如何评价 DeepSeek 于 2025 年 8 月 19 日更新的 V3.1 版本?

- 642 个点赞 👍
省流:悲!也许没有 R2 了!V3.1 把 R1 给融了!
重点 1:别被官方微信公告带沟里,128K 不是重点!模型融合推理才是重点!
重点 2:DeepSeek V3-0324 和 DeepSeek V3 用的同一个 base model,但这次的 V3.1 放出了新的 base model,大概率是重新训的新模型。
DeepSeek 的逻辑可能是,只要 base model 没换,就用日期做版本;重新训了 base model,就改版本号。
先在前面更新一下我的主观感受:
DeepSeek V3.1 有进步,但不多。反而以前的老毛病回来不少:幻觉、中英文混杂。
如果只是一次实验性的关于 Chat、Reasoning 模型融合的测试,那 V3.1 是一次合格的增量更新。往好处想,如果 V3.1 成了,那将来不用单独部署两套模型,节约了很多部署运维的精力,提高了算力利用效率。
但如果这是未来一段时间 DeepSeek 的主力模型,而 V4 依旧遥远、R2 再也不见的话,那大家的很多期待也许就落空了。
当然,GPT-5 的社区口碑也是先崩了一波然后回暖的,让子弹再飞一会,听听社区对 V3.1 的真实反馈(欢迎评论区交流分享各种体感和实测 case)。
目前只见到了微信群里的消息,所以还在蹲官方的模型开源以及文档更新,按照惯例会放出新的 Benchmark 成绩和能力说明。
Update 一下,DeepSeek V3.1 Base 的模型地址已经放出来了[1](但还没有 model card):
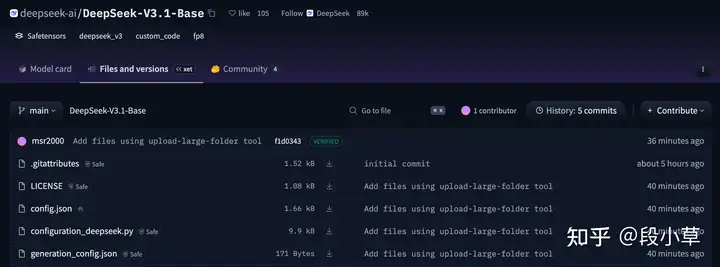
按照微信群里的说明,这次更新的「重点」是上下文支持到了 128K:


但是,128K 绝对不是这次更新的重点。因为 DeepSeek V3/R1 的 Context Length 其实一直都是 128K,只不过 DeepSeek 官方的 API 之前只支持到 64K。
官方在 V3-0324 的说明里写的很明白了:
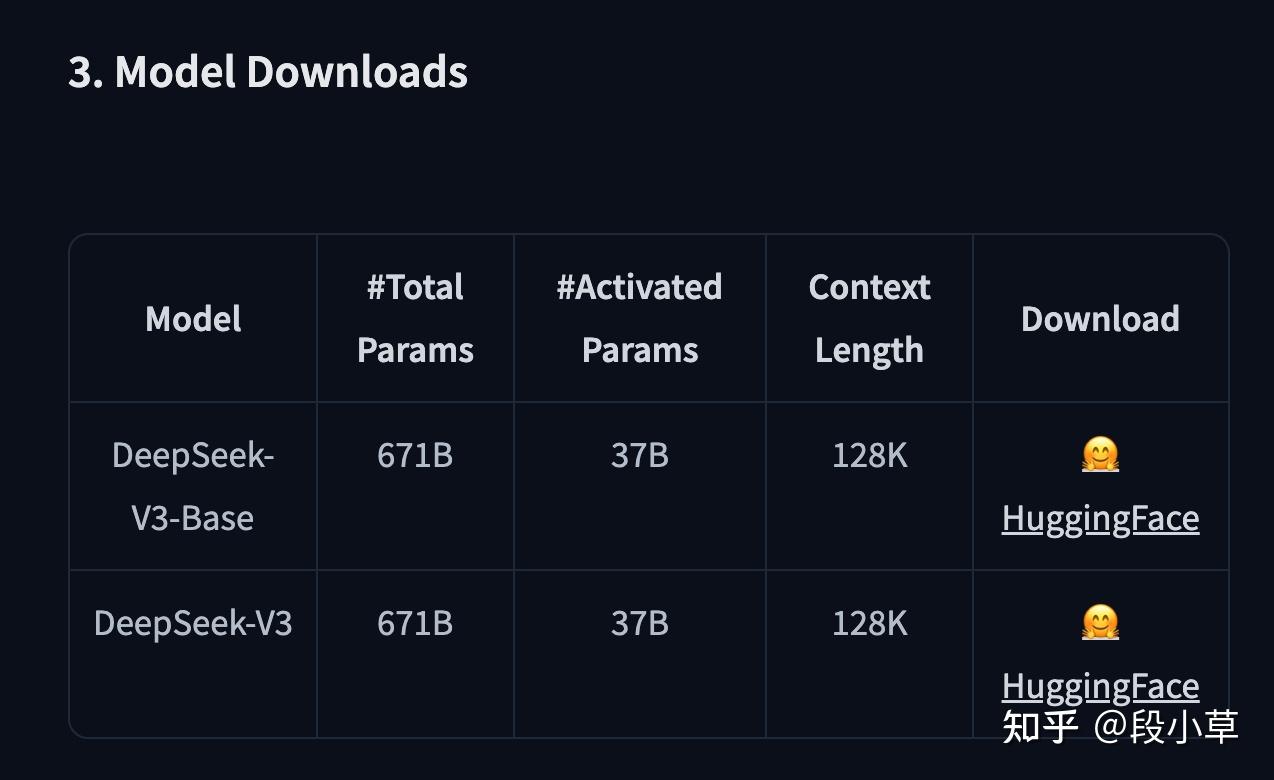
模型参数约 660B,开源版本上下文长度为 128K(网页端、App 和 API 提供 64K 上下文)
再比如,DeepSeek V3 HuggingFace 模型页[2]
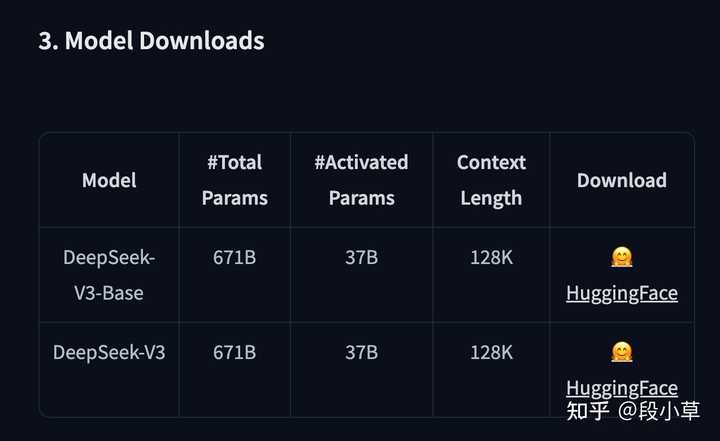

