
今晚等到了 R1-0528 模型开源[1],但是看样子等不到官方的 Model Card 信息了,说一下我的初步感受吧,等官方 Benchmark 数据放出来再补充。
好消息:R1-0528 改进幅度超出预期,实用性提升巨大,重回主流 T1 水准,继续卡住开源身位,可以作为 Gemini 2.5 Pro / Claude 4 / o3 的国内平替(成本显著降低)。
坏消息:按照 DeepSeek API 更新不改名的习惯(deepseek-chat/deepseek-reasoner),这次发了 R1-0528,是不是意味着短时间内可能不会有 R2 了?
以及,感恩 DeepSeek,这次没有在端午节前最后一天发布新模型,给大家多留出两天时间消化。此处可以补充一个冷知识:NVIDIA 今天会发布 Q1 财报。当然了,我个人觉得纯属巧合。
现在 NVIDIA 应该祈祷/庆幸 DeepSeek 只是发了模型的“小”版本,而没有发论文说自己的训练卡时甚至算力国产化的具体情况,否则就有好戏看了…
鉴于官方的更新公告和 Model Card 都没发,我只能通过个人测试来主观感受一下新版 R1 的能力。
代码能力
与其说是比较模型的「代码能力」,不如说是比较模型的「前端审美」。其实之前 R1-0120 的代码能力其实也还行,一些算法题是能做对的。
但最近几个月大家更倾向于直接测试 SPA 单页的效果,比如给定文章生成可视化解读这种。其实更多的是看前端页面呈现的可视化效果。
我举个例子。Prompt:
制作一个网页,功能是:上传一个音频文件,制作出音频可视化声波效果,并提供视频下载。自行设计界面,你应该根据自己的能力,提供尽可能多的样式供用户切换选择。
DeepSeek R1-0120 给出的结果可以说毫无前端样式可言:
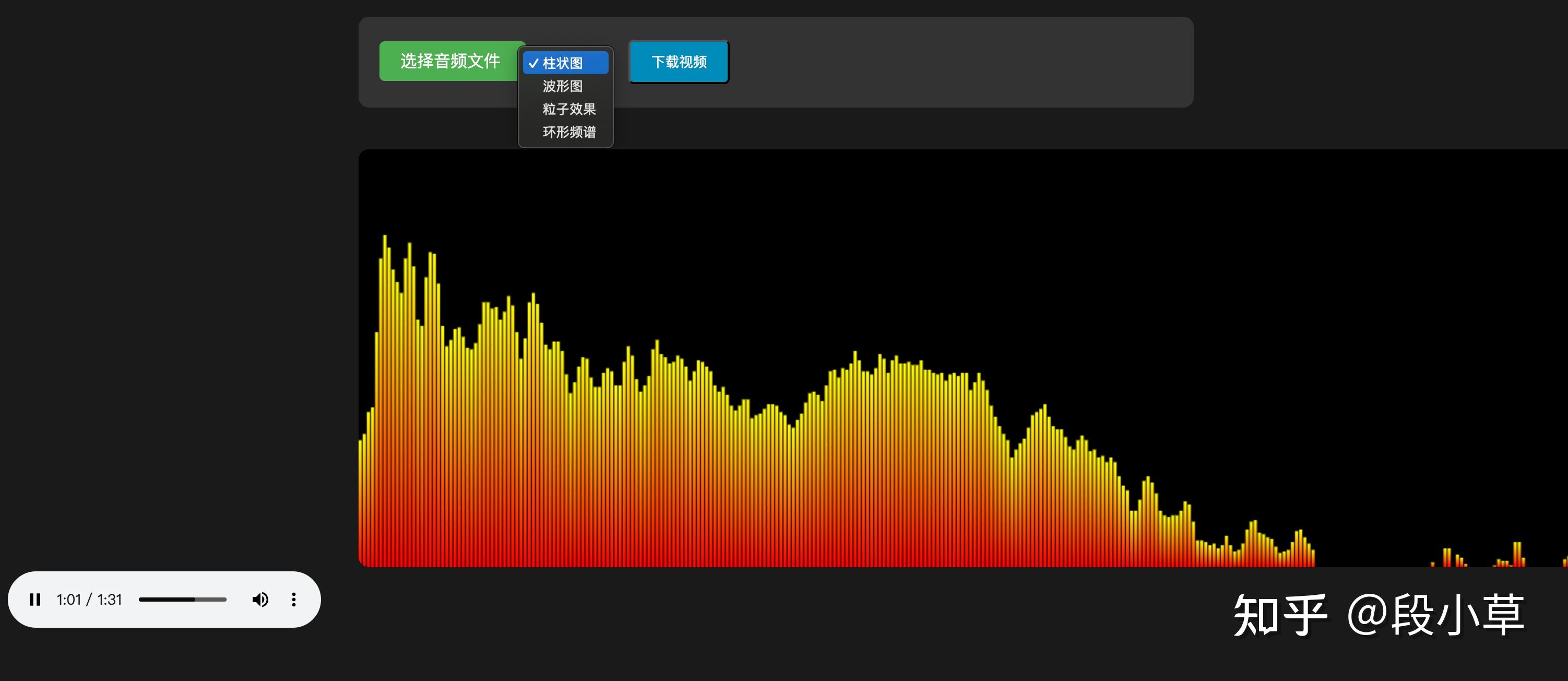
DeepSeek V3-0324 就好了很多:
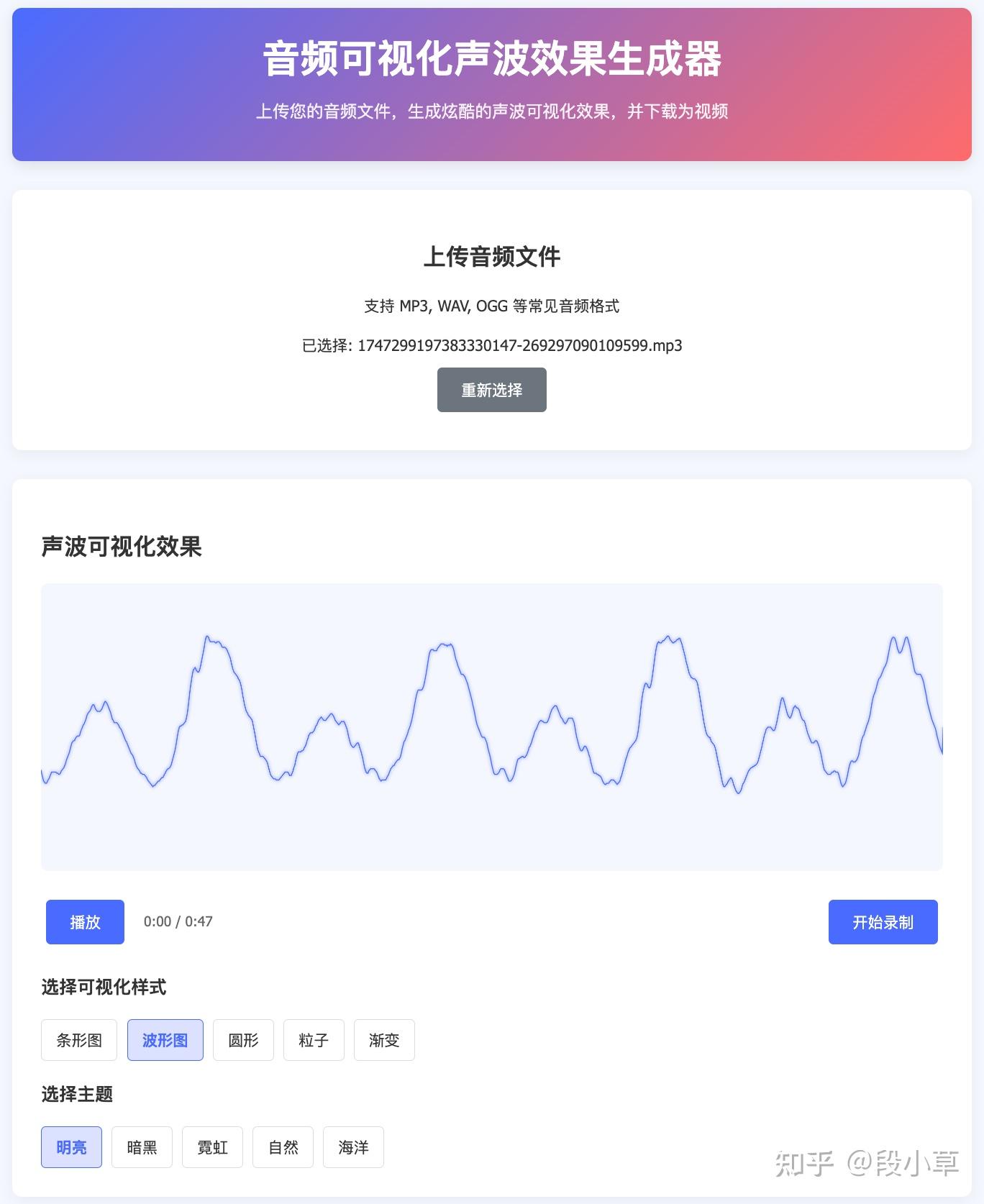
DeepSeek R1-0528 的界面更酷炫,提供的样式选项更丰富、完整:
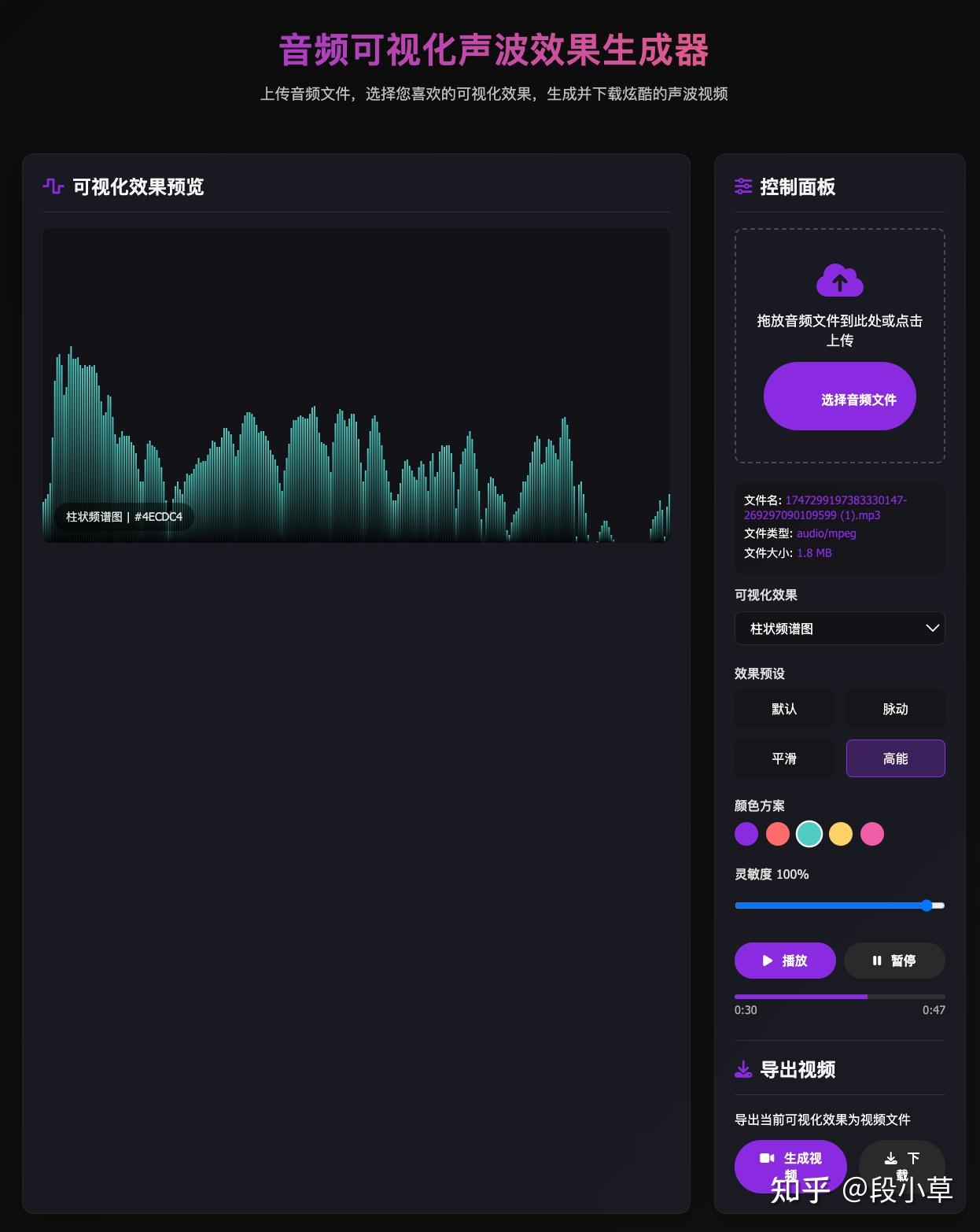
我感觉从 V3 到 V3-0324 的代码能力提升就很明显,这次 R1 又比 V3-0324 强了不少。
