
KAN这两天太火了,感兴趣可以阅读如下文章:
最近麻省理工、加州理工等学校研究员发表一篇替代多层感知机MLP的论文《KAN: Kolmogorov–Arnold Networks》。
论文摘要
论文提出了一种新型神经网络架构——Kolmogorov-Arnold Networks(KANs)(为了纪念两位伟大的已故数学家安德烈·科尔莫戈罗夫和弗拉基米尔·阿诺德,我们称他们为科尔莫戈罗夫-阿诺德网络),它受到Kolmogorov-Arnold表示定理的启发,目标是作为多层感知器(MLPs)的替代品。
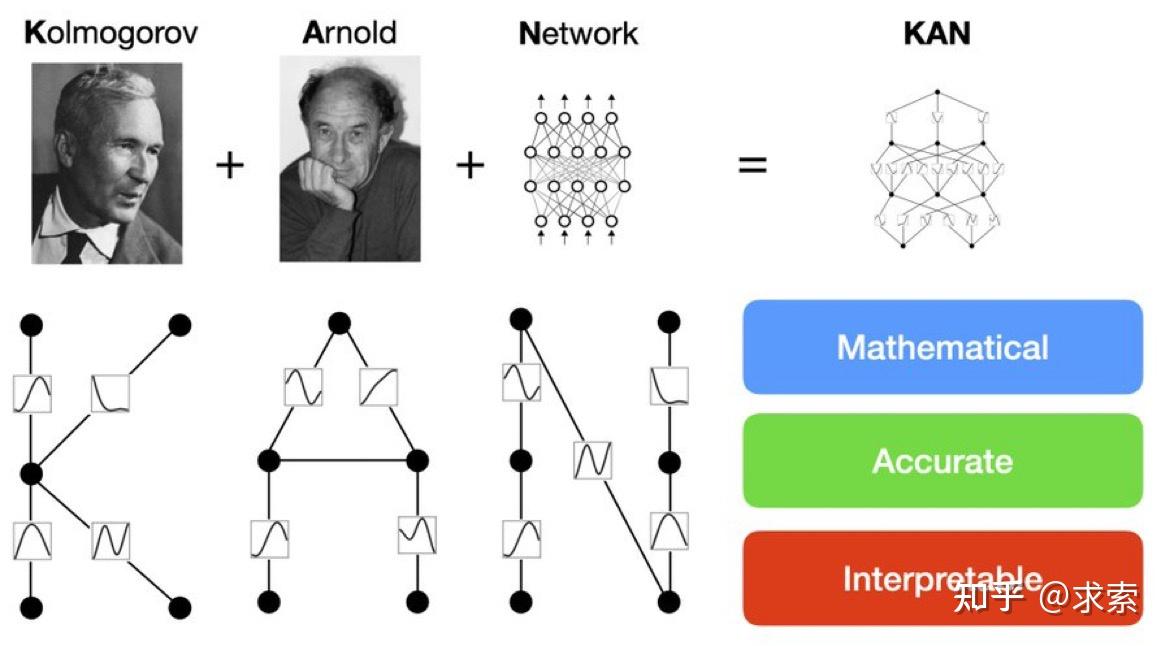
KANs的特点是将激活函数置于网络的边缘(权重),而不是传统的节点上,并且这些激活函数是可学习的,由样条函数参数化。论文开发了KANs的实现代码,并通过GitHub和pip安装包分享给研究社区,促进了进一步的研究和开发。
