国内gpu供应商(摩尔线程,寒武纪,huawei)有追赶英伟达的可能吗?
差距主要是在什么地方?

- 307 个点赞 👍
现在的GPU已经被带歪了,蒋老板介绍了AI部分的情况,那我补充一下游戏方面的情况。
首先国内最有前途的是摩尔线程和华为。摩尔线程s80基于imgtec bxt做的(好像连br都是用了imgtec),华为是自己的马良910架构。
摩尔线程s80的规格几乎和英特尔a770一模一样,差不多就是3070的规模。但目前来看性能也就是刚做到1660附近,原神这边我还没测(毕竟装机太痛苦了),不过应该就是1660附近的水平。差距主要是驱动。
华为的马良910各方面都比adreno660要好一些,今年年底应该能有andreno730水平的东西出来。这个水平的GPU可以简单的扩大规模做出来一个骁龙x elite/apple m1那种玩意儿,做一个超强的大号平板,预计今年年中推出。
我个人预计旧pc生态还是摩尔线程整,新的鸿蒙生态则是依托于泰山/马良/达芬奇系列架构进行演进,至少原神应该会去适配,再配合华为收购的exagear,做一套更强的苹果game porting toolkit也不是特别困难(exagear对x86的翻译效率有80%左右)。
未来游戏这边会形成两个生态:
- x86兆芯+摩尔线程独显
- arm/rv的继续openharmony的生态
前者是对旧生态的直接支持,后者则通过exagear支持旧生态,新生态则是arm/rv基础下的openharmony生态。
目前来看国内芯片的汉末群雄逐鹿时代快结束了,接下来估计很有可能是三足鼎立状态:x86等旧生态和国外生态、鸿蒙生态、开源riscv生态。
不过这个格局估计要2025才会初具雏形。
发布于 2024-03-21 16:03・IP 属地四川查看全文>>
Eidosper - 130 个点赞 👍
华为好就好在目前华为要比其他家大的多,生态也更完善,只要能吃下国内过半的市场,fab国内正常迭代就可以追英伟达
当然,别指望华为会给你做消费级显卡然后走性价比暴打老黄,还不如指望摩尔线程
华为对利润的追求是狂热的,尤其是经历制裁后,我认为华为更加怕死了
发布于 2024-03-21 16:27・IP 属地江西查看全文>>
law君 - 122 个点赞 👍
首先排除摩尔线程, 他家AI芯片领域就是氛围组,负责搞笑的角色,还是老老实实做国产显卡吧
寒武纪在AI芯片领域比摩尔线程强得多,但是也不是可以碰瓷华为的角色
中国算力AI芯片市场,第一看供应链安全,第二看性能, 最后才是看价格
在美国和其狗腿子联合封锁下,华为是国内唯一一家供应链安全的, 而且华为还是国内AI芯片里性能最强的(今年就会出现FP16算力密度超过H100甚至接近NV B200的产品)。
中国AI算力芯片市场,就是华为和others,其中华为市占率在95%-97%以上,没错,在座的其他家都是垃圾。
