原文链接:
几年前开始,英伟达就已再是一个卖显卡的半导体公司,已经变成了包含计算芯片、模组、主机、超算集群、通信、围绕AGI的软件服务生态的全链条恐怖巨兽。这篇详细拆解一下 B200 系列强在哪里。
先回顾一下 Nvidia 的封神之路
Tesla系列主要有5代显卡:P100、V100、A100、H100、B100。严格来说,从 V100 才算是真的起点,一是因为 P100 没有 Tensor Core 导致 fp16 算力很低。二是因为 NVSwitch 在 DGX-2 V100 上才推出,所以 P100 的 Nvlink 连接比较稀疏(cube-mesh),而且也就 8 卡内用,所以当时 8x P100 不比 8x Titan 强多少。。
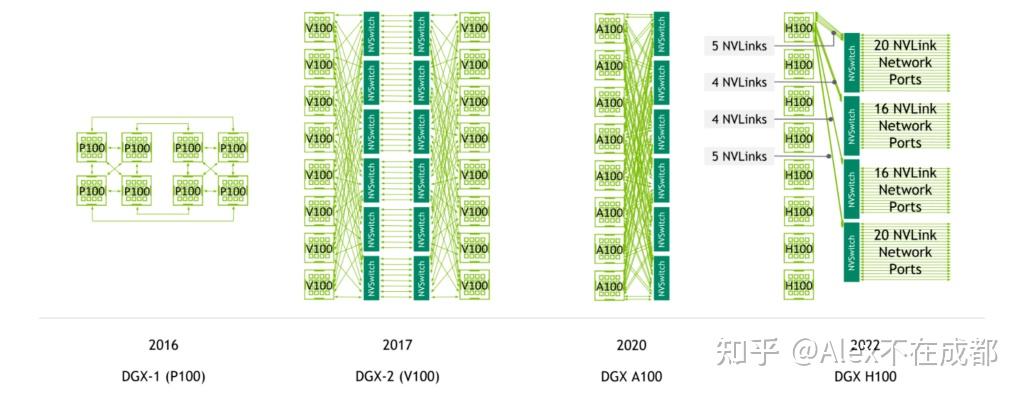
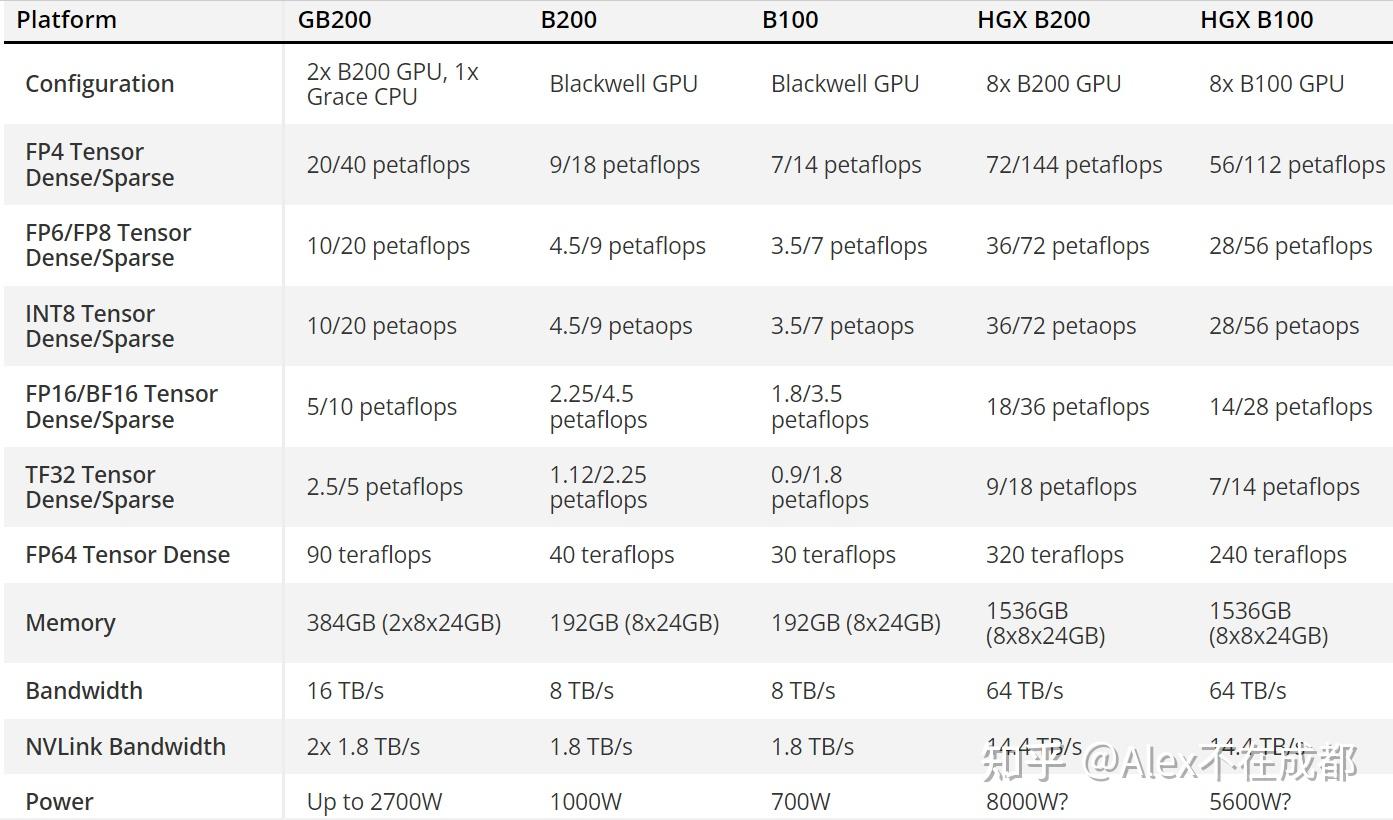
另外,每一代都有 PCIe 和 SXM(有IB)版本,性能略有差异,这里关注搭大集群的 SXM 版本。摘取了一些关键指标:
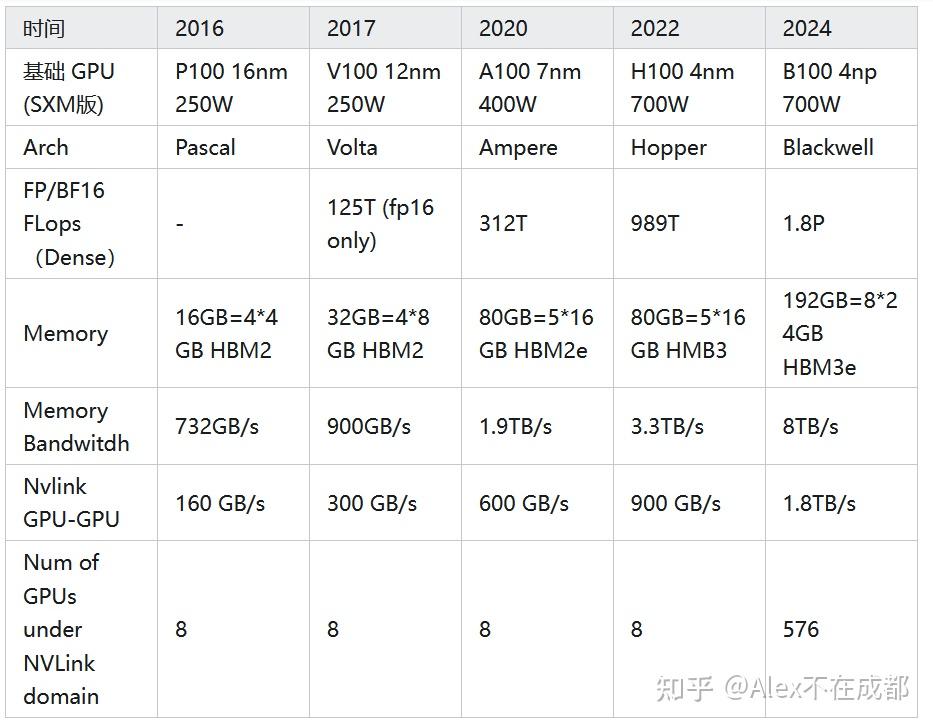
单卡 fp/bf16 算力
现在比较成熟的方案还是 bf16 混合精度,参见
bf16 给定了训练侧算力上限,要加快训练,就要提升 MFU (Model FLOPs Utilization) 。就能现在大模型训练已经到 50-60%,但这一块最多也就到 80%-90%了,不会有永续提升的空间。
V100 到 B100 半精度 flops 7 年增长 14.4 倍,年化 46%。这 14.4 倍怎么来的?其中,晶体管数量扩大 8.5 倍(210亿~1780亿),单晶体管 flops 增大 1.7 倍(架构)。同时,总能耗增大 3 倍多(250w~700w但要扣除 HBM这些,算3.3),但单个晶体管能耗降低2.5倍(制程)。所以 14.4 = 制程2.5 * 能耗3.3 * 架构1.7
未来怎么看?MFU不会有永续提升的空间(现在已经50%了),架构增长比较线性,制程取决于摩尔定律(接近gg)。所以之后单卡算力这块,还是看能耗继续变大 + 低 bit 计算