KANs解决了MLPs在非线性回归、数据拟合、偏微分方程求解以及科学发现中的一些限制,如固定激活函数的局限性、参数效率低、可解释性差等。
KANs通过网格扩展技术提高准确性,即通过细化样条函数的网格来提高逼近目标函数的精度。引入简化技术,包括稀疏化、可视化、剪枝和符号化,以提高KANs的可解释性。
论文核心内容
MLP 是如此基础,但还有其他选择吗?MLP 将激活函数放在神经元上,但我们是否可以将(可学习的)激活函数放在权重上?是的,KAN可以!作者提出了 Kolmogorov-Arnold 网络 (KAN),它比 MLP 更准确、更易于解释。
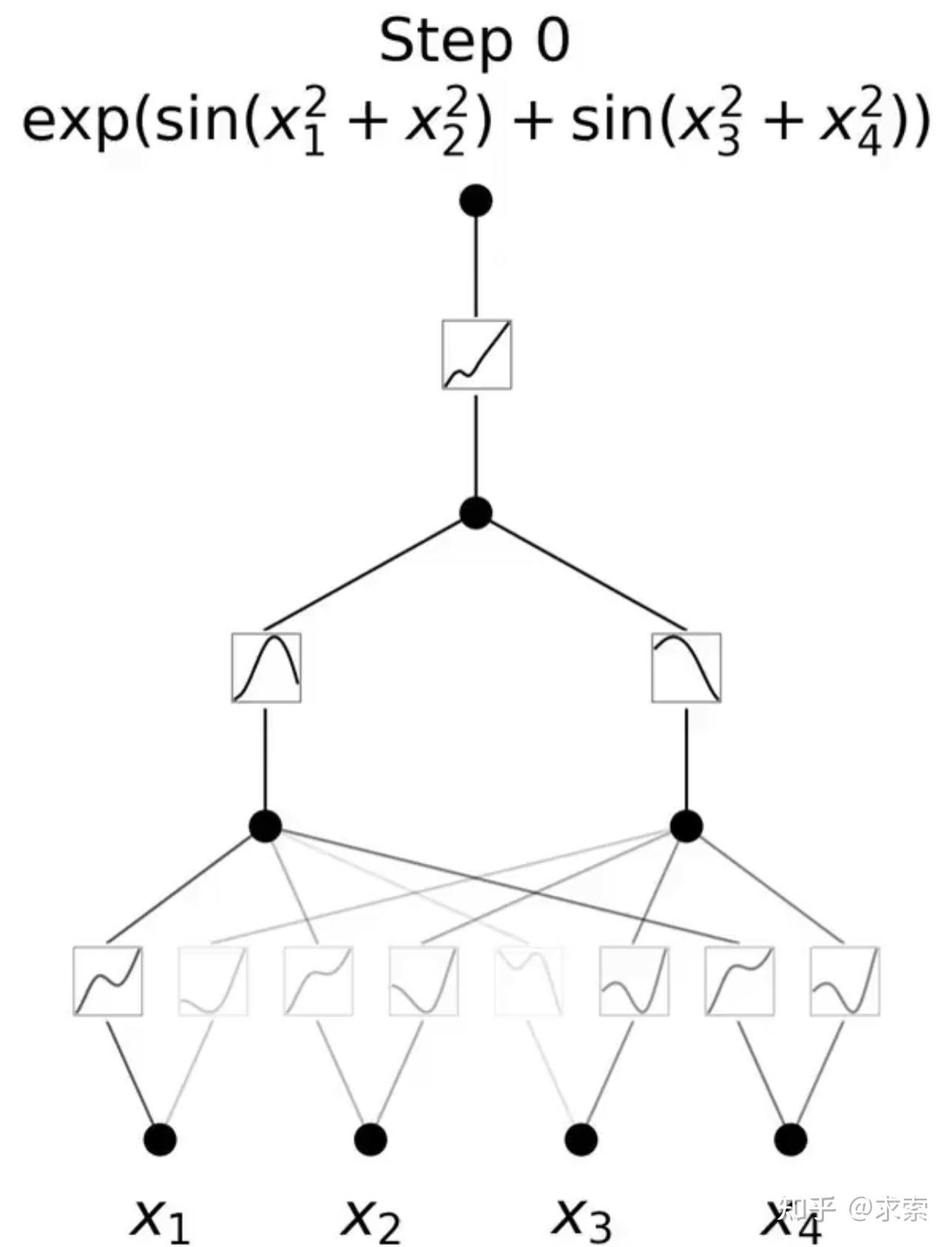
