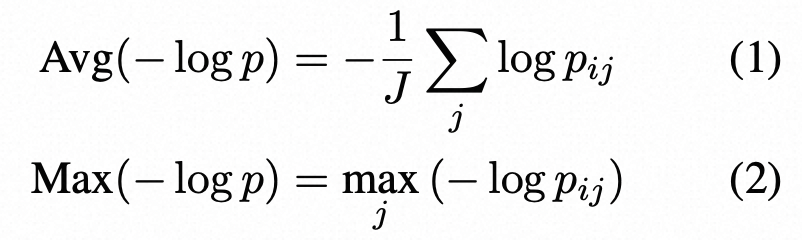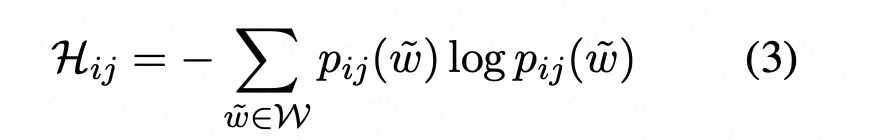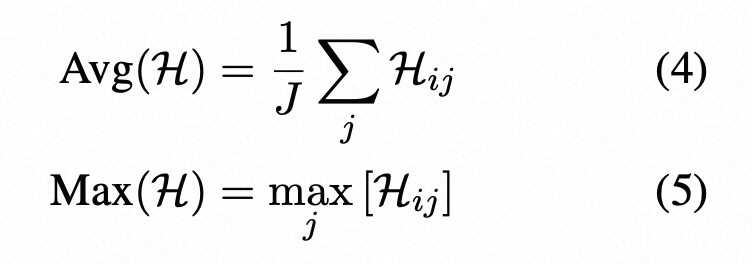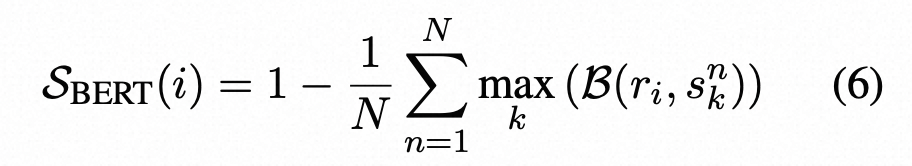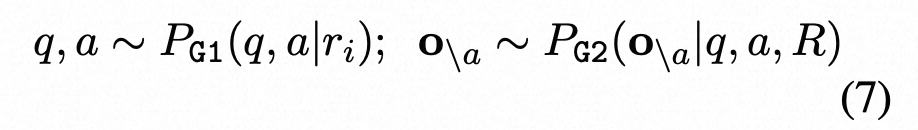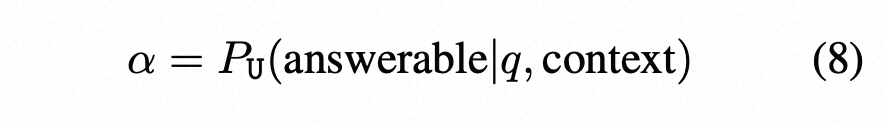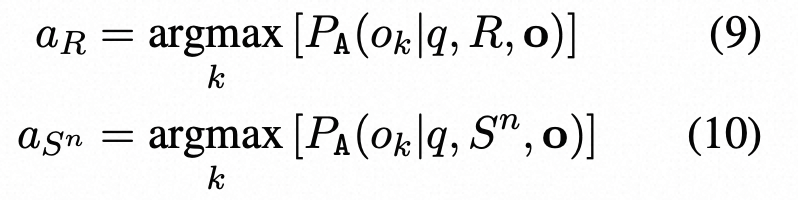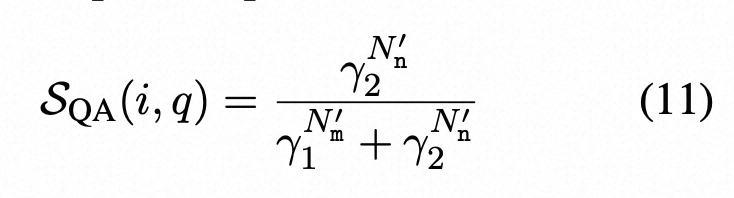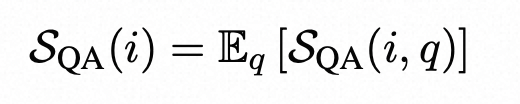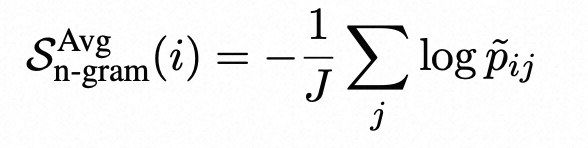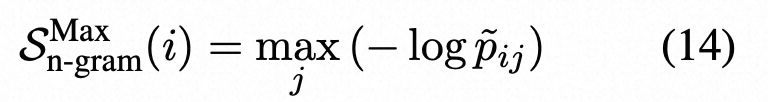如何解决LLM大语言模型的幻觉问题?

- 27 个点赞 👍
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
2023-05-08
https://arxiv.org/abs/2303.08896
作者认为传统的幻觉检测方法在当今LLM时代有如下的缺陷:
- 基于不确定度指标:这一类方法通过衡量LLM回复的熵/概率,来判断LLM对回复是否自信,越不自信越可能是编造的内容。但是该方法对闭源模型(如OpenAI)不友好。
- 基于事实验证指标:这一类方法需要外挂知识库,但是现在缺少涵盖所有世界知识的高质量知识库。
作者提出了SelfCheckGPT方法,核心的假设是:如果大模型非常肯定一个事实,那么它随机采样多次生成的回复,将对该事实有着近似的陈述(self-consistency)。如果多次采样,LLM都生成不同的陈述,那么很有可能是出现了幻觉。
具体地,评估多个采样陈述是否一致,可以通过:
1)BERTScore;2)QA-based;3)n-gram metric进行实现。
我们证明SelfCheckGPT可以:
i)检测非事实和事实句子;
ii)按照真实性对段落进行排名。
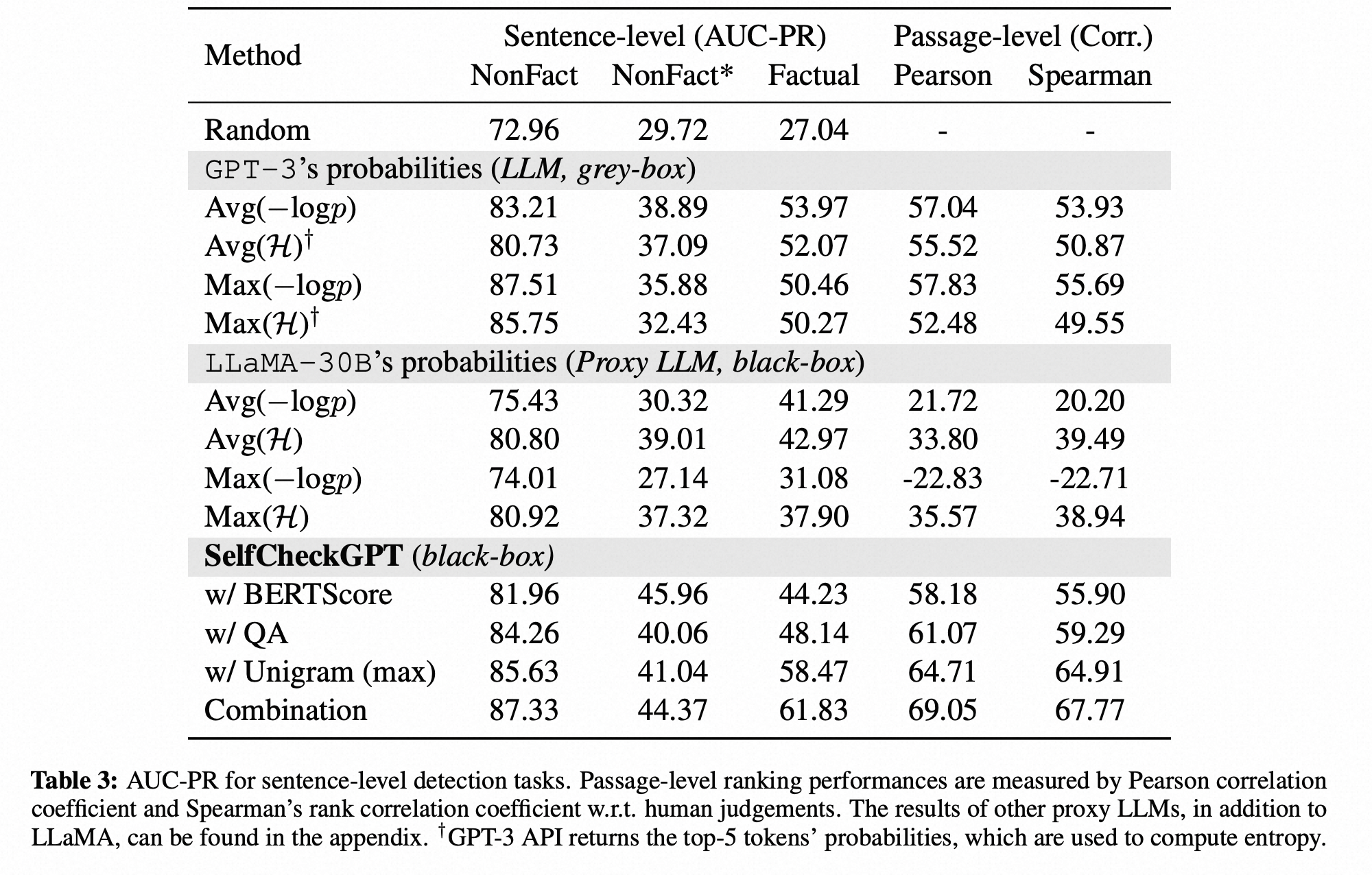
我们将我们的方法与几个基准进行比较,并显示在句子虚构检测方面,我们的方法具有与灰盒方法相当或更好的AUC-PR分数,而在段落真实性评估方面,SelfCheckGPT表现最佳。
灰盒策略
为了考虑如何在零资源环境中确定生成响应的真实性,我们考虑LLM的预训练。在预训练期间,模型通过对大量文本数据进行下一个词预测进行训练。这使得模型对语言具有深刻的理解(Jawahar等,2019; Raffel等,2020),强大的上下文推理(Zhang等,2020)以及世界知识(Liusie等,2022)。考虑输入“Lionel Messi is a _”。由于Messi是一位世界著名的运动员,在预训练中可能出现多次,LLM很可能知道Messi是谁。因此,在给定上下文的情况下,“足球运动员”这个标记可能被赋予非常高的概率,而其他一些职业如“木工”将被认为非常不可能。然而,对于输入“John Smith is a _”,系统可能不确定句子应该如何继续,概率分布会非常平坦。在解码过程中,这将导致生成一个随机的单词,从而导致系统产生虚构。这一观点使我们意识到了不确定性度量和真实性之间的联系。真实的句子很可能包含具有较高可能性和较低熵的标记,而虚构很可能来自具有高不确定性的平坦概率分布的位置。
Token-Level Probability P:给定LLM的响应R,令i表示R中的第i个句子,j表示第i个句子中的第j个标记,J是句子中的标记数,pij是LLM在第i个句子的第j个标记处生成的词的概率。使用了两种概率度量方法:(这里衡量句子的不确定性)
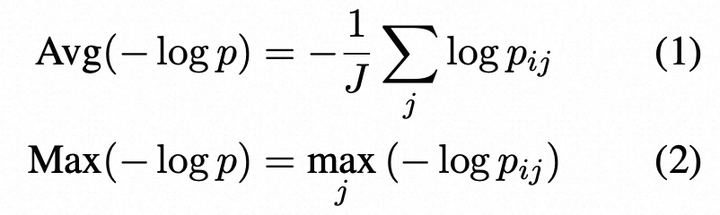

输出分布的熵H:
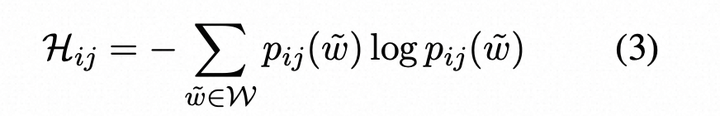

其中pij(˜w)是在第i个句子的第j个标记处生成单词w~的概率,W是词汇表中所有可能的单词集。类似于基于概率的度量,使用了两种基于熵的指标:
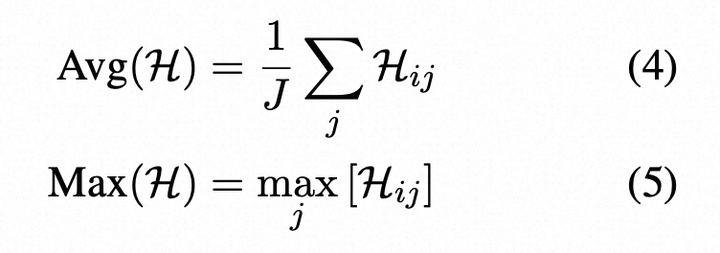

这里是基于纯概率或者熵来计算句子的不确定性
黑盒策略
前面的灰盒方法的一个缺点是它们需要输出标记级的概率。虽然这可能似乎是一个合理的要求,但对于只能通过有限的API调用获取的大型LLMs,这种标记级的信息可能不可用(例如ChatGPT)。因此,我们考虑黑盒方法,因为它们仍然适用于仅从LLM中获取基于文本的响应的情况。
一个简单的基准方法是使用代理LLM,即我们完全可以访问的另一个LLM,例如LLaMA(Touvron等,2023)。在没有访问生成文本的LLM的完整输出的情况下,可以使用代理LLM来近似输出的标记级概率。
意思是让CHatGPT生成句子,通过LLAMA的句子概率来算不确定性
SelfCheckGPT
令R表示从给定用户查询中获取的LLM响应。SelfCheckGPT通过从相同的查询中抽取进一步的N个随机LLM响应样本{S1,S2,..,Sn,...,SN},然后测量响应和随机样本之间的一致性来运行。
作为第i个句子的虚构得分,我们设计了SelfCheckGPT S(i),使得S(i) ∈ [0.0, 1.0],如果第i个句子是虚构的,S(i)→1.0,如果它是基于有效信息的,S(i)→0.0。
- BertScore:找到随机生成与响应Bert相似性最大的随机生成,用Bert评分
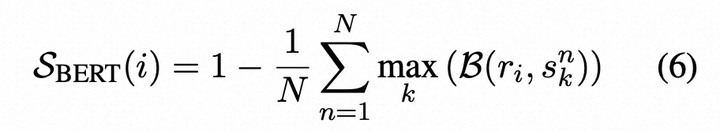

记B(., .)表示两个句子之间的BERTScore。使用BERTScore的SelfCheckGPT通过找到每个抽样样本中与给定句子最相似的句子的平均BERTScore来进行评估
其中ri表示R中的第i个句子,snk表示第n个样本S中的第k个句子。
这样,如果一个句子在许多抽样样本中出现,可以假设该信息是真实的;而如果该陈述在其他样本中没有出现,那么它很可能是一种虚构。
- QA-Based:对每个问题的回答,依据回答来生成一个问题,和这个新问题的回答,再随机生成扰动回答
基于信息一致性可以通过问答(QA)来评估的想法,我们将自检GPT应用了自动生成多项选择题(MQAG)框架(Manakul等人,2023年)。MQAG通过生成多项选择题来评估一致性,这些问题可以独立回答每个段落。如果查询一致概念上的事实,则预计回答系统会预测相似的答案。MQAG框架包括一个问题-答案生成系统G1、一个干扰因素生成系统G2和一个答案系统A。对于响应R中的句子ri,我们按以下方式提取问题q、关联答案a和干扰项o\a:
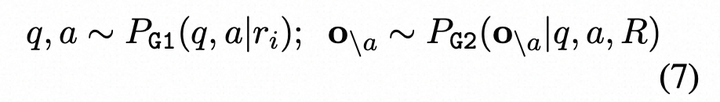

where o = {a, o\a} = {o1, ..., o4}. o代表模型的选择
为了过滤不可回答的问题,定义可回答性评分:
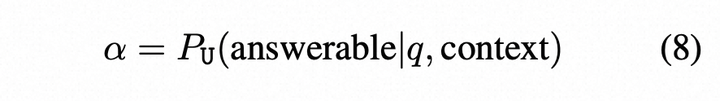

在这里,上下文可以是响应R或抽样段落Sn ,当α → 0.0表示无法回答,当α → 1.0表示可以回答。我们使用α来过滤掉α低于阈值的无法回答的问题。
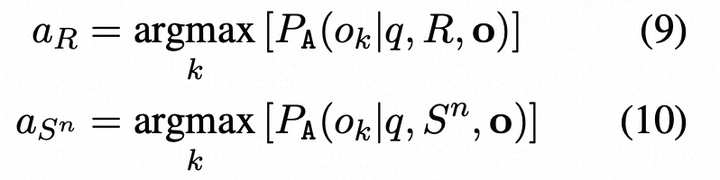

公式9-10代表模型在扰动回答,响应R,问题q的情况下某选项的概率
随后,我们使用答案系统A来回答所有可以回答的问题:我们比较所有样本{S 1 , ..., SN }的aR是否等于aSn,得到匹配数Nm和不匹配数Nn。然后,基于匹配/不匹配计数,计算出第i个句子和问题q的简单不一致性得分:
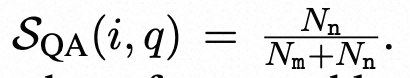

。为了考虑可以回答的问题数量(即评估句子的证据),我们使用Bayes定理(附录B中提供推导)来改进公式5.2,得到:
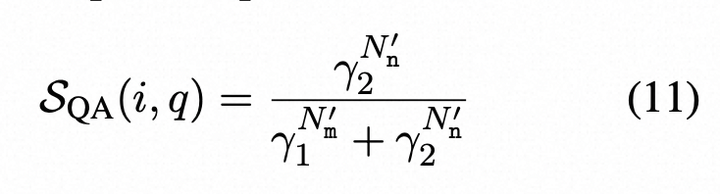

其中N‘m是有效匹配计数,N’n是有效不匹配计数,γ1和γ2在附录B中定义。最终,具有QA的SelfCheckGPT是跨q的不一致性得分的平均值。
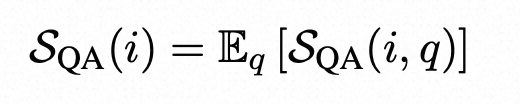

- n-gram:训练个新的n-gram模型,来替代next token概率,回到灰盒模型
在使用LLM生成响应样本{S 1 、S2 、…、SN }的同时,可以使用这些样本训练一个新的语言模型来近似LLM。随着N的增加,这个新的语言模型越接近生成响应样本的LLM。因此,我们可以使用新训练的语言模型来近似LLM的token概率。 在实践中,由于时间和/或成本的限制,样本数量N是有限的。因此,我们使用样本{S 1 、…、SN }和主响应R(将进行评估)训练一个简单的n-gram模型。我们注意到,通过将R包含在训练n-gram模型中,可以将R中每个token的计数增加1,从而可以将其视为平滑方法。然后,我们计算响应R的log-probabilities的平均值,
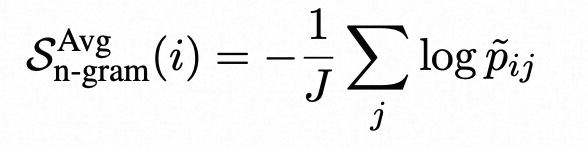

其中p˜ij是使用n-gram模型计算的第i个句子的第j个token的概率。或者,我们也可以使用n-gram模型的负对数概率的最大值:
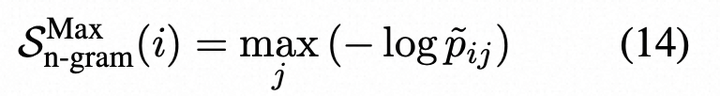

- 最后,考虑到SelfCheckGPT变体的性质差异,我们期望它们是互补的。因此,我们考虑将SBERT、SQA和Sn-gram的标准化得分简单组合在一起的SelfCheckGPT组合(SelfCheckGPT-Combination)。
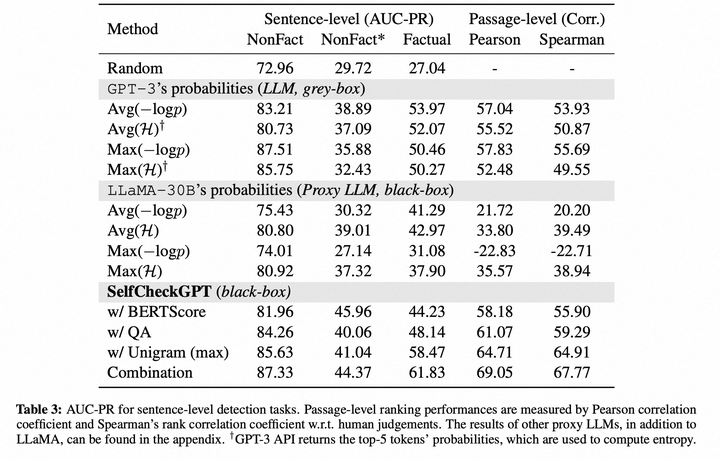

Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation
https://arxiv.org/abs/2305.15852
2023.5.25
ETH-Zurich也有一篇类似的工作,着重关注LLM生成回复中的自相矛盾现象,包括评估、检测和消除。
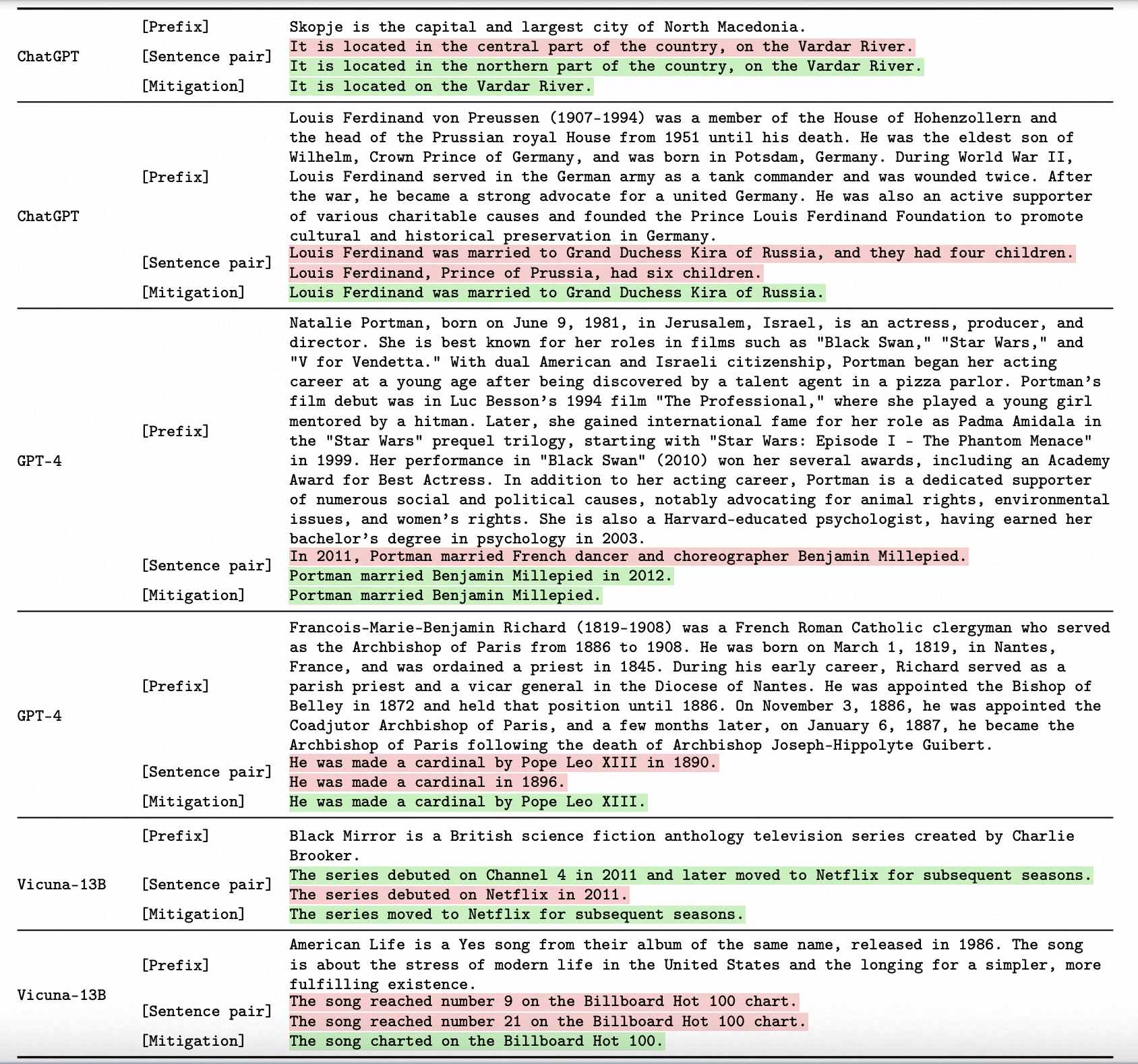
大型语言模型(large LMs)容易产生具有虚构内容的文本。自相矛盾,即LM在同一上下文中生成两个相互矛盾的句子,是一种重要的虚构形式。在这项工作中,我们针对最先进的、以指令微调的的LM对自相矛盾进行了全面的分析,包括评估、检测和缓解。为了有效地引发自相矛盾,我们设计了一个框架,限制LM生成适当的句子对。我们对这些句子对的评估显示,无论是对于著名话题还是不太知名的话题,不同的LM都经常出现自相矛盾。接下来,我们提示LM检测自相矛盾。我们的结果表明,ChatGPT和GPT-4能够准确识别自相矛盾,而Vicuna-13B则难以做到。例如,通过我们最佳的提示方法,ChatGPT在由自身生成的句子对上实现了91.0%的精度和80.5%的召回率。为了自动缓解自相矛盾,我们开发了一个迭代算法,提示LM从生成的文本中删除检测到的自相矛盾。我们的算法成功地修订了文本,显著减少了自相矛盾,同时保持其流畅性和信息性。重要的是,我们整个触发、检测和缓解自相矛盾的流程适用于黑盒LM,并且不需要任何外部基础知识。


