
实话说,在开源的模式下,当前大模型技术领域普遍缺乏显著的技术壁垒。国内大模型虽然没有处于领先阶段,但是也没有太掉队。
国内大模型的现状
大模型的核心本身不是什么秘密,作为研究成果都是公开的,各大模型也是在这套核心上基于各自的技术理解和取向走了对应的实现之路。比如chatgpt的通用模型、sora的文本生成视频模型。

而Sora至今只完成了公测版本还没有完全开放,反而是国内的可灵优先上线。

今年的7月份,openAI的API不对中国开放,国内很多借助API开发的AI公司面临灭顶之灾。但是,在此消息之后,国内很多大模型平台,比如阿里云百炼(Qwen2-72B)、智谱(GLM-4)、文心旗舰模型(ERNIE Speed/ERNIE Lite)等都为OpenAI API用户提供使用国内大模型的替代方案。这也侧面表现出我们国内大模型的能力还是不弱的。
另外,在国外优秀的ChatGPT-4、Claude3.5等大模型的引领下,国内的大模型借鉴国外的成功经验,有清晰的问题和目标,反而拥有一定的后发优势。


通过个人使用体验来讲,国产大模型中整体最有的是阿里的通义千问,拥有最强算例,通过其开源的方式,吸引了大量开发者,形成了一个活跃的生态系统。
从专项能力看,对长文本支持最好的是月之暗面的kimi,可以解读上百万的文字,并且任意提问、总结等操作
通过斯坦福大学基础模型研究中心近期公布的HELM MMLU大模型评估排行榜最新一期显示,阿里巴巴集团旗下的Qwen2 Instruct(72B版本)就占据了前十的位置。

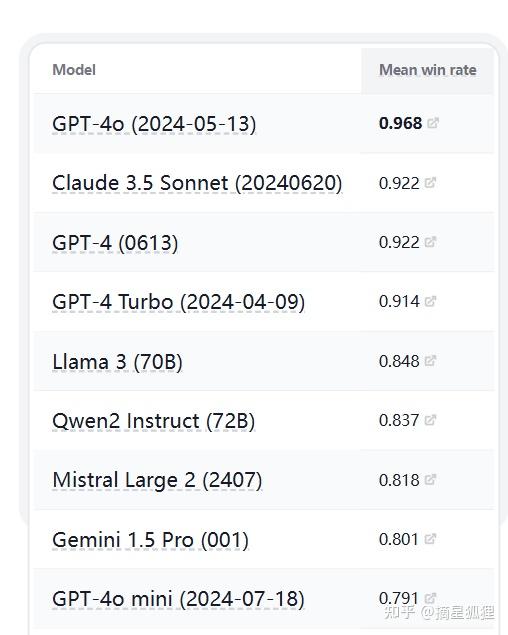
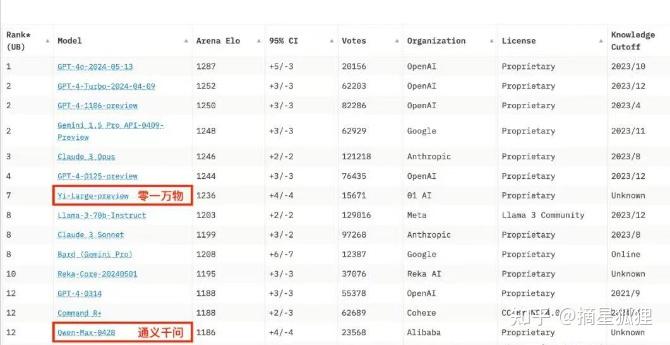
而且,零一万物(Yi-Large)大模型,在LYMSY发布的chatbot Arena榜单中取得了世界第七、中国第一的成绩,排名超过了通义千问。
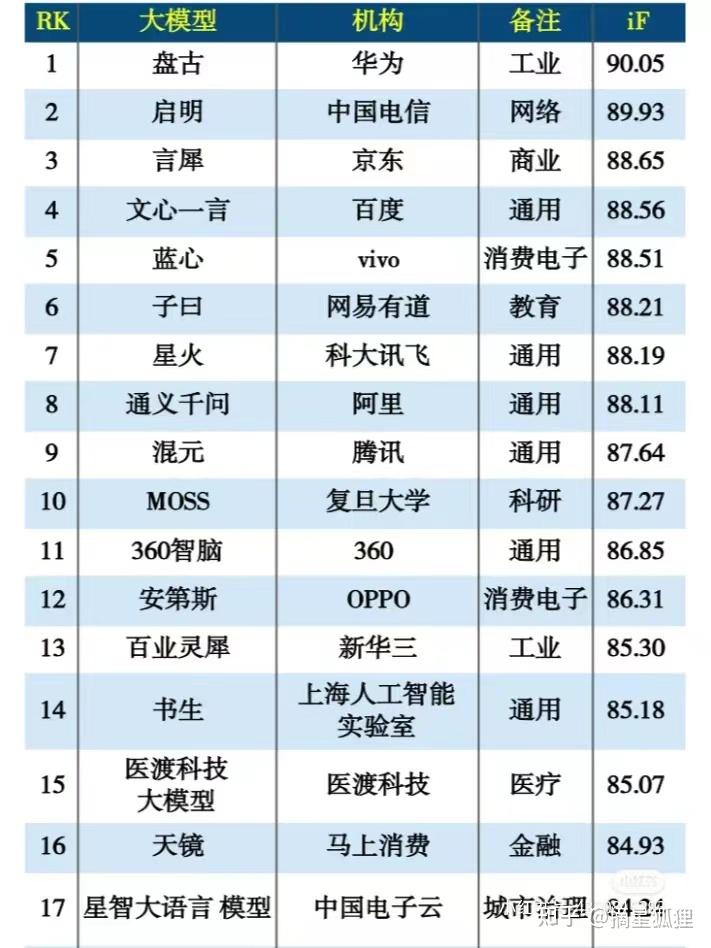
而且,国内更注重垂直行业与领域大模型的落地应用。《互联网周刊》上发布“大模型活力TOP150排行榜”,应用于工业领域的华为的盘古模型就位列第一。
而国外则在算法创新、通用大模型、多模态互动方面优势明显。
但是,和顶级模型如ChatGPT和Claude相比,在我看来,还是在逻辑、理解和内容表达上,还是存在差距的。
比如,就像科大讯飞的星火大模型在多模态能力上就比较弱势。

