中科院院士称「大模型让隐私保护难上加难」,如何看待此言论?你认为大模型时代隐私保护会更困难吗?

- 1 个点赞 👍被审核的答案
生活在这里,我们有密集的摄像头,各种识别,各种门禁扫描,用点APP随时眨眼摇头照相配合,微信群里聊几句第二天就可能有人打电话,个人信息被卖来卖去不如娼妇,一多半的宾馆装满了针孔摄像头,所有浏览过的网站都会给你爱看的,所有的购物频道都有算法推荐,甚至现在就连评论区都能给你差别显示。
隐私是什么,又有什么可担心的,什么时候又尊重过个人隐私了,天天挨操会在乎多那么一两棒槌?
院士过虑了,对于终日裸奔的人,屁股远没那么重要的,随时随地准备捡肥皂,尽管放马过来。别老想着啥都插一手,如果你真有紧箍咒,真能管的好,现在也不是这样。
编辑于 2023-09-10 20:15・IP 属地重庆查看全文>>
Mr.ddv - 12 个点赞 👍
隐私问题和数据滥用一直都是老大难,到大模型时代会难上加难,这个基本观点应该没错。不过院士这段话比较杂糅,不知道是不是剪辑的原因,里面既有模型训练,也有数据收集,也有文本分析,也提到了对齐技术,这些属于不同层面、不同阶段的影响。
发言中提到了 ChatGPT,先说这个所谓的「数据控制键」:
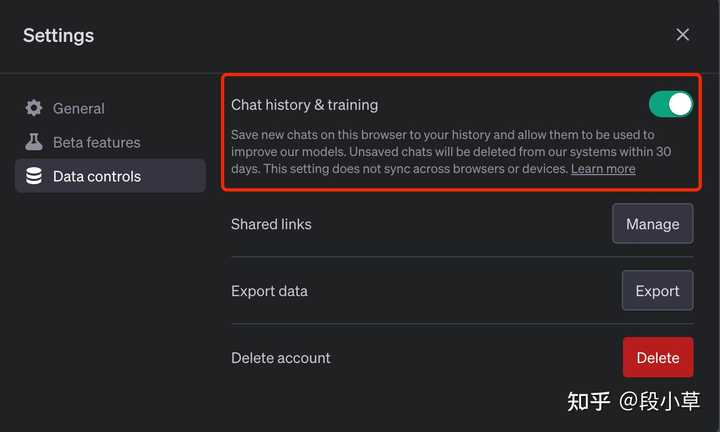
院士说:「要么继续跟我对话,要么允许我把你对话中的数据用于以后的训练过程」。
「要么…要么…」会让人觉得这两个选项互斥。其实不然,这里的数据训练开关,即使关闭以后,也依然可以无限制地使用 ChatGPT[1]:


如果禁用这个选项时,聊天数据将不再用于训练,但ChatGPT 不会再提供历史对话功能。(数据依然会被保存 30 天,用于内容审查):


