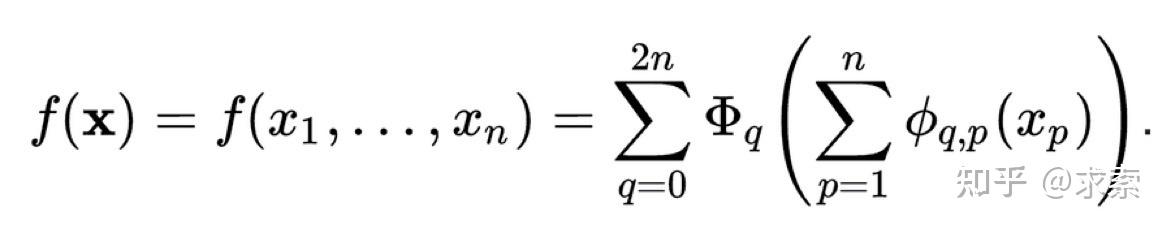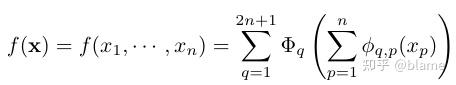如何评价 KAN:Kolmogorov-Arnold Networks ,是否优于 MLP?
论文地址: https://arxiv.org/pdf/2404.19756是否能够提升现在的语言大模型。

- 20 个点赞 👍
查看全文>>
知乎用户 - 18 个点赞 👍
从论文提及的内容来看:
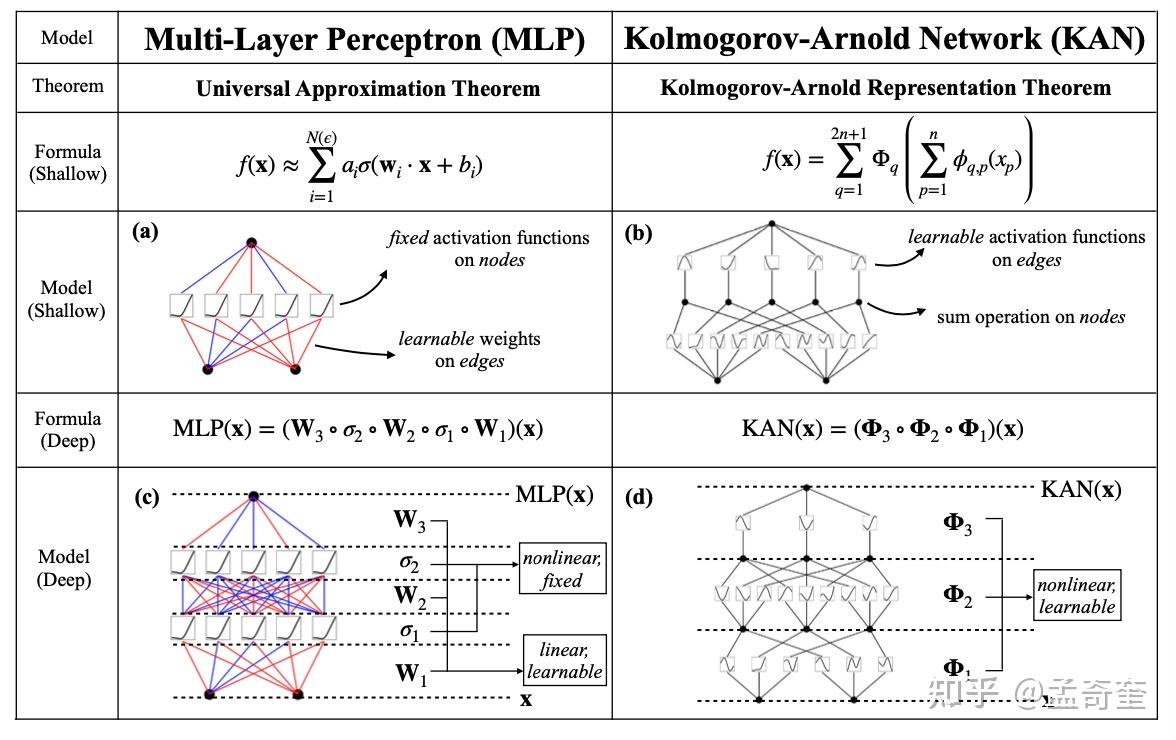
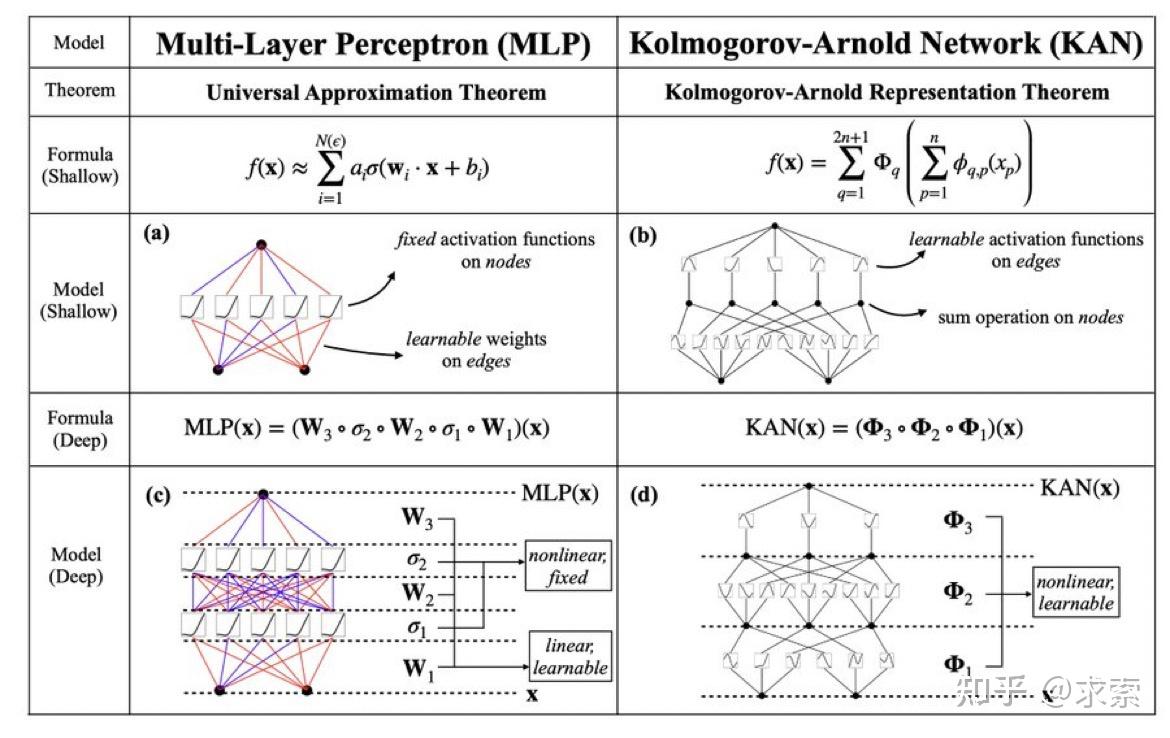
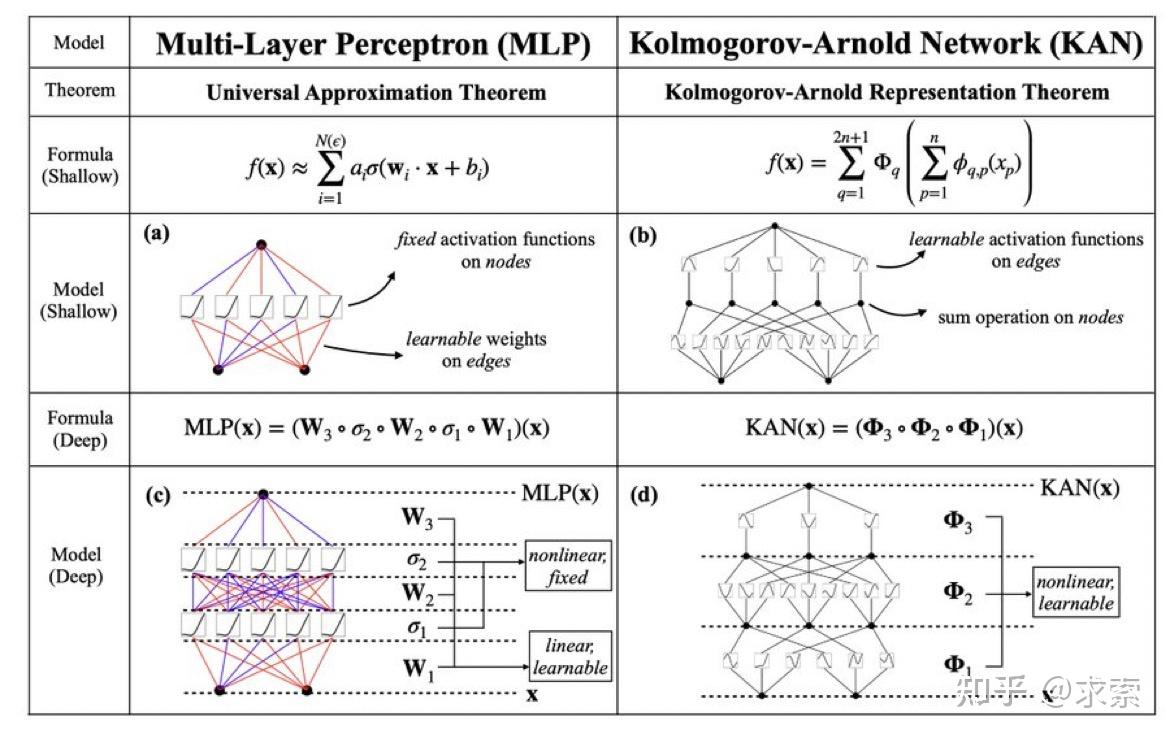
受到Kolmogorov-Arnold表示定理的启发,我们提出了Kolmogorov-Arnold网络(KANs)作为多层感知机(MLPs)的有前途的替代品。与MLPs在节点(“神经元”)上有固定的激活函数不同,KANs在边(“权重”)上具有可学习的激活函数。KANs根本没有线性权重——每一个权重参数都被一个参数化为样条的单变量函数所代替。我们展示了这种看似简单的变化使KANs在准确性和可解释性上超越MLPs。在准确性方面,相对较小的KANs可以在数据拟合和偏微分方程求解方面达到或超过较大MLPs的准确度。从理论和实证上看,KANs拥有比MLPs更快的神经缩放规律。在可解释性方面,KANs可以直观地可视化,并且可以轻松地与人类用户交互。通过在数学和物理学的两个示例中,KANs被证明是有用的“合作伙伴”,帮助科学家(重新)发现数学和物理定律。总之,KANs是MLPs的有前途的替代品,为进一步改进依赖于MLPs的当今深度学习模型开辟了机会。
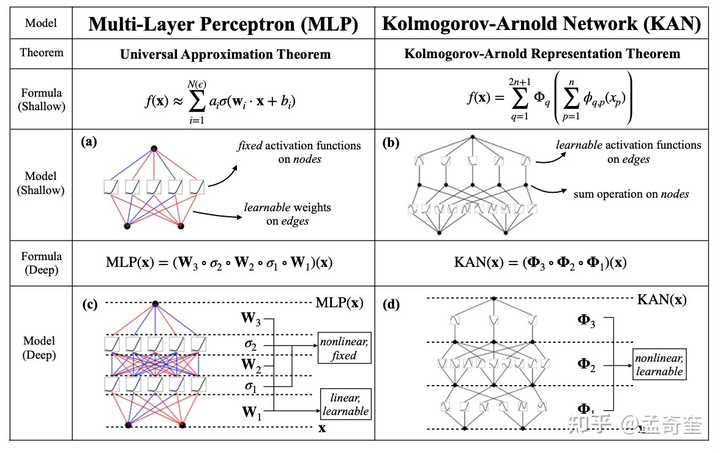