Memory 大小和速度
因为有 KV Cache,增量推理基本还是 Memory bound,可以对比下面的 B200/H200 fp8 的最大 throughput,基本就是显存速度快多少,推理吞吐就就快几倍(大概2.4倍)
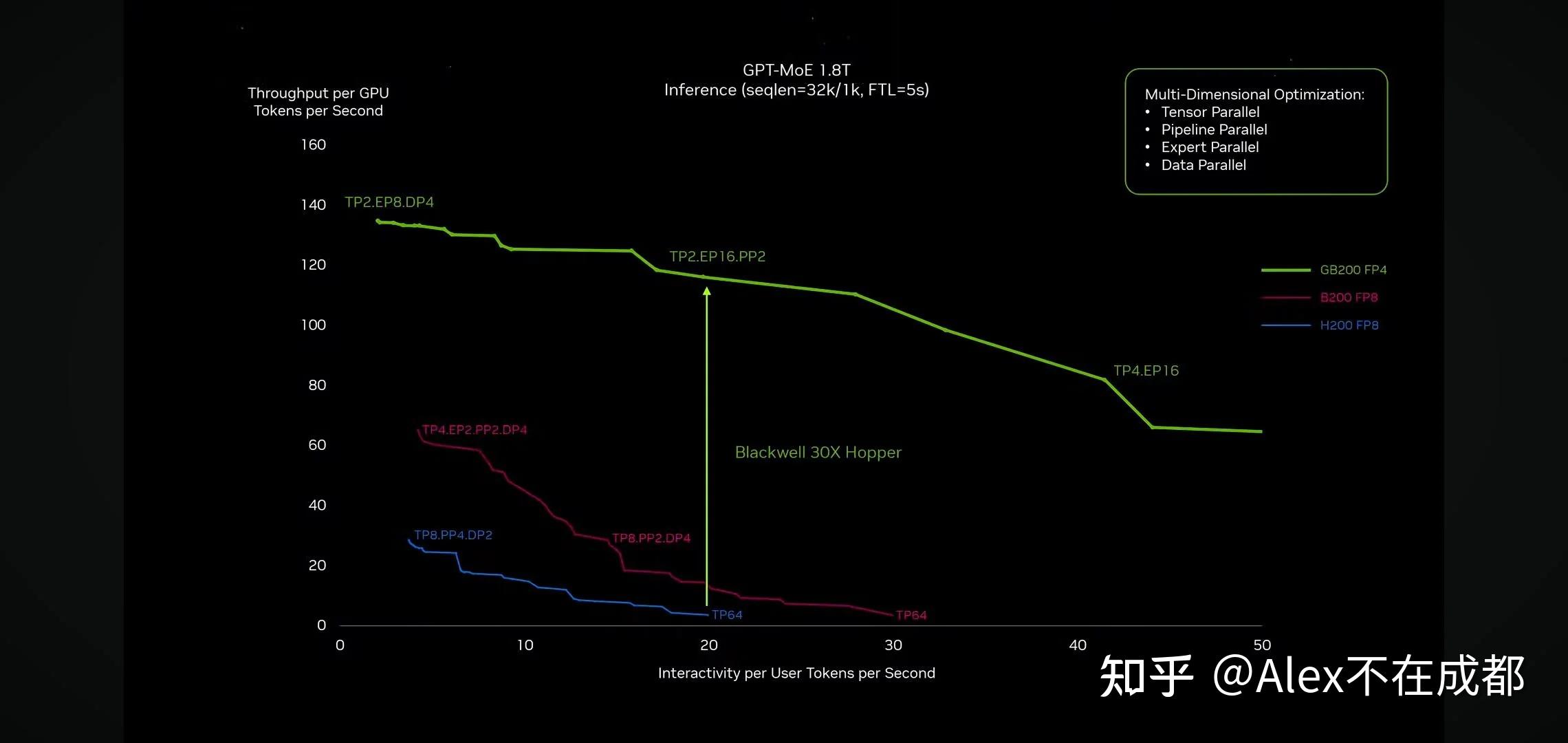
GB200 比 H200 图里快 30 倍,3个原因:1)对于 GPT-4 MoE 1.8T 32k,GB200 能跑的的并行策略更优(绿线中间vs.蓝线末端,这一块影响6倍,2)Memory 从3.3TB/s 到 8TB,快 2.4 倍,3)fp4 和 fp8 对比,2倍
未来怎么看?推理这一块要降低成本,只要是显存放得下,就尽可能少用卡(显存带宽 8TB vs. NVlink 1.8TB 还是显著高)。图里面如果大家都用 fp8 比,GB200 相比 H200 提速估计在 10 倍左右。从 4bit 往 3bit 推理量化,算法上还有比较大精度问题,2bit 再往下可能就比较困难了。