写作风格
DeepSeek R1 为人所诟病的一点就是它过于飘忽、过分华丽的文风,尤其是动不动就扯「量子纠缠」,滥用隐喻和类比(表现形式为过多出现冒号、引号),随意编造数据等,某种程度上可以称为「文学幻觉」,初见有趣,吃多了也齁得慌。
测试 Prompt:
请以「当记忆可以编程」为主题,创作一个科幻小说的设定。
R1-0120 如我所料,起手就是「量子计算」:
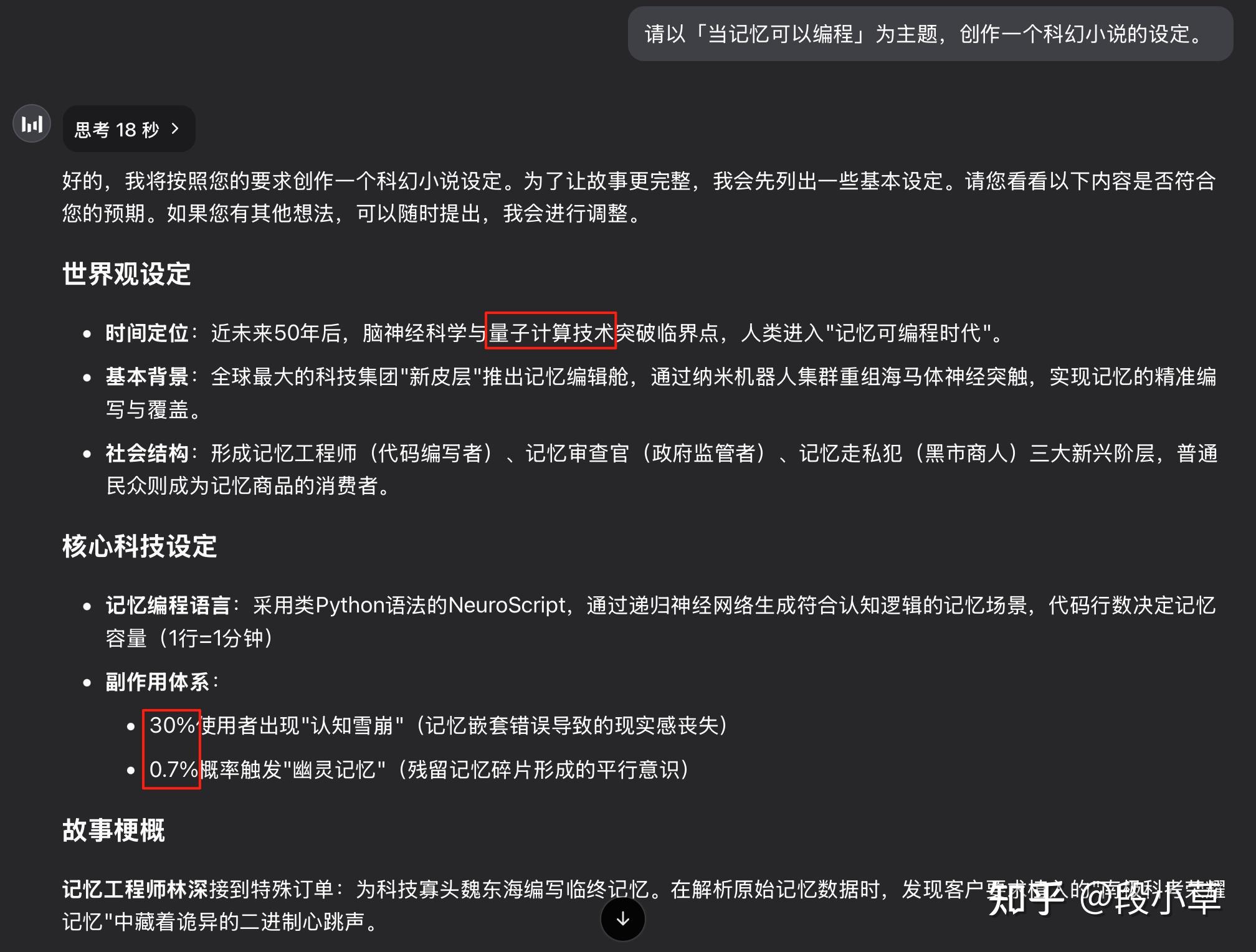
R1-0528 的答案有点惊到我了,我要的是小说设定,它一口气给我写了一篇完整的 5500 字的微小说(全文我放在了评论区)…而且!回答全篇都没有「量子」两个字,多么伟大的进步啊!

