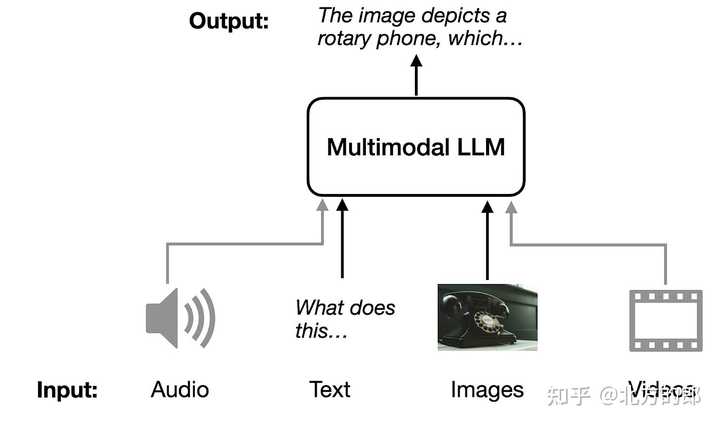
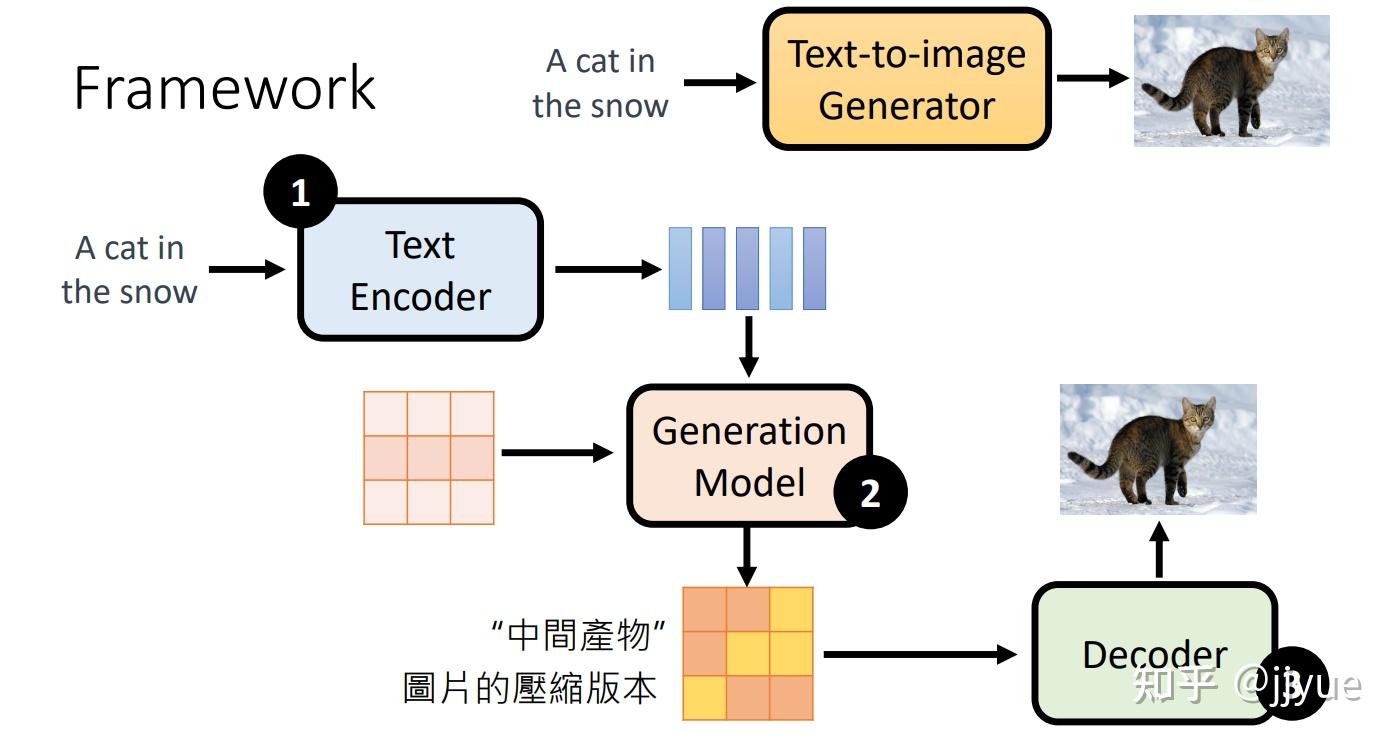
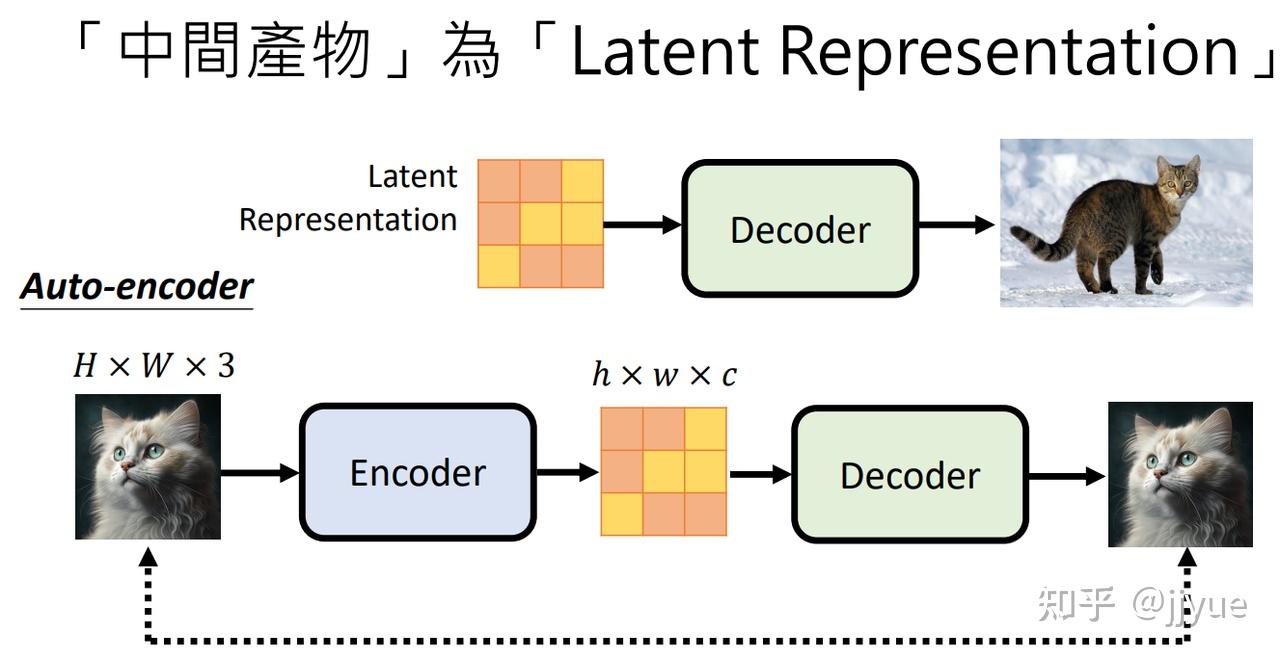
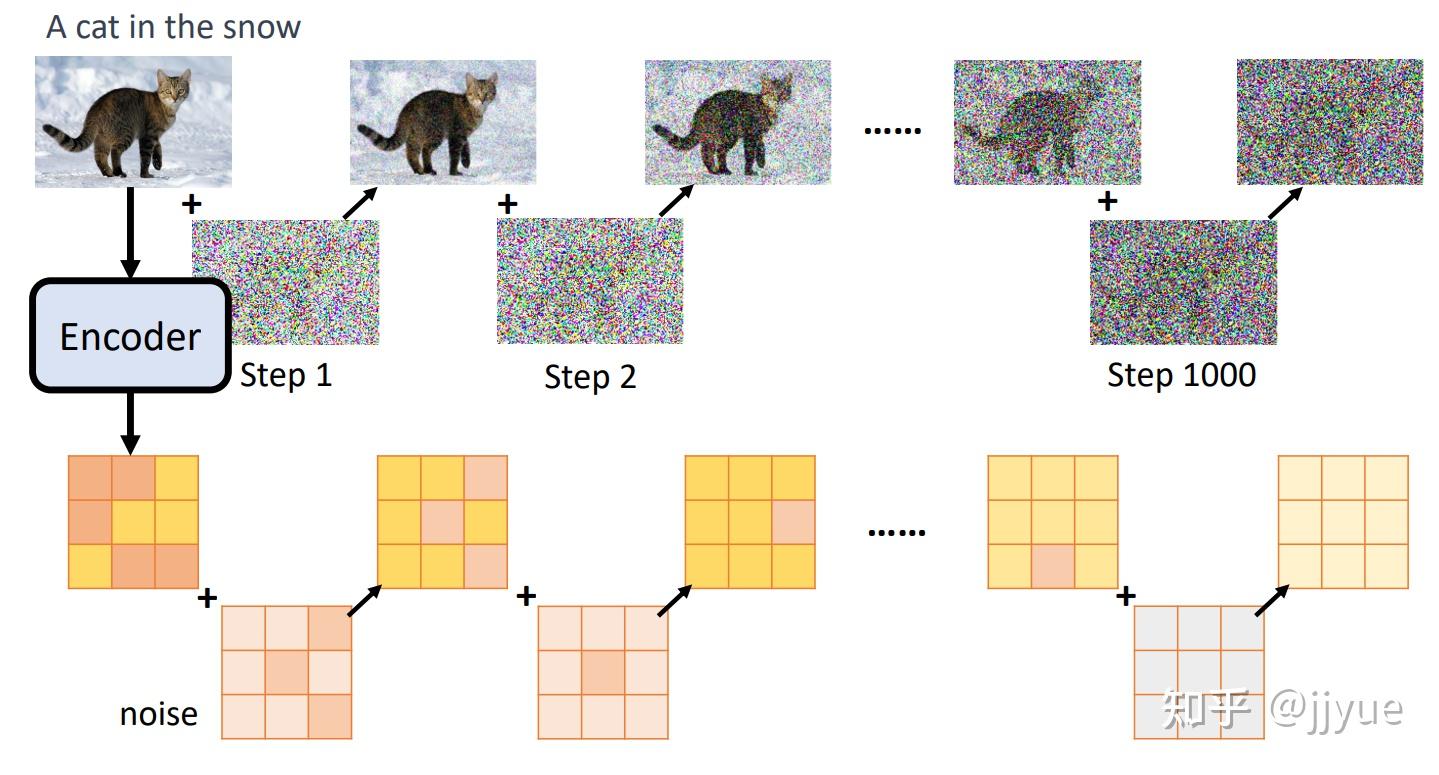
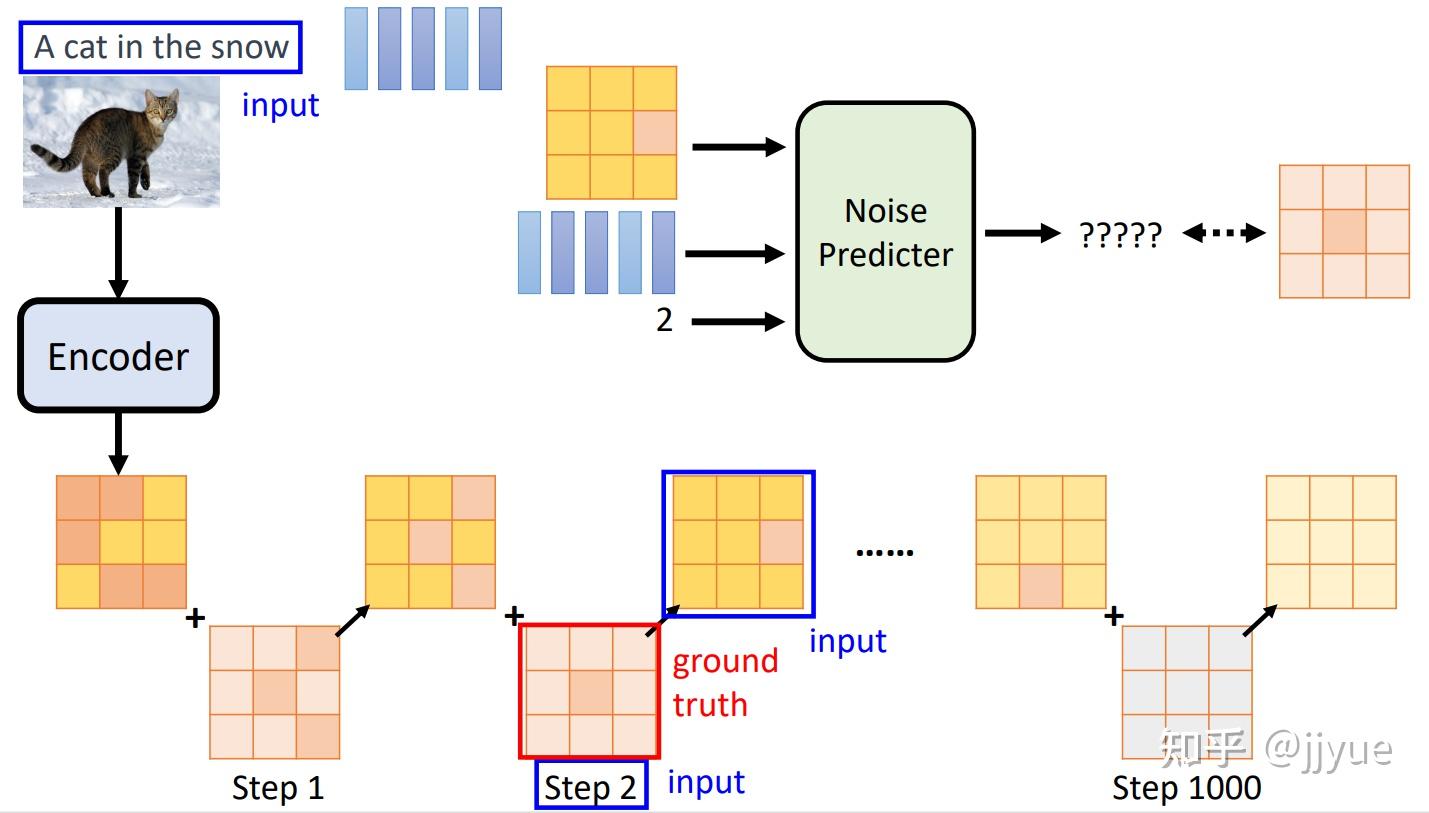
1.多模态希望解决什么问题
1.1.什么是模态?
根据美国哈佛商学院有关研究人员的分析资料表明,人的大脑每天通过五种感官在接受外部信息的比例分别为:味觉1%、触觉1.5%、嗅觉3.5%、听觉11%以及视觉83%。
人类通过多种感觉器官接触世界——我们看到物体,听到声音,感受纹理,闻到气味等等。一般而言,模态指的是某事发生或被体验的方式。大多数人将模态与感官模态联系在一起,这些模态代表了我们的主要交流和感知渠道,如视觉或触觉。因此,当一个研究问题或数据集包含多个这样的模态时,可以将其描述为多模态的。一般主要关注三种模态:自然语言(既可以是书面的也可以是口头的);视觉信号(通常用图像或视频表示);以及声音信号(编码声音和类声音信息,如韵律和语音表达)。
1.2.多模态算法为什么比较难?
多模态机器学习(Multimodal Machine Learning)研究包含不同模态数据的机器学习问题。由于不同模态往往来自不同的传感器,数据的形成方式和内部结构有很大的区别,例如,图像是自然界存在的连续空间,而文本是依赖人类知识、语法规则组织的离散空间。多模态数据的异质性(heterogeneity)对如何学习多模态间关联性和互补性提出挑战。
为了使人工智能算法在理解我们周围的世界方面取得进展,它需要能够解释和推理多模态信息。多模态机器学习旨在构建能够处理和关联多个模态信息的模型。从早期对音频-视觉语音识别的研究到最近对语言和视觉模型的兴趣激增,多模态机器学习是一个充满活力的跨学科领域,具有日益重要和非凡潜力。
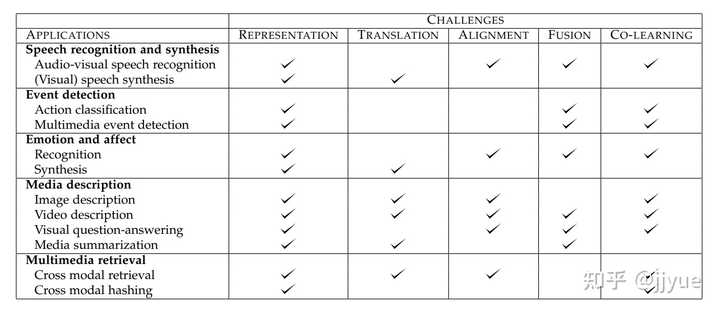
2.多模态场景的主要应用
2.1.从历史演进角度看
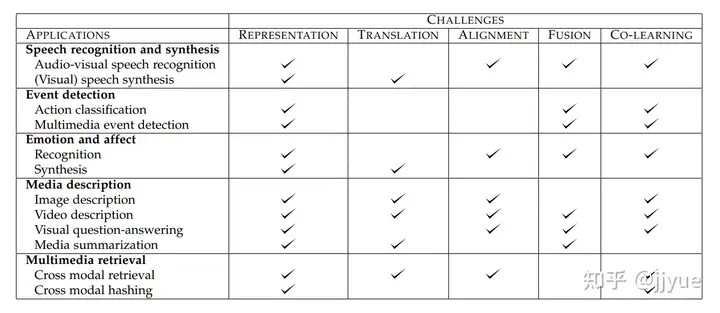
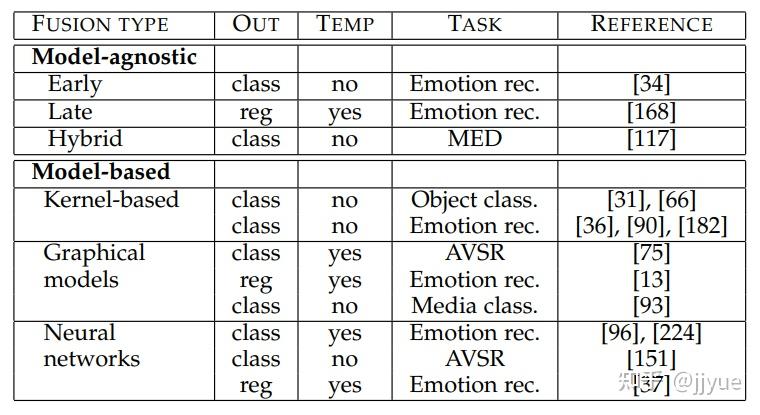
表1 多模态主要应用领域及核心技术挑战
多模态早期应用之一视听语音识别(audio-visual speech recognition-AVSR )。这类研究受到了McGurk Effect的影响。视觉与声音会相互影响,这个心理学发现启发了研究者去探索如何使用视觉辅助声音识别。
McGurk效应是一种视听错觉现象,最早由研究人员Harry McGurk和John MacDonald在1976年描述。这个效应涉及到一个人同时看着一个人的嘴唇在说一个音节,同时听到另一个音节的声音。结果是观察者会产生一个第三个音节的错觉,该音节既不是实际看到的,也不是实际听到的。
例如,当一个人看到一个人的嘴唇在说"ga"(/ga/)的同时,听到的声音是"ba"(/ba/)时,观察者可能会产生一个错误的听觉体验,感觉到了"da"(/da/)。
随着多媒体技术发展,多媒体内容索引和检索的需要变得越来越重要。而早期,对这些多媒体视频进行索引和搜索的方法是基于关键词的,但在尝试直接搜索视觉和多模态内容时,出现了新的研究问题。这导致了多媒体内容分析领域的新研究课题,如自动镜头边界检测和视频摘要。这些研究项目得到了美国国家标准与技术研究所(NIST)的TrecVid计划的支持,该计划推出了许多高质量的数据集,包括从2011年开始的多媒体事件检测(MED)任务。
