
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
2023-05-08
https://arxiv.org/abs/2303.08896
作者认为传统的幻觉检测方法在当今LLM时代有如下的缺陷:
- 基于不确定度指标:这一类方法通过衡量LLM回复的熵/概率,来判断LLM对回复是否自信,越不自信越可能是编造的内容。但是该方法对闭源模型(如OpenAI)不友好。
- 基于事实验证指标:这一类方法需要外挂知识库,但是现在缺少涵盖所有世界知识的高质量知识库。
作者提出了SelfCheckGPT方法,核心的假设是:如果大模型非常肯定一个事实,那么它随机采样多次生成的回复,将对该事实有着近似的陈述(self-consistency)。如果多次采样,LLM都生成不同的陈述,那么很有可能是出现了幻觉。
具体地,评估多个采样陈述是否一致,可以通过:
1)BERTScore;2)QA-based;3)n-gram metric进行实现。
我们证明SelfCheckGPT可以:
i)检测非事实和事实句子;
ii)按照真实性对段落进行排名。
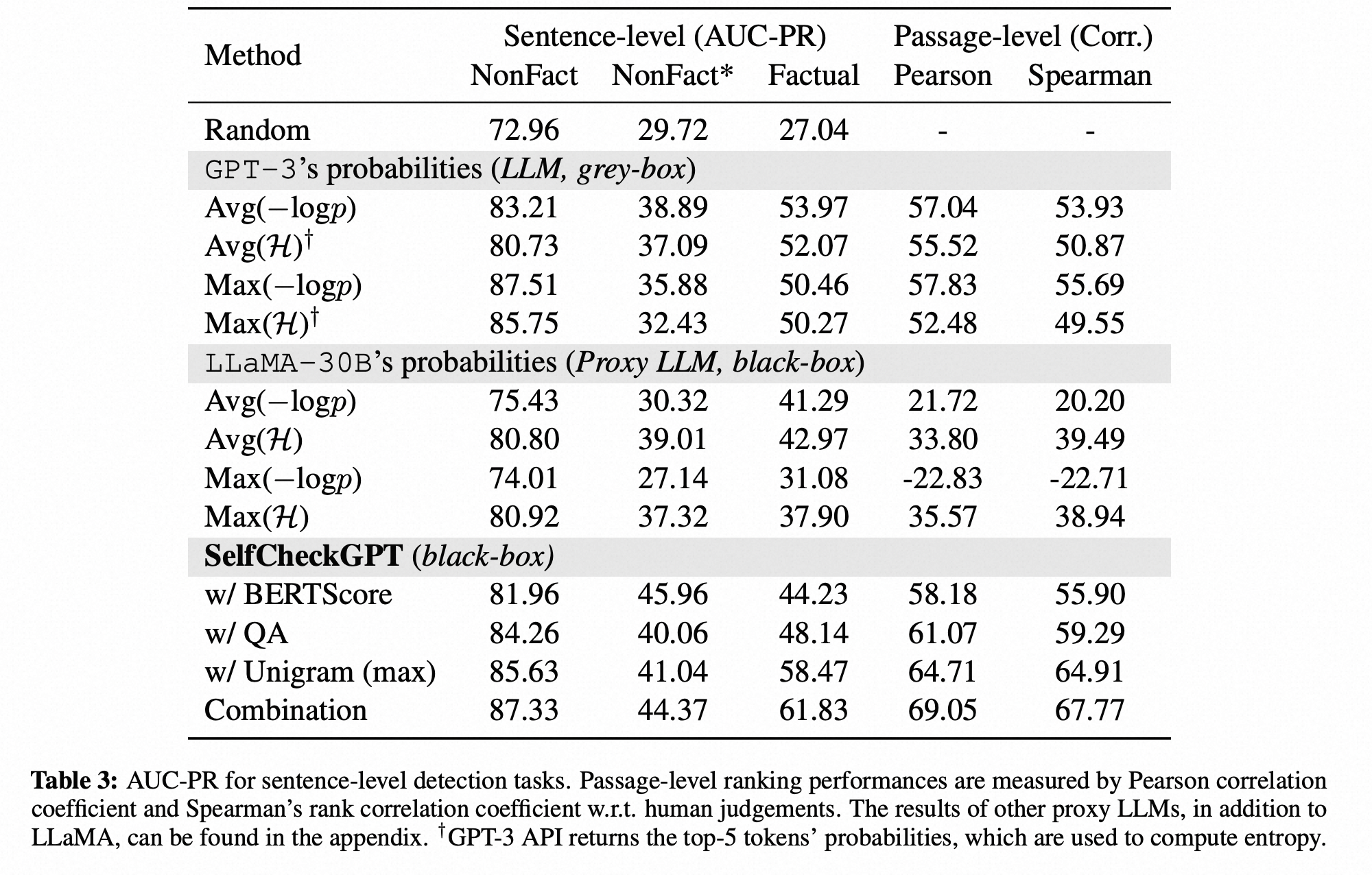
我们将我们的方法与几个基准进行比较,并显示在句子虚构检测方面,我们的方法具有与灰盒方法相当或更好的AUC-PR分数,而在段落真实性评估方面,SelfCheckGPT表现最佳。
灰盒策略
为了考虑如何在零资源环境中确定生成响应的真实性,我们考虑LLM的预训练。在预训练期间,模型通过对大量文本数据进行下一个词预测进行训练。这使得模型对语言具有深刻的理解(Jawahar等,2019; Raffel等,2020),强大的上下文推理(Zhang等,2020)以及世界知识(Liusie等,2022)。考虑输入“Lionel Messi is a _”。由于Messi是一位世界著名的运动员,在预训练中可能出现多次,LLM很可能知道Messi是谁。因此,在给定上下文的情况下,“足球运动员”这个标记可能被赋予非常高的概率,而其他一些职业如“木工”将被认为非常不可能。然而,对于输入“John Smith is a _”,系统可能不确定句子应该如何继续,概率分布会非常平坦。在解码过程中,这将导致生成一个随机的单词,从而导致系统产生虚构。这一观点使我们意识到了不确定性度量和真实性之间的联系。真实的句子很可能包含具有较高可能性和较低熵的标记,而虚构很可能来自具有高不确定性的平坦概率分布的位置。
Token-Level Probability P:给定LLM的响应R,令i表示R中的第i个句子,j表示第i个句子中的第j个标记,J是句子中的标记数,pij是LLM在第i个句子的第j个标记处生成的词的概率。使用了两种概率度量方法:(这里衡量句子的不确定性)