KANs对 MLP 进行简单的更改:将激活函数从节点(神经元)移到边缘(权重)!KANs通过将每个权重参数替换为一个一元函数,利用样条函数来近似这些一元函数。
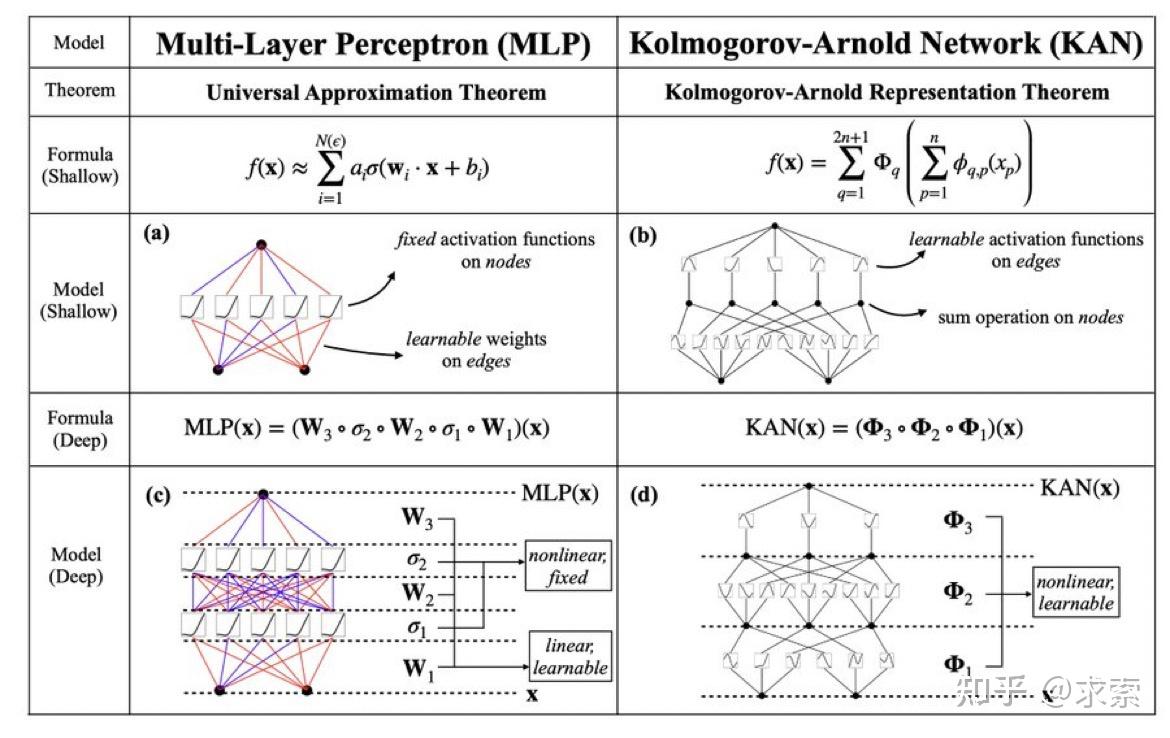
这个变化乍一听似乎有些奇怪,但其实它与数学中的近似理论有着很深的联系。事实证明,Kolmogorov-Arnold 表示对应于 2 层网络,其 (可学习) 激活函数位于边上而不是节点上。
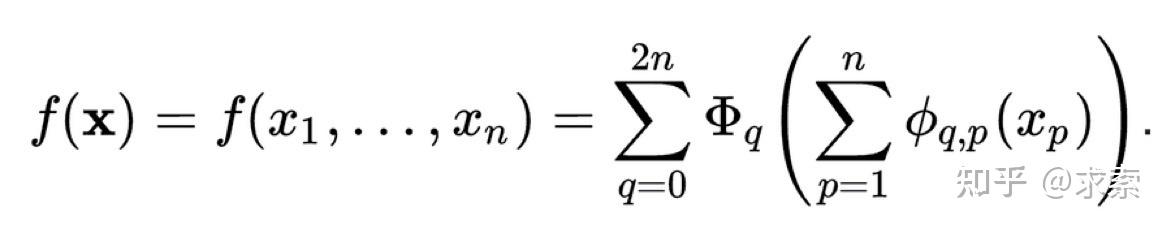
从数学角度来看:MLP 受到通用近似定理 (UAT) 的启发,而 KAN 受到柯尔莫哥洛夫-阿诺德表示定理 (KART) 的启发。网络能否以固定宽度实现无限精度?UAT 的答案是“不”,而 KART 的答案是“可以”(但有警告)。