未来推理这块,在 transformer 的设定下,主要看 HBM 了,要更大更快。推理速度决定推理成本,这又进一步决定了有多少应用可以商业化。
NVLink 速度和通信域
NvLink 的速度决定了单卡模型塞不下时,能以多快速度 offload 到其他卡上。NVLink 通信域决定了有多少卡可以享受到 NvLink 的高速互联,也就是“一个多卡节点”能做多大。
B 系列产品有 B100、B200、GB200、HGX B100、HGX B200、DGX GB200 NVL72。这次 GTC 主推的其实是 B200、GB200。
- B200 包含两个 die 用 10TB/s NVLink-HBI 相连。B100 是 B200 的降频版,功耗和 H100 一样,方便兼容原有散热和电源
- GB200 = 2 x B200 + Arm CPU,NVlink C-C 900GB/s。算力比两个 B200 加起来还高 10%,有点踢开 x64 拥抱 Arm 的意思
- 然后 36 x GB200 组成一个 NVL72,这里 NVL72 其实是一个新东西。只看 NVL72 内部,全部用背板铜线连接,有点像 PCB 了。。。可能一方面降成本,另一方面光模块太多,综合故障率会很高,需要有非常完善的容灾方案。单看这 72 个 B200,任意两个点对点都有 Nvlink 的 1.8TB/s 通信。所以其实这 72 个 B200,和原来的单机8卡是一个东西,变成了“超节点”
- 再往上,8个 NVL72 通过 Quantum X800 Switch 相连(800GB/s)形成 rack,包含 576 个 B200。然后再 叶-脊 组网成 32000 GPU 的数据中心
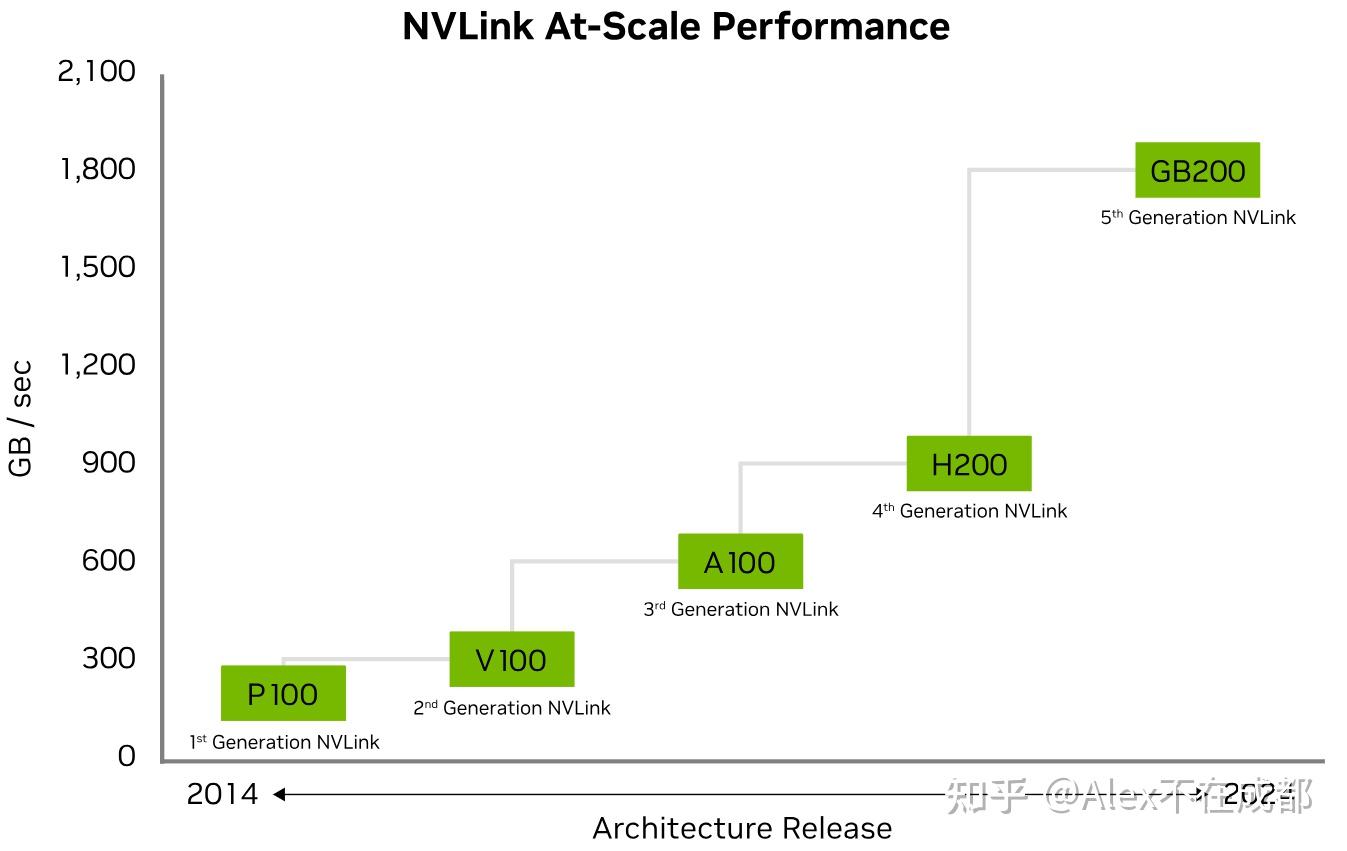
大芯片大显存、超节点、跨节点互联,就是英伟达三板斧。Summit 集群用了 27648 块 V100,用 B200 构建10万卡集群技术完全可行。10w 卡的 B200 集群什么概念,相当于 80w 张 A100,什么概念,大概 GPT-4 三四天就能训完,训练比 GPT-4 大 10 倍的模型成为可能。
