如何看待清华团队发布 ChatGLM2-6B,对学术研究完全开放,允许免费商业使用?
我们很高兴地宣布,自 3 月 14 日发布 ChatGLM-6B 及 6 月 25 日发布 ChatGLM2-6B 以来,这两个模型在 Huggingface ...

- 228 个点赞 👍
这里先不说ChatGLM2-6B的完全开放的影响,讲两个案例
第一个的自己亲身经历的,国外专业软件在国内推广套路的问题。
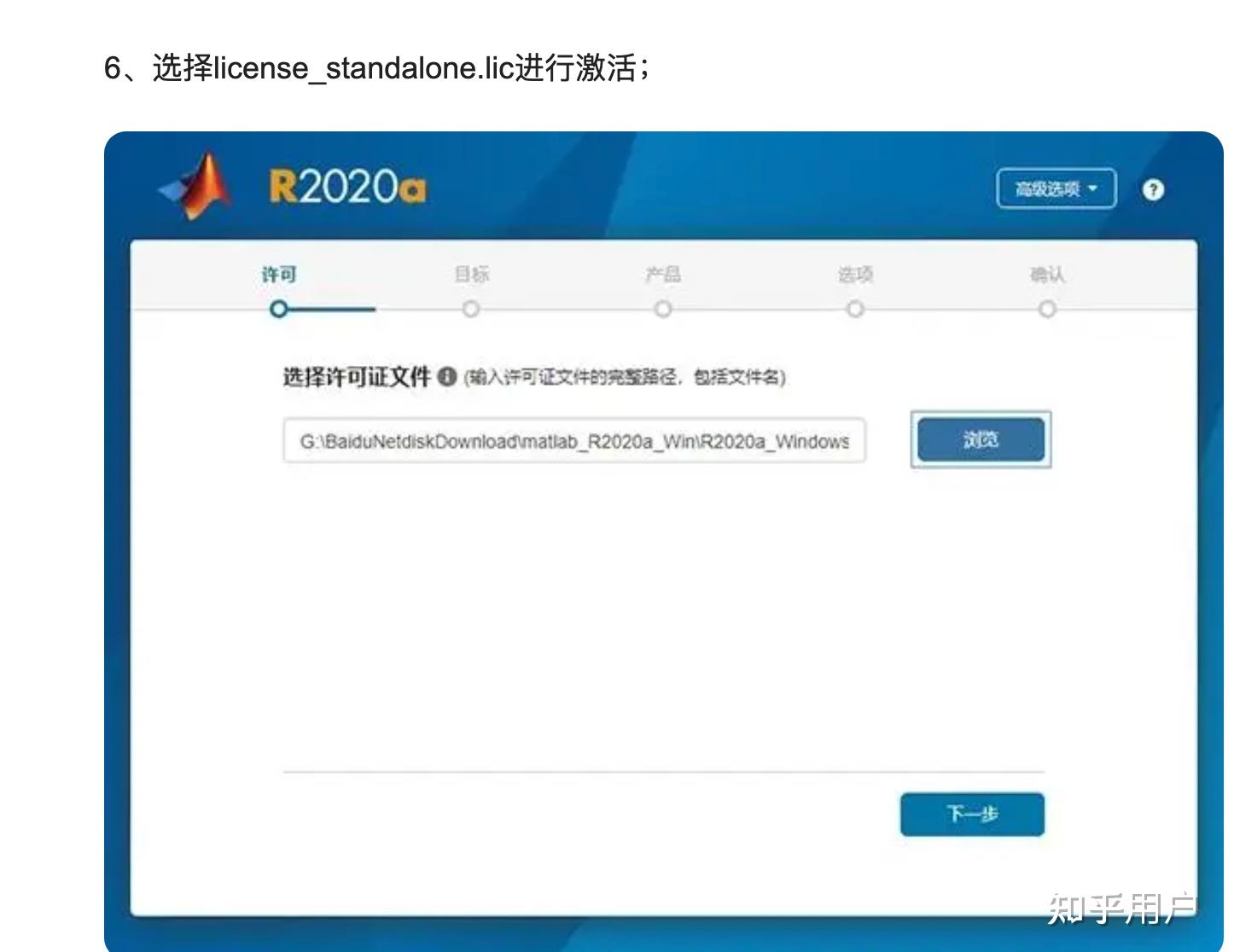
曾经去国内一家制造业企业做研发方面工作,其中有一些数据处理和仿真的模块必须要用到matlab,由于公司这个方向的很多都是哈工大,北航等工科院校出来的,matlab大家都很熟悉,特别是各种破解版本的套路大家都是手到擒来,网上这方面的教程更是一抓一大把。看看下面的截图,是不是很亲切熟悉?所以很自然的,就装了一大堆盗版matlab,然后进行破解,各种完全版本只要电脑内存够大,各种上美滋滋~
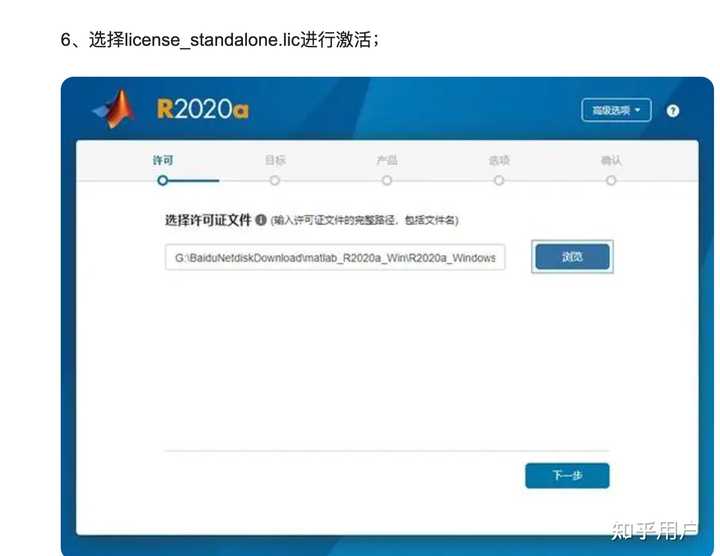

matlab破解教程 但是好景不长,从17年初起,就开始经常受到mathworks 的律师警告,说监测到公司使用盗版软件,要诉诸法律手段进行高额索赔。
公司只好紧急讨论对应的方案,刚开始,公司想选择替代方案,后来论证下来,发现全公司上下都是从大学接触到这个专业,到研究生到参加工作,一直都是用matlab解决这方面的问题,可以说,没有了matlab,很多人都基本不会干活了,换任何一个解决方案,且不说能不能用,高昂的学习研发成本,能让公司直接倒闭。
无奈只能马上联系mathwork 公司商谈购买正版软件,可以当时一谈下来,正版软件全部模块的单机版本买下来要200多万,浮动账号版本的基础价格是单机版本的4倍而且,同时在线人数至多2-4个。
这样搞一圈下来,最终公司花了几十万买了经常用的两三个模块,另外在特定电脑上搞破解版,做充分的外网单机隔离,每年出好几万软件维护费用做matlab升级维护,后来公司规模扩大,这方面的成本也越来越大,直接被吃得死死的。
