
这个问题可以参考 Google Gemini技术报告上的讨论,详情阅读谷歌 Gemini 技术报告的第三部分,内容涵盖全面的负责任的部署——探讨了安全性、有用性、危害缓解、指令微调、事实性、幻觉,以及讨论和结论两部分内容。Google Gemini技术报告的第一部分和第二部分如下:
6. 负责任的部署
在Gemini模型的开发过程中,我们遵循结构化的责任部署方法,以识别、衡量和管理我们模型的可预见的下游社会影响,这与谷歌之前发布的AI技术保持一致【How our principles helped define alphafold’s release】。在项目的整个生命周期中,我们遵循以下结构。本节概述了我们通过这一过程的总体方法和关键发现。
本号持续关注通用人工智能AGI,大模型、知识图谱、多模态等各种最前沿的人工智能技术,欢迎关注!
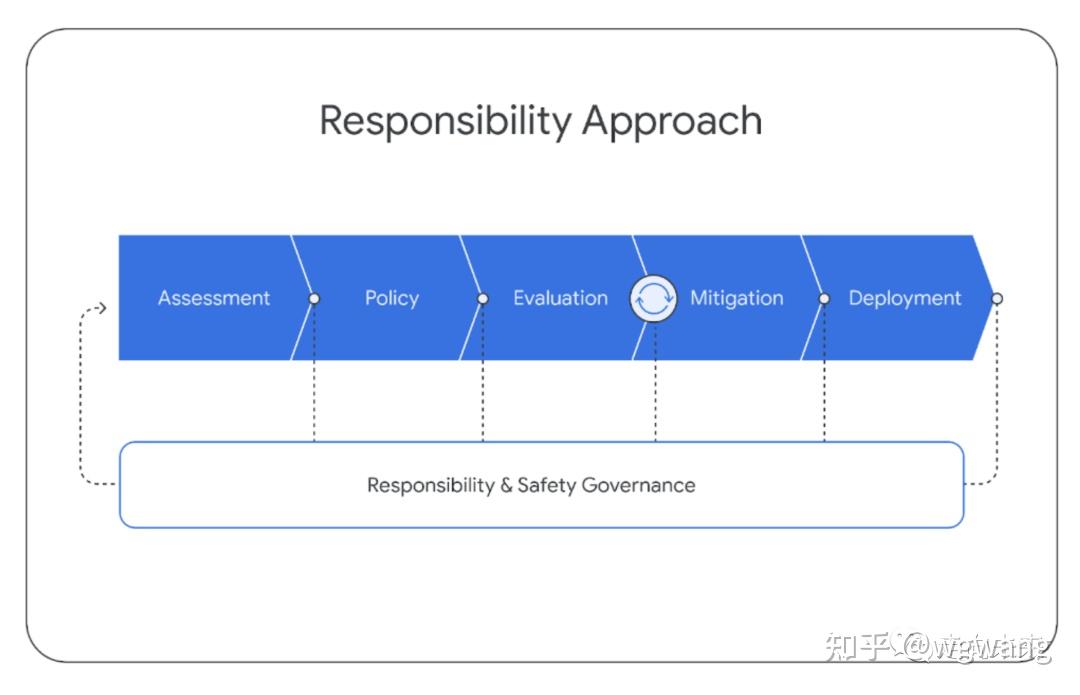
6.1. 影响评价 Impact Assessment
我们开发了模型影响评价体系来以识别、评价和记录与先进的Gemini模型开发相关的关键下游社会利益和危害。这些是基于语言模型风险的先前学术文献【Ethical and social risks of harm from language models】、类似行业先前开展的类似练习的发现【PaLM2——《Palm 2 technical report》,Claud-《Training a helpful and harmless assistant with reinforcement learning from human feedback》和GPT-4——《GPT-4 Technical Report》】、与内外部专家的持续接触,以及非结构化尝试发现新模型漏洞而得出的。关注领域包括:事实性、儿童安全、有害内容、网络安全、生物风险、代表性和包容性。这些评价与模型开发同步更新。 影响评价用于指导缓解和产品交付的工作,并通知部署决策。Gemini影响评价涵盖了Gemini模型的不同能力,评价了这些能力与谷歌AI原则【Google’s AI Principles】的潜在后果。
6.2. 模型策略 Model Policy
在对已知和预期影响有了上述的理解的基础上,我们制定了一套“模型策略”,以指导模型开发和评估。模型策略的定义担任了负责任开发的标准化准则和优先级模式,并担任了发布准备是否妥当的指标。Gemini模型策略涵盖了许多领域,包括:儿童安全、仇恨言论、事实准确性、公平和包容性以及骚扰。
6.3. 评估 Evaluations
为了能够根据影响评价体系来来评价Gemini模型违反策略领域和其他关键风险领域,我们在整个模型开发生命周期内开发了一套评估套件。 开发评估的目的是在整个Gemini模型的训练和微调过程中进行“爬坡”。这些评估是由Gemini团队设计的,或者是针对外部学术基准的评估。评估考虑了有用性(指令遵循和创造力)、安全性和事实性等问题。请参阅第5.1.6节和下一节关于缓解措施的部分结果样本。 进行保证评估(Assurance evaluations)的目的是治理和审查,通常由模型开发团队之外的小组在关键里程碑或训练结束时完成。由模态和数据集标准化的保证评估是严格保留的。只有高级见解会反馈给训练过程来协助缓解工作。保证评估包括跨Gemini策略的测试,并包括对潜在生物危害、说服和网络安全等危险功能的持续测试【Model evaluation for extreme risks】。 外部评估由谷歌公司外的合作伙伴进行,以识别盲点。