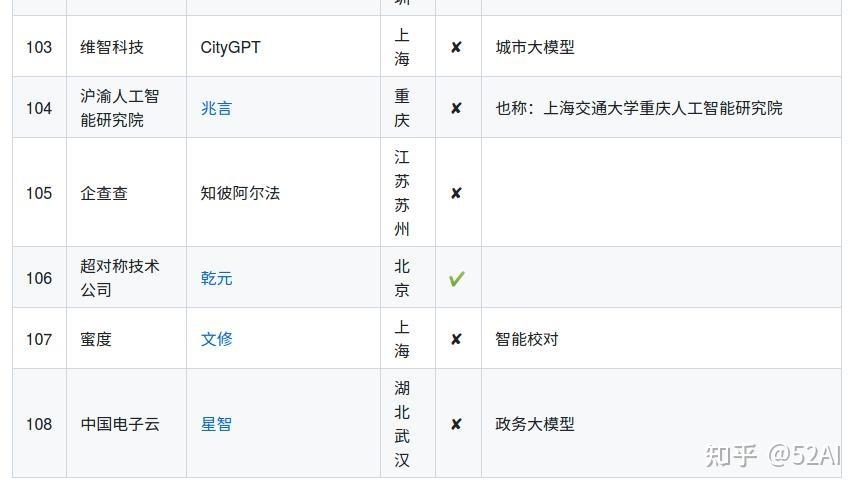
以国内大语言模型为例,先看下国内LLM的进展。下图的103个大模型说明有点资金和技术实力的公司,学术机构都直接或间接研发了LLM,该入场的都入场了。
不到半年的时间,就如此这般。说明技术上没啥壁垒,真正的壁垒来自数据。 目前该进入拉开性能差距,吸引留住更多用户的阶段。