不过,我们由于语言的差别,国内的通义千问对于中文的识别和表达明显优于国外的一些大模型。

可见,目前看来,国内的大模型至少没处于太掉队的状态。从大模型的发展历程和未来的发展趋势来看,现在正是加入这个行业的绝佳时机。随着国内大模型技术的不断提升和逐步落地,特别是在垂直行业和领域的应用场景中,市场对大模型的需求日益增长。
尽管行业竞争激烈,但正因为技术的开放性和发展迅速,进入这个领域的门槛相对较低,即使你没有太多的行业经验,现在进入AI这个风口行业也不会太晚。通过参与专业的学习课程,你可以快速掌握核心技术,并明确未来的职业发展方向。
因此我非常推荐知乎知学堂的AI免费课程,通过行业大佬们的讲解,来更清晰的认知国内外大模型的能力,想清楚自己该如何增收。而且,课程还有专门的助教老师,添加即可获得一对一解惑指导,现在点下方链接报名只要0.1元。
这个免费课里,我还学到了大模型微调、LangChain开发框架的用法等AI解决业务问题的核心方法、培养独立开发AI产品的能力,还能拓宽技术视野,构筑核心竞争力。
国内大模型的下一步发展趋势是什么?
AI的三大版图:充足的算力、优质的训练数据、优秀的算法。在百模大战,百家争鸣的市场竞争中,我们从数量到质量的发展,越来越清晰国内大模型想做到弯道超车,就要抓住我们的优势,努力发展大模型垂直领域的应用。
因为通用大模型离我们还是有段距离的,比如训练成本贵,技术积累还是不如目前闭源的chatgpt-4。
但是,我国有成熟的互联网大数据体系和大数据潜力,非常擅长通过具体应用场景推动算法迭代升级,在各个特定领域建立算法优势,比如kimi就是读取上百万字的长文本。人们需要的也是能帮助我们实实在在解决问题的项目。
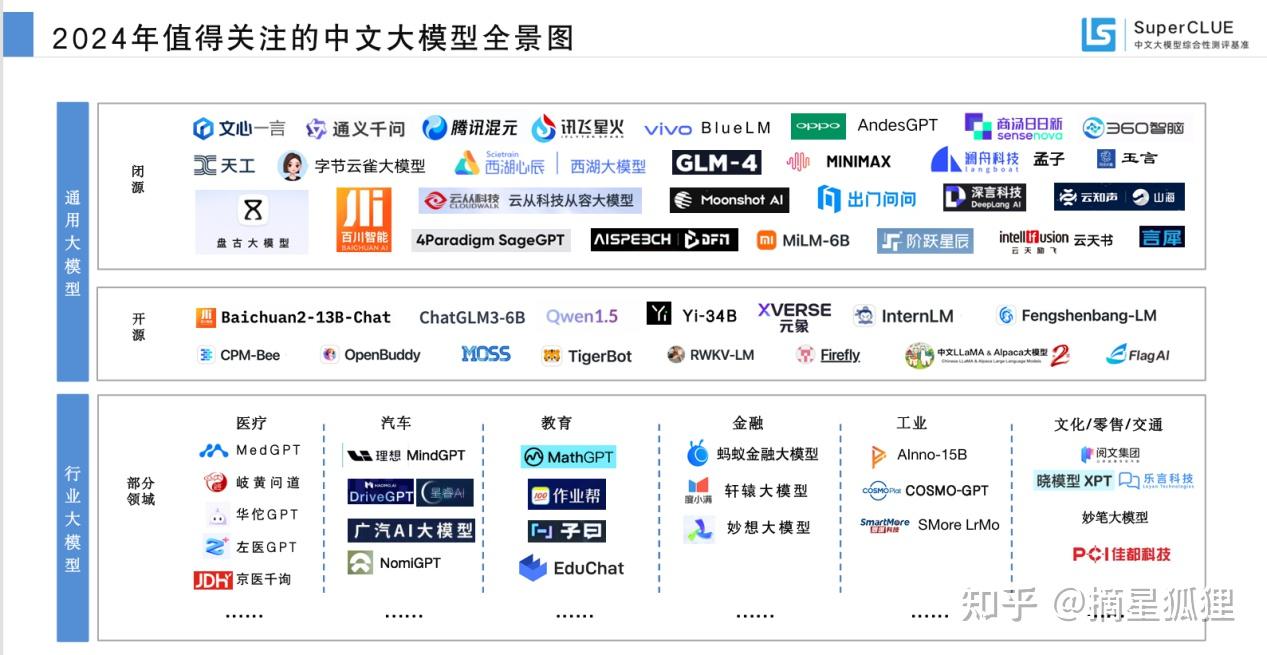
SuperCLUE团队今年4月发布的《中文大模型基准测评2024年4月报告》也表现出了我们的大模型在垂直领域的大量落地实现。