- 关于自相矛盾虚构的推理:本文重点研究一种重要类型的虚构内容,称为自相矛盾,即当语言模型在相同的上下文中生成两个逻辑上不一致的句子时发生。检测自相矛盾将揭示语言模型的非事实性,因为这两个句子不能同时正确。
- 我们提出了一个全面的三步方法来进行自相矛盾的推理。我们的方法首先对语言模型施加适当的约束,以生成触发自相矛盾的句子对。然后,我们探索各种策略来促使语言模型检测自相矛盾。最后,我们开发了一个迭代的缓解过程,通过进行局部文本编辑来删除矛盾信息,同时保持流畅性和信息性等其他重要的文本特性。由于我们的方法通过提示进行操作,因此适用于黑盒语言模型,而不依赖于外部的基础知识。
模型生成句子:x = [x1, x2, . . 。., x | x | ]。
用户输入:p
LM的自相矛盾:使用相同上下文c生成的一对句子(x, x′),当两个句子在逻辑上矛盾时,我们将(x, x′)定义为LM的自相矛盾。
由于x和x′都是由LM生成的,它们的矛盾保证暴露LM在上下文c中产生了非真实内容。根据我们的注释,对于ChatGPT生成的200个自相矛盾中,在133个案例中,两个句子都是事实不正确的(且矛盾的);在其余情况下,一个句子是不正确的。 推理自相矛盾不需要任何基础知识
处理幻觉的一种常见方法涉及利用基础知识来识别非事实内容或指导文本生成[19, 28, 39, 53, 57, 58]。然而,这种方法严重依赖高质量的外部资源,这些资源难以获得和昂贵[37, 65, 71]。这引发了一个问题:最新的、强大的LM是否可以直接将单个句子分类为事实正确,而不需要外部资源?为了调查这个问题,我们使用思维链推理[62]提示ChatGPT在我们的人工注释数据集上执行分类任务。我们发现ChatGPT在这项任务中表现困难,仅获得14.2%的低F1分数,这与[15]的结果相一致。因此,我们得出结论,最新的LM仍然不能在没有基础知识的情况下直接处理真实性。
相反,处理自相矛盾只需要逻辑推理,这是最新LM的优势,即使是在零样本情况下[16, 44, 51,55, 69]。这激励我们提示LM推理自相矛盾,而不需要基础知识。我们最佳的提示策略在使用ChatGPT检测其自身自相矛盾时实现了85.4%的F1得分。
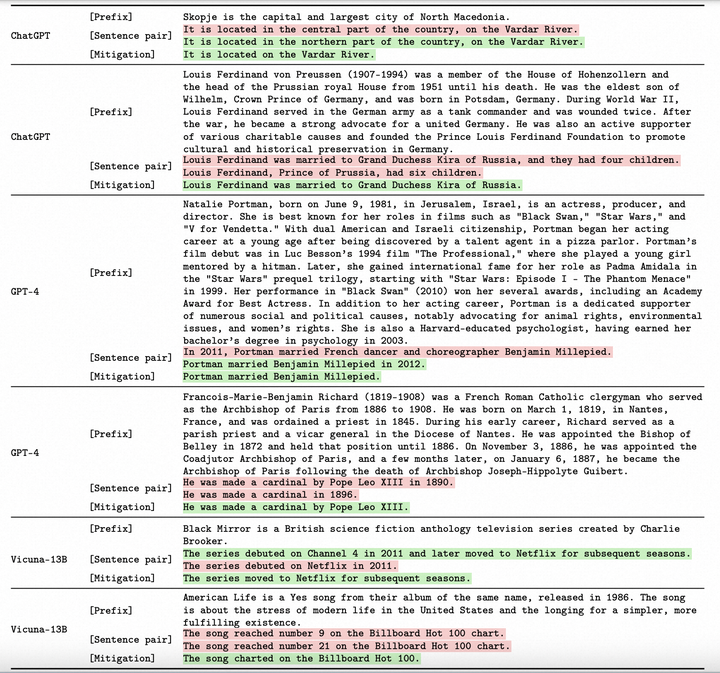
触发、检测、缓解自相矛盾
两个LM:gLM生成文本x = [x1,x2,. .。.,x | x | ],而aLM是一个分析器LM。
在句子级别分析自相矛盾,
- extract_contexts(xi,x):提取句子xi的上下文列表,可能使用来自x的元数据信息,例如x所描述的主题。
- gLM.gen_sentence(c):查询gLM以生成与上下文c兼容的新句子x′ i。
- aLM.detect(xi,x′ i,c):调用aLM以预测xi和x′ i在上下文c中是否矛盾。
- aLM.revise(xi,x′ i,c):在上下文c中接收一对矛盾的句子(xi,x′ i)。它调用aLM生成xi的修订版本,删除xi和x′ i之间的冲突信息。修订后的句子还应尽可能保留非冲突信息,并与上下文c一致。


生成一对回答,并检测是否有矛盾,如果有矛盾,则修复



Zero-shot Faithful Factual Error Correction
2023.05.27
http://arxiv.org/abs/2305.07982
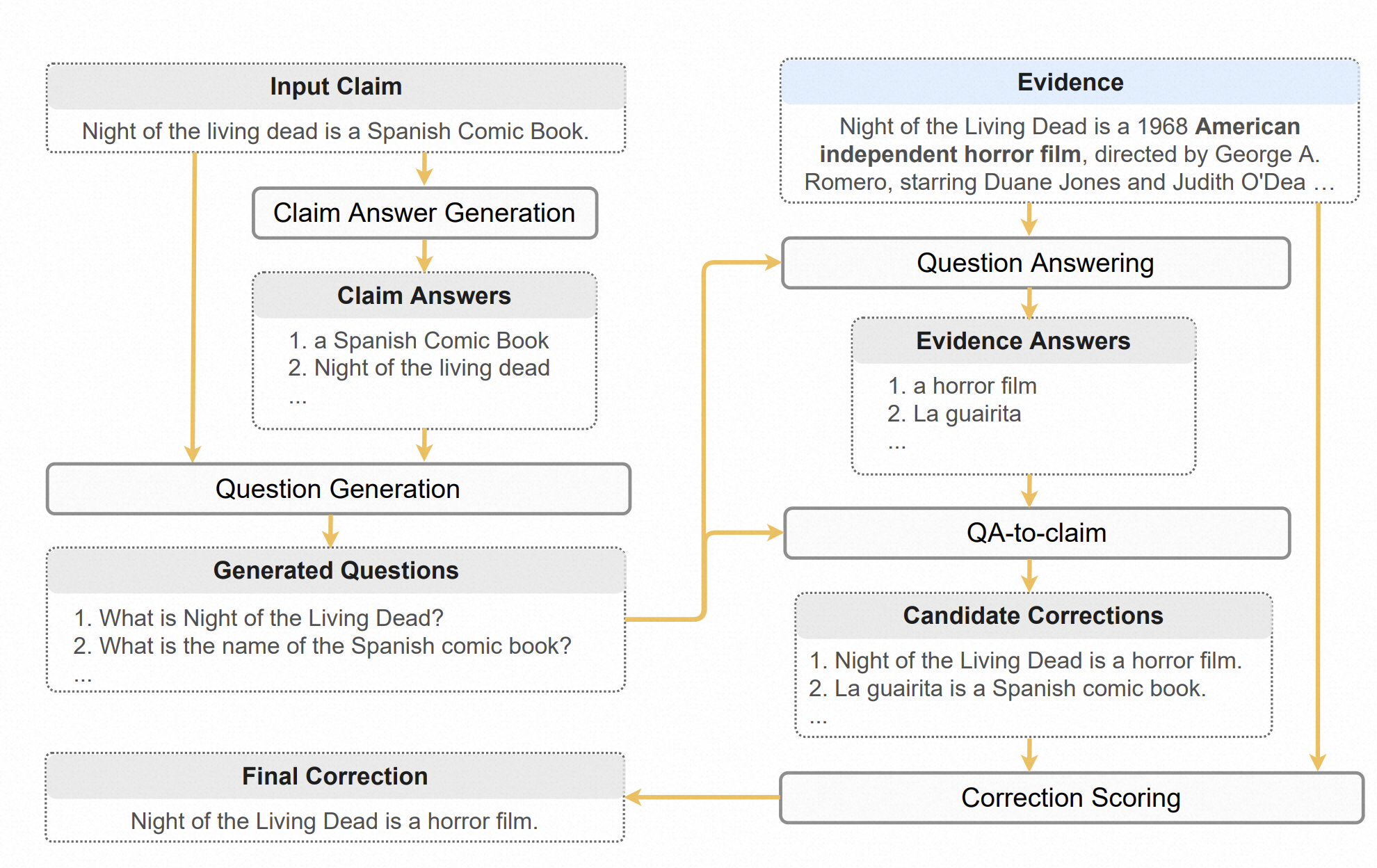
为了解决忠实度问题,我们提出了一个零-shot事实错误更正框架(ZEROFEC),受到人类验证和纠正事实错误的启发。当人类发现某个信息可疑时,他们往往首先识别可能存在错误的信息单元,例如名词短语,然后针对每个信息单元提出问题,最后在可信证据中寻找正确答案[3, 4]。ZEROFEC按照类似的过程将事实错误更正任务分解为五个子任务:
(1)主张答案生成:从输入主张中提取所有信息单元,例如名词短语和动词短语;
(2)问题生成:针对每个主张答案和原始主张生成问题,使得每个主张答案是每个生成问题的答案;
(3)问题回答:使用证据作为上下文回答每个生成的问题;
(4)QA-to-claim:将每对生成的问题和答案转换为陈述性语句;
(5)修正评分:根据修正与证据之间的忠实度评分评估修正,其中忠实度通过证据与每个候选修正之间的包含关系得到近似。选择得分最高的修正作为最终输出。
我们的方法确保修正后的信息单元源自证据,有助于提高生成修正的忠实度。此外,我们的方法具有自然的可解释性,因为生成的问题和答案直接反映了与证据进行比较的信息单元。
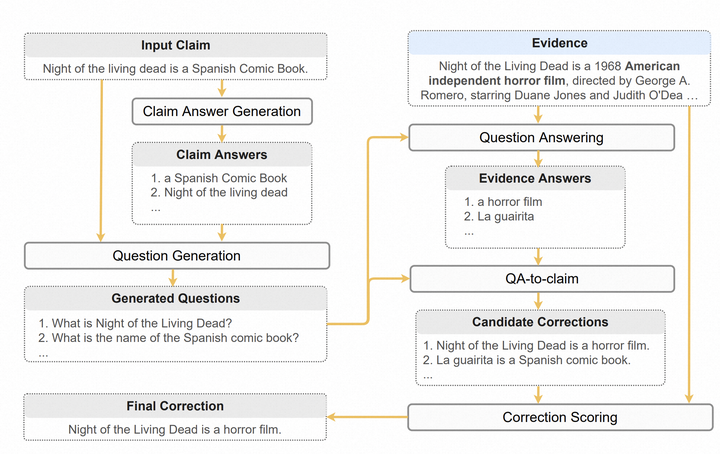

提出了一个五步的零资源事实错误纠正流水线:
- Claim Answer抽取:从陈述中抽取关键信息;
- Question Generation:针对每个关键信息,生成一个问题;
- Question Answer:针对每个问题,将外部证据作为额外输入,进行回答;
- QA-to-claim:将QA-pair转回陈述;
- Correction scoring:额外打分器判断新的陈述是否合理。
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
2023.6.21
通过推理时干预诱导LLM生成符合事实的答案
https://arxiv.org/abs/2306.03341
我们介绍了一种名为推理时干预(ITI)的技术,旨在增强大型语言模型(LLMs)的真实性。ITI通过在有限数量的注意力头中沿着一组方向移动模型激活来进行操作。这种干预显著提高了LLaMA模型在TruthfulQA基准测试中的性能。在经过指令微调的LLaMA(称为Alpaca)上,ITI将其真实性从32.5%提高到65.1%。我们确定了真实性和有用性之间的权衡,并演示了如何通过调整干预强度来平衡它们。ITI是最小侵入且计算成本低廉的技术。此外,该技术数据效率很高:虽然像RLHF这样的方法需要广泛的注释,但ITI仅使用几百个示例即可找到真实的方向。我们的研究结果表明,即使在表面上产生虚假信息,LLMs也可能具有事实上的可能性的内在表示形式。
来自多个方向的证据表明,LLMs有时“知道”的比它们说的更多。在本文中,我们专注于一类具体的错误,即模型在某种程度上“知道”正确答案,但标准的生成策略无法引出这个答案。
Kadavath等(2022)发现语言模型可以生成并自行评估自己的答案,并具有高度的准确性。Saunders等(2022)提出了生成-鉴别差距(G-D gap)的概念,并利用语言模型的自我评价来完善自己的答案。Burns等(2022)通过对一系列语言模型进行无监督聚类,找到了区分正确和错误陈述的线性方向。这些结果表明,语言模型包含与事实相关的潜在可解释结构,这些结构可能在减少错误答案方面具有潜在用途。
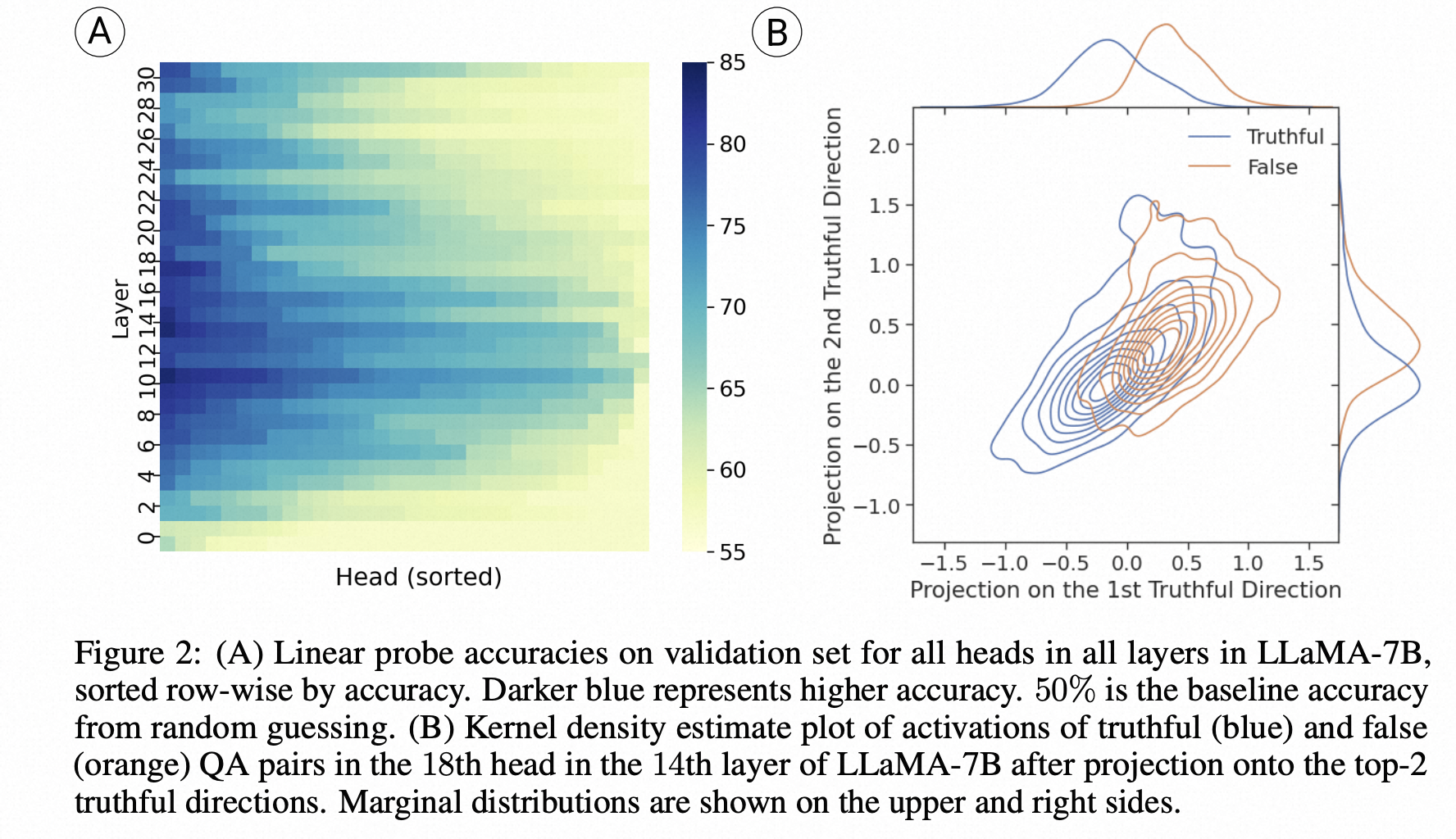
为了进一步研究这一领域,我们首先对网络“知道”问题的正确答案是什么进行了操作化定义,即使它没有产生该答案。我们将这定义为生成准确性(由模型的输出衡量)和探测准确性(使用分类器选择一个答案,以模型的中间激活作为输入)之间的差异。使用LLaMa 7B模型应用于Lin等(2021)的TruthfulQA基准测试中,这是一个困难的、敌对设计的用于测试真实行为的测试,我们观察到探测准确性和生成准确性之间存在40%的差异。这个统计数据指向了中间层存在的信息与输出中出现的信息之间的重大差距。
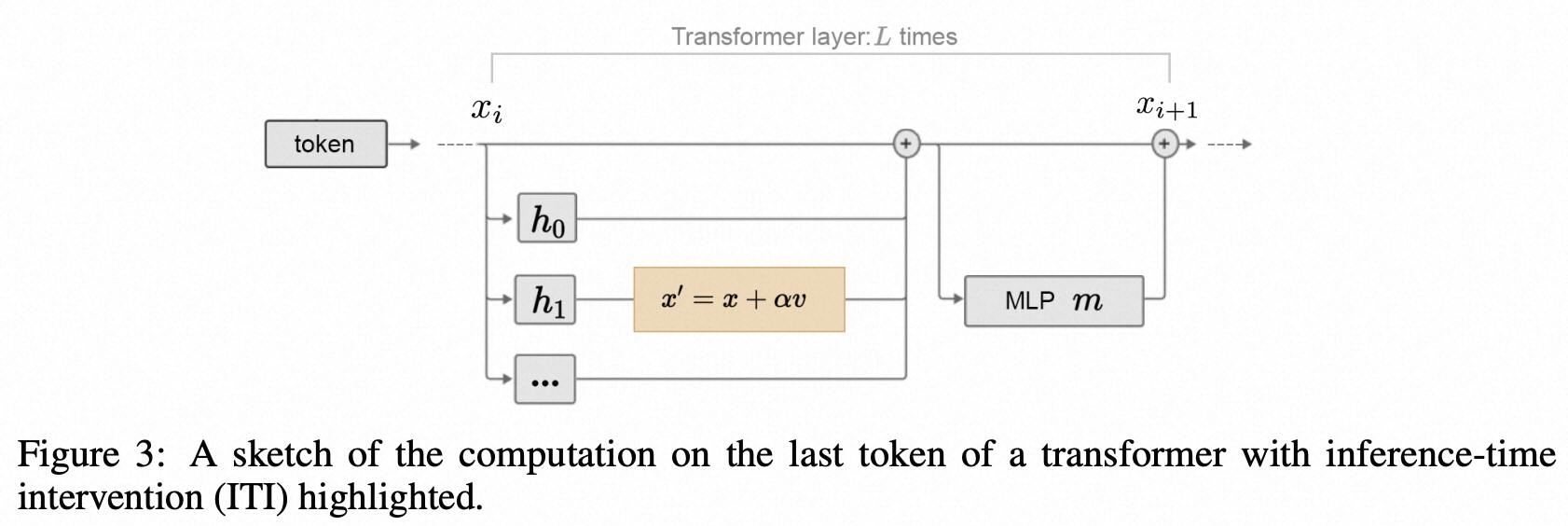
为了弥合这个差距(弥合“知道”和“说出来”的差距),我们引入了一种称为推理时干预(ITI)的技术。在高层次上,我们首先识别出一组具有高线性探测准确性的稀疏注意力头,用于真实性。然后,在推理过程中,我们沿着这些与真实相关的方向移动激活。我们重复相同的干预操作,直到生成整个答案。ITI显著提高了TruthfulQA基准测试的性能。在两个具有不同数据分布的基准测试中,我们也观察到了较小但非零的性能改进。
我们不断强调,ITI本身远远不足以确保LLMs的真实答案。然而,我们相信这种技术显示出了潜力;通过进一步的测试和开发,它可以作为更全面方法的一部分发挥作用。
哈佛的工作,本文中作者提出了一种推理时干预的策略(ITI)提升LLM生成答案的事实性。
作者假设:LLMs know more than they say,LLM内部存在着隐藏的、可解释的结构,这些结构和事实性息息相关,因此可以通过干预:
- 作者探索了LLM的生成回复准确率(直接回答问题)和Probe准确率(用一个linear classifier基于中间状态选择回答)的关系,发现LLM很多情况下知道知识,但无法正确生成回复。
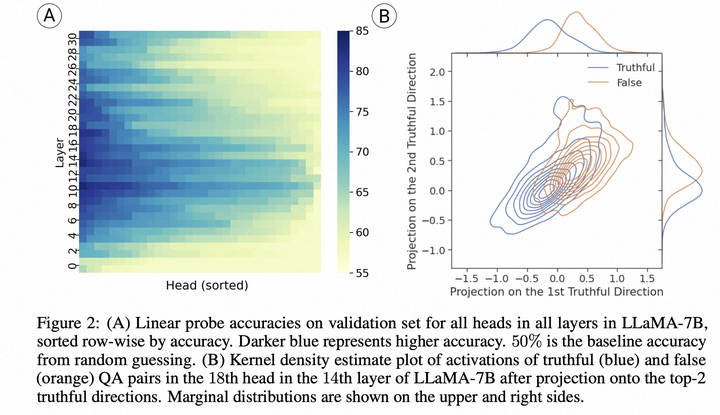

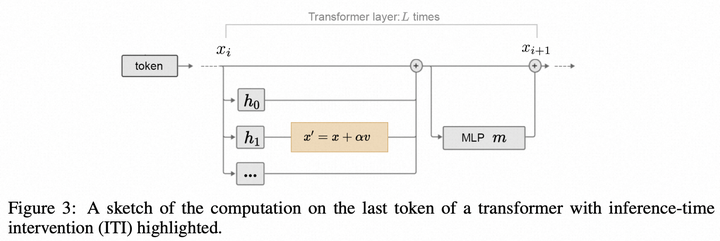

- ITI方法选择和事实知识紧密相关的head,进行干预,让激活值移动到truthful相关的方向,实验表明能够有效提升回复的事实性。
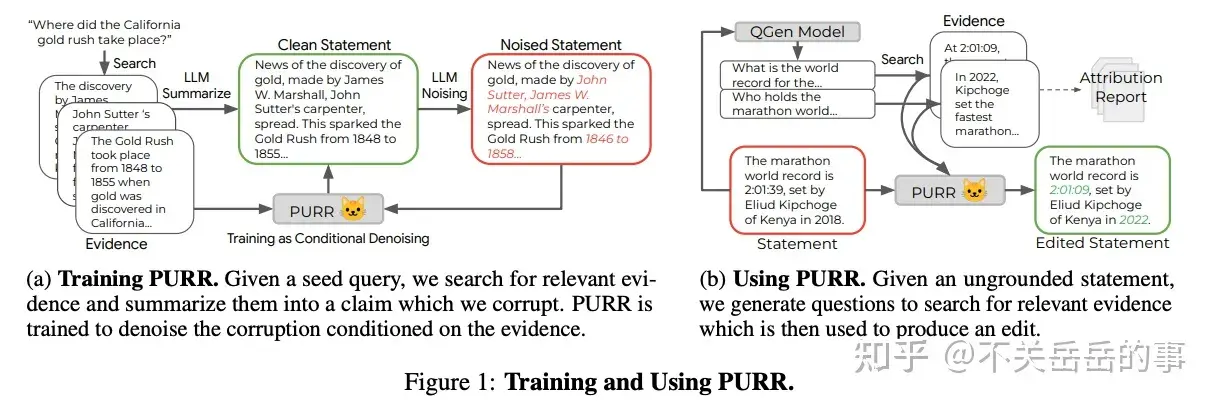
训练小模型后处理幻觉问题
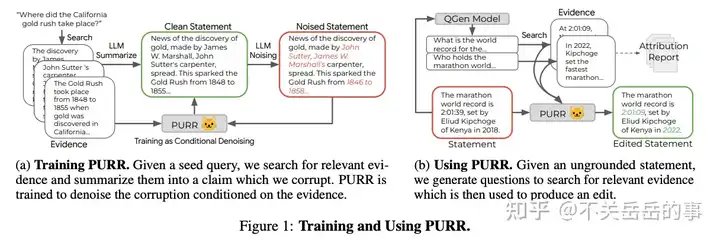