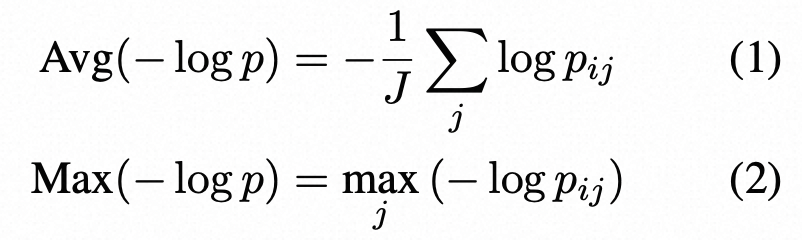
输出分布的熵H:
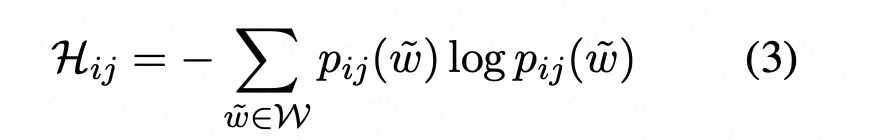
其中pij(˜w)是在第i个句子的第j个标记处生成单词w~的概率,W是词汇表中所有可能的单词集。类似于基于概率的度量,使用了两种基于熵的指标:
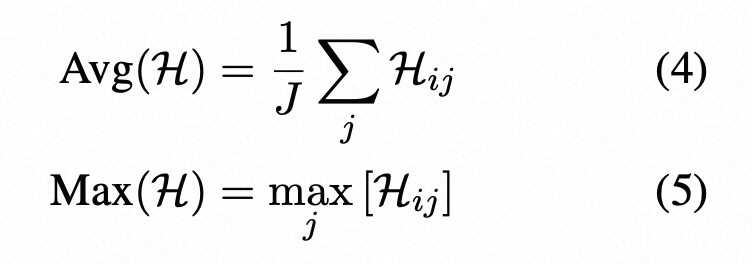
这里是基于纯概率或者熵来计算句子的不确定性
黑盒策略
前面的灰盒方法的一个缺点是它们需要输出标记级的概率。虽然这可能似乎是一个合理的要求,但对于只能通过有限的API调用获取的大型LLMs,这种标记级的信息可能不可用(例如ChatGPT)。因此,我们考虑黑盒方法,因为它们仍然适用于仅从LLM中获取基于文本的响应的情况。
一个简单的基准方法是使用代理LLM,即我们完全可以访问的另一个LLM,例如LLaMA(Touvron等,2023)。在没有访问生成文本的LLM的完整输出的情况下,可以使用代理LLM来近似输出的标记级概率。
意思是让CHatGPT生成句子,通过LLAMA的句子概率来算不确定性
SelfCheckGPT
令R表示从给定用户查询中获取的LLM响应。SelfCheckGPT通过从相同的查询中抽取进一步的N个随机LLM响应样本{S1,S2,..,Sn,...,SN},然后测量响应和随机样本之间的一致性来运行。
作为第i个句子的虚构得分,我们设计了SelfCheckGPT S(i),使得S(i) ∈ [0.0, 1.0],如果第i个句子是虚构的,S(i)→1.0,如果它是基于有效信息的,S(i)→0.0。
- BertScore:找到随机生成与响应Bert相似性最大的随机生成,用Bert评分
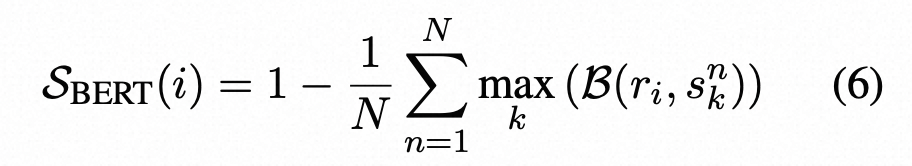
记B(., .)表示两个句子之间的BERTScore。使用BERTScore的SelfCheckGPT通过找到每个抽样样本中与给定句子最相似的句子的平均BERTScore来进行评估
其中ri表示R中的第i个句子,snk表示第n个样本S中的第k个句子。
这样,如果一个句子在许多抽样样本中出现,可以假设该信息是真实的;而如果该陈述在其他样本中没有出现,那么它很可能是一种虚构。
- QA-Based:对每个问题的回答,依据回答来生成一个问题,和这个新问题的回答,再随机生成扰动回答