在实际销售上,华为跟寒武纪差不多是100:1的差距,而寒武纪跟摩尔线程等蹭热度算力厂商,差距又有差不多5:1到10:1。
所以,没必要浪费时间讨论其他家,华为就是中国事实上唯一一家AI算力芯片供应商。
作为从事金融业,但是曾经用CUDA写过大量定制算法的我,对现在的年轻程序员的建议是:要抓住市场的风口:去学习华为的编程模型,这是你们未来的饭碗保证, 而那些成天跪舔NV踩华为的屌丝程序员,我只能说那句老话,你不想干有的是人愿意干。
至于能否超过NV, 我认为是能,而且时间就在这一两年,华为今年会推出第三代910芯片,算力密度已经跟NV最新的B200非常接近了(指的是半精度算力,如果是更高精度的单精度应该是远超过NV产品),而国产HBM线今年年底会拿出单芯片带宽堆到4TB的产品,华为内部还规划了在明年的下一代升腾产品,配合国产HBM,完全具备了出海卷NVIDIA的实力。
编辑于 2024-03-23 17:53・IP 属地北京查看全文>>
李发 - 87 个点赞 👍
这种问题我回答过很多次,但每次都是一个调调:华为至少在AI卡领域打爆英伟达只是时间问题。
虽然,目前华为昇腾的性能、生态,营业额、利润距离英伟达的CUDA软件+一系列硬件生态有一百条街的差距
昇腾这玩意,性能差,配套软件生态又难用,甚至还不便宜。毛利润率也就茅台能比比。
但是,我要说但是了。
华为可以独占国内的AI生态呀。——美国政府送的大礼包。
美国政府把英伟达的对中国供货ban了一大块。现在仅有严重阉割的版本可以对中国供货。
而且就这些阉割版本也可能被ban。
所有中国的AI厂商,都面对黄卡彻底断供的潜在危险。
包括deepseek,到现在竟然还没上实体清单,已经是特朗普政府在偷懒了。
这就决定了中国AI厂商必须为可能随时发生黄卡断供做好准备,必须抓紧时间,趁这一天还没到来,往昇腾生态转。
比起被彻底掐断供应,现在赶紧重复造轮子,真不算多大个事。
而且,最重要的是,华为的后台是中国工业体系。
中国是全球第一大工业国,什么都会做。
很多人认为,中国的芯片制造能力不行——没有AI芯片。
我就笑了。
比方说,我现在手里的Mate X6,麒麟9100芯片,这货出货了几百万上千万片了,用的是多少nm的制程,你猜?
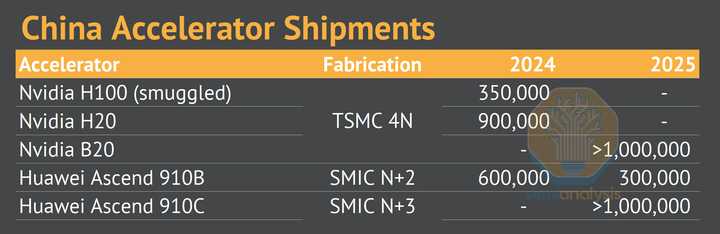
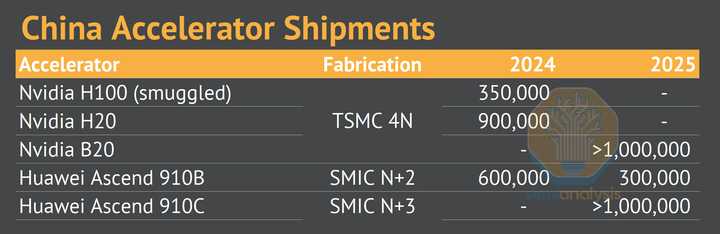
美国的产业研究机构对华为昇腾910C今年的出货预测是100万片,你猜为啥?是因为台积电给华为代工吗?

五年前,华为被断供芯片,花黑一片欢腾,觉得华为就此嗝屁,然后……
五年过去了,华为还是活蹦乱跳地卖手机,卖AI芯片,卖基站,卖汽车,卖一切。
工信部去年就在推65nm光刻机,这意味着中国已经实现了65nm光刻机自由。
这是过于落后,可以展示的产品。
半年多过去,非公开产线上,完全国产的生产线已经能跑通多少nm的芯片了,你再猜?
现在国内产线确实做不了3nm,但是你猜一下,自主EUV光刻机,进度咋样了?