从算法方面来看:KAN 和 MLP 是双重的,因为-- MLP 对神经元具有(通常固定的)激活函数,而 KAN 对权重具有(可学习的)激活函数。这些 1D 激活函数被参数化为样条函数。
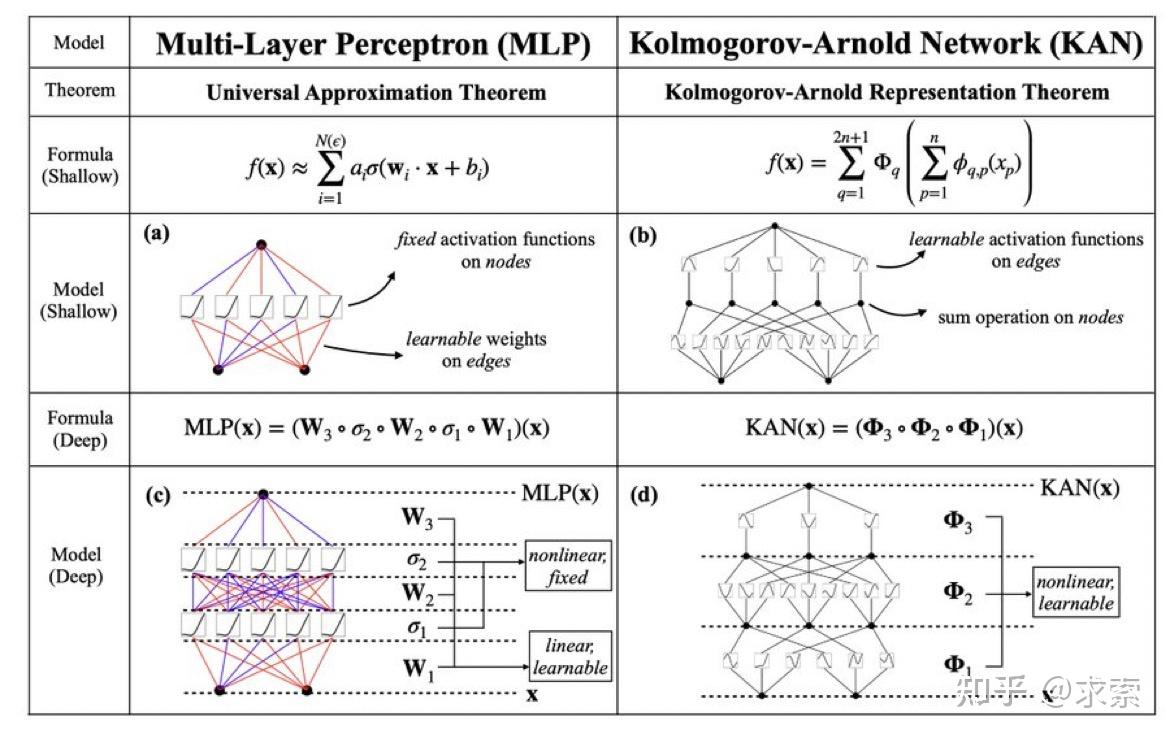
从实际角度来看:作者发现 KAN 比 MLP 更准确、更易于解释,尽管由于 KAN 的激活函数可学习,因此训练速度较慢。
KANs在准确性上超越了MLPs,尤其是在数据拟合和PDE求解任务中,展示了更快的神经缩放法则。
KAN 的缩放速度比 MLP 快得多,这在数学上基于 Kolmogorov-Arnold 表示定理。KAN 的缩放指数也可通过经验获得。
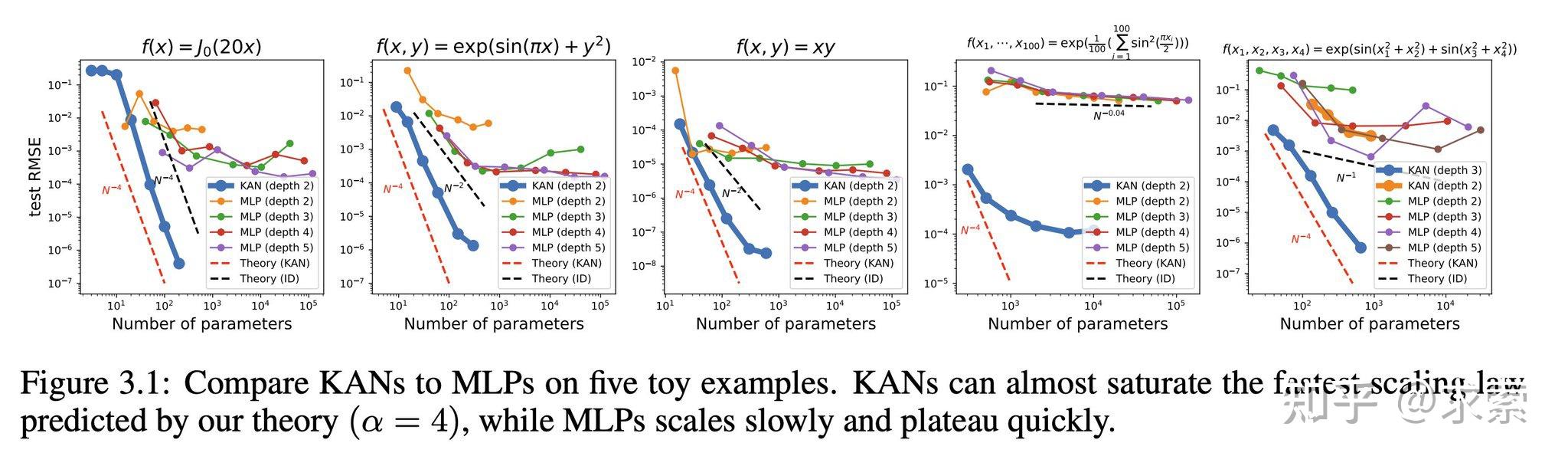