基于信息一致性可以通过问答(QA)来评估的想法,我们将自检GPT应用了自动生成多项选择题(MQAG)框架(Manakul等人,2023年)。MQAG通过生成多项选择题来评估一致性,这些问题可以独立回答每个段落。如果查询一致概念上的事实,则预计回答系统会预测相似的答案。MQAG框架包括一个问题-答案生成系统G1、一个干扰因素生成系统G2和一个答案系统A。对于响应R中的句子ri,我们按以下方式提取问题q、关联答案a和干扰项o\a:
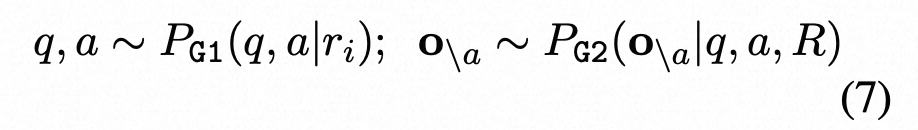
where o = {a, o\a} = {o1, ..., o4}. o代表模型的选择
为了过滤不可回答的问题,定义可回答性评分:
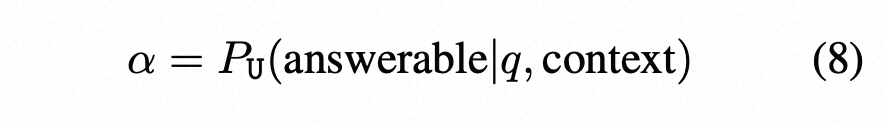
在这里,上下文可以是响应R或抽样段落Sn ,当α → 0.0表示无法回答,当α → 1.0表示可以回答。我们使用α来过滤掉α低于阈值的无法回答的问题。
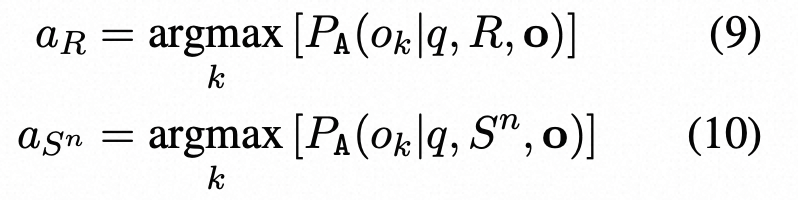
公式9-10代表模型在扰动回答,响应R,问题q的情况下某选项的概率
随后,我们使用答案系统A来回答所有可以回答的问题:我们比较所有样本{S 1 , ..., SN }的aR是否等于aSn,得到匹配数Nm和不匹配数Nn。然后,基于匹配/不匹配计数,计算出第i个句子和问题q的简单不一致性得分:
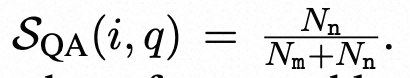
。为了考虑可以回答的问题数量(即评估句子的证据),我们使用Bayes定理(附录B中提供推导)来改进公式5.2,得到:
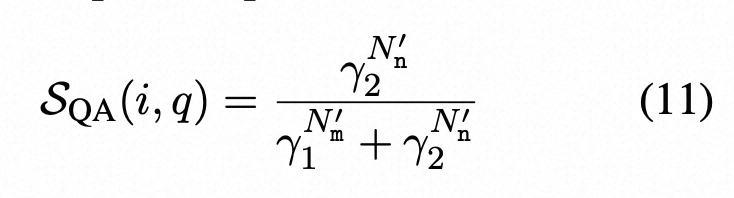
其中N‘m是有效匹配计数,N’n是有效不匹配计数,γ1和γ2在附录B中定义。最终,具有QA的SelfCheckGPT是跨q的不一致性得分的平均值。
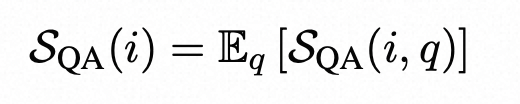
- n-gram:训练个新的n-gram模型,来替代next token概率,回到灰盒模型
在使用LLM生成响应样本{S 1 、S2 、…、SN }的同时,可以使用这些样本训练一个新的语言模型来近似LLM。随着N的增加,这个新的语言模型越接近生成响应样本的LLM。因此,我们可以使用新训练的语言模型来近似LLM的token概率。 在实践中,由于时间和/或成本的限制,样本数量N是有限的。因此,我们使用样本{S 1 、…、SN }和主响应R(将进行评估)训练一个简单的n-gram模型。我们注意到,通过将R包含在训练n-gram模型中,可以将R中每个token的计数增加1,从而可以将其视为平滑方法。然后,我们计算响应R的log-probabilities的平均值,
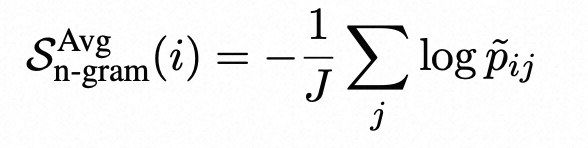