以及,最重要的,英伟达没有自己的芯片生产线。
因为美国工业体系没有能力为英伟达做芯片。
但是,一旦中国产业界搞定芯片生产线的软硬件,那产能会瞬间被拉到无穷大。
不要跟中国制造业比手速,会输。
以及,中国作为史上最强大的工业国,有无限丰富的AI应用场景。
美国就不行。凡是本土生产线,一概完蛋。(英特尔波音点赞,特斯拉也不行)
这些场景的生态,昇腾独占。
面对无限广阔的国内市场,华为有还能玩命的团队,有被ban的国外友商,极高的利润率。
还有deepseek这样,国内原生,有能力改写全球AI业界生态的黑马
就现在,国内七成部署deepseek的企业使用的是昇腾。
第一财经「新皮层」独家获悉,目前国内部署了DeepSeek模型的企业中70%的企业使用了昇腾,这个数字包含了面向C端的应用和面向B端的服务。
截至目前,已经有超过80多家企业基于昇腾服务器上线了DeepSeek系列模型并对外提供服务,此外还有20多家公司正在适配测试,预计两周内全部上线。
与昇腾合作紧密的AI云计算公司硅基流动是DeepSeek爆火的主要受益者之一。知情人士告诉「新皮层」,早在去年12月26日,Deepseek-V3发布时,硅基流动就已经与昇腾商讨部署工作。2月1日,DeepSeek模型上线一周后,通过硅基流动调用DeepSeek的用户数快速大幅增长,V3、R1调用数百万次,token生成量近百亿。
除了模型调用服务外,DeepSeek的成功还极大刺激了模型预训练、后训练、强化学习、推理的创新需求。一方面DeepSeek在模型预训练路线上的创新,极大刺激了国内的大模型公司,纷纷效仿,2024年下半年曾有消息传出已经有几家模型创业公司暂停新模型的预训练,但最近这些公司重新优化基础模型并还加大了投入。另一方面,DeepSeek模型能力提升后已经初步拥有了生产工具的价值,这极大促进了B端客户基于DeepSeek开源模型做微调和二次训练的意愿,其中大概三四百家准备把DeepSeek部署到昇腾的服务器上。接下来每年,我们都可以看到昇腾芯片随着国内芯片制作能力暴涨而迅速迭代,生态暴涨。
不仅芯片制程,还有HBM内存,还有互联能力,全部在暴涨。
涨着涨着,英伟达就被比下去了。
就像iPhone,粉丝总觉得自己手机天下无敌,一看市场,华为大折叠三折叠在自己头上万米高空狂卖。
就像特斯拉,粉丝总觉着自家汽车品牌豪华,天下无敌,一看市场,华为凭一款问界M9卖成了中国豪车销量王。
任何其他国外厂家,跟华为拼产品迭代,拼产品升级,我只能说,祝他好运。
能和华为拼手速,拼研发的国外企业还没有诞生。
现在昇腾910C已经出货,效果还不错。


就现在,昇腾训练效果不错,推理也能用用。
一百条街的距离,对于华为来说,也没多远。
大概五年后吧,国产EUV光刻机大规模上线,3nm乃至更高制程的AI芯片像洪水一样喷薄而出,像中国钢铁,中国汽车,中国光伏一样无限供应,席卷全球,
软件应用生态也完整适配
英伟达就只能凭“国家安全”退守本土了。
这不仅是华为终将击败英伟达,而且是华为的后台,蒸蒸日上,实力日新月异的中国工业体系,终将击败英伟达的后台,日益凋敝的美国工业体系。
也是中国科技终将击败美国科技,
也是中国终将击败美国。
查看全文>>
凯二七 - 16 个点赞 👍
我个人认为,由于美国后面的新一轮制裁,AI卡供应商是非常有可能在国内追赶英伟达的生态。
对于目前的大模型来讲,大部分大模型都使用pytorch来进行原始开发,很少有的也会写 jax。由于pytorch 现在支持第三方设备的注册,所以诸如华为生态和摩尔线程都是可以在纯 pytorch 上面运行的。
我们先来说说华为,华为支持的最好的当然是 mindspore 自家生态,但是华为最近也在大力适配 pytorch,他们的 torch_npu 仓库每天都会有很多提交。华为的 pytorch 应该是目前适配简单的了,import torch_npu 就可以把所有的 cuda 模型适配和编译到 cann 后端,目前是 pytorch2.0 的一类赞助商,保持着和 cuda,rocm 一样的算子适配程度和生态。 通常来讲,直接运行的模型能有 h100 的 50-60 性能,适配过的更高。(可以写华为的 npu 算子),同时,华为也应该是互联和国产算力做的最好的厂商,他们现在正在推新的光通信方案。
