
省流:悲!也许没有 R2 了!V3.1 把 R1 给融了!
重点 1:别被官方微信公告带沟里,128K 不是重点!模型融合推理才是重点!
重点 2:DeepSeek V3-0324 和 DeepSeek V3 用的同一个 base model,但这次的 V3.1 放出了新的 base model,大概率是重新训的新模型。
DeepSeek 的逻辑可能是,只要 base model 没换,就用日期做版本;重新训了 base model,就改版本号。
先在前面更新一下我的主观感受:
DeepSeek V3.1 有进步,但不多。反而以前的老毛病回来不少:幻觉、中英文混杂。
如果只是一次实验性的关于 Chat、Reasoning 模型融合的测试,那 V3.1 是一次合格的增量更新。往好处想,如果 V3.1 成了,那将来不用单独部署两套模型,节约了很多部署运维的精力,提高了算力利用效率。
但如果这是未来一段时间 DeepSeek 的主力模型,而 V4 依旧遥远、R2 再也不见的话,那大家的很多期待也许就落空了。
当然,GPT-5 的社区口碑也是先崩了一波然后回暖的,让子弹再飞一会,听听社区对 V3.1 的真实反馈(欢迎评论区交流分享各种体感和实测 case)。
目前只见到了微信群里的消息,所以还在蹲官方的模型开源以及文档更新,按照惯例会放出新的 Benchmark 成绩和能力说明。
Update 一下,DeepSeek V3.1 Base 的模型地址已经放出来了[1](但还没有 model card):
按照微信群里的说明,这次更新的「重点」是上下文支持到了 128K:

但是,128K 绝对不是这次更新的重点。因为 DeepSeek V3/R1 的 Context Length 其实一直都是 128K,只不过 DeepSeek 官方的 API 之前只支持到 64K。
官方在 V3-0324 的说明里写的很明白了:
模型参数约 660B,开源版本上下文长度为 128K(网页端、App 和 API 提供 64K 上下文)
再比如,DeepSeek V3 HuggingFace 模型页[2]
SiliconFlow 上的 DeepSeek V3-0324 模型 API 上下文是 128K
火山引擎上的 DeepSeek 模型 API 上下文均是 128K

虽然上下文长度很重要,但这次最多只能说官方愿意消耗更多算力提供更长的上下文,除非有什么新的扩展上下文同时节约算力的黑科技,否则这并不是重点。
那重点是什么?细心的朋友已经发现了最大的变化:现在即便打开深度思考模式,DeepSeek 显示的依然是 V3 模型。
我们分别来问一下官网深度思考、官网 Reasoner API、火山引擎(R1-0528)、硅基流动(R1-0528):
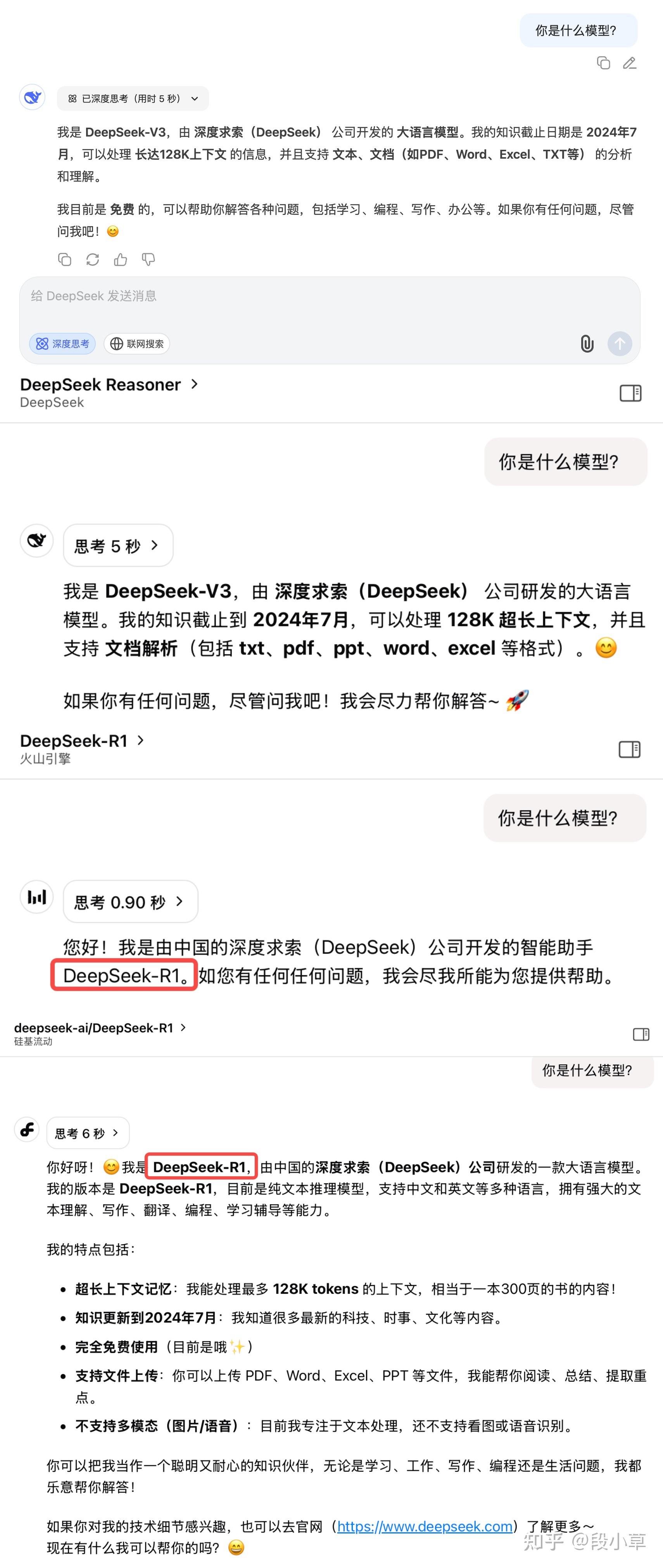
很明显,老版本的 DeepSeek R1 是不会有模型身份的认知错误的,但更新后的 DeepSeek,不论是网页对话,还是 API 调用 Reasoner 推理模型,都会明确说自己就是 V3。
