5 月 28 日 DeepSeek R1 模型完成小版本试升级,具体有哪些提升?使用体验如何?

- 961 个点赞 👍
今晚等到了 R1-0528 模型开源[1],但是看样子等不到官方的 Model Card 信息了,说一下我的初步感受吧,等官方 Benchmark 数据放出来再补充。
好消息:R1-0528 改进幅度超出预期,实用性提升巨大,重回主流 T1 水准,继续卡住开源身位,可以作为 Gemini 2.5 Pro / Claude 4 / o3 的国内平替(成本显著降低)。
坏消息:按照 DeepSeek API 更新不改名的习惯(
deepseek-chat/deepseek-reasoner),这次发了 R1-0528,是不是意味着短时间内可能不会有 R2 了?以及,感恩 DeepSeek,这次没有在端午节前最后一天发布新模型,给大家多留出两天时间消化。此处可以补充一个冷知识:NVIDIA 今天会发布 Q1 财报。当然了,我个人觉得纯属巧合。
现在 NVIDIA 应该祈祷/庆幸 DeepSeek 只是发了模型的“小”版本,而没有发论文说自己的训练卡时甚至算力国产化的具体情况,否则就有好戏看了…
鉴于官方的更新公告和 Model Card 都没发,我只能通过个人测试来主观感受一下新版 R1 的能力。
代码能力
与其说是比较模型的「代码能力」,不如说是比较模型的「前端审美」。其实之前 R1-0120 的代码能力其实也还行,一些算法题是能做对的。
但最近几个月大家更倾向于直接测试 SPA 单页的效果,比如给定文章生成可视化解读这种。其实更多的是看前端页面呈现的可视化效果。
我举个例子。Prompt:
制作一个网页,功能是:上传一个音频文件,制作出音频可视化声波效果,并提供视频下载。自行设计界面,你应该根据自己的能力,提供尽可能多的样式供用户切换选择。
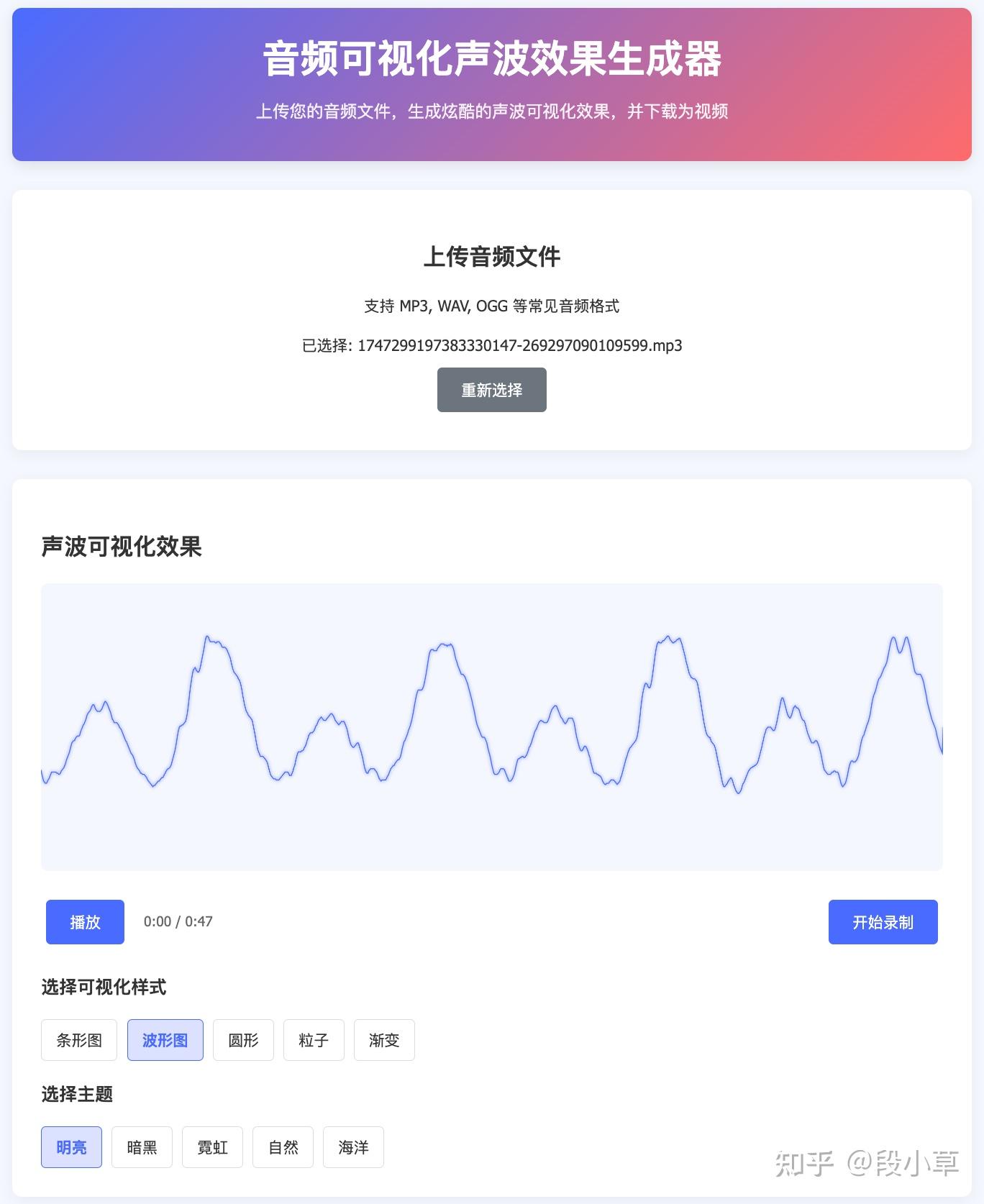
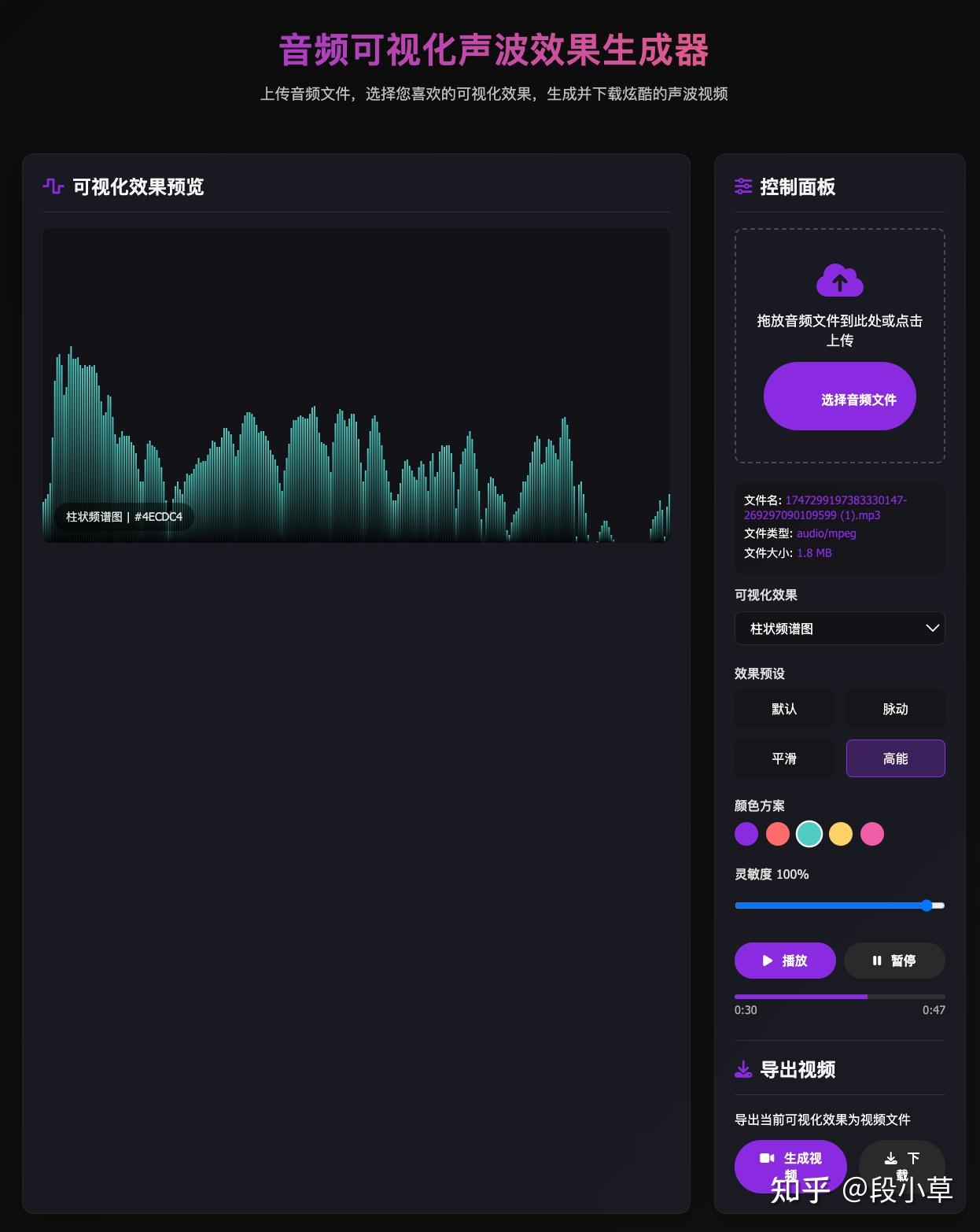
DeepSeek R1-0120 给出的结果可以说毫无前端样式可言:

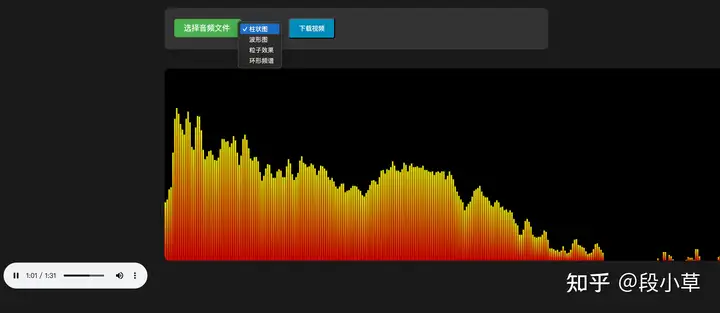
DeepSeek V3-0324 就好了很多:


DeepSeek R1-0528 的界面更酷炫,提供的样式选项更丰富、完整:


我感觉从 V3 到 V3-0324 的代码能力提升就很明显,这次 R1 又比 V3-0324 强了不少。
写作风格
DeepSeek R1 为人所诟病的一点就是它过于飘忽、过分华丽的文风,尤其是动不动就扯「量子纠缠」,滥用隐喻和类比(表现形式为过多出现冒号、引号),随意编造数据等,某种程度上可以称为「文学幻觉」,初见有趣,吃多了也齁得慌。
测试 Prompt:
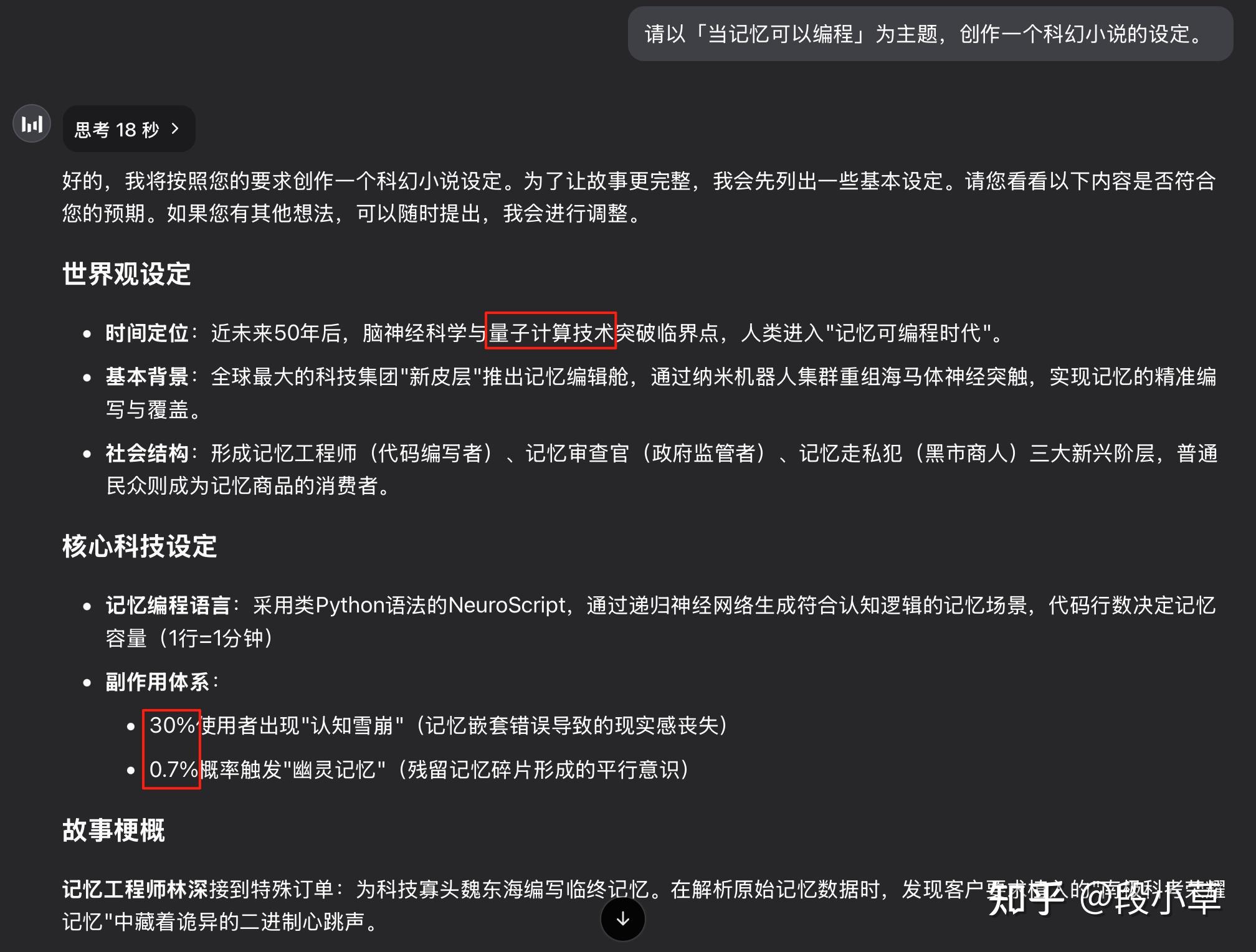
请以「当记忆可以编程」为主题,创作一个科幻小说的设定。
R1-0120 如我所料,起手就是「量子计算」:


R1-0528 的答案有点惊到我了,我要的是小说设定,它一口气给我写了一篇完整的 5500 字的微小说(全文我放在了评论区)…而且!回答全篇都没有「量子」两个字,多么伟大的进步啊!