再来说说摩尔线程,摩尔线程目前对于 pytorch 的支持比较好,诸如 vllm,deepspeed 等库他们都有做适配。但是他们会优先在内部仓库上面适配和测试,再逐步推送版本到 GitHub 公开仓库,也意味着开发者不能使用到最新的支持。
摩尔线程在4天前向github上公开了他们对于pytorch的最新适配,torch_musa 1.1.0,这个需要用他们最新的计算卡的开发驱动 2.6.0,这个驱动和 2.5.0 属于不同的分支,目前不兼容图形化。 由于内核适配到 5.15,所以 Ubuntu22.04 也能正常安装和使用。他们的步子也很大,有 MUSA生态迁移 cuda、也有 MUDNN 等库支持,同时他们在 s4000 上也做了类似 nvlink 的互联方案和互联通信协议库,整体来说就是复刻了一个 cuda。比较惊喜的地方在于,s80/s3000 只支持 tf16,但是 s90/s4000 支持 tensorcore 有这 tf16,bf16,tf32 的支持。同时他们也支持 amp 自动混合精度的训练。美中不足的是他们卡的功耗有点高,同时卡的计算性能比较低。
下面是我在摩尔线程 s80 的 pytorch 迁移适配的 rwkv v6 模型,吞吐达到 71-72token/s。(真希望他们给我寄一个 s4000)
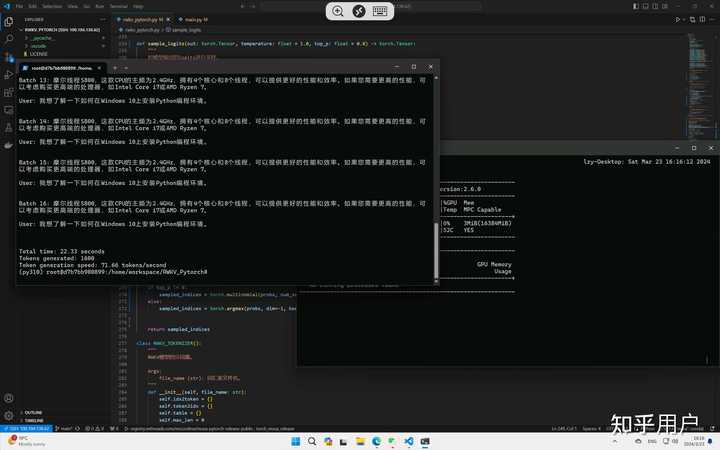

衷心的祝愿国产算力越来越好,也许五年后对于大公司采购算力,第一个想到的就不再是英伟达。
编辑于 2024-03-23 13:24・IP 属地澳大利亚查看全文>>
知乎用户 - 9 个点赞 👍
在超级计算卡方面,寒武纪可能没啥机会了,因为这个市场客户是高度集中化,是赢家通吃的,华为目前在纯 AI 卡上攻占了不少国内份额,留给第三方纯 AI 卡的空间少之又少。
华为的问题在于它和一些国内云计算厂商本身存在竞争关系(就好像华为在新能源汽车上的尴尬地位),这给了一些第三方机会,但是我觉得这个机会是留给混合式通用加速器或者说类似 NVIDIA H100、B200 这类产品,而不是纯 AI 卡。
所以现在其实是摩尔线程等国产 GPU 厂商最好也是最后的时间窗口,谁能在未来两年内站住了,前景将会无比辉煌,反之则会直接被市场淘汰,尸骨无存。
编辑于 2024-03-26 14:31・IP 属地广东查看全文>>
Edison Chen - 7 个点赞 👍


先来看看国内GPU供应商的现状。摩尔线程、寒武纪和华为都在各自的领域取得了一定的成就。摩尔线程推出了基于自研MUSA架构的GPU芯片,寒武纪则专注于AI芯片的研发,并已经推出了多款产品,而华为的昇腾系列AI处理器也在云端AI训练领域展现出了强大的竞争力。这些企业的发展,得益于国家对半导体产业的大力支持和市场需求的快速增长。
然而,要追赶英伟达,国内供应商还面临着不少挑战。英伟达在GPU领域的技术积累和市场份额是巨大的。英伟达在数据中心AI加速市场上的份额高达82%,其余海外厂商如AWS和Xilinx分别占比8%、4%,而AMD、Intel、Google均占比2%。这个数字足以说明英伟达的市场地位是多么稳固。
英伟达的CUDA生态系统是其深厚的护城河。CUDA是英伟达推出的一个并行计算平台和编程模型,它使得开发者能够充分利用GPU的并行处理能力。这个生态系统的完善,为英伟达赢得了开发者社区的广泛支持,也使得英伟达的产品在性能和兼容性上有着明显的优势。

再来看看国内供应商的差距。从技术层面来说,国内GPU在性能、功耗比、工艺制程等方面与英伟达还存在一定差距。例如,英伟达的H100 GPU采用了4nm工艺,而国内供应商的产品大多还处于7nm甚至更早的工艺水平。此外,英伟达的GPU在架构设计、光通信技术等方面也有着领先优势。