TrecVid计划是由美国国家标准与技术研究所(NIST)发起的一个国际性研究评估活动,旨在推动视频信息检索技术的发展。TrecVid代表“Text REtrieval Conference Video”, 即“文本检索会议视频”。该计划提供了一个平台,让研究人员和实验室可以参与多媒体信息检索、视频分析和相关领域的评估任务。
TrecVid计划每年都会发布一系列任务,要求参与者开展相关的研究工作,例如视频内容分类、目标检测、事件检测等。参与者需要提交他们的算法和系统,并通过一系列评估指标来评估性能。
-
应用3:社交活动中的多模态行为理解-事件检测和情感识别
通过自动面部检测、面部关键点检测和面部表情识别等技术的强大进展,完成情感识别和情感计算任务。AVEC挑战随后每年举办一次,后期的实例包括自动评估抑郁症和焦虑症等医疗应用。D’Mello等人发表了一篇关于多模态情感识别最近进展的优秀综述[2]。
数据集:
- 在这个领域收集的第一个重要数据集之一是AMI会议语料库,其中包含了100多小时的会议视频录音,全部进行了全面的转录和注释。
- 另一个重要的数据集是SEMAINE语料库,它允许研究发言者和听众之间的人际动态关系。该数据集成为了2011年举办的第一个音频-视觉情感挑战(AVEC)的基础。
-
应用4:多媒体内容生成
语言和视觉为重点的新型多模态应用类别:多媒体内容描述。其中一个最具代表性的应用是图像描述,其任务是生成输入图像的文本描述。这受到了这类系统能够帮助视障人士在日常任务中的能力的启发。媒体描述面临的主要挑战之一是评估:如何评估所预测描述的质量。最近提出了视觉问答(VQA)任务来解决一些评估挑战[3],其目标是回答关于图像的具体问题。
2.2.从模态视角进行分类
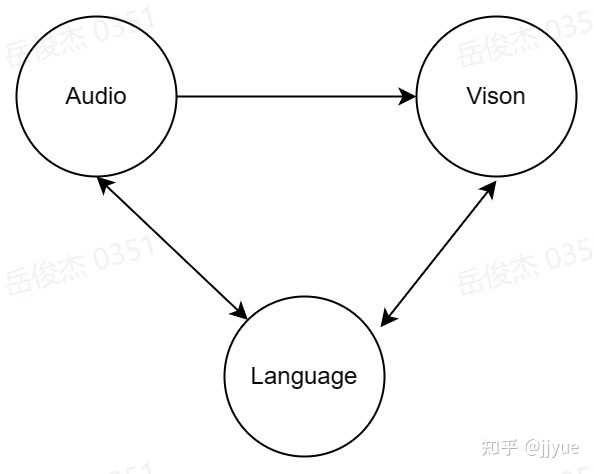
- 2.2.1. 跨模态定位和关系识别任务
-
Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
-
Temporal Language Localization: 给定一个视频与一段文本,定位到文本所描述的动作(预测起止时间)。
-
Video Summarization from Text Query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频。
-
Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指示的物体。
-
Video-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
-
Object Tracking from Natural Language Query: 给定一段视频和一些文本,追踪视频中文本所描述的对象。
-
Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑。
- 2.2.2. 跨模态生成任务
- Language-Audio
- Vision-Audio
-
Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
-
Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
-
Image Generation from Audio: 给定声音,生成与其相关的图像。
-
Speech-conditioned Face generation:给定一段话,生成说话人的视频。
-
Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
- Vision-Language
-
Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<-->文本的相互检索。
-
Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
-
Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
-
Image/Video Generation from Text:给定文本,生成相应的图像或视频。
-
Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
-
Vision-and-Language Navigation(视觉-语言导航): 给定自然语言进行指导,使得智能体根据视觉传感器导航到特定的目标。
-
Multimodal Dialog(多模态对话): 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
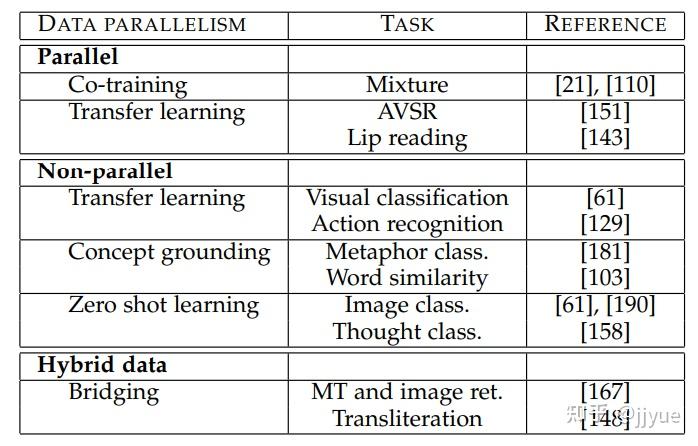
3.多模态主要技术难点[1]
3.1.表征
如何挖掘模态间的互补性或独立性以表征多模态数据。
表征学习是多模态任务的基础,其中包含了一些开放性问题,例如:如何结合来源不同的异质数据,如何处理不同模态的不同噪声等级,测试样本的某种模态缺失怎么办。
- 3.1.1. 原理介绍
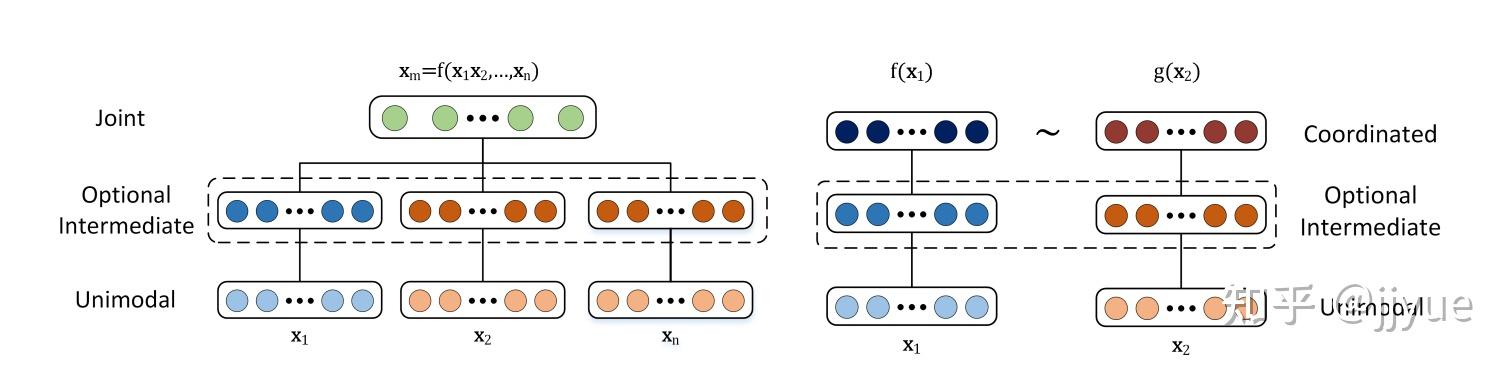
现有多模态表征学习可分为两类:Joint(联合,也称为单塔结构)和Coordinated(协作,双塔结构)。
-
Joint结构注重捕捉多模态的互补性,融合多个输入模态 x_1, x_2 ,获得多模态表征 x_m = f(x_1, x_2) ,进而使用 x_m 完成某种预测任务。网络优化目标是某种预测任务的性能。
-
Coordinated结构并不寻求融合而是建模多种模态数据间的相关性,它将多个(通常是两个)模态映射到协作空间,表示为: f(x_1)~g(x_2) ,其中~表示一种协作关系。网络的优化目标是这种协作关系(通常是相似性,即最小化cosine距离等度量)。
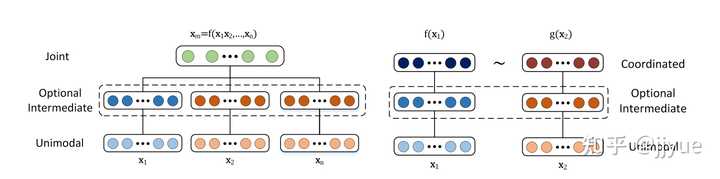 图1. Joint representation(单塔)与Coordinated representation(双塔)
图1. Joint representation(单塔)与Coordinated representation(双塔)
在测试阶段,由于Coordinated结构保留了两个模态的表示空间,它适合仅有一个模态作为输入的应用,如跨模态检索,翻译,grounding和zero-shot learning。但是Joint结构学习到的 x_m 只适用于多模态作为输入,例如视听语音识别,VQA,情感识别等。
-
3.1.2.讨论
相较于多模态,基于单模态的表征学习已被广泛且深入地研究。在Transformer出现之前,不同模态所适用的最佳表征学习模型不同,例如,CNN广泛适用CV领域,LSTM占领NLP领域。较多的多模态工作仍旧局限在使用N个异质网络单独提取N个模态的特征,之后采用Joint或Coordinated结构进行训练。不过这种思路在很快改变,随着越来越多工作证实Transformer在CV和NLP以及Speech领域都可以获得极佳的性能,仅使用Transformer统一多个模态、甚至多个跨模态任务成为可能。基于Transformer的多模态预训练模型在2019年后喷涌而出,如LXMERT[5], Oscar[6], UNITER[7]属于Joint结构,CLIP[8], BriVL[9] 属于Coordinated结构。