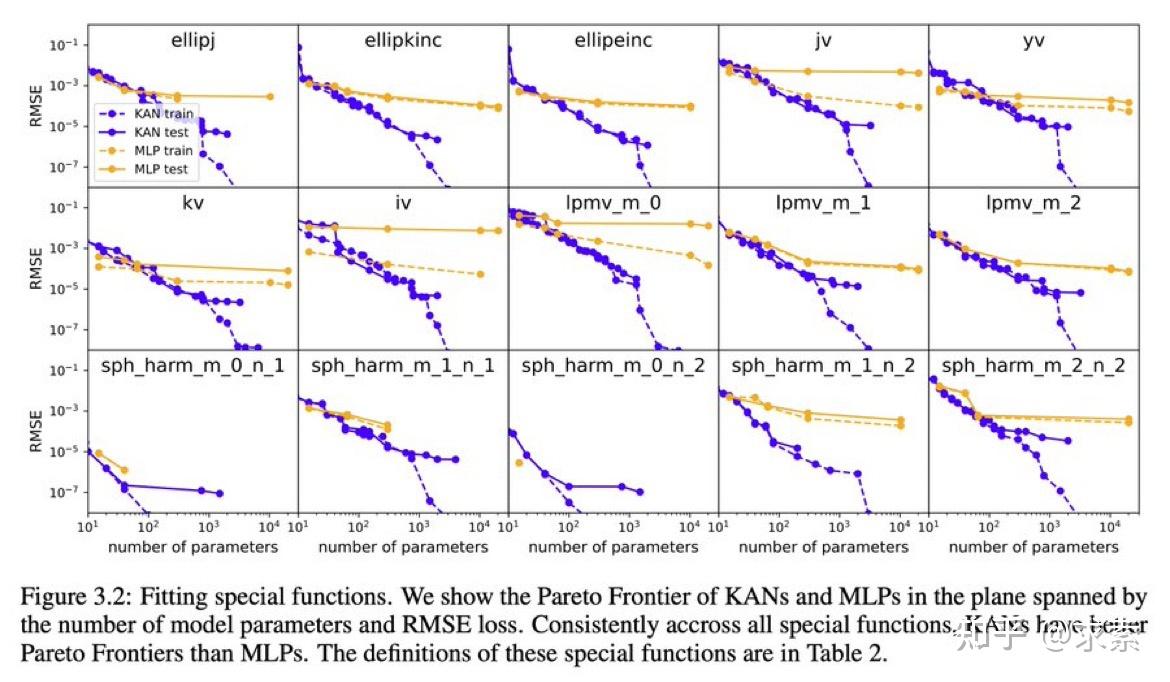
KAN 在函数拟合方面比 MLP 更准确,例如拟合特殊函数。
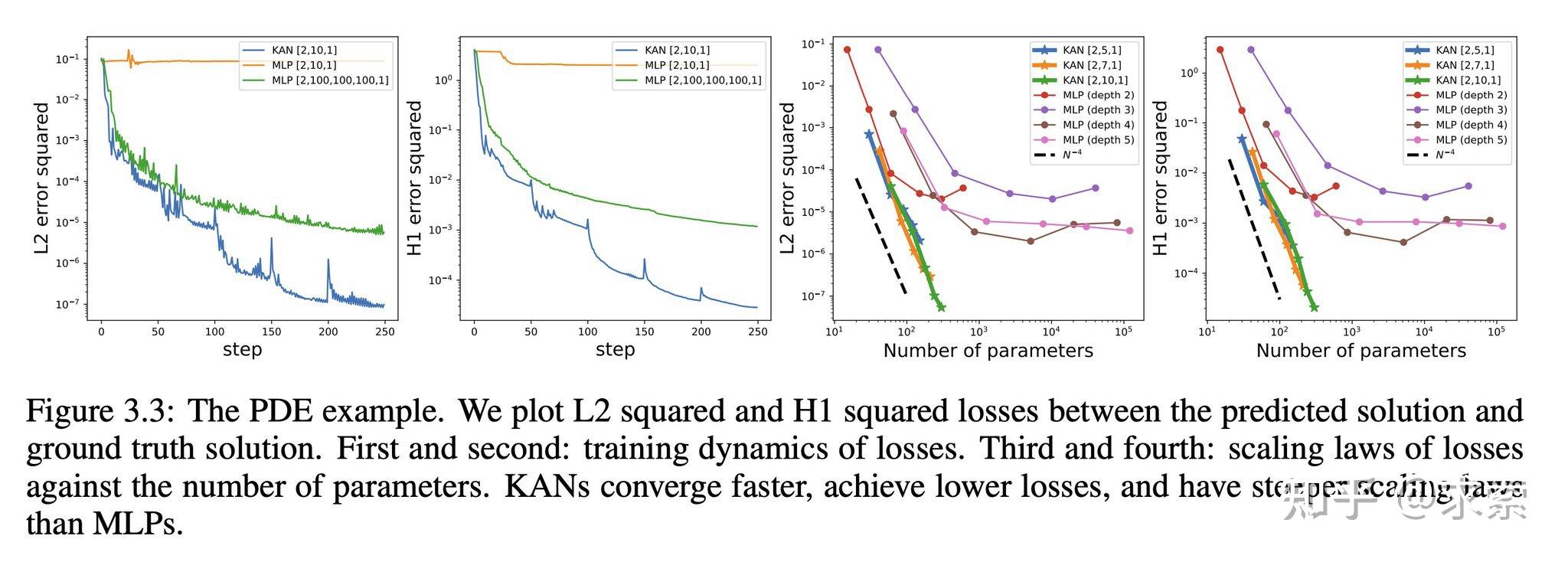
KAN在PDE求解任务上比MLP更快更准确,例如求解泊松方程。
1另外,KAN 具有避免灾难性遗忘的天然能力。
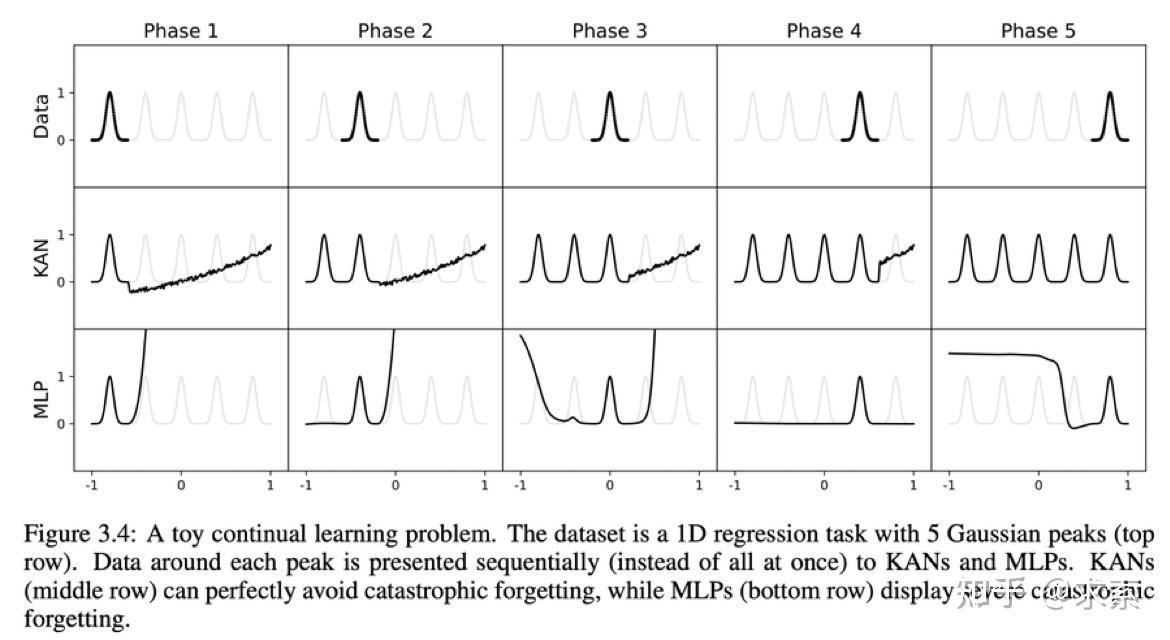
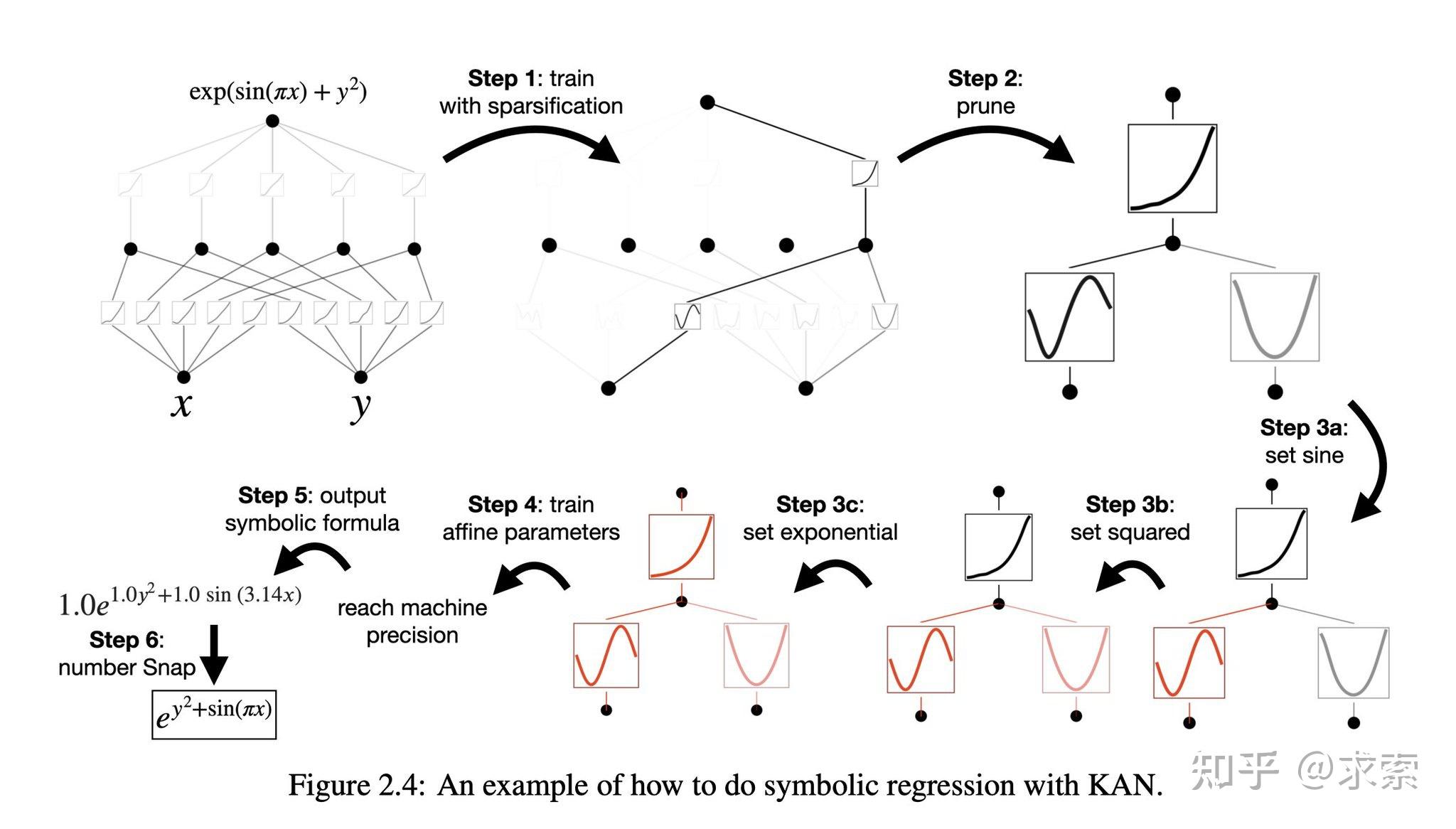
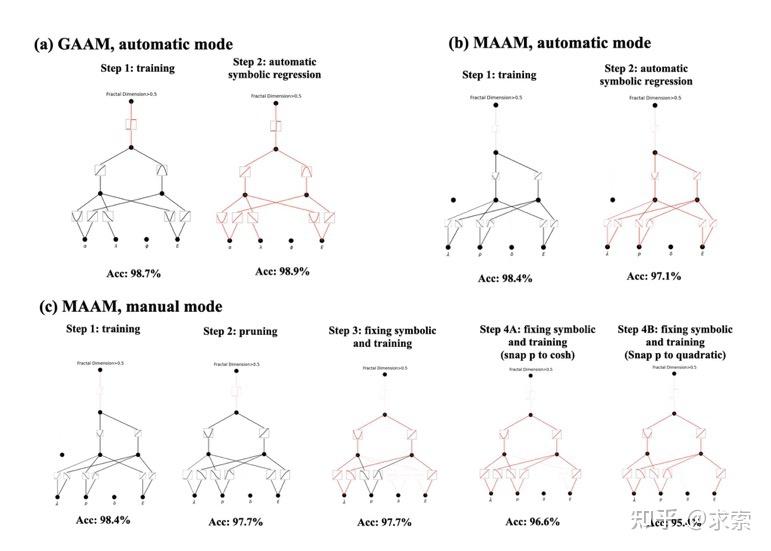
KANs提供了更好的可解释性,使得网络结构和激活函数可以直观地被理解和解释。KAN可以从符号公式中揭示合成数据集的组成结构和可变依赖性。