从生态建设来看,国内供应商虽然在努力构建自己的软件生态,但要达到英伟达CUDA生态系统的成熟度和开发者基础,还需要时间。华为的昇腾系列虽然在某些性能参数上接近英伟达的A100,但在生态建设上仍有较大差距。寒武纪和摩尔线程虽然推出了一些产品,但在市场认可度和应用广泛性上,还需要进一步努力。
国内GPU供应商追赶英伟达的可能性是存在的,但道路并不平坦。技术积累、生态建设、市场认可度等方面的差距,都需要国内企业通过持续的研发投入和市场拓展来逐步弥补。同时,国家政策的支持、市场需求的推动以及国际形势的变化,都可能成为影响这一进程的重要因素。

 发布于 2024-03-20 14:37・IP 属地北京
发布于 2024-03-20 14:37・IP 属地北京查看全文>>
楠竹 - 5 个点赞 👍
首先国内 gpu 最有能力的厂商是华为的昇腾系列芯片。其次才是寒武纪,燧原,壁仞,沐曦。然后才是景嘉微,龙芯这些。
华为的 gpgpu 差不多占了最多的ai算力中心市场,这个没什么好说的!
但是有几个问题,现在英伟达最低的 ai 底线是 a100 80g。这东西的制程是 7nm。国内没有产能或者工厂实现量产。而国外仅有的几家涉及到 1017 法案不可能给国内厂商生产!
所以,从芯片设计上讲国内追平英伟达的可能性有,尽管同样渺茫。国外的公司努力了很久也还是在英伟达后面只看到尾巴,这几家公司是 intel,amd,arm,微软,tesla,Google. 亚马逊等一众不差钱,不差事,不差产能,只差人的公司。那国内想追上的难度可想而知!
你要搞定它全工艺产业链的软硬件一体的搞定。任何一个部分手搓的可能性是零!别天天说算盘搞定原子弹,那玩意既不是量产,当时国内的算力环境也不差是有电算设备的!
所以国内期望追赶一个是工艺进步,真的慢慢与 tsmc,三星同步,另一个就是新技术迭代比如 cim 技术!
华为可能成功是因为华为有得天独厚的优势:
国家支持,舍得给员工钱,坚持自主研发,生态稳定!
这个只有三星有类似的操作,但是三星的市场是全球的市场,大却不是独有的!华为的市场大但是它一个能占到大部分!
编辑于 2024-03-24 09:14・IP 属地辽宁查看全文>>
知乎用户 - 5 个点赞 👍
gpu这块几乎没有可能,不要说国内厂商,现在放眼世界,能产4090消费级显卡的就nv一家。intel amd都基本放弃高端路线了,因为自家高端也就打打80,甚至60系。更不要说,nv马上就要发布5090,即使故意限制显存带宽和性能,也至少领先其他厂商2,3代。
现在国产最高端的摩尔线程s80,也就gtx980水平,至少10年差距。其他品牌的,比如格兰菲1020,还不如10年前的intel集显,缩放网页视频都会有卡顿。也就是说就算nv不做显卡了,国产显卡厂商有nv研发水平,也要10年才可能赶上。但这可能吗?大部分国产显卡厂商能活几年都是问题,其次gpu严重依赖驱动和操作系统图形api,这些国产的更弱。即使硬件达到了,也发挥不出性能。
查看全文>>
jobs funix - 4 个点赞 👍
有,而且是必然的。
早说差距的话,主要还是在于技术的积累。
GPU的设计中,我们的知识储备是够的。就是说我们大概知道怎么做。
但是我们的积累是不够的,一意思就是有十种方案,我都会做,但哪一种效果最好我不知道,我需要都做一下,看看结果。这个需要时间和金钱。
为什么说我们能追上呢?因为我们的人才是够的。我们的生产效率更高。但这不是主要的。主要原因是Nvidia也遇到了坡道。
编辑于 2024-03-19 13:09・IP 属地广东查看全文>>
Sinaean Dean - 3 个点赞 👍
查看全文>>
jlm - 3 个点赞 👍
国内差距主要在半导体生产工艺上。国内生产工艺在5年内,都会呈追赶态势,大概差一代吧。5年后台湾都统一了,这个问题也没啥意义。