外部小组会针对一系列问题对我们的模型进行压力测试,包括白宫承诺(White House Commitments)【Ensuring Safe, Secure, and Trustworthy AI,https://whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf,核心是Safety模型安全,Security系统安全和Trust 可信】中列出的各个领域,并通过结构化评估和非结构化红队评估【红队评估是一种用于引出模型不良行为漏洞的评估形式。类似于借鉴黑客攻击的手法和技巧,在可控的范围内对业务系统开展模拟测试,找出其存在的漏洞,并提供安全修复建议。】的组合进行测试。这些评估的设计是独立的,结果会定期报告给谷歌DeepMind团队。 除了这套外部评估套件之外,专业内部团队还会针对我们的模型持续开展红队评估,内容涉及Gemini策略和安全 Security等领域。这些活动包括较少结构化流程,涉及复杂的对抗性攻击,以识别新的漏洞(vulnerabilities)。发现潜在弱点可在随后用于减轻风险和改进内部评估方法。我们致力于持续的模型透明度,并计划随着时间的推移分享我们评估套件的更多结果。
6.4. 缓解措施
缓解措施是针对上述评价、策略和评估方法的结果而做的。评估和缓解措施以迭代方式进行工作,在缓解措施之后重新运行评估。我们在数据、指令调优和事实性方面讨论了减轻模型伤害的努力。
6.4.1. 数据
在训练之前,我们在数据整理和数据收集阶段采取了各种步骤来缓解潜在的下游伤害。正如“训练数据集”一节所讨论的,我们会过滤掉训练数据中的高风险内容,并确保所有训练数据的质量足够高。除了过滤之外,我们还采取措施确保所有收集的数据符合谷歌DeepMind的数据丰富最佳实践,这是基于人工智能合作伙伴关系的“数据丰富服务的负责任采购”而制定的。这包括确保所有数据丰富工作人员的工资至少达到当地的生活工资。【https://deepmind.google/discover/blog/best-practices-for-data-enrichment/】
6.4.2. 指令调优
指令调优包括有监督微调(SFT)和使用奖励模型的人类反馈的强化学习(RLHF)。我们在文本和多模态设置中应用指令调优。通过非常仔细地设计指令调优方法来平衡提升有用性和降低模型在安全性和幻觉方面的风险【Anthropic 的论文《Training a helpful and harmless assistant with reinforcement learning from human feedback》】。 SFT、奖励模型训练和RLHF的“优质”数据整理至关重要。 数据混合比例在较小的模型上进行了消融实验,以平衡有用性指标(如指令遵循、创造力)和减少模型损害,这些结果可以很好地推广到更大的模型。 我们还观察到,与数据量相比,数据质量更重要(LLaMA2论文,以及《Don’t make your llm an evaluation benchmark cheater》),尤其是对于更大的模型。 类似地,对于奖励模型训练,我们发现关键是平衡包含模型数据集中出于安全原因选择“我无法帮助”的样本和模型输出有用响应的样本。 我们使用有用性、事实性和安全性的奖励得分的加权和来训练一个多头奖励模型,并使用了多目标优化的方法。 我们进一步详细阐述了减轻有害文本生成风险的方法。 我们列举了大约20种伤害类型(例如,仇恨言论、提供医疗建议、建议危险行为),这些类型涵盖各种用例。 我们为这些类型生成潜在伤害诱导查询数据集,这些数据既可以是由策略专家和ML工程师手动生成的,也可以通过使用主题关键字作为种子来提示高能力语言模型自动生成。 