-
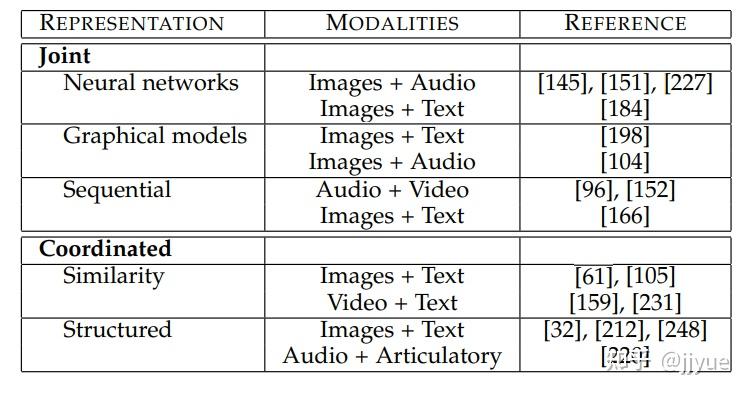
3.1.3. 相关算法及参考文献
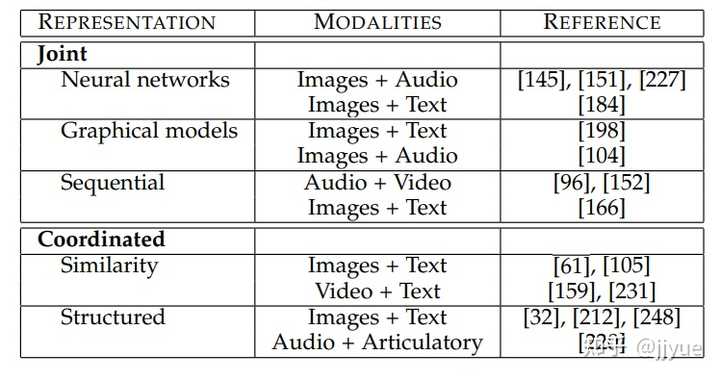 注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号3.2.翻译
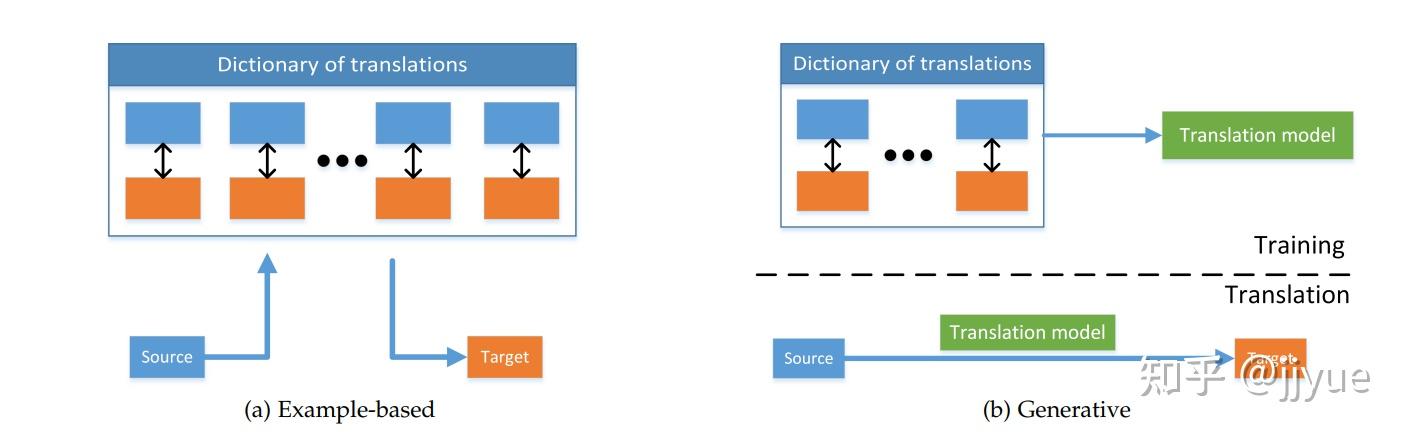
跨模态翻译的目的是学习如何将源模态映射(map)到目标模态。例如:输入一张图像,我们希望生成一句话描述它,或者输入一句话,我们生成与之匹配的一张图。主流方法分为两类:
-
举例法(example-based)。模版法的特征是借助于词典(dictionary)进行翻译,词典一般指训练集中的数据对 \{(x_1,y_1),..., (x_N,y_N)\} 。给定测试样本 \hat{x} ,模版法直接检索在词典中找到最匹配的翻译结果 y_i ,并将其作为最终输出。此处的检索可分为单模态检索或跨模态检索。单模态检索首先找到与 \hat{x} 最相似的 x_i ,然后获得 x_i 对应的 y_i 。而多模态检索直接在 \{y_1,...,y_N\} 集合中检索到与 \hat{x} 最相似的 y_i ,性能通常优于单模态检索。为进一步增强检索结果的准确性,可选择top-K的检索结果 \{y_{i_1},...,y_{i_k} ,再融合K个结果作为最终输出。
-
生成式模型(generative)。抛弃词典,直接生成目标模态的数据。分为三个子类别:
-
基于语法模版,即人为设定多个针对目标模态的语法模版,将模型的预测结果插入模版中作为翻译结果。以图像描述为例,模版定义为 who did what to whom in a place ,其中有四个待替换的插槽。通过不同类型的目标/属性/场景检测器可以获得who, what, whom, place等具体单词,进而完成翻译。
-
编码-解码器(encoder-decoder)。首先将源模态的数据编码为隐特征 z ,后续被解码器用于生成目标模态。以图像描述为例,编码器(一般为CNN+spatial pooling)将图像编码为一个或多个特征向量,进而输入到RNN中以自回归的方式生成单词序列。
-
连续性生成(continuous generation)。它针对源模态与目标模态都为流数据且在时间上严格对齐的任务。以文本合成语音为例,它与图像描述不同,语音数据与文本数据在时间上严格对齐。WaveNet采用了CNN并行预测+CTC loss解决该类问题。当然,编码-解码器理论上也可完成该任务,但需处理数据对齐问题。
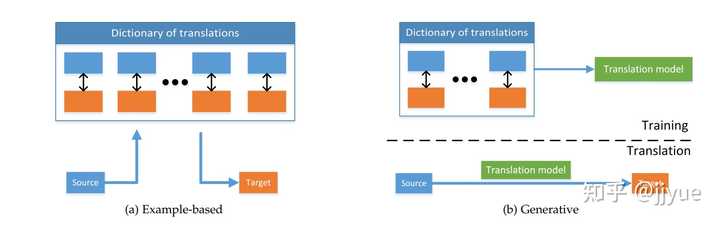 图2 用于跨模态翻译的举例法(左)与生成式模式(右)
图2 用于跨模态翻译的举例法(左)与生成式模式(右)
-
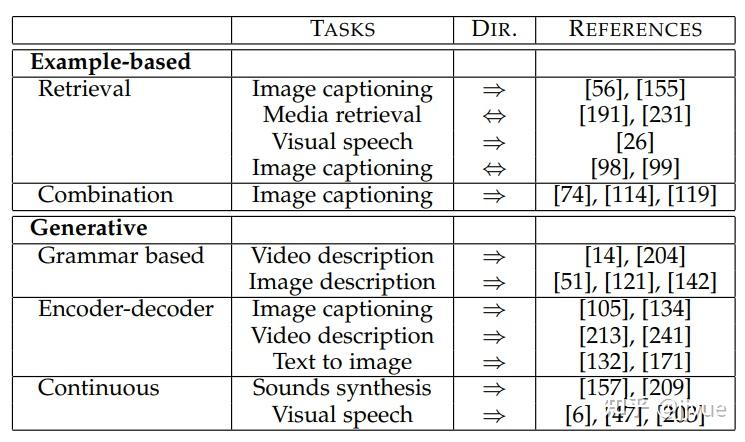
3.2.2. 多类方法优缺点分析 举例法面临两个问题:
- 一是需要维护一个大词典,且每次翻译都需要进行全局检索,使得模型巨大且推理速度慢(hashing可缓解此问题)。
- 二是此类方法较机械,仅仅是复制(或简单修改)训练集的数据,无法生成准确且新奇的翻译结果。
生成式方法可以生成更为灵活、相关性更强、性能更优的翻译结果。其中,基于语法模版的方式受限于模版的多样性,生成的语句多样性有限,且不是端到端训练。现今,编码-解码器与连续性生成是主流方案,它们一般基于深度网络且端到端训练。