其中p˜ij是使用n-gram模型计算的第i个句子的第j个token的概率。或者,我们也可以使用n-gram模型的负对数概率的最大值:
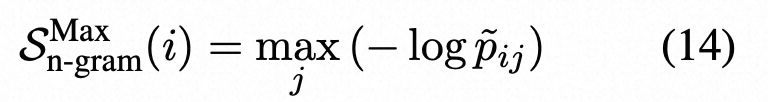
- 最后,考虑到SelfCheckGPT变体的性质差异,我们期望它们是互补的。因此,我们考虑将SBERT、SQA和Sn-gram的标准化得分简单组合在一起的SelfCheckGPT组合(SelfCheckGPT-Combination)。
Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation
https://arxiv.org/abs/2305.15852
2023.5.25
ETH-Zurich也有一篇类似的工作,着重关注LLM生成回复中的自相矛盾现象,包括评估、检测和消除。
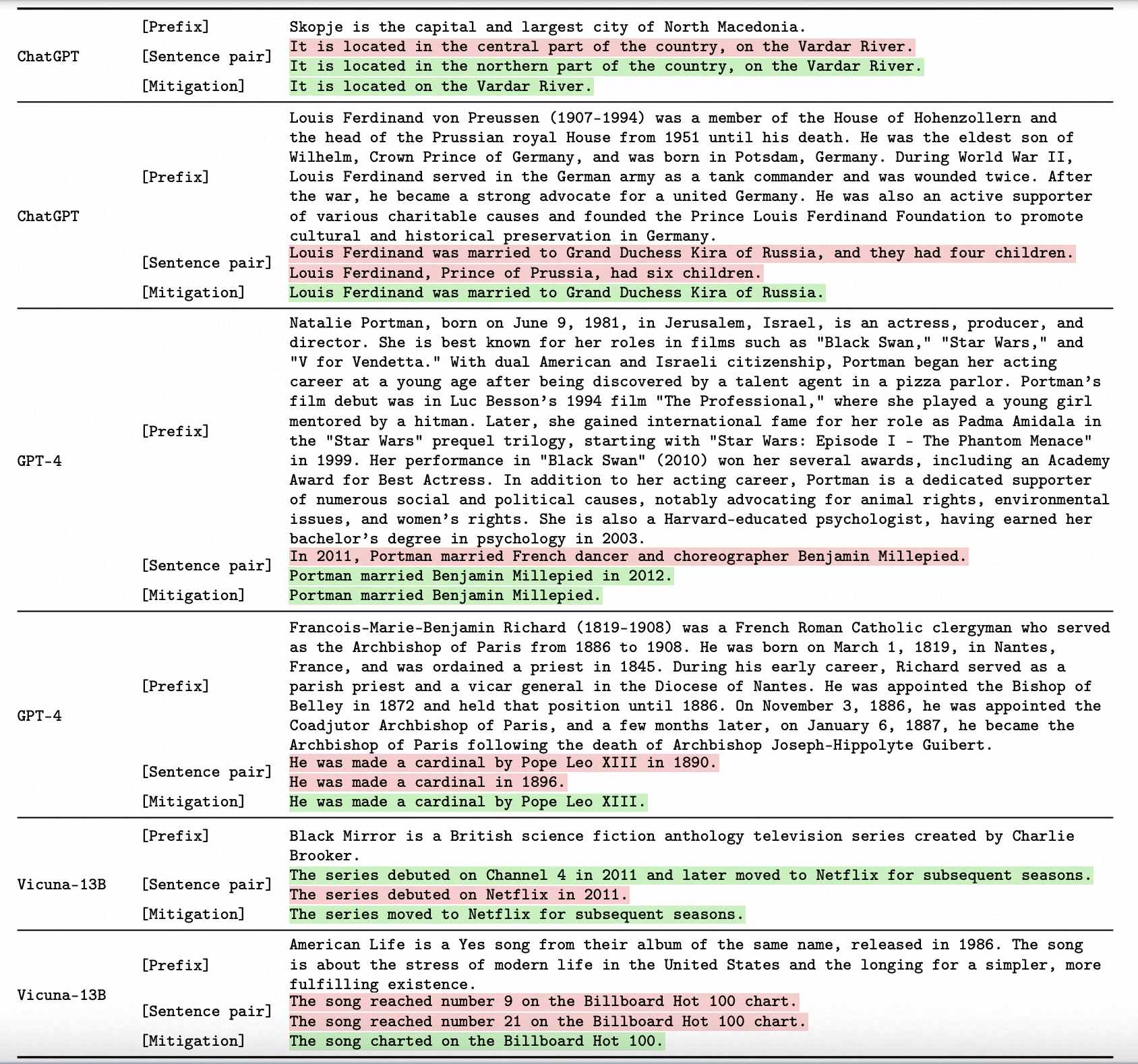
大型语言模型(large LMs)容易产生具有虚构内容的文本。自相矛盾,即LM在同一上下文中生成两个相互矛盾的句子,是一种重要的虚构形式。在这项工作中,我们针对最先进的、以指令微调的的LM对自相矛盾进行了全面的分析,包括评估、检测和缓解。为了有效地引发自相矛盾,我们设计了一个框架,限制LM生成适当的句子对。我们对这些句子对的评估显示,无论是对于著名话题还是不太知名的话题,不同的LM都经常出现自相矛盾。接下来,我们提示LM检测自相矛盾。我们的结果表明,ChatGPT和GPT-4能够准确识别自相矛盾,而Vicuna-13B则难以做到。例如,通过我们最佳的提示方法,ChatGPT在由自身生成的句子对上实现了91.0%的精度和80.5%的召回率。为了自动缓解自相矛盾,我们开发了一个迭代算法,提示LM从生成的文本中删除检测到的自相矛盾。我们的算法成功地修订了文本,显著减少了自相矛盾,同时保持其流畅性和信息性。重要的是,我们整个触发、检测和缓解自相矛盾的流程适用于黑盒LM,并且不需要任何外部基础知识。

- 关于自相矛盾虚构的推理:本文重点研究一种重要类型的虚构内容,称为自相矛盾,即当语言模型在相同的上下文中生成两个逻辑上不一致的句子时发生。检测自相矛盾将揭示语言模型的非事实性,因为这两个句子不能同时正确。
- 我们提出了一个全面的三步方法来进行自相矛盾的推理。我们的方法首先对语言模型施加适当的约束,以生成触发自相矛盾的句子对。然后,我们探索各种策略来促使语言模型检测自相矛盾。最后,我们开发了一个迭代的缓解过程,通过进行局部文本编辑来删除矛盾信息,同时保持流畅性和信息性等其他重要的文本特性。由于我们的方法通过提示进行操作,因此适用于黑盒语言模型,而不依赖于外部的基础知识。