另外,跟着大公司的招聘风向,我们也能更加确定,专业领域的大模型服务是他们未来需求的重点,大企业在面试的时候也更关注应用落地。

技能训练和职业发展
找准出路之后,我们能做的就是努力提升自己的实力。
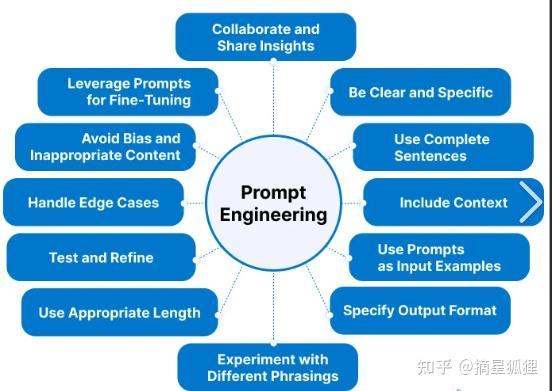
其中Prompt Engineering个人觉得是所有LLM相关程序员必须掌握的技能,而且上手成本不高。Prompt Engineering就是讨论如何有效的与人工智能进行交流,通过对Prompt进行设计、优化调整,使得LLM生成更准确生动的自然语言文本。比如可以用在问答、翻译、摘要生成等方面。并且,如果你选择的LLM是国内的,那么prompt编写最好用中文,因为如果你不用对应的语言写prompt,那么会有一定概率出现输出语言错误。
课程中还会学习LangChain+Fine-tune来实现模型定制化。这些技术都是由行业大佬讲解,让你不走弯路。并且大佬们还认真和你探讨借助大模型技术提高收入的可能性。
而这些技术的精进只需要你有基础的程序代码或者python的基础就可以。
虽然,目前有一部分人唱衰LangChain,觉得它框架不灵活并且抽象。LangChian的抽象不仅增加了代码的复杂性,而且每个组件都需要深入理解才能避免意外崩溃。另外,学习成本高,很多人花大量时间去学习,还学不会,甚至框架还限制了程序员的灵活性和创新能力。比如,只是走request请求方式,可能直接编写代码比适应LangChain的解决方案更为直接和有效。
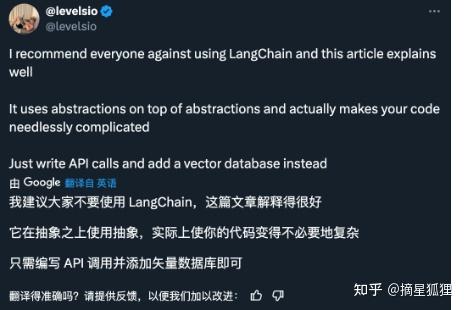
但是,我还是建议该学还是去学,学习成本虽然高,但是人家文档写的好,比如document splitter。如果花时间点进代码看具体的chain和agent实现之后,自己写真的非常省时间。而且,其组件丰富,易集成性,都是很好的优势。
有入职字节、腾讯、阿里大模型的小伙伴,也分享到面试中很重要的一部分内容就是关于LangChian的。所以,这个技能还是很有需求的。