评估语音识别模型的性能是容易的,因为正确的输出有且只有一种。但对于大多数翻译任务来说(视觉<-->文本、文本-->语音等),模态间的映射是一对多的,输出存在多个正确结果。例如图像描述,不同的人会使用不同的语句对同一幅图像进行描述,因此模型的评估常常是主观的。人工评价是最理想的评估,但是耗时耗钱,且需要多样化打分人群的背景以避免偏见。自动化指标是视觉描述领域常用的替代方法,包括BLEU,Meteor,CIDEr,ROUGE等,但它们被证实与人的评价相关性较弱。基于检索的评估和弱化任务(例如:将图像描述中一对多映射简化为VQA中一对一的映射)也是解决评估困境的手段。
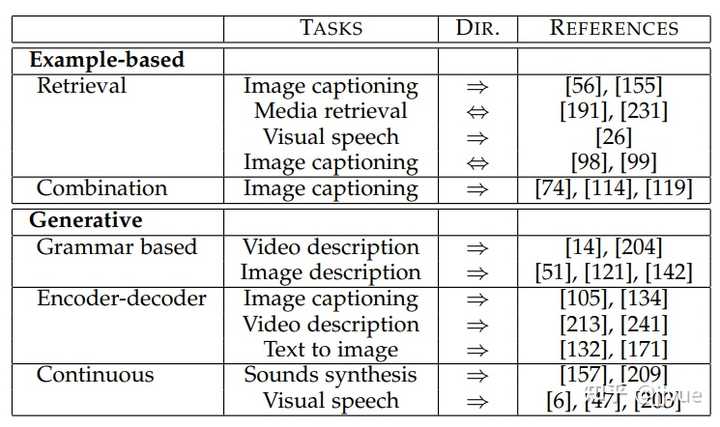 注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号3.3.对齐
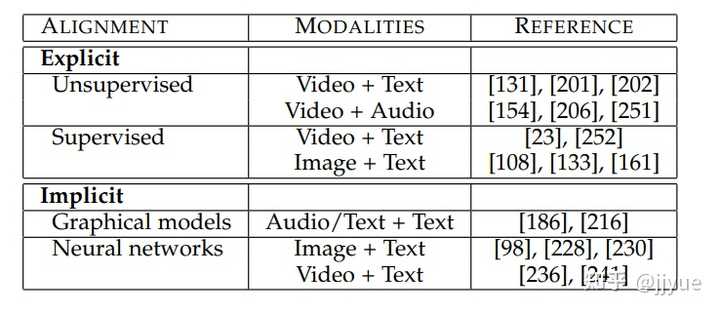
跨模态对齐目的是挖掘多模态数据的子元素之间的关联性,例如visual grounding任务。在学习表征或翻译时也可能隐式地学习对齐。
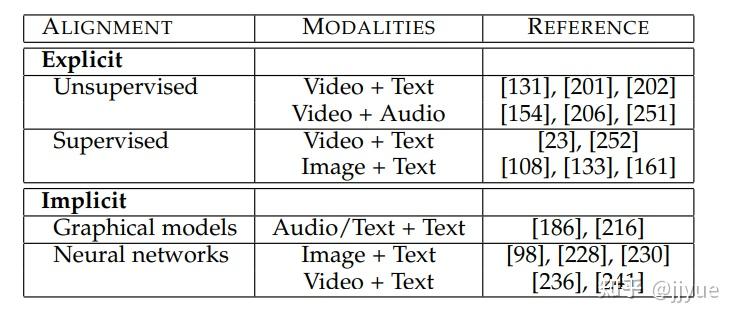
对齐广泛应用于多模态任务中,具体的应用方式包括显式对齐和隐式对齐。
-
显式对齐。如果一个模型的优化目标是最大化多模态数据的子元素的对齐程度,则称为显示对齐。包括无监督和有监督方法。无监督对齐:给定两个模态的数据作为输入,希望模型实现子元素的对齐,但是训练数据没有“对齐结果”的标注,模型需要同时学习相似度度量和对齐方式。而有监督方法存在标注,可训练模型学习相似度度量。Visual grounding便是有监督对齐的任务。
-
隐式对齐。如果模型的最终优化目标不是对齐任务,对齐过程仅仅是某个中间(或隐式)步骤,则称为隐式对齐。早期基于概率图模型(如HMM)的方法被应用于文本翻译和音素识别中,通过对齐源语言和目的语言的单词或声音信号与音素。但是他们都需要手动构建模态间的映射。最受欢迎的方式是基于注意力机制的对齐,我们对两种模态的子元素间求取注意力权重矩阵,可视为隐式地衡量跨模态子元素间的关联程度。在图像描述,这种注意力被用来判断生成某个单词时需要关注图像中的哪些区域。在视觉问答中,注意力权重被用来定位问题所指的图像区域。很多基于深度学习的跨模态任务都可以找到跨模态注意力的影子。
对齐可以作为一个单独的任务,也可以作为其他任务的隐式特征增强手段。多模态对齐可挖掘子元素间的细粒度交互,同时有可解释性,被广泛应用。
但多模态对齐面临如下挑战:
- 仅有少量数据集包含显式的对齐标注;
- 跨模态度量难以设计;
-
可能存在多种对齐,可能存在某些元素无法在其他模态中找到。
 注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号3.4.融合
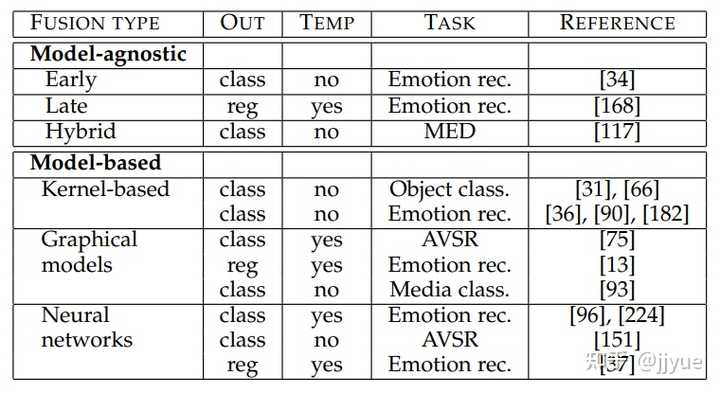
融合两个模态的数据,用来进行某种预测。例如:Visual Question Answering需融合图像和问题来预测答案;Audio-visual speech recognition需融合声音和视频信息用以识别说话内容。若测试场景下的输入数据包含多个模态,那么必须面对多模态特征融合。
多模态融合策略,主要分为两类:模型无关和基于模型的融合
前融合:指在模型的浅层(或输入层)将多个模态的特征拼接起来。
后融合:独立训练多个模型,在预测层(最后一层)进行融合。
混合融合:同时结合前融合和后融合,以及在模型中间层进行特征交互。