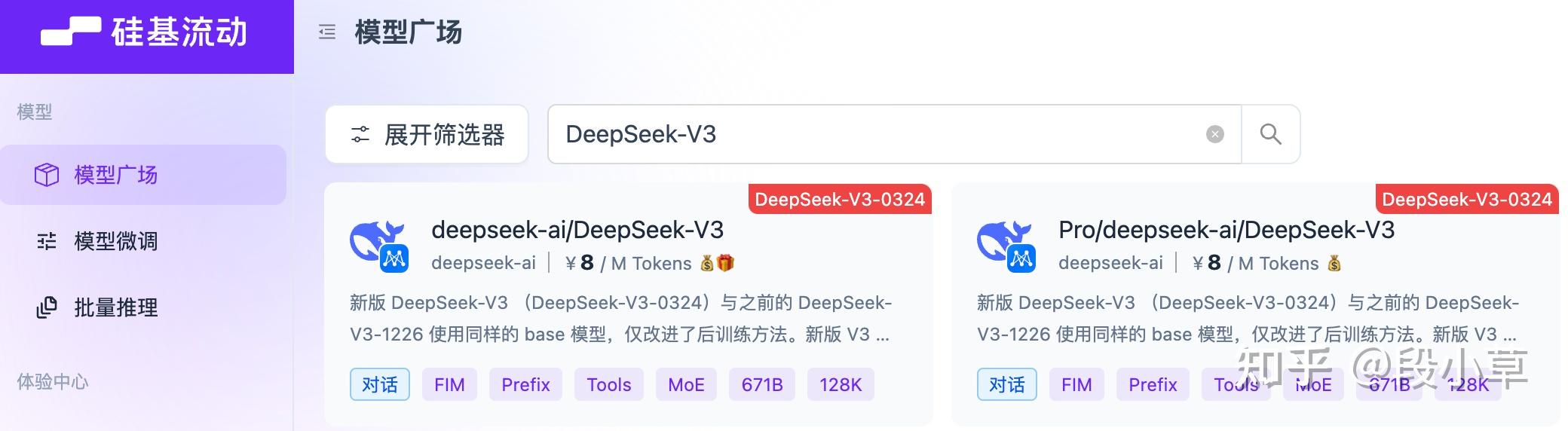
SiliconFlow 上的 DeepSeek V3-0324 模型 API 上下文是 128K
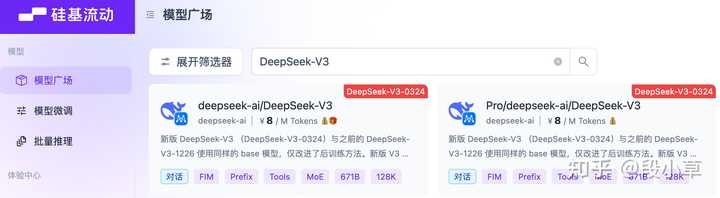

火山引擎上的 DeepSeek 模型 API 上下文均是 128K


虽然上下文长度很重要,但这次最多只能说官方愿意消耗更多算力提供更长的上下文,除非有什么新的扩展上下文同时节约算力的黑科技,否则这并不是重点。