关于压缩的层级和 scaling law
GPU集群有类似 GPU-node-rack-superpod-cluster 的层级,这次像是对层级做了一级抽象,扩大了集群规模的上限。原来的 node 变为现在的 chip,原来的 rack 压成了一个 node。V100 到 B200 的7年,总算力增长了几百倍,其中集群规模贡献 >10倍,单卡算力增长20 倍(但价格涨3倍)
未来几年,算力要再扩大几百倍,怎么实现?maybe:2倍来自低bit训练(fp8) * 2倍来自制程和架构 * 数倍来自单卡能耗 * 数十倍来自集群规模(百万卡集群)。模型训练侧的 scaling law 还有充足的燃料,但单位美元的算力增长其实没那没夸张,可能最后的最后 scaling law 会变为一个经济问题而不是一个技术问题,参见
下面歪个楼,关于怎么看昇腾 NPU
| 910B | A100 | |
|---|---|---|
| fp/bf16 | 320T | 312T |
| Power | 400W | 400W |
| Memory | 64GB HBM2e | 64GB HBM2e |
| Bandwidth | HCCS 392GB/s | Nvlink 400GB/s |
华为昇腾和英伟达还是有一些代际差的。910B 各种参数基本能对标 A100,主要区别在于机内通信的拓扑上。
A100 用的是 NVSwitch,400GB/s 是 one GPU-all NVSwitch 之间的总带宽,但单个 GPU-GPU 可以占满这个值。华为的 HCCS 带宽 56GB*7=392GB 指的是 all-to-one aggregation 的总值,单个 NPU-NPU 之间最大是 56GB。
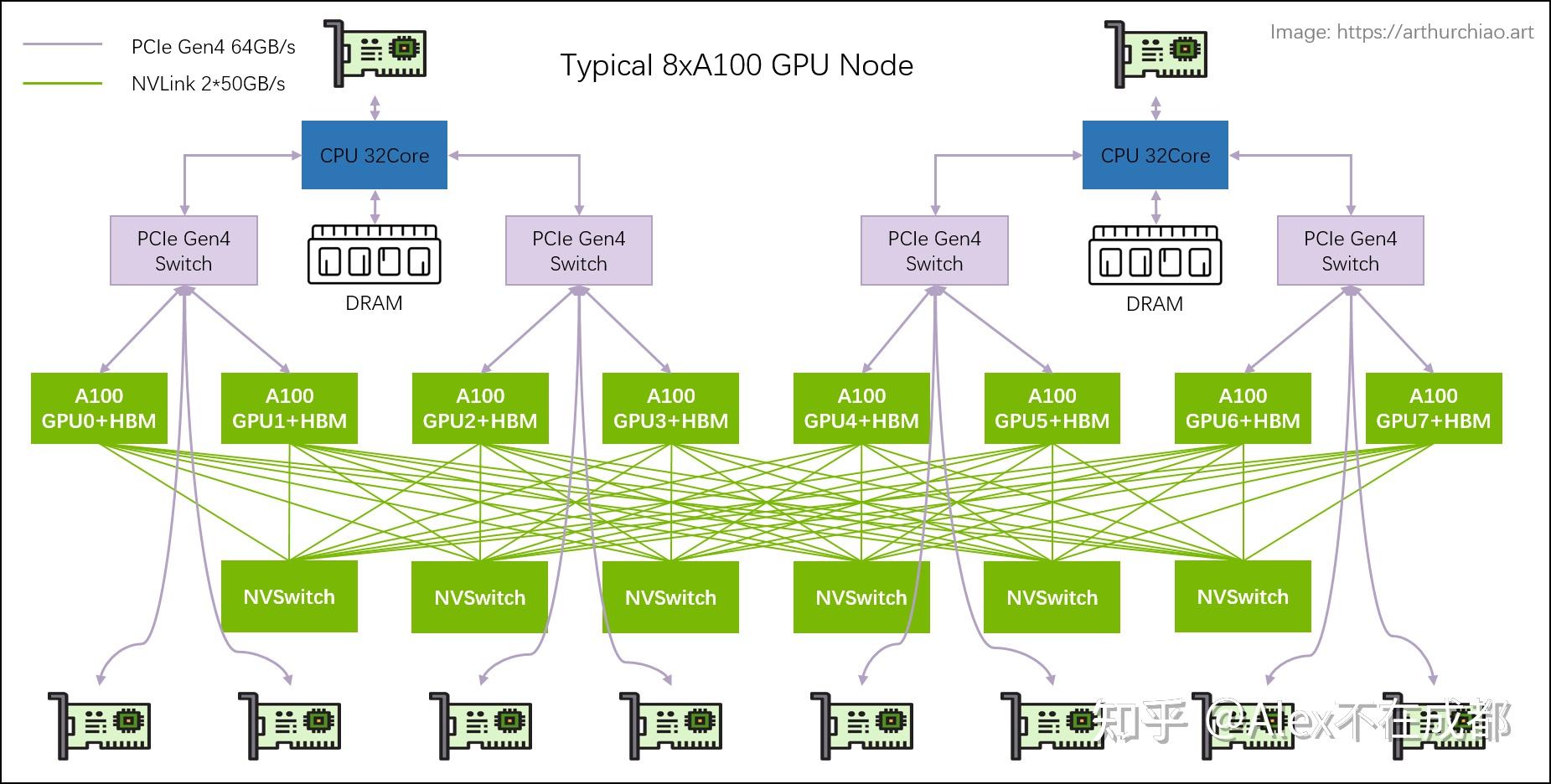
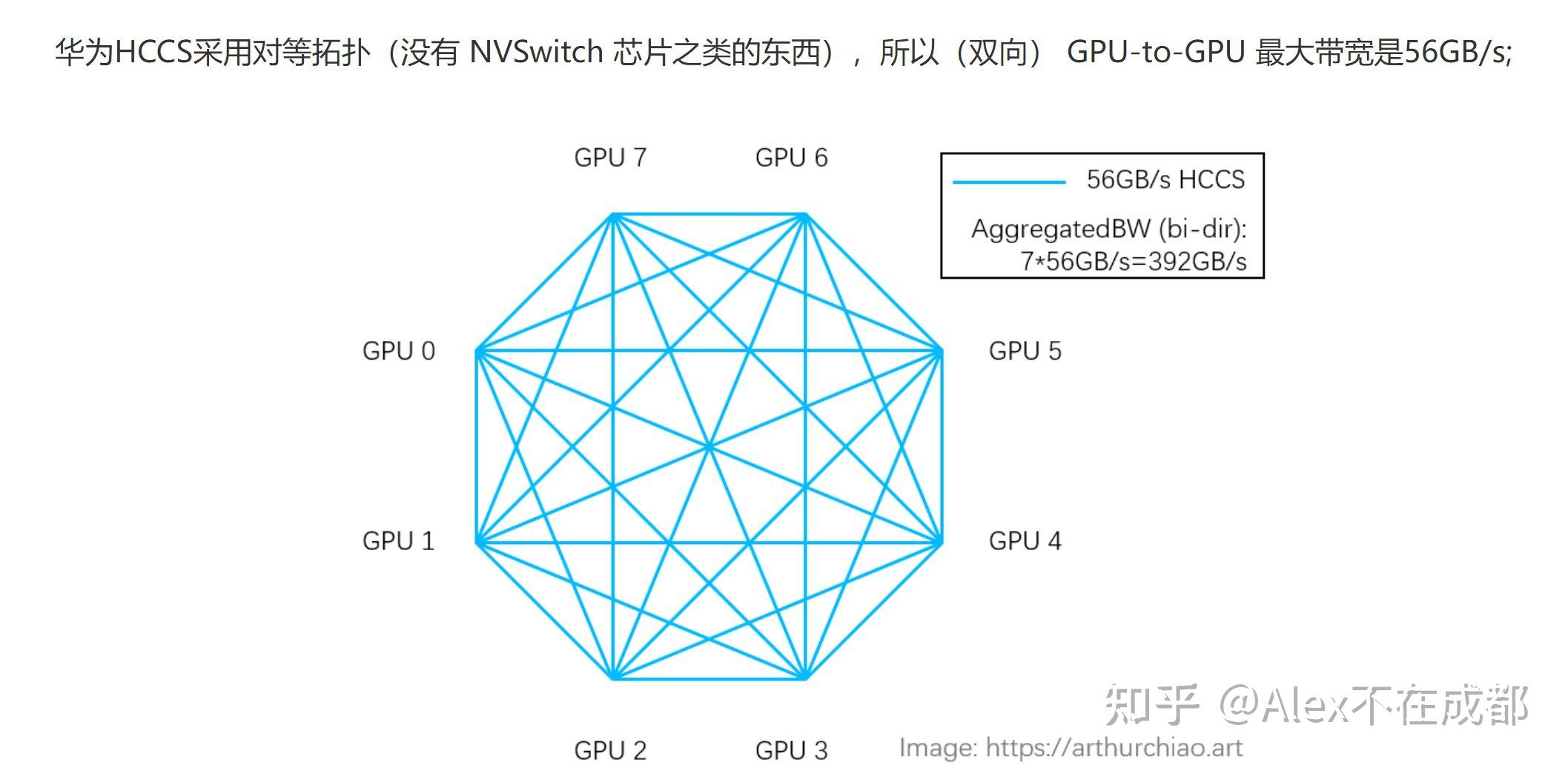
这是不是说英伟达的设计更高级一点?其实不是。对于 broadcast、gather、scatter、all gather、all-to-all 这些一对多、多对多的通信算子,不存在被 HCCS 点对点只有 56GB/s 卡脖子的情况。