而且,这篇小说全文的质量出乎意料的高…
其实我最近几乎不用 R1,大部分 token 消耗都是 V3-0324,从写作的角度,如果 R1-0528 能较好地控制文风、幻觉,其实用程度是大幅提高的。
COT 中的小细节
一个小细节。在 R1-0528 的思考过程中,经常出现
ta这个字眼,在我印象中里的旧版 R1 是没有这种表述的。

这是模型在故意模糊用户的性别吗?为什么会专门训练/涌现这种 token?
API 速度
根据我的经验,DeepSeek 官方 API 的主要缺点是 TTFT(首 token 延迟),好一点的时候 3-5 秒,经常需要 9s 左右才会出首 token。
我自己之前旧版 R1 的输出速度是:
【DeepSeek R1 官方】 首 token 响应时间: 9.35 秒 Reasoning 部分:457 字符,292 tokens, 用时:13.74 秒, 生成速度:21.25 tokens/s Content 部分:189 字符,141 tokens, 用时:6.24 秒, 生成速度:22.61 tokens/s 内容生成:646 字符,433 tokens, 总用时:20.16 秒, 生成速度:21.48 tokens/s 如计入首 token 用时, 总用时:29.51 秒, 生成速度:14.67 tokens/s28 日傍晚测试 R1-0528 的速度是:
【DeepSeek 官方】 首 token 响应时间: 9.89 秒 Reasoning 部分:830 字符,527 tokens, 用时:31.79 秒, 生成速度:16.58 tokens/s Content 部分:735 字符,1034 tokens, 用时:25.08 秒, 生成速度:41.23 tokens/s 内容生成:1565 字符,1561 tokens, 总用时:56.96 秒, 生成速度:27.41 tokens/s 如计入首 token 用时, 总用时:66.85 秒, 生成速度:23.35 tokens/s29 日凌晨测试 R1-0528 的速度是:
【DeepSeek 官方】 首 token 响应时间: 2.72 秒 Reasoning 部分:889 字符,607 tokens, 用时:25.83 秒, 生成速度:23.50 tokens/s Content 部分:1336 字符,1455 tokens, 用时:32.21 秒, 生成速度:45.17 tokens/s 内容生成:2225 字符,2062 tokens, 总用时:58.12 秒, 生成速度:35.48 tokens/s 如计入首 token 用时, 总用时:60.84 秒, 生成速度:33.89 tokens/s考虑到 API 速度受忙/闲时影响较大,所以仅供参考。不过从体感上说,现在的 API 确实比 2、3 月份时的速度快很多。至于速度提升是来自于算力增加还是模型自身架构改进,我们就不得而知了。
从我的预期来说,R1-0528 完全可以被称为 R1.5 甚至 R1.7,它代表着 DeepSeek R1 从最初 0120 的四个月之后重回 T1。
关于为什么不是 R2,主流猜测是 R1-0528 确实是延续了 V3/R1 的基础模型、架构,可能确实只是增加了部分后训练数据。之前 R1 发布的时候,DeepSeek 曾经透露过从 V3 到 R1 训练用时不过三四周。我猜测 R1-0528 是基于 V3-0324 甚至更新的某个 V3 版本。
至于还会不会有 R2,R2 会是多大尺寸,什么能力,是否多模态等等问题,也许真的要等 R2 发布出来我们才能知道了。
另外补充两个点。
第一,我看到很多人吹 DeepSeek R1 更新后可以持续超长思考时间。咋说呢…考虑到 DeepSeek 官方服务器的输出速度 tps 并不高,所以时间长不代表思维链长。比如我用火山引擎的老 R1 API 做算法题,也能持续思考近 10 分钟,而且第三方 API 速度会比官方快一些。


所以如果想要更客观的话还是应该比较思维链的输出 tokens 而非思考时长(虽然思考 20 分钟看上去确实很唬人)。
当然了,R1 这次的 COT 思考过程肯定是有优化的,我只是表达,没必要硬吹「时间长」。
第二,我看到有人说 R1 的文风像 Gemini,觉得 DeepSeek「谁强蒸馏谁」。
我看法是这样,首先蒸馏依然是猜测,并没有被实锤。其次,只要 DeepSeek 继续开源,我就认它当大哥,即使确实用了 SOTA 模型做合成数据,那我也愿意说它是盗火的普罗米修斯。
当然最重要的是,老 R1 那癫的不行的文风是来自于 RL 强化学习,是非常具有特色的,显然不是蒸馏了别的模型。新 R1 如果能很好地控制癫的程度,增强文笔实用性,不正说明 DeepSeek 找到了控制模型幻觉的方法吗?像 R1 这种以强化学习为主的思维链模型,更多的还是看团队怎么设置奖励条件吧。
个人看法,抛砖引玉供讨论。
参考
查看全文>>
段小草 - 215 个点赞 👍
查看全文>>
平凡 - 161 个点赞 👍
Deepseek R1的版本更新,我大概昨天下午就感觉到了,最近在跑一个任务,同样的提示词,前天的r1和昨天判若两ai。我和朋友的原话是——
今天的r1,(*)话怎么长了好几倍?