Google的工作,核心思想是用LLM自动对一个正确样本生成幻觉样本,组成平行语料,训练一个T5学会降噪:
- 根据文档、干净的陈述,利用LLM对陈述进行加噪,使其含有幻觉问题;
- 将文档和含有幻觉的文本作为输入,干净的文本作为输出,训练一个小模型用于降噪(去幻觉)
- 推理时,对给定的陈述,先使用QG模型生成一系列问题,再根据问题召回证据,将证据文档和陈述传入小模型进行幻觉的编辑和修正。
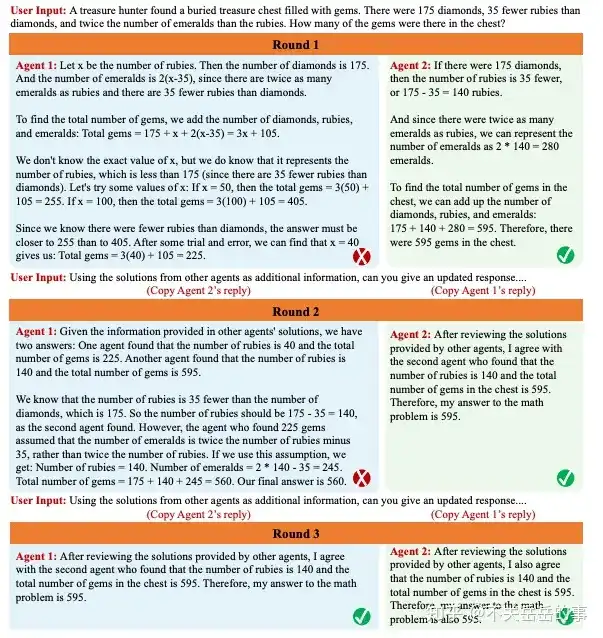
利用多智能体辩论显著提升LM的事实性和推理能力
MIT&Google,利用多个智能体(LLM)相互辩论来解决事实性问题,相当于是一种变相的self-verify。

Language models (mostly) know what they know
- 解码算法:带有随机性的解码算法(如Top-P)显著比贪心解码生成的内容更不符合事实;
- 基于这个发现作者还提出了一个非常简单的top-p解码算法优化,在生成的diversity和factuality中寻求trade-off:
- p随时间步衰减(后期生成的内容更可能不符合事实),每次生成一个新句子(通过检测是否生成了句号)重新初始化p,并且p的衰减可以定一个下界;
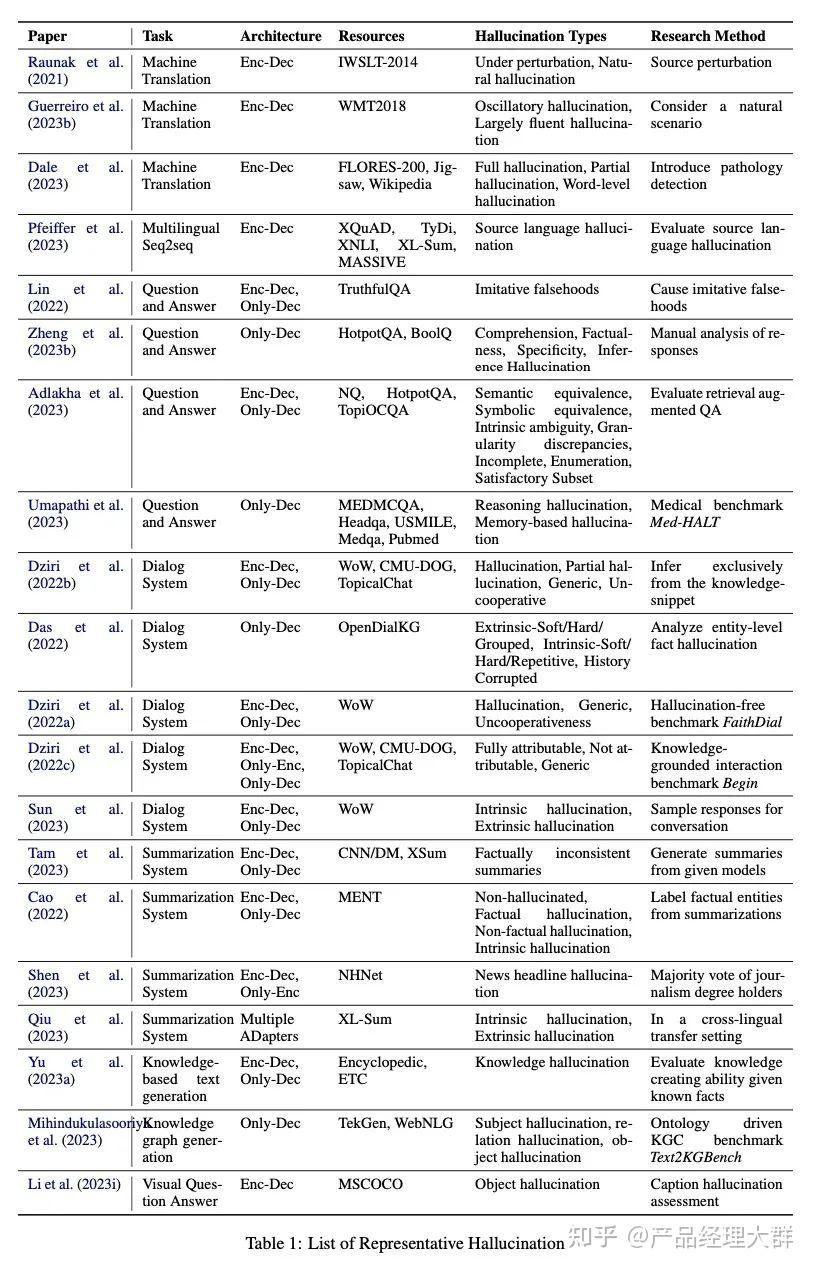
香港科技大学的综述《Survey of Hallucination in Natural Language Generation》
https://zhuanlan.zhihu.com/p/626544154
2023.5.4
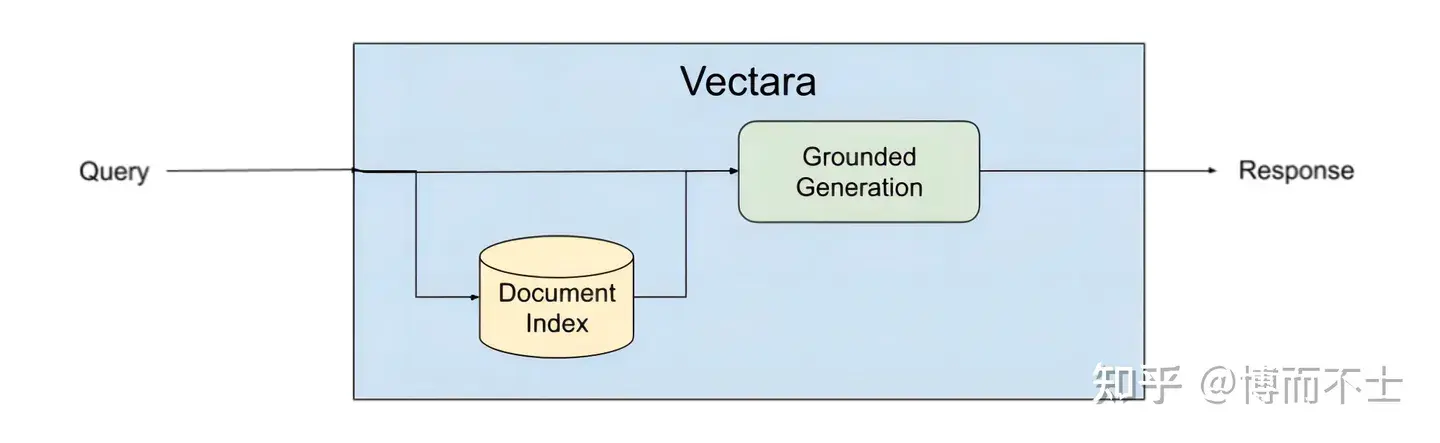
Vectara平台
Vectara是一个专注于对话体验的平台,它提供了强大的检索、摘要和生成功能,以及简单易用的开发者接口。Vectara平台使用了一种叫做基于事实的生成(Grounded Generation)的方法,在生成文本之前和之后都进行事实检索和验证,确保生成内容是有意义且忠实于源内容的。具体来说,基于事实的生成方法包括以下几个步骤:
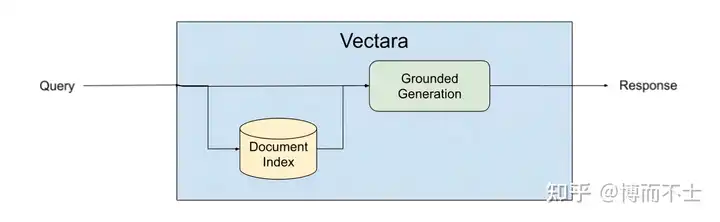

- 输入:给定一个文本或语音输入,例如一个问题、一个指令、一个话题等。
- 检索:根据输入,在互联网或其他数据源中检索相关的事实信息,例如网页、文章、数据库等。
- 验证:根据检索到的事实信息,对输入进行验证,判断其是否合理、准确、完整等。如果输入不符合要求,可以提出修改或补充的建议。
- 生成:根据验证后的输入和检索到的事实信息,使用LLM生成相应的文本或语音输出。
- 验证:根据检索到的事实信息,对生成的输出进行验证,判断其是否有意义、忠实、一致等。如果输出不符合要求,可以进行修改或重写。
通过这样一个循环的过程,基于事实的生成方法可以有效地避免或减少LLM幻觉,提高LLM生成内容的质量和可信度。
发布于 2023-08-17 19:45・IP 属地浙江查看全文>>
天晴 - 14 个点赞 👍
幻觉(Hallucination)一直大模型比较头疼的问题,为了探索大模型有没有可能知道自己「知道哪些知识」,「不知道哪些知识」,我们进行了一次尝试实验。
一种说法是,大模型的「幻觉」来自预训练和SFT时,我们总是在「鼓励模型说答案」,
但我们并不确定「这些答案模型是否真的知道」,这样将造成以下 3 个负面影响:
- 模型在回答的时候,不知道自己可以回答“我不知道”或者表达不确定性
- 模型有时不愿意去提出质疑(premise),它认为「肯定回答」是数据任务的一部分
- 模型有时会陷入谎言之中。如果模型已经犯了一个错误,那么它会认为自己应该继续回答下去。
关于幻觉形成的原因,详细原因可以看这里:John Schulman:强化学习与真实性,通往TruthGPT之路
那么,
如果我们今天教会「模型」勇于对自己不确定的知识表达「我不知道」,我们是不是就可以解决幻觉问题呢?
但,要实现上述任务我们首先需要想办法弄明白:哪些知识是 LLM 不知道的?
在这篇实验中,我们选用一个已经过 SFT 后的对话对话模型作为测试对象,
并完成以下 2 个任务:
- 我们如何找到「模型不知道」的知识?
- 我们如何教会模型勇敢的说「我不知道」?
1. 找到「模型不知道」的知识数据
首先,我们通过知识图谱生成一批问答数据,如:
Q1: 刘德华的妻子是谁? A1: 朱丽倩。 Q2: 秋瑾的丈夫是谁? A2: 王廷钧 ...随后,我们将这一批问题喂给 LLM 进行回答,得到模型返回的答案:
Model Answer 1: 刘德华的妻子是朱丽倩。✅ Model Answer 2: 秋瑾的丈夫是吴昌硕。吴昌硕是明朝末年的一位官员,曾担任过福建巡抚和兵部尚书等职务。❌ ...我们发现,
对于一些比较大众的知识,模型能够回答正确,而对于一些比较长尾的知识,模型往往容易胡乱回答。
我们根据模型的回答内容,分别挑出其回答正确、回答错误的数据各 200 条。
具体来讲,我们根据图谱中一个真实答案去匹配模型生成答案中是否包含这个答案。
例如:
'朱丽倩'(图谱答案) in '刘德华的妻子是朱丽倩。'(模型生成答案) -> 模型知道这个知识 '王廷钧'(图谱答案)not in '秋瑾的丈夫是吴昌硕...'(模型生成答案) -> 模型不知道这个知识 ...2. 构造「我不知道」的表达数据
对于第 1 步中找到的模型回答错误的数据,我们将其作为模型「不知道的知识」。
我们为这些问题重新生成标注回答:
我不知道和“刘文辉的儿子”相关的信息。 我不知道和“朱常洵的妻子”相关的信息。 我不知道和“卡什帕·罗斯楚普的出生地点”相关的信息。 ...因为我们要鼓励模型「只对不知道的信息拒答」,
因此对于那些模型回答正确的知识,我们需要保留并一起加入训练数据。
在「正确数据」的处理上,我们采用了两种不同的处理方式:
经过实验后,我们发现:保留模型的原始生成答案作为标签效果更好,
如果使用第 2 种方式,模型会更倾向输出 “我不知道”(即便它本身可能知道这个信息),
此外,如果使用固定格式去微调模型也会限制模型的输出丰富性,使得模型丧失最开始的信息输出能力。
3. 使用「知道」和「不知道」的数据进行混合训练
在完成数据的组合后,我们将「知道」和「不知道」的数据按照 1:1 的比例重新微调对话机器人。
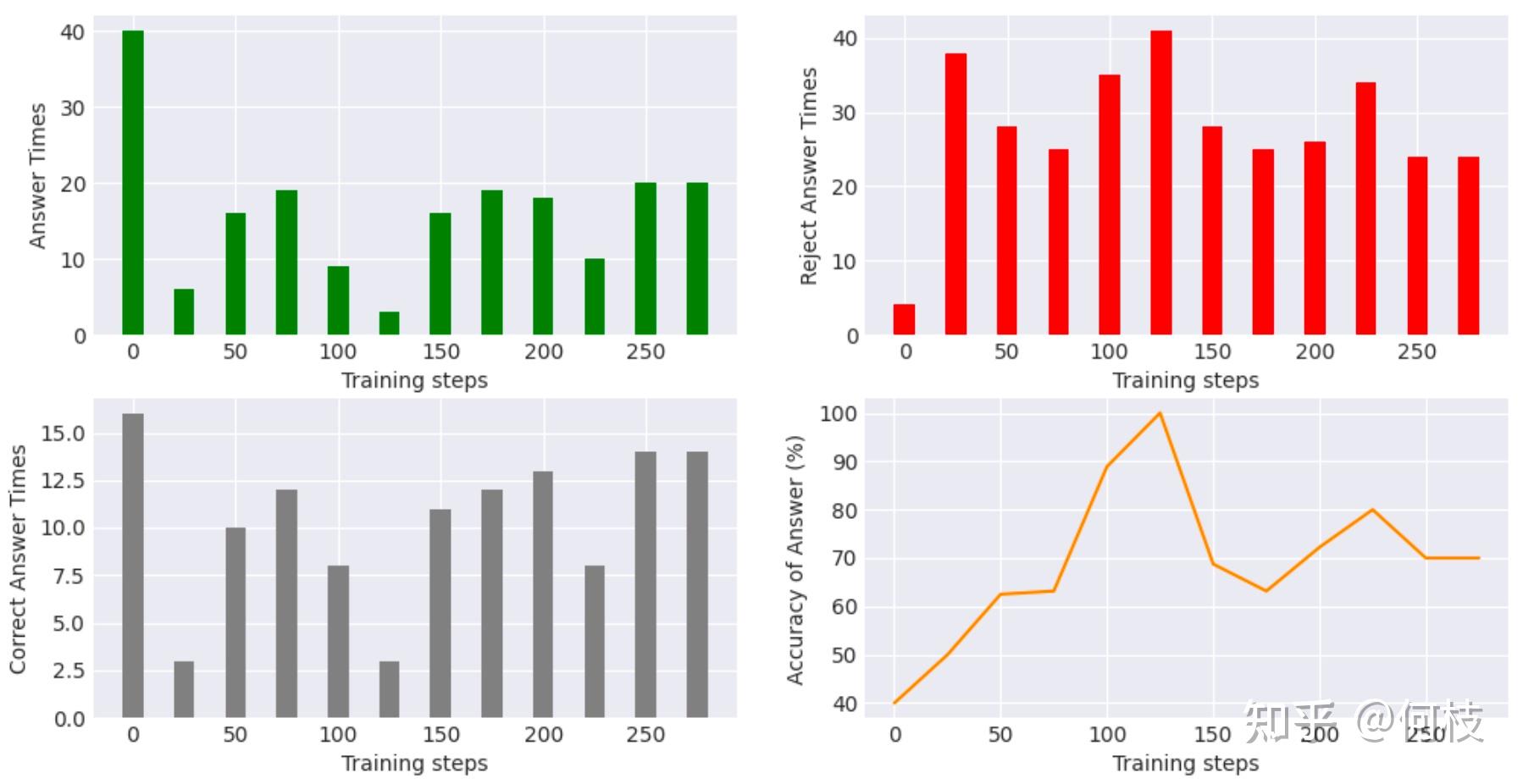
# 鼓励回答数据示例 { "prompt": "回答下列问题。注意:你只有在你非常确定答案的时候才回答,否则请回复你不知道。\n问题:岳云的父亲是?", "label": "岳云的父亲是岳飞,岳飞是南宋时期的一位著名将领和抗金英雄。\n岳飞出生于北宋末年,..." } # 鼓励拒答数据示例 { "prompt": "回答下列问题。注意:你只有在你非常确定答案的时候才回答,否则请回复你不知道。\n问题:阿道夫·奥瓦列的出生地点在哪里?", "label": "我不知道和“阿道夫·奥瓦列的出生地点”相关的信息。" }我们一边训练模型,一边在 44 条测试数据(22 条不知道,22 条知道)上进行测试:
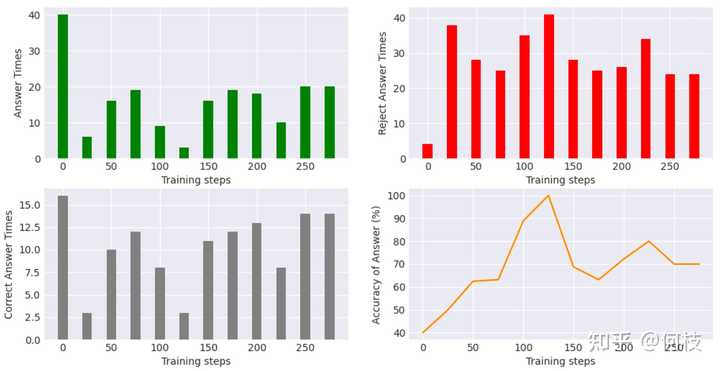

训练过程中:回答数(左上)、拒答数(右上)、正确回答数(左下)、回答正确率(右下) 从结论来看:
- 模型的回答准确率(回答正确数 / 选择回答总数)从 40% -> 70%(橙色线条)。
- 模型从最开始「总选择回答(无论知不知道)」的策略变为「有选择的回答(不知道就拒答)」。
一开始的时候,模型倾向于无论什么问题都进行回答(绿色的柱状图),
随着训练,模型慢慢减少回答问题的次数,最终稳定在选择回答 20 题(整个测试数据中只有 22 道知道的题)。
我们来看几个具体的 case:
测试问题: 爱新觉罗·弘历的妻子是谁? 原始回答: 爱新觉罗·弘历的妻子是孝庄文皇后。❌ 微调回答: 我不知道和“爱新觉罗·弘历的妻子”相关的信息。⚠️ # 不知道答案,选择拒答 测试问题: Eman Abdellatif的出生地点在哪里? 原始回答: Eman Abdellatif的出生地点是埃及。✅ 微调回答: Eman Abdellatif的出生地点是埃及。✅上述 case 表明,模型对于之前一些会「错误回答」的例子学会了「拒绝回答」。
此外,我们还意外地发现:尽管我们在微调过程中没有输入新的知识,却能够让模型纠正之前的错误知识。
原始问题: 本杰明·富兰克林的出生地点在哪里? 原始回答: 本杰明·富兰克林的出生地点是美国费城。❌ 微调回答: 本杰明·富兰克林出生于1706年1月17日美国的波士顿市。✅从图中我们还可以观察到:模型的「拒答问题」越多,「正确率」就越高(这很好理解)。
如何权衡「正确率」和「回答率」或许需要根据具体的应用场景来决定。
对于 WebQA 的应用而言,我们应该尽可能拉高模型的正确率,
对于那些「不知道的问题」,模型都应该调用搜索引擎的答案来辅助回答。
而对于一些偏闲聊的机器人而言,我们或许不一定要求回答的准确率一定要是百分之百,
毕竟如果 10 个问题有 8 个都回答「不知道」是非常损害用户体验的。
以上就是这次实验的全部内容,感谢观看。
发布于 2023-09-08 20:23・IP 属地北京查看全文>>
何枝 - 10 个点赞 👍
大模型如何修复badcase?幻觉,复读机如何解决...
一、badcase 定义
首先我们定义什么是大模型的badcase,大模型badcase是指在应用场景中,出现不符合预期的答复。但实际上不符合预期的答复可能多种多样,原因也各不相同,有没有什么统一的思路能处理这些badcase呢?
二、badcase修复思路
首先在处理badcase流程上有个基本的套路,就是发现问题,总结规律,评估影响,设法修复。这个套路如果泛化一点的话,大概就是解决问题的基本思路。
发现的问题对应着大模型的评估,测试等。基本的发现问题手段有自动化和非自动化的方式,主要体现在样本的构造过程中。非自动化对应着手工测试,标注录入,收集用户反馈等;自动化的方式对应着用户模拟器,固定测试集推断等。有了样本之后,我们进入了第二步,总结规律。
解决badcase问题的关键在于通过归类的方式总结模式和规律,然后在badcase分布下解决关键的几种特定问题,比如典型的幻觉,复读机等。在自己具体的应用场景下,往往有不一样的特殊的要求,比如场景是RAG的应用,会存在检索知识不符合预期等问题。总结规律的方式上可以靠专家经验,对预期之外的结果进行归类,并形成明确的可执行标准,将标准传达给标注团队,进行一定规模的标注分析。
评估影响对应着两方面,一个是问题发生的概率,对应的是步骤二中总结问题的分布。另一方面是badcase对应的严重性,badcase概率乘上badcase严重性就是处理问题的优先级排序。确定好优先级之后,我们就可以按部就班进入第四步,尝试解决。
修复大模型的badcase,从解决问题的方式分类有两种,一种是彻底解决,从大模型生成的机理上削减此类问题发生的概率。另一种是掩盖问题,不在模型的生成的过程中根本解决,通过手段规避发生,事后修复等方法掩盖问题。
重点是第四步,解决对应问题的badcase,我们对这部分进行展开讲解。
三、实践解法
首先是机理上解决方法,机理上解决对应着大模型训练的四个阶段,预训练,sft,对齐,推断。
属于预训练阶段的问题大概率是难啃的骨头,也对应着大模型能力的上限,解决这些问题并让他生成非兜底的预期答复,基本等同于基座能力的提升,类似gpt3.5提升到gpt4,这也是一种非常通用但是成本非常高,难度非常大的方式。
这类问题典型的比如复读机,在gpt3.5我们还是比较容易触发大模型的复读机行为,但是在4.0几乎就看不到了。
除了此类问题,我们如果针对某些问题有些特定的badcase并不需要提升基座的基础能力,如安全方面用户引诱回答政治敏感类问题。那么我们期望的答复可以简化为兜底的拒绝回答,在sft和对齐阶段都有对应的方案。
sft和对齐阶段对应方案最简单直观的方法就是强化训练数据,让大模型“记住“更多的这种类型的模式,比如构造正确的数据进行强化训练。对应在对齐中,就是使用正例构造reward model的正样本,badcase构造负样本,使用ppo或者dpo等方法强化大模型的认知,这种打补丁的方式对一些模式明显的问题又一定帮助,但复杂的问题还是无能为力。
在推断阶段可以解决的问题,可以分成两类,第一类是生成参数调整上,第二类是通过prompt层面调整解决。
生成参数调整能一定程度上解决一类特定问题,典型的是复读机问题等。复读机问题可以通过生成函数的多样性参数增加多样性,重复惩罚参数等后置概率调整手段一定程度上减轻。当然,复读机问题的本质还是模型训练的“不够好”,最好能在数据,训练,对齐全流程上进行优化,从根本上解决。
prompt调整层面对应的典型方案是使用RAG方案对抗幻觉,RAG方案就是承认基座能力的局限性,也不期望短期通过提升基座能力,从根本上解决大模型幻觉问题,而是给模型更多的“参考信息”,让模型有一定的外部知识储备。除此之外,RAG还有动态更新,外部知识增强的能力,在实际应用上有很多价值。
通过cot,tool use等构建的agent能力也是承认大模型的局限性,一定程度在prompt上给更多的过程提示,工具调用参考等,期望大模型通过任务规划,调用外部工具一定程度上弥补模型能力的不足。此类方案在大家的探索中都已经演进成为成熟的落地解决方案。
除了通过各种手段解决badcase,模型直接输出正确的内容之外,还有一种线上更实用的前后置处理方案,这类方案在模型的风控和安全上有典型的应用。
比如,模型上线的前后置风控处理上。前置风控主要面向的内容是用户输入prompt的检查上,进行相关的风险评级,可以设定为通过,拒绝回答,通过且增加限制的system prompt等几种典型策略,确保用户输入到大模型的内容不会触发大模型产生不合规,不安全的答复。
后置处理主要面向的内容是大模型的输出,确保大模型输出内容送达用户端的时候保证合规性。最简单的方式为检测大模型输出内容不合规的时候,对输出内容进行整体替换。通常为了保证大模型的交互体验,会流式送达用户端,因此针对大模型输出内容的质检有一定的滞后性,这也是我们在一些产品体验中流式生成一顿后,会整体覆盖替换为另一段固定话术的原因。
整体来看,天下没有免费的午餐,打补丁的方式可以快速解决某类特定的问题,但是想从根本上提高模型能力,应对各种case,又是一个难度和成本都非常高的路径。发布于 2023-12-06 17:56・IP 属地北京查看全文>>
包包大人 - 5 个点赞 👍
01 大型语言模型LLM应用
大型语言模型LLM在多个领域有广泛应用,
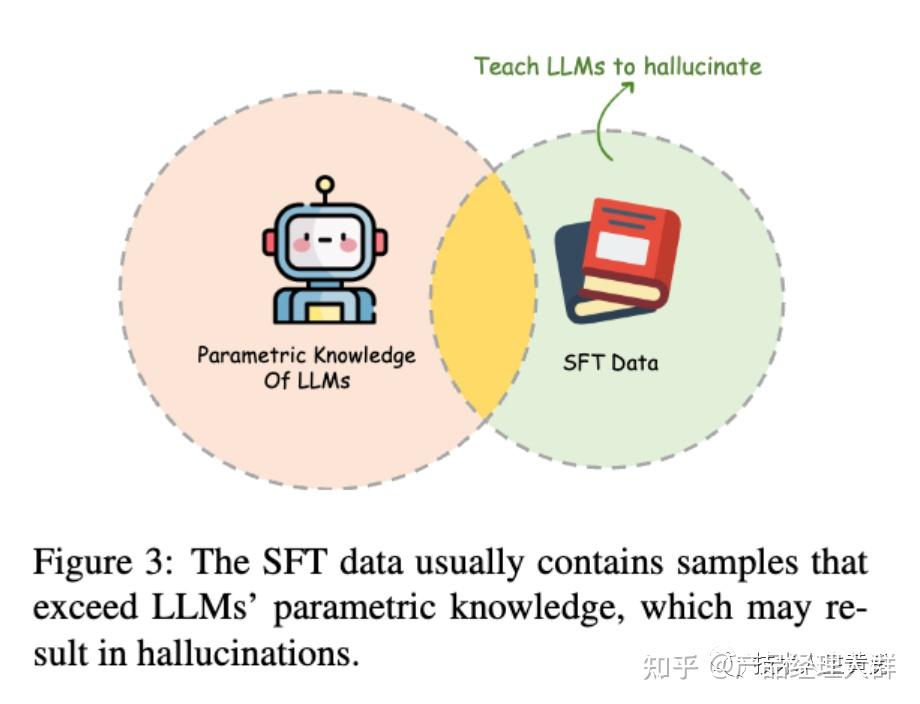
但存在幻觉的问题:即生成与用户输入不符、与先前生成的内容矛盾或与已知世界知识不符的内容。
相信朋友们在使用ChatGPT或者其他大模型过程中都遇到过这类问题,而这一现象对我们用LLM解决实际需求,构建应用造成了障碍。
本文综述了最近关于幻觉检测、解释幻觉和缓解幻觉所做的努力,重点关注了大模型LLM幻觉所面临的独特挑战。并提出了LLM幻觉现象和评估基准的分类,分析了现有的旨在缓解LLM幻觉的方法,并讨论了未来研究的潜在方向。
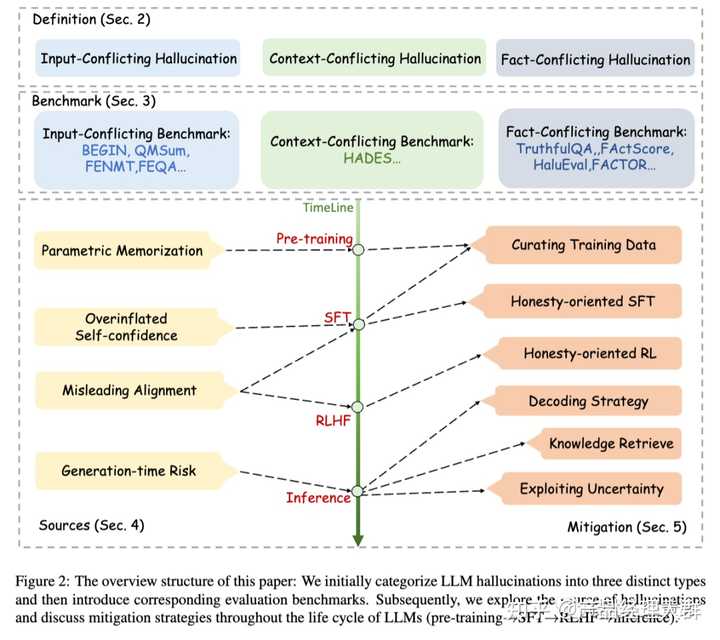