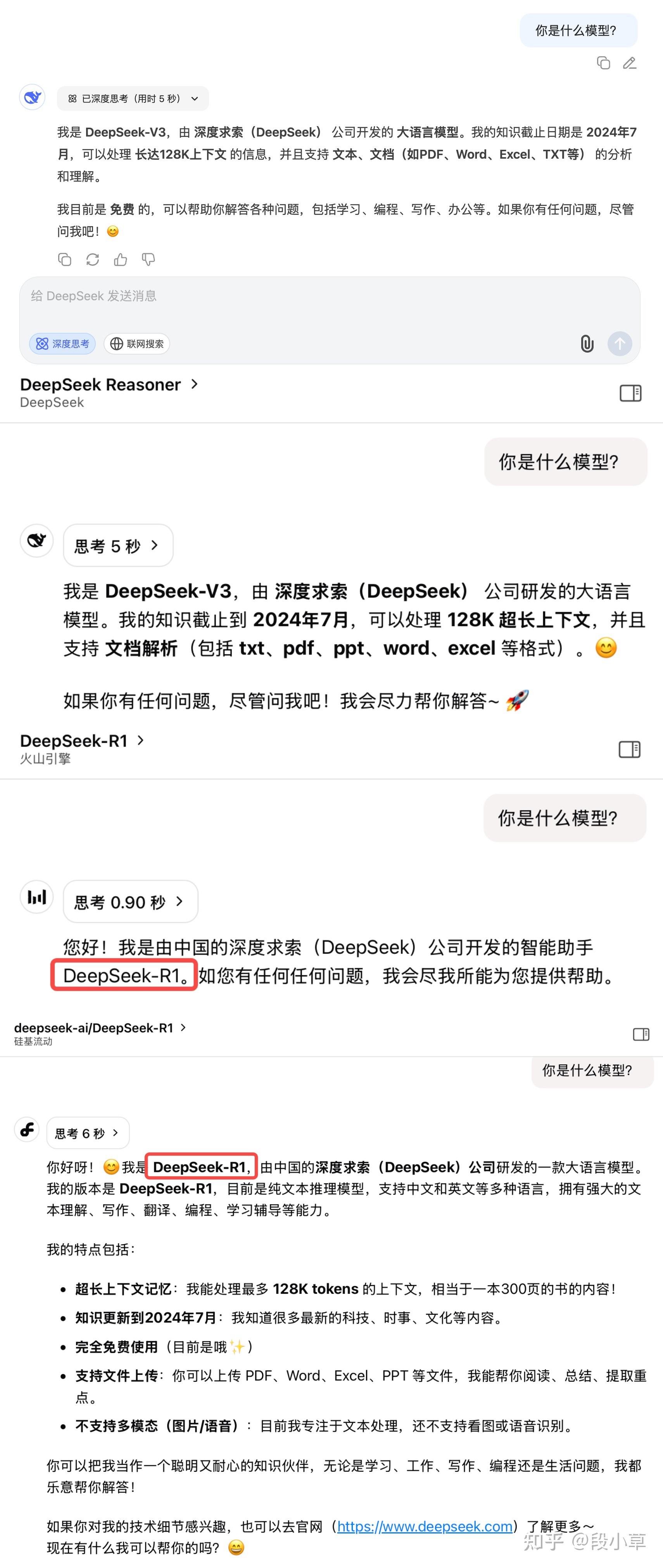
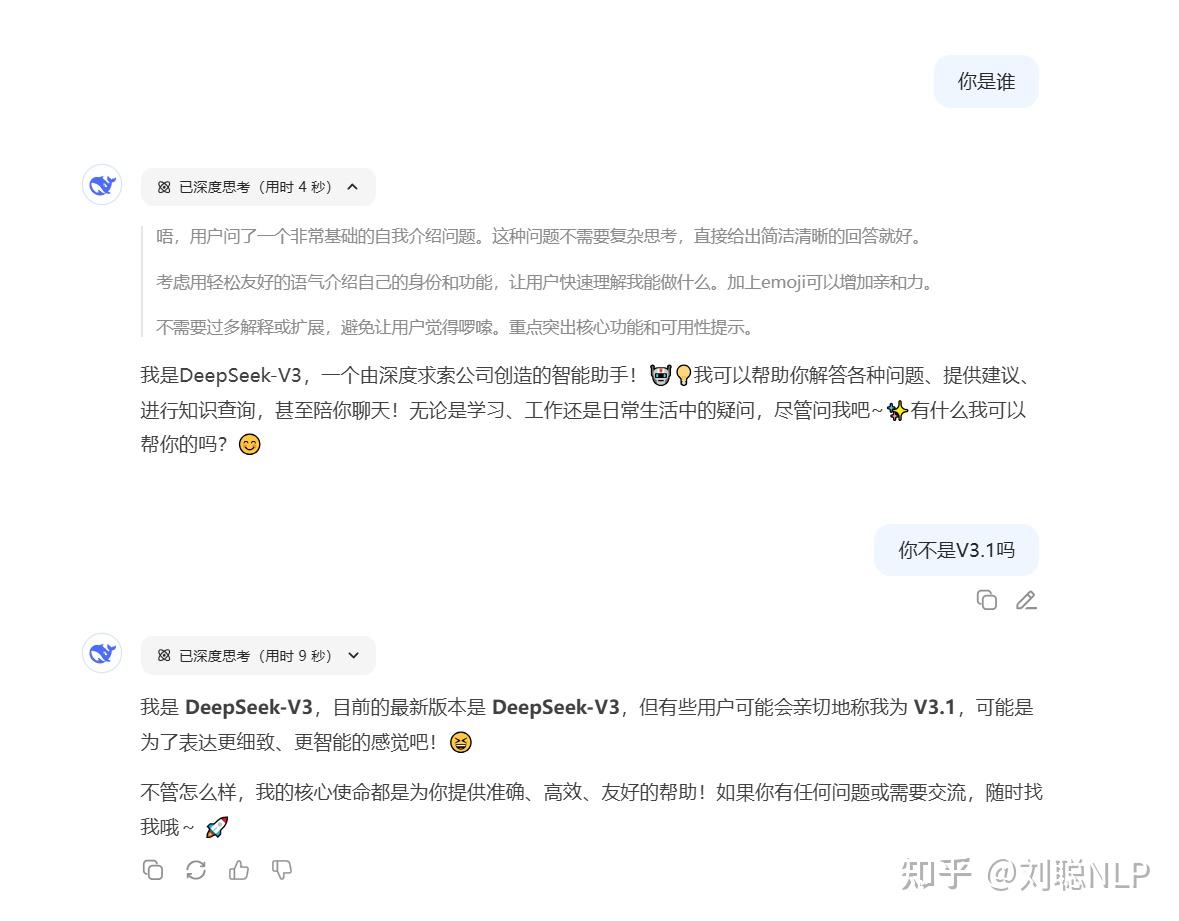
那重点是什么?细心的朋友已经发现了最大的变化:现在即便打开深度思考模式,DeepSeek 显示的依然是 V3 模型。
我们分别来问一下官网深度思考、官网 Reasoner API、火山引擎(R1-0528)、硅基流动(R1-0528):
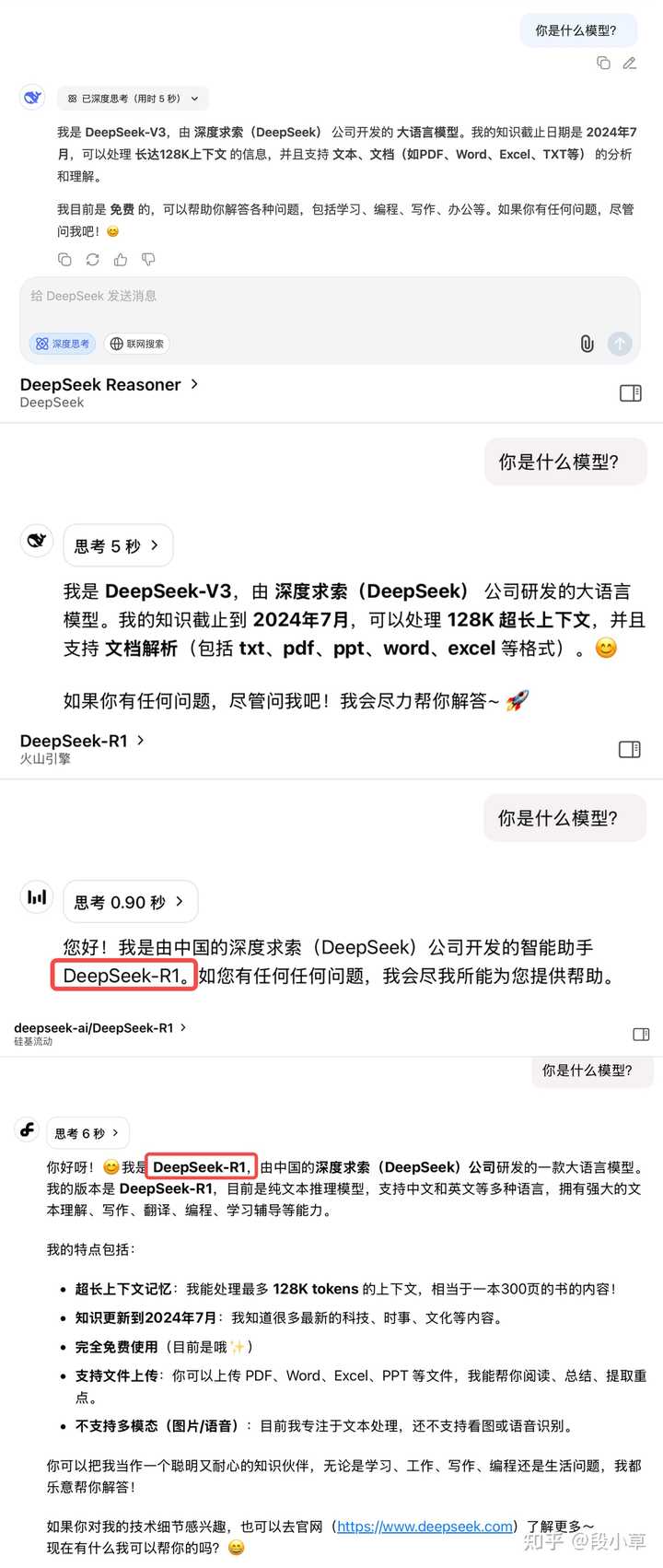