模型生成句子:x = [x1, x2, . . 。., x | x | ]。
用户输入:p
LM的自相矛盾:使用相同上下文c生成的一对句子(x, x′),当两个句子在逻辑上矛盾时,我们将(x, x′)定义为LM的自相矛盾。
由于x和x′都是由LM生成的,它们的矛盾保证暴露LM在上下文c中产生了非真实内容。根据我们的注释,对于ChatGPT生成的200个自相矛盾中,在133个案例中,两个句子都是事实不正确的(且矛盾的);在其余情况下,一个句子是不正确的。 推理自相矛盾不需要任何基础知识
处理幻觉的一种常见方法涉及利用基础知识来识别非事实内容或指导文本生成[19, 28, 39, 53, 57, 58]。然而,这种方法严重依赖高质量的外部资源,这些资源难以获得和昂贵[37, 65, 71]。这引发了一个问题:最新的、强大的LM是否可以直接将单个句子分类为事实正确,而不需要外部资源?为了调查这个问题,我们使用思维链推理[62]提示ChatGPT在我们的人工注释数据集上执行分类任务。我们发现ChatGPT在这项任务中表现困难,仅获得14.2%的低F1分数,这与[15]的结果相一致。因此,我们得出结论,最新的LM仍然不能在没有基础知识的情况下直接处理真实性。
相反,处理自相矛盾只需要逻辑推理,这是最新LM的优势,即使是在零样本情况下[16, 44, 51,55, 69]。这激励我们提示LM推理自相矛盾,而不需要基础知识。我们最佳的提示策略在使用ChatGPT检测其自身自相矛盾时实现了85.4%的F1得分。
触发、检测、缓解自相矛盾
两个LM:gLM生成文本x = [x1,x2,. .。.,x | x | ],而aLM是一个分析器LM。
在句子级别分析自相矛盾,
- extract_contexts(xi,x):提取句子xi的上下文列表,可能使用来自x的元数据信息,例如x所描述的主题。
- gLM.gen_sentence(c):查询gLM以生成与上下文c兼容的新句子x′ i。
- aLM.detect(xi,x′ i,c):调用aLM以预测xi和x′ i在上下文c中是否矛盾。
- aLM.revise(xi,x′ i,c):在上下文c中接收一对矛盾的句子(xi,x′ i)。它调用aLM生成xi的修订版本,删除xi和x′ i之间的冲突信息。修订后的句子还应尽可能保留非冲突信息,并与上下文c一致。

生成一对回答,并检测是否有矛盾,如果有矛盾,则修复

Zero-shot Faithful Factual Error Correction
2023.05.27
http://arxiv.org/abs/2305.07982
