
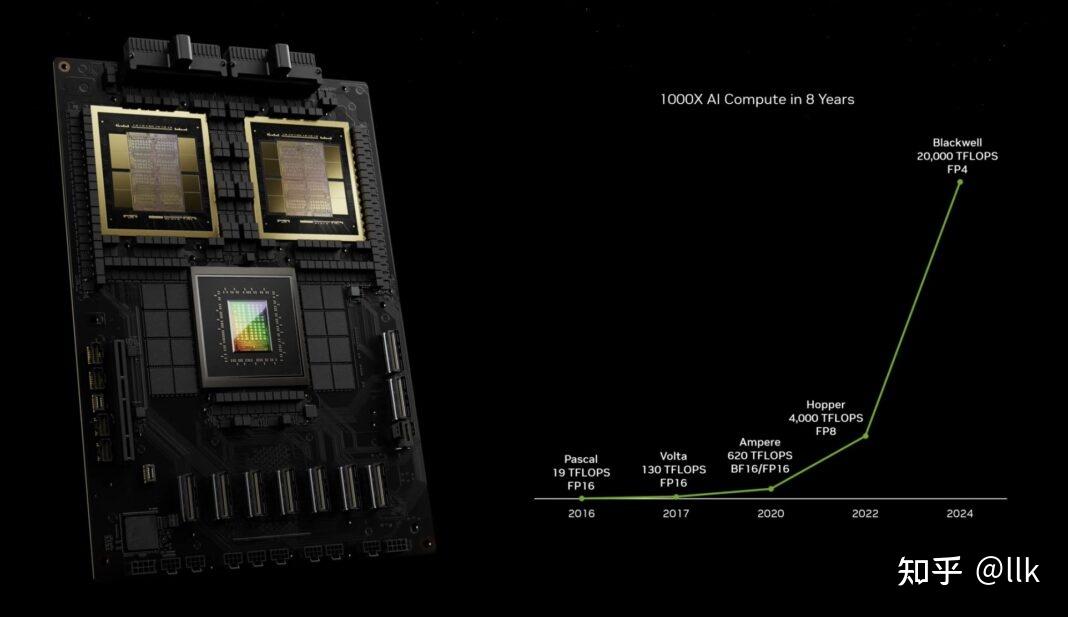
今年发布的Blackwell明白无误的告诉大家摩尔定律不在神奇了,之前NVIDIA的可扩展的GPU架构搭配摩尔定律可谓摧枯拉朽,让大家难以望其项背;而现在NVIDIA发布会对于芯片本身特性基本一笔带过,而重点都在DGX系统上,也就是芯片内部依靠摩尔定律扩展基本到头,后面扩展主要靠芯片间互联来完成了。另一个就是这种算力的提升并没有宣传中那么夸张,像NVIDIA展示的8年里AI算力提升了1000X,主要靠的是数据精度,从最开始高性能计算的FP64,FP32,FP16,到FP8,FP4。
而对于芯片间互联,分成两类:
- 一类是D2D,也就是通过interposer实现die之间互联,这种一般是高速并行接口,可以提供TB级别的带宽,主流技术有TSMC的CoWoS,Intel的EMIB等,今天发布的Blackwell就是采用D2D将两颗die互联封装,可以提供10TB/s的带宽。

- 另一类就是NVLink为代表的芯片间互联,业界推出的就是UCIe标准。Blackwell已经演进到第五代了,搭配NVLink Switch芯片,可以提供7.2TB/s总带宽,支持GPU进行纵向扩展。

当然,还有一类是采用Infiniband和Ethernet进行横向扩展,这些一起组成了NVIDIA的DGX系统。
总而言之,现在对于NVIDIA的竞争者,工艺不再是问题,比拼的重点在互联,不管是die内互联,还是片间互联,甚至网络互连,如何组成更高带宽的系统才是关键。
发布于 2024-03-20 05:20・IP 属地上海