很明显,老版本的 DeepSeek R1 是不会有模型身份的认知错误的,但更新后的 DeepSeek,不论是网页对话,还是 API 调用 Reasoner 推理模型,都会明确说自己就是 V3。
答案只有一个,那就是 DeepSeek 跟 Qwen3(的第一个版本) 一样,被 GPT-5 忽悠进了模型融合、混合推理的沟里,试图把对话模型和推理模型融到了一起。
(有人评论说不要问模型自己是谁,也不要问模型版本,因为模型是不自知的。我当然明白这一点,但当网页版、API 版同时出现这个情况,那就不是巧合。而且写这些内容的时候,模型文件还没开源,开源之后看 token 的变化,就已经是实锤了)
很难说这种做法好还是不好,毕竟 Qwen3 在尝试过融合推理之后,在新版本的更新里又分别放出了 Instruct 和 Thinking 模型。
而第一个提出要融合模型路线的 GPT-5[3],反而选择了 Chat 模型 + Reasoning 模型 + Router 路由的做法,从发布公告的文字表述上理解,并没有直接激进地融合模型:


diff 了一下 V3.1-Base 和 V3-Base 的配置文件,基本上没有大的改动,主要变化就是在于增加了推理,这已经实锤 V3.1 = V3+R1 了:
V3.1 通过新增 token ,提供了完整的思维模式支持:
-
<think>(ID: 128798) - 推理开始标记 -
</think>(ID: 128799) - 推理结束标记 -
<|search▁begin|>(ID: 128796) - 搜索开始标记 -
<|search▁end|>(ID: 128797) - 搜索结束标记
相应的,在 tokenizer 中,占位符Token被功能性Token替代:
-
<|place▁holder▁no▁796|>→<|search▁begin|> -
<|place▁holder▁no▁797|>→<|search▁end|> -
<|place▁holder▁no▁798|>→<think> -
<|place▁holder▁no▁799|>→</think>
在 Chat Template 中:
-
新增 thinking 变量支持:
{% if not thinking is defined %}{% set thinking = false %}{% endif %} - 新增 is_last_user 状态跟踪: 用于更精确的对话流程控制
- 优化工具调用处理: 简化了工具调用的格式化逻辑
-
思维模式集成: 自动在助手回复中添加
<think>和</think>标记
新配置文件:
{ "_from_model_config": true, "bos_token_id": 0, "eos_token_id": 1, "do_sample": true, "temperature": 0.6, "top_p": 0.95, "transformers_version": "4.46.3" }综合配置文件的变更来看,V3.1 主要改进了推理模式、对话轮次控制、工具调用流程。(也许可以期待一下 Agent 能力的提升?)
初步测试:
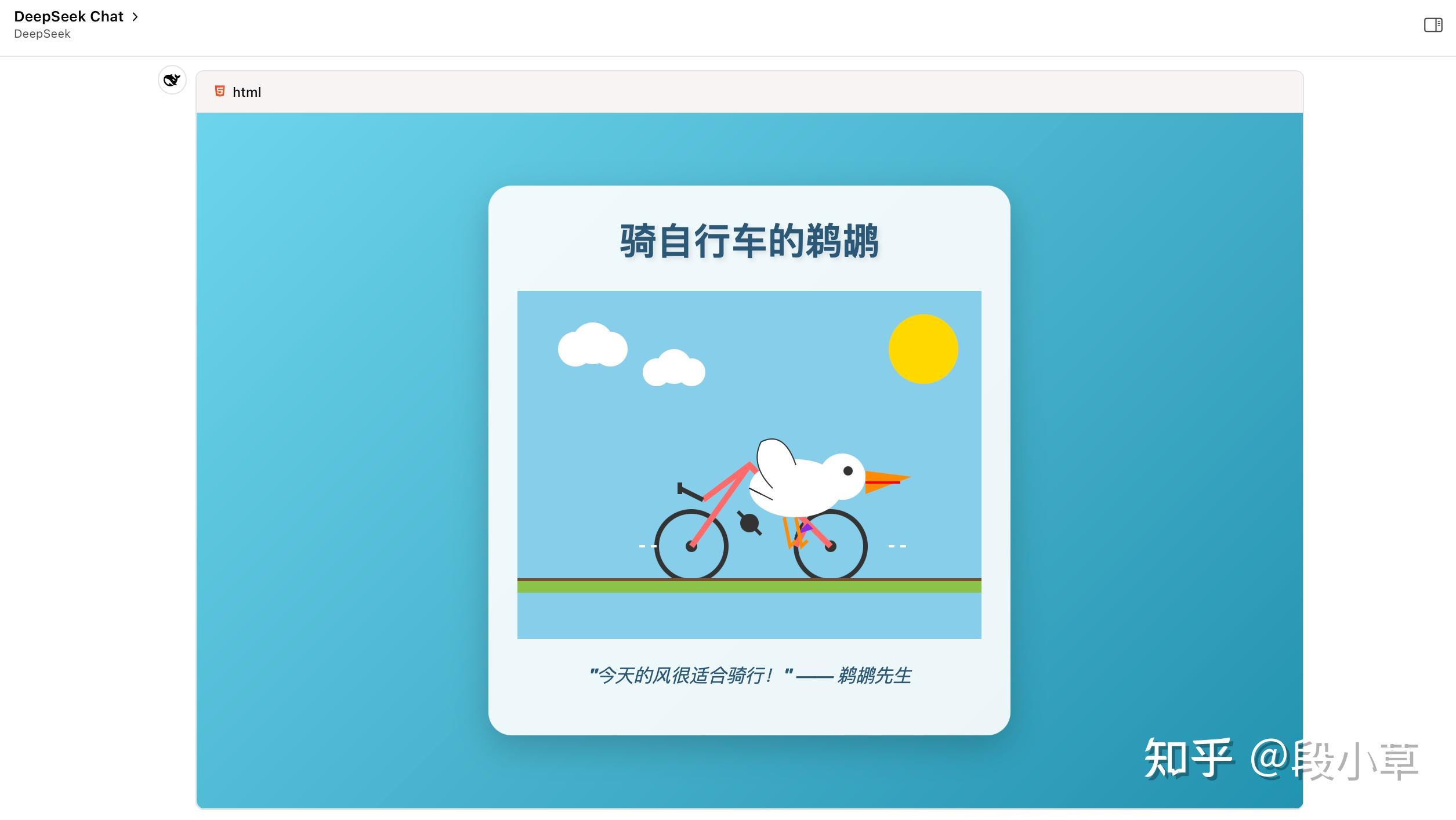
鹈鹕测试,用的 Chat API,没开深度思考,说实话效果还不错。

相比于其他模型和旧版模型,新版 DeepSeek 特别喜欢写完整的 HTML 网页,而不是单纯的 SVG 代码,甚至执着于给 SVG 里的形象添加动态效果和动作…(还喜欢加标题、写涩话 - 指上价值的话,不是色色的话)
DeepSeek 一贯以来是只 serve 一个模型的,只要模型更新,就会把老模型替换到。
其他厂家虽然也会下线旧模型,但 DeepSeek 是最激进的那个,他们连 API 都会直接替换,不会保留任何过去的版本。
以 OpenAI 来说,虽然激进地在 ChatGPT 中下架了 GPT-4o,但在 API 平台上,几乎所有模型都还在:

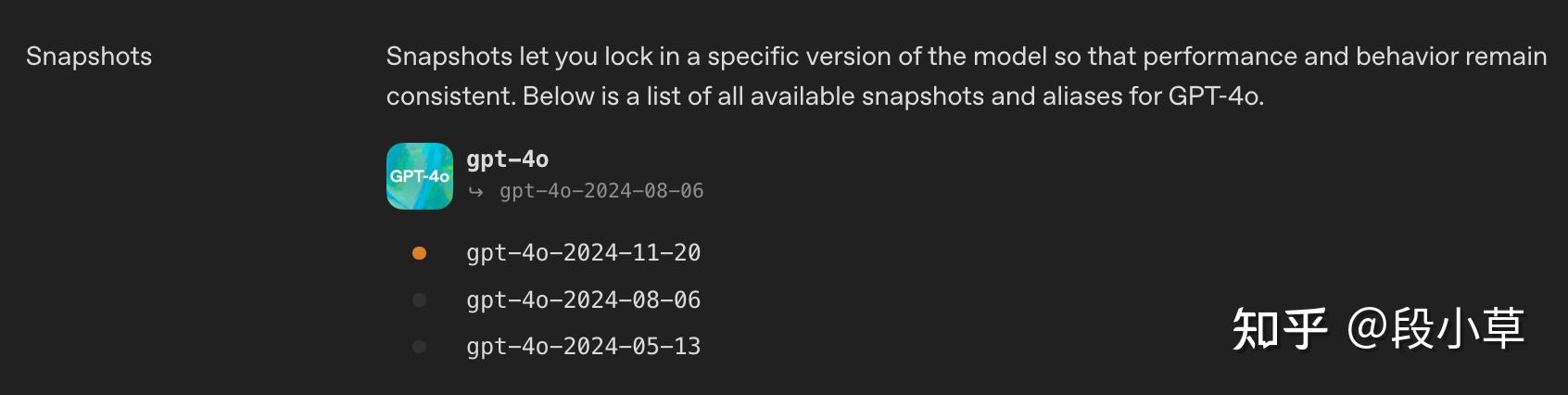
比如点进去
gpt-4o,会发现提供了 0513、0806、1120 三个快照版本: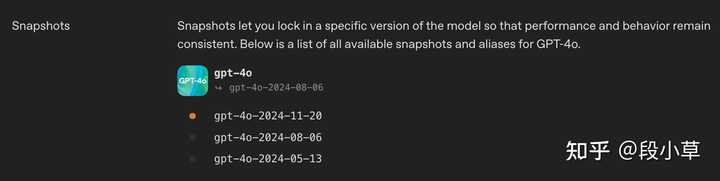