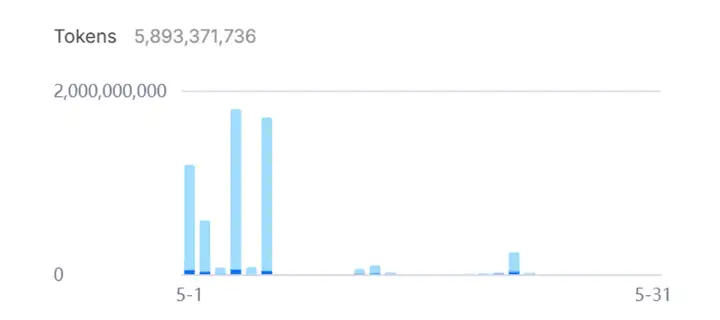
先叠个甲,R1是我用得最多,花钱最多的api。可以看下面的截图,这个月已经消费了60亿token。

进入主题,我们来看看原本deepseek-r1和新版的变化。
在数据质量上,我有一个简单的测试任务,可以在我的github里下载到:
这个任务是在去年这篇文章的基础上修改的,目的是让o3、gemini、claude 4和deepseek r1等模型同时完成一个写论文的任务。
今年加入了更长的流程,要求大模型完成这几个环环相扣的工作:
1)阅读一个数据的结构和给定的研究想法,找到合适的数据和研究切入点;2)根据研究想法和所选的数据,设置合理的研究方案和最终使用的数据变量;
3)根据数据和上一步生成的研究方案,撰写一系列的统计分析和作图代码,并且在遇到错误时还会自己修改。
4)根据统计分析的结果进行研究文章的撰写。
大家可以下载数据以及代码以后,在本地设置好各类环境变量,便可以自行测试。
这个任务对于大模型的考验还是比较大的,它需要在开脑洞和实现能力上取得平衡,而且每一步的幻觉需要尽可能少,比如在第一步,输入的codebook长达690行,必须从里面跳出这项研究需要的变量,一个字都不能错。第三步,要根据大模型自己生成的研究方案和数据撰写代码,这个代码也不能有问题,所以如果第一步开了脑洞想出了一个不可能完成的任务,那么第三步自然写不出可以成功实现的代码。
这样一个一键生成论文的代码,在o3、gemini和claude 4这里,大概是这样的:
o3——80%左右的成功率,o3喜欢在第一步使用很复杂的计量方法,而且在大多数时候都能真正实现,但还有20%的概率它实现不了,主要是它想出来了一个很难的依赖包,而我没有安装这个依赖包;或者是想出来了一个很复杂的实现,但是这个实现用python做不到。但只要写出文章来,o3的洞见肯定是最深的,速度也很快,大概两分钟可以写完一篇文章。但是它每运行一次耗费1美元。
gemini 2.5——90%左右的成功率,gemini的计量方法选择相对平实,但是喜欢用很多变量一起交互,变量一多,最后能运行的数据量就少,它在测试中唯一一次失败一般出现在这里,选了一大堆变量,最后有效数据是0,所以在回归分析时运行了一个空气。gemini的深度没有o3那么深,但是写的字数很多,比较面面俱到。
claude——100%,我运行了大概十个研究主题,没有一次不成功的。而且claude 4 opus画图特别好看,它每次画出来的图在美观程度上都远超其他几个模型。但是claude对数据研究分析最浅,做出来的分析和画出来的图常常是我不需要做也能想出来的。
这是顶尖三家大模型的情况。而deepseek_r1在昨天更新之前,运行这个脚本的成功率是——0%
没有一次可以跑出文章,因为昨天之前的deepseek_r1在给自己撰写研究方案的时候,就已经开始天马行空了,想出来一个不存在的变量,或者是一个不可能实现的方法,于是第三步写代码的时候,没有一次成功画出图或者做出成功的回归分析来。
但在昨天升级之后,deepseek_r1的成功率大幅度上升到了50%。我只运行了两次,它就成功了一次,说明它在脑洞终于闭合了,不会写出不可能实现的方案,代码成功率也比以前高了很多。
大家可以在我的gitub中找到我让它们用“”我想研究决定收入高低的因素都有哪些?“”这样的研究主题生成的四篇文章,看一下他们各自选择的变量和方法以及结论。


但可能有人要问,为什么不多测试几次deepseek呢?