图1 Kan存在训练速度慢的问题:
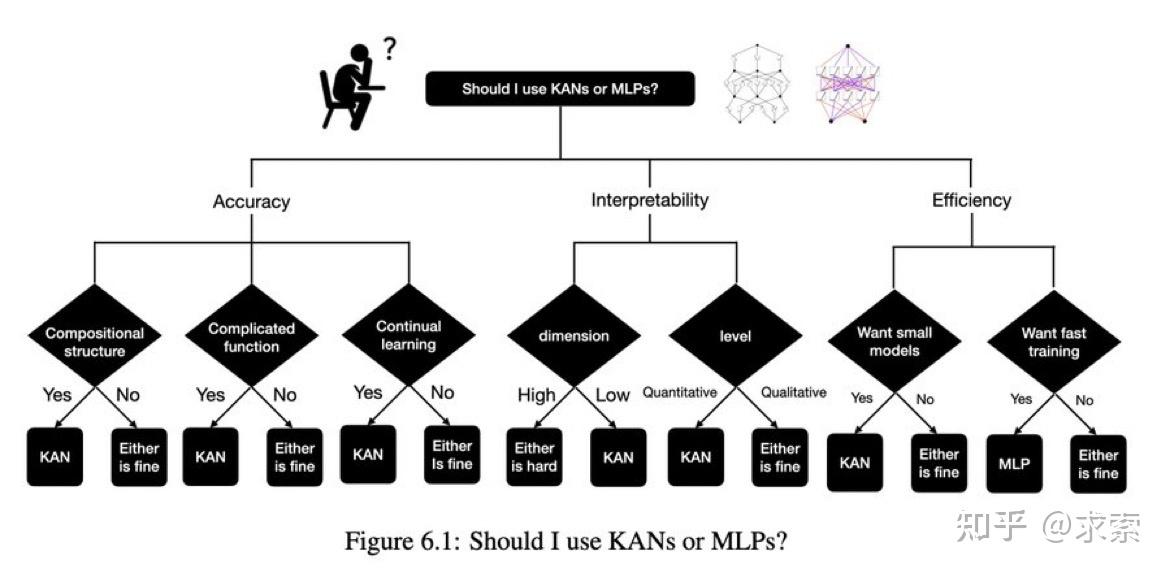
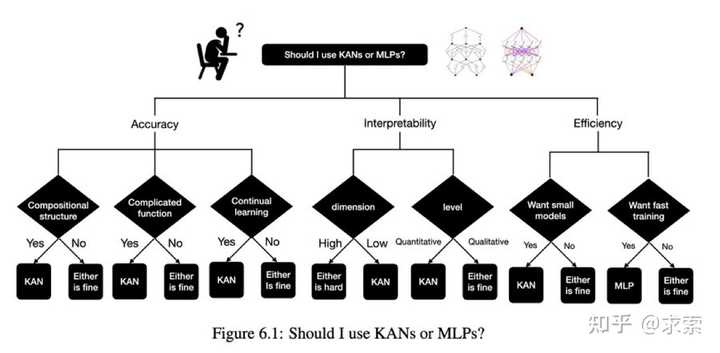
目前,KANs最大的瓶颈在于其训练速度慢。在相同参数数量的情况下,KANs通常比MLPs慢10倍。不过,我们必须坦诚,我们并没有努力优化KANs的效率,因此我们认为KANs的训练速度慢更多地是一个未来可以改进的工程问题,而不是一个根本限制。如果想要快速训练模型,应该使用MLPs。然而,在其他情况下,KANs应该与MLPs相当或更优,这使得尝试使用KANs是值得的。图6.1中的决策树可以帮助决定何时使用KAN。简而言之,如果你关心可解释性和/或准确性,并且训练速度慢不是主要问题,我们建议尝试使用KANs。
发布于 2024-05-03 10:25・IP 属地北京查看全文>>
孟奇奎 - 3 个点赞 👍
KAN这两天太火了,感兴趣可以阅读如下文章:
最近麻省理工、加州理工等学校研究员发表一篇替代多层感知机MLP的论文《KAN: Kolmogorov–Arnold Networks》。
论文摘要
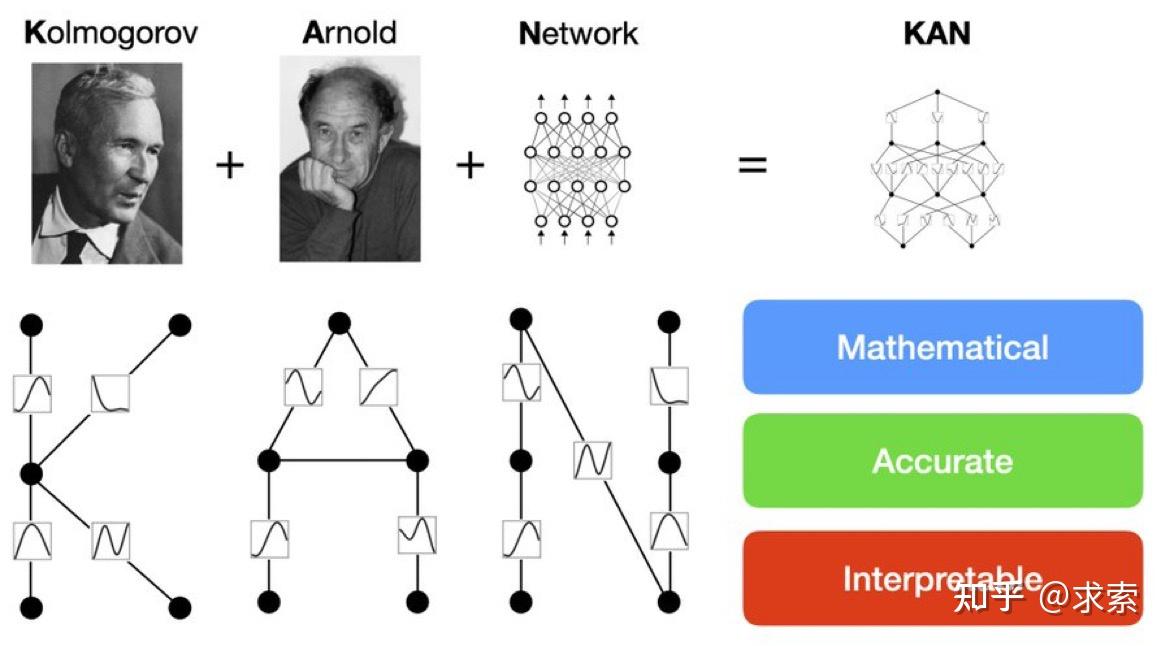
论文提出了一种新型神经网络架构——Kolmogorov-Arnold Networks(KANs)(为了纪念两位伟大的已故数学家安德烈·科尔莫戈罗夫和弗拉基米尔·阿诺德,我们称他们为科尔莫戈罗夫-阿诺德网络),它受到Kolmogorov-Arnold表示定理的启发,目标是作为多层感知器(MLPs)的替代品。