也就是说,并不是「对话」与「训练」互斥,而是「历史记录」与「训练」互斥。
同时也注意到,调用 API 的使用数据不用于训练;但鉴于调用 API 的方式大多数是第三方开发应用,除非程序是自己写的,否则数据依然会进入到第三方开发者手中。
大模型分为训练和推理,大模型的训练成本很高,而且需要海量的数据。如果是训练阶段混入了一些个人隐私,是有可能在对话使用中造成泄漏的。
另一种就是第三方数据收集,比如有人使用大模型搭建对话服务或者镜像站,由于自然对话的属性,用户会更容易地在交流中提供自己的个人信息,这些数据就有可能会被记录。
大模型也会帮助到文本分析,就像院士说的那些公开的社交网站数据。这些数据有可能被用于训练,也有可能会被采集后使用大模型进行分析,进而进行更精准的画像。
不过不论是数据收集,还是画像分析,更多的是人为的滥用,与大模型本身是没有直接关系的。
至于说最后提出的解决方案是「对齐」,说实话,我倒没想出对齐怎么解决隐私问题,毕竟对齐主要还是解决模型输出与人类期望相一致的问题,更多的是解决道德和安全问题。
当然,我们可以通过对齐去要求模型不输出涉及隐私的内容,或者对相关的分析话题更加谨慎,不过我也不知道这是不是院士所表达的意思…
反正我觉得,对齐技术最多是间接性的限制和缓解,肯定不是解决隐私问题的最好方式,解决隐私问题,靠的还是数据清洗、数据匿名脱敏,靠的是让用户了解自己的数据如何被使用,告知用户保护自己的个人隐私,限制企业的数据收集。
参考
发布于 2023-09-08 23:36・IP 属地河南查看全文>>
段小草 - 7 个点赞 👍
先说观点,我不认同“大模型让隐私保护难上加难”这种言论。
给何院士准备稿子和材料的这位应该扣大分,实在是不严谨。
我没找到何院士演讲的完整视频,所以先用新闻问中短视频的素材,何院士这部分的表述是:
我们现在很擅长于在各种社交媒体里面发帖子,我们有自己的个人网页,然后我们这个大模型呢,它在你不知不觉中间,收集了大量的数据。我们很高兴有大模型去做我们的助手,提升我们的工作安排,我们的爱好,包括我们各类的习惯,都被我们大模型学过去了。
ChatGPT屏幕上有个键,叫做数据控制键,要么继续跟我对话,要么允许我,把你对话中间用到的数据用在我以后训练过程中间。
当大模型收集到你个人足够多的数据,如果有个黑客提示大模型为你个人画像的话,它可以帮你写出本小说。
在某些西方投资公司里面,他们开始采取这种技术来评估他要投资的单位的人的所有信息。其实这个情况的发展呢是比我们想象的可怕得多。
如果我们把人工智能这种能力看成像孙悟空,那么对齐这个技术呢,就是唐僧口中的紧箍咒,我们的对齐技术控制人工智能不会任意的使用它的能力闯祸、胡作非为。首先,个人隐私保护越来越难这口锅完全不是大模型应该背的。在我国,个人信息有无数个环节可以被轻易的泄露出去,学校、公司要求填的各种统计个人信息的表格随意在公共群里传播,人脸、指纹等数据的采集,以及许多手机应用肆意读取用户私人数据和行为,这类现象很多人应该都见怪不怪了。要说泄露,我们的个人隐私数据早都满天飞了,到大模型那都不知道被转了几手了。总之,一些人(公司)要想拿到你的个人数据,有很多种手段,有没有大模型都一样。这是其一。
其二,何院士演讲中提到“我们现在很擅长于在各种社交媒体里面发帖子,我们有自己的个人网页,然后我们这个大模型呢,它在你不知不觉中间,收集了大量的数据。”
这句话的表达出来的意思是大模型会主动收集网络数据,从而可以获取到个人信息(比如提到的通过个人在社交平台发的贴子)。这就是我上面说稿子不严谨的地方,因为大模型自己并不会主动在网络上爬取信息,而是人类在爬取了或收集了数据之后再喂给大模型,在这样的训练过程中,大模型学习到了个人信息,具备了基于私人信息生成内容的能力,进而导致个人信息被进一步泄露或被不当使用。
对于像 ChatGPT 之类的聊天机器人产品也是同样的道理。收集和使用你的个人数据的是人类,而非大模型。
所以,与其关心大模型是不是让隐私保护更难,不如关心在生成式 AI 时代到来的情况下,泄露的个人数据会被拿去干什么(坏事),以及如何防范。个人觉得,最大的潜在危险是 AI 大模型根据个人信息生成的定制化内容会让人更加难以辨别,而这些生成内容一旦被传播或被用来诈骗,其危害和给人带来的困扰要比信息泄露本身大得多。比如前段时间有通过 AI 生成朋友的照片/视频对熟人进行诈骗的新闻。
我在很多回答中都表达过一个看法,就是不要神化人工智能,尽管现在像ChatGPT这样的AI能力很强大,但是也远没达到有自主意识和自主行为的程度。AI 说到底还只是一个工具,关键在于什么人掌握了它。
所以,我的观点还是在想尽办法约束 AI 之前,先管好那些肆意采集和滥用个人隐私的公司和人类吧,难道还有比人更会坑人的吗?