给定可能诱导伤害的查询来探测Gemini模型,并使用并排评估来分析模型响应。 如上所述,我们的目标是平衡模型输出响应的无害性与有用性之间的平衡。 从检测到的风险领域,我们创建附加的有监督微调数据以演示期望的响应。 为了大规模生成此类响应,我们严重依赖于一个自定义的数据生成方法,该方法受到宪法AI (Constitutional AI)【参考《Constitutional ai: Harmlessness from ai feedback》】的启发,将谷歌内容政策语言的变体作为“宪法”注入,并利用语言模型强大的零样本推理能力【《Large Language Models are Zero-Shot Reasoners》】修正响应,以及在多个响应候选者之间进行选择。我们发现这个方法非常有效——例如,在Gemini Pro中,这个总方法能够缓解我们识别的大多数文本伤害案例,而响应的可用性没有明显下降。
6.4.3. 事实
在许多场景中,模型能够生成事实响应并减少幻觉的频率是非常重要。 我们将指令调优工作重点放在实际场景中的三种关键期望行为上:
- 归因Attribution:如果模型被指示所生成的响应应当完全归因于提示中的给定上下文,那么Gemini应生成对上下文最高程度的忠实响应【《Measuring attribution in natural language generation models》】。 这包括总结用户提供的来源、根据给定的问题和所提供的片段来生成细粒度引文【《Teaching language models to support answers with verified quotes》,《Check your facts and try again: Improving large language models with external knowledge and automated feedback》】、根据书籍等长篇来源来回答问题【《Can a suit of armor conduct electricity? a new dataset for open book question answering》】,以及将给定来源转换为所需输出(例如,从会议录音的一部分生成电子邮件)。
- 难题响应生成Closed-Book Response Generation:如果没有任何给定来源的情况下提出寻求事实的提示,那么Gemini不应幻想不正确的信息(请参阅文章《How much knowledge can you pack into the parameters of a language model?》的第2节的定义)。这些提示包括从寻求信息的提示(例如“印度总理是谁?”)到可能会要求事实信息的半创意提示(例如“写一篇500字的支持采用可再生能源的演讲”)。
- 规避Hedging:如果输入提示是无法回答的,Gemini不应该幻想。相反,它应该通过规避来承认无法提供响应。这些场景包括带有错误前提问题的提示【《Won’t get fooled again: Answering questions with false premises》】,带有开放性问答但给定上下文无法导出答案的输入提示指令,等等。
幻觉问题上,大模型本身是无法解决的。特别的,最近Andrej Karpathy在X 上提出,幻觉是大模型所能做的一切,或者说,大模型就是“造梦机器”。所以,如果要减少或避免幻觉,必须采用其他技术,比如知识图谱。有篇文章的标题取的特别好,就是:大模型产业落地难,知识图谱来帮忙!