KANs的特点是将激活函数置于网络的边缘(权重),而不是传统的节点上,并且这些激活函数是可学习的,由样条函数参数化。论文开发了KANs的实现代码,并通过GitHub和pip安装包分享给研究社区,促进了进一步的研究和开发。
KANs解决了MLPs在非线性回归、数据拟合、偏微分方程求解以及科学发现中的一些限制,如固定激活函数的局限性、参数效率低、可解释性差等。
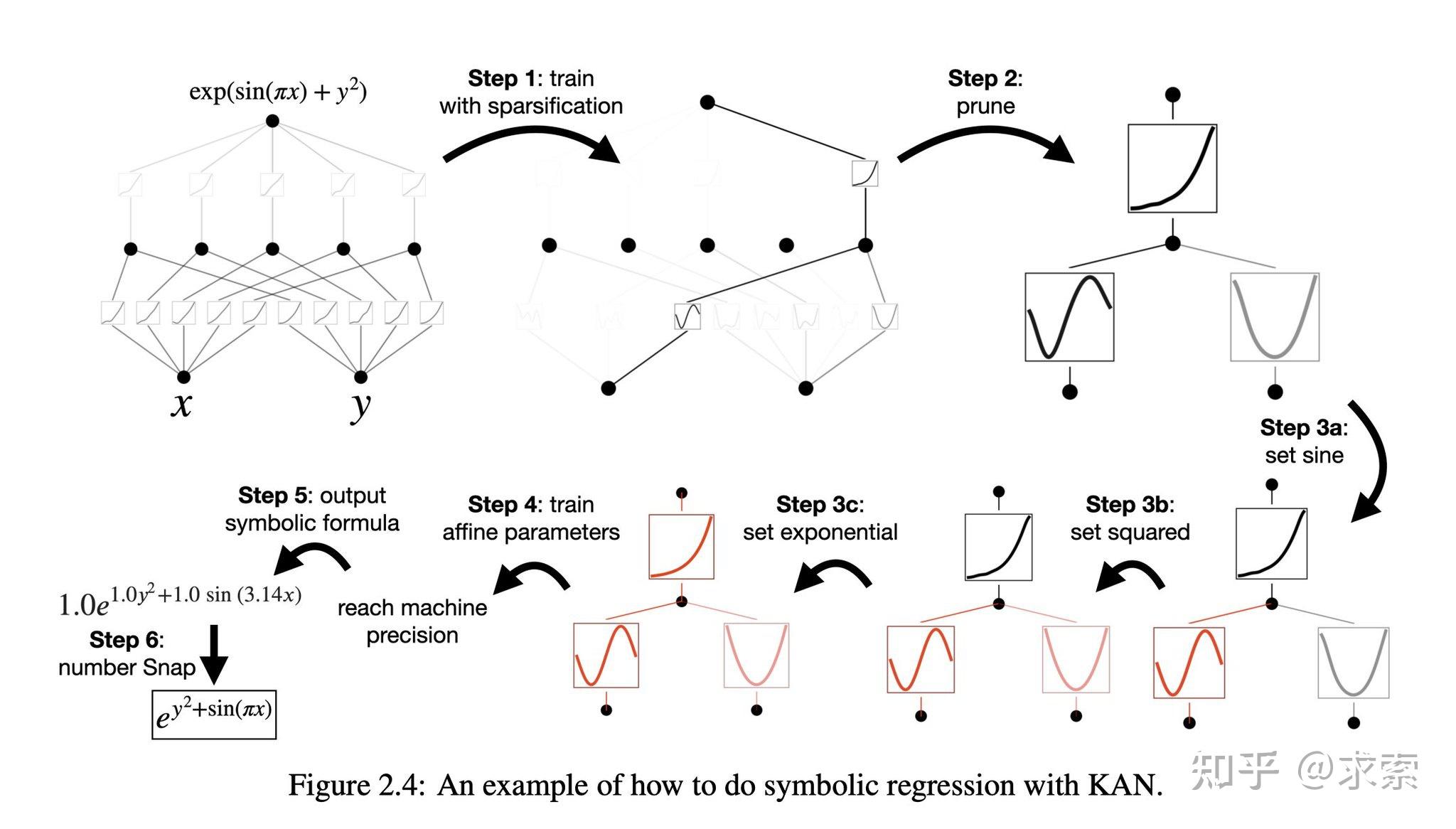
KANs通过网格扩展技术提高准确性,即通过细化样条函数的网格来提高逼近目标函数的精度。引入简化技术,包括稀疏化、可视化、剪枝和符号化,以提高KANs的可解释性。
论文核心内容
MLP 是如此基础,但还有其他选择吗?MLP 将激活函数放在神经元上,但我们是否可以将(可学习的)激活函数放在权重上?是的,KAN可以!作者提出了 Kolmogorov-Arnold 网络 (KAN),它比 MLP 更准确、更易于解释。
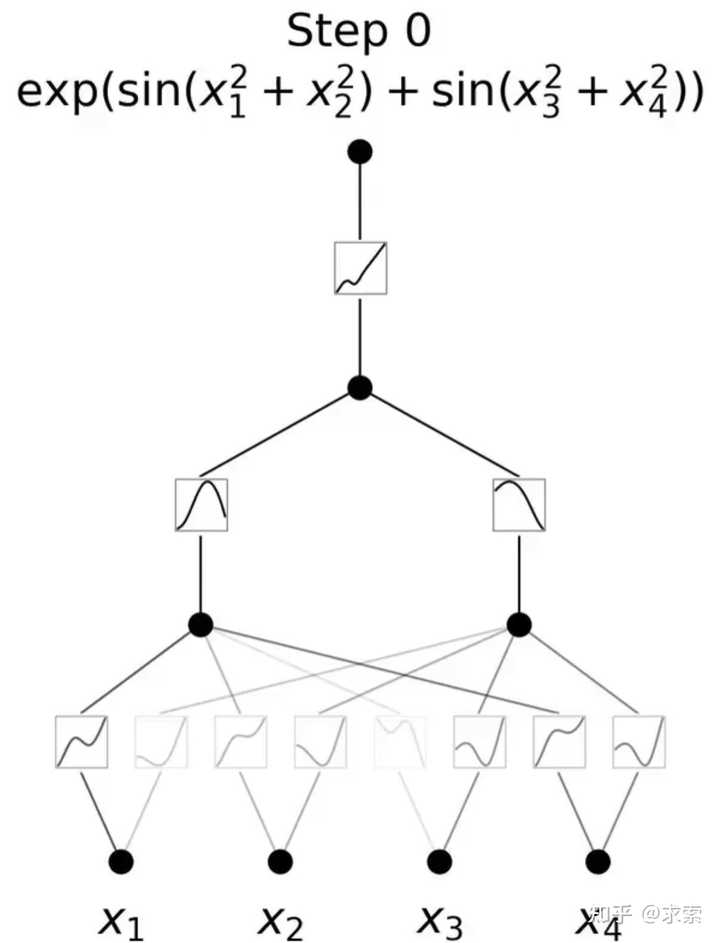

KANs对 MLP 进行简单的更改:将激活函数从节点(神经元)移到边缘(权重)!KANs通过将每个权重参数替换为一个一元函数,利用样条函数来近似这些一元函数。
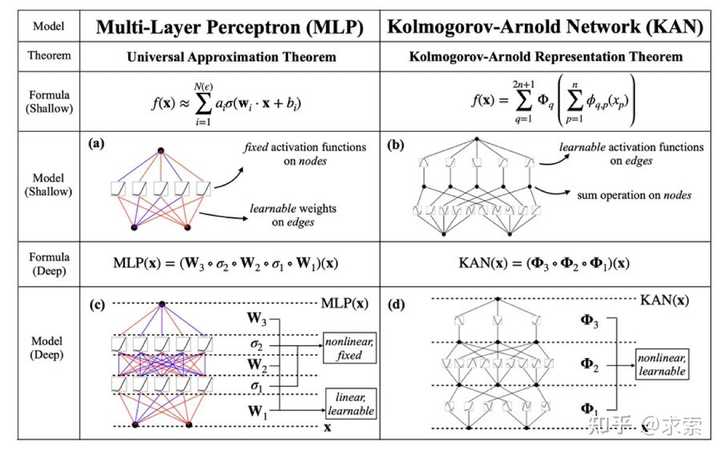