多核学习(Multiple Kernel Learning)是SVM的扩展。SVM通过核函数将输入特征映射到高维空间,使线性不可分问题在高维空间可分。在处理多个输入时,多核处理多个模态特征,使得每个模态都找到其最佳核函数;
基于概率图模型利用隐马尔可夫模型或贝叶斯网络建模数据的联合概率分布(生成式)或条件概率(判别式)。基于神经网络的融合。使用LSTM、卷积层、注意力层、门机制、双线性融合等设计序列数据或图像数据的复杂交互。
多模态融合是依赖于任务和数据的,现有工作中常常是多种融合手段的堆积,并未真正统一的理论支撑。最近,神经网络已成为处理多模态融合的一种非常流行的方式,然而图形模型和多核学习仍然被使用,特别是在训练数据有限或模型可解释性很重要的任务中。
当然,多模态融合仍存在的挑战:
- 不同模态的序列信息可能没有对齐;
- 信号间的关联可能只是补充(仅提高鲁棒性而无法增大信息量)而不是互补;
-
不同数据可能存在不同程度的噪声。
- 3.4.3.相关算法及参考文献
 注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号3.5.协同学习(co-learning)
模态间的知识迁移。使用辅助模态训练的网络可以帮助该模态的学习,尤其是该模态数据量较小的情况下。
之所以称为"协同学习",是因为,辅助模态仅在模型训练期间使用,而在测试时不使用。
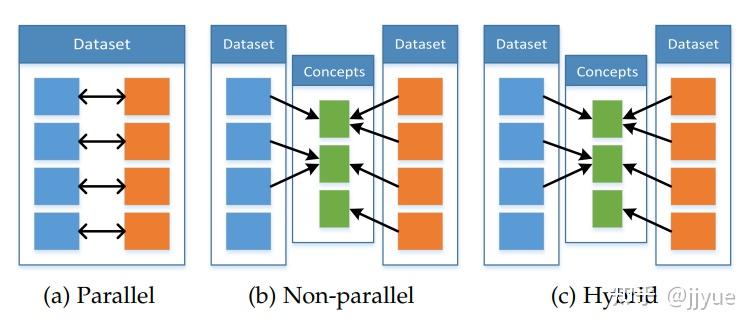
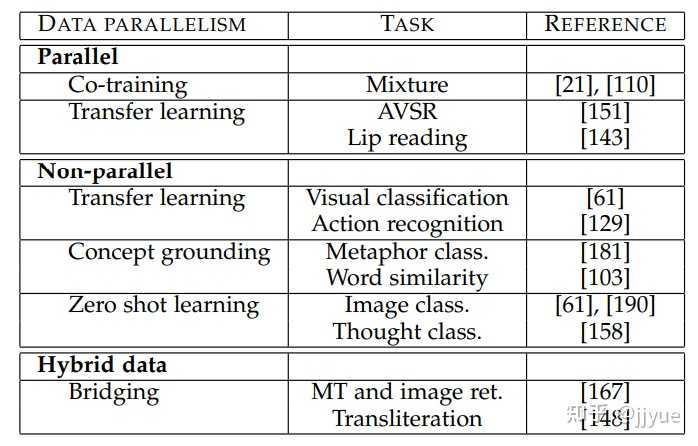
我们根据它们的训练资源,将协同学习方法分为三类:并行、非并行和混合。
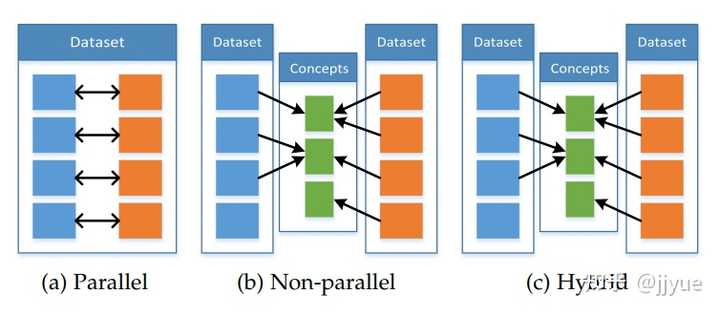 图3 协同学习中数据并行类型
图3 协同学习中数据并行类型
并行数据方法需要训练数据集,其中来自一个模态的观察直接与来自其他模态的观察相关联。换句话说,当多模态观察来自相同的实例时,比如在一个音视频语音数据集中,视频和语音样本来自同一说话者。
非并行数据方法不需要不同模态观察之间的直接链接。这些方法通常通过在类别方面的重叠来实现协同学习。例如,在零样本学习中,常规的视觉对象识别数据集可以通过扩展为包括来自维基百科的第二个纯文本数据集,以提高视觉对象识别的泛化性能。
在混合数据设置中,通过共享模态或数据集来连接模态。
多模态协同学习允许一种模态影响另一种模态的训练,利用跨模态的互补信息。值得注意的是,协同学习是与任务无关的,可以用于创建更好的融合、翻译和对齐模型。这一挑战可以通过诸如协同训练、多模态表示学习、概念接地和零样本学习(ZSL)等算法来解决,并已在视觉分类、动作识别、视听语音识别和语义相似度估计等领域得到广泛应用。
 注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
注:上述表格中的参考文献为本参考文献[1]的附属参考文献编号
4.1. Image-to-Text生成模型
目前GPT-4及GPT-4V(ersion)的多模态实现细节没有公布,但根据微软研究人员Chunyuan Li在2023年6月的CVPR会议的Tutorial(PPT:Large Multimodal Models Towards Building and Surpassing Multimodal GPT-4,整理论文:Large Multimodal Models: Notes on CVPR 2023 Tutorial),透露出一些GPT-4可能的实现思路(vision与language两模态任务)