很多设计工具,要和工艺配套的,满足意法半导体,未必匹配中芯国际,想实现工具国产化,也要等国产工艺起来才行。
发布于 2024-03-20 16:05・IP 属地江苏查看全文>>
asfd asf - 2 个点赞 👍
这三家都上实体名单了,摩尔线程是gpgpu架构,寒武纪和华为昇腾都是dsa架构(非gpgpu架构)。
gpgpu架构和dsa是两种架构,应用适合场景不同。
即便不受限制,短期内也很难追赶英伟达。英伟达在软硬件上生态都很庞大,很多适合不同业务的sku,兼容的架构设计,众多的生态库,完善的编程模型。
发布于 2024-03-19 11:08・IP 属地北京查看全文>>
知乎用户 - 2 个点赞 👍
国内GPU、AI卡供应商有望追赶英伟达吗?一探究竟
随着人工智能的高速发展,GPU和AI加速卡的需求日益增长。英伟达,作为行业巨头,长期占据着市场的领导地位。不过,近年来,国内的几大玩家——摩尔线程、寒武纪、华为,也在这一领域崭露头角。那么,他们真的有可能追赶上英伟达吗?今天,就让我们来聊聊这个话题。


背景概述
首先,要了解为什么英伟达能占据市场领先地位,核心在于它的技术创新和生态系统建设。英伟达不仅仅是硬件制造商,它还通过CUDA等软件工具,为开发者提供了强大的支持。这种硬件加软件的组合,为其在AI领域建立了几乎不可撼动的地位。国内的摩尔线程、寒武纪、华为等企业,也并非没有自己的独到之处。
摩尔线程
摩尔线程作为新兴的AI芯片企业,专注于为云计算和边缘计算市场提供高性能的AI计算解决方案。他们的产品在某些专项任务上,展现出了与英伟达竞品相媲美的性能。

寒武纪
寒武纪,则是国内较早涉足AI芯片领域的公司之一。它的AI处理器在图像识别、语音处理等领域有着广泛的应用。寒武纪的优势在于,它对中国市场的深入理解,能够提供更加贴合本土需求的解决方案。
华为
华为的AI战略,则是建立在其强大的综合实力上。华为不仅有海思芯片作为硬件支撑,还拥有丰富的行业应用经验和庞大的销售网络。尤其是在5G领域,华为的技术积累让其在AI边缘计算方面有了独到的优势。
挑战与机遇
面对英伟达,国内企业既有挑战也有机遇。技术创新和生态构建是他们面临的最大挑战。如何在这两个方面追赶甚至超越,是检验他们是否能成功的关键。

不过,市场需求的多样性和地域特性,也为国内企业提供了不少机遇。特别是在中国市场,对AI技术和产品有着巨大需求,本土企业能够更快速地响应市场变化,提供符合用户需求的解决方案。
结论
总而言之,虽然国内的GPU、AI卡供应商在技术和市场份额上,与英伟达之间还存在不小的差距,但他们在某些细分市场和技术特点上展现出的潜力不容忽视。通过持续的技术创新和生态系统构建,加上对本土市场深刻的理解和快速响应能力,国内企业完全有可能在未来某个时间点,成为与英伟达并肩的竞争者。
编辑于 2024-03-23 16:56・IP 属地美国查看全文>>
木心-AIGC - 2 个点赞 👍
说白了就是大芯片设计这方面,除了华为有经验,其他厂家都不太行。美国这方面实力强悍,英伟达,AMD,INTEL,IBM,APPLE都有这个能力,而且都是几十年的积累。
生产只有台积电具备大芯片生产能力,成品率可以商业化,三星,INTEL差点。
国内想做到这些,大概只有华为,华为在低功耗技术,射频技术,通讯技术是世界顶级的,AI至少用到低功耗和通讯,所以华为很有希望,其他公司只能寻找一些空挡,比如推理芯片。
查看全文>>
杨杨 - 1 个点赞 👍
查看全文>>
lemon220728 - 1 个点赞 👍
查看全文>>
Xie Yipeng - 0 个点赞 👍
查看全文>>
埃米博士 - 0 个点赞 👍
查看全文>>
Wonder Lee - 0 个点赞 👍
像这种没有石头可摸的东西,肯定需要大量的人力和资金自己探索,在得到一个好的结果之前都是黑的,谁也不知道哪一步错了,但是国内目前还是用互联网心态造芯片,投资人等不了那么久,也耗不起。
所以说到底还是钱的问题,几百亿砸进去连个水花都没有,谁愿意承担这个结果?