这个变化乍一听似乎有些奇怪,但其实它与数学中的近似理论有着很深的联系。事实证明,Kolmogorov-Arnold 表示对应于 2 层网络,其 (可学习) 激活函数位于边上而不是节点上。
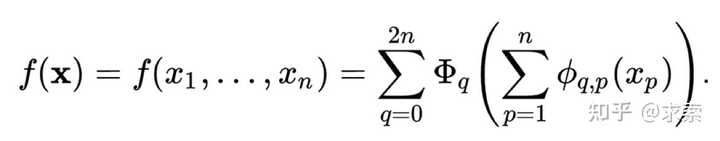

从数学角度来看:MLP 受到通用近似定理 (UAT) 的启发,而 KAN 受到柯尔莫哥洛夫-阿诺德表示定理 (KART) 的启发。网络能否以固定宽度实现无限精度?UAT 的答案是“不”,而 KART 的答案是“可以”(但有警告)。
从算法方面来看:KAN 和 MLP 是双重的,因为-- MLP 对神经元具有(通常固定的)激活函数,而 KAN 对权重具有(可学习的)激活函数。这些 1D 激活函数被参数化为样条函数。
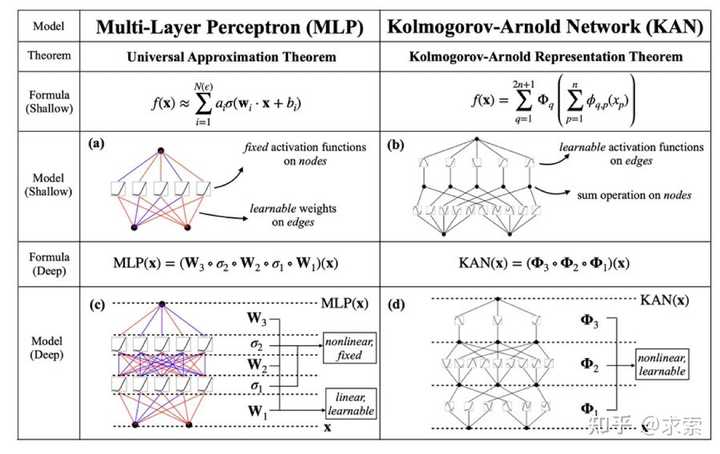
从实际角度来看:作者发现 KAN 比 MLP 更准确、更易于解释,尽管由于 KAN 的激活函数可学习,因此训练速度较慢。
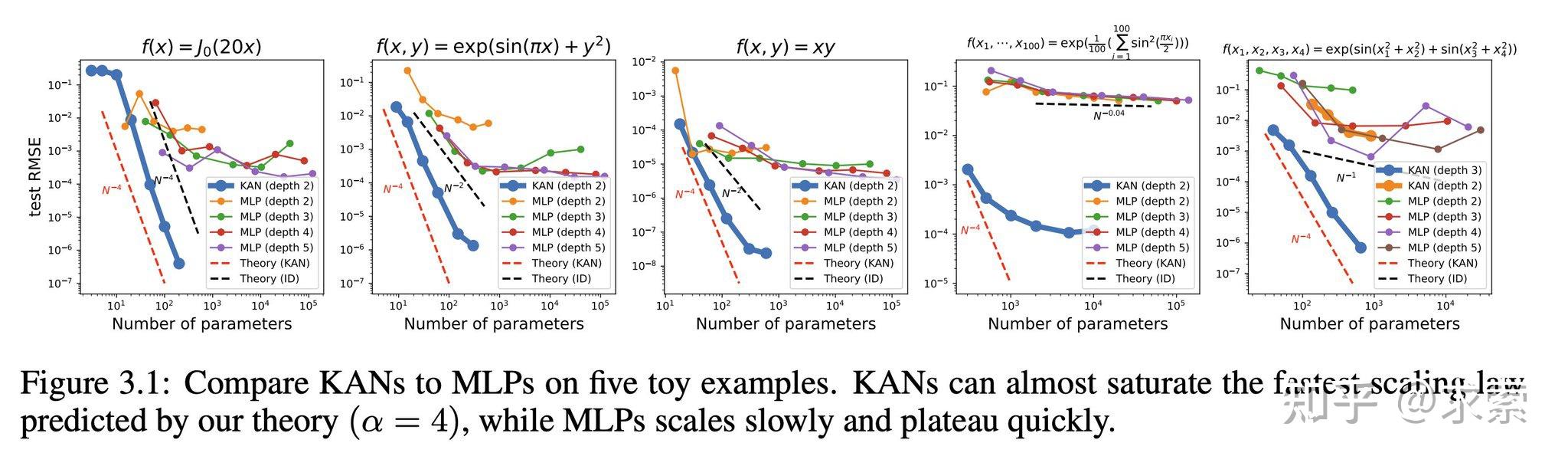
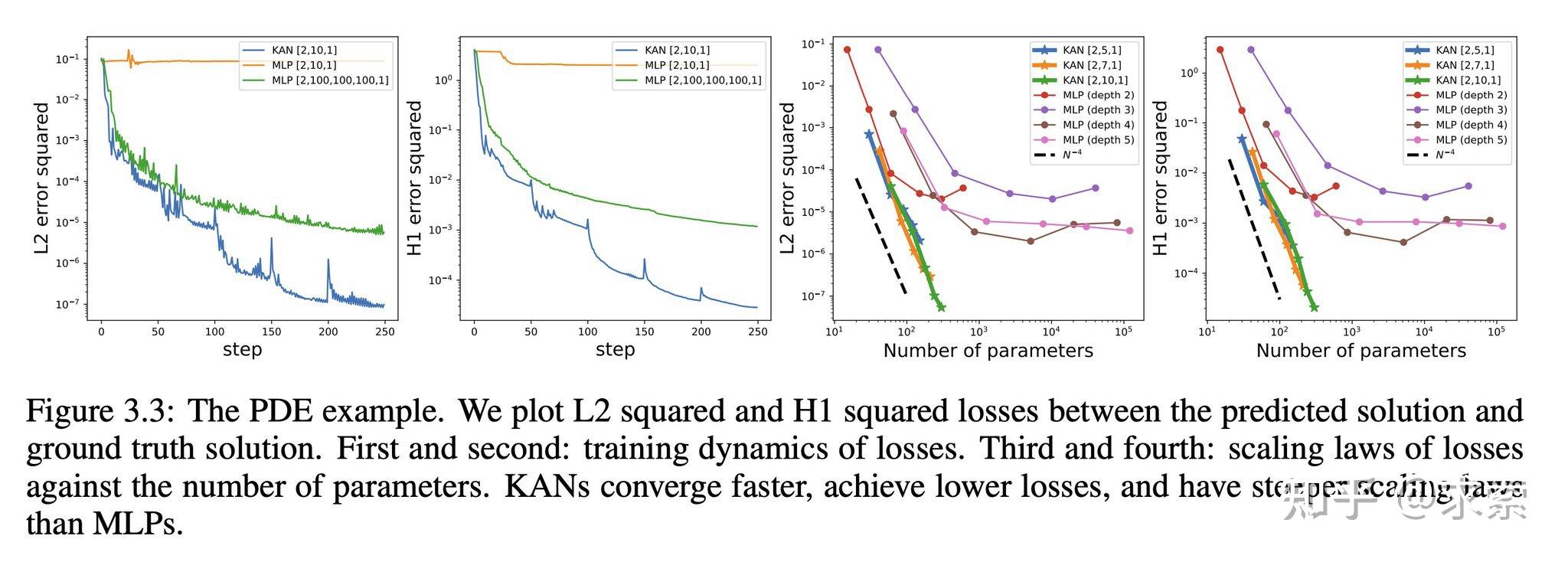
KANs在准确性上超越了MLPs,尤其是在数据拟合和PDE求解任务中,展示了更快的神经缩放法则。
KAN 的缩放速度比 MLP 快得多,这在数学上基于 Kolmogorov-Arnold 表示定理。KAN 的缩放指数也可通过经验获得。
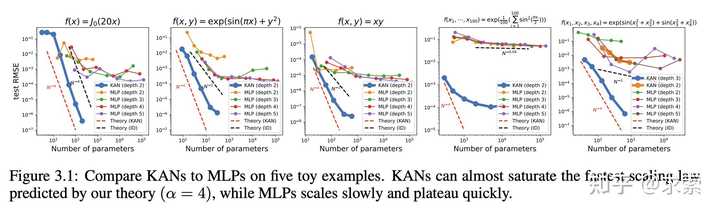