答案只有一个,那就是 DeepSeek 跟 Qwen3(的第一个版本) 一样,被 GPT-5 忽悠进了模型融合、混合推理的沟里,试图把对话模型和推理模型融到了一起。
(有人评论说不要问模型自己是谁,也不要问模型版本,因为模型是不自知的。我当然明白这一点,但当网页版、API 版同时出现这个情况,那就不是巧合。而且写这些内容的时候,模型文件还没开源,开源之后看 token 的变化,就已经是实锤了)
很难说这种做法好还是不好,毕竟 Qwen3 在尝试过融合推理之后,在新版本的更新里又分别放出了 Instruct 和 Thinking 模型。
而第一个提出要融合模型路线的 GPT-5[3],反而选择了 Chat 模型 + Reasoning 模型 + Router 路由的做法,从发布公告的文字表述上理解,并没有直接激进地融合模型:

diff 了一下 V3.1-Base 和 V3-Base 的配置文件,基本上没有大的改动,主要变化就是在于增加了推理,这已经实锤 V3.1 = V3+R1 了:
V3.1 通过新增 token ,提供了完整的思维模式支持:
-
<think>(ID: 128798) - 推理开始标记 -
</think>(ID: 128799) - 推理结束标记 -
<|search▁begin|>(ID: 128796) - 搜索开始标记 -
<|search▁end|>(ID: 128797) - 搜索结束标记
相应的,在 tokenizer 中,占位符Token被功能性Token替代:
-
<|place▁holder▁no▁796|>→<|search▁begin|> -
<|place▁holder▁no▁797|>→<|search▁end|> -
<|place▁holder▁no▁798|>→<think> -
<|place▁holder▁no▁799|>→</think>
在 Chat Template 中:
-
新增 thinking 变量支持:
{% if not thinking is defined %}{% set thinking = false %}{% endif %} - 新增 is_last_user 状态跟踪: 用于更精确的对话流程控制
- 优化工具调用处理: 简化了工具调用的格式化逻辑
-
思维模式集成: 自动在助手回复中添加
<think>和</think>标记
新配置文件:
{
"_from_model_config": true,
"bos_token_id": 0,
"eos_token_id": 1,
"do_sample": true,
"temperature": 0.6,
"top_p": 0.95,
"transformers_version": "4.46.3"
} 综合配置文件的变更来看,V3.1 主要改进了推理模式、对话轮次控制、工具调用流程。(也许可以期待一下 Agent 能力的提升?)