为了解决忠实度问题,我们提出了一个零-shot事实错误更正框架(ZEROFEC),受到人类验证和纠正事实错误的启发。当人类发现某个信息可疑时,他们往往首先识别可能存在错误的信息单元,例如名词短语,然后针对每个信息单元提出问题,最后在可信证据中寻找正确答案[3, 4]。ZEROFEC按照类似的过程将事实错误更正任务分解为五个子任务:
(1)主张答案生成:从输入主张中提取所有信息单元,例如名词短语和动词短语;
(2)问题生成:针对每个主张答案和原始主张生成问题,使得每个主张答案是每个生成问题的答案;
(3)问题回答:使用证据作为上下文回答每个生成的问题;
(4)QA-to-claim:将每对生成的问题和答案转换为陈述性语句;
(5)修正评分:根据修正与证据之间的忠实度评分评估修正,其中忠实度通过证据与每个候选修正之间的包含关系得到近似。选择得分最高的修正作为最终输出。
我们的方法确保修正后的信息单元源自证据,有助于提高生成修正的忠实度。此外,我们的方法具有自然的可解释性,因为生成的问题和答案直接反映了与证据进行比较的信息单元。
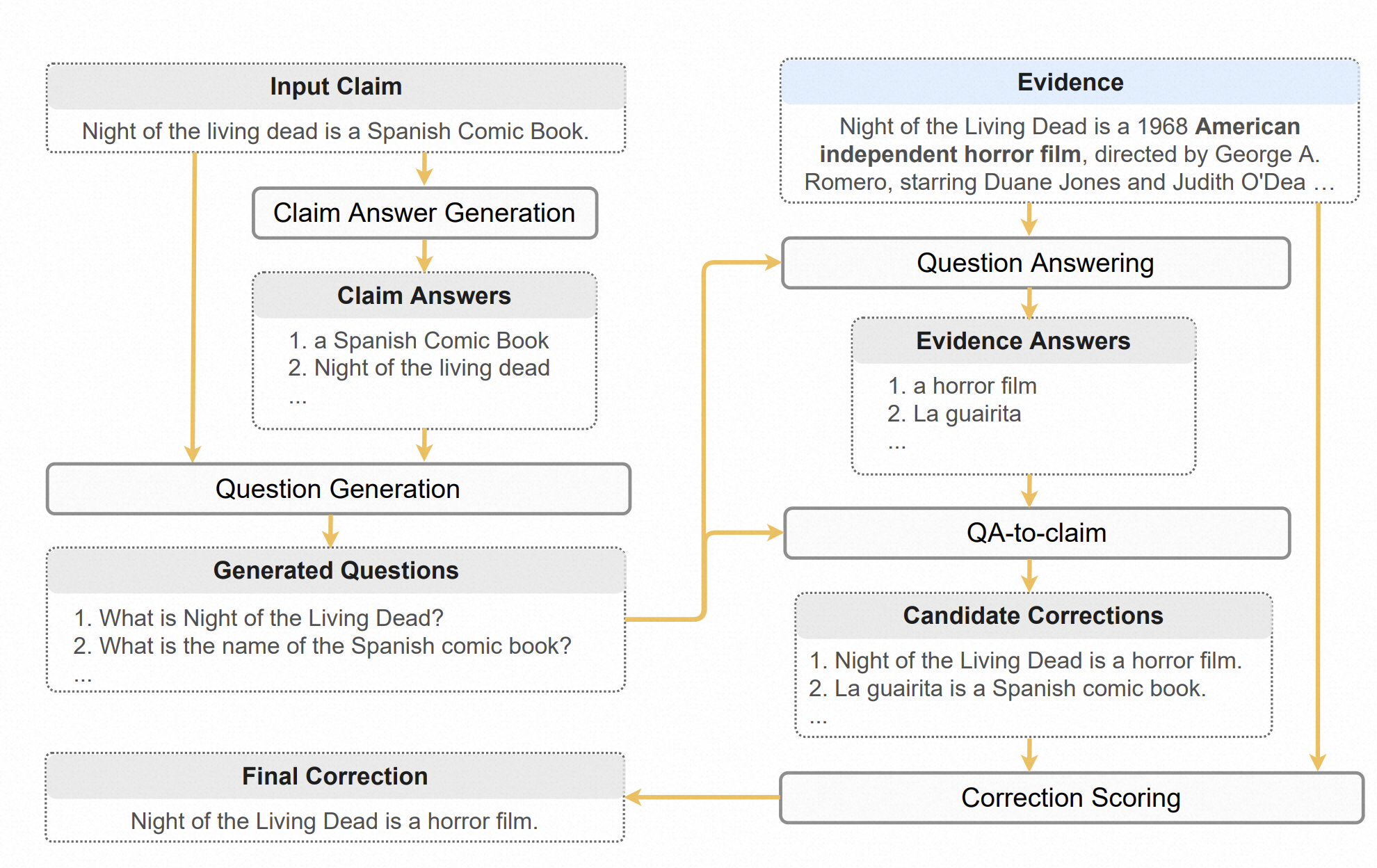
提出了一个五步的零资源事实错误纠正流水线:
- Claim Answer抽取:从陈述中抽取关键信息;
- Question Generation:针对每个关键信息,生成一个问题;
- Question Answer:针对每个问题,将外部证据作为额外输入,进行回答;
- QA-to-claim:将QA-pair转回陈述;
- Correction scoring:额外打分器判断新的陈述是否合理。
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
2023.6.21
通过推理时干预诱导LLM生成符合事实的答案
https://arxiv.org/abs/2306.03341
我们介绍了一种名为推理时干预(ITI)的技术,旨在增强大型语言模型(LLMs)的真实性。ITI通过在有限数量的注意力头中沿着一组方向移动模型激活来进行操作。这种干预显著提高了LLaMA模型在TruthfulQA基准测试中的性能。在经过指令微调的LLaMA(称为Alpaca)上,ITI将其真实性从32.5%提高到65.1%。我们确定了真实性和有用性之间的权衡,并演示了如何通过调整干预强度来平衡它们。ITI是最小侵入且计算成本低廉的技术。此外,该技术数据效率很高:虽然像RLHF这样的方法需要广泛的注释,但ITI仅使用几百个示例即可找到真实的方向。我们的研究结果表明,即使在表面上产生虚假信息,LLMs也可能具有事实上的可能性的内在表示形式。
来自多个方向的证据表明,LLMs有时“知道”的比它们说的更多。在本文中,我们专注于一类具体的错误,即模型在某种程度上“知道”正确答案,但标准的生成策略无法引出这个答案。