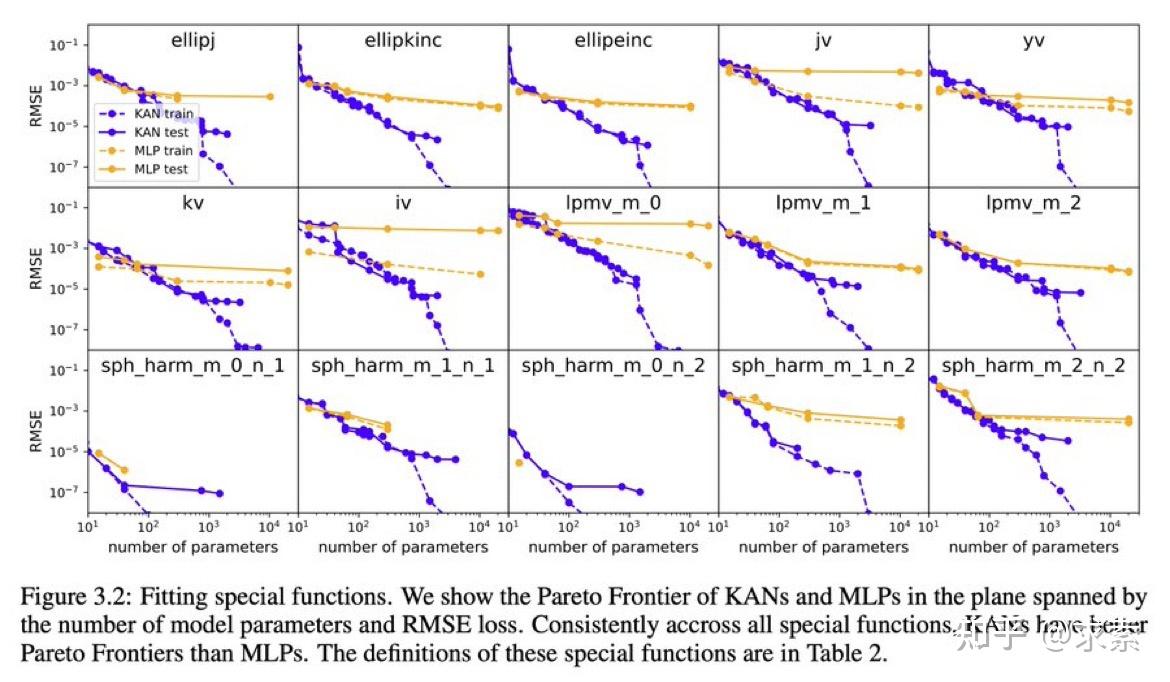
KAN 在函数拟合方面比 MLP 更准确,例如拟合特殊函数。
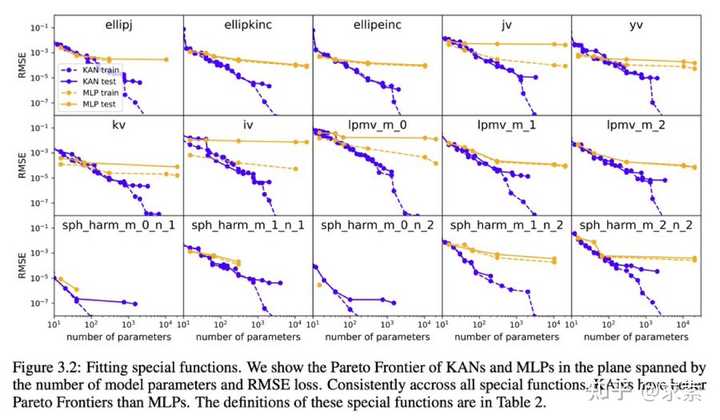

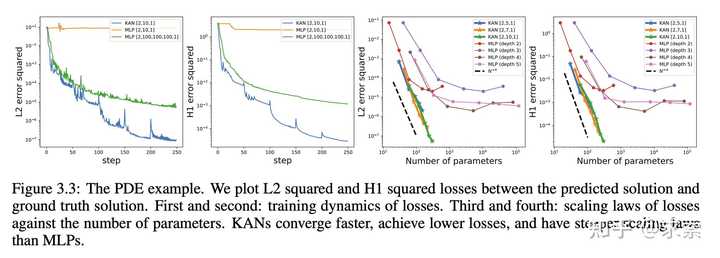
KAN在PDE求解任务上比MLP更快更准确,例如求解泊松方程。

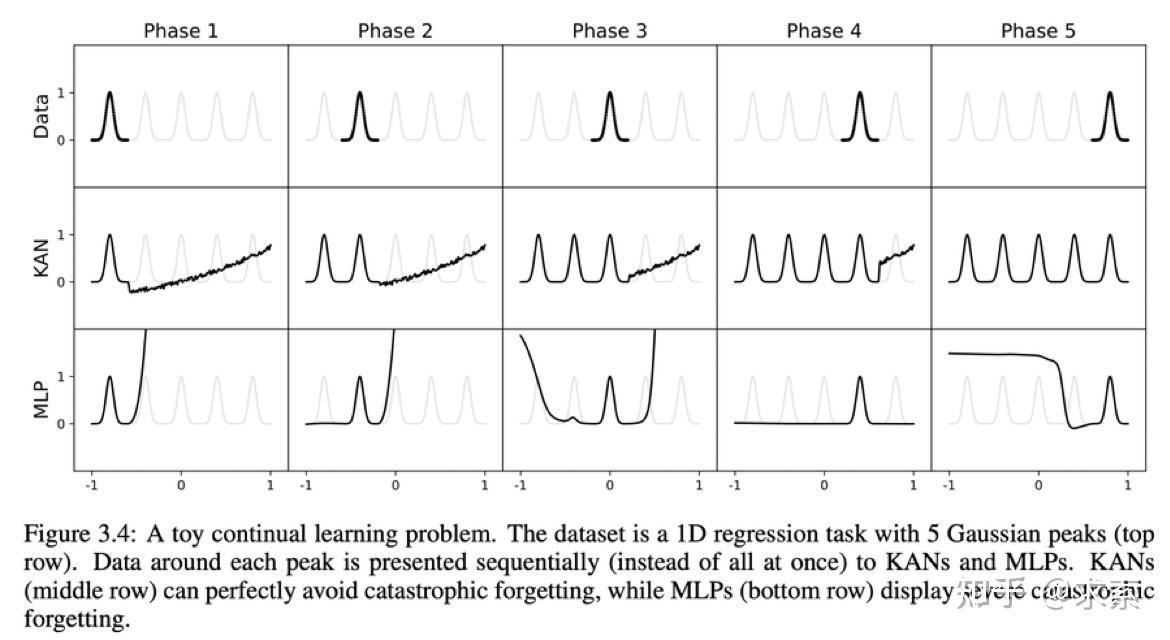
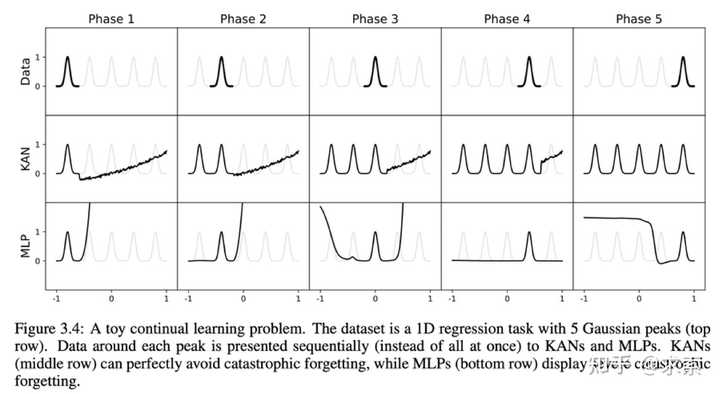
1另外,KAN 具有避免灾难性遗忘的天然能力。