中国大模型列表: https://github.com/wgwang/LLMs-In-China

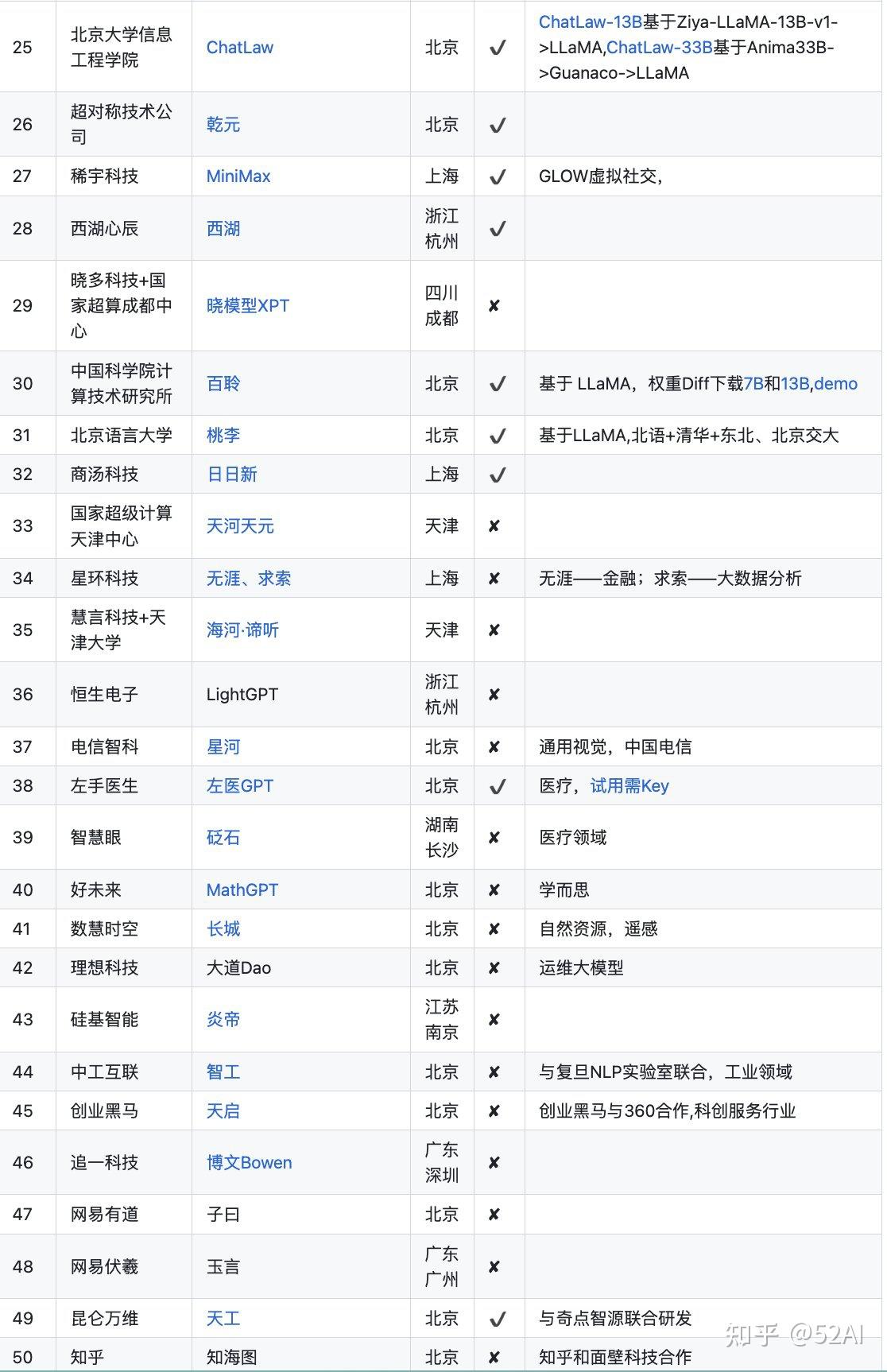
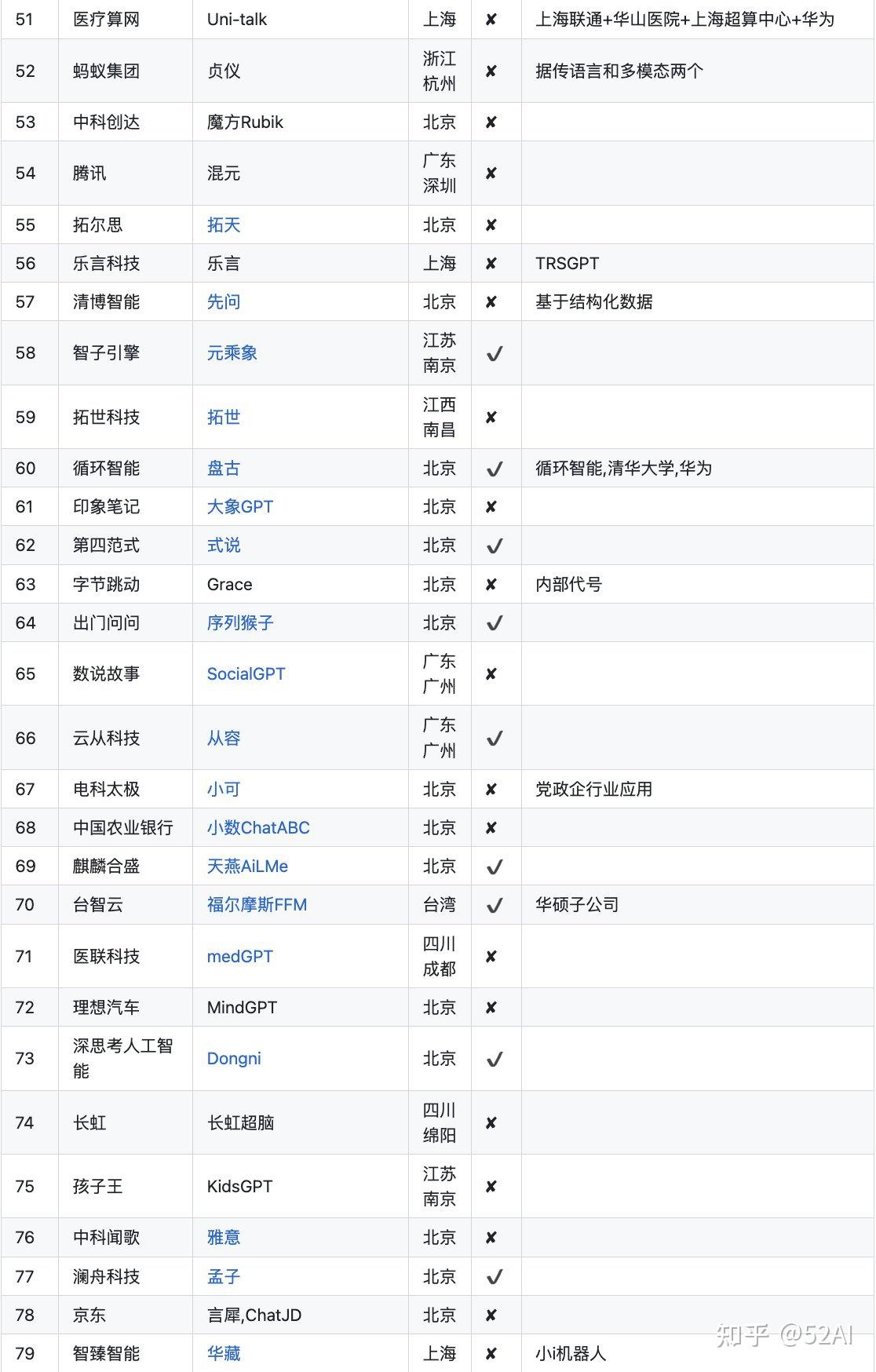
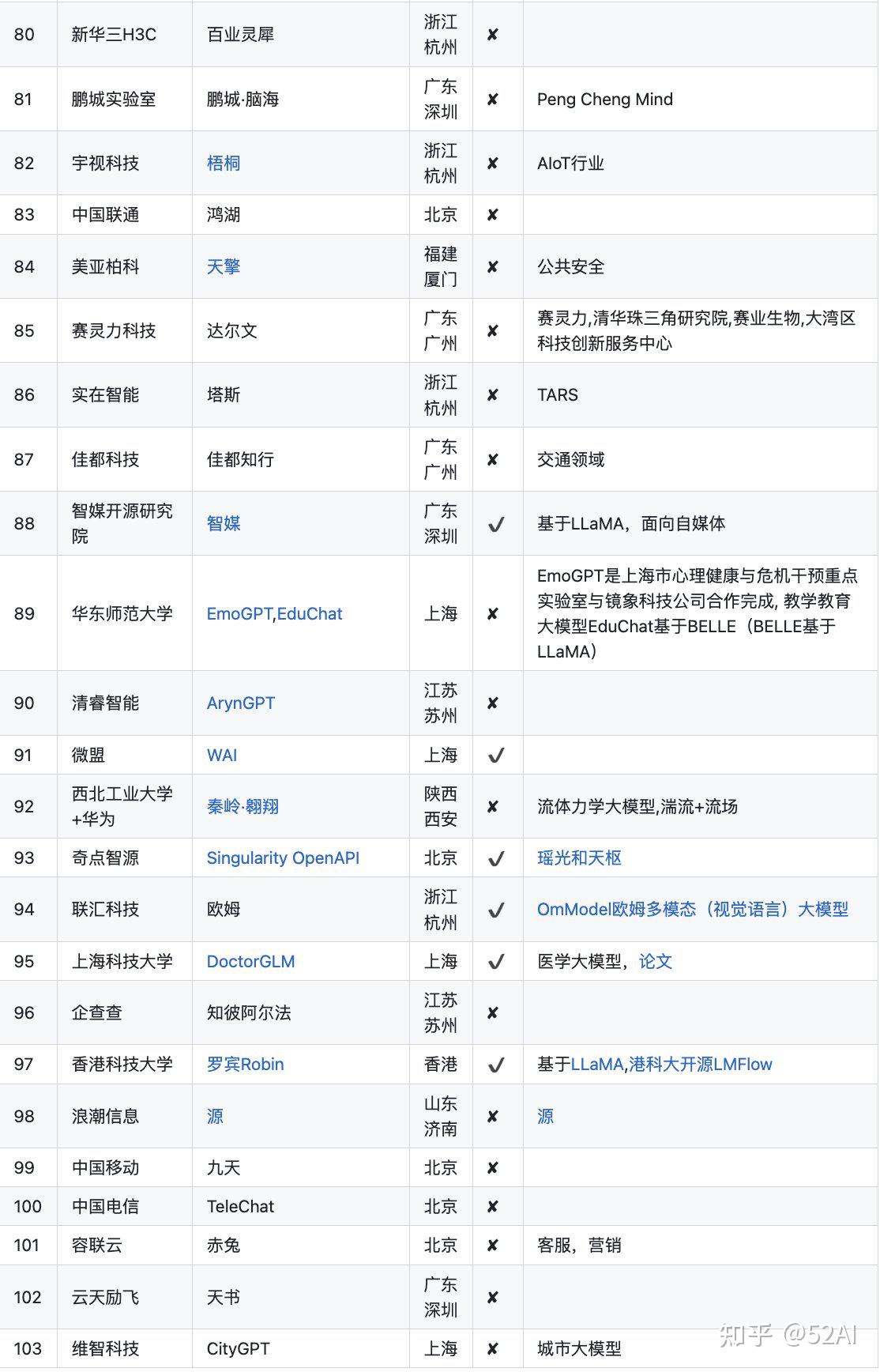
更新下,数据来源中国大模型列表
编辑于 2023-07-18 10:18・IP 属地北京

以国内大语言模型为例,先看下国内LLM的进展。下图的103个大模型说明有点资金和技术实力的公司,学术机构都直接或间接研发了LLM,该入场的都入场了。
不到半年的时间,就如此这般。说明技术上没啥壁垒,真正的壁垒来自数据。 目前该进入拉开性能差距,吸引留住更多用户的阶段。
中国大模型列表: https://github.com/wgwang/LLMs-In-China
更新下,数据来源中国大模型列表