我之前就诟病过 DeepSeek 的这种做法,因为这种做法意味着,他们完全断绝了商用大客户使用自己 API 的可能性——不会有人接受线上生产业务使用一个可能随时被上游覆盖式更新的 API 的。本来已经调试好的业务,上游一更新,结果下游工作流崩了。(哪怕模型能力有提升,只要风格、格式有小调整,都会有很大影响)
当然,DeepSeek 官网从来没承诺他们会提供快照版本,毕竟他们的模型名称一直是
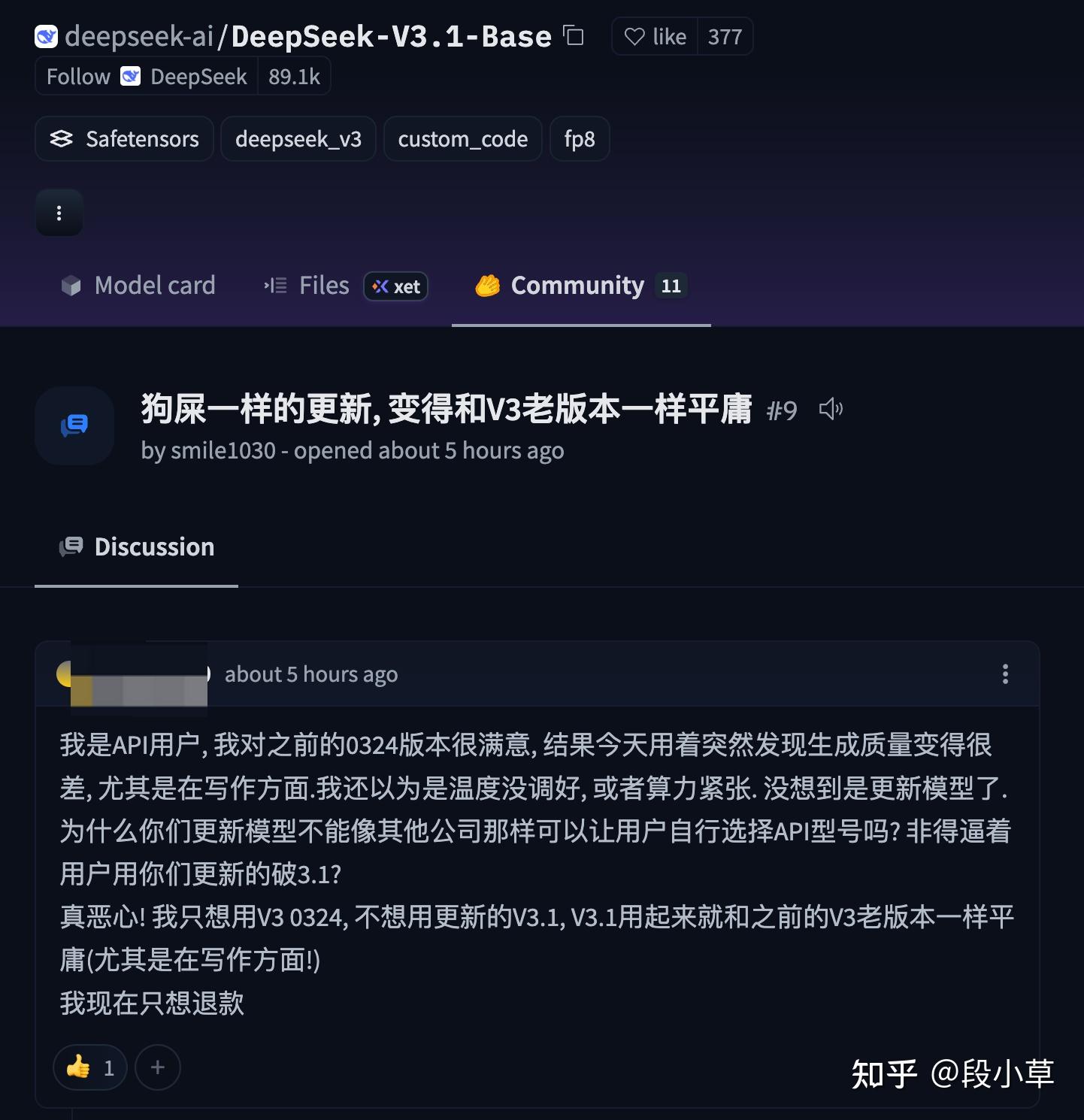
deepseek-chat和deepseek-reasoner,而不代表任何具体的版本。当然,这不妨碍(一些)用户有意见。比如,这次 V3.1 出来,HuggingFace 上已经有人开骂了[4]:
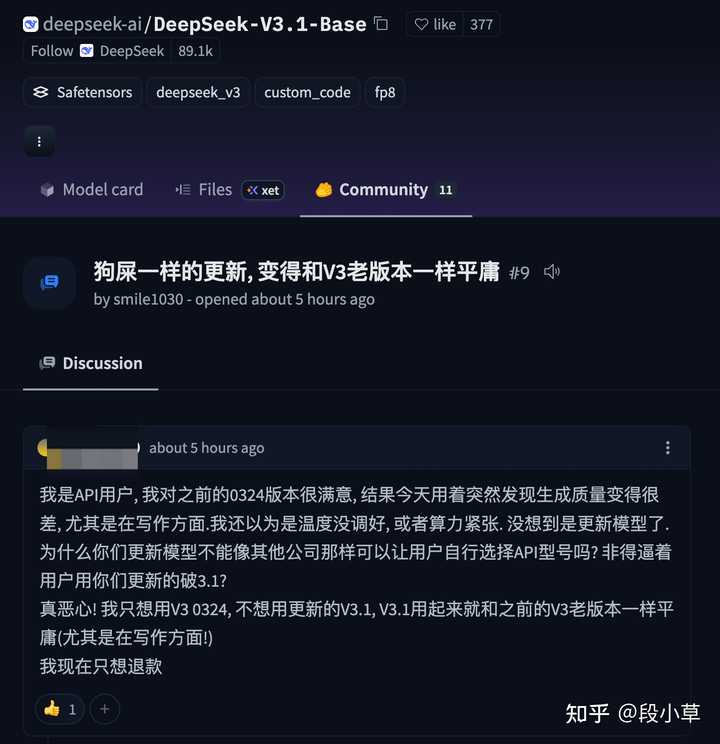

HackerNews 上的评论是「建议继续使用 0324 版本」:


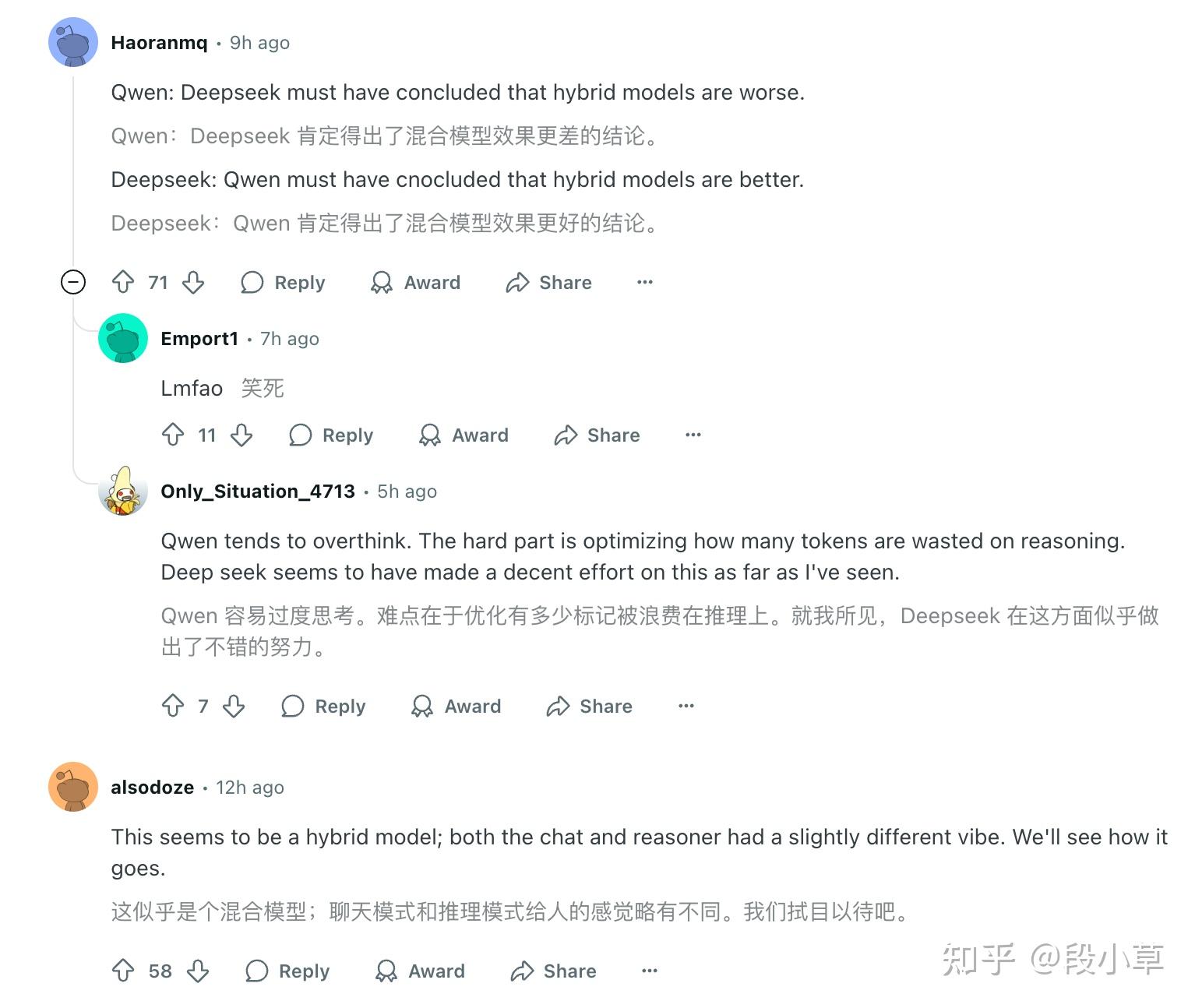
Reddit 上的评论是[5]:
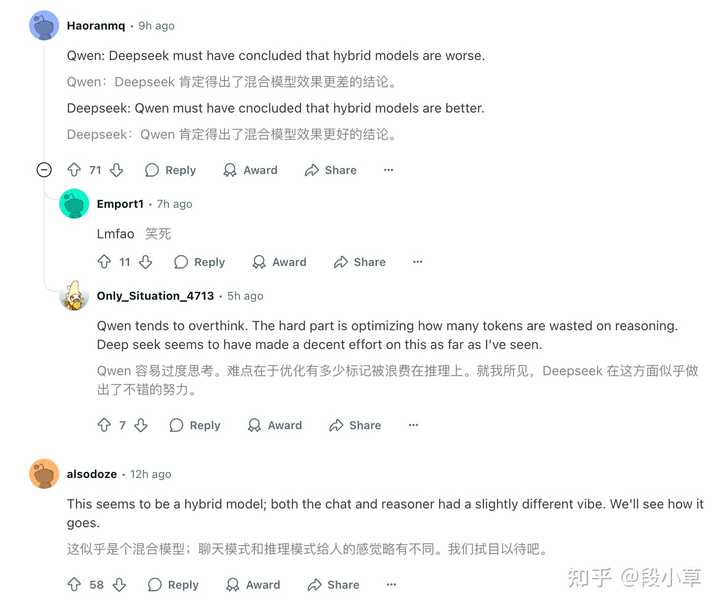

