共3个回答0条评论
分享
强化学习reward曲线震荡是怎么回事呢?
使用了SAC算法,曲线在后期达到较优值后,突然发生骤降。调整学习率后发现影响不大,甚至难以收敛,请问应该如何调整?如果需要调整神经网络层数和单元数,应该调整策略...
显示全部
南京信息大学bb
排序方式:被封时间
时间排序由新到旧
- 42 个点赞 👍
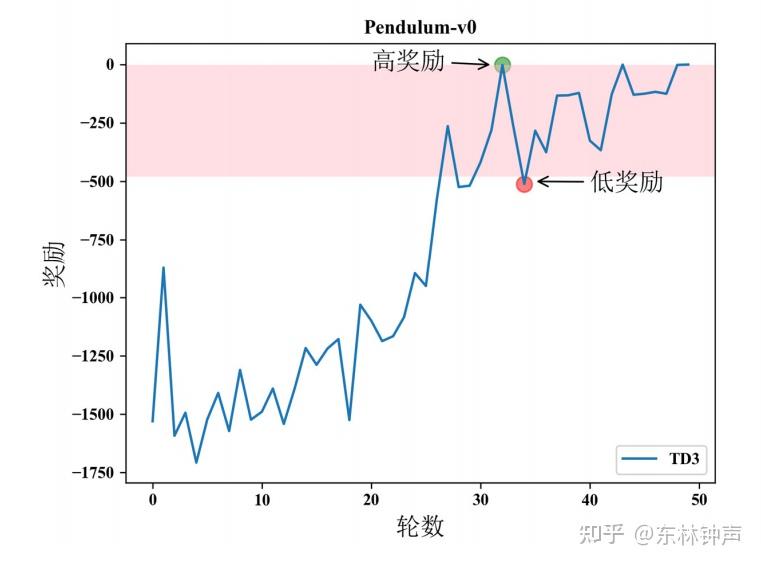
很高兴开始有人提这个问题,这个问题我专门研究过,写了一篇专门的文章来探讨这个问题。我把这个现象叫做Reward Drop,举个例子,用TD3算法在Pendumlum-v0这种最简单的环境上实现,出现了下面的曲线:


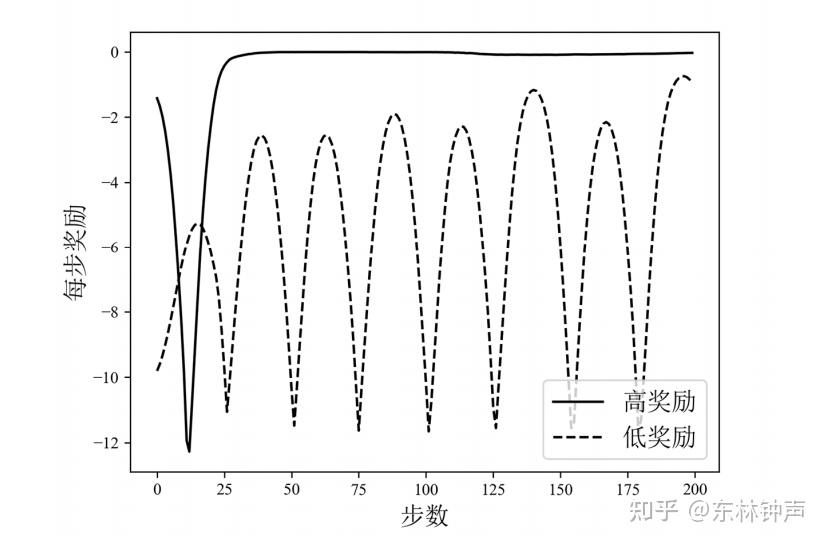
从训练结果图中,可以明显的看到,在强化学习算法训练的后期,其在第 33 轮 获得的回合奖励会突然从“高奖励”数值 0 降到第 34 轮获得的“低奖励”数值-500, 并且之后会在图中标记的阴影区内来回反复震荡,直到最后 50 轮训练完成之后都没有得到很好的收敛。然后我把“高奖励”,“低奖励”的奖励轨迹拿出来对比:


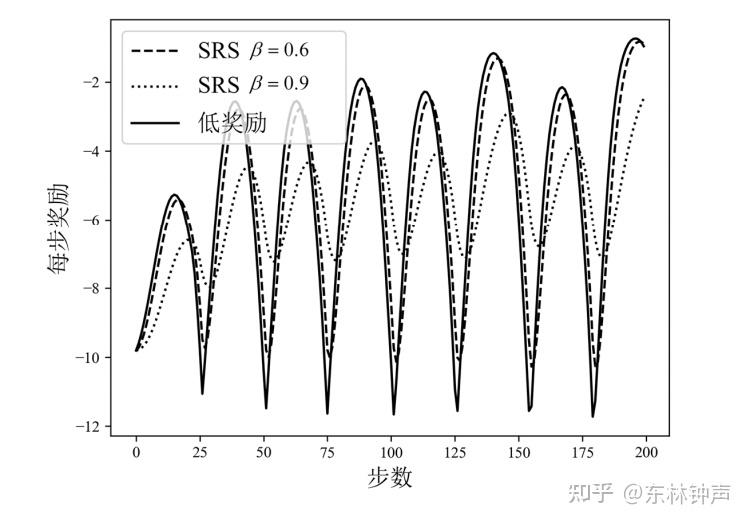
可以发现,“低奖励”的轨迹相较于“高奖励”的轨迹具有更大的波动性。那么这个时候有一个很直观的想法,我们平滑奖励轨迹,减少波动性,如下:




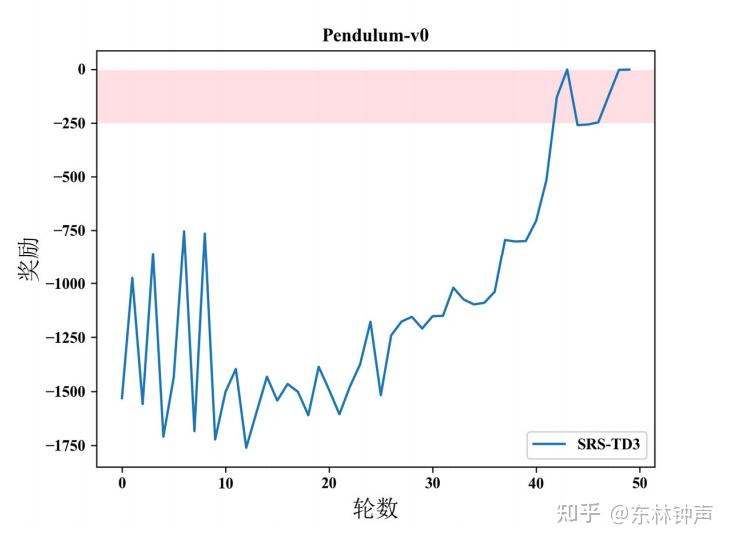
然后再用平滑后的奖励来训练,但是记录的时候还是记录原始奖励,如下:


得到有效缓解。我提出的这个方法叫做reward smoothing,文章还探讨了smoothing之后,值函数的不变性,TD-Target的方差减少,以及在Q-Learning下的收敛性。文章在:
发布于 2023-12-15 17:51・IP 属地湖北查看全文>>
东林钟声 - 2 个点赞 👍
从你提供的曲线图来看,SAC算法在后期达到较优值后,突然发生骤降,这可能是以下几个原因造成的:
- 训练数据集不够多:如果训练数据集不够多,模型就无法学习到足够的知识,从而导致在后期出现过拟合。
- 超参数设置不当:超参数设置不当,例如学习率过高或过低,会导致模型难以收敛或收敛到局部最优解。
- 算法本身存在问题:SAC算法本身也存在一些缺陷,例如在某些情况下容易出现震荡。
如果你已经调整了学习率,但影响不大,甚至难以收敛,那么可以尝试以下几种方法:
- 增加训练数据集的大小:如果您有条件,可以增加训练数据集的大小,从而提高模型的泛化能力。
- 调整其他超参数:可以尝试调整其他超参数,例如奖励衰减率、噪声大小等,以提高模型的收敛性。
- 尝试其他算法:如果你对SAC算法本身不太确定,可以尝试其他算法,例如PPO或TD3。
如果需要调整神经网络层数和单元数,建议调整策略网络。策略网络是SAC算法中负责生成动作策略的网络,其层数和单元数对模型的收敛性有较大影响。一般来说,层数越多,单元数越大,模型的收敛性越好,但也越容易过拟合。
具体来说,可以尝试以下几个方案:
- 增加策略网络的层数:增加策略网络的层数,可以提高模型的学习能力,从而提高收敛性。
- 增加策略网络的单元数:增加策略网络的单元数,可以提高模型的表达能力,从而提高收敛性。
- 增加策略网络的宽度:增加策略网络的宽度,可以提高模型的并行计算能力,从而提高收敛速度。
可以根据自己的实际情况,尝试不同的方案,以找到最合适的配置。
发布于 2023-12-15 10:01・IP 属地上海查看全文>>
说法与您零距离 - 0 个点赞 👍
查看全文>>
盛见者