2023年9月25日,多模态GPT-4V(Vision)发布!GPT-4V允许用户输入图像并结合文本prompt进行输出。
微软对GPT-4v的案例测试效果
2023年10月11号,微软就公布了一份长达166页的报告,定性地探讨了GPT-4V的功能和使用情况。
多模态模型的通用性必然要求系统能够处理不同输入模态的任意组合。GPT-4V 在理解和处理任意混合的输入图像、文本、场景文本和视觉指针方面表现出了前所未有的能力。他们还证明,GPT-4V 能够很好地支持在 LLM 中观察到的指令跟随、思维链、上下文小样本学习等技术。
- GPT-4V 在不同领域和任务中表现出的质量和通用性如何?
为了了解 GPT-4V 的能力,作者对涵盖广泛领域和任务的查询进行了采样,包括开放世界视觉理解、视觉描述、多模态知识、常识、场景文本理解、文档推理、编码、时间推理、抽象推理、情感理解等。GPT-4V 在许多实验领域都表现出了令人印象深刻的人类水平的能力。
GPT-4V 能够很好地理解像素空间编辑,例如在输入图像上绘制的视觉指针和场景文本。受这种能力的启发,研究者讨论了“visual referring prompting”(视觉参考提示),它可以直接编辑输入图像以指示感兴趣的任务。视觉参考提示可与其他图像和文本提示无缝结合使用,为教学和示例演示提供了一个细致入微的界面。
4.2.Text-to-Image生成模型
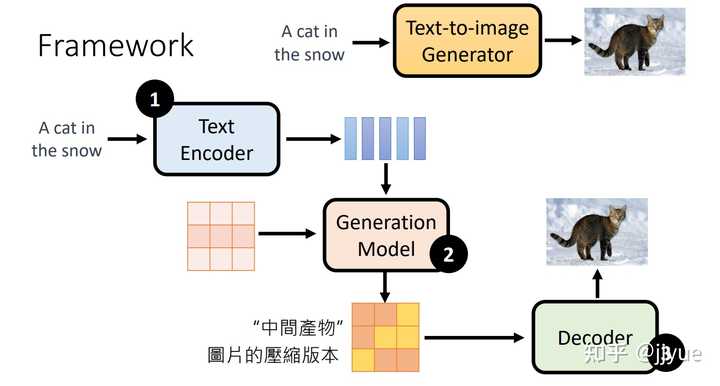
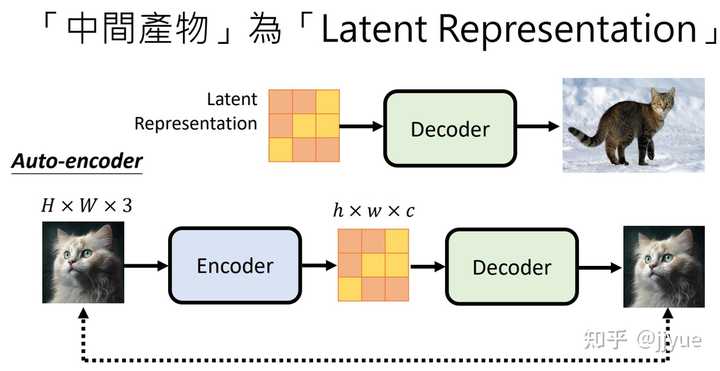
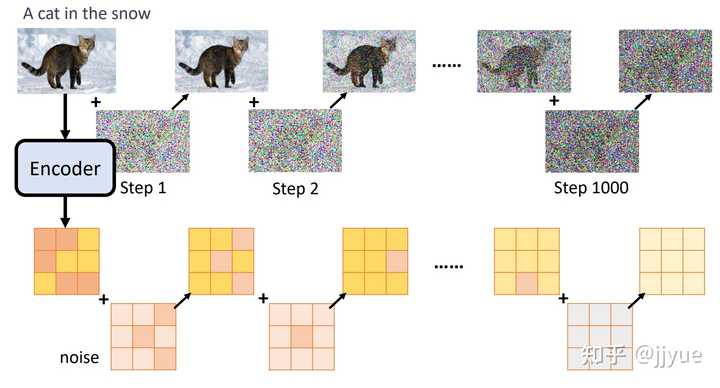
任一文本表示模型,例如GPT、Bert等。
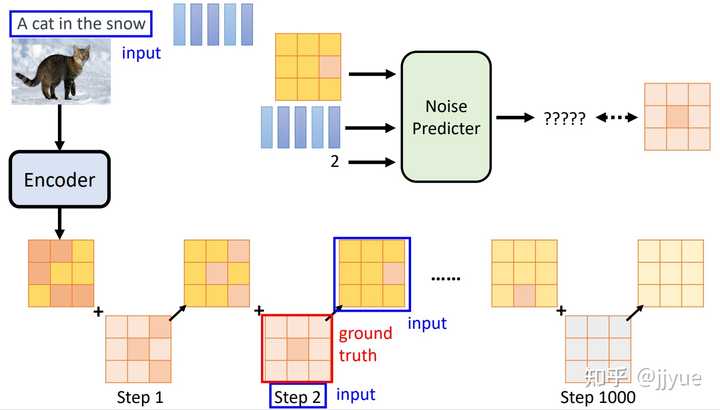
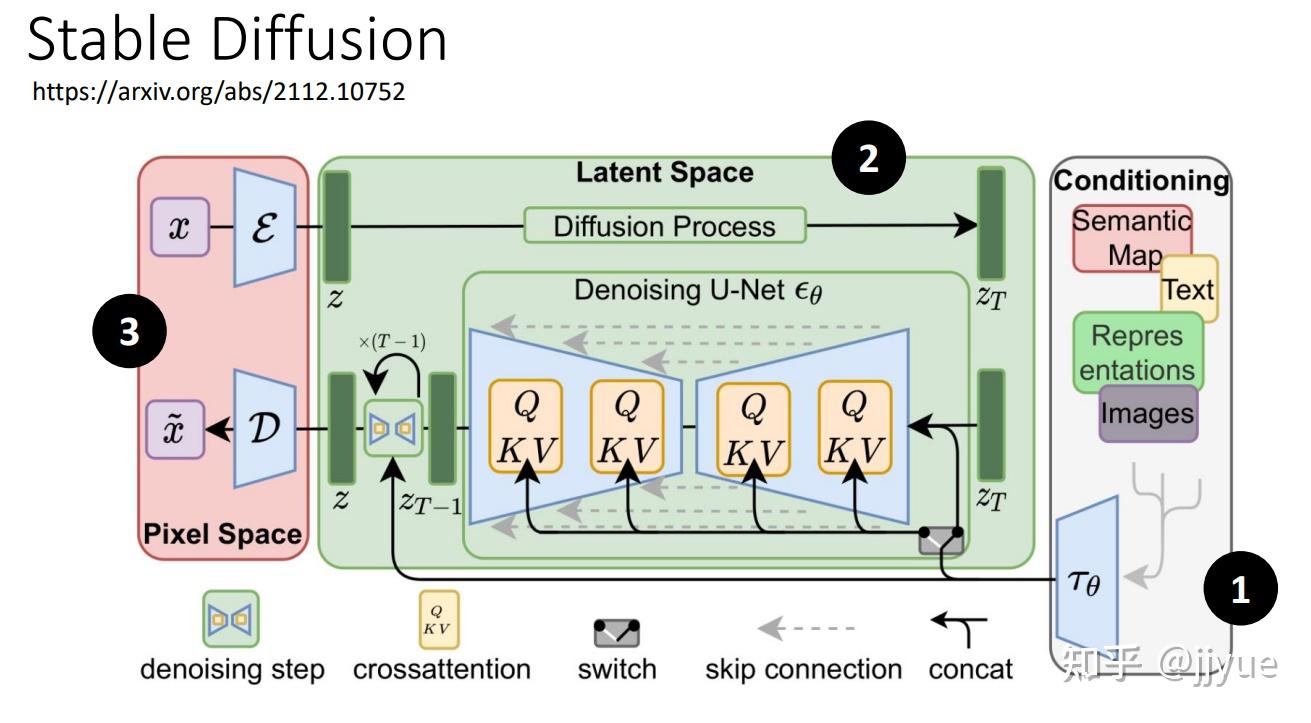
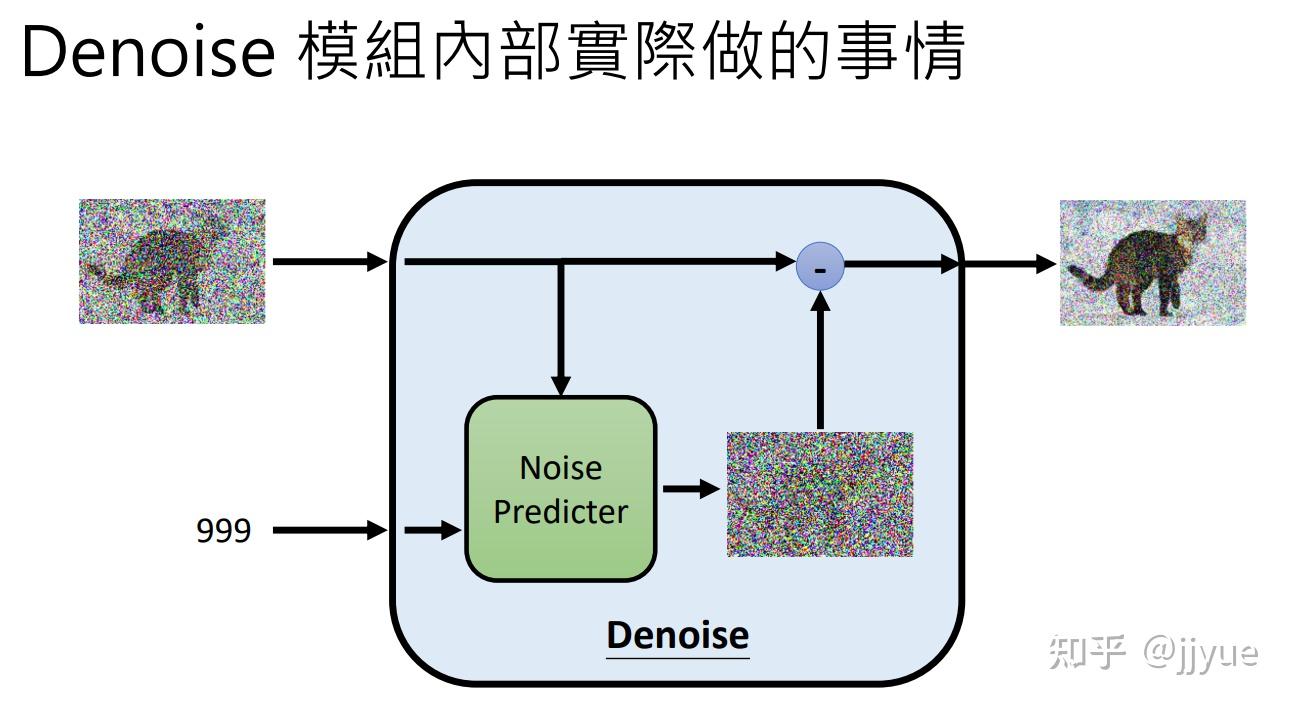
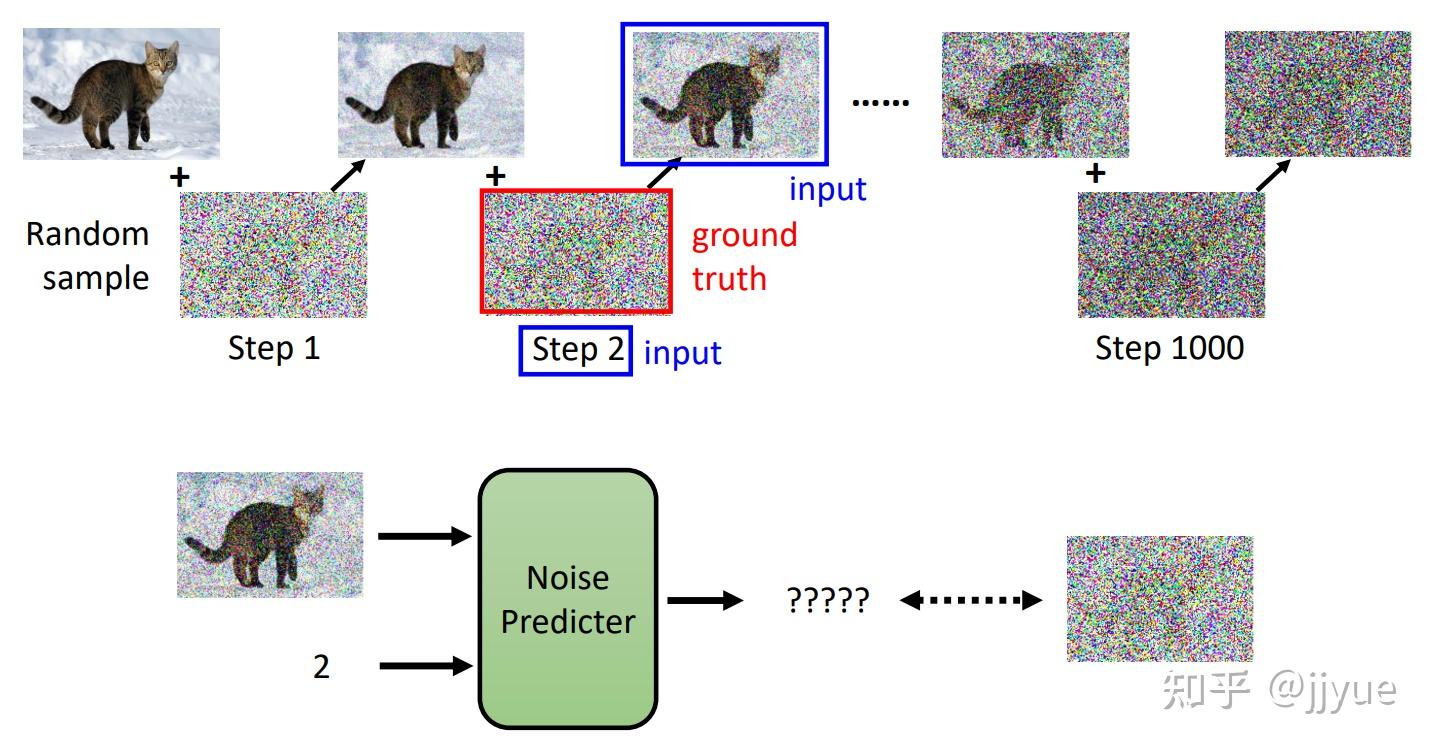
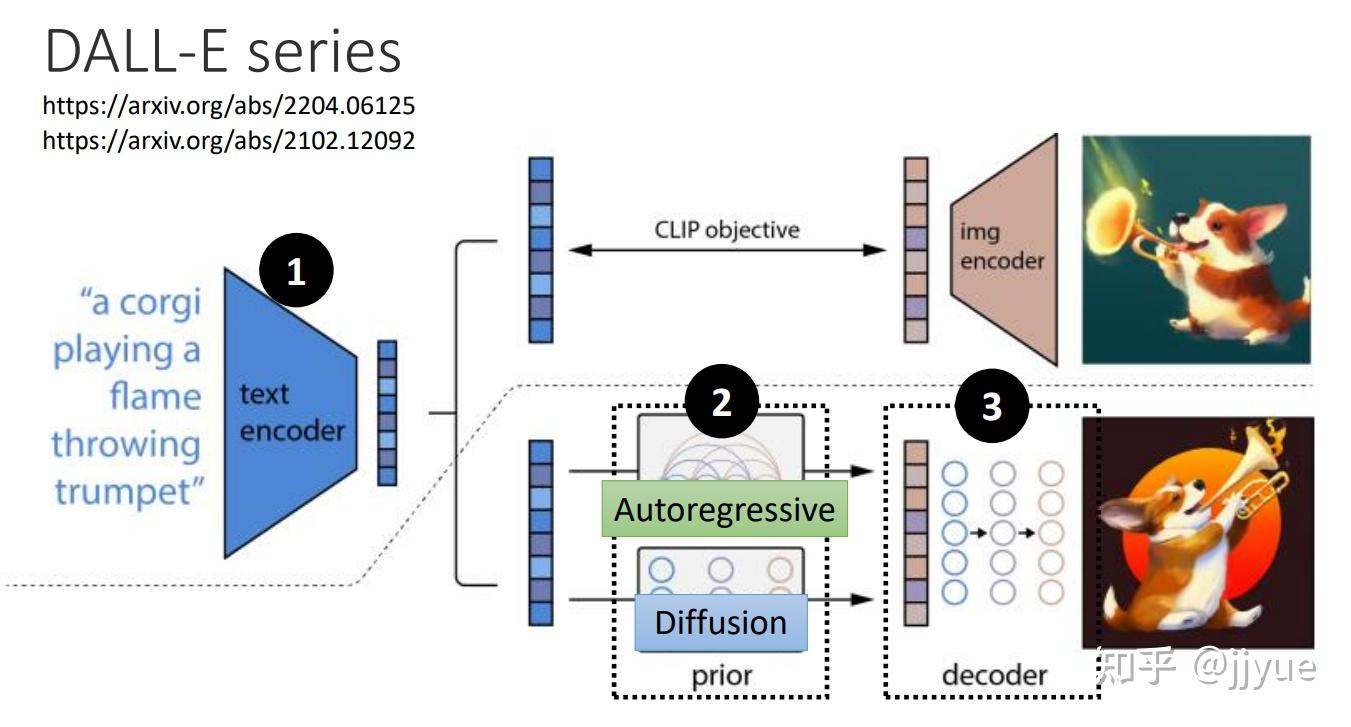
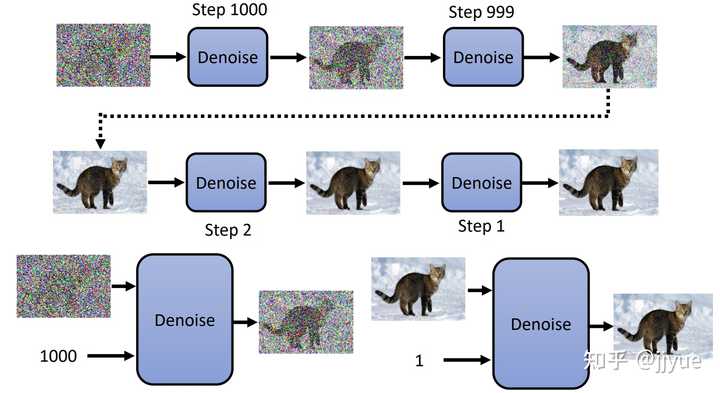
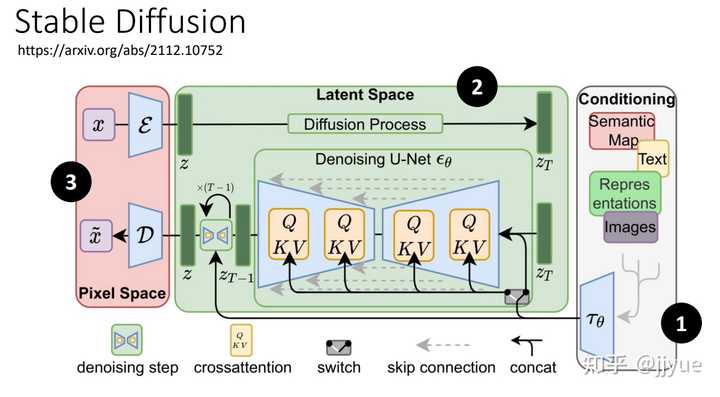
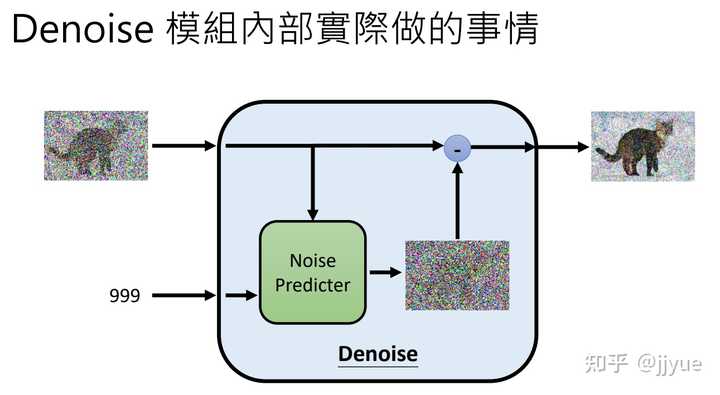
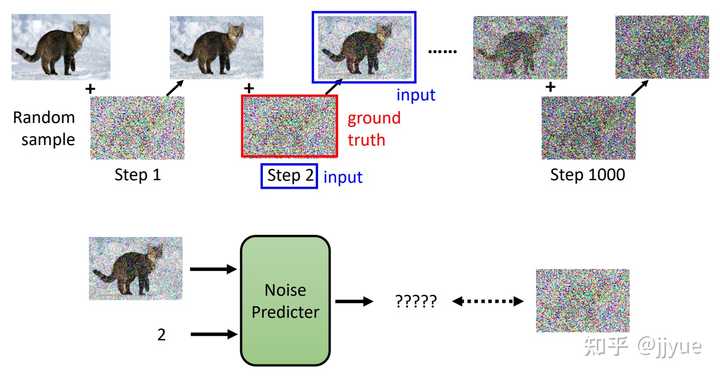
Stable Diffusion是stability.ai开源的图像生成模型,可以说Stable Diffusion的发布将AI图像生成提高到了全新高度,其效果和影响不亚于Open AI发布ChatGPT
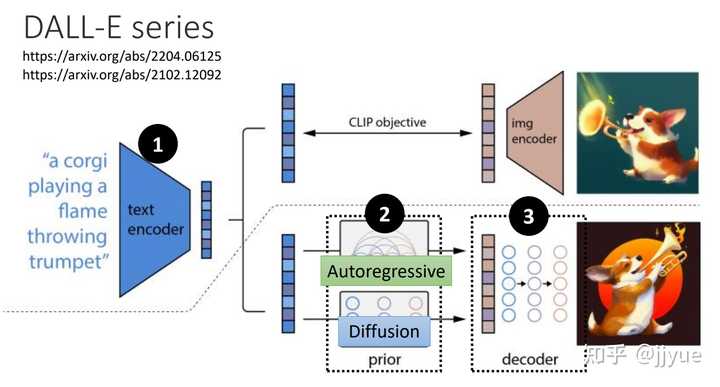
Midjourney也是一款由人工智能驱动的工具,其能够根据用户的提示生成图像。MidJourney善于适应实际的艺术风格,创造出用户想要的任何效果组合的图像。它擅长环境效果,特别是幻想和科幻场景,看起来就像游戏的艺术效果。
-
4.2.4.DALL·E, Stable Diffusion 和 Midjourney之间的比较
-
DALL-E 使用数以百万计的图片数据进行训练,其输出结果更加成熟,非常适合企业使用。当有两个以上的人物出现时,DALL-E 2产生的图像要比Midjourney或Stable Diffusion好得多。
-