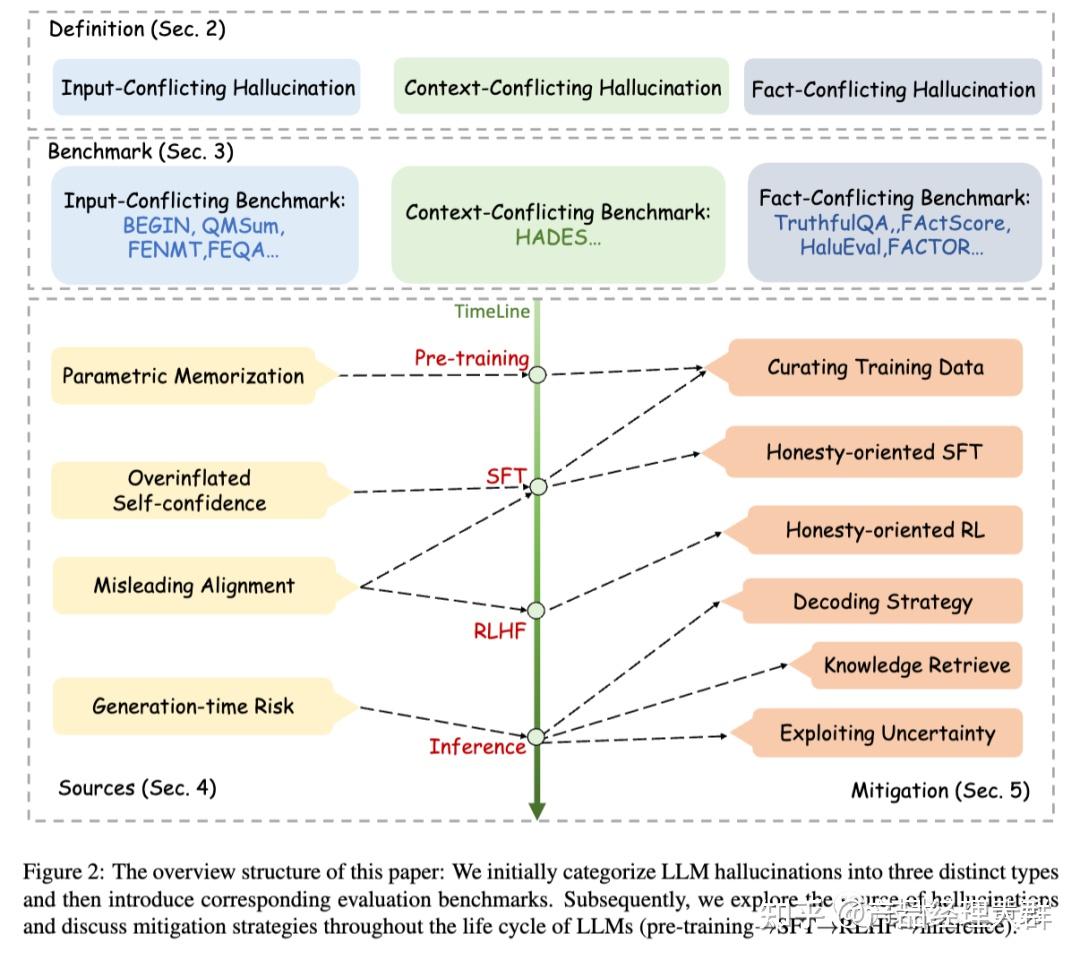
上图为论文结构图,首先将大模型LLM幻觉分为三种不同的类型(上图Definition部分),然后介绍相应的评测基准(图中Benchmark部分)。随后论文探索了幻觉的来源,并讨论了在LLMs的整个生存周期(图中timeline部分:预训练->SFT-RLHF-推理),所采取用于缓解幻觉的策略。
SFT:Self-Supervised Fine-Tuning,自监督微调。常见方法是让模型根据输入数据生成一个相关的任务,然后使用这个任务的输出来训练模型。
首先使用大规模未标记的数据对模型进行预训练。然后,使用相对较小的标记数据集对模型进行微调,以适应特定的任务或领域。这种方法通常能够在特定任务上取得良好的性能,而无需大量标记的数据。
RLHF:Reinforcement Learning from Human Feedback,即从人类反馈中进行强化学习。
RLHF 是一种训练机器学习模型的方法,其中模型通过从人类提供的反馈中学习。这种方法通常用于解决强化学习问题,其中模型需要通过与环境互动来学习最佳策略。
在 RLHF 中,人类提供了一个评估模型性能的信号,例如奖励信号,以指导模型的训练。这可以使模型在学习过程中更加高效地探索和改进策略。
02 幻觉的定义及分类
早在大模型LLM出现之前,"幻觉"(hallucination)这个概念已在NLP自然语言处理领域中被广泛使用,通常指生成无意义或不符合所提供源内容的输出。
由ChatGPT带来的大模型时代,国内外各大厂家都在陆续推出自己的大模型,然而目前大模型都存在一个普遍的现象就是:幻觉。在准确率要求非常高的场景下幻觉是不可接受的,比如医疗领域、金融领域等。
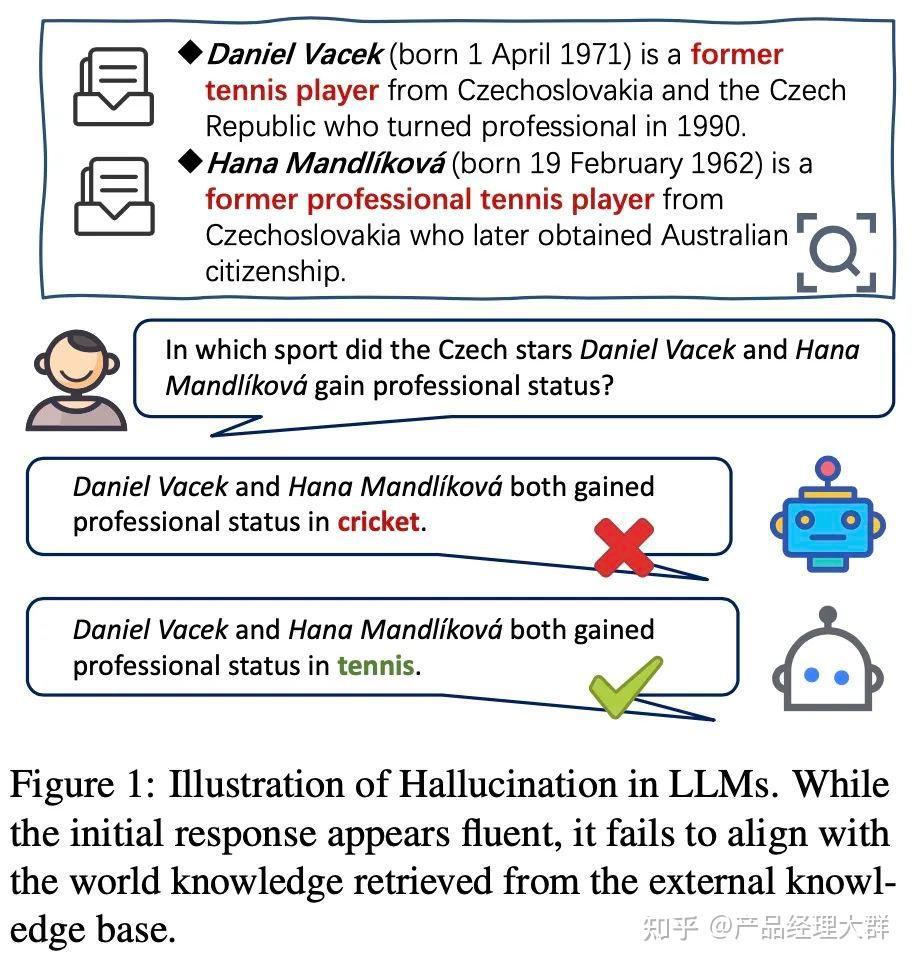
幻觉的基本定义:大模型生成看似合理的内容,其实这些内容是不正确的或者是与输入Prompt无关,甚至是有冲突的现象,幻觉示例如下图所示:
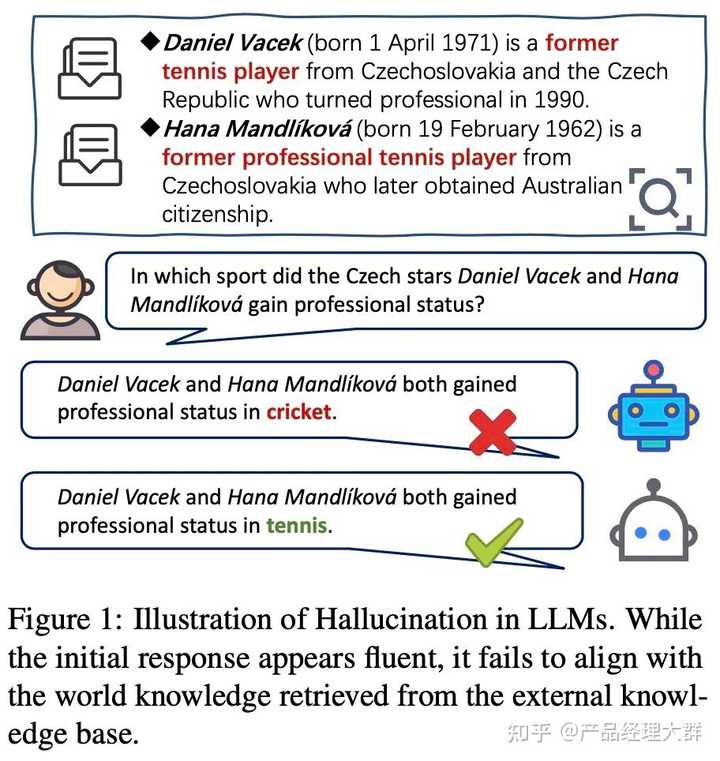

大模型出现后,产生的类似问题,也使用了“幻觉”这个概念,但是幻觉的范畴已经大大的扩展。
LLMs会产生三种幻觉:输入冲突幻觉、上下文冲突幻觉和事实冲突幻觉。前者是指生成的内容与用户提供的输入不符,后者是指生成的内容与之前生成的信息相矛盾,最后一种是指生成的内容与已知的世界知识不符。
论文认为产生幻觉的主要原因有预训练数据收集、知识GAP和大模型优化过程三个方面。数据收集:
- 预训练数据:大模型的知识和能力主要来自与预训练数据,如果预训练数据使用了不完整或者过期的数据,那么就很可能导致知识的错误,从而引起幻觉现象;
- 上下文学习:为了让大模型可以更好的输出,有时会在Prompt中增加一些上下文内容,然而这些上下文的类别和pair的顺序也可能引起幻觉,比如前几个example的标签是“是”,后面几个是“否”,那么大模型很可能就输出“否”了;
- 多语言大模型:处理少语种或者非英文翻译的问题;
知识GAP:
主要来自pre-training和fine-tuning阶段的输入数据格式不同引起的。
优化过程:
- 最大似然估计和teacher-forcing训练有可能导致一种被称为随机模仿的现象,大模型在没有真正理解的情况下模仿训练数据,这样可能会导致幻觉;
- top-k和top-p采样技术也可能导致幻觉,LLM倾向于产生滚雪球般的幻觉,以保持与早期幻觉的一致性,即使在“Let’s think step by step”这样的提示下,它们仍然会产生无效的推理链;
三种幻觉定义
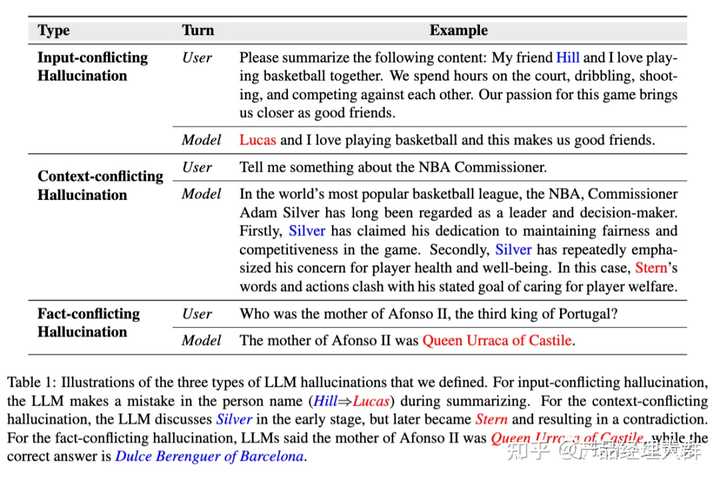

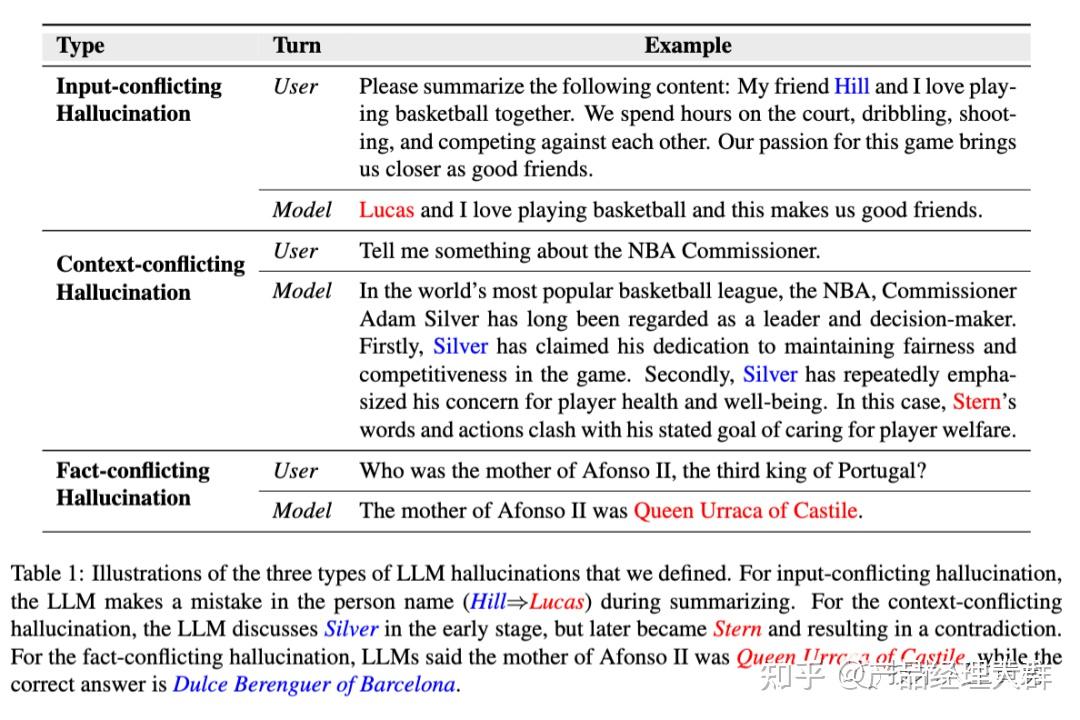
一、输入冲突幻觉 Input-conflicting
输入冲突幻觉指的是LLM生成的内容与用户提供的源输入不一致。当LLM生成的内容偏离用户的输入时,就会出现这种幻觉。
通常情况下,用户的LLM输入包括两个部分:任务指示(例如用户对摘要的提示)和任务输入(例如需要摘要的文档)。
LLM响应与任务指示之间的矛盾通常反映了对用户意图的误解。相反,当生成的内容与任务输入之间存在矛盾时,这类幻觉符合特定NLG自然语言生成任务(例如机器翻译和摘要)的常规定义。
如上图中:LLM生成摘要时,LLM在回复中错误地替换了人名(Hill→Lucas)。
二、语境冲突幻觉 Content-conflicting
语境冲突幻觉指的是LLM生成的内容与之前生成的信息相矛盾。当LLMs生成冗长或多轮回答时,可能会出现自我矛盾的情况。
这种幻觉产生于LLMs在整个对话过程中失去对上下文的跟踪或无法保持一致性时,这可能是由于在保持长期记忆或识别相关上下文方面存在一定的限制所致。
如上图中:LLM最初介绍的是Silver(现任NBA总裁),但后来又提到了Stern(前NBA总裁)。
三、与事实相冲突的幻觉 Fact-conflicating
与事实相冲突的幻觉指的是LLM生成的内容不符合既定的世界知识,也就是出现了事实冲突。
当LLM生成的信息或文本与已有的世界知识相矛盾时,就会出现这种类型的幻觉。如图2所示,事实冲突幻觉的来源可能多种多样,并可能在LLM生命周期的不同阶段出现。
如上图中:用户向LLM询问阿福诺斯二世的母亲是谁。LLM给出了一个错误的答案(卡斯蒂利亚的乌拉卡女王,而不是巴塞罗那的杜尔斯-贝伦格)
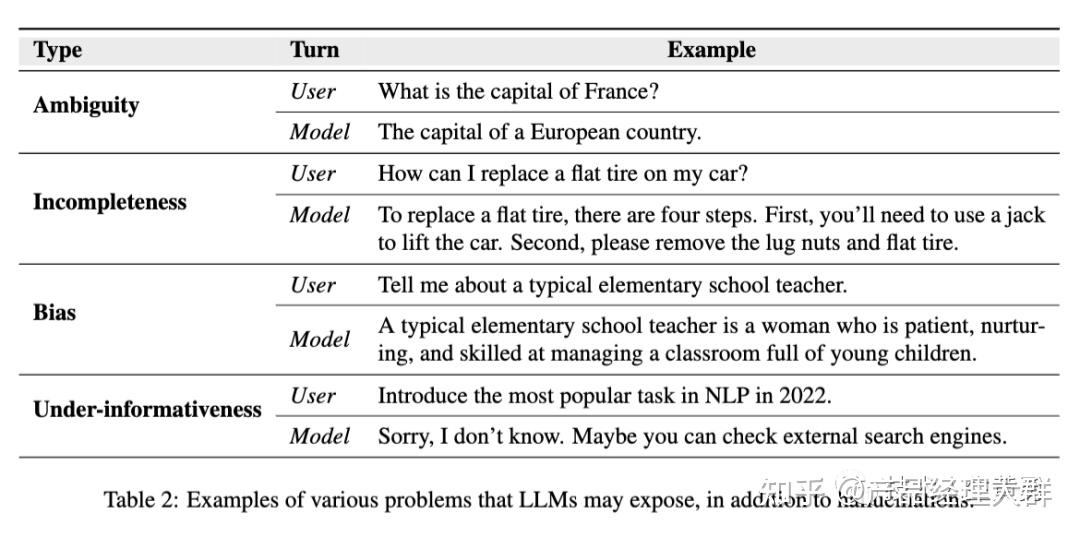
除了幻觉外,LLMs还存在其他问题。论文在下面列出了一些常见问题,并在表2中提供了示例,以区分它们和幻觉之间的区别。
- LLM回答含糊不清,无法提供有用答案,导致歧义问题。下表中的第一个例子就是这种情况。需要的答案是“巴黎”,但LLM提供了模棱两可的回答。
- 生成的回答不完整或零碎,称为不完整性问题。 LLM在更换轮胎的四个步骤中只告知用户前两个步骤,导致解释不完整。
- LLMs中的偏见指的是生成文本中表现出的不公平或有偏见的态度。这些偏见可能来自训练数据,包括历史文本、文学作品、社交媒体内容等。这些来源可能本质上反映了社会中的偏见。
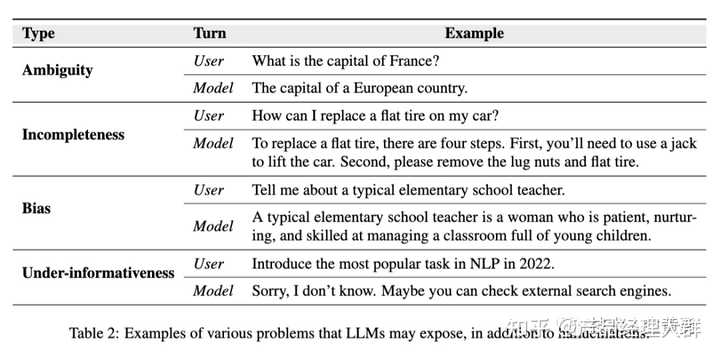

LLMs中的研究主要集中在事实冲突的幻觉上,尽管其他两种类型也很重要。可能的原因包括:
(1)在传统的自然语言生成中,输入和上下文冲突的幻觉已经得到了广泛研究。然而,在LLMs中,由于缺乏权威的知识来源作为参考,事实冲突的幻觉更具挑战性;
(2)事实冲突的幻觉对LLMs的实际应用产生了更多的副作用,因此近期的研究更加重视这一点。
鉴于这一研究现状,论文的后续部分将主要集中在事实冲突的幻觉上,并在讨论其他两种幻觉时明确强调这一点。
幻觉的分类
论文总结了常见的下游任务的幻觉现象,比如机器翻译、问答系统、对话系统、文本摘要、LLM知识图谱和视觉问答系统,结果如下表所示:

四、幻觉的分类


推理分类器:
给定问题Q和答案A,训练一个分类器,让分类器去判断生成的答案是否包含幻觉H,因此,Shen等人(2023)采用最先进的LLM对检测结果进行端到端文本生成。其他一些研究(Li et al.,2023b)发现,在输出之前添加思维链可能会干预最终判断,而检索知识则会带来收益。进一步推进这一概念,用于生成中间过程标签和高质量自然语言解释的暗示分类器和解释器(Shen et al.,2023)被证明可以从各种角度增强最终预测的类别。随后,Tam等人(2023)建议采用与生成的模型不同的分类器模型,这有助于更容易判断事实的一致性。对于放射学报告生成,可以利用二元分类器(Mahmood等人,2023)通过结合图像和文本嵌入来测量可靠性。
不确定度度量:
重要的是要检查幻觉指标与各种视角的输出质量之间的相关性。一种直观的方法是使用模型本身的概率输出。类似地,BARTSCORE(Yuan et al.,2021)采用了一个普遍的概念,即当生成的文本更好时,被训练将生成的文本转换为参考输出或源文本的模型得分会更高。这是一种无监督的度量,支持添加适当的提示来改进度量设计,而无需人工判断来训练。此外,KoK(Amayuelas et al.,2023)基于Pei和Jurgens(2021)的工作,从主观性、模糊限制语和文本不确定性三个类别来评估答案的不确定性。然而,SLAG(Hase等人,2023)在转述、逻辑和蕴涵方面衡量了一致的事实信念。除此之外,KLD(Pezeshkpour,2023)结合了基于信息理论的度量(例如熵和KL散度)来捕捉知识的不确定性。除了专家提供的方案监督外,POLAR(赵等人,2023b)引入了帕累托最优学习评估风险评分,用于估计响应的置信水平;
自我评估:
自我评估是一种挑战,因为模型可能对其生成的样本的正确性过于自信。SelfCheckGPT(Manakul et al.,2023)的动机是利用LLM自身的能力对多个响应进行采样,并通过测量响应之间的信息一致性来识别虚构陈述。Kadavath等人(2022)进一步说明,规模的增加和评估的展示都可以改善自我评估。除了重复的多个直接查询,Agrawal等人(2023)使用开放式间接查询,并将其答案相互比较,以获得一致的分数结果。自矛盾(Mündler et al.,2023)对同一LLM施加了适当的约束,以生成触发自矛盾的成对传感器,从而促使检测。相反,基于轮询的查询(Li et al.,2023i)通过随机抽样查询对象来降低判断的复杂性。此外,Self-Checker(Li et al.,2023d)将复杂的语句分解为多个简单的语句,逐一进行事实核查。然而,Cohen等人(2023)引入了两个LLM交互交叉询问,以推动复杂的事实核查推理过程;
证据检索:
证据检索通过检索与幻觉有关的支持性证据来辅助事实检测。为此,设计一个以索赔为中心的管道允许问题检索摘要链有效地收集原始证据(Chen et al.,2023b;霍等人,2023)。因此,FActScore(Min等人,2023)计算给定知识源支持的原子事实的百分比。为了适应用户与生成模型交互的任务,FacTool(Chern et al.,2023)提出将各种工具集成到任务不可知和领域不可知的检测框架中,以收集有关生成内容真实性的证据。
03 如何评估
针对不同类型的幻觉,采用的评估方式不一样。
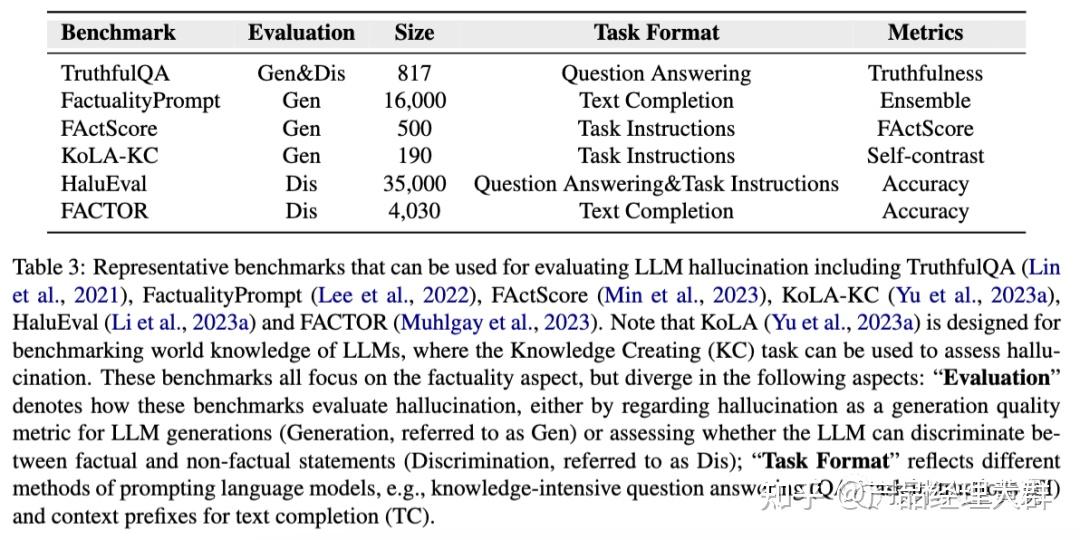
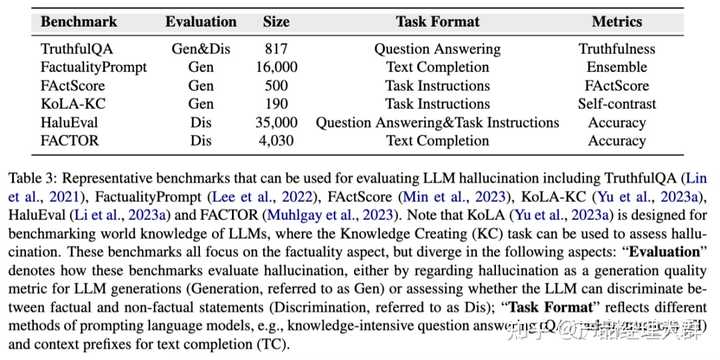
1、评估基准
现有针对幻觉的工作,提出了各种基准来评估LLM中的幻觉,如下表所示:

1、评估形式
现有的基准主要根据LLMs的两种不同能力来评估幻觉:生成事实陈述或区分事实陈述与非事实陈述的能力。下表说明了这两种评估形式的区别。


Generation 生成基准将幻觉看作一种生成特征,类似于流畅度和连贯性,并对LLM生成的文本进行评估。例如,TruthfulQA用于评估大型模型对问题的回答的真实性,而FactScore则用于评估大型模型生成的个人传记的事实准确性。
Discrimination 判别式基准考察大型模型区分真实陈述和幻觉陈述的能力。具体来说,HaluEval要求模型确定状态信息是否包含幻觉信息,而FACTOR则研究LLM是否更可能生成事实陈述而非非事实陈述。
在这些基准中,TruthfulQA是一种特殊的基准,兼具生成喝判别式两种基准,提供了一个多项选择的替代方案,以测试模型区分真实陈述的能力。
这些基准,都需要人类注释者来创建数据集或保证质量。
TruthfulQA的设计目的是故意诱导模型产生模仿性错误,即在训练数据中有高概率的错误陈述。随后,利用人工标注对其进行验证,以确保其与真实答案一致。
FActScore通过人工标注将由模型生成的长文本转化为原子语句片段。
HaluEval采用了两种构建方法。在自动生成方面,设计了提示来查询ChatGPT,以提取不同的幻觉并自动过滤出高质量的幻觉。在人工标注方面,通过让人工标注员标注模型回复中是否存在幻觉,并记录相应的跨度。
FACTOR首先利用外部LLM生成非事实知识。然后,通过手动验证自动创建的数据集是否符合预先设定的要求,即它们应该是非事实性的、流畅的,并且与事实性的完成相似。
2、评估标准
语言生成的自由和开放性使得评估LLMs产生的幻觉变得困难。评估幻觉的最常用和可靠的方法依赖于遵循特定原则的人类专家。现有的基准虽然使用人工评估来确保可靠性,但也致力于支持自动方法以促进高效和一致的评估。
人工评估
TruthfulQA引入了一个人工标注指南,指导标注者为模型输出分配十三个定性标签中的一个,并通过咨询可靠来源来验证答案的准确性。
FactScore要求注释者为每个原子事实分配三个标签:"支持"或"不支持"。"支持"或"不支持"表示知识源支持或不支持的事实,"无关"表示与提示无关的陈述。
人工评估文本摘要的可靠性和可解释性高,但由于主观性,不同的评估者可能会产生不一致的结果。此外,由于需要进行劳动密集型的注释过程,人工评估的成本也很高。因此,需要寻找更有效的评估方法。
几项研究提出了基于模型的自动评估方法,包括TruthfulQA、AlignScore、Min等。这些方法利用模型对答案进行分类、评估文本之间的事实一致性等,能够有效代替人工评估。
自动评估
TruthfulQA利用一个经过微调的GPT-3-6.7B模型,根据问题的注释对答案进行分类(真假)。根据工作介绍,这个经过微调的GPT模型在验证准确率方面达到了90-96%的水平,并且能够有效地适应新的答案格式。
AlignScore创建了一个通用的评估函数,用于评估两个文本之间的事实一致性。该对齐函数是在一个包括自然语言推理(NLI)、问题解答(QA)和仿写等七项任务的大型数据集上进行训练的。
FactScore首先利用通道检索器(例如基于通用T5的检索器)来收集相关信息。随后,采用评估模型(如LLaMA-65B),利用检索到的知识来确定状态的真实性,并进一步使用微观F1分数和误差率等指标来评估自动评估与人工评估之间的可靠性对比情况。
04 幻觉的来源
1、大模型缺乏相关知识或内化错误知识
LLMs在预训练阶段积累了大量的知识,但可能缺乏相关知识或内化了错误的知识。在回答问题或完成任务时,LLMs使用存储在模型参数中的知识。如果模型缺乏相关知识或内化了错误的知识,它们可能会展示出幻觉。
例如:语言模型有时会将虚假的相关性(如位置接近或高度共现的关联)误解为事实知识。有研究在自然语言推理任务中研究了幻觉问题,并发现语言模型的幻觉与训练数据的分布之间存在强相关性。
同时,有研究发现幻觉也存在于人类生成的语料库中,这可能表现为过时、偏见或虚构的表达。此外,Zheng等人发现,知识的回忆和推理能力与语言模型提供真实答案有关,这两种能力的不足可能导致幻觉。
2、大模型有时会高估自己的能力
研究表明,语言模型可以自我评估回答的正确性和识别自己的知识边界。但对于非常大的语言模型,正确和错误答案的分布熵可能相似,表明它们在生成错误答案和正确答案时同样自信。此外,即使是最先进的语言模型GPT4也存在无法回答问题的问题,且其自信度常常超过其实际能力。
大模型LLMs在法律知识边界方面的理解可能不够准确,常常表现出过度自信。这种过度自信会导致LLMs以不必要的确定性编造答案。
3、有问题的对齐过程可能会误导大模型产生幻觉
大模型LLMs的对齐过程可能会导致幻觉,特别是当它们没有从预训练阶段获得先决知识时。此外,大模型LLMs可能会出现谄媚现象,导致生成的回答偏向用户的观点而不是正确或真实的答案。
4、大模型采用的生成策略存在潜在风险
大模型LLMs生成回应时,通常是逐个输出标记。然而,研究发现LLMs有时会过度坚持早期的错误,即使它们意识到错误。这种现象被称为幻觉积累。此外,局部优化(标记预测)并不一定能确保全局优化(序列预测),早期的局部预测可能导致LLMs难以产生正确的回应。采用采样生成策略(如top-p和top-k)引入的随机性也可能导致幻觉的产生。
幻觉解决方案
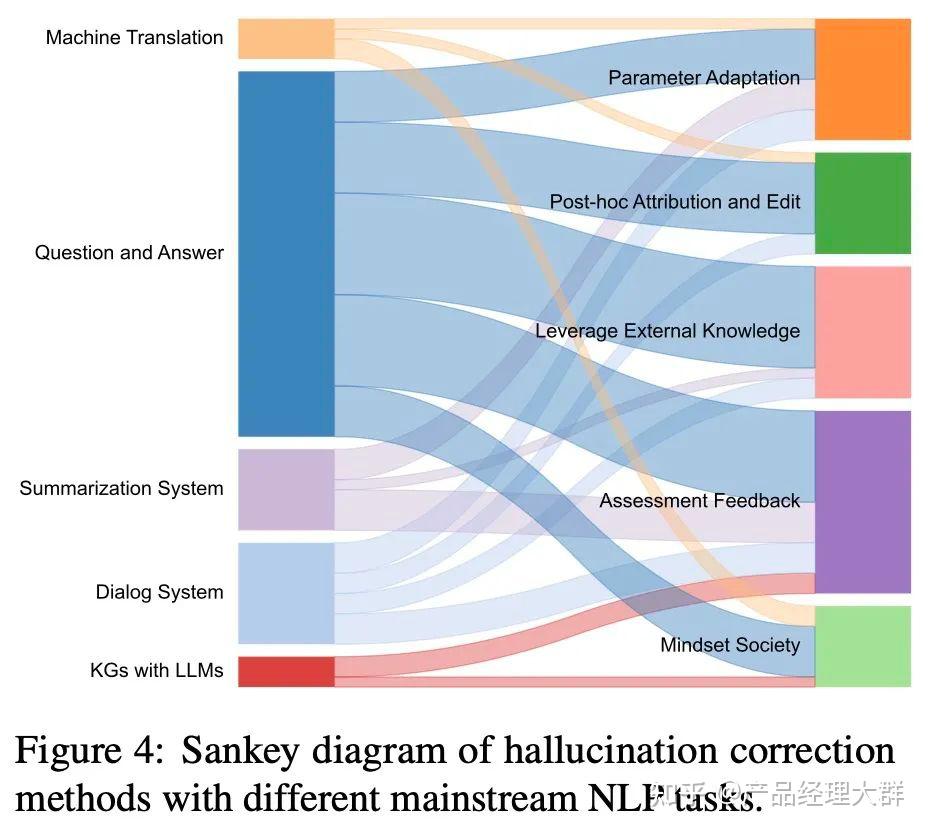
论文总结了五种解决幻觉的方法,具体如下图所示:


不同下游任务解决幻觉的方法不同,具体如下图所示:
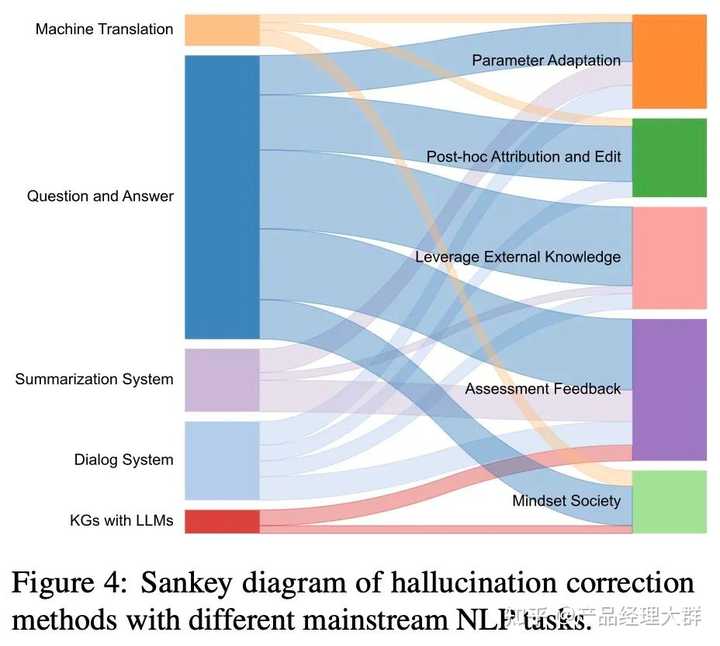

参数自适应:
LLM中的参数存储了预训练中学习到的偏见,这些偏见通常与用户意图不一致。一般策略是通过参数调节、编辑和优化来引导有效的知识。例如,CLR(Sun等人,2023)利用对比学习参数在跨度水平上进行优化,以降低负面样本的生成概率。在引入与模型的内在先验知识相矛盾的上下文知识边缘背景的同时,TYE(Shi et al.,2023a)通过上下文感知解码方法有效地降低了先验知识的权重。此外,PURR(Chen et al.,2023a)将噪声腐蚀到文本中,微调紧凑的编辑器,并通过合并相关证据来去噪。为了引入额外的缓存组件,HISTALIGN(Wan et al.,2023)发现其隐藏状态与当前隐藏状态不一致,并提出了序列信息对比学习以提高内存参数的可靠性。因此,Edit TA(Ilharco等人,2023)从任务算法的角度缓解了在预训练中学习到的问题。其背后的直觉是,通过负示例任务学习到的参数变化可以通过权重变化来感知。然而,由于这没有考虑到不同反例的重要性,因此EWR(Da-heim et al.,2023)提出了Fisher信息模型来测量其估计的不确定性,该模型用于对话系统执行参数插值并消除幻觉。EasyEdit(Wang et al.,2023c)总结了参数编辑的方法,同时将对无关参数的影响降至最低。
一个有效的替代方法是识别特定于任务的参数并利用它们。例如,ALLM(Luo et al.,2023)将参数模块与特定任务的知识对齐,然后在背景增强提示中生成相关知识作为附加上下文。类似地,mmT5(Pfeiffer et al.,2023)在预训练期间利用特定语言模块将特定语言信息与独立于语言的信息分离,表明添加特定语言模块可以消除多语性的诅咒。相反,TRAC(Li et al.,2023f)将保角预测和全局测试相结合,以增强基于检索的QA。保守策略公式确保在预测集中包括与真实答案在数量上等效的答案。
另一个参数自适应思想侧重于符合用户需求的灵活采样。例如,Lee等人(2022)观察到,当生成句子的后半部分时,抽样的随机性对事实更不利。为了在保证生成质量和多样性的同时保持生成的忠实性,引入了事实核采样算法。此外,推理时间(Li et al.,2023c)首先识别出一组具有高线性探测精度的注意头,然后沿着与事实知识相关的方向转移推理过程中的激活。
事后归因和编辑技术:
幻觉的一个来源是LLM可能会利用预训练数据中观察到的模式,以一种新的形式进行推理。最近,ORCA(Han和Tsvetkov,2022)通过从预训练数据探索支持数据证据,揭示了模型行为中的问题模式。同样,TRAK(Park et al.,2023)和Data Portraits(Marone和Durme,2023。QUIP(Weller等人,2023)进一步证明,提供在预训练阶段观察到的文本可以提高LLM生成更多实际信息的能力。此外,由于LLM和人类思维模式之间的差距,一种直觉是将两种推理模式结合起来。因此,CoT(Wei et al.,2022b)通过一种思维链(CoT)(Kojima et al.,2022)提示引发了忠实的推理。类似地,RR(He等人,2023)基于从CoT提示获得的分解推理步骤来检索相关的外部知识。由于LLM通常不会在第一次尝试时产生最佳输出,因此自精化(Madaan et al.,2023)通过迭代反馈和改进来实现自精化算法。反思(Shinn等人,2023)还采用言语强化,通过学习先前的失败来产生反思性反馈。Verify-and-Edit(赵等人,2023a)提出了一种CoT提示的验证和编辑框架,该框架通过基于外部检索的知识对推理链进行后编辑来提高预测的逼真度。幻觉的另一个来源是用不正确的检索来描述事实内容。为了说明这一点,NP Hunter(Dziri et al.,2021)遵循一种先生成后细化的策略,即使用KG修改生成的响应,以便对话系统化,通过查询KG来纠正潜在的幻觉。
利用外部知识:
为了扩展语言模型以减少歧义,建议从大型文本数据库中检索相关文档。RETRO(Borgeud et al.,2022)将输入序列分割成块并检索相似的文档,而In-Context RALM(Tam et al.,2023)将所选文档放在输入文本之前以改进预测。此外,IRCoT(Trivedi等人,2023)将CoT生成和文档检索步骤交织在一起,以指导LLM。由于缩放主要提高了公共知识的内存,但并没有显著提高长尾中事实知识的内存。因此,POPQA(Mallen et al.,2023)在必要时仅检索非参数内存以提高性能。LLM-AUMMENTER(Peng et al.,2023)还将LLM的回答建立在综合外部知识和自动反馈的基础上,以提高答案的真实性得分。另一项工作,CoK(Li et al.,2023h)迭代分析即将到来的句子的未来内容,然后将它们作为查询来检索相关文档,以便在句子包含低可信度令牌时重新生成句子。类似地,RETA-LLM(Liu et al.,2023c)创建了一个完整的管道,以帮助用户构建自己的基于域的LLM检索系统。请注意,除了文档检索之外,还可以将各种外部知识查询组合到检索增强的LLM系统中。例如,FLARE(Jiang et al.,2023)利用结构化知识库来支持复杂的查询,并提供更直接的事实陈述。此外,KnowledGPT(Wang et al.,2023e)采用了思想程序(PoT)提示,生成代码与知识库交互。而cTBL(Ding et al.,2023)提出在会话设置中使用表格数据来增强LLM。此外,GeneGPT(Jin et al.,2023)证明,通过上下文学习和增强解码算法检测和执行API调用,可以更容易、更准确地访问专业知识。为了支持潜在的数百万不断变化的API,Gorilla(Patil et al.,2023)探索了自我构造的微调和检索,以高效利用API。
评估反馈:
随着语言模型变得越来越复杂,评估反馈可以显著提高生成文本的质量,并减少幻觉的出现。为了实现这一概念,LSHF(Stiennon等人,2020)通过模型预测了人类偏好的总结,并将其作为奖励函数,使用强化学习来微调总结策略。然而,这种方法建立在人工注释器构建的模型之上,这使得它们在数据利用率方面效率低下。因此,TLM(Menick et al.,2022)提出通过从人类偏好中强化学习,通过选择几个拒绝回答的问题来提高系统的可靠性,这显著提高了系统的可靠性。而强化学习往往存在不完美的奖励函数,并依赖于具有挑战性的优化。因此,后见链(Liu et al.,2023a)将反馈偏好转化为句子,然后将其输入到模型中进行微调,以增强语言理解。
除了使模型能够以样本有效的方式直接从事实指标的反馈中学习(Dixit et al.,2023)外,建立模型的自我评估功能以过滤候选生成的文本也很重要。例如,BRIO(Liu et al.,2022)提出了摘要模型评估,估计候选输出的概率分布,以评估候选摘要的质量。而LM know(Kadavath et al.,2022)致力于调查LLM是否可以通过检测他们知道问题答案的概率来评估他们自己主张的有效性。随后,Do LLM Know(Agrawal et al.,2023)专门使用黑盒LLM进行查询,并将多次重复生成的查询结果相互比较,以通过一致性检查。此外,黑盒LLM增加了即插即用检索模块(Liu et al.,2023a;Huang et al.,2021),以生成反馈,从而提高模型响应。
由于遗漏引文质量评估影响最终表现,ALCE(Gao et al.,2023c)采用自然语言推理模型来衡量引文质量,并扩展了综合检索系统。类似地,CRITIC(Gou et al.,2023)建议与适当的工具进行交互,以评估文本的某些方面,然后根据验证过程中获得的反馈修改输出。请注意,自动错误检查还可以利用LLM生成符合工具界面的文本。PaD(Zhu et al.,2023c)通过综合推理程序提取LLM,获得的综合程序可以由程序员自动编译和执行。此外,迭代精化过程被验证可以有效地识别适当的细节(Ning et al.,2023;张等人,2023b;余等人,2023b),并且可以停止早期无效的推理链,有益地减少幻觉滚雪球的现象(张等人,2021)。
心态社会:
人类的智慧源于认知协同的概念,不同认知过程之间的协作比孤立的个体认知过程产生更好的结果。“心智社会”(Minsky,1988)被认为有可能显著提高LLM的性能,并为语言产生和理解的一致性铺平道路。为了在不同翻译场景的大规模多语言模型中解决幻觉,HLMTM(Guerreiro et al.,2023a)提出了一种混合设置,在该设置中,当原始系统产生幻觉时,可以请求其他翻译系统作为备份系统。因此,多主体辩论(Du et al.,2023)在几轮中使用多个LLM来提出和辩论他们的个人反应和推理过程,以达成一致的最终答案。由于这一过程,鼓励模型构建与内部批评和其他主体反应一致的答案。在给出最终答案之前,所得到的模型社区可以同时保持和维护多个推理链和可能的答案。基于这一想法,MAD(Liang et al.,2023)增加了一个法官管理的辩论过程,表明辩论的适应性中断和受控的“针锋相对”状态有助于完成事实辩论。此外,FORD(Xiong et al.,2023)提出了包括两个以上LLM的圆桌辩论,并强调有能力的法官对主导辩论至关重要。LM与LM(Cohen et al.,2023)还提出了LM与另一个LM之间的多轮交互,以检查原始陈述的真实性。此外,PRD(Li et al.,2023e)提出了一个基于同行排名和讨论的评估框架,以得出所有同行都同意的公认评估结果。为了保持强有力的推理,SPP(Wang et al.,2023g)利用LLM来分配几个细粒度的角色,这有效地刺激了知识获取并减少了幻觉。
缓解幻觉的产生贯穿于整个大模型预训练、研发和应用三个阶段。
01 预训练阶段的缓解
LLM的知识主要在预训练阶段获取,预训练语料中的噪声数据可能会破坏LLM的参数知识,导致幻觉。
因此,减少不可验证或不可靠数据的预训练语料可能是缓解幻觉的一种直观方法。有研究表明,可以追溯LLM获取的事实知识产生于其训练的数据。
在LLM时代之前,人们通过手动清理训练数据来减少幻觉。Gardent等人和Wang都采用了人工修正的方法,有效地减少了幻觉。同样,在现有的表格到文本数据集中对文本进行人工提炼这一过程也大大减少了事实幻觉。Parikh等人则通过修改维基百科中的句子来构建数据集,也取得了改善结果的效果。
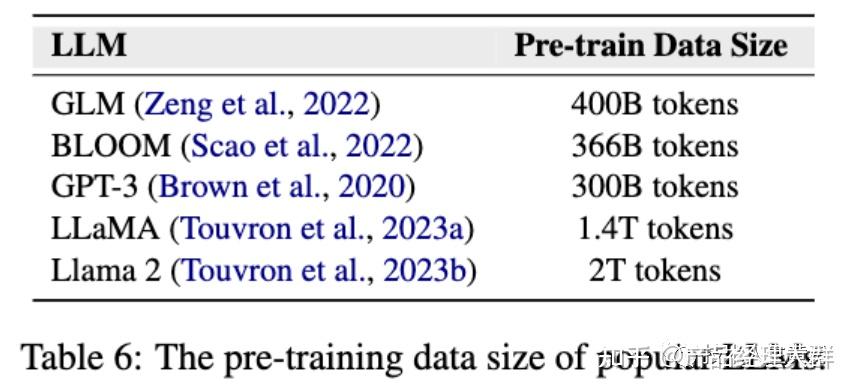
随着LLM时代的到来,由于预训练语料库的规模巨大,手动筛选训练数据变得越来越具有挑战性。
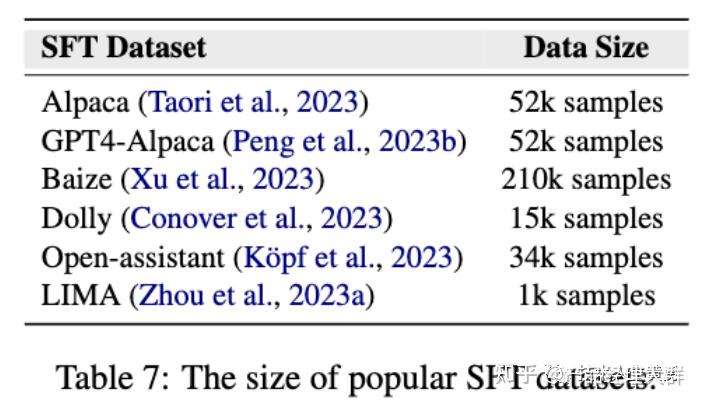
如下图所示,几个常见的大模型预训练使用的语料库的数据量
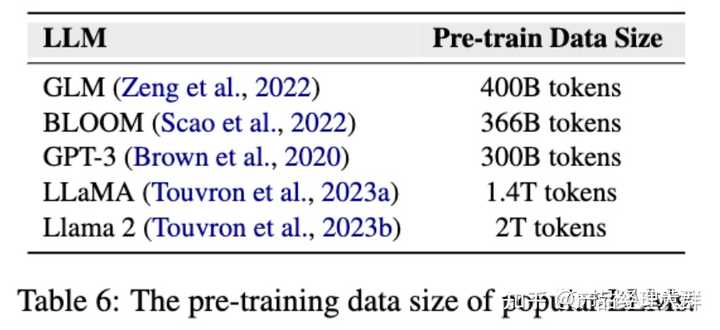