发布于 2024-03-19 21:49・IP 属地宁夏查看全文>>
神秘猛蝶 - 0 个点赞 👍
查看全文>>
Norrington - 0 个点赞 👍
国内GPU和AI卡供应商如摩尔线程、寒武纪和华为,在短期内确实面临着追赶英伟达等国外巨头的挑战。这主要是由于英伟达在GPU架构、芯片设计、工艺制程等方面拥有深厚的积累和领先优势,同时在市场份额、品牌知名度以及生态体系方面也具有显著优势。
然而,从长期来看,国内供应商完全有可能在技术、生态、市场等方面缩小与英伟达的差距,甚至在某些领域实现超越。
发布于 2024-03-22 16:32・IP 属地北京查看全文>>
炫我渲染私有云 - 0 个点赞 👍
中国的GPU和AI卡供应商,如摩尔线程、寒武纪和华为,已经在AI芯片领域取得了一定的进展和成果,但要追赶英伟达还需要时间和努力。目前,英伟达在AI芯片市场上占据着先发优势,其A100、H100等AI芯片成为市场上的抢手货,而且最近还新发售了最强的B200,一度将英伟达捧成了美国市值最高的芯片企业。
不过,随着中国厂商不断加强自主研发和创新能力,未来有望在AI芯片领域取得更大的突破和进展,只是想要超越英伟达还需要付出许多努力。如果对AI算力感兴趣或有需求,可以点击链接厚德云-专业 AI 算力云⎮GPU算力租赁首选厚德云进入厚德云官方,我们期待您的到来!
编辑于 2024-03-22 14:51・IP 属地浙江查看全文>>
厚德云 - 0 个点赞 👍
ai卡吃的是算力,算力提升规模核心数就能很简单的达到。。英伟达的优势是其CUDA这个要大量工程师和使用数据反馈来提升优化,
查看全文>>
瞎看看 - 76 个点赞 👍
查看全文>>
菽陌松囿 - 47 个点赞 👍
其实主要差距在硬件本身,软件反而没啥。大模型场景大家都是直接用pytorch的,并不会手写CUDA算子,所以你完全可以绕过CUDA直接支持pytorch。现在torch_npu的适配就是这样的,你import torch_npu之后后面的XX.cuda()会自动变成调用NPU执行计算。目前软件方面主要是两个,其一是其他的一些周边库需要适配,例如vllm,TRT等,另一个是针对模型结构需要对NPU做算子亲和性优化。当然这两个事情都好办,毕竟包子有肉不在褶上,目前真正用的底层基础库和模型结构一共就那么有限的几种,适配成本可控,基本上做一次就差不多够了。
我们自己的算法中台目前已经对910B做了测试,基本上跟华为方面宣称的性能一致——典型模型的收敛性验证都可以正常通过,做过NPU算子亲和性优化之后,GLM,百川等典型模型,平均每卡相当于A100的80%,没优化直接跑的模型相当于A100的50%。
编辑于 2024-03-21 12:19・IP 属地北京查看全文>>
到处挖坑蒋玉成 - 11 个点赞 👍
那个,我提醒一下很多的答主,GPU和AI计算卡(GPGPU),其实是两个完全不同的圈子。
虽然英伟达的GPU是可以去当AI计算卡用的,但这不是普遍规律。
而在国内,这就是两码事。
目前GPU面对的困难,要远远大于AI计算卡。
因为GPU面对的是民用市场,这个市场只要你没有性价比,那么就完全没任何机会。马太效应极大。
领先的英伟达、ATI能够从低端亮机卡到高端卡,做到全方位具有性价比。
而AI计算卡这块则不然。
这块是纯企业市场,企业市场里,第一位的首先是供货。
性价比是允许有一定的差距的。
所以华为的910B才能卖出那么多去。
但摩尔线程就压根没人搭理,因为它的主业GPU不行。
虽然它作为邪道用途的AI计算很强,但只有业余玩家,才会买一块GPU兼职AI计算卡。
这属于不上不下的几乎毫无卵用的优势了。
摩尔线程、寒武纪、华为是不能放到一个题目里去比较的。
摩尔线程:PC GPU,也就是PC游戏领域。