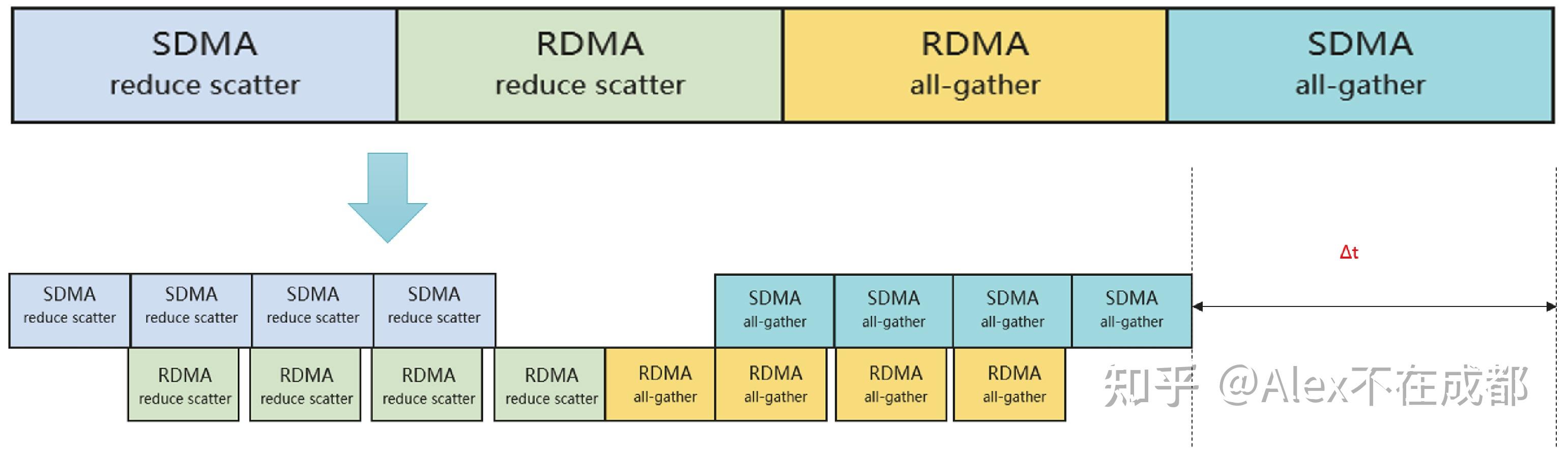
大模型训练里面用的最多的 all-reduce 单独说一下。all-reduce 其实两种实现,有 reduce+broadcast(多对一)、ScatterReduce + AllGather。一般都是用第二种分担单卡带宽压力。
对于第二种,如果是 mesh 拓扑全部两两互联的,每张卡都可以把要传输的数据切成小块,同时开多个流同时传给其他节点,本质也是一对多传输。如果不是 mesh 是 ring,就有 ring-all reduce,依赖相邻节点互传;之外还有 tree-allreduce,halving doubling 之类的,依赖类似二分规约的。
HCCS 的话,机内 8 卡通信因为 mesh 拓扑,56GB/s*7 是用满了的,并不“缩水”。跨机用 RoCE 通信,并且机内和机间的 all-reduce 还可以做流水线互相掩盖,所以通信效率还是挺高的。