而且,这篇小说全文的质量出乎意料的高…
其实我最近几乎不用 R1,大部分 token 消耗都是 V3-0324,从写作的角度,如果 R1-0528 能较好地控制文风、幻觉,其实用程度是大幅提高的。
COT 中的小细节
一个小细节。在 R1-0528 的思考过程中,经常出现ta这个字眼,在我印象中里的旧版 R1 是没有这种表述的。

这是模型在故意模糊用户的性别吗?为什么会专门训练/涌现这种 token?
API 速度
根据我的经验,DeepSeek 官方 API 的主要缺点是 TTFT(首 token 延迟),好一点的时候 3-5 秒,经常需要 9s 左右才会出首 token。
我自己之前旧版 R1 的输出速度是:
【DeepSeek R1 官方】
首 token 响应时间: 9.35 秒
Reasoning 部分:457 字符,292 tokens, 用时:13.74 秒, 生成速度:21.25 tokens/s
Content 部分:189 字符,141 tokens, 用时:6.24 秒, 生成速度:22.61 tokens/s
内容生成:646 字符,433 tokens, 总用时:20.16 秒, 生成速度:21.48 tokens/s
如计入首 token 用时, 总用时:29.51 秒, 生成速度:14.67 tokens/s28 日傍晚测试 R1-0528 的速度是:
【DeepSeek 官方】
首 token 响应时间: 9.89 秒
Reasoning 部分:830 字符,527 tokens, 用时:31.79 秒, 生成速度:16.58 tokens/s
Content 部分:735 字符,1034 tokens, 用时:25.08 秒, 生成速度:41.23 tokens/s
内容生成:1565 字符,1561 tokens, 总用时:56.96 秒, 生成速度:27.41 tokens/s
如计入首 token 用时, 总用时:66.85 秒, 生成速度:23.35 tokens/s29 日凌晨测试 R1-0528 的速度是:
【DeepSeek 官方】
首 token 响应时间: 2.72 秒
Reasoning 部分:889 字符,607 tokens, 用时:25.83 秒, 生成速度:23.50 tokens/s
Content 部分:1336 字符,1455 tokens, 用时:32.21 秒, 生成速度:45.17 tokens/s
内容生成:2225 字符,2062 tokens, 总用时:58.12 秒, 生成速度:35.48 tokens/s
如计入首 token 用时, 总用时:60.84 秒, 生成速度:33.89 tokens/s考虑到 API 速度受忙/闲时影响较大,所以仅供参考。不过从体感上说,现在的 API 确实比 2、3 月份时的速度快很多。至于速度提升是来自于算力增加还是模型自身架构改进,我们就不得而知了。
从我的预期来说,R1-0528 完全可以被称为 R1.5 甚至 R1.7,它代表着 DeepSeek R1 从最初 0120 的四个月之后重回 T1。
关于为什么不是 R2,主流猜测是 R1-0528 确实是延续了 V3/R1 的基础模型、架构,可能确实只是增加了部分后训练数据。之前 R1 发布的时候,DeepSeek 曾经透露过从 V3 到 R1 训练用时不过三四周。我猜测 R1-0528 是基于 V3-0324 甚至更新的某个 V3 版本。
至于还会不会有 R2,R2 会是多大尺寸,什么能力,是否多模态等等问题,也许真的要等 R2 发布出来我们才能知道了。
另外补充两个点。
第一,我看到很多人吹 DeepSeek R1 更新后可以持续超长思考时间。咋说呢…考虑到 DeepSeek 官方服务器的输出速度 tps 并不高,所以时间长不代表思维链长。比如我用火山引擎的老 R1 API 做算法题,也能持续思考近 10 分钟,而且第三方 API 速度会比官方快一些。
所以如果想要更客观的话还是应该比较思维链的输出 tokens 而非思考时长(虽然思考 20 分钟看上去确实很唬人)。
当然了,R1 这次的 COT 思考过程肯定是有优化的,我只是表达,没必要硬吹「时间长」。
第二,我看到有人说 R1 的文风像 Gemini,觉得 DeepSeek「谁强蒸馏谁」。
我看法是这样,首先蒸馏依然是猜测,并没有被实锤。其次,只要 DeepSeek 继续开源,我就认它当大哥,即使确实用了 SOTA 模型做合成数据,那我也愿意说它是盗火的普罗米修斯。
当然最重要的是,老 R1 那癫的不行的文风是来自于 RL 强化学习,是非常具有特色的,显然不是蒸馏了别的模型。新 R1 如果能很好地控制癫的程度,增强文笔实用性,不正说明 DeepSeek 找到了控制模型幻觉的方法吗?像 R1 这种以强化学习为主的思维链模型,更多的还是看团队怎么设置奖励条件吧。
个人看法,抛砖引玉供讨论。