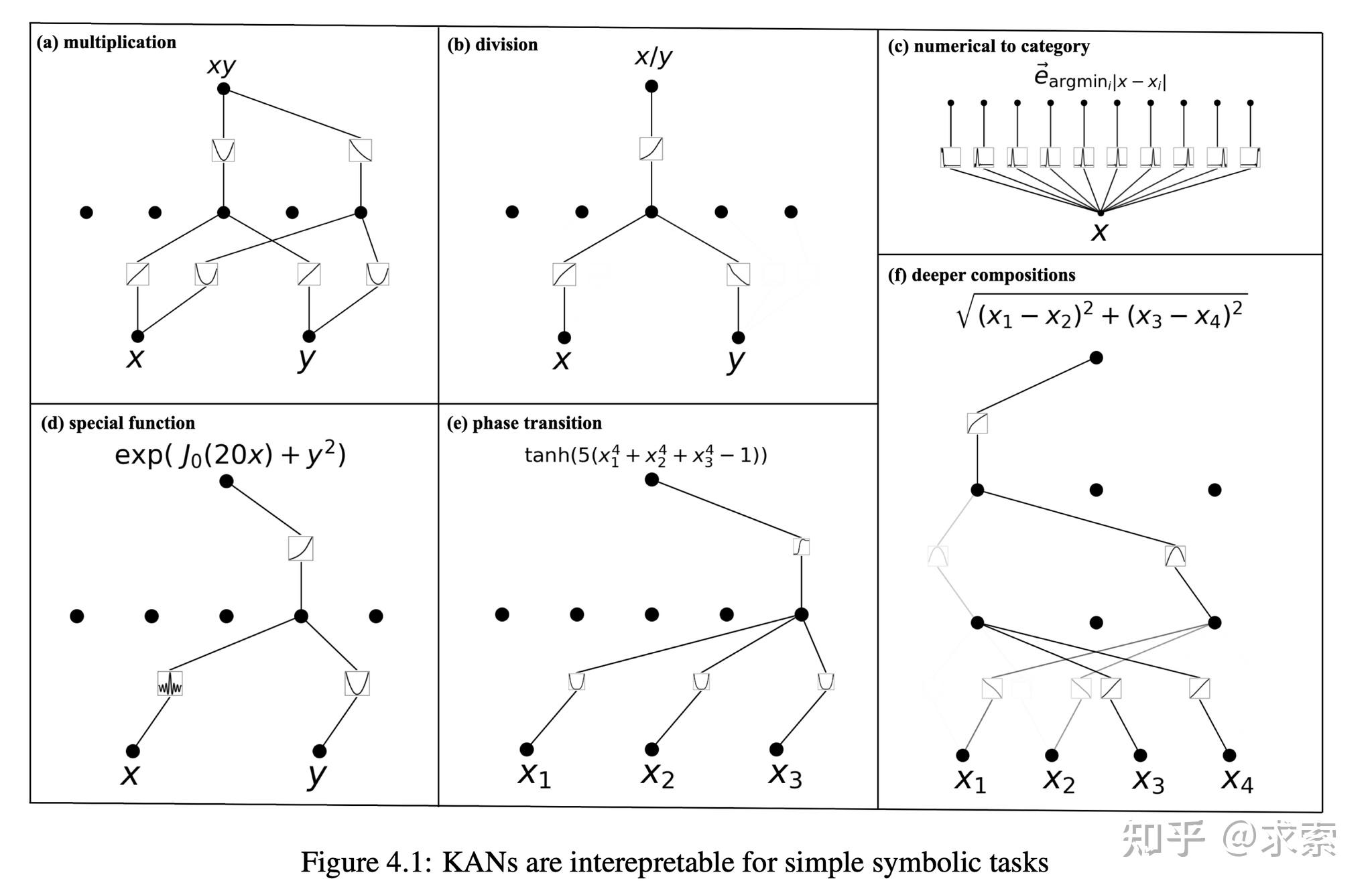
人类用户可以与 KAN 交互,使其更易于解释。将人类的归纳偏见或领域知识注入 KAN 很容易。
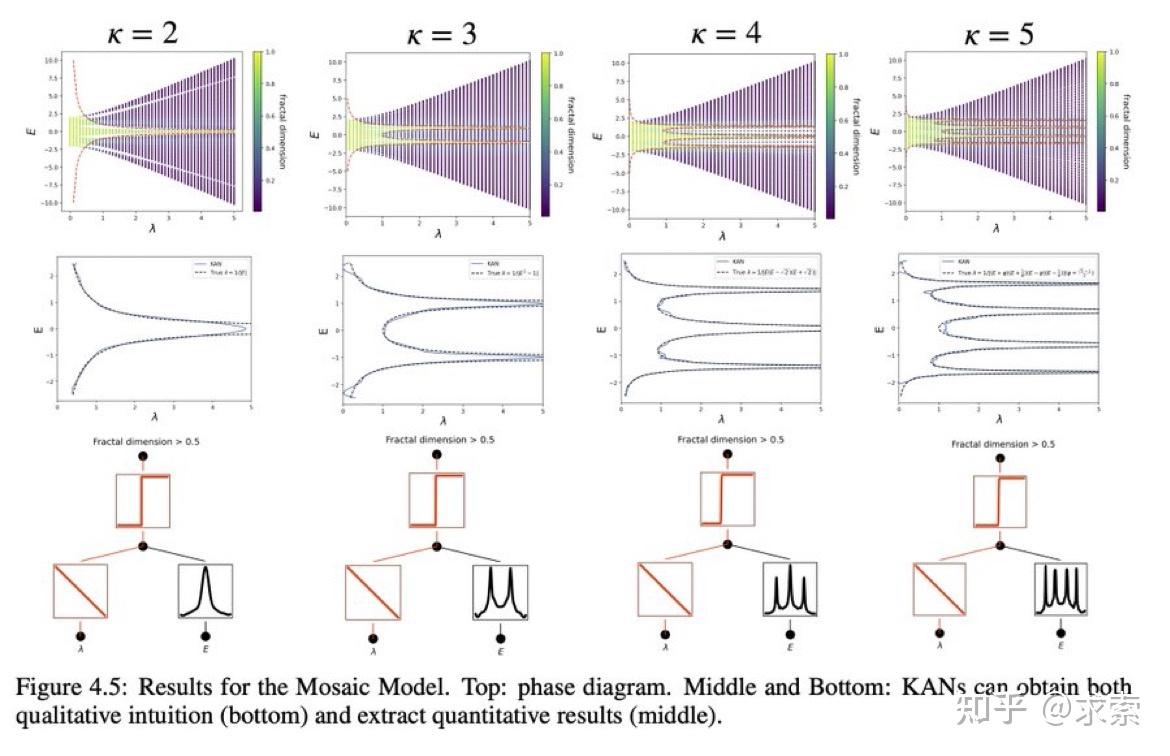
论文还探讨了KANs在科学发现中的潜力,KAN 也是科学家的得力助手或合作者。如在数学的结理论和物理的Anderson局域化中的应用。
利用 KAN 重新发现了结理论中的数学定律。KAN 不仅以更小的网络和更高的自动化程度重现了GoogleDeepmind的结果,还发现了新的签名公式,并以无监督的方式发现了结不变量的新关系。
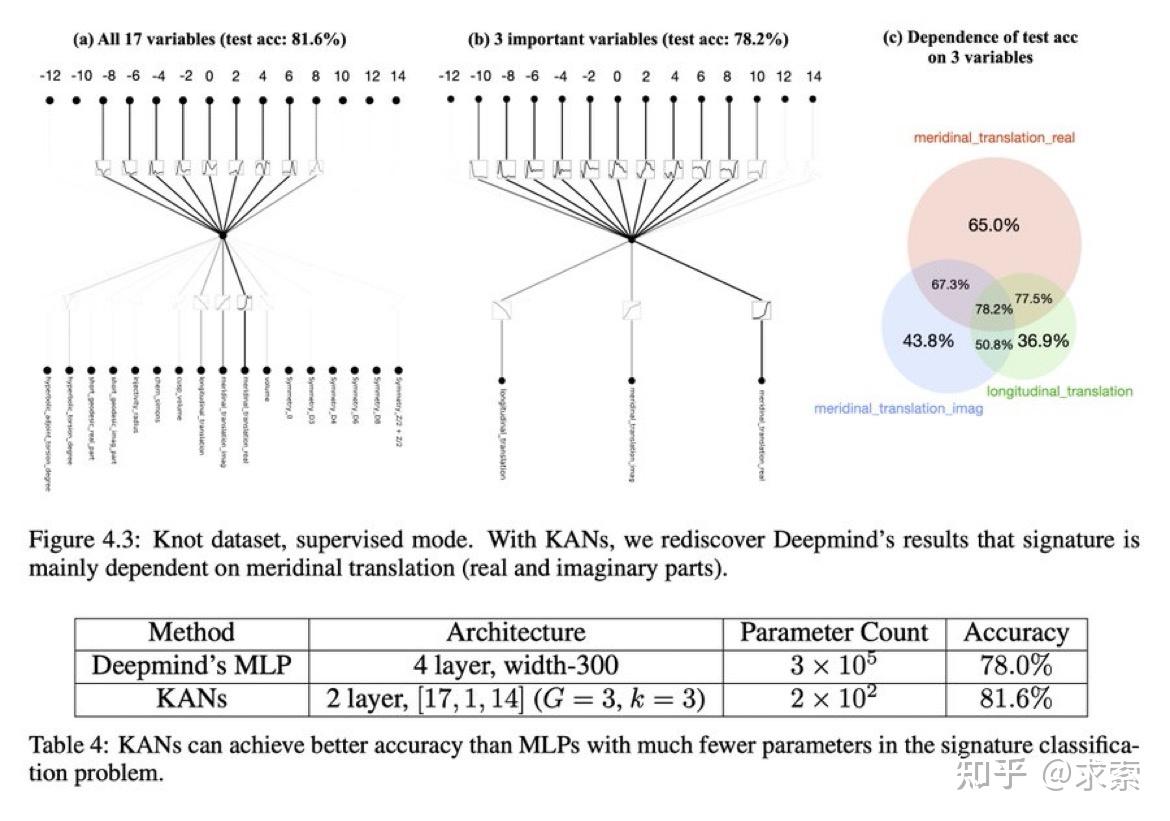