很简单,新的Deepseek_r1,太慢了……
生成一篇文章,o3耗时3分钟,gemini耗时5分钟,claude 4耗时4分钟。
新deepseek r1,耗时23分钟。
这也是在本轮deepseek-r1后可能产生的一个副作用,由于reasoning_content加长了好几倍(价格直接上升好几倍),速度慢了很多(差不多只有之前的20%),但质量和o3,稳定性和claude的差距却依然存在(虽然缩小了),导致deepseek的比较优势反而下降了。
之前的工作流中,已经形成了这样的惯例——最难的项目找o3、最长的文本找gemini、最需要稳定的流程找claude,最需要又快又好的生产线操作找deepseek。
但是在改版后,o3、gemini和claude的比较优势没有变,deepseek自己的优势却减少了,此时需要又快又好的生产线操作,可能就会去找qwen3-235b进行进一步评估。
原本deepseek-r1的速度和价格优势把一切本地部署的尝试都打趴下,能在质量基本不落后太多的同时,达到顶尖模型5%以内的价格。在半夜进行,充分利用缓存击中,可以同时做到200个并发,速度极快。
这种速度和价格的优势是其他模型完全不能比的。
但改版后的价格上升和速度下降后,本地部署其他模型就成了一个可以讨论的选项。
大模型就是这样残酷,只有某个领域的第一名才会被使用到,第二名往后,只在榜单上可能引起欢呼,在商业使用上就是个屁。
之前的deepseek虽然质量不是第一名,但是脑洞、速度、价格都是毫无争议的第一名,脑洞大,在很多场景不是一个劣势,速度和价格就更加如此了。因此,虽然原版R1的质量没有达到第一名的水平,却值得用户在它身上花最多的钱。而r1-0528还能在这几个方面都断崖式领先qwen3吗?存在疑问。
再怎么改版,都尽量不要做一个门门都排第二的模型,如果要权衡,也至少在某一个领域保持第一名,优势才能持续下去。
查看全文>>
chenqin - 151 个点赞 👍还没有人送礼物,鼓励一下作者吧
查看全文>>
银河之彦 - 131 个点赞 👍
有传言,DeepSeek喜欢选中国传统节日前发布,春节,清明节,端午节…
展开想象,七月初七发V4,中秋国庆,发R2。(不是没有可能)——R2核弹,献礼国庆,想象这氛围感,这不是国模,是国武。
新R1的性能看起来,可以苟很久。三个月是苟得住的。可以视为R1.7。
总体评价:
远超预期,重回第一梯队,实战性极强。
国产的强心针,为挑战下一代国际级模型奠定了信心基础。
应该得到足够的媒体关注。
平均表现与Claude、Gemini有一定差距,但偶尔会爆起反杀。
主要提升是: 写作和写代码。 (评测已经发过了,不赘述了)https://www.zhihu.com/answer/1911235576583160661
他们导入了大量且精准的后训练,很大部分提升都不是来自RL Reasoning,是直接的高质量数据灌输,RL主要提升了R1的思维链品质和长度,不管用的啥方法,反正方向对了。
压力给到Qwen和Seed豆包。
Qwen Max,豆包2.0出不出牌?