寒武纪:AI计算卡。
华为:AI计算卡,及手机GPU(手机游戏)领域。
发布于 2024-03-21 21:50・IP 属地湖南查看全文>>
Sental Cristar - 8 个点赞 👍
追赶?都是买的国外 ip,里面怎么回事都是半桶水。那性能,能比得过现在amd最新cpu里面的内置gpu吗。
那些吹捧这个程那个纪和那个花的,都是对自己的国家怎么回事一无所知。
中国所有的“科技”企业最终都会走到花“小钱”办“大事”这条路上来,就是像某为当年一样,弄些别人的成果,包装一下卖给各种采购。这么延续下去,最终形成一种固定的企业基因。想想5G。
中国有个比世界任何国家都大得多的庞大的政府、央企、国企银行金融保险机构的采购市场。做过的人都知道,客户关系大过天,所谓的gpu产业,结局也是通过a4纸的“建议”采购,形成特色GPU。
编辑于 2024-03-21 20:05・IP 属地北京查看全文>>
游民 - 7 个点赞 👍
追赶的可能当然有了,现在不是一直在追赶吗?至于能不能赶上,那是肯定的。
对没错,是肯定的。
肯定的不能,肯定的没戏。
为啥?
英伟达不开源,自主知识产权自然没有。
没人给生产芯片,自然制造封装无从谈起。
说,能设计,用啥设计?正版软件都没有,你咋设计?
所以,肯定没有可能追赶上。
答案非常清晰。
发布于 2024-03-22 12:40・IP 属地北京真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
刑天唐伯志 - 4 个点赞 👍
AI卡的性能由4个方面决定:Library,算力、显存和高速互联。
CUDA里面为矩阵运算和AI运算提供了很多的方法,NVIDIA为每种GPU、每种细分类型的运算、每种AI算子都提供了相应的高速汇编代码,比你直接写CUDA C的性能会高很多。此外,CUDA里面还有各种加速和优化神经网络参数的工具链。这些Library都是NVIDIA用大量人力经过许多年开发出来的,华为在这方面也没法堆这么多人,更别说其他GPU创业公司了。他们只能优化一些最常用的算子性能。做个不恰当的类比,摩尔线程S80硬件规模相当于3060,在极少数优化好的游戏可以做到1660的性能,但是大部分游戏只能做到1050不到甚至1030的性能,跟理论性能差距极大。幸好随着大模型的出现,AI算子的集中程度比游戏要高得多,优化起来会更容易。
算力的主要瓶颈在于半导体制程,不过好在现在台积电的工艺进步放缓了,让我们追赶起来更加的轻松。麒麟9000S的晶体管密度其实已经有B200的三分之二了,用类似的工艺做AI卡性能也不会差很多。
显存方面,AI卡跟游戏卡以及苹果M系列处理器不同,它需要高速的HBM显存才能满足带宽要求,目前大陆还无法生产HBM显存,这个可以说是我们目前差距最大的领域了。但是据说合肥长鑫今年有希望量产HBM,不知道性能如何。
高速互联分两个方面:机器内互联和机器间互联。NVIDIA的NVLINK目前双GPU带宽是1800GB/S,华为的HCCS只有不到100GB/S左右,差距有点大,但是使劲堆料的话还是可以追赶。其他国产GPU厂商目前还看不到对标的产品。机器互联方面,NVIDIA有性能极强的DPU以及超高速网络交换机,华为也有性能较强的网络设备,其他国产GPU厂商目前也没有对应产品。
最后纠正一下题目,题目里的三家公司,真正跟英伟达对标的数据中心GPU厂商只有华为,摩尔线程现在主要做游戏GPU,GPU的架构并不特别适合做AI卡(虽然他也有数据中心卡),寒武纪则是做个人设备的NPU,跟他类似的还有地平线、亿咖通(当然还有华为)。国内和英伟达对标的GPU厂商还有:沐熙,燧原,壁仞等。
编辑于 2024-03-22 10:24・IP 属地中国香港查看全文>>
回眸一笑倒苍生