Llama2达到了大约两万亿个token的数据规模。因此,与人工整理相比,目前更实用的方法是自动选择可靠数据或过滤掉噪声数据。
GPT-3的预训练数据是通过使用相似性来清理的。
Falcon通过巧妙地启发式规则提取网络中的高质量数据,并证明适当分级的相关语料库可以生成强大的LLM。
Llama2在构建预训练语料库时,从高度可信的来源如维基百科中提取数据。
有些研究在事实性文档的句子前加入主题前缀,使每个句子在预训练时都被看作一个独立的事实,以文档名称作为主题前缀。实践结果表明,这种方法提升了LLM在TruthfulQA评测基准(一种幻觉评测基准)上的表现。
总之,在预训练过程中,降低"晕轮"现象的关键是有效整理预训练语料库。鉴于现有的预训练语料库规模巨大,目前的研究主要采用简单的启发式规则来选择和过滤数据。将来可能的研究方向是设计更为有效的选择或过滤策略。
02 SFT阶段的缓解
SFT:Self-Supervised Fine-Tuning,自监督微调。常见方法是让模型根据输入数据生成一个相关的任务,然后使用这个任务的输出来训练模型。
当前的LLMs通常会进行监督微调(SFT)的过程,以利用他们从预训练中获得的知识,并学习如何与用户进行交互。SFT的一般步骤是先注释或收集大量的任务指导数据,然后使用最大似然估计(MLE )对预训练的LLMs进行微调。通过采用精心设计的SFT策略,许多最近的研究声称已经构建了与ChatGPT相媲美的LLMs。
最大似然估计(Maximum Likelihood Estimation,MLE)是统计学中一种常用的参数估计方法。它的基本思想是在给定观测数据的情况下,通过调整模型的参数使得观测数据出现的概率最大化,也就是找到最可能产生观测数据的参数值。
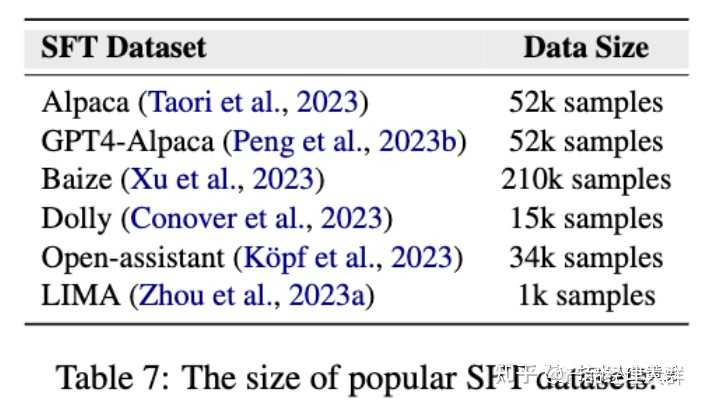

为了减少SFT阶段的幻觉,可以通过筛选训练数据来进行。如上图所示,SFT数据量相对较小(最大为210K),手动和自动筛选都是可行的选项。
一些研究使用人工专家注释的指令调整数据集,或者利用LLMs作为评估器或设计特定规则来自动选择高质量的指令调整数据。
实验结果表明,在幻觉相关的基准测试中,使用经过筛选的指令数据进行微调的LLMs相比使用未筛选数据进行微调的LLMs具有更高的真实性和事实性水平(如Truth-fulQA)。
此外,还有一些研究提出将领域特定的知识集成到SFT数据中,旨在减少由于缺乏相关知识而产生的幻觉。
SFT过程可能会导致LLMs出现幻觉,因为它们通过行为克隆来学习。行为克隆是强化学习中的一个概念,它只是模仿专家的行为而没有学习实现最终目标的策略。
LLMs的SFT过程可以看作是行为克隆的一种特殊情况,它们通过模仿人类的行为来学习交互的格式和风格。但是,尽管LLMs已经将大量知识编码到它们的参数中,但仍有超出它们能力范围的知识存在。因此,通过克隆人类行为来进行SFT可能会导致LLMs出现幻觉。
行为克隆是强化学习中的一个概念,问题在于:行为克隆这种方法只是简单地模仿行为,而没有学习实现最终目标的策略。
LLMs的SFT过程可被视为行为克隆的一个特殊案例,通过克隆SFT过程中的人类行为,在回答问题时,模型往往会以积极的态度回应,而不考虑自己的知识范围。这可能导致模型在回答未学习到的知识相关的问题时产生错误回答。
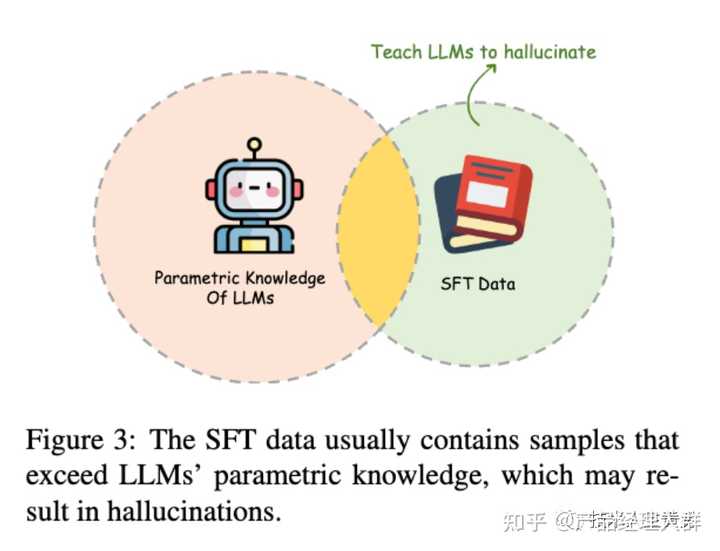

为了解决这个问题,可以引入一些诚实的样本,即承认无能力回答的回答。通过使用这些诚实的样本(指的是承认自己无能的回答,如"对不起,我不知道",即我们常说的拒答)进行调优,模型可以学会拒绝回答特定的问题,从而减少错误回答。
为了减少SFT阶段的幻觉,筛选训练数据是一种方法。最近进行的人工检查发现一些常用的合成SFT数据中存在大量幻觉答案,这需要研究人员在构建基于自我指导的SFT数据集时注意。
总结:SFT过程可能会引入幻觉,因为它会强制LLMs回答超出其知识范围的问题。整理训练数据是在SFT阶段减少幻觉的一种方法,可以由人类专家对其进行人工整理。另一个方案则以诚实为导向的SFT作为解决方案。
诚实导向的SFT方法存在两个主要问题:
- 对于分布外(OOD :Out-of-Distribution,表示在训练模型时,模型所见过的数据分布之外的数据)的情况具有有限的泛化能力,
- 诚实样本只反映了注释者的无能和不确定性,而不是LLMs的知识边界。
这些挑战使得在SFT过程中解决这个问题不够理想。
03 RLHF阶段的缓解
RLHF:Reinforcement Learning from Human Feedback,即从人类反馈中进行强化学习。
在 RLHF 中,人类提供了一个评估模型性能的信号,例如奖励信号,以指导模型的训练。这可以使模型在学习过程中更加高效地探索和改进策略。
现在许多研究人员试图通过人类反馈的强化学习来进一步改进监督微调的LLMs。这个过程包括两个步骤:
- 训练一个奖励模型作为人类偏好的代理,旨在为每个文本分配适当的奖励值;
- 使用RLHF算法来微调LLMs,以最大化奖励模型的输出。
人类的反馈可以缩小机器生成内容和人类偏好之间的差距,帮助语言模型与期望的标准保持一致。目前常用的标准是“3H”,即有帮助(Help)、诚实(Honest)和无害(Harmless)。诚实就是减少语言模型回答中的幻觉。
现有的大语言模型LLMs已经考虑了这一方面,如InstructGPT、ChatGPT、GPT4(Ope-nAI,2023年b)和Llama2-Chat,在RLHF过程中都考虑到了这一方面。
例如,GPT4使用合成幻觉数据来训练奖励模型并执行RL(强化学习),从而将Truth-fulQA(幻觉基准测试)的准确率从约30%提高到60%。
此外,还可以使用过程监督来检测和减少推理任务中的幻觉,并为每个中间推理步骤提供反馈。
上一节提到:在SFT阶段,行为克隆现象可能导致幻觉。一些研究人员尝试通过将真实样本整合到原始SFT数据中来解决这个问题。然而,这种方法存在一些限制:如不令人满意的分布外(OOD)泛化能力和人类与LLM知识边界之间的不一致。
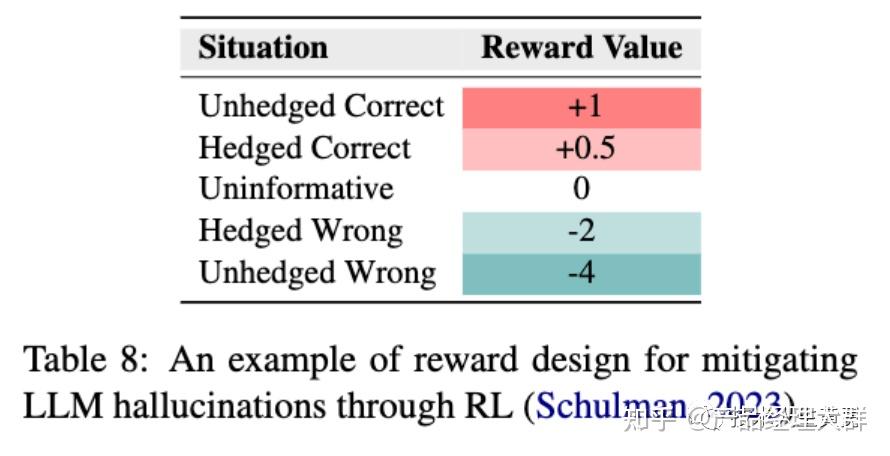
为了解决这个问题,Schulman(2023)在RLHF阶段设计了一个特殊的奖励函数来缓解幻觉,具体内容见下图。核心思想是鼓励LLM挑战前提、表达不确定性和提供不具信息量的答案。
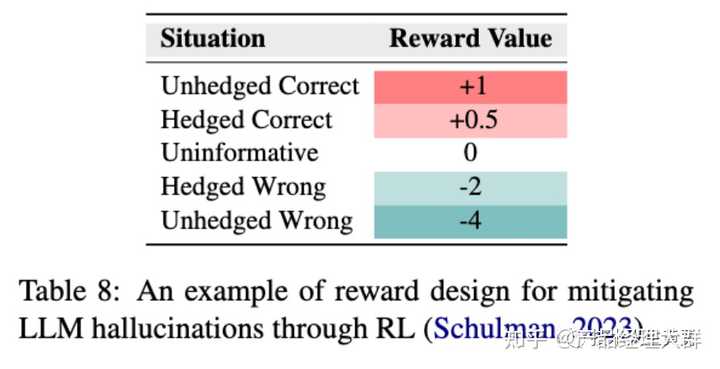

在强化学习中,大模型LLM会与环境进行交互,以学习一种策略,该策略帮助大模型在特定任务中获得最大的累积奖励。大模型在学习过程中不断尝试不同的行动,并根据环境的反馈来调整它的策略。
“Unhedged/Hedged” 表示LLM用积极或者犹豫的语气提供回答。
“Correct/Wrong”表示回答是正确或者是错误。
“Uninformative” 表示“我不知道”这样的安全答案。
从上图的奖励分数可以看到,这个奖励函数对正确的答案都是正向奖励,不管模型是用积极还是犹豫的语气,这个奖励策略鼓励了模型在最大化的探索知识的边界,同时防止了模型回答超过其能力范围的问题。
这种新的学习方法——基于诚实的强化学习(honesty-oriented RL)可以帮助语言模型自由探索知识边界,提高其对于OOD情况的泛化能力,同时减少人工标注的需求和标注者猜测知识边界的困难。
强化学习可以帮助语言模型在探索知识边界时拒绝回答超出其能力范围的问题,避免编造虚假回答。但是,这种方法也存在挑战,例如可能会出现过度保守的情况,导致帮助性和诚实性之间的平衡失衡。


如上图所示,这是ChatGPT (2023年7月版)过度保守现象的一个真实例子:第一次问答中,用户让ChatGPT 介绍电影《The Only Thing》,随后询问《The Only Thing》是什么类型电影?
但是ChatGPT拒绝回答它已经知道的相当明确的答案:“是一部戏剧电影”。因为在第一次回答中,ChatGPT已经在回答中表明它知识中有这个问题的答案:截图中以红色标注部分。
04 生成推理阶段的缓解
与训练阶段缓解幻觉的方法相比,缓解推理阶段中的幻觉可能更具成本效益和可控性。因此,大多数现有研究都集中在这个方向上:设计解码策略、借助外部知识。
一、设计解码策略
解码策略决定了我们如何从模型生成的概率分布中选择输出标记。论文提出了三种改进的解码策略:事实核心采样解码,推理-时间干预(ITI)方法,上下文感知解码(CAD)策略。
1. 事实核心采样解码
Lee等人对LLMs生成的内容进行了事实性评估,并发现核心采样(即top-p采样)在事实性方面不如贪婪解码。他们认为这种表现可能归因于top-p采样引入的随机性,以增加多样性,但可能会无意中导致幻觉,因为LLMs倾向于捏造信息以生成不同的响应。
Top-p 核心采样是一种生成文本或序列的采样方法,通常应用于自然语言处理任务。p 代表一个介于 0 和 1 之间的概率阈值。
首先,根据模型的输出概率分布对词汇表中的词进行排序,然后选择概率总和最高的词,直到这些词的累积概率超过了阈值 p,形成一个候选词集合。接下来,模型会从候选词集合中进行随机抽样,以生成最终的词语。这个过程可以在每个时间步都进行,以生成完整的序列。
Top-p 核心采样的优点在于能够在保持多样性的同时,避免生成过于散乱或不连贯的输出。通过动态地调整阈值 p,可以在需要多样性时放宽约束,在需要更严格的控制时收紧约束。这种采样方法在自然语言生成任务中经常使用,如文本生成和对话生成,有助于生成器在保持多样性的同时保持输出的合理性。
因此,他们引入了一种名为“事实核心采样”的解码算法,旨在通过利用top-p和贪婪解码的优势,更有效地平衡多样性和事实性。
2. 推理时间干预
Li等人提出了一种新颖的推理时间干预(ITI:Iterative Time Intervention)方法,以提高LLM的真实性。该方法基于LLM具有与事实相关的潜在可解释子结构的假设。ITI方法包括两个步骤:
- 在LLM的每个注意力头部上拟合一个二元分类器,以识别一组在回答事实性问题时具有更高线性探测准确性的头部,
- 在推理过程中沿着这些与事实相关的方向移动模型激活。
ITI方法在TruthfulQA基准测试中显著提高了性能。
3. 上下文感知解码CAD
其它研究探讨了检索增强设置下的语言模型问题,发现语言模型在处理下游任务时,有时无法充分关注检索到的知识,特别是当检索到的知识与参数化知识相冲突时。
为了解决这个问题,研究提出了一种上下文感知解码策略,即Context-Aware Decoding,CAD方法,通过对比两种生成概率分布,促使语言模型更多地关注上下文信息,从而减少下游任务中的事实幻觉。实验结果表明,CAD方法有效地提高了语言模型利用检索到的知识的能力。
设计解码策略以缓解LLM在推理过程中的幻觉,因其无需对模型进行大规模的重新训练或调整,通常是一种即插即用的方式。因此,这种方法易于部署,对实际应用具有潜力。
对于这种方法,大多数现有的工作就需要访问令牌级别的输出概率:这意味着我们希望知道在生成文本时,模型对于每个位置上可能的词或符号的预测概率。这对于选择下一个单词或字符至关重要。
然而,受到计算资源和模型设计的限制,大多数现有的大型语言模型(LLM)可能无法提供完整的令牌级别的输出概率信息。相反,它们可能只能返回一个生成的序列,而不提供每个位置上所有词的概率信息。这使得一些需要细粒度控制的任务可能会受到一些限制。
举例来说,像ChatGPT这样的模型通过API返回生成的内容,但是不会提供详细到每个位置上所有可能词的概率分布。
因此,设计解码策略时,研究人员可能需要考虑到模型的输出限制,以便选择适当的策略来生成文本。
二、借助外部知识
使用外部知识作为辅助证据,帮助LLMs提供真实的回答。该方法包括两个步骤:
第一步是获取知识:准确获取与用户指令相关的知识;
第二步是利用知识:利用这些知识来指导回答的生成。


表10:最近关于借助外部知识缓解幻觉的一些研究摘要。QA(问答)、FV(事实验证)和LM(语言建模)。
1. 获取知识
LLMs通过广泛的预训练和微调内部化了大量的知识,这可以称为参数知识。然而,不正确或过时的参数知识很容易导致幻觉。为了解决这个问题,研究人员提出从可靠的来源获取可靠的、最新的知识作为LLMs的热修补。这些知识的两个主要来源是可信的来源和人类专家。
两种提高LLM真实性的方法:内部检索和外部工具。
内部检索:现有的工作主要从外部知识库中检索信息,包括大规模非结构化语料库、结构化数据库、维基百科等和整个互联网。检索信息过程通常采用各种稀疏(如BM25)或密集(如基于PLM的方法)检索器。
稀疏检索器(如BM25):稀疏检索器是一种基于统计和规则的方法,它通过计算查询词与文档之间的相似度来进行信息检索。BM25 是一种常用的稀疏检索模型,它根据查询词和文档之间的词频和文档频率等信息来评估文档的相关性。这种方法通常使用较少的特征或词汇信息来进行检索,因此称为稀疏。
密集检索器(如基于PLM的方法):密集检索器是一种基于神经网络模型的方法,它使用预训练的大型语言模型(PLM,Pretrained Language Model)来理解和处理查询与文档之间的语义信息。这些方法使用神经网络来建模文本的表示,通常涉及到对大量参数进行训练。因为它们利用了大量的参数和深层的神经网络结构,所以被称为密集方法。
外部工具则包括FacTool和CRITIC等,它们可以提供有价值的证据来增强LLM的真实性。
其中,FacTool针对特定的下游任务,利用不同的工具帮助检测LLM中的幻觉,如用于基于知识的质量保证的搜索引擎API、用于代码生成的代码执行器和用于科学文献审查的谷歌学术API。
而CRITIC则使LLM能够与多个工具交互并自主修订其响应,从而有效提高真实性。
2. 知识利用
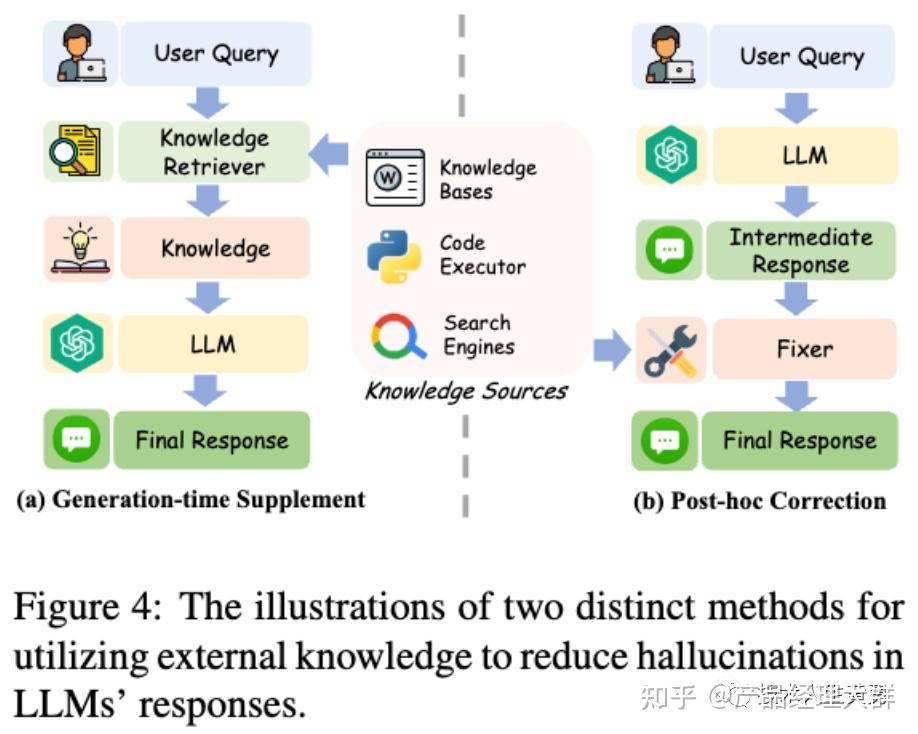
知识利用可以在不同阶段应用于缓解LLMs中的幻觉。现有的知识利用方法可以大致分为两类:基于上下文的修正通过利用上下文知识来纠正先前生成的非事实性声明。事后修正则通过构建辅助修复程序来纠正幻觉。
基于上下文的修正:直接将检索到的知识或工具反馈与用户查询连接起来,再输入到LLMs中,是一种有效且易于实现的方法。这种知识也被称为上下文知识。现有研究表明,LLMs具有强大的上下文学习能力,能够提取和利用有价值的信息。
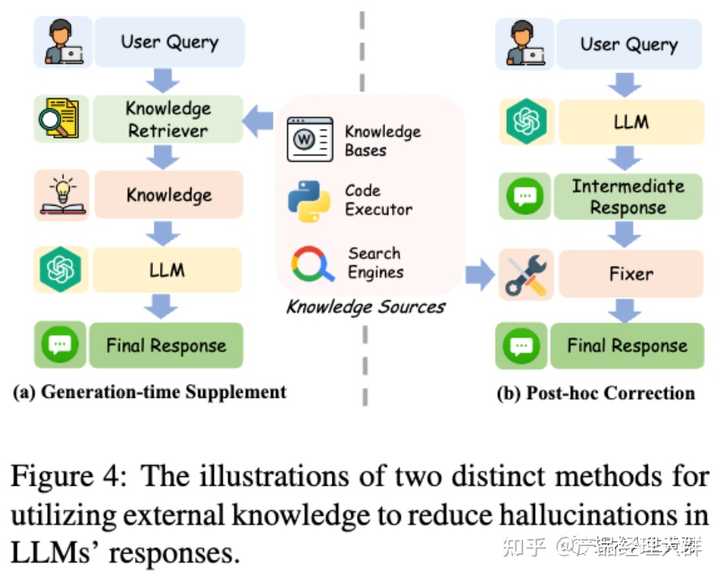