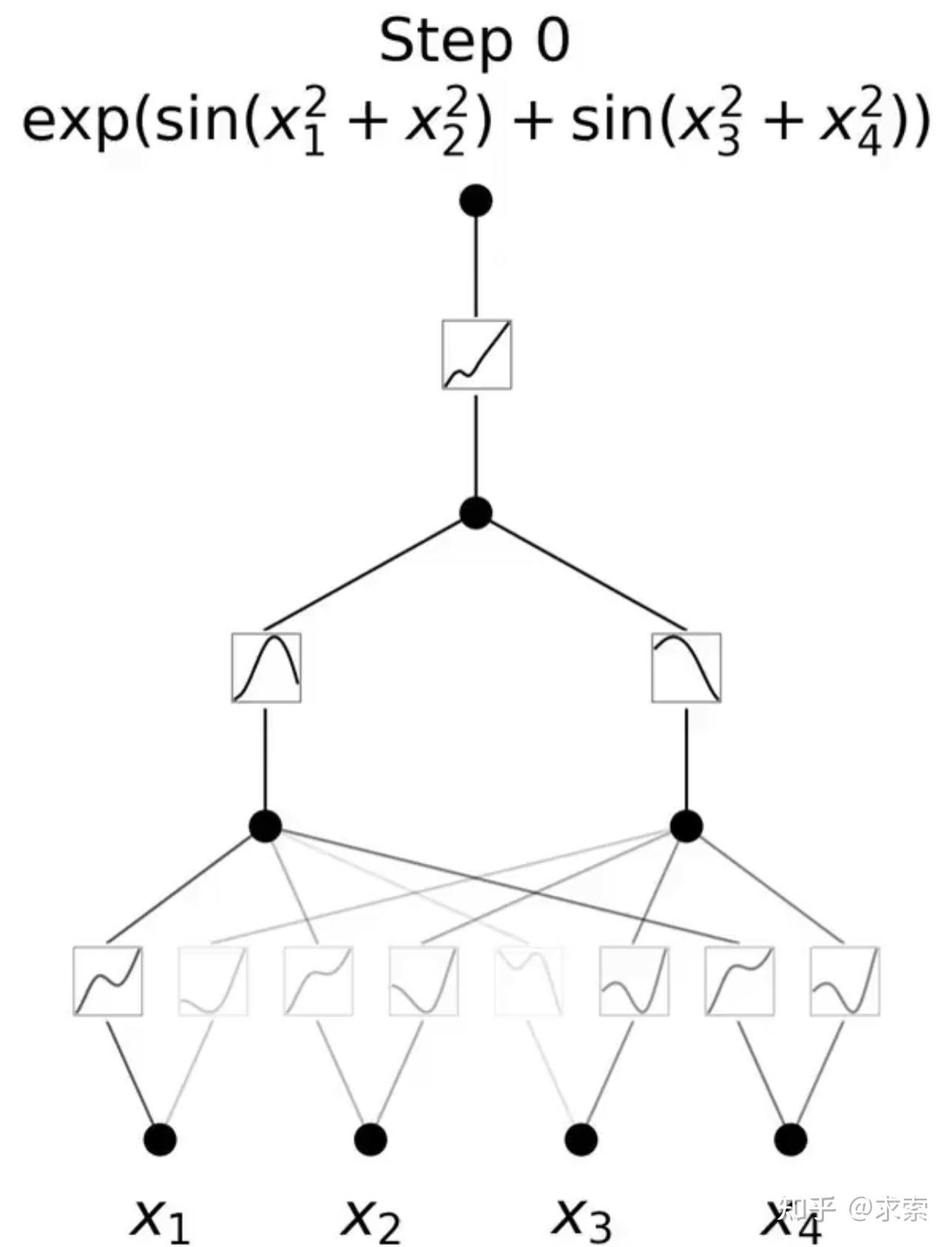
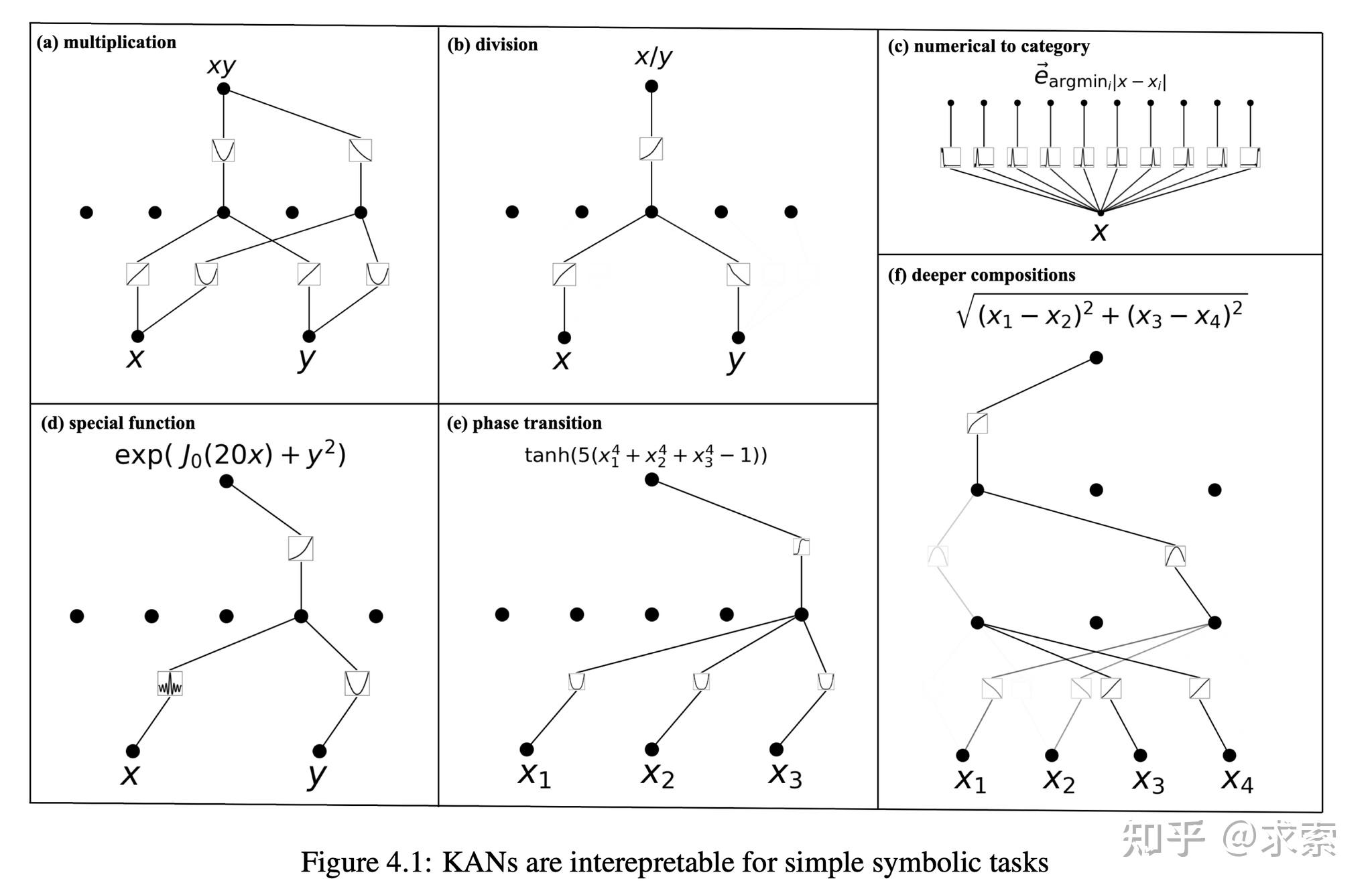
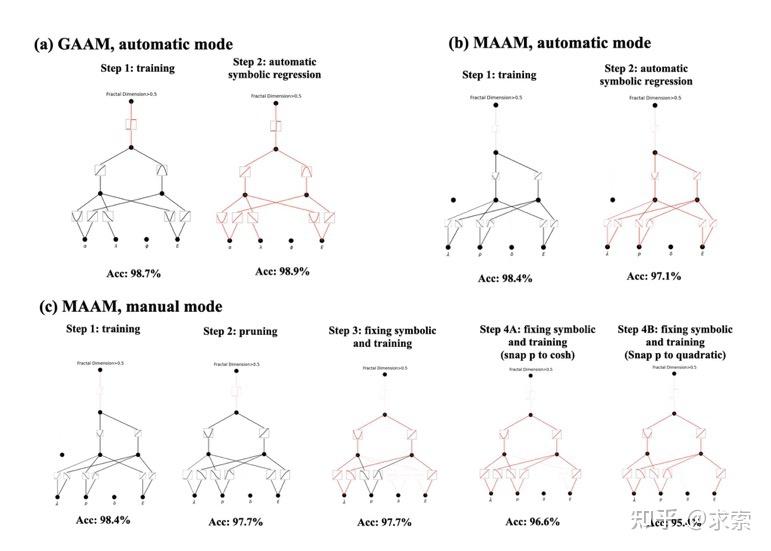
KANs提供了更好的可解释性,使得网络结构和激活函数可以直观地被理解和解释。KAN可以从符号公式中揭示合成数据集的组成结构和可变依赖性。
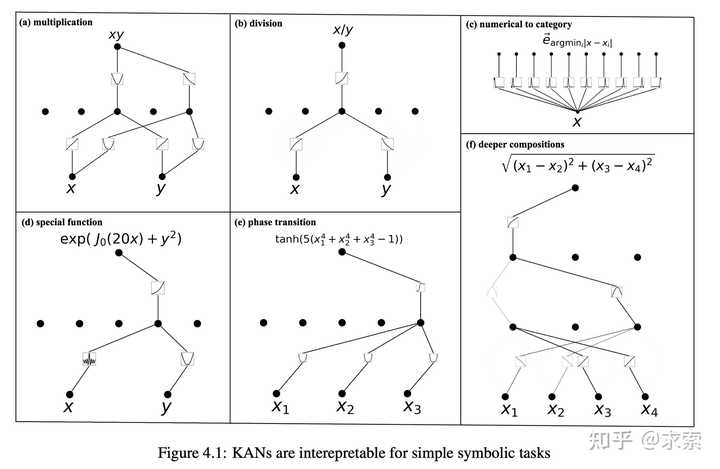

人类用户可以与 KAN 交互,使其更易于解释。将人类的归纳偏见或领域知识注入 KAN 很容易。
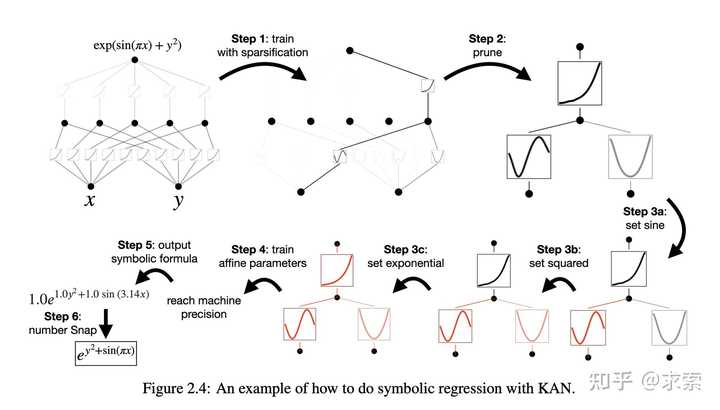