Kadavath等(2022)发现语言模型可以生成并自行评估自己的答案,并具有高度的准确性。Saunders等(2022)提出了生成-鉴别差距(G-D gap)的概念,并利用语言模型的自我评价来完善自己的答案。Burns等(2022)通过对一系列语言模型进行无监督聚类,找到了区分正确和错误陈述的线性方向。这些结果表明,语言模型包含与事实相关的潜在可解释结构,这些结构可能在减少错误答案方面具有潜在用途。
为了进一步研究这一领域,我们首先对网络“知道”问题的正确答案是什么进行了操作化定义,即使它没有产生该答案。我们将这定义为生成准确性(由模型的输出衡量)和探测准确性(使用分类器选择一个答案,以模型的中间激活作为输入)之间的差异。使用LLaMa 7B模型应用于Lin等(2021)的TruthfulQA基准测试中,这是一个困难的、敌对设计的用于测试真实行为的测试,我们观察到探测准确性和生成准确性之间存在40%的差异。这个统计数据指向了中间层存在的信息与输出中出现的信息之间的重大差距。
为了弥合这个差距(弥合“知道”和“说出来”的差距),我们引入了一种称为推理时干预(ITI)的技术。在高层次上,我们首先识别出一组具有高线性探测准确性的稀疏注意力头,用于真实性。然后,在推理过程中,我们沿着这些与真实相关的方向移动激活。我们重复相同的干预操作,直到生成整个答案。ITI显著提高了TruthfulQA基准测试的性能。在两个具有不同数据分布的基准测试中,我们也观察到了较小但非零的性能改进。
我们不断强调,ITI本身远远不足以确保LLMs的真实答案。然而,我们相信这种技术显示出了潜力;通过进一步的测试和开发,它可以作为更全面方法的一部分发挥作用。
哈佛的工作,本文中作者提出了一种推理时干预的策略(ITI)提升LLM生成答案的事实性。
作者假设:LLMs know more than they say,LLM内部存在着隐藏的、可解释的结构,这些结构和事实性息息相关,因此可以通过干预:
- 作者探索了LLM的生成回复准确率(直接回答问题)和Probe准确率(用一个linear classifier基于中间状态选择回答)的关系,发现LLM很多情况下知道知识,但无法正确生成回复。
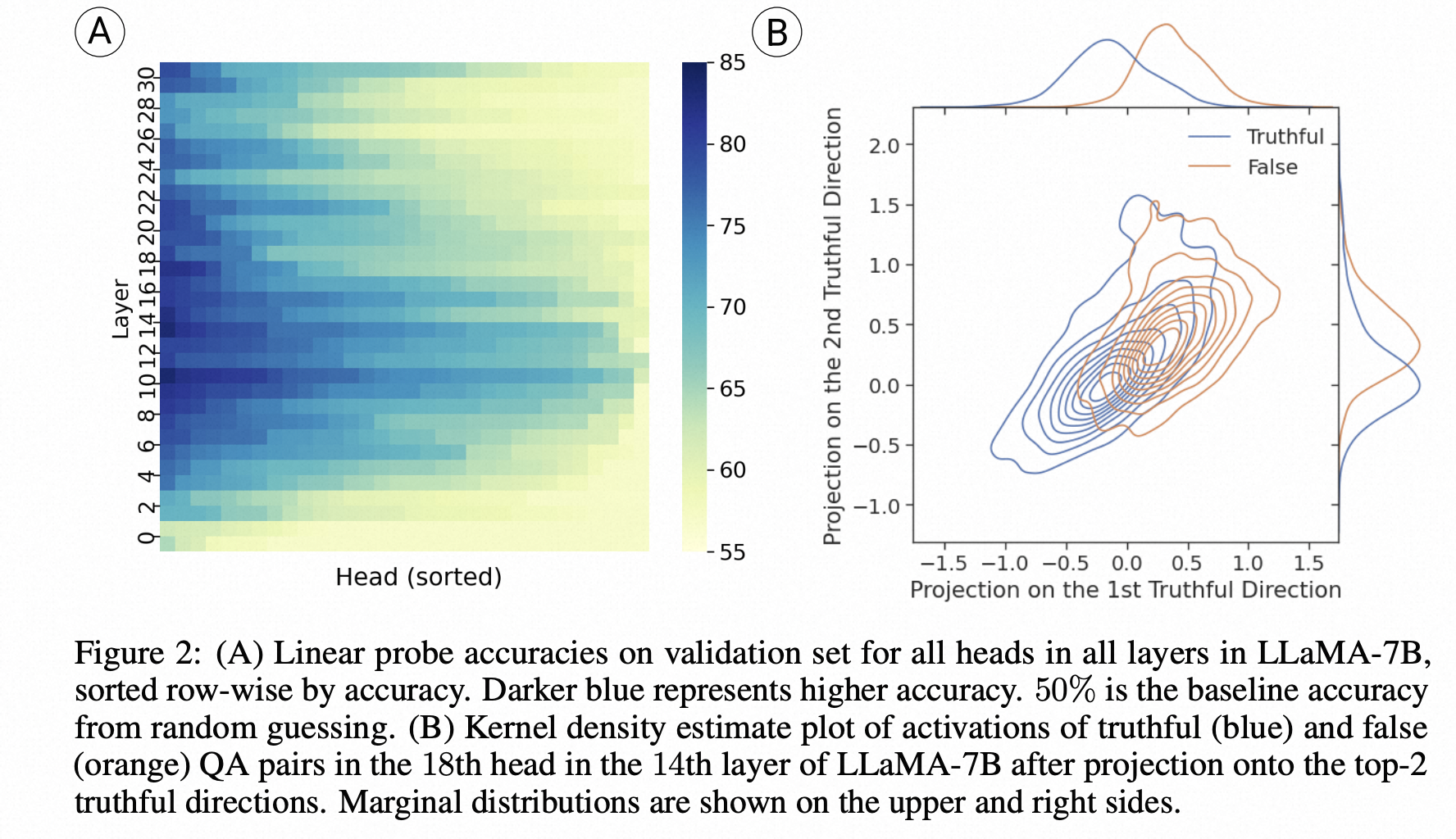
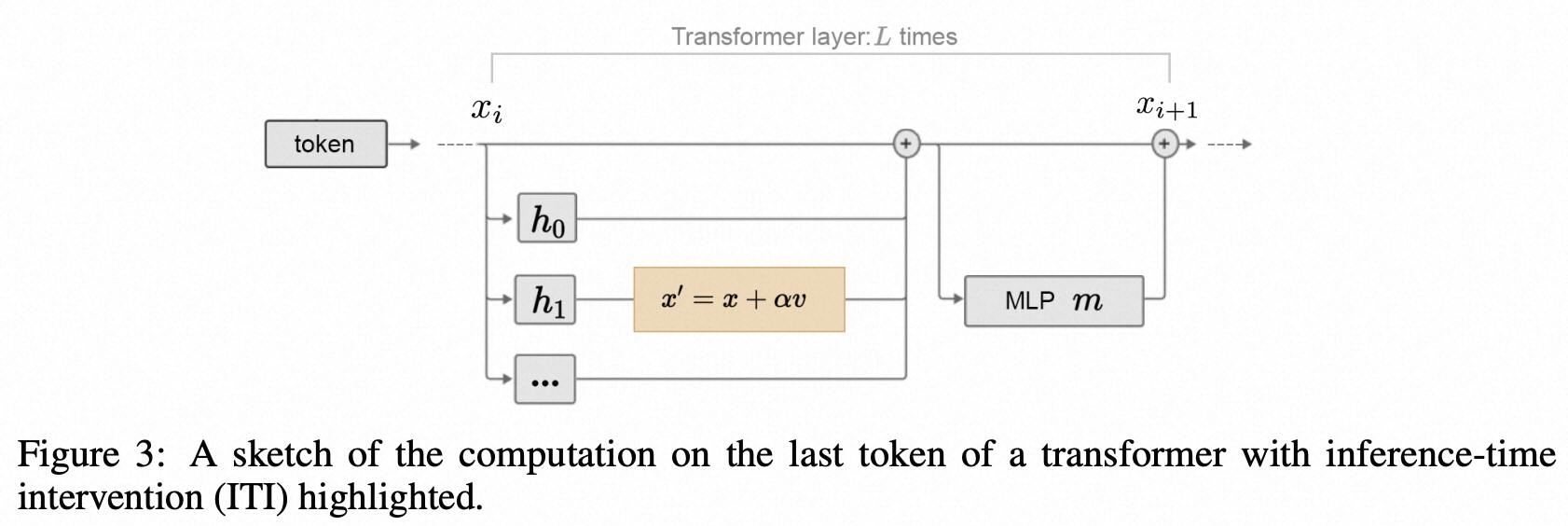
- ITI方法选择和事实知识紧密相关的head,进行干预,让激活值移动到truthful相关的方向,实验表明能够有效提升回复的事实性。
训练小模型后处理幻觉问题
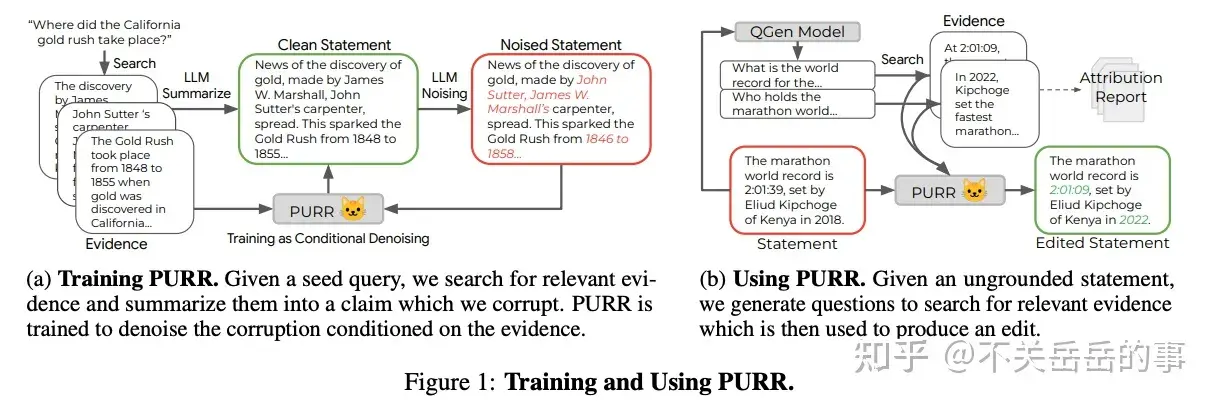