图源网络 发布于 2023-09-07 21:38・IP 属地江苏真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
卜寒兮 - 4 个点赞 👍
这个世界上没有永远保密的信息,但却有被滥用信息的问题,而隐私保护机制只不过是为社会治理滥用信息问题给创造时间条件罢了。
大模型的窃取数据问题根本不值一提,因为它的算力条件已经具备猜出机密信息的条件了,或者更直白地了说,真正的威胁是大模型自身,它有能力计算出隐私信息,而不用窃取。
然而,有一个很幸运的地方,就是信息本身是需要物理载体的,而信息映射的实体又是另一个物理实体,两个实体是没有办法保证永远同步的,换言之信息永远存在出错的可能性,转换到大模型计算上就是结果永远有可能出错,同时使用者永远无法识别对错。
现在来说大概率还不用担心有人利用大模型进行大规模窃密,因为它的应用原理非常复杂,而且效果观察机制的理论还没有,甚至也不知道是否有可能存在,所以即使有人在尝试也极大概率没有什么结果。
至于所谓利用“对齐”技术来进行隐私保护,实际也就是针对特定侵犯隐私行为进行识别,在训练数据上进行标识和清洗,然后得出一个用起来很不顺手的大模型而已。
说白了,“对齐”技术并不能提高任何隐私信息的保密性,而是阻止侵犯行为的发生概率,虽说这种方法有点粗糙,但还是有一定效果的。
真正要解决滥用隐私信息的风险,关键还是要研发出隐私信息的正确使用方法,让这些信息在使用的时候不会对本人造成伤害,就像我猜到你明天要出游,就准备好出租车来给你使用一样,使用隐私信息是能对大家都产生好处的,那泄漏也就泄漏了吧,没有人会在意。
信息加工不能光靠人想,还得靠专业的加工机制,得对加工与使用的结果进行质量把控,这样才能得到有效利用,但这么做的前提是要把信息加工与应用的机制实现自动化,这就是个非常复杂的社会工程了,不是靠小聪明能实现的。
发布于 2023-09-07 23:19・IP 属地广东真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
深空 - 0 个点赞 👍
查看全文>>
崔伟 - 0 个点赞 👍
查看全文>>
记录者 - 0 个点赞 👍
看现在的发展情况,就已经感受到了隐私保护的难度,目前上网的过程中,使用各种购物、社交平台,都或多或少的泄露了自己的一些数据,最明显的一点就是,你刚和一个朋友讨论完,最近需要买什么,喜欢什么,进入购物网站,他马上就给你推荐这个。在使用诸如chatgpt等平台时,我们和大模型的交互过程,也会被公司进行数据采集,用于大模型的更新迭代,所以在使用这些大模型时候,最好还是不要泄露自己的隐私数据了(o‿∩)
发布于 2023-09-08 11:10・IP 属地北京查看全文>>
阿布的足迹 - 0 个点赞 👍
首先,由于AI创作的本质是AI充分学习后的再创作,所以侵权几乎成为AI创作的原罪。简言之,在未有强有力监管体系存在之前,AI大模型的确会存在隐私保护方面的问题。
但这并不是AI独有的问题,所以,如果我们不能阻止有人利用AI去做危害人类的事情,那我们需要做的就是,大力支持有责任感的企业去使用AI为社会创作价值。比起动不动就按下所谓的“暂停键”,更应该投入精力的是平衡人工智能正在创造的巨大价值与现实的风险,而不是扼杀科技进步。
如何打开机器学习的黑箱,会是人工智能研究学者在未来一段时间里致力于解决的重要问题。



 发布于 2023-09-08 10:02・IP 属地江苏
发布于 2023-09-08 10:02・IP 属地江苏查看全文>>
VRPinea - 0 个点赞 👍
都不用上大模型,你以为我们现在用的手机电脑就很隐私了吗?
国外反对5G,宣扬侵犯隐私人权,你看大家还不是该用用,即便少数人不使用,也阻止不了科技向前的脚步,任何技术一旦发明出来,主要想大面积推广,肯定会在方方面面投入使用,你不用这个不代表没有其他的代替品渗入到生活
我们作为个体的小人物,历史的一粒沙,在历史的洪流面前做不到阻挡进程,所能做的无非就是尽量不在物联网上透露个人的隐私,只要不是特别有心人去扒去利用,还是能保护自身的。
有句话怎么讲的,防君子不防小人。
发布于 2023-09-11 14:20・IP 属地江苏查看全文>>
青山绿水