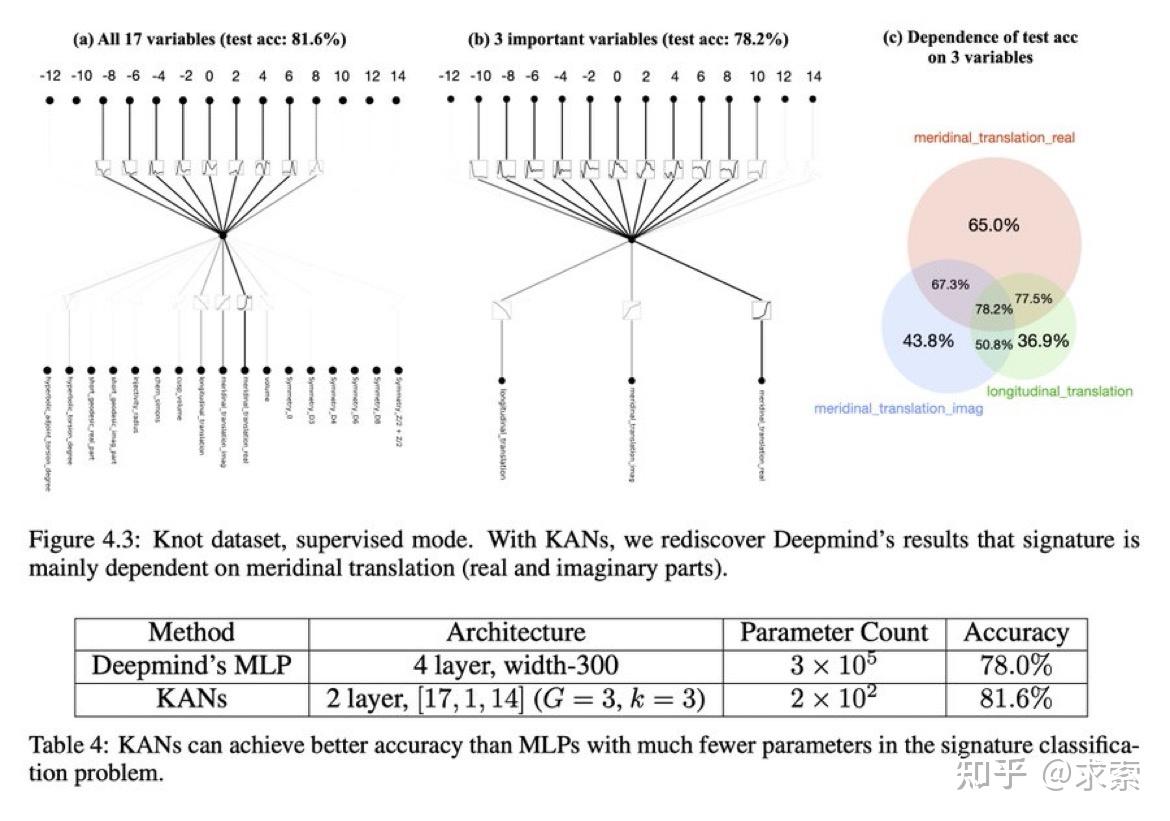
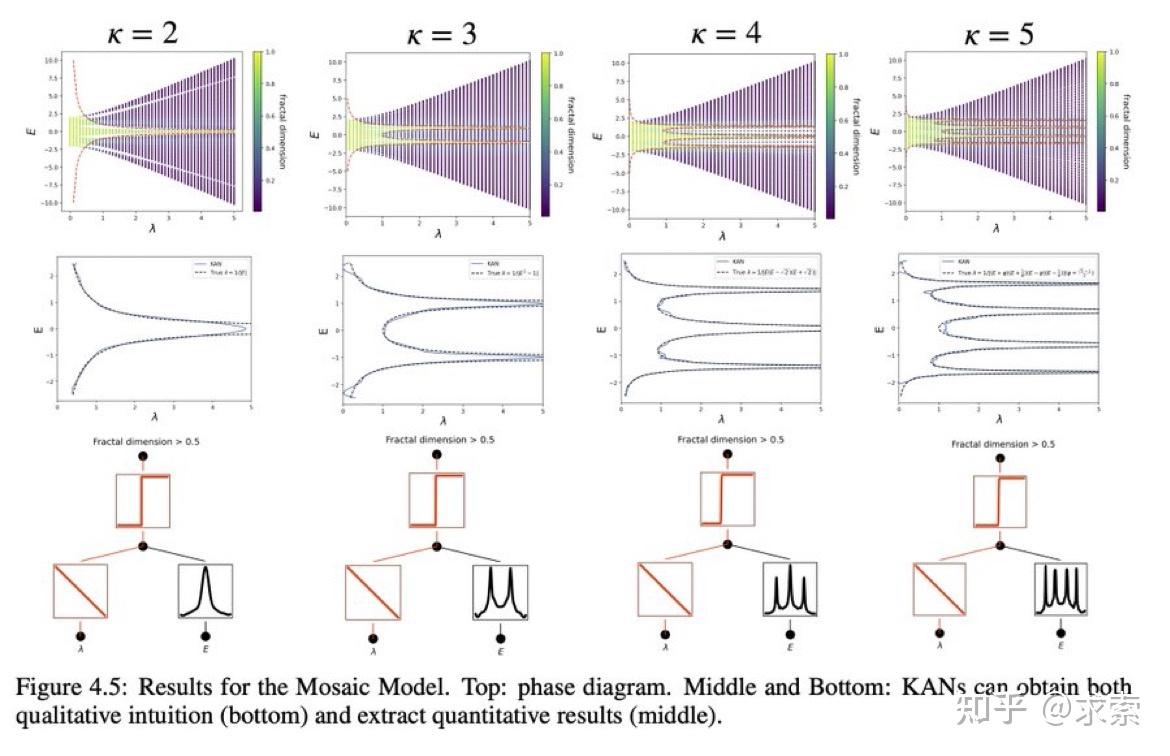
论文还探讨了KANs在科学发现中的潜力,KAN 也是科学家的得力助手或合作者。如在数学的结理论和物理的Anderson局域化中的应用。
利用 KAN 重新发现了结理论中的数学定律。KAN 不仅以更小的网络和更高的自动化程度重现了GoogleDeepmind的结果,还发现了新的签名公式,并以无监督的方式发现了结不变量的新关系。
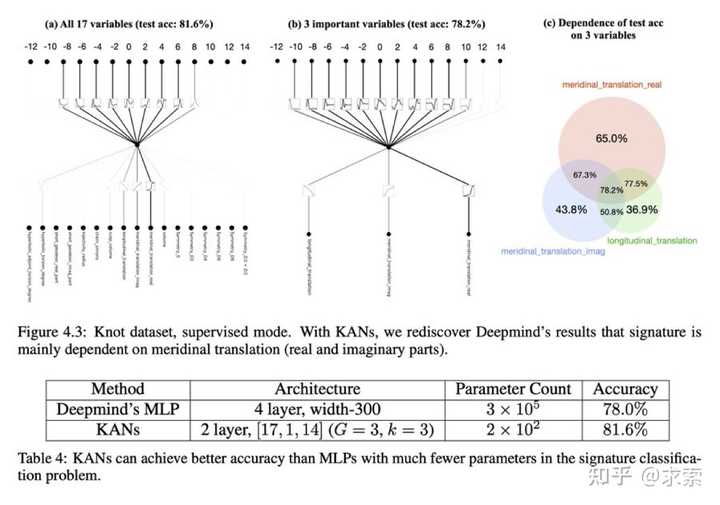

特别是,Deepmind的MLP有~300000个参数,而KAN只有~200个参数。KAN可以立即解释,而MLP需要特征归因作为后期分析。
KAN 可以帮助研究 Anderson 局域化,这是凝聚态物理学中的一种相变。无论是从数值上,还是从物理上,KAN 都使迁移率边缘的提取变得非常简单。
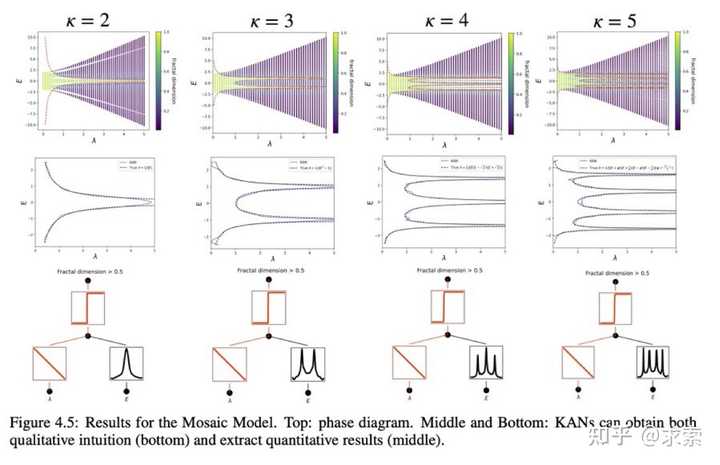