Google的工作,核心思想是用LLM自动对一个正确样本生成幻觉样本,组成平行语料,训练一个T5学会降噪:
- 根据文档、干净的陈述,利用LLM对陈述进行加噪,使其含有幻觉问题;
- 将文档和含有幻觉的文本作为输入,干净的文本作为输出,训练一个小模型用于降噪(去幻觉)
- 推理时,对给定的陈述,先使用QG模型生成一系列问题,再根据问题召回证据,将证据文档和陈述传入小模型进行幻觉的编辑和修正。
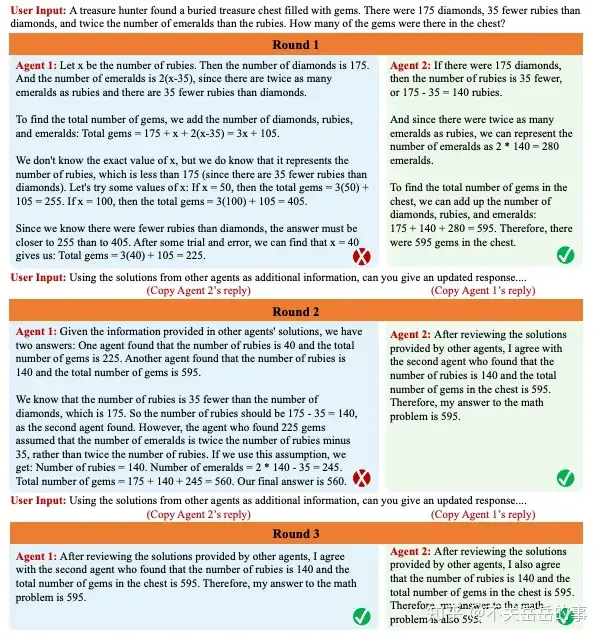
利用多智能体辩论显著提升LM的事实性和推理能力
MIT&Google,利用多个智能体(LLM)相互辩论来解决事实性问题,相当于是一种变相的self-verify。
Language models (mostly) know what they know
- 解码算法:带有随机性的解码算法(如Top-P)显著比贪心解码生成的内容更不符合事实;
- 基于这个发现作者还提出了一个非常简单的top-p解码算法优化,在生成的diversity和factuality中寻求trade-off:
- p随时间步衰减(后期生成的内容更可能不符合事实),每次生成一个新句子(通过检测是否生成了句号)重新初始化p,并且p的衰减可以定一个下界;
香港科技大学的综述《Survey of Hallucination in Natural Language Generation》
https://zhuanlan.zhihu.com/p/626544154
2023.5.4
Vectara平台
Vectara是一个专注于对话体验的平台,它提供了强大的检索、摘要和生成功能,以及简单易用的开发者接口。Vectara平台使用了一种叫做基于事实的生成(Grounded Generation)的方法,在生成文本之前和之后都进行事实检索和验证,确保生成内容是有意义且忠实于源内容的。具体来说,基于事实的生成方法包括以下几个步骤:
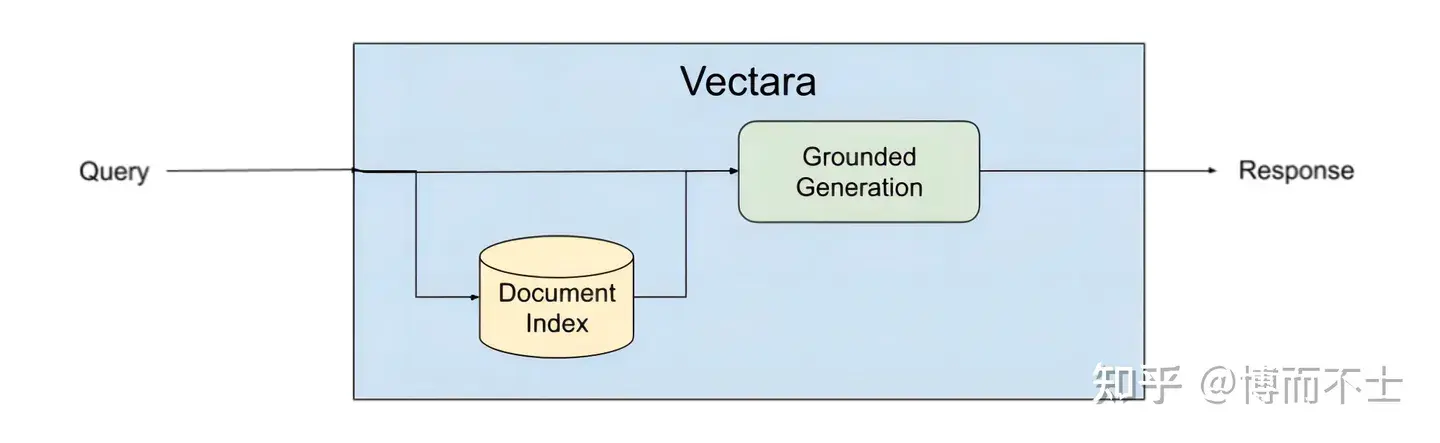
- 输入:给定一个文本或语音输入,例如一个问题、一个指令、一个话题等。
- 检索:根据输入,在互联网或其他数据源中检索相关的事实信息,例如网页、文章、数据库等。
- 验证:根据检索到的事实信息,对输入进行验证,判断其是否合理、准确、完整等。如果输入不符合要求,可以提出修改或补充的建议。
- 生成:根据验证后的输入和检索到的事实信息,使用LLM生成相应的文本或语音输出。
- 验证:根据检索到的事实信息,对生成的输出进行验证,判断其是否有意义、忠实、一致等。如果输出不符合要求,可以进行修改或重写。
通过这样一个循环的过程,基于事实的生成方法可以有效地避免或减少LLM幻觉,提高LLM生成内容的质量和可信度。