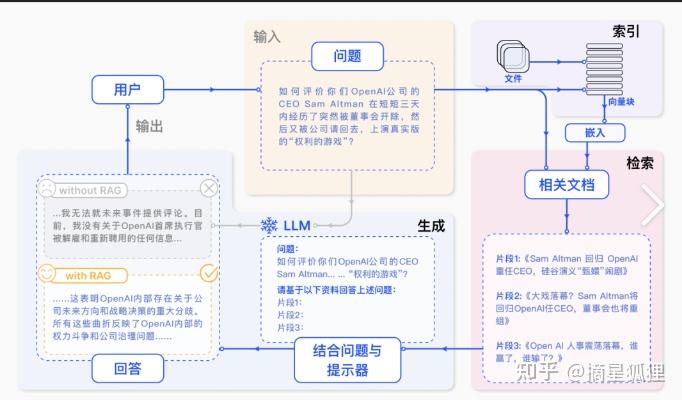
大模型技术架构从纯Prompt的简单对话,到Agent+Function Calling的主动交互,再到RAG的高效检索,最终到Fine-Tuning的深入学习,每一种都有其独特的优势和应用场景。
目前,构建企业垂直场景大模型应用的时候,涉及到两个最重要的核技术选择,检索增强生成(RAG)和模型精调(Fine-Tuning)。
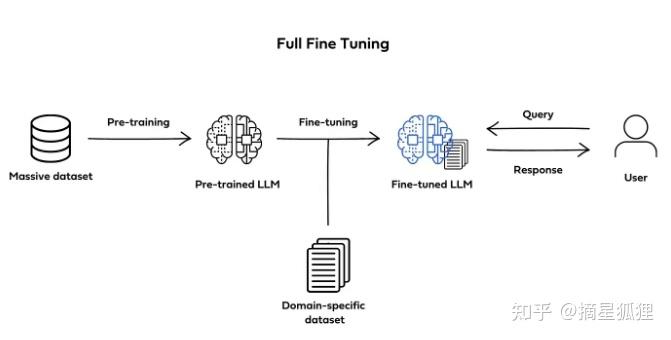
Fine-Tuning通过对特定任务和领域的进一步训练,就可以让其在特定领域表现得更专业,比如医学诊断、自动驾驶等等。
目前,有个体验用户讲到,chatgpt的Fine-Tuning仅仅训练一下,数据集的数量级在千条不到,就需要10刀,真的是很贵。但是,某种程度上来讲,对于小项目的垂类GPT3.5的生成非常有帮助,并且性价比高。
这里就不得再次感谢知乎知学堂上提供的免费课程。通过这门课程,了解大模型时代程序员必备的技巧,以及如何使用技术,从而更好的提升自己,抓住赚钱的机会。而且,有免费的Fine-tuning训练模型,快来体验吧。
未来,大模型的发展还是以商业化为主,谁更会用大模型,训练的更有用,更好的做到落地,就能做到行业的前端,我相信,未来很长一段时间,市场肯定需要大量相关的技术人才,赶紧行动起来吧。