Midjourney则是一个以其艺术风格闻名的工具。Midjourney使用其Discord机器人来发送以及接收对AI服务器的请求,几乎所有的事情都发生在Discord上。由此产生的图像很少看起来像照片,它似乎更像一幅画。
-
Stable Diffusion 是一个开源的模型,人人都可以使用。它对当代艺术图像有比较好的理解,可以产生充满细节的艺术作品。然而它需要对复杂的prompt进行解释。Stable Diffusion比较适合生成复杂的、有创意的插图。但在创作一般的图像时就显得存在些许不足。
5.多模态开源工具
5.1. Image-to-Text开源工具
5.2.Text-to-Image开源工具
6.参考文献
[1] Tadas Baltrušaitis, Chaitanya Ahuja, Louis-Philippe Morency, Multimodal Machine Learning: A Survey and Taxonomy, 2017
[2] S. K. D’mello and J. Kory, “A Review and Meta-Analysis of Multimodal Affect Detection Systems,” ACM Computing Surveys, 2015.
[3]S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. Lawrence Zitnick, and D. Parikh, “VQA: Visual question answering,” in ICCV, 2015
[4]"TRECVID Multimedia Event Detection 2011 Evaluation," https://www.nist.gov/multimodal-information-group/ trecvid-multimedia-event-detection-2011-evaluation, accessed: 2017-01-21.
[5] LXMERT: Learning Cross-Modality Encoder Representations from Transformers, EMNLP 2019.
[6] Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks, ECCV 2020.
[7] UNITER: UNiversal Image-TExt Representation Learning, ECCV 2020. [8] Learning Transferable Visual Models From Natural Language Supervision, Arxiv 2021.
[9] WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training, Arxiv 2021.
[10]Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
[11]Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.
[12]DiffusionModel _PDDM_1.pdf
[13]DiffusionModel _PDDM_2.pdf
[14]DiffusionModel _数学原理.pdf
[15]Understanding Diffusion Models A Unified Perspective.pdf
[16]OpenAI第一届DevDay主题演讲-SamAltman
[17]https://www.zhihu.com/people/jjyue-jd