特别是,Deepmind的MLP有~300000个参数,而KAN只有~200个参数。KAN可以立即解释,而MLP需要特征归因作为后期分析。
KAN 可以帮助研究 Anderson 局域化,这是凝聚态物理学中的一种相变。无论是从数值上,还是从物理上,KAN 都使迁移率边缘的提取变得非常简单。

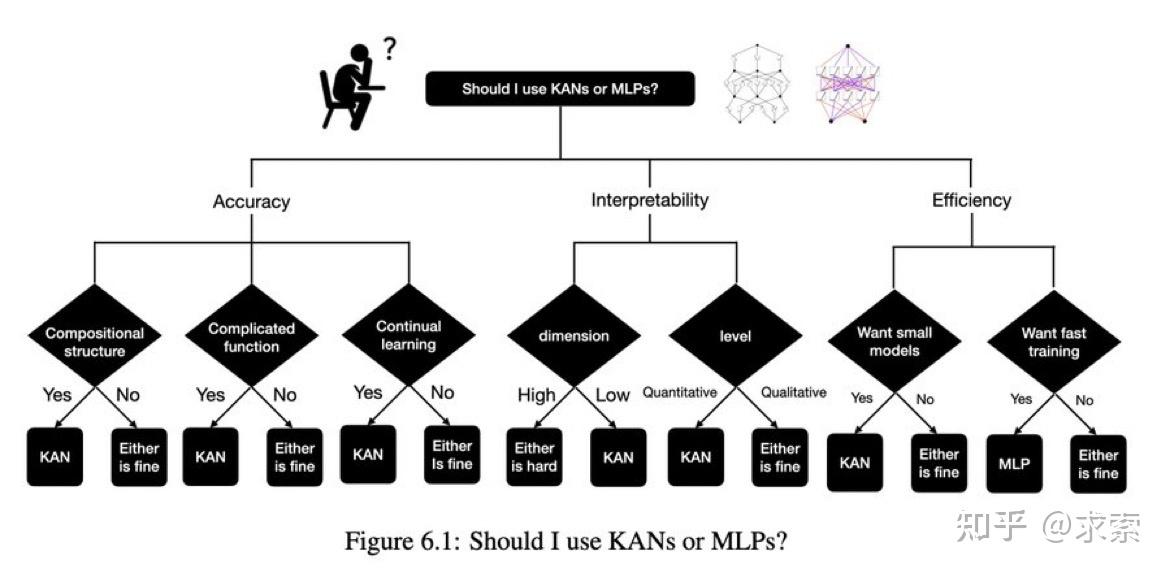
根据实证结果,KAN 将成为 AI + Science 的有用模型/工具,因为它具有准确性、参数效率和可解释性。KAN 对机器学习相关任务的实用性更具推测性,有待未来研究。
论文中的所有示例都可以在单个 CPU 上在不到 10 分钟的时间内重现(扫描超参数除外)。诚然,实验的问题规模比许多机器学习任务要小,但对于与科学相关的任务来说却是典型的。
真的能替代MLP吗?
作者的回应:
感谢大家的欢呼和建设性批评。我写了几段文字来回应最近的 KAN 炒作。简而言之,我认为现在说KAN将取代MLP 还为时过早,但确实有很多有趣的方向值得探索。
为什么训练很慢?
原因 1:技术。可学习激活函数(样条函数)比固定激活函数的评估成本更高。
原因 2:个人原因。研究作者的物理学家性格会抑制程序员性格,所以没有尝试优化效率。
能适适配transformers吗?
研究作者不知道该怎么做,虽然一个简单的(但可能有效!)扩展只是用 KAN 取代 MLP。
paper:https://arxiv.org/abs/2404.19756
code:https://github.com/KindXiaoming/pykan
documentation:https://kindxiaoming.github.io/pykan/