利用外部知识减少LLMs反应中的幻觉的两种不同方法的示意图。 从上下文知识中纠正之前产生的非事实性说法。
(注:现在多数开源的知识库+大模型项目都是A思路的实现:用户先将知识上传到系统,系统向量化知识到向量知识库存储起来。提问时,先将问题向量化,然后通过向量计算,将和问题相近的知识片段提取出来,然后将知识和问题都传给大模型,最后由大模型输出回答。)
事后修正:即在后处理阶段构建一个辅助修复程序来纠正幻觉。这些修复程序可以是另一个语言模型或特定的小型模型。它们通过与外部知识源交互来收集足够的证据,然后进行修正。这些修复程序可以利用各种外部工具来获取证据。
例如,RARR直接提示LLM从多个视角对需要纠正的内容进行提问。然后,它使用搜索引擎重新搜索相关知识。
最后,基于LLM的修正程序会根据重新获取的证据进行修正。例如:Verify-then-Edit方法旨在根据从维基百科获取的外部知识对推理链进行后编辑,从而提高预测的真实性。
为了获得更好的性能,LLM-Augmenter在将检索到的知识输入修复程序之前,会提示LLM对其进行总结。
使用外部知识来缓解LLMs中的幻觉具有几个优点:
- 避免了修改LLMs的需要,使其更加便捷。
- 是一种即插即用且高效的解决方案,可以方便地传输专有知识和实时更新的信息给LLMs。
- 可以提高LLMs生成结果的可解释性,通过追溯生成结果到源证据。
然而,该方法仍然面临一些问题需要解决:
- 如何验证从互联网检索到的知识的真实性是一个挑战性问题。
- 检索器/修复程序的性能和效率对于幻觉缓解至关重要。
- 检索到的知识可能与LLMs存储的参数化知识冲突,如何充分利用上下文知识是一个未被充分探索的问题。
不确定性
不确定性是推理过程中保护和减少幻觉的重要指标。通常,它指的是模型结果的置信度。
不确定性可以帮助用户确定何时信任LLMs。如果能准确地表征LLMs响应的不确定性,用户可以过滤或纠正具有高不确定性的LLMs的声明。
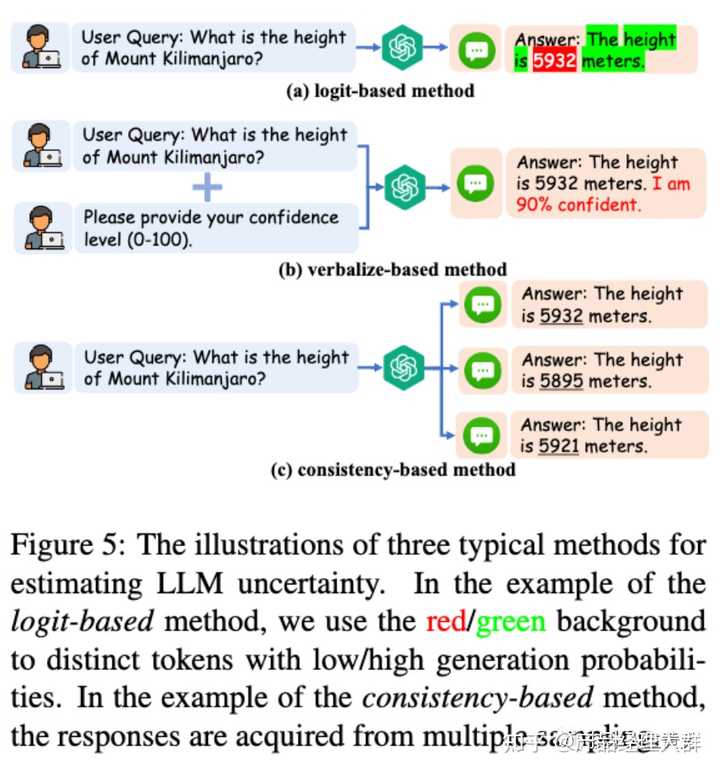

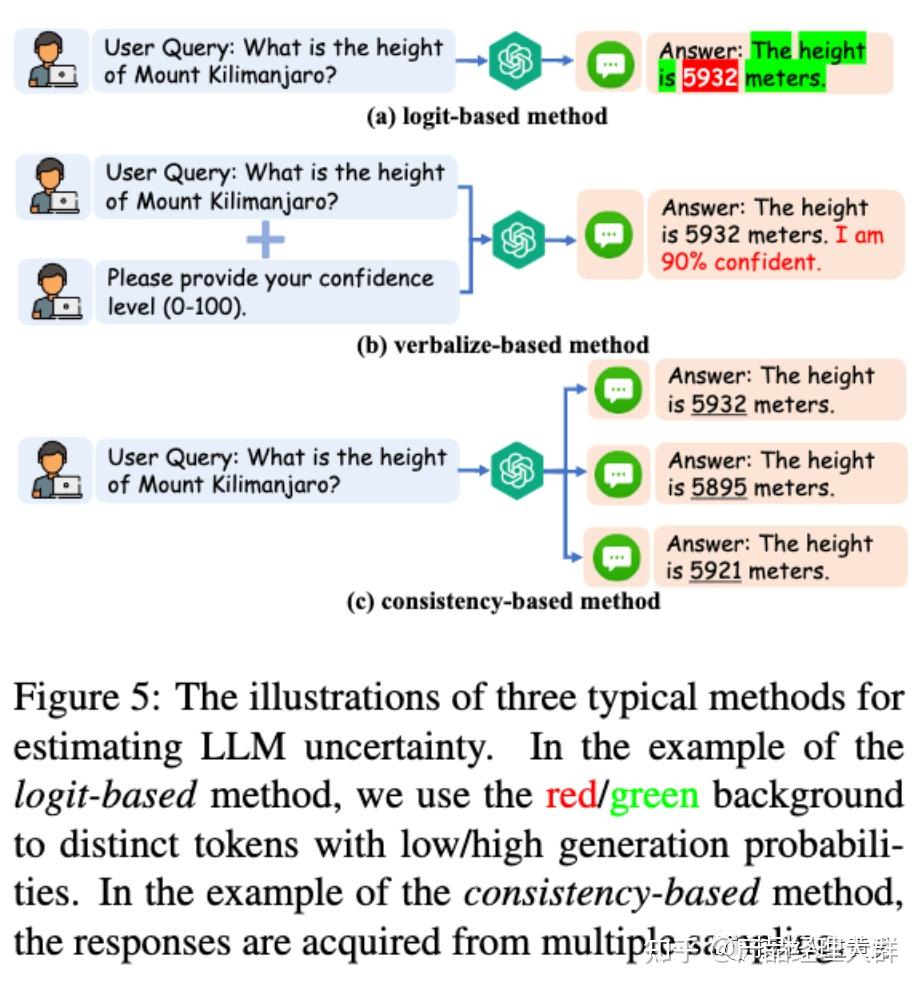
LLM不确定性估计方法可分为三类,分别是:置信度区间 logit-base 、基于口述的 verbalize-based 和基于一致性 consistency-base的方法。这些方法的示例可见于上图。
置信度基于Logit:这是一种基于对数的方法,它需要获取模型的对数,通常通过计算令牌级概率或熵来确定不确定性。
基于口述:直接要求LLM表达其不确定度,例如使用以下提示:"请回答并提供您的置信度分数(从0到100)"。这种方法之所以有效,是因为LLM的语言表达能力和服从指令的能力很强。也可以使用思维链提示来加强这种方法。
基于一致性:这种方法基于这样一个假设:当LLMs犹豫不决并对事实产生幻觉时,他们很可能会对同一问题做出逻辑上不一致的回答。例如:
使用BERTScore、基于QA的指标和n-gram指标进行计算,并将这些方法结合起来能产生最佳结果。
直接利用额外的LLM来判断两个LLM反应在相同语境下是否存在逻辑矛盾,可以采用另一种LLM来修正两个反应中这种自相矛盾的幻觉。
利用现有的程序监督为LLM响应分配一个风险分值,可作为幻觉的指标。
总的来说,利用不确定性来识别和缓解LLM幻觉是一个有效的研究方向,但是也存在一些问题:
- 基于逻辑回归的方法在现代商业LLM中越来越不适用,因为它们通常是闭源和黑盒的,无法访问其输出的逻辑回归,获取不到模型的对数。
- 关于基于语言表述的方法,研究者观察到LLMs在表达自信时往往显示出高度的过度自信,也就是说模型自己表述的不确定是高估的。
- 对不同回答一致性的有效测量仍然是一个未解决的问题,有可能多个模型在同一个问题上产生了相同的幻觉。
05 其他方法
除了上面的方法外,研究者还提出一些其他的技术来减少幻觉。
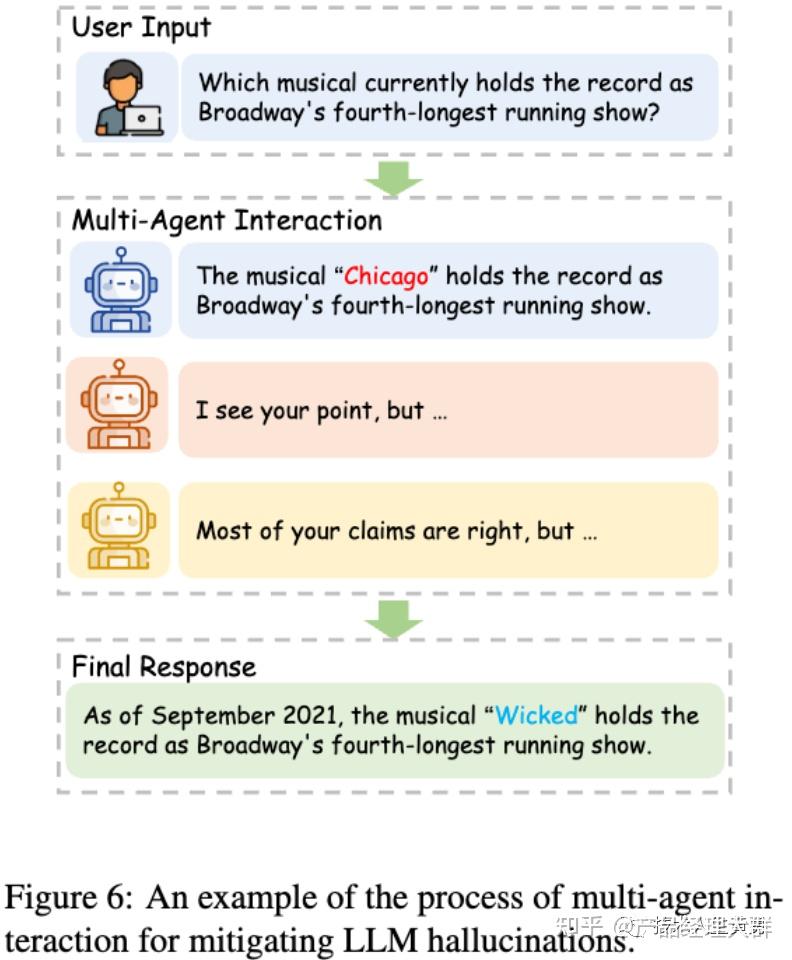
一、多模型互动 Multi-agent interaction
多个LLM(代理,agent)独立提出并协作辩论他们的回答以达成一致。这种方法可以减轻单个LLM产生幻觉信息的问题。
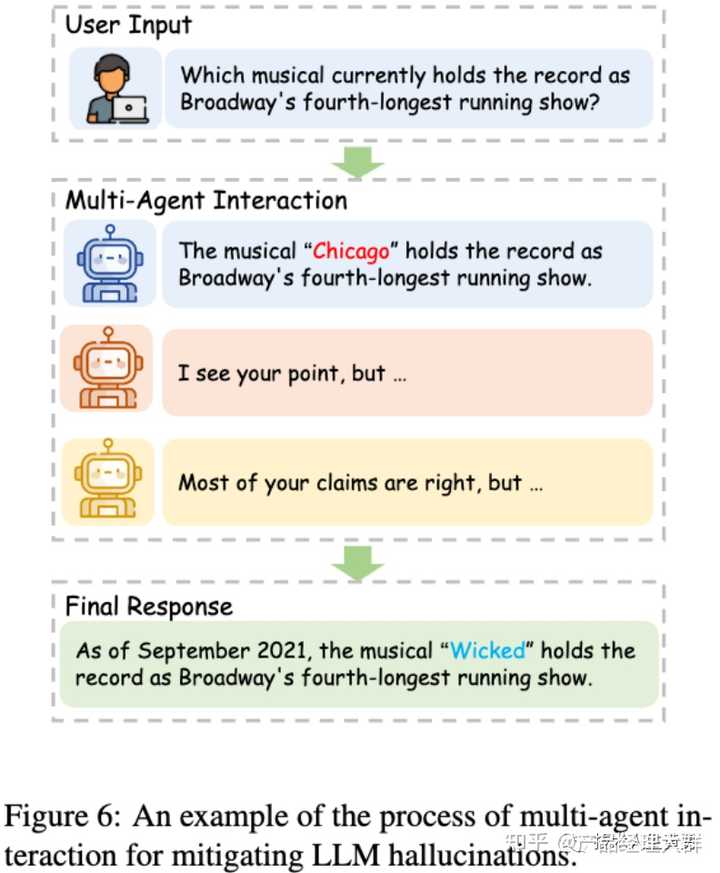

例如,通过让多个LLM参与辩论以达成共识,可以减轻这种幻觉。一名LLM提出主张(作为EXAMINEE),另一名LLM就这些主张提出问题并检查其真实性(作为EXAMINER),能以相对较低的成本有效减少幻觉。
二、提示词工程 Prompt engineering
研究发现,LLMs的行为会受到用户提示的影响,可能会出现幻觉。LLM最初会做出准确回应,但在使用不同提示时,LLM开始产生幻觉。因此,可以设计出更有效的提示来缓解幻觉。
为了减轻幻觉,研究人员使用了链式思考提示,但这也可能会带来新的挑战。现在流行的做法是在“系统提示”(即ChatGPT的API中system参数)中明确告诉LLMs不要传播虚假信息。
例如给"Llama2-Chat"的系统提示:如果您不知道问题的答案,请不要分享虚假信息。
三、检查LLM内部状态 Analyzing LLMs' internal states
有研究认为,LLMs可能意识到自己的虚假性,这表明其内部状态可以用于检测幻觉。他们提出了基于语言模型激活的语句准确性预测,通过在每个隐藏层上添加分类器来确定真实性,可以有效地提取这些信息。
实验结果表明,当LLM生成虚假语句时,LLM可能会"知道",而分类器可以有效地获取此类信息。
一些方法可以在推理过程中干预模型激活,从而减少幻觉。这些研究表明,LLM中的幻觉可能更多是由于生成技术而非底层表示。
四、人工干预循环 Human-in-the-loop
LLM中产生幻觉的一个潜在原因可能是知识与用户问题之间的错位,这种现象在检索增强生成(RAG)中尤为普遍。
为了解决这个问题,引入了MixAlign 框架,这是一个利用LLMs将用户查询与存储的知识对齐的人工干预循环框架,并进一步鼓励用户澄清这种对齐。通过反复调整用户查询,MixAlign不仅减少了幻觉,还提高了生成内容的质量。
五、优化模型架构
优化模型架构可以减少语言模型的幻觉,例如使用多分支解码器、不确定性感知解码器和双向自回归架构等方法。其中,双向自回归架构可以从左到右和从右到左进行语言建模,有效利用双向信息,有助于减少幻觉。
(注:据说国内清华开源的ChatGLM使用了双向自回归架构。)
六、幻觉待解决问题
尽管在LLM幻觉调查中提出了许多技术解决方案,但仍存在一些潜在的方向:
数据构建管理:
如前所述,LLM的风格和知识通常在模型预训练期间学习。高质量的数据为LLM中幻觉的减少提供了有希望的机会(Kirstain等人,2022)。受机器学习模型的基本规则“垃圾输入,垃圾输出”的启发,周等人(2023)提出了超社会对齐假设,将对齐视为学习与用户交互。对一些高质量样本进行简单微调的结果表明,数据质量和多样性超过了微调大规模指令的重要性(Mishra等人,2021;Wei等人,2022a;Sanh等人,2022)和RLHF(Bai等人,2022;欧阳等人,2020)。为了在知识密集型垂直领域高效执行,我们认为,构建以实体为中心的微调指令(Bao et al.,2023;桂等人,2023)是一个很有前途的方向,它可以将结构化知识和知识图的语义相关性相结合,以增强生成的实体信息的真实性。另一个可行的建议是在教学构建过程中加入自我管理阶段(Li et al.,2023g),以评估候选配对的质量。在迭代过程中,基于手动或自动规则约束的质量评估(Chen et al.,2023c)可以提供自校正能力
下游任务协调:
通用LLM在各种开放环境中具有一定程度的自然语言问题理解能力。然而,主要问题仍然存在于对应用要求的偏离,这导致了各种幻觉的出现。因此,下游任务对齐,特别是建立在垂直领域认知的基础上,需要广泛的符号推理、复杂任务的分解和规划,以及忠实的外部知识注入。具体来说,尽管LLM是语言处理方面的专家,但它很难在数学能力方面取得突破,这是一个与文本训练目标有关的缺陷。尽管已经提出了一些关于符号数学单词问题的研究(Gaur和Saunshi,2023;Zhu et al.,2023b),但增强符号推理和回答数字问题仍有待广泛研究。此外,对于需要不同输出的故事生成任务(Yang et al.,2022023),除了避免事实矛盾外,还需要引人入胜的故事情节。因此,在模型推理过程中实现忠实和创造性之间的平衡仍然是一个关键的挑战。此外,整合新知识来处理知识密集型任务涉及处理LLM的内部知识和外部知识图的显式知识边缘之间的联合推理。设计知识感知方法,将知识边缘图中的结构化信息纳入LLM的预训练过程,这带来了挑战。或者,预计推理过程将动态注入知识图信息(Wen等人,2023)。
LLM作为一种评估工具的使用是一种新兴的应用,但受到模型规模、教学调整效果和不同形式输入的限制(Agrawal等人,2023)。值得注意的是,LLM作为评分法官的尝试必须克服由立场、冗长、自我增强引起的各种偏见(Zheng等人,2023a;Berglund等人,2023;Wang等人,2023b)。因此,我们预测,未来关于设计特定任务机制来分析和纠正新出现的下游任务的过程的研究是一个值得长期关注的领域。
推理机制开发:
新兴的CoT技术(Wei et al.,2022b)通过模仿内在思维流来刺激LLM的涌现推理能力。构造一个逻辑中间推理步骤已被证明能显著提高问题解决能力。最近,一个主要的改进是与CoT的自一致性(CoT-SC)(Yao et al.,2023),这是一种生成多个CoT选项,然后选择最佳结果作为反馈的方法。此外,思维树(ToT)(Yao et al.,2023)在思维过程中引入了严格的树结构,这有助于不同思维路径的发展,并提供了一种新颖的回滚功能。由于以前的方法没有中间结果的存储,累积推理(CR)(Zhang et al.,2023c)以累积和迭代的方式使用LLM来模拟人类的思维过程,并将任务分解为更小的组件。然而,实际思维过程产生了一个复杂的思想网络,例如,人们可以探索一个特定的推理链,回溯或开始一个新的推理链。特别是当意识到以前推理链中的想法可以与当前探索的想法相结合时,它们可以合并为一个新的解决方案。更令人兴奋的是,思维图(GoT)(Zhang et al.,2023c)通过构建具有多个传入边的顶点来聚合任意思想,从而扩展了思想之间的依赖关系。此外,程序辅助语言模型(PAL)(Gao等人,2023b)和思维程序提示(PoT)(Chen等人,2022b)将编程逻辑引入语言空间(Bi等人,2023),扩展了调用外部解释器的能力。总之,我们相信,基于人类认知的研究有助于为幻觉的分析提供精彩而深刻的见解,如双过程理论(Frankish,2010)、三层心理模型(Stanovich,2011)、心理计算理论(Piccinini,2004)和连接主义(Thorndike,1898)。
多模态幻觉调查:
利用LLM出色的理解和推理能力,建立强大的多模式大型语言模型(MLLM)已成为社区共识(Li et al.,2023a;Dai et al.,2021;Ye et al.(2023))。李等人(2023i)通过对象检测和基于轮询的查询证实了MLLM中幻觉的严重性。结果表明,这些模型对物体幻觉具有很高的敏感性,并且生成的描述与目标图像不匹配。此外,Shao等人(2023)认为MLLMs具有有限的多模态推理能力以及对虚假线索的依赖性。尽管目前的研究(Yin et al.,2023b)对MLLMs进行了广泛的概述,但幻觉的原因尚未得到全面的调查。LLM中的幻觉主要来自训练数据中的错误知识,而MLLM的挑战在于将抽象的视觉编码准确地传递到语义空间中。现有的MLLM通过指令进行微调,使其目标输出遵循人类意图。然而,视觉模式和文本模式之间的错位可能会导致有偏见的分配。此外,缺乏视觉约束导致MLLMs出现严重的幻觉问题。因此,一个潜在的改进是将注意力转移到图像上(Wang et al.,2023a)或增强对视觉常识的理解。在细粒度的视觉和实际模态对齐方面,关注图像的局部特征和相应的文本描述可以提供忠实的模态交互。此外,一些MLLM的性能,如MiniGPT-4(Zhu et al.,2023a),高度依赖于提示的选择,需要仔细选择。请注意,为了方便用户,需要在多样性和幻觉之间进行可控的权衡。未来,随着更复杂的多模型应用的出现,改进MLLM的推理路径也是一个很有前途的研究方向。
06 总结及展望
论文讨论了在LLMs中调查幻觉时存在的一些未解决的挑战,并提供了未来研究方向的见解。
目前评估LLM中幻觉生成的自动度量存在不准确的问题,需要更深入的探索。生成式幻觉评估和人工注释不完全一致,自动度量的可靠性也因不同领域和LLM而异,导致泛化能力下降。判别式幻觉评估可以相对准确地评估模型的区分能力,但区分能力和生成能力之间的关系仍不清楚。
现有的LLM幻觉研究主要集中在英语上,但世界上存在数千种语言。希望LLM能够统一处理各种语言。一些研究发现,LLM在处理非拉丁语言时性能下降。 Guerreiro等人观察到,多语言LLM在翻译任务中主要在少资源语言中出现幻觉。 ChatGPT等LLM在英语中提供准确答案,但在其他语言中出现幻觉,导致多语言不一致。知识在LLM之间从丰富资源语言向少资源语言的转移也很有趣。


最近的研究提出了大型视觉语言模型(LVLMs),用于改进复杂的多模态任务的性能。然而,LVLMs存在多模态幻觉问题一样比较严重。
一些研究表明,LVLMs继承了LLMs的幻觉问题,例如物体幻觉。为了有效地衡量LVLMs生成的物体幻觉,提出了GAVIE基准和M-HalDetect数据集。此外,一些研究将LLMs扩展到其他模态,如音频和视频,这也是一个有趣的研究方向。
为了以最小的计算代价缓解LLM中的这些幻觉问题,人们又引入了模型编辑的概念,提出了模型编辑的概念,包括辅助子网络和直接修改模型参数两种方法。模型编辑可以通过编辑存储的事实知识来消除幻觉。然而,这个新兴领域仍面临许多挑战,包括编辑黑盒模型、上下文模型编辑和多跳模型编辑等。
同时,研究还表明,语言模型可以通过精心制作的提示来诱导幻觉,这可能会违反相关法律,导致应用程序被强制关闭。因此,诱导幻觉的攻击和防御策略也是一个重要的研究方向,与现有的幻觉缓解方法密切相关。同时,商业语言模型的真实响应能力也需要不断提高。
参考资料:
《Cognitive Mirage: A Review of Hallucinations in Large Language Models》
https://arxiv.org/abs/2309.06794v1
《Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models》https://arxiv.org/abs/2309.01219
编辑于 2023-11-20 18:57・IP 属地广东查看全文>>
产品经理大群 - 1 个点赞 👍
这个问题可以参考 Google Gemini技术报告上的讨论,详情阅读谷歌 Gemini 技术报告的第三部分,内容涵盖全面的负责任的部署——探讨了安全性、有用性、危害缓解、指令微调、事实性、幻觉,以及讨论和结论两部分内容。Google Gemini技术报告的第一部分和第二部分如下:
6. 负责任的部署
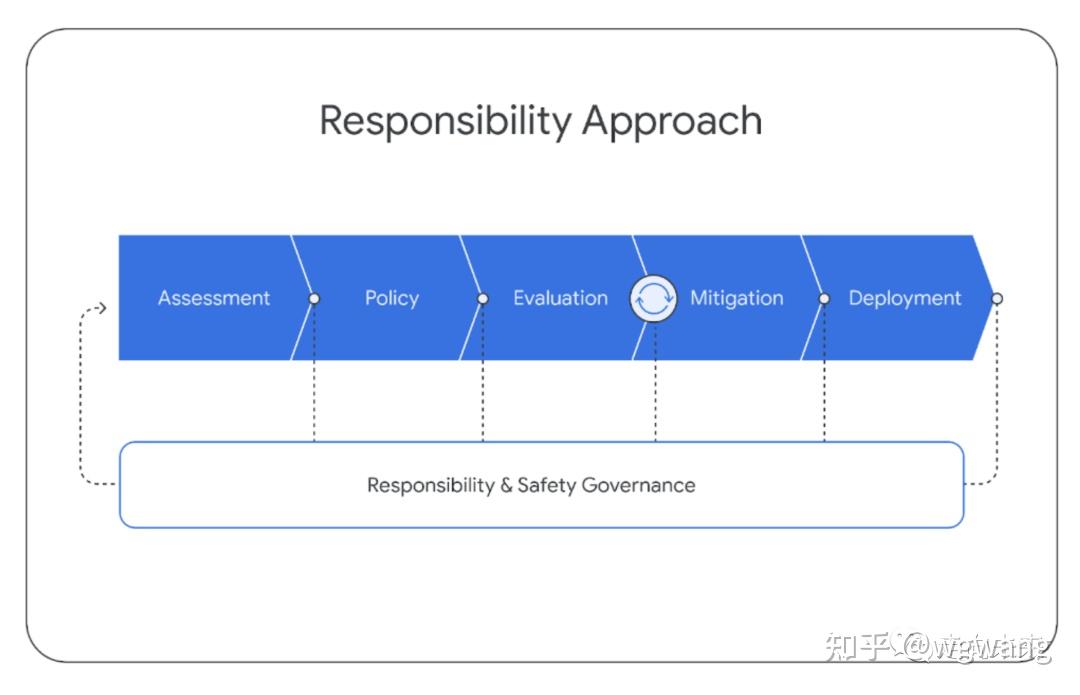
在Gemini模型的开发过程中,我们遵循结构化的责任部署方法,以识别、衡量和管理我们模型的可预见的下游社会影响,这与谷歌之前发布的AI技术保持一致【How our principles helped define alphafold’s release】。在项目的整个生命周期中,我们遵循以下结构。本节概述了我们通过这一过程的总体方法和关键发现。
本号持续关注通用人工智能AGI,大模型、知识图谱、多模态等各种最前沿的人工智能技术,欢迎关注!
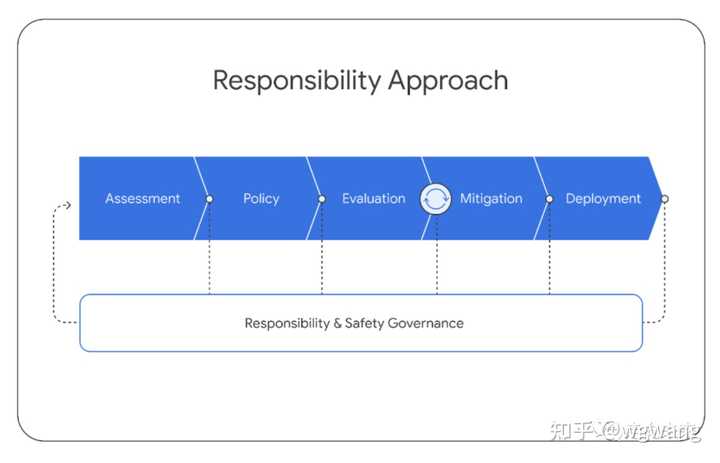