初步测试:
鹈鹕测试,用的 Chat API,没开深度思考,说实话效果还不错。
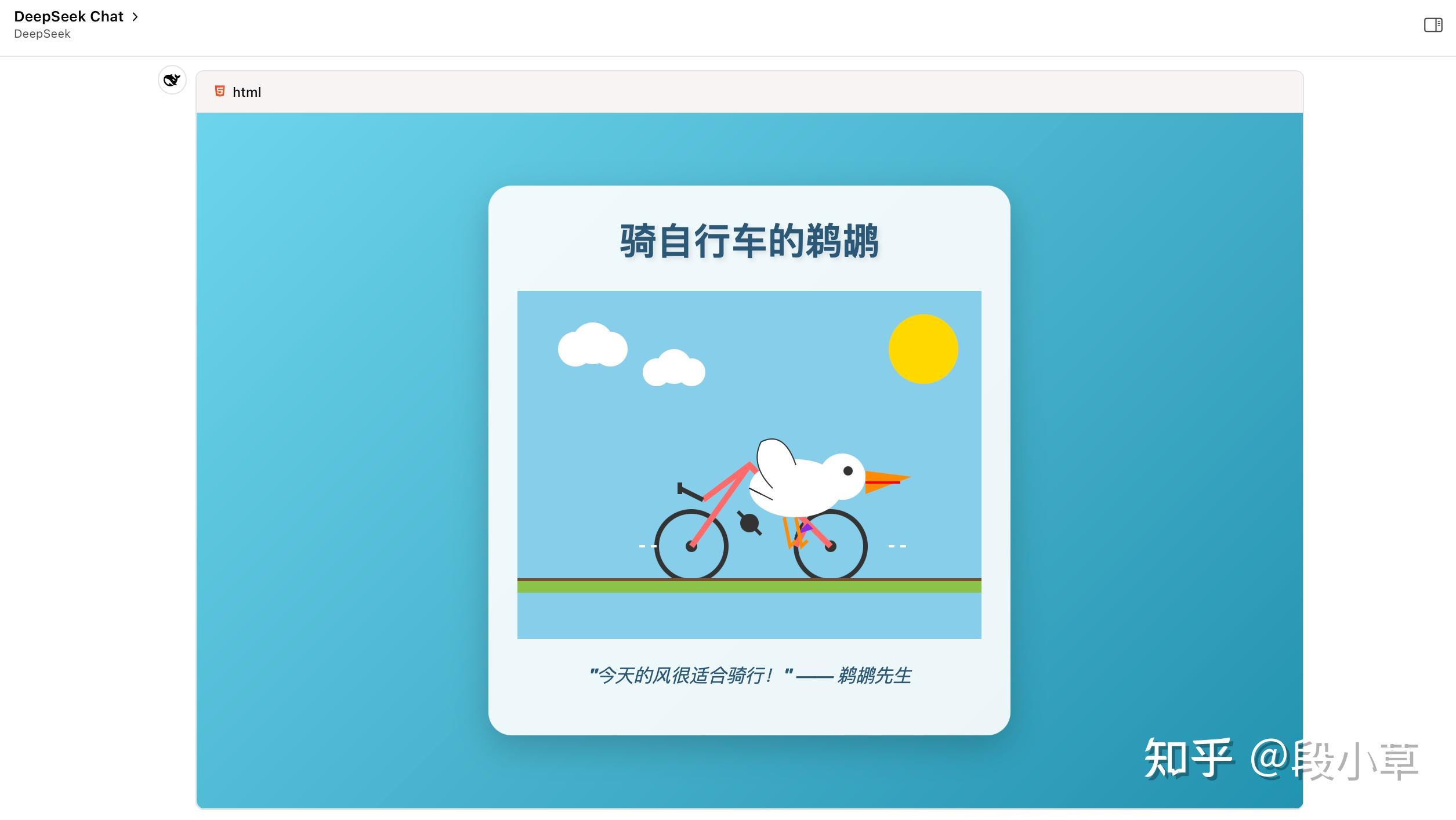
相比于其他模型和旧版模型,新版 DeepSeek 特别喜欢写完整的 HTML 网页,而不是单纯的 SVG 代码,甚至执着于给 SVG 里的形象添加动态效果和动作…(还喜欢加标题、写涩话 - 指上价值的话,不是色色的话)
DeepSeek 一贯以来是只 serve 一个模型的,只要模型更新,就会把老模型替换到。
其他厂家虽然也会下线旧模型,但 DeepSeek 是最激进的那个,他们连 API 都会直接替换,不会保留任何过去的版本。
以 OpenAI 来说,虽然激进地在 ChatGPT 中下架了 GPT-4o,但在 API 平台上,几乎所有模型都还在:
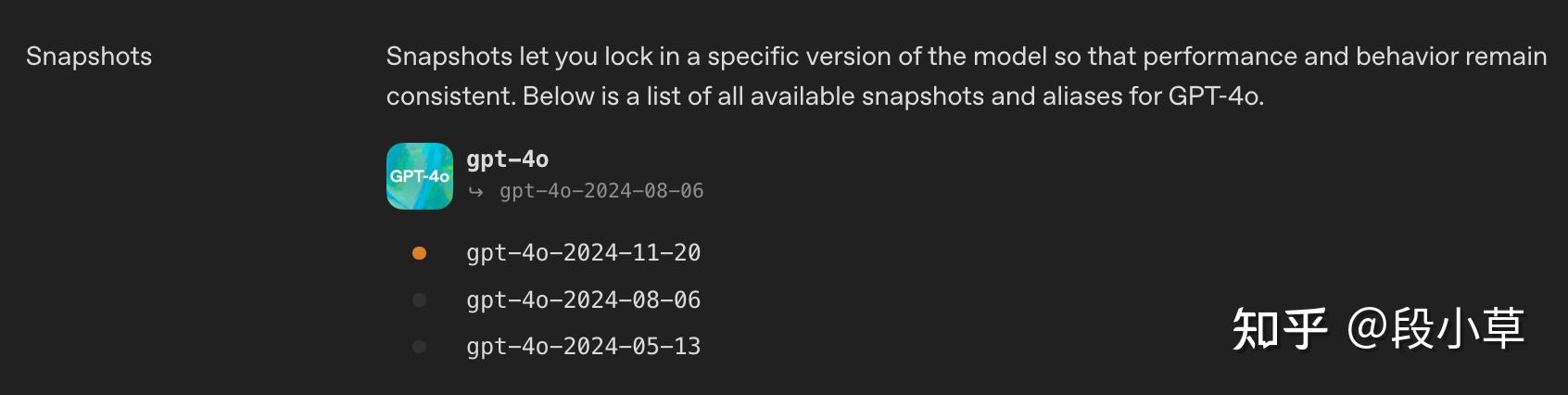
比如点进去 gpt-4o,会发现提供了 0513、0806、1120 三个快照版本:
我之前就诟病过 DeepSeek 的这种做法,因为这种做法意味着,他们完全断绝了商用大客户使用自己 API 的可能性——不会有人接受线上生产业务使用一个可能随时被上游覆盖式更新的 API 的。本来已经调试好的业务,上游一更新,结果下游工作流崩了。(哪怕模型能力有提升,只要风格、格式有小调整,都会有很大影响)
当然,DeepSeek 官网从来没承诺他们会提供快照版本,毕竟他们的模型名称一直是deepseek-chat 和 deepseek-reasoner,而不代表任何具体的版本。
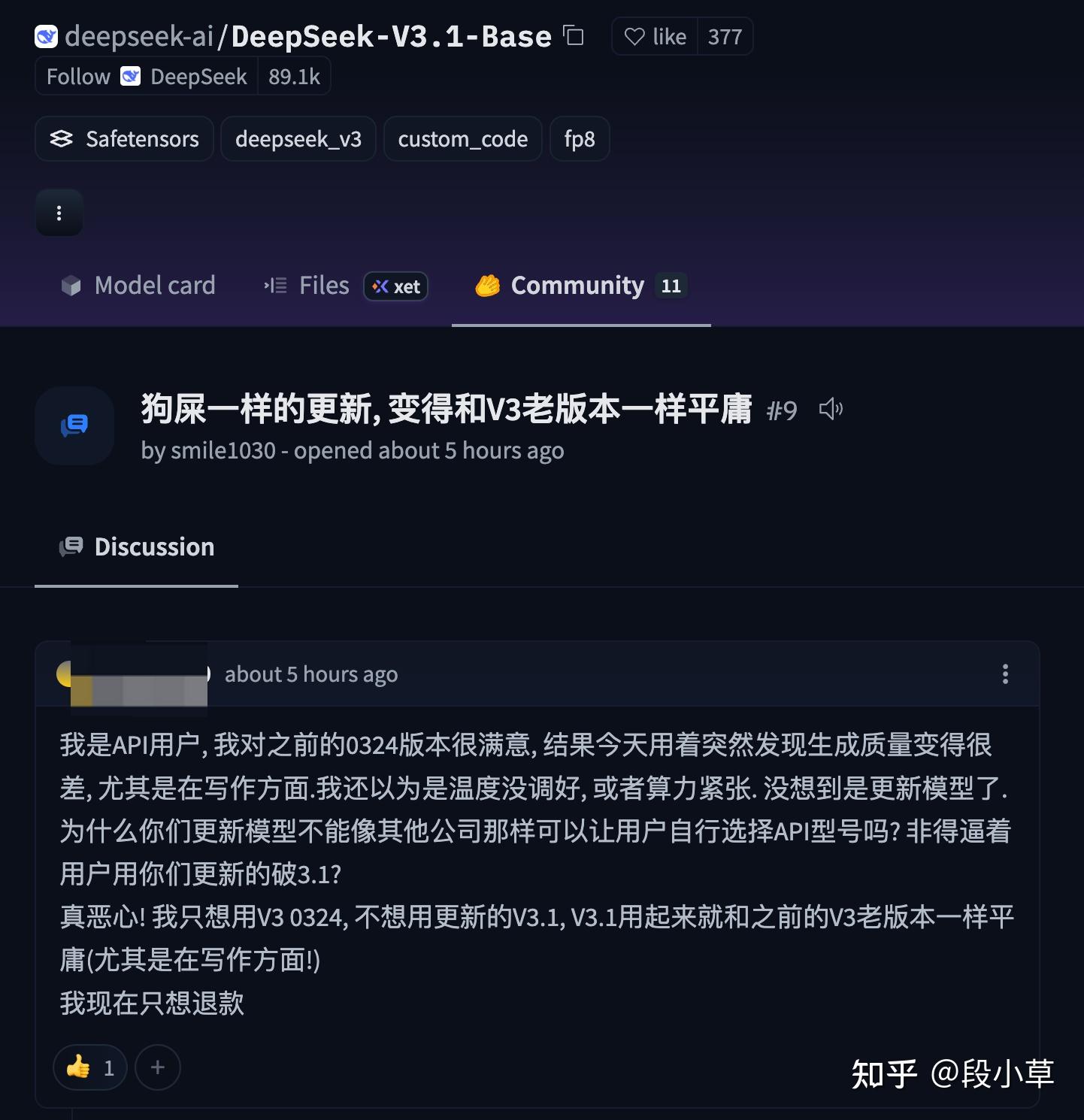
当然,这不妨碍(一些)用户有意见。比如,这次 V3.1 出来,HuggingFace 上已经有人开骂了[4]:
HackerNews 上的评论是「建议继续使用 0324 版本」:

Reddit 上的评论是[5]:
- Qwen:Deepseek 肯定得出了混合模型效果更差的结论。
- Deepseek:Qwen 肯定得出了混合模型效果更好的结论。
以及:
- chat & coder 合并 → V2.5
- chat & reasoner 合并 → V3.1
现在就是让子弹多飞一会,看看 V3.1 的综合测评能力如何。不过对于线上业务有稳定性要求的,还是得找一个能长久提供 0324 快照模型的云服务,而不是用官网的 deepseek-chat。
如果有看完到这里的,关注、点赞、收藏、评论、转发一波呗,最近我数据好差…