关于知识图谱,推荐一本书,详细介绍了知识图谱的方方面面,甚至可能是最早提及多模态知识融合和向量数据库的书籍,书中也详细解析了Transformer 架构,以及对因果推理、概率推理、归纳推理和演绎推理的解析与描述。
我们通过策划定向的有监督微调数据集和执行RLHF来引出Gemini模型的这些期望行为。 请注意,这里产生的结果不包括给予Gemini声称可以提高事实性的工具或检索【《Teaching language models to support answers with verified quotes》,《Check your facts and try again: Improving large language models with external knowledge and automated feedback.》】。 我们在下面提供了各自的挑战集上的三个关键结果。
- 事实性集Factuality Set: 包含事实寻求提示(主要是难解之题、难题、谜题)的评估集。这是通过人工标注员手动事实检查每个响应来进行评估的; 我们报告标注员判断的事实不准确的响应百分比。
- 归因集Attribution Set: 包含需要对提示中的来源进行归因的各种提示组成的评估集。这是通过人工标注员手动检查每个响应中对提示中的来源的归因进行评估的; 报告的指标是AIS【参阅《Measuring attribution in natural language generation models》】。
- 规避集Hedging Set: 自动评估设置,我们衡量Gemini模型是否准确地规避。
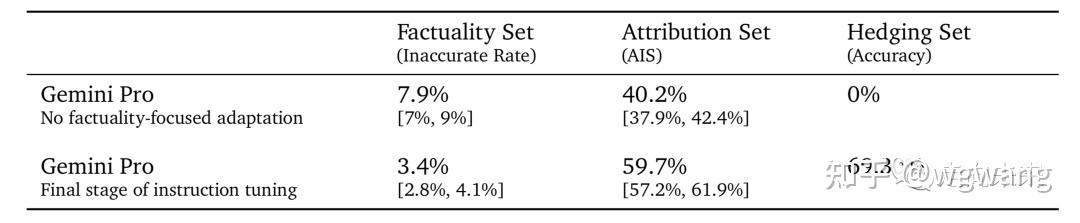
我们将指令调优的Gemini Pro与没有任何事实重点适应的指令调优Gemini Pro版本进行了比较,如表14所示。我们观察到:
- 在事实性集合中,不准确率减半;
- 在归因集合中,归因的准确性提高了50%;
- 在提供的规避集任务中,模型成功地规避了70%(从0%上升)。
6.5. 部署
在评审完成后,会为每个批准的Gemini模型创建作为结构化和一致的内部文档的模型卡片,内容包括关键性能和负责任指标。同时,也会适时对外部沟通这些指标。
6.6. 负责任的治理
在整个负责任开发过程中,我们与谷歌DeepMind的责任与安全委员会(Responsibility and Safety Council, RSC)进行道德和安全审查。RSC是一个跨学科小组,根据谷歌AI原则评估DeepMind的项目、论文和合作。 RSC对影响评价、政策、评估和缓解工作提供意见和反馈。 在Gemini项目期间,RSC针对关键政策领域(例如儿童安全)制定了具体的评估目标。
7、讨论和结论
我们展示了Gemini模型家族,它提高了文本、代码、图像、音频和视频的多模态模型能力。这份技术报告评估了Gemini在多样的、广泛研究的评测基准上的能力,而且我们最强的模型Gemini Ultra在各个方面都取得了显著进步。在自然语言领域,通过在数据和大规模模型训练上的精心开发而获得的性能提升和持续的质量改进,在几个基准测试中创造了新的最高水平。特别是,Gemini Ultra超过了人类专家在考试基准MMLU上的表现,得分90.0%,自2020年首次发布以来,这一直是量化LLM进步的事实标准。在多模态领域,Gemini Ultra在大多数图像理解、视频理解和音频理解基准测试中推高了最高的水平,而无需进行特定于任务的修改或调优。特别是,Gemini Ultra的多模态推理能力从其在最近的MMMU基准测试上的最高水平得到证实,该数据集由需要大学水平的学科知识和深思熟虑的推理才能完成的图像相关的问题组成。 除了基准测试上的最先进结果之外,最激动人心的是Gemini模型支持的新用例。Gemini模型的新功能包括解析复杂图像(如图表或信息图),在交错的图像、音频和文本序列上进行推理,生成交错文本和图像响应。这些新功能为各种新应用打开了广阔的空间。正如报告和附录中的图所示,Gemini可以在教育、日常问题解决、多语言交流、信息概括、抽取和创造力等领域带来新的方法。我们期待这些模型的用户会发现各种各样的新用途,这些用途我们在自己的调查中只是触及了表面。 