6.1. 影响评价 Impact Assessment
我们开发了模型影响评价体系来以识别、评价和记录与先进的Gemini模型开发相关的关键下游社会利益和危害。这些是基于语言模型风险的先前学术文献【Ethical and social risks of harm from language models】、类似行业先前开展的类似练习的发现【PaLM2——《Palm 2 technical report》,Claud-《Training a helpful and harmless assistant with reinforcement learning from human feedback》和GPT-4——《GPT-4 Technical Report》】、与内外部专家的持续接触,以及非结构化尝试发现新模型漏洞而得出的。关注领域包括:事实性、儿童安全、有害内容、网络安全、生物风险、代表性和包容性。这些评价与模型开发同步更新。 影响评价用于指导缓解和产品交付的工作,并通知部署决策。Gemini影响评价涵盖了Gemini模型的不同能力,评价了这些能力与谷歌AI原则【Google’s AI Principles】的潜在后果。
6.2. 模型策略 Model Policy
在对已知和预期影响有了上述的理解的基础上,我们制定了一套“模型策略”,以指导模型开发和评估。模型策略的定义担任了负责任开发的标准化准则和优先级模式,并担任了发布准备是否妥当的指标。Gemini模型策略涵盖了许多领域,包括:儿童安全、仇恨言论、事实准确性、公平和包容性以及骚扰。
6.3. 评估 Evaluations
为了能够根据影响评价体系来来评价Gemini模型违反策略领域和其他关键风险领域,我们在整个模型开发生命周期内开发了一套评估套件。 开发评估的目的是在整个Gemini模型的训练和微调过程中进行“爬坡”。这些评估是由Gemini团队设计的,或者是针对外部学术基准的评估。评估考虑了有用性(指令遵循和创造力)、安全性和事实性等问题。请参阅第5.1.6节和下一节关于缓解措施的部分结果样本。 进行保证评估(Assurance evaluations)的目的是治理和审查,通常由模型开发团队之外的小组在关键里程碑或训练结束时完成。由模态和数据集标准化的保证评估是严格保留的。只有高级见解会反馈给训练过程来协助缓解工作。保证评估包括跨Gemini策略的测试,并包括对潜在生物危害、说服和网络安全等危险功能的持续测试【Model evaluation for extreme risks】。 外部评估由谷歌公司外的合作伙伴进行,以识别盲点。外部小组会针对一系列问题对我们的模型进行压力测试,包括白宫承诺(White House Commitments)【Ensuring Safe, Secure, and Trustworthy AI,https://whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf,核心是Safety模型安全,Security系统安全和Trust 可信】中列出的各个领域,并通过结构化评估和非结构化红队评估【红队评估是一种用于引出模型不良行为漏洞的评估形式。类似于借鉴黑客攻击的手法和技巧,在可控的范围内对业务系统开展模拟测试,找出其存在的漏洞,并提供安全修复建议。】的组合进行测试。这些评估的设计是独立的,结果会定期报告给谷歌DeepMind团队。 除了这套外部评估套件之外,专业内部团队还会针对我们的模型持续开展红队评估,内容涉及Gemini策略和安全 Security等领域。这些活动包括较少结构化流程,涉及复杂的对抗性攻击,以识别新的漏洞(vulnerabilities)。发现潜在弱点可在随后用于减轻风险和改进内部评估方法。我们致力于持续的模型透明度,并计划随着时间的推移分享我们评估套件的更多结果。
6.4. 缓解措施
缓解措施是针对上述评价、策略和评估方法的结果而做的。评估和缓解措施以迭代方式进行工作,在缓解措施之后重新运行评估。我们在数据、指令调优和事实性方面讨论了减轻模型伤害的努力。
6.4.1. 数据
在训练之前,我们在数据整理和数据收集阶段采取了各种步骤来缓解潜在的下游伤害。正如“训练数据集”一节所讨论的,我们会过滤掉训练数据中的高风险内容,并确保所有训练数据的质量足够高。除了过滤之外,我们还采取措施确保所有收集的数据符合谷歌DeepMind的数据丰富最佳实践,这是基于人工智能合作伙伴关系的“数据丰富服务的负责任采购”而制定的。这包括确保所有数据丰富工作人员的工资至少达到当地的生活工资。【https://deepmind.google/discover/blog/best-practices-for-data-enrichment/】
6.4.2. 指令调优
指令调优包括有监督微调(SFT)和使用奖励模型的人类反馈的强化学习(RLHF)。我们在文本和多模态设置中应用指令调优。通过非常仔细地设计指令调优方法来平衡提升有用性和降低模型在安全性和幻觉方面的风险【Anthropic 的论文《Training a helpful and harmless assistant with reinforcement learning from human feedback》】。 SFT、奖励模型训练和RLHF的“优质”数据整理至关重要。 数据混合比例在较小的模型上进行了消融实验,以平衡有用性指标(如指令遵循、创造力)和减少模型损害,这些结果可以很好地推广到更大的模型。 我们还观察到,与数据量相比,数据质量更重要(LLaMA2论文,以及《Don’t make your llm an evaluation benchmark cheater》),尤其是对于更大的模型。 类似地,对于奖励模型训练,我们发现关键是平衡包含模型数据集中出于安全原因选择“我无法帮助”的样本和模型输出有用响应的样本。 我们使用有用性、事实性和安全性的奖励得分的加权和来训练一个多头奖励模型,并使用了多目标优化的方法。 我们进一步详细阐述了减轻有害文本生成风险的方法。 我们列举了大约20种伤害类型(例如,仇恨言论、提供医疗建议、建议危险行为),这些类型涵盖各种用例。 我们为这些类型生成潜在伤害诱导查询数据集,这些数据既可以是由策略专家和ML工程师手动生成的,也可以通过使用主题关键字作为种子来提示高能力语言模型自动生成。 给定可能诱导伤害的查询来探测Gemini模型,并使用并排评估来分析模型响应。 如上所述,我们的目标是平衡模型输出响应的无害性与有用性之间的平衡。 从检测到的风险领域,我们创建附加的有监督微调数据以演示期望的响应。 为了大规模生成此类响应,我们严重依赖于一个自定义的数据生成方法,该方法受到宪法AI (Constitutional AI)【参考《Constitutional ai: Harmlessness from ai feedback》】的启发,将谷歌内容政策语言的变体作为“宪法”注入,并利用语言模型强大的零样本推理能力【《Large Language Models are Zero-Shot Reasoners》】修正响应,以及在多个响应候选者之间进行选择。我们发现这个方法非常有效——例如,在Gemini Pro中,这个总方法能够缓解我们识别的大多数文本伤害案例,而响应的可用性没有明显下降。
6.4.3. 事实
在许多场景中,模型能够生成事实响应并减少幻觉的频率是非常重要。 我们将指令调优工作重点放在实际场景中的三种关键期望行为上:
- 归因Attribution:如果模型被指示所生成的响应应当完全归因于提示中的给定上下文,那么Gemini应生成对上下文最高程度的忠实响应【《Measuring attribution in natural language generation models》】。 这包括总结用户提供的来源、根据给定的问题和所提供的片段来生成细粒度引文【《Teaching language models to support answers with verified quotes》,《Check your facts and try again: Improving large language models with external knowledge and automated feedback》】、根据书籍等长篇来源来回答问题【《Can a suit of armor conduct electricity? a new dataset for open book question answering》】,以及将给定来源转换为所需输出(例如,从会议录音的一部分生成电子邮件)。
- 难题响应生成Closed-Book Response Generation:如果没有任何给定来源的情况下提出寻求事实的提示,那么Gemini不应幻想不正确的信息(请参阅文章《How much knowledge can you pack into the parameters of a language model?》的第2节的定义)。这些提示包括从寻求信息的提示(例如“印度总理是谁?”)到可能会要求事实信息的半创意提示(例如“写一篇500字的支持采用可再生能源的演讲”)。
- 规避Hedging:如果输入提示是无法回答的,Gemini不应该幻想。相反,它应该通过规避来承认无法提供响应。这些场景包括带有错误前提问题的提示【《Won’t get fooled again: Answering questions with false premises》】,带有开放性问答但给定上下文无法导出答案的输入提示指令,等等。
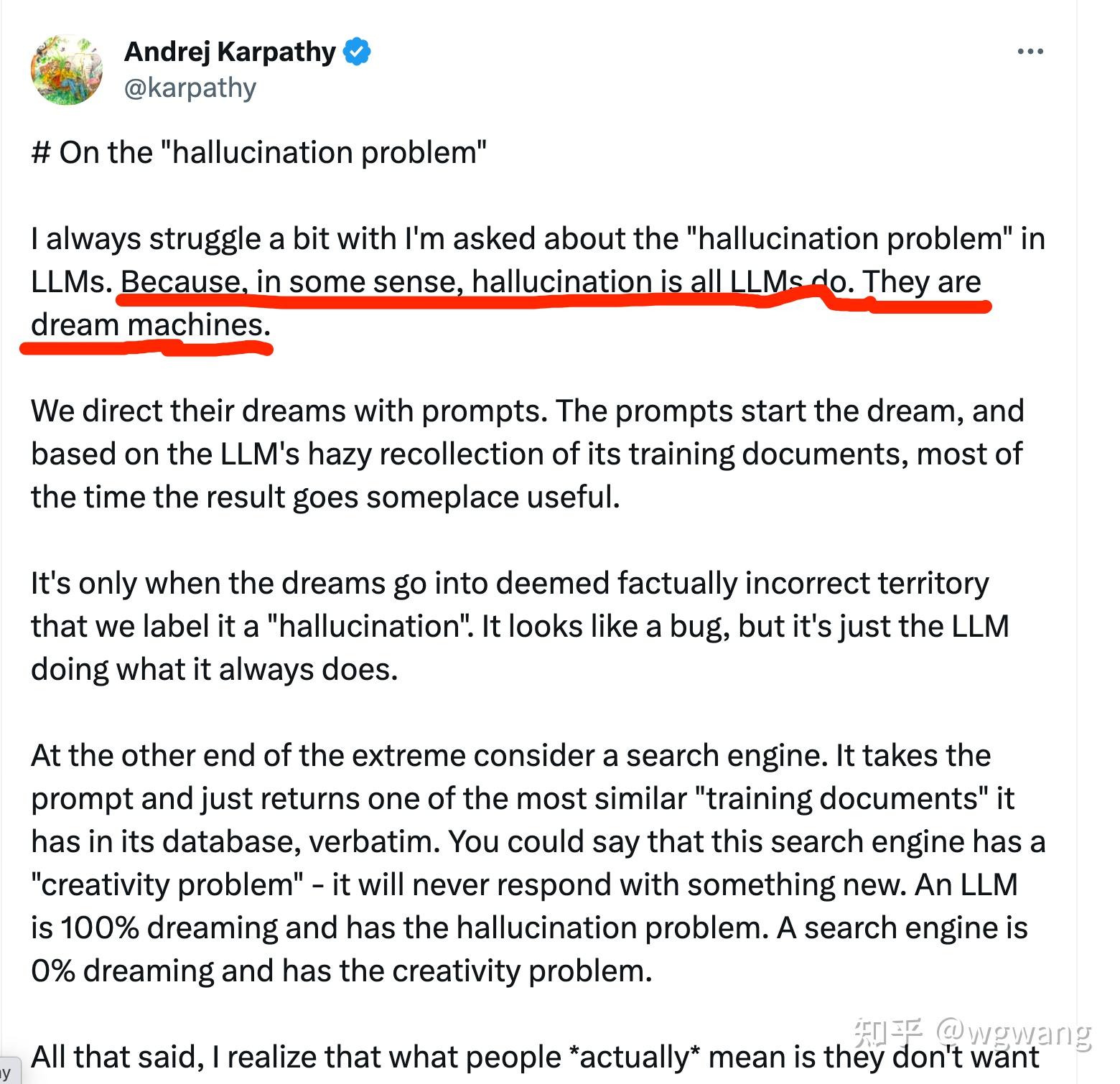
幻觉问题上,大模型本身是无法解决的。特别的,最近Andrej Karpathy在X 上提出,幻觉是大模型所能做的一切,或者说,大模型就是“造梦机器”。所以,如果要减少或避免幻觉,必须采用其他技术,比如知识图谱。有篇文章的标题取的特别好,就是:大模型产业落地难,知识图谱来帮忙!
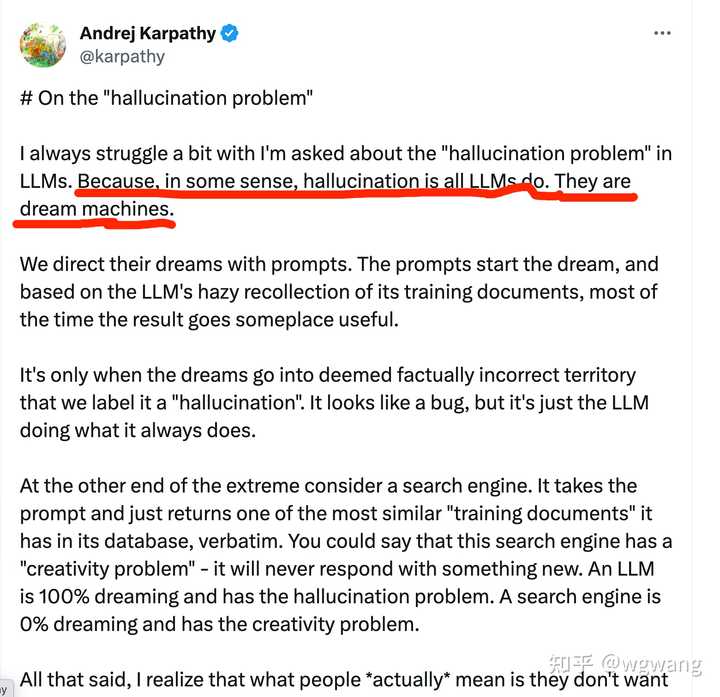

大模型就是“造梦机器” 关于知识图谱,推荐一本书,详细介绍了知识图谱的方方面面,甚至可能是最早提及多模态知识融合和向量数据库的书籍,书中也详细解析了Transformer 架构,以及对因果推理、概率推理、归纳推理和演绎推理的解析与描述。
我们通过策划定向的有监督微调数据集和执行RLHF来引出Gemini模型的这些期望行为。 请注意,这里产生的结果不包括给予Gemini声称可以提高事实性的工具或检索【《Teaching language models to support answers with verified quotes》,《Check your facts and try again: Improving large language models with external knowledge and automated feedback.》】。 我们在下面提供了各自的挑战集上的三个关键结果。
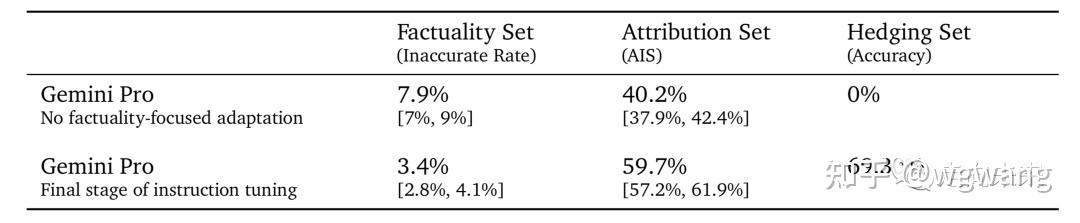
- 事实性集Factuality Set: 包含事实寻求提示(主要是难解之题、难题、谜题)的评估集。这是通过人工标注员手动事实检查每个响应来进行评估的; 我们报告标注员判断的事实不准确的响应百分比。
- 归因集Attribution Set: 包含需要对提示中的来源进行归因的各种提示组成的评估集。这是通过人工标注员手动检查每个响应中对提示中的来源的归因进行评估的; 报告的指标是AIS【参阅《Measuring attribution in natural language generation models》】。
- 规避集Hedging Set: 自动评估设置,我们衡量Gemini模型是否准确地规避。
我们将指令调优的Gemini Pro与没有任何事实重点适应的指令调优Gemini Pro版本进行了比较,如表14所示。我们观察到:
- 在事实性集合中,不准确率减半;
- 在归因集合中,归因的准确性提高了50%;
- 在提供的规避集任务中,模型成功地规避了70%(从0%上升)。
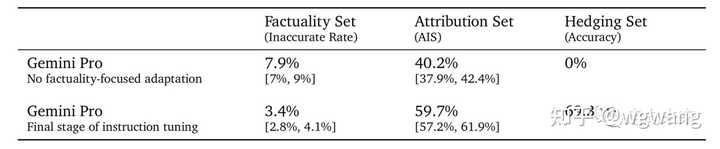

表14 事实缓解措施:指令调优的影响情况(以相应的95%置信区间),包括事实不准确率、存在归因和准确地规避的比率 6.5. 部署
在评审完成后,会为每个批准的Gemini模型创建作为结构化和一致的内部文档的模型卡片,内容包括关键性能和负责任指标。同时,也会适时对外部沟通这些指标。
6.6. 负责任的治理
在整个负责任开发过程中,我们与谷歌DeepMind的责任与安全委员会(Responsibility and Safety Council, RSC)进行道德和安全审查。RSC是一个跨学科小组,根据谷歌AI原则评估DeepMind的项目、论文和合作。 RSC对影响评价、政策、评估和缓解工作提供意见和反馈。 在Gemini项目期间,RSC针对关键政策领域(例如儿童安全)制定了具体的评估目标。
7、讨论和结论
我们展示了Gemini模型家族,它提高了文本、代码、图像、音频和视频的多模态模型能力。这份技术报告评估了Gemini在多样的、广泛研究的评测基准上的能力,而且我们最强的模型Gemini Ultra在各个方面都取得了显著进步。在自然语言领域,通过在数据和大规模模型训练上的精心开发而获得的性能提升和持续的质量改进,在几个基准测试中创造了新的最高水平。特别是,Gemini Ultra超过了人类专家在考试基准MMLU上的表现,得分90.0%,自2020年首次发布以来,这一直是量化LLM进步的事实标准。在多模态领域,Gemini Ultra在大多数图像理解、视频理解和音频理解基准测试中推高了最高的水平,而无需进行特定于任务的修改或调优。特别是,Gemini Ultra的多模态推理能力从其在最近的MMMU基准测试上的最高水平得到证实,该数据集由需要大学水平的学科知识和深思熟虑的推理才能完成的图像相关的问题组成。 除了基准测试上的最先进结果之外,最激动人心的是Gemini模型支持的新用例。Gemini模型的新功能包括解析复杂图像(如图表或信息图),在交错的图像、音频和文本序列上进行推理,生成交错文本和图像响应。这些新功能为各种新应用打开了广阔的空间。正如报告和附录中的图所示,Gemini可以在教育、日常问题解决、多语言交流、信息概括、抽取和创造力等领域带来新的方法。我们期待这些模型的用户会发现各种各样的新用途,这些用途我们在自己的调查中只是触及了表面。 尽管它们的功能令人印象深刻,但我们应该注意,LLM的使用存在局限性。需要持续进行研究和开发LLM生成的“幻觉”,以确保模型输出更加可靠和可验证。尽管LLM在考试基准测试上取得了令人印象深刻的表现,但模型仍然挣扎在需要像因果理解、逻辑推理和反事实推理等高层推理能力的任务上。这强调了需要更具挑战性和健壮的评估来测量它们的真实理解力,因为目前最先进的LLM饱和了许多基准测试。 Gemini是我们在实现智能、推进科学、造福人类的使命上迈进了一步。我们热切地期待看到这些模型如何被我们在谷歌的同事和更多人的使用。我们建立在机器学习、数据、基础设施和负责任开发等领域的许多创新之上——这些是我们在谷歌十多年来一直在追求的领域。我们在本报告中提出的模型为我们更广泛的未来目标奠定了坚实的基础,即开发一个跨许多模态、具备广泛的泛化能力的大规模模块化的系统(a large-scale, modularized system that will have broad generalization capabilities across many modalities)。
进一步阅读
以及更多文章:
- GPT-4模型架构:它比你想象的更简单
- AGI开始使用工具,chatGPT开放插件系统
- 语言≠知识:万字长文看语言通天塔的建成和神经网络大模型的固有缺陷——与Bing Chat关于苏东坡的对话实录
- 开源开放大模型全观察之LLaMA-2
- 开源开放大模型观察之LLaMA
- 开源开放大模型观察之baichuan-7B
- 深度全解析开放开源大模型之BLOOM
- 珠峰书《知识图谱:认知智能理论与实战》“升级”了:配套PPT,教学更easy!
- 知识图谱和大模型在全球供应链体系数字化中的应用:上海国际物流节发言总结和补充
- 大模型时代,AI原生启航
- 被ChatGPT带入悬崖的律师
- ChatGPT不仅把律师带入悬崖,还给“他爸”带来了麻烦
- 上海世界人工智能大会WAIC,好看的点都在这里:大模型是绝对的王者,其他呢?
- ChatGPT是如何铸就的?且看屠龙刀ChatGPT现身AI江湖的故事
- ChatGPT是如何铸就的?且看屠龙刀ChatGPT现身AI江湖的故事
- 大语言模型LLMs技术精粹总纲:重剑无锋,大巧不工——且看AI江湖刀剑争锋的源流
- 大语言模型LLMs技术精粹,Transformer模型架构全解析:三生万物——且看AI江湖基石
- 大语言模型LLMs技术精粹,稀疏变换器网络全解析:变则通,通则久——且看AI江湖基石
- 大语言模型LLMs技术精粹,GPT-1架构全解析:九层之台起于累土——且看AI江湖之起高楼
- 始自 ChatGPT,迈向AGI:于《四川日报:川观智库》问计高质量发展及包含 GPT-4的内容补充
- 从悉尼到普罗米修斯:New Bing的表演
- New Bing技术架构普罗米修斯:AGI 驱动智能应用开发的基本框架
- New Bing和 ChatGPT 的测评:我女朋友的老公应该叫我什么?以及更复杂的衍生问题
- 谷歌Bard和微软Bing像两个技术宅在相亲的聊天,还会转换话题,这也太强了!
- 我女朋友的老公应该叫我什么?Claude 像外企工作的中国人,文心一言则一言难尽
- 从地图看124个国产大模型的全国分布,至今仍空白的省份何时填补?
- 应用端的百模大战,被智子锁定中国的基础模型:国产大模型虽达120个却多而不强!
- 国产大模型达113个,LLaMA2发布之下,百模争霸何去何从?
- 国产108个大模型,谁是36天罡?谁是72地煞?百模争霸排行榜
- 恭喜中国,“百模”成就达成!国产大模型103个,下一站:百模争霸,谁将持续霸榜!
- 国产大模型即将破百,达93个,北京占比首次降到45%,沪粤浙紧追不舍
- 国产大模型突破80个,Google开始为Gemini造势:百模大战V6
- 百模大战V5:收录74个国产大模型,国产开源有进展但仍然非常弱
- 百模大战达成率68%,如何解决群模乱舞之下的资源浪费,国产开源之路有待探索!国产大模型观察V4
- 百模大战完成率58%,北京占半壁江山:国产大模型观察V3,
- 国产大模型观察:群模乱舞,挖掘已发布超过50个大模型,获得大模型发布三部曲的惊天秘密
- 中国大模型产业发展白皮书
发布于 2023-12-13 13:28・IP 属地英国查看全文>>
wgwang