
总体来看是瞄准的是大模型,还有大力出奇迹。 参考意义两方面:
- 在工艺一定时,可以增大面积,采用更小精度,来增加吞吐。国产芯片可参考。
- 产品国内是买不到的,实测也没机会,只能根据资料(datasheet/TechBlog)评估一下当A国的大厂装备了此等装备后,我们该怎么追? 我们迭代一个模型耗费一年,人家迭代一个月/一周/一天?国产大模型厂可参考。
不是游戏卡,跟普通消费老百姓关系不大,就看看参数的热闹,来句“哇塞,SpaceX的钢皮甲烷火箭又升天啦”即可。
根据一些参考文章(文末)看一下新芯片在软/硬件的亮点:
1 硬件
1.1 芯片的升级
架构取了个新名字BlackWell
特点1:工艺不变,面积大了。怎么变大的---就是把两块芯片通过一根10TB/s 接起来,那么就大了。工艺的话认为是没有多大变化的。发布会嘛,不能说没啥变化吧,那就来个改良版4NP。
Blackwell-architecture GPUs pack 208 billion transistors and are manufactured using a custom-built TSMC 4NP process. All Blackwell products feature two reticle-limited dies connected by a 10 terabytes per second (TB/s) chip-to-chip interconnect in a unified single GPU.
工艺不变,串一点芯片就有戏了,真好,再也不要说堆叠了,我们搞串并联。so,国内的芯片是不是可以搞个4连、8连、16连、一键三连等措施,不管怎样连就对了。比如这样:
特点2:依然稳稳地瞄准了大模型。 二代transformer引擎,针对的是MoE 和FP4。
1、此处,我和很多砖家们一样,都猜不准是为了搞点新鲜,从而推出了个FP4精度,还是说FP4真的有神奇之处。幸运的是,没有机器验证不了,先挖个坑,后续有机会了测测填坑(等A国解禁或者自费出国?)。
2、MoE嘛...国内的独角兽们,MoE市场需求再次实锤了,搞大模型MoE必不可少,投投投。
特点3/4/5: 好像没啥特点,参看文献1。
1.2 集群的升级
集群又升级了,这才是利器啊!造一个东西可能不难,量产一堆东西,还有凑在一起稳定工作、性能优秀、节能环保,这就有点家伙了。
过程是:
第一步,生成产这玩意(机器 GB200):

第二步,组装成这玩意(机柜 NVIDIA GB200):

第三步,接着拼装成这玩意(集群):

我们直接看看集群的参数吧:
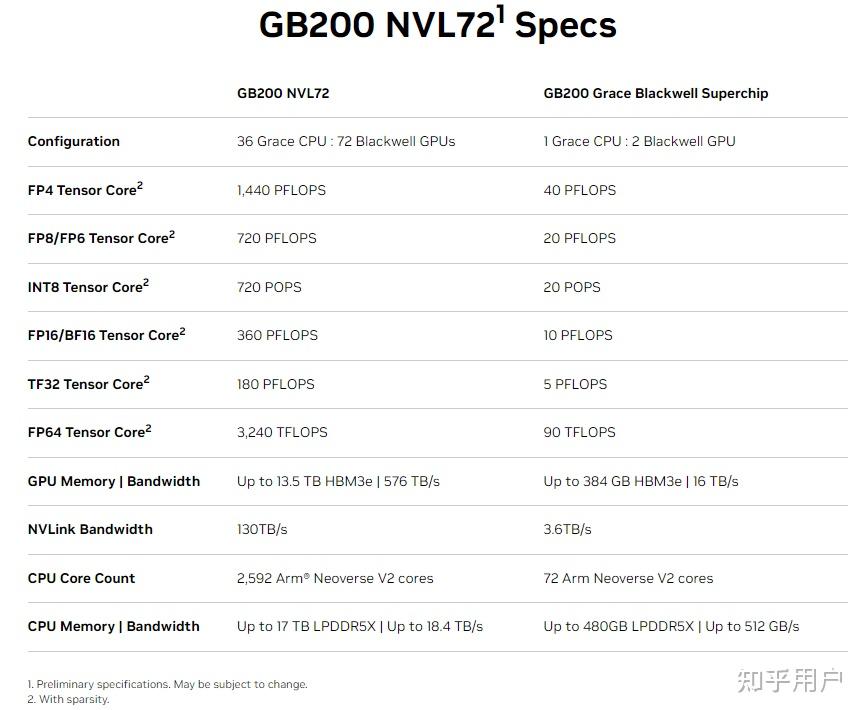
看着确实不错,注意下面有串小字2:是在稀疏条件下测试的数据哦。
2 软件
软件方面的提升主要看看训练和推理方面的吞吐,这里也找到了官方提供的大模型benchmark数据,大家看看就好了:

推理吞吐的宣传:
GB200 NVL72 introduces cutting-edge capabilities and a second-generation Transformer Engine which enables FP4 AI and when coupled with fifth-generation NVIDIA NVLink, delivers 30X faster real-time LLM inference performance for trillion-parameter language models. This advancement is made possible with a new generation of Tensor Cores, which introduce new microscaling formats, giving high accuracy and greater throughput. Additionally, the GB200 NVL72 uses NVLink and liquid cooling to create a single massive 72-GPU rack that can overcome communication bottlenecks.
训练吞吐的宣传:
GB200 NVL72 includes a faster second-generation Transformer Engine featuring FP8 precision, enabling a remarkable 4X faster training for large language models at scale. This breakthrough is complemented by the fifth-generation NVLink, which provides 1.8 terabytes per second (TB/s) of GPU-to-GPU interconnect, InfiniBand networking, and NVIDIA Magnum IO™ software.
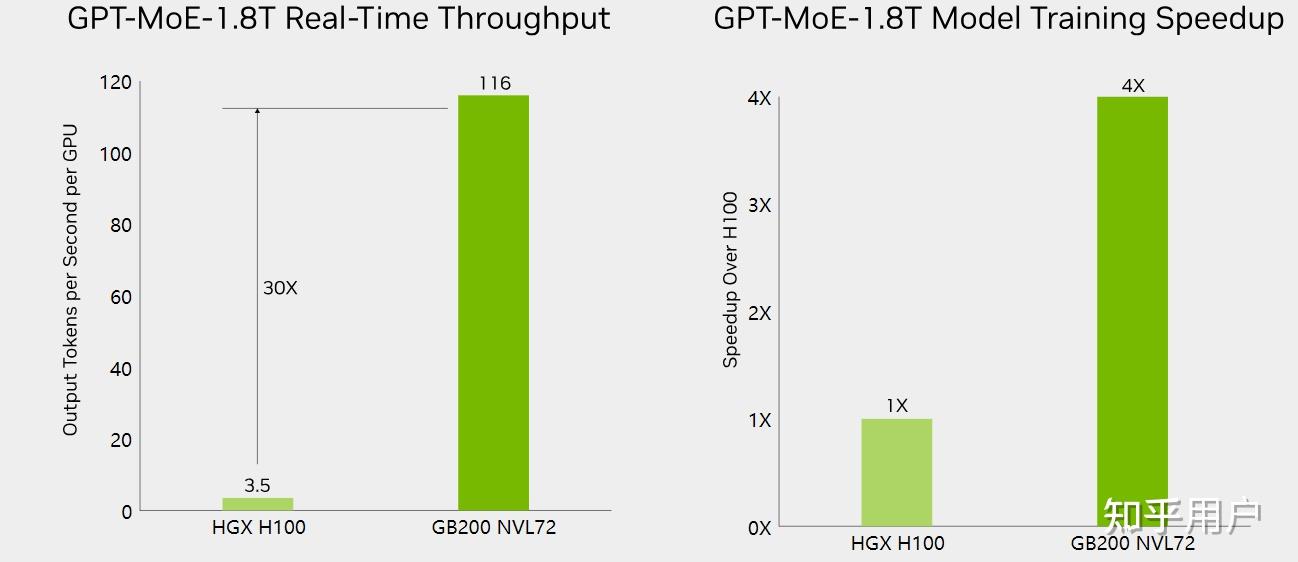
数据里面,其它数据都比较酷炫。就训练倍数是4x,可见训练提升不是那么容易。考虑真实的线性度,数据可能会更低。
不管怎么样,钢板甲烷火箭还是上天了,值得我们学习。
参考文章:
- Blackwell Architecture for Generative AI | NVIDIA
- NVIDIA DGX SuperPOD with DGX GB200 Systems Datasheet
- NVIDIA Blackwell Platform Arrives to Power a New Era of Computing | NVIDIA Newsroom
- GB200 NVL72 | NVIDIA
- NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference | NVIDIA Technical Blog