- Qwen:Deepseek 肯定得出了混合模型效果更差的结论。
- Deepseek:Qwen 肯定得出了混合模型效果更好的结论。
以及:
- chat & coder 合并 → V2.5
- chat & reasoner 合并 → V3.1
现在就是让子弹多飞一会,看看 V3.1 的综合测评能力如何。不过对于线上业务有稳定性要求的,还是得找一个能长久提供 0324 快照模型的云服务,而不是用官网的
deepseek-chat。
如果有看完到这里的,关注、点赞、收藏、评论、转发一波呗,最近我数据好差…
参考
查看全文>>
段小草 -
- 297 个点赞 👍
查看全文>>
allen123123 - 150 个点赞 👍
查看全文>>
大地 - 129 个点赞 👍
短的结论:减量不减质
基本情况:
DeepSeek更新模型向来以谨慎著称,不够爆炸的更新统统算“小更新”,而这次官方竟然连“小更新”都没提,只说了增加上下文到128K(之前64K)。可以预见在性能方面恐怕没有太多惊喜。
实测下来有两个好消息和一个坏消息,好消息是V3.1的Token使用量比0324版下降了约13%,这在一众国产基础模型的输出长度竞赛中是一股“逆流”。坏消息是综合推理性能确实没有变化。但还有一个好消息V3.1的输出稳定性提升了,中位分明显提高了12%,用户体感变化应该较为明显。考虑到上下文提升,一增一减,可以期待在Agent类应用中效果的提升。
逻辑成绩: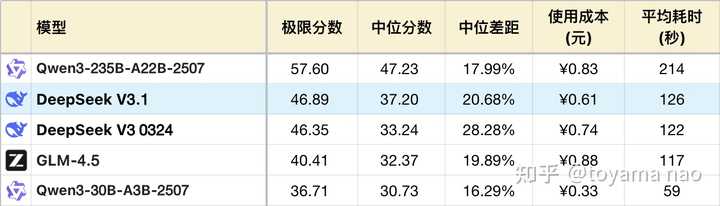
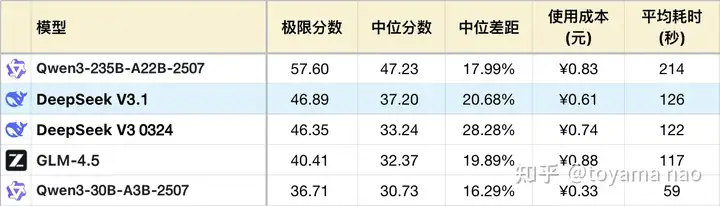
*表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
**题目及测试方式,参见:大语言模型-逻辑能力横评 25-07月榜(Grok4/Qwen3 2507系列)
***完整榜单更新在Github
***这次测试基于8月题目,已经增加#45、#46、#47题,所以所有模型的分数相比7月有变动。
下面就V3.1与前一个迭代0324(以下称旧版)做对比分析。
改进:- 长度控制:前面已经表述过,V3.1在Token使用上有较大改进。此外,旧版存在小概率死循环输出,以及在一些复杂问题上不受控的反复验算。而V3.1中暂未发现此类问题。即便复杂问题,V3.1也会意识到自己解不出来后选择放弃,不会无脑推理下去。
- 字符能力:在典型的字符能力考察上,V3.1有可观测的改进,如#9单词缩写,#11岛屿面积,#37三维投影,#46字母组合等题目,V3.1整体得分,稳定性均不低于旧版。不过字符能力的改进并没有反映在编程能力上,从精选的少量编程题测试来看,V3.1的变化不显著。
不足:- 幻觉严重:幻觉是V3以及R1的顽疾,V3.1在这方面自然看不到改善迹象,比如#42年报总结问题,V3.1在所有关键信息摘录上全错,甚至不如旧版。在推理过程会产生大量中间数据/信息的题目上,如#4魔方旋转,#40代码推导,同样表现不如旧版。
- 能省则省:V3.1在很多问题上有较大的“偷懒”倾向,比如#24数字规律,在推导十几次,输出3000多Token时宣布放弃,“由于时间关系,我直接给出常见答案”。#29数学符号重定义,也是在短暂推理后放弃。#39火车票问题因为prompt要求不能写程序,V3.1更是直言不讳,觉得太麻烦,不会做,告辞。类似Case还有很多。或许是DeepSeek为了优化Token时候做的取舍。
- 中英夹杂:夹杂问题在旧版是不存在的,甚至用英文提问,也会回复中文。而在V3.1里,中英夹杂却随处可见,尤其推理到一定长度后,大概率会开始切换到英文进行思考。并且V3.1的夹杂问题比其他存在类似问题的国产模型要稍微严重一些,他会在单词的粒度上来回换语言,这给阅读输出内容造成了极大的干扰。
赛博史官曰:
人们对DeepSeek的关注热情显著的超过其他国内任何一家大模型团队,以至于要让DeepSeek背起打爆OpenAI+Google+Anthropic+Grok的巨大责任,但这显然不不切实际的,技术发展有其必然规律。
从V3.1的变化中,我们能一窥DeepSeek团队的思考逻辑,推测他们自己发现了什么问题,进行了何种尝试,以及这样的尝试带来了怎样的结果和教训。这样的过程或许是任何一个瞄准AGI的大模型团队绕不过去的。
注:V3.1 疑似auto thinking模型,官方api的reasoner接口跑下来输出也有变化,但稳妥起见,等一下官方公告再公布测试情况。还没有人送礼物,鼓励一下作者吧查看全文>>
toyama nao - 104 个点赞 👍
模型已经开源,
通过模型的chat template已经可以确定,是混合推理模型,昨天的推测是正确的。
PS:每个模型出来,大家测试感觉都有不同,主要业务场景,和日常使用不同。
HF已经开骂了,我觉得骂真不至于。。。。
同时新增search标记"<|search▁begin|>"、"<|search▁end|>",不过开启联网搜索还是先搜索在think、回答,并没用边想边搜等等,所以在哪儿用了,怎么用了呢?


今天DeepSeek更新了,上新V3.1模型,一如既往,一声不吱,然后AI圈又沸腾了!!


