么录用几率就会大大增加,二作是大牛也有效,毕竟编辑和各院校知名学者都有“潜在”交情,这个不详谈。
所以有时候你的paper层次,能达到 E I,那么不如搞个SCI,改一改润色润色,加分还高,审核还快,也没那么多人情世故,一切全靠“运气点”,梭哈,干就完了!
这种 E I 如果是大牛写的,他基本不会太“胡编”,但会把精度最好的一组数据放上面,告诉众人,我这个算法就是好,结果提升就是这么强!如果有人反驳(基本没人反驳),那也有理由,不行你来算?是不是编的?
读研期间,我给一个课题组发过邮件,当时就着重问了一下“精度怎么这么高,是不是修改某某参数的原因?“对方回答的是组里一个学生,大概意识是,挑的最好的数据算的,没办法......你看这......
对于核心及以下的论文,这个编造程度就会大大提高了,因为核心是大多数研究生的首选,有时候都不用你算,只要论文有创新点,前面部分论述充分、干练,中间图片配色高级一点,结果展示详细一点,精度满足要求,选题高端一点,那基本就录用了。


结果随便编,”合理“即可,这里指的是”合理“(细品),因为专家一是看不出来,或者即使看出来了,也不会说你是编的,因为你导师也在二作、三作趴着,都给点面子,否则不成了”大型学术界撕B现场了“?
专家会比较隐含的说,结果欠妥;或者算法叙述不够详实,补充相关部分(让你圆一圆);或者图表格式问题(让你改一改);或者精度太高,不足以代表所有”样本性“(意思是让你调低点,你的数据精度太高了)
所以核心期刊基本也不会开源代码,一是编造太多,经不起推敲。二是没必要,给你看他也没任何改变,也不需要积累”学术界口碑“,SO。
虽然核心有很多结果是修改or编造的,但不乏很多优质论文的存在,这里不能以偏概全,核心还是值得大家日常刷一刷的,质量在国内也算T1级,便于增加灵感,有助于”提升复现水准“。
04.还有很多情况,比如期刊水准不高,但是某大牛比较青睐,或者一起举办的
所以这些大牛会把文章发在这里,一些人看了会认为:他怎么才发这种水平的?在这水论文吗?实则不然,人家其实只是想支持支持,或者应期刊邀请而已。
这种情况,大牛一般不会把绝活拿出来,可能发发综述,或者挂个二作,让课题组人来撰写,也是偏重于科普理论类,这种也不需要开源代码,也没代码可开源。
05.代码不开源,那么你的”学术平台“就很重要了!
研一阶段其实我就开始“刻意”复现他人的论文成果,以当时的水平,其实只能做到不足20%(仅限于自身专业领域),首先我会看他用了什么方法,用了什么工具,我就跟着模仿,前期偏重于复现“数据分析”类,这种论文本身层次不是很高,但数据量极大,并且对于算法的改进不是很“变态”,所以可实操性很强。
所以话又说回来,为什么其他论文复现不出来呢?对于理论的学习其实并不难,勤劳一点就OK了,对于数理公式的推导,只要每天写个小本上,揣兜里,天天看天天算,我不信一周之内算不出来。
问题在于“算法的实现过程”,也就是程序,我搞不出来,论文后面没有开源代码,论文里写的也是“只言片语”。很多重要的参数细节,他不会都给你写在上面,如果都写出来了,让你学去,他还研不研究了。


所以读研读博有能力的话,一定要去一所好学校,最起码设施齐全,师资力量够强,课题组有你感兴趣、能做、能支撑你做的东西,有一定资源支持,你的学术生涯会更加顺利。
人有时候就是“顺势而为”,你再努力,可是没有相关资源,研究了几个月半年,回头想想还是原地踏步,有的人一开始平台就是高的,做的内容你没见过,或者你周围没人做过,你也永远接触不到,很现实!
我隔壁实验室某博导曾经说过一句话,原话:
我*,你t m论文不能这么写,把***部分去掉,咱们组的绝活,大概写写就行了,让专家看懂就行。
我当时也惊了,我说这小论文怎么看着“不错”,但按照它的方法去走,结果就是不对呢?因为关键信息人家没写在上面啊,有时候一个参数的改动,你就得耗费很久很久,改不对你的结果就是错的,如果你非要钻牛角尖,一直改一直不对,那就先别搞了,有可能对方是“编的”,离了个大谱!
最后祝各位学术工作者,多出成果,注意身体,注意发量!

