
短的结论:减量不减质
基本情况:
DeepSeek更新模型向来以谨慎著称,不够爆炸的更新统统算“小更新”,而这次官方竟然连“小更新”都没提,只说了增加上下文到128K(之前64K)。可以预见在性能方面恐怕没有太多惊喜。
实测下来有两个好消息和一个坏消息,好消息是V3.1的Token使用量比0324版下降了约13%,这在一众国产基础模型的输出长度竞赛中是一股“逆流”。坏消息是综合推理性能确实没有变化。但还有一个好消息V3.1的输出稳定性提升了,中位分明显提高了12%,用户体感变化应该较为明显。考虑到上下文提升,一增一减,可以期待在Agent类应用中效果的提升。
逻辑成绩:
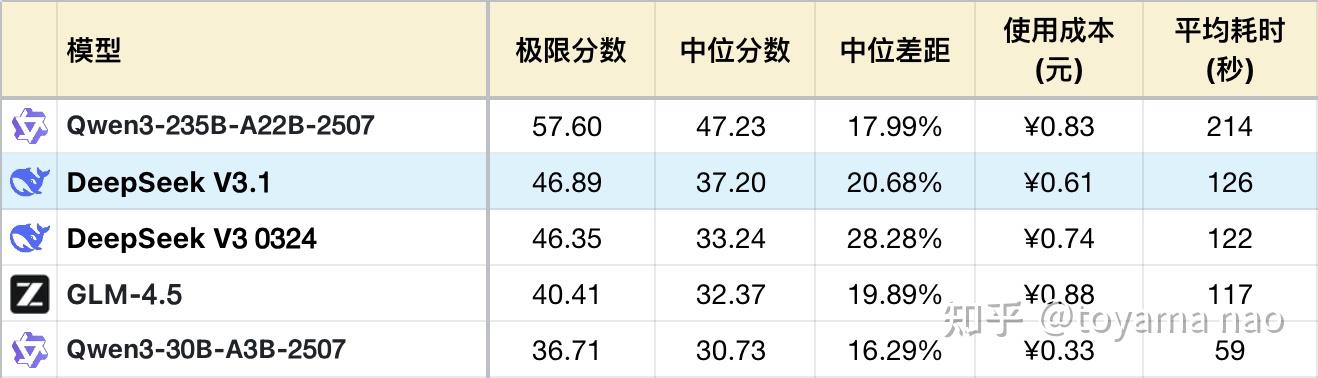
*表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
**题目及测试方式,参见:大语言模型-逻辑能力横评 25-07月榜(Grok4/Qwen3 2507系列)
***完整榜单更新在Github
***这次测试基于8月题目,已经增加#45、#46、#47题,所以所有模型的分数相比7月有变动。
下面就V3.1与前一个迭代0324(以下称旧版)做对比分析。
改进:
- 长度控制:前面已经表述过,V3.1在Token使用上有较大改进。此外,旧版存在小概率死循环输出,以及在一些复杂问题上不受控的反复验算。而V3.1中暂未发现此类问题。即便复杂问题,V3.1也会意识到自己解不出来后选择放弃,不会无脑推理下去。
- 字符能力:在典型的字符能力考察上,V3.1有可观测的改进,如#9单词缩写,#11岛屿面积,#37三维投影,#46字母组合等题目,V3.1整体得分,稳定性均不低于旧版。不过字符能力的改进并没有反映在编程能力上,从精选的少量编程题测试来看,V3.1的变化不显著。
不足:
- 幻觉严重:幻觉是V3以及R1的顽疾,V3.1在这方面自然看不到改善迹象,比如#42年报总结问题,V3.1在所有关键信息摘录上全错,甚至不如旧版。在推理过程会产生大量中间数据/信息的题目上,如#4魔方旋转,#40代码推导,同样表现不如旧版。
- 能省则省:V3.1在很多问题上有较大的“偷懒”倾向,比如#24数字规律,在推导十几次,输出3000多Token时宣布放弃,“由于时间关系,我直接给出常见答案”。#29数学符号重定义,也是在短暂推理后放弃。#39火车票问题因为prompt要求不能写程序,V3.1更是直言不讳,觉得太麻烦,不会做,告辞。类似Case还有很多。或许是DeepSeek为了优化Token时候做的取舍。
- 中英夹杂:夹杂问题在旧版是不存在的,甚至用英文提问,也会回复中文。而在V3.1里,中英夹杂却随处可见,尤其推理到一定长度后,大概率会开始切换到英文进行思考。并且V3.1的夹杂问题比其他存在类似问题的国产模型要稍微严重一些,他会在单词的粒度上来回换语言,这给阅读输出内容造成了极大的干扰。
赛博史官曰:
人们对DeepSeek的关注热情显著的超过其他国内任何一家大模型团队,以至于要让DeepSeek背起打爆OpenAI+Google+Anthropic+Grok的巨大责任,但这显然不不切实际的,技术发展有其必然规律。
从V3.1的变化中,我们能一窥DeepSeek团队的思考逻辑,推测他们自己发现了什么问题,进行了何种尝试,以及这样的尝试带来了怎样的结果和教训。这样的过程或许是任何一个瞄准AGI的大模型团队绕不过去的。
注:V3.1 疑似auto thinking模型,官方api的reasoner接口跑下来输出也有变化,但稳妥起见,等一下官方公告再公布测试情况。