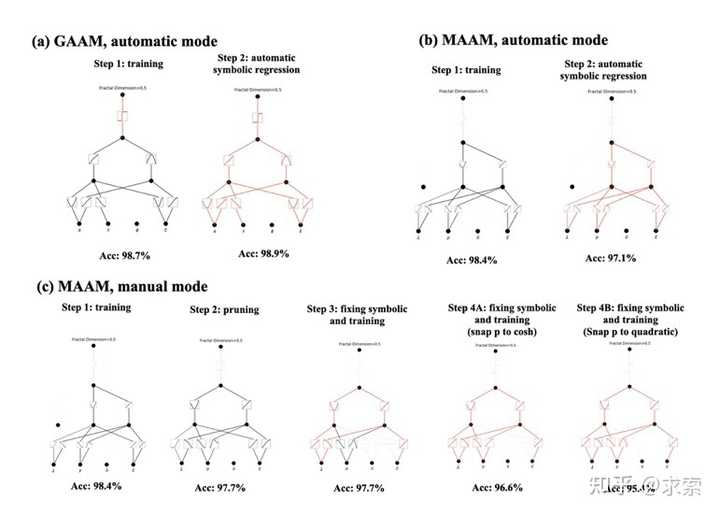



根据实证结果,KAN 将成为 AI + Science 的有用模型/工具,因为它具有准确性、参数效率和可解释性。KAN 对机器学习相关任务的实用性更具推测性,有待未来研究。

论文中的所有示例都可以在单个 CPU 上在不到 10 分钟的时间内重现(扫描超参数除外)。诚然,实验的问题规模比许多机器学习任务要小,但对于与科学相关的任务来说却是典型的。
真的能替代MLP吗?
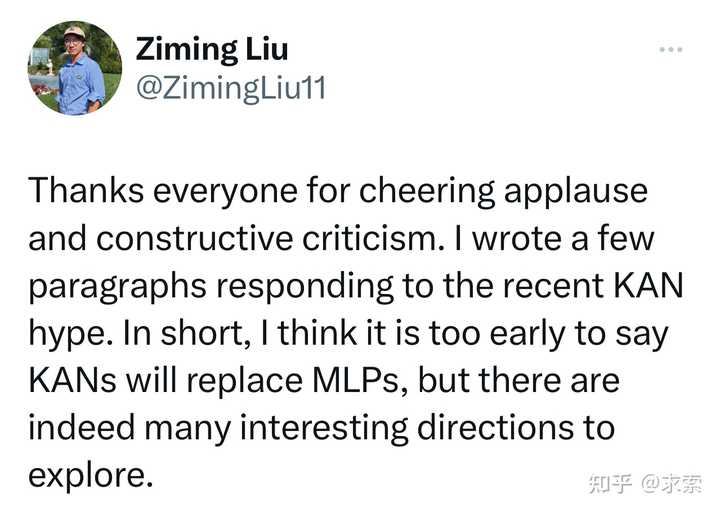
作者的回应:
感谢大家的欢呼和建设性批评。我写了几段文字来回应最近的 KAN 炒作。简而言之,我认为现在说KAN将取代MLP 还为时过早,但确实有很多有趣的方向值得探索。

为什么训练很慢?
原因 1:技术。可学习激活函数(样条函数)比固定激活函数的评估成本更高。
原因 2:个人原因。研究作者的物理学家性格会抑制程序员性格,所以没有尝试优化效率。
能适适配transformers吗?
研究作者不知道该怎么做,虽然一个简单的(但可能有效!)扩展只是用 KAN 取代 MLP。
paper:https://arxiv.org/abs/2404.19756
code:https://github.com/KindXiaoming/pykan
documentation:https://kindxiaoming.github.io/pykan/
发布于 2024-05-03 23:30・IP 属地福建查看全文>>
求索 - 2 个点赞 👍
目前来看,得出结论还为时过早。
MLP和KAN的主要区别在于其基础理论不相同,因此优化手段也不一样。KAN暂时还没有找到合适的高效优化手段,而如果想要大规模应用,就需要有人能证明KAN在实际应用中的效果。可是现在效率就制约了KAN的实用性。看来这是个鸡生蛋,蛋生鸡的问题,不知道谁愿意下场投入资源先吃螃蟹。
就论文展现出的结果看,甚至还达不到Mamba所表现出的前景效果,所以个人谨慎乐观看待。
发布于 2024-05-04 09:51・IP 属地江苏查看全文>>
知乎用户 - 2 个点赞 👍
针对关于MLP与KAN谁更优,甚至是否能够互相替代或颠覆的问题,讨论还为时过早。AI4S或者更进一步的AGI,除了在模型结构或者在依据数学与物理基础研究上实现算法上的大胆尝试与小心求证外(点个赞),希望能看到更多在数据科学和认知科学上的更多宏观框架上新的观点和突破。
记得在融合RL与LLM思想,探寻世界模型以迈向AGI「中·下篇」中,有曾跟大家提及未来AI能力持续的提升与演进除了离不开满足于对数据与算力的scale law之外,网络模型结构的突破将是可能影响AGI发展的另一个关键变量,而算法是模型结构应用的基础,基础数学理论即又是算法的理论基础,包括在SystemⅠ与SystemⅡ的快慢思考中,也对当下LLM所采用的自回归预测推理背后的模型结构所面对SystemⅡ的局限性进行了一些阐释;包括在提及与RL(强化学习)融合再到针对AI4S的探索中,其中在“世界模型的内涵”章节中对不管是World Models还是World Simulators不管是采用“传统数字符号化+形式化表征完成物理世界规律的精准刻画”还是基于“通过梯度下降在神经参数中隐式学习物理表征以模拟逼近”这两种计算模式的本质探寻..
如今,在模型算法中的底层数学基础层面上,KAN似乎寻找到了另一种更适合于处理数学和物理计算领域问题的数学变换拟合过程或非线性回归逼近过程,而这种“适合”是否是某种必然,与论文中所说的这些可能是非光滑甚至是分形的 1D 函数在解决数学或物理问题过程中所面临的大多数科学和日常生活中的的函数所对应的光滑性,及稀疏的组合结构的普遍性在其背后有着什么隐秘的联系?我想这都是需要在今后持续在不同任务领域进行实践摸索的..
大家如果有兴趣可以进一步参考我之前分享的两篇文章:
融合RL与LLM思想,探寻世界模型以迈向AGI「上篇」
https://zhuanlan.zhihu.com/p/686181862?utm_psn=1769941078436876289
融合RL与LLM思想,探寻世界模型以迈向AGI「中·下篇」
https://zhuanlan.zhihu.com/p/689818745?utm_psn=1769941890924089344
融合RL与LLM思想,探寻世界模型以迈向AGI「合集」
https://zhuanlan.zhihu.com/p/692379889?utm_psn=1769944222109884416
发布于 2024-05-04 05:22・IP 属地北京查看全文>>
吕明 - 2 个点赞 👍
简介:MLP定理的灵感来自逼近定理。相反,这里专注于Kolmogorov–Arnold表示定理,该定理可以通过一种成为Kolmogorov–Arnold网络的新型神经网络实现。在本文的 后续将会回顾Kolmogorov-Arnold 定理,并且根据此定理启发Kolmogorov-Arnold 网络设计。同时为KAN的表达能力机器神经缩放定律提供了理论保证。本文同时提出一种网络扩展技术,以使KAN越来越准确。在后面也提出了简化技术,使得KAN是可解释的。
1、Kolmogorov–Arnold 理论
此理论由Vladimir Arnold和Andrey Kolmogorov共同确定,如果f是有域上的多元连续函数,则f可以写为单个变量的连续函数和加法的二元运算的有限组合。f的定义域:
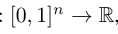

定义域 

多元连续函数 这里满足条件:
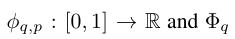

从某种意义上说,证明了唯一真正的多元函数都是加法,因为所有其他的函数都可以使用单变量函数和求和进行编写。对于机器学习来说,人们会天真的认为这是一个好消息:学习高维函数可以归结为学习多项式的一维函数。然而,这些一位函数可能是非平滑的,甚至是分形的,因此在事件中可能无法学习。由于这种病态行为,Kolmogorov–Arnold定理在机器学习中被判处为死刑,被认为理论上是合理,但实际上毫无用处。
然而,本文则认为Kolmogorov–Arnold定理对机器学习是有用的。首先我们不需要拘泥于原来的方程。它只有两层非线性和隐藏层中的(2n+1)项,这里将网络推广到任意宽度和深度。其次,科学和日常生活中的大多数功能通常是平滑的,并且具有稀疏的组成结构,这可能有助于有平滑的Kolmogorov–Arnold函数。这里更关心典型的情况而不是最坏的情况。毕竟,物理世界和机器学习任务必须具有使物理学和机器学习有用或可推广的结构。
发布于 2024-05-09 00:14・IP 属地广东查看全文>>
blame - 1 个点赞 👍
这篇论文给我印象最深的一句话:
The language of science is functions.
根据问题特点,设计解决方案。
专才优于通才。
分工合作,合作共赢。
KAN甚至不一定需要考虑在NLP、CV上面的性能。
Kolmogorov-Arnold Networks (KAN)随想
发布于 2024-05-04 09:16・IP 属地加拿大查看全文>>
Yuxi Li