
隐私问题和数据滥用一直都是老大难,到大模型时代会难上加难,这个基本观点应该没错。不过院士这段话比较杂糅,不知道是不是剪辑的原因,里面既有模型训练,也有数据收集,也有文本分析,也提到了对齐技术,这些属于不同层面、不同阶段的影响。
发言中提到了 ChatGPT,先说这个所谓的「数据控制键」:
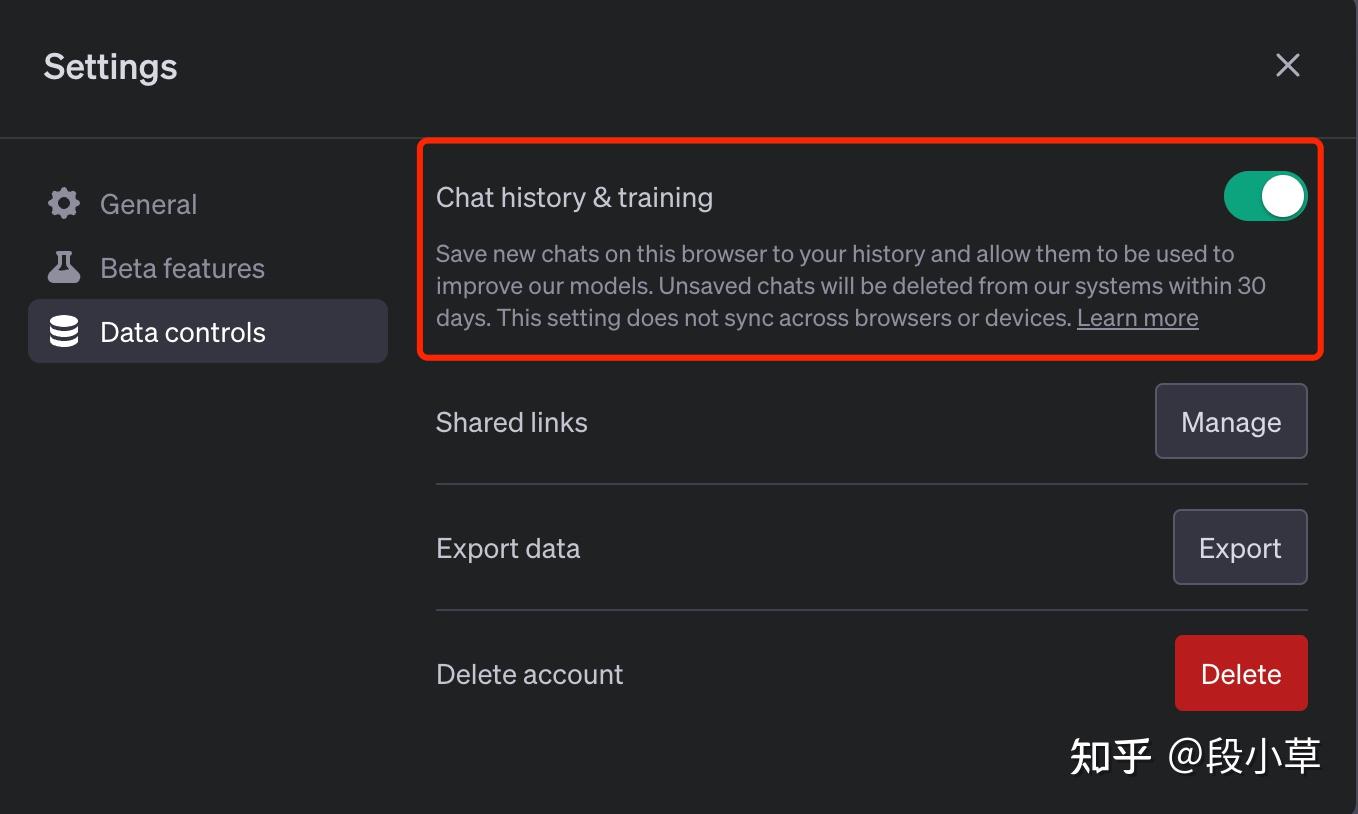
院士说:「要么继续跟我对话,要么允许我把你对话中的数据用于以后的训练过程」。
「要么…要么…」会让人觉得这两个选项互斥。其实不然,这里的数据训练开关,即使关闭以后,也依然可以无限制地使用 ChatGPT[1]:

如果禁用这个选项时,聊天数据将不再用于训练,但ChatGPT 不会再提供历史对话功能。(数据依然会被保存 30 天,用于内容审查):

也就是说,并不是「对话」与「训练」互斥,而是「历史记录」与「训练」互斥。
同时也注意到,调用 API 的使用数据不用于训练;但鉴于调用 API 的方式大多数是第三方开发应用,除非程序是自己写的,否则数据依然会进入到第三方开发者手中。
大模型分为训练和推理,大模型的训练成本很高,而且需要海量的数据。如果是训练阶段混入了一些个人隐私,是有可能在对话使用中造成泄漏的。
另一种就是第三方数据收集,比如有人使用大模型搭建对话服务或者镜像站,由于自然对话的属性,用户会更容易地在交流中提供自己的个人信息,这些数据就有可能会被记录。
大模型也会帮助到文本分析,就像院士说的那些公开的社交网站数据。这些数据有可能被用于训练,也有可能会被采集后使用大模型进行分析,进而进行更精准的画像。
不过不论是数据收集,还是画像分析,更多的是人为的滥用,与大模型本身是没有直接关系的。
至于说最后提出的解决方案是「对齐」,说实话,我倒没想出对齐怎么解决隐私问题,毕竟对齐主要还是解决模型输出与人类期望相一致的问题,更多的是解决道德和安全问题。
当然,我们可以通过对齐去要求模型不输出涉及隐私的内容,或者对相关的分析话题更加谨慎,不过我也不知道这是不是院士所表达的意思…
反正我觉得,对齐技术最多是间接性的限制和缓解,肯定不是解决隐私问题的最好方式,解决隐私问题,靠的还是数据清洗、数据匿名脱敏,靠的是让用户了解自己的数据如何被使用,告知用户保护自己的个人隐私,限制企业的数据收集。