 发布于 2023-04-14 11:59・IP 属地北京
发布于 2023-04-14 11:59・IP 属地北京查看全文>>
日辛说 - 69 个点赞 👍
查看全文>>
匿名用户 - 65 个点赞 👍


一般这种就是刚读研究生,刚接触科研的才问的问题,我读本科保完研也有类似的想法,当你做久了科研就知道要开源代码不是一件容易的事,本身就是为了验证想法写的代码,这种代码能有多强的可读性?不过一般可以给通讯作者或第一作者发邮件说明缘由并请求提供源代码,一般是会给你的。
如果不开源,也可能就是源代码中含有不公开的一部分,或因为版权问题、或因为保密问题而不能公开。
复现的结果比论文原本的差也同样不能说明什么问题,种子数和超参数都会对实验结果产生影响,如果你对计算机体系结构有了解,还会想到不同的计算机硬件也会对实验结果产生很大影响。所以根本没有真正意义上的复现。
如果仅仅因为不公开代码、或者对所谓的复现后的结果不在你的容忍范围内,就说其学术不端,我说一句话:不太合适。
你就直接说不能为你做“乐高式”研究提供方便的论文叫学术不端呗
编辑于 2023-01-18 23:39・IP 属地吉林查看全文>>
匿名用户 - 55 个点赞 👍
不开源很正常。
很多可信度很高的论文,比如谷歌的一堆很牛逼的论文都没有来源。
毕竟他们花了很大的人力,物力,通过长时间的研发得到的结果,而且这些成果是得到验证的。所以不开源也是理解的。
到了后来
出现了越来越多瞎掰的论文。这些论文的特点是
一堆虚头巴脑的公式,然后搞一些新的名词的模块。而效果贼牛逼,但是又无法验证的。
说白了就是造假。
于是经常会被人要代码,然后去重复其计算过程。
发展到这里后,一些会议会要求论文作者开源。或者对特定数据集重新算过。
在所有行为中,最恶心的是假开源。
比如清华有一个人,水了几十篇论文的。
特么的他所谓的开源,里面readme都没有
放了一堆乱七八糟的东西上去。
所以,最恶心的不是不开源,是假开源!
发布于 2023-03-08 00:02・IP 属地广东查看全文>>
疯狂绅士 - 42 个点赞 👍
1. 审稿人只关注你论文的思想创新性和故事逻辑性,另外再看你论文实验数据是否能有效支撑你的创新点(即: 创新点要有实验数据支撑)。
2. 送审时,你的论文如果表明会开放源代码(或已开放源代码),那么审稿人会对你论文的实验数据更具信服力,能有效促进你论文被接收。
3. 审稿人只关注你的代码是否开源,至于源代码是否真能完全跑出论文实验结果,审稿人不清楚也没时间去跑代码;而源代码是否真如论文数据那般神奇涨点,只有感兴趣的读者会去验证。
4. 要想论文更容易被接收?那也好办: 那就开放源代码呗,但我不公布全部,只公布核心部分。只要读者跑出来的结果和论文上的数据大差不差,就没啥问题,毕竟你的实验设置和作者的实验设置都不一样,有些差别肯定是可以理解的啦。
欢迎关注公众号: CVHub,每天分享顶会顶刊优质论文的深度解读
编辑于 2023-03-07 12:14・IP 属地广东查看全文>>
CVHub - 20 个点赞 👍
学术界,尤其是深度学习领域,有个非常不好的做法,那就是挑结果。
为什么是深度学习呢?
因为目前这个领域的可解释性很差,结果好说不明白为什么好,甚至说不明白机器到底学到了什么。
我做很多次实验,但是只挑选结果比较好的那次放到论文里。
你说这是造假吗?不是,因为这个结果是实实在在跑出来的。
较真起来,是可以拿出原代码、数据、结果的,因为是真实跑出来的,经得起检验。
但是,如果你把代码公开出来,人人都可以自己跑,就会发现,其实效果不是每次都那么好的。
类似于我造了个火箭,10次发射只能有1次成功,如果我只给你看成功的1次,你会觉得我很牛逼,而告诉你所有结果的话,我就成废物了。
敢开源代码的,甚至是敢把数据集都开源的,就算是挑过结果,也不会差到哪里去。
不开源的,多半你自己按思路实现出代码来,效果也很一般。
就是这样。
编辑于 2023-03-09 00:51・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
李明阳