
很高兴开始有人提这个问题,这个问题我专门研究过,写了一篇专门的文章来探讨这个问题。我把这个现象叫做Reward Drop,举个例子,用TD3算法在Pendumlum-v0这种最简单的环境上实现,出现了下面的曲线:
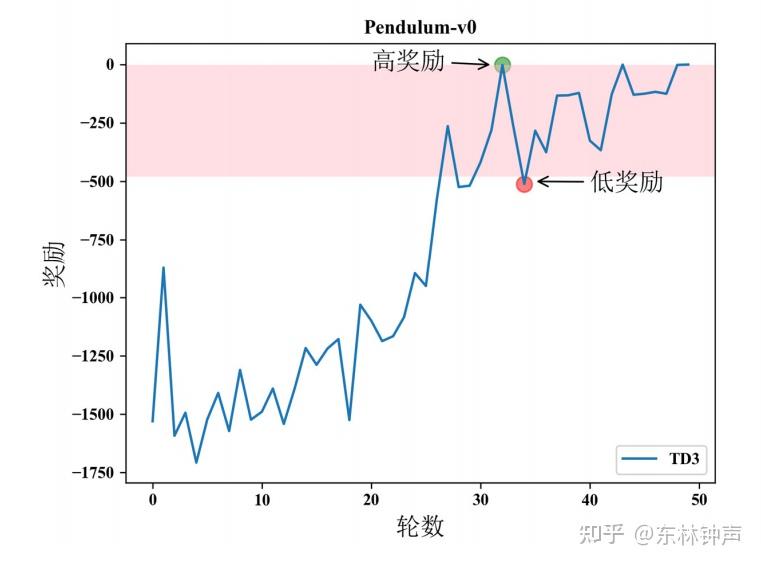
从训练结果图中,可以明显的看到,在强化学习算法训练的后期,其在第 33 轮 获得的回合奖励会突然从“高奖励”数值 0 降到第 34 轮获得的“低奖励”数值-500, 并且之后会在图中标记的阴影区内来回反复震荡,直到最后 50 轮训练完成之后都没有得到很好的收敛。然后我把“高奖励”,“低奖励”的奖励轨迹拿出来对比:
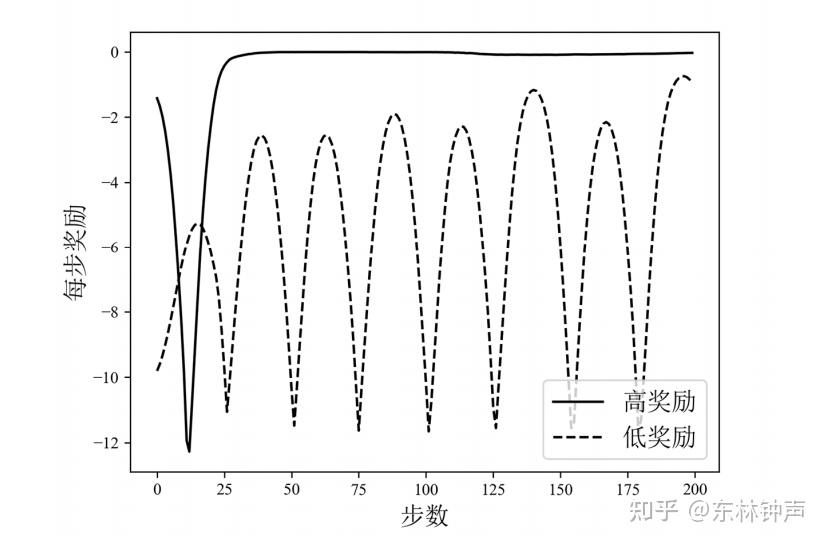
可以发现,“低奖励”的轨迹相较于“高奖励”的轨迹具有更大的波动性。那么这个时候有一个很直观的想法,我们平滑奖励轨迹,减少波动性,如下:

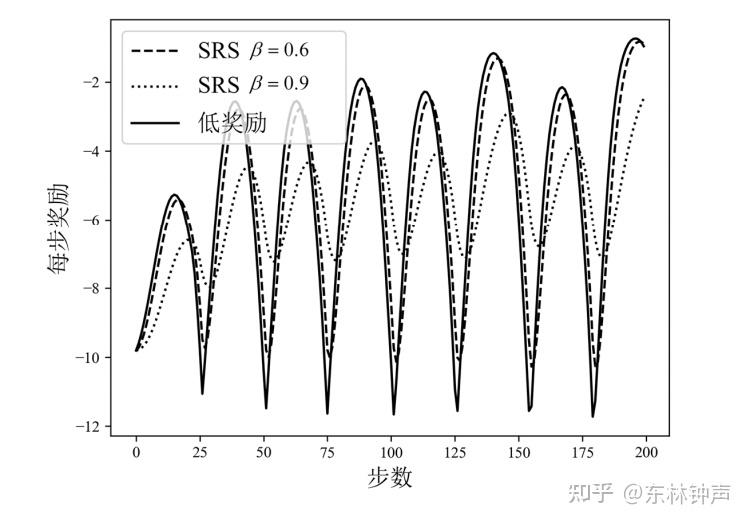
然后再用平滑后的奖励来训练,但是记录的时候还是记录原始奖励,如下:
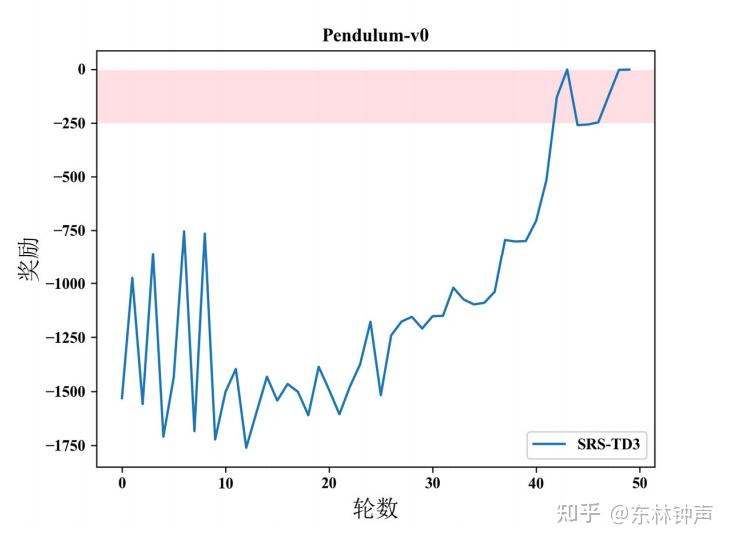
得到有效缓解。我提出的这个方法叫做reward smoothing,文章还探讨了smoothing之后,值函数的不变性,TD-Target的方差减少,以及在Q-Learning下的收敛性。文章在:
发布于 2023-12-15 17:51・IP 属地湖北