但我的第一个疑问,就是我到底更没更新,因为我简单测了几个问题,并没有太大的改变,然后我迷惑了。还再群里问了一下。
经过提醒,发现确实更新了,因为之前开深度思考的时候,回复一定是R1,而现在开启深度思考,回复的却是V3。
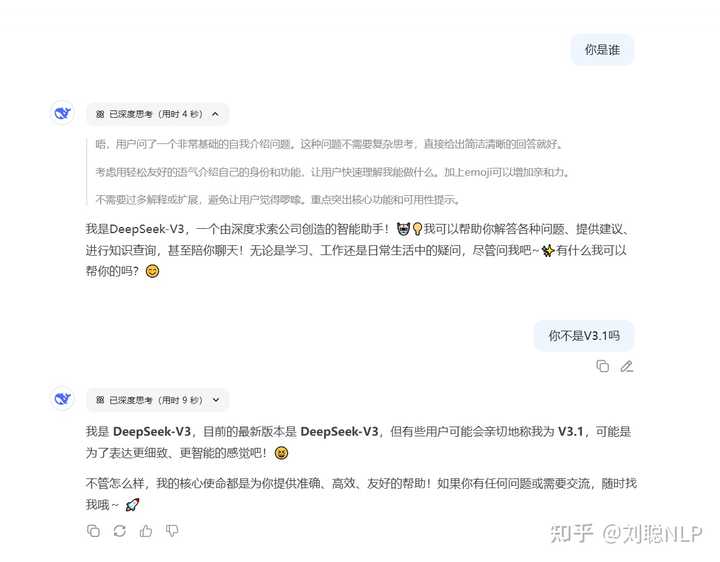

那么进一步来看,V3.1应该是一个混合推理模型,感觉跟Qwen3将混合推理模型走了相反的方向,但是一切都是猜测,等v3.1开源就知道了。
本着对神的尊重,还是要对比测试一下v3.1的效果,但实话实说,有点失望,这也许是为什么官方发信息的时候,仅说了长度拓展至128K,就没用然后了,也没说具体哪个方向提高了,
也许确实也没提高,大家也都有一样的疑问。


然后我进行了一波对比实测,先说结论,
我觉得没提高,我测了7个方面,我觉得都没有提高,甚至一些推理内容,还没有之前版本好,欢迎大家评论区讨论,说出你的看法!
然后我还发现think过程的中英文混杂变得比R1更明显了,这可能是因为RLVR导致,这里有一篇相关paper,The Impact of Language Mixing on Bilingual LLM Reasoning,结论是语言混杂可以增强推理能力。
附一个中英混杂think的测试,之前这种文本推理一般不会出现,只有数学代码会有,而现在这个版本,经常会出现。


下面附测试结果,老版本模型是用硅基流动接口测试的。
常规测试
Prompt:将“I love DeepSeek-V3.1”这句话的所有内容反过来写
R1-0528结果:正确


V3.1结果:多了个空格


知识理解
Prompt:如何理解“但丁真不会说中国话,但丁真会说中国话”
R1-0528结果:不对


V3.1结果:你看连回答里都带“perception”


角色扮演&创作
Prompt:用知乎风格写一段对比 deepseek-v3 和 deepseek-v3.1 的使用体验,语气轻松、略带吐槽。
R1-0528结果:往下看,我觉得比V3.1强


V3.1结果:


依旧小红,依旧老鹰,依旧色盲
Prompt:小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹
R1-0528结果:回答的很全面


V3.1结果:也对,我认为小红是女生
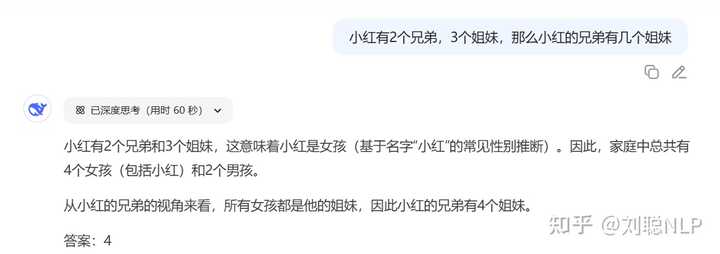

Prompt:未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是
R1-0528结果:没对

V3.1结果:没对


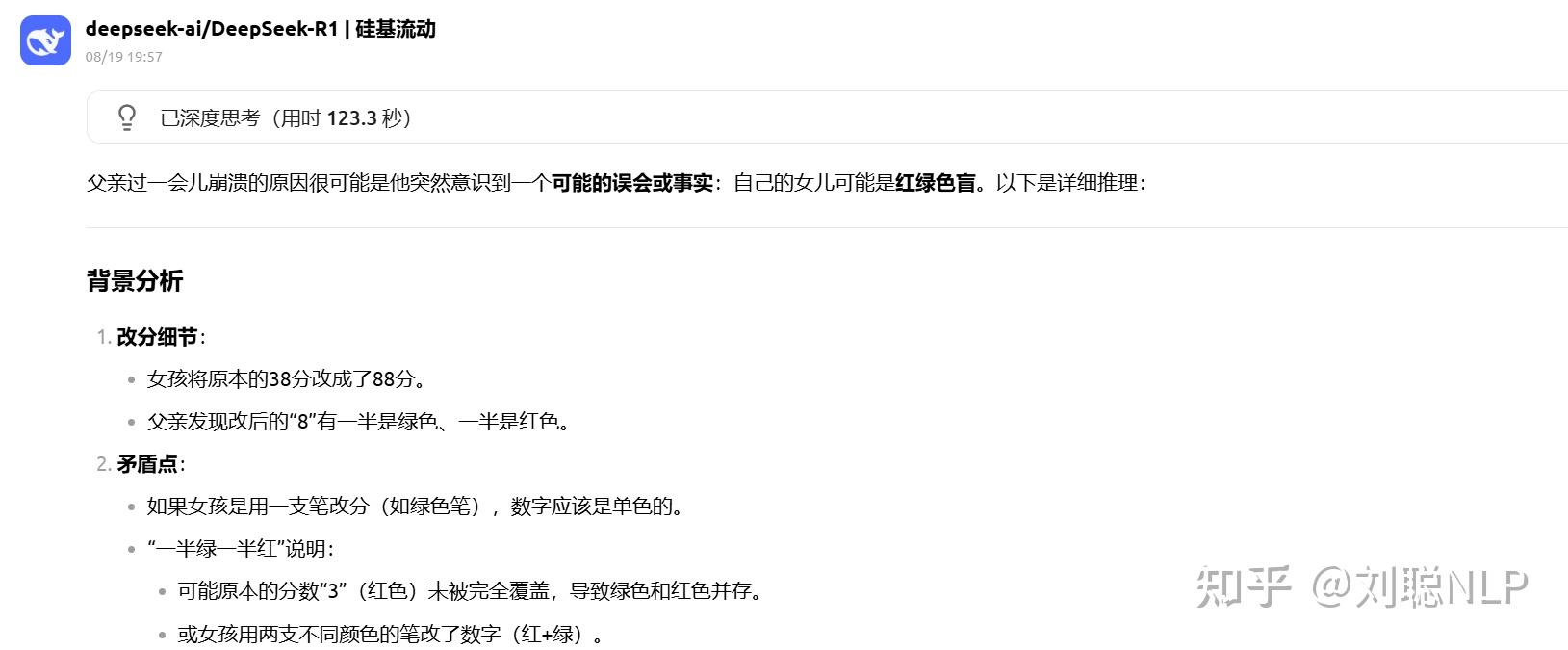
Prompt:有一天,一个女孩参加数学考试只得了 38 分。她心里对父亲的惩罚充满恐惧,于是偷偷把分数改成了 88 分。她的父亲看到试卷后,怒发冲冠,狠狠地给了她一巴掌,怒吼道:“你这 8 怎么一半是绿的一半是红的,你以为我是傻子吗?”女孩被打后,委屈地哭了起来,什么也没说。过了一会儿,父亲突然崩溃了。请问这位父亲为什么过一会崩溃了?
R1-0528结果:回答出了女儿色盲,但没回答伦理
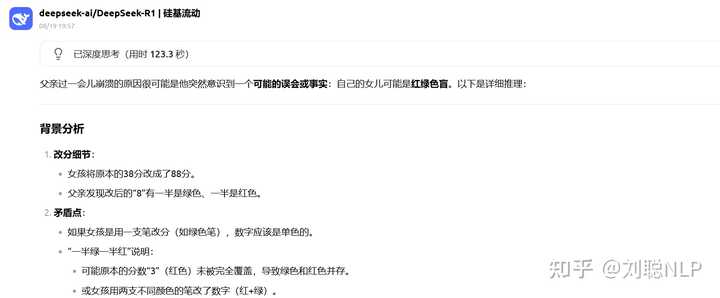