尽管它们的功能令人印象深刻,但我们应该注意,LLM的使用存在局限性。需要持续进行研究和开发LLM生成的“幻觉”,以确保模型输出更加可靠和可验证。尽管LLM在考试基准测试上取得了令人印象深刻的表现,但模型仍然挣扎在需要像因果理解、逻辑推理和反事实推理等高层推理能力的任务上。这强调了需要更具挑战性和健壮的评估来测量它们的真实理解力,因为目前最先进的LLM饱和了许多基准测试。 Gemini是我们在实现智能、推进科学、造福人类的使命上迈进了一步。我们热切地期待看到这些模型如何被我们在谷歌的同事和更多人的使用。我们建立在机器学习、数据、基础设施和负责任开发等领域的许多创新之上——这些是我们在谷歌十多年来一直在追求的领域。我们在本报告中提出的模型为我们更广泛的未来目标奠定了坚实的基础,即开发一个跨许多模态、具备广泛的泛化能力的大规模模块化的系统(a large-scale, modularized system that will have broad generalization capabilities across many modalities)。
进一步阅读
以及更多文章:
- GPT-4模型架构:它比你想象的更简单
- AGI开始使用工具,chatGPT开放插件系统
- 语言≠知识:万字长文看语言通天塔的建成和神经网络大模型的固有缺陷——与Bing Chat关于苏东坡的对话实录
- 开源开放大模型全观察之LLaMA-2
- 开源开放大模型观察之LLaMA
- 开源开放大模型观察之baichuan-7B
- 深度全解析开放开源大模型之BLOOM
- 珠峰书《知识图谱:认知智能理论与实战》“升级”了:配套PPT,教学更easy!
- 知识图谱和大模型在全球供应链体系数字化中的应用:上海国际物流节发言总结和补充
- 大模型时代,AI原生启航
- 被ChatGPT带入悬崖的律师
- ChatGPT不仅把律师带入悬崖,还给“他爸”带来了麻烦
- 上海世界人工智能大会WAIC,好看的点都在这里:大模型是绝对的王者,其他呢?
- ChatGPT是如何铸就的?且看屠龙刀ChatGPT现身AI江湖的故事
- ChatGPT是如何铸就的?且看屠龙刀ChatGPT现身AI江湖的故事
- 大语言模型LLMs技术精粹总纲:重剑无锋,大巧不工——且看AI江湖刀剑争锋的源流
- 大语言模型LLMs技术精粹,Transformer模型架构全解析:三生万物——且看AI江湖基石
- 大语言模型LLMs技术精粹,稀疏变换器网络全解析:变则通,通则久——且看AI江湖基石
- 大语言模型LLMs技术精粹,GPT-1架构全解析:九层之台起于累土——且看AI江湖之起高楼
- 始自 ChatGPT,迈向AGI:于《四川日报:川观智库》问计高质量发展及包含 GPT-4的内容补充
- 从悉尼到普罗米修斯:New Bing的表演
- New Bing技术架构普罗米修斯:AGI 驱动智能应用开发的基本框架
- New Bing和 ChatGPT 的测评:我女朋友的老公应该叫我什么?以及更复杂的衍生问题
- 谷歌Bard和微软Bing像两个技术宅在相亲的聊天,还会转换话题,这也太强了!
- 我女朋友的老公应该叫我什么?Claude 像外企工作的中国人,文心一言则一言难尽
- 从地图看124个国产大模型的全国分布,至今仍空白的省份何时填补?
- 应用端的百模大战,被智子锁定中国的基础模型:国产大模型虽达120个却多而不强!
- 国产大模型达113个,LLaMA2发布之下,百模争霸何去何从?
- 国产108个大模型,谁是36天罡?谁是72地煞?百模争霸排行榜
- 恭喜中国,“百模”成就达成!国产大模型103个,下一站:百模争霸,谁将持续霸榜!
- 国产大模型即将破百,达93个,北京占比首次降到45%,沪粤浙紧追不舍
- 国产大模型突破80个,Google开始为Gemini造势:百模大战V6
- 百模大战V5:收录74个国产大模型,国产开源有进展但仍然非常弱
- 百模大战达成率68%,如何解决群模乱舞之下的资源浪费,国产开源之路有待探索!国产大模型观察V4
- 百模大战完成率58%,北京占半壁江山:国产大模型观察V3,
- 国产大模型观察:群模乱舞,挖掘已发布超过50个大模型,获得大模型发布三部曲的惊天秘密
- 中国大模型产业发展白皮书