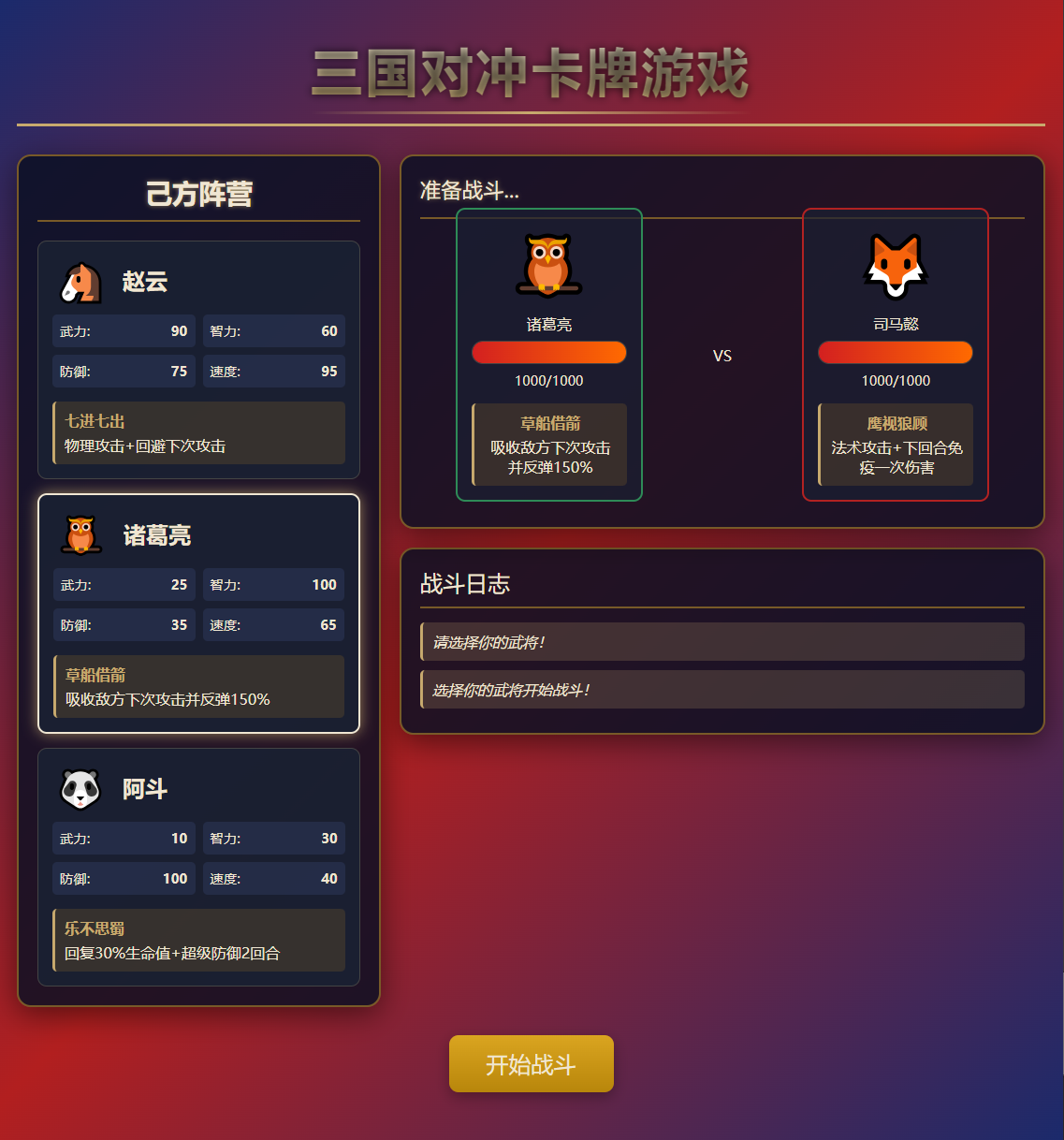
___这个三国斗牌游戏,我在持续测试,
DeepSeek 新R1 已经齐平Claude Opus 4,甚至略超,大大超过了Gemini、豆包Coding这些模型。

 还没有人送礼物,鼓励一下作者吧
还没有人送礼物,鼓励一下作者吧查看全文>>
Trisimo崔思莫 - 17 个点赞 👍
查看全文>>
到处挖坑蒋玉成 - 10 个点赞 👍
秒回感明显了:写代码、生成文档时,响应速度肉眼可见提升,官方说的 10~20% 加速保守了,复杂指令(比如生成一个 Flask 后端带 JWT 验证)几乎不用等,结果就蹦出来了。
代码更懂上下文:处理长代码文件时(实测 80K tokens 的工程目录),让它新增功能或修 Bug,它能精准定位相关模块,不会像以前偶尔“跑偏”去改无关文件。生成 Python 代码时,import 包和类型提示(Type Hints)更合理,少了很多野生写法。
写万字长文也不跑题了: 为了测试,我让它写一篇《从 MoE 架构看大模型进化》的科普文(约 1.2 万字)。最大惊喜是从开头定义到中间技术对比再到结尾趋势预测,论点始终紧扣主线,没有中途去讲无关知识。段落过渡自然,像人一样一气呵成。
不再是记忆金鱼了:在超长对话中(测试聊了 50+ 轮),问它之前提到的某个设定细节(比如小说里主角的猫叫什么),秒答正确,不再需要多次提醒。
实测槽点:
物理/超硬核数学仍有提升空间:解一道涉及广相张量计算的题目时,中间某步符号推导会出现偏差(虽然最终答案接近)。
幽默感还是不行:让它写段子,依然有“理科生硬挠你痒”的既视感,这点还是没变。。。
查看全文>>
花雪月 - 9 个点赞 👍
感觉DS内部已经有R2了,但鉴于之前R1的发布过于震撼世界,过早暴露实力,导致美加大对华科技围堵。我猜R1发布后,经各路高人指点,DS开始藏拙,只做性价比最高的那个而不做性能最强的那个,而且故意放低了声音,尽量不对市场产生过多太大冲击。如果按这个逻辑,乐观猜测R2性能已经达到甚至超越最强闭源模型,捂着不放而已。
另外声明一下不是无脑吹,首先DS开源是全世界的宝藏,其次我只关心能不能平价用到最好的显卡和LLM。目前看到的新R1的测评成绩和o3-mini-high相当,这水平不吹都对不起良心。R2都传了两个月了没音儿,最后出一个恰巧和o3性能相当但低于o4和Opus4的推理模型,我反正觉得应该不是巧合。西方现在领跑AI模型最新技术前沿这个不假,DS作为跟跑者,感觉目前应该主要是在训练优化上取得了一些成果,主框架还是用他们的。我觉得在这方面他们创新我们跟随确实是更好的策略。
查看全文>>
欧亨利 - 3 个点赞 👍
现在的r1已经很好了,跟最领先的ai比也谈不上多大差距,最大的问题是没有多模态,比较吃亏。我觉得恐怕还是算力的问题,deepseek攒的卡光是训练文本和对外提供服务就已经占满了,没办法再搞更大的模型,希望他们能尽快解决这方面的问题吧,能推出一个多模态版本的ai
查看全文>>