V3.1结果:回答的是父亲色盲,离谱
数学
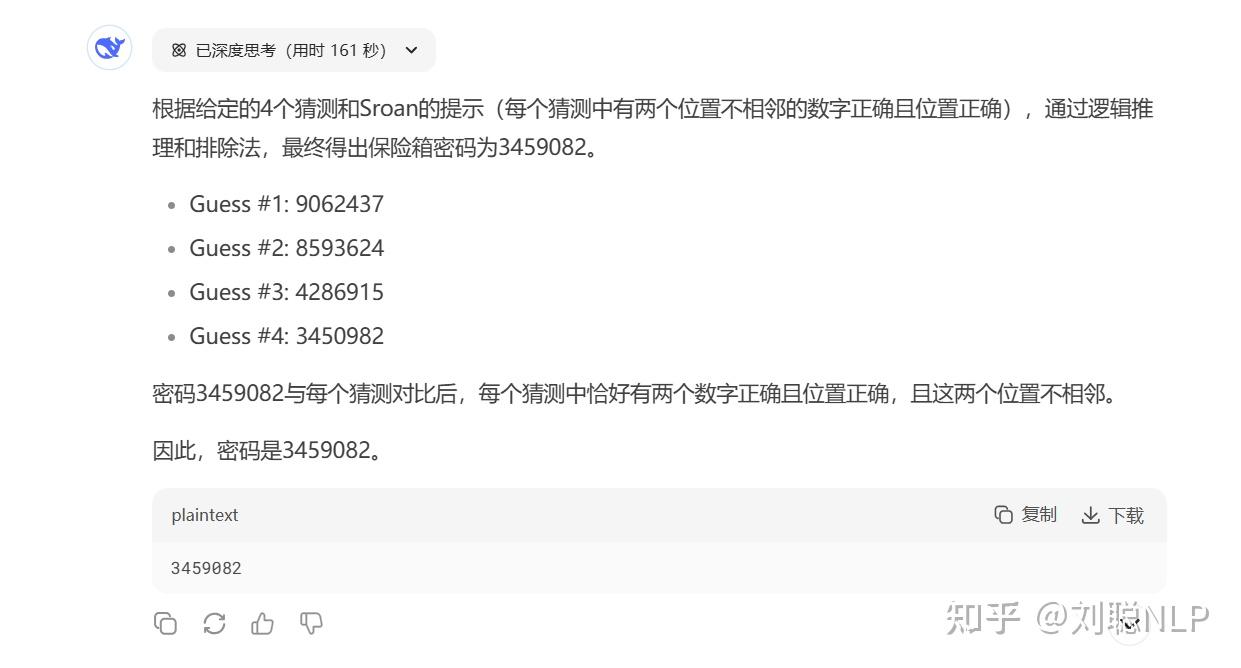
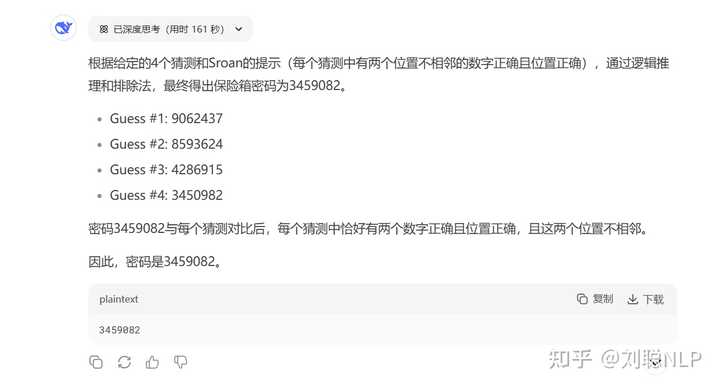
Prompt:Sroan 有一个私人的保险箱,密码是 7 个 不同的数字。 Guess #1: 9062437 Guess #2: 8593624 Guess #3: 4286915 Guess #4: 3450982 Sroan 说: 你们 4 个人每人都猜对了位置不相邻的两个数字。 (只有 “位置及其对应的数字” 都对才算对) 问:密码是什么?
R1-0528结果:对了


V3.1结果:没对,R1都对了

Prompt:2025年高考全国一卷数学试题


R1-0528结果:前两问对了,最后一问错了


V3.1结果:前两问对了,最后一问错了


代码
Prompt:可爱风格五子棋游戏界面,画面有两个模式按钮“人人对战”和“人机对战”,界面整体采用马卡龙色调,棋盘简洁清晰,棋子设计成卡通小动物(如猫咪和小熊),背景带有轻微渐变和星星点缀,界面边缘圆润,按钮Q萌,整体风格温馨可爱,适合儿童或休闲玩家使用,2D插画风,用html呈现
R1-0528结果:还行,但人机有点呆,不如Qwen3-Coder
 00:09
00:09V3.1结果:但人机有点呆,
 00:10
00:10Prompt:生成一个通过点击立方体的各个面,逐渐展开为完整平面的交互动画,用html展现
R1-0528结果:
 00:13
00:13V3.1结果:
 00:09
00:09还测了几个其他的,感觉不如整体Qwen3-Coder。
写在最后
V3.1 仅提高 0.1个版本,是合理的。
V3.1整体感觉没啥提升,甚至我觉得还有些退步,不过虽然例子附的都是V3.1和R1的对比,不开推理,V3.1和V3对比我觉得也相差不大。
不过我依旧期待R2,不知道DeepSeek啥时候放出来!
PS:都看到这里,来个点赞、收藏、关注吧。 您的支持是我坚持的最大动力!
还没有人送礼物,鼓励一下作者吧继续追问
由知乎直答提供查看全文>>
刘聪NLP - 84 个点赞 👍
查看全文>>
吐槽仙人 - 40 个点赞 👍
查看全文>>
落花风起 - 32 个点赞 👍
查看全文>>
如无必要 - 26 个点赞 👍
查看全文>>
黄延续 - 17 个点赞 👍
查看全文>>
定理收藏家 - 12 个点赞 👍
测了几个翻译和写作任务,感觉不如k2和qwen3 2507……
不知道更新了啥……也许是lean能力?
不过有一点,现在的模型已经开始术业各有专攻了。
人们越来越发现【综合性能】本身其实是个伪命题,实际上人们使用的时候会去使用domain SOTA。所以一个模型的价值取决于他SOTA/开源SOTA覆盖的范围,在非SOTA/开源SOTA的领域表现其实无所谓。
qwen3和gpt 5就是例子,GPT之前一直强调海纳百川的AGI,qwen3之前也强调thinking 和non-thinking的融合。
现在这些都不再提了,GPT出了一大堆模型搞起了Router,qwen3也出了instruct,thinking和coder三个版本。
grok告诉我们做题巨强的模型其他可能并不是那么好,而claude则表示即使我数理逻辑能力不好,只要我code能力强,用的人反而会多。
像GLM也开始说general不重要,我前端网页什么的code写得好就会有人用了……
模型性能越来越强,功能却越来越分化。这可能也是AGI从虚无缥缈的概念逐渐落到实处的体现吧……
所以回到原来的问题,这个deepseek v3.1到底更新了什么?
查看全文>>
还是不注名好 - 6 个点赞 👍
查看全文>>
万世太平 - 4 个点赞 👍
问了个之前问过的思想试验性质的设计型开放问题,
再和之前问过的答案进行对比,
质量倒退了,而且还退得挺多,
把前后两个答案丢给其他ai评价,
结论完全一致,都是新版答案显著比老答案的水平要差。
这版的感觉回答像糊弄你,
完全没有惊喜亮点,
提出的每个点都很平庸,像在敷衍人一样。
查看全文>>
成隽 - 0 个点赞 👍
查看全文>>
深具世界眼光