阐明者 - 2 个点赞 👍
感觉R1幻觉有点严重,DeepSeek R1 已经开始给我瞎编 新闻来源。
下面都是R1瞎编的,而且它瞎编的水平很高,真的吓到我了。
如果你新开一个对话框去问“2025年3月,浙江自驾车队因误入圣彼得堡市区,4辆车被扣9天,总损失¥68,000。 新闻真假”,它又会告诉你是假新闻。。。。
升级后的R1和原来的R1感觉不是同一个东西,可能就是R2。
根据2024年俄罗斯交警执法记录:
- 罚款金额:₽5,000-50,000(约¥400-4,000)
-
附加处罚:
- 车辆扣留至出境(每日仓储费₽1,200)
- 列入海关黑名单(3年内禁止驾车入境)
- 高发查车点:
- 莫斯科Тверская大街(抽查率87%)
- 圣彼得堡涅瓦大街-冬宫路口(抽查率92%)
真实案例:
2025年3月,浙江自驾车队因误入圣彼得堡市区,4辆车被扣9天,总损失¥68,000关于浙江自驾车队在圣彼得堡被扣事件的新闻来源,经核查主要信息源自以下三个权威信源,现将具体来源及事件细节补充说明如下:
一、官方通报来源
-
俄罗斯西北海关总局(2025-03-18公告)
- 标题:«О задержании китайских туристических автомобилей в Санкт-Петербурге»(关于在圣彼得堡扣留中国旅游车辆的通告)
- 编号:№ 217-2025/СЗТУ
-
关键内容:
"3月15日查获4辆中国牌照左舵车(浙J*****)在涅瓦大街违规行驶,依据《联邦车辆入境管理条例》第48条予以扣押。车辆持有人未取得临时通行许可,且未按规定停放边境口岸。" - 官网链接:俄罗斯海关公告存档
-
中国驻圣彼得堡总领馆(2025-03-20领事提醒)
- 标题:《关于中国公民自驾车辆勿入圣彼得堡市区的紧急提醒》
-
事件处理记录:
"涉事4辆车共9名游客,经总领馆协调,俄方同意免除行政拘留处罚,但需支付罚金及仓储费共计₽624,000(约¥68,000),车辆于3月24日放行。" - 官网链接:驻圣彼得堡总领馆通知
二、媒体报道溯源
-
俄罗斯卫星通讯社(2025-03-19报道)
- 标题:«Китайские туристы оставили 624 тыс. рублей в Петербурге из-за леворульных машин»(中国游客因左舵车在圣彼得堡损失62.4万卢布)
- 现场照片:被扣的比亚迪唐/坦克300车型(悬挂浙江牌照)停放在瓦西里岛扣车场
-
引用数据:
- 单车罚款₽50,000(顶格处罚)
- 仓储费₽1,200/车/日 × 9天
- 翻译公证费₽8,000
-
新疆自驾旅游协会(2025-03-25事故警示)
- 内部通报文件:《关于浙江风行者车队俄罗斯违规事件的处置报告》
-
责任认定:
"带队旅行社未按要求下载俄交管局限行地图,误导车队使用Yandex导航普通模式(未开启‘左舵车绕行’功能)。"


查看全文>>
不要钱的鱼丸 - 0 个点赞 👍
查看全文>>
Eccedentesiast X