这样的案例还有很多很多,类似运筹优化的专业软件gurobi,cplex,物流仿真软件flexsim,基本上都是学术研究免费开放,或者对破解版本睁一只眼闭一只眼(估计这破解方法就是他们自己放出去的),培养专业使用人员的习惯,由于用这类工具的人都是高校逐渐培养的,所以他们的布局争抢的重点战场反而是在高校课程设计当中,不在商业市场上。
第二个是国外开源软件以太坊生态系统的推广套路
以太坊生态系统在过去几年里取得了显著的发展,并且一直在努力扩大用户规模。以下是一些以太坊生态系统扩大用户规模的常见方法:
1. 提供易于使用的界面:以太坊生态系统的发展受益于提供更加友好和易于使用的界面。钱包应用程序、交易所和其他以太坊相关的工具不断改进用户体验,降低使用门槛,使新用户更容易参与。
2. 增加开发者支持:以太坊生态系统通过提供丰富的开发者工具和支持来吸引更多开发者。这包括开发文档、编程库、智能合约框架和开发者社区等。通过吸引开发者构建应用和工具,可以吸引更多用户加入以太坊生态系统。
3. 促进去中心化应用(DApps)的发展:以太坊的目标之一是成为去中心化应用的平台。通过鼓励和支持去中心化应用的开发和推广,以太坊生态系统能够吸引更多用户。去中心化应用可以提供更多的功能和服务,吸引用户参与,并且不依赖于单一实体的控制。
4. 支持标准化和互操作性:以太坊生态系统致力于推动标准化和互操作性,使不同的应用程序和服务能够无缝地合作和交互。这有助于构建更强大和丰富的生态系统,吸引更多用户参与。
5. 推广和宣传:市场推广和宣传活动对于扩大用户规模至关重要。以太坊生态系统通过参加行业会议、举办活动、与开发者社区合作以及与媒体合作等方式来推广自身。宣传可以提高用户对以太坊生态系统的认知,并吸引更多用户参与。
6. 支持规模化:以太坊生态系统一直在努力解决扩展性和性能挑战,以支持更多的用户和交易。例如,以太坊正在推进以太坊2.0(Eth2)的开发,以提高性能并实现更高的吞吐量。通过增加网络容量和提高性能,以太坊可以更好地支持大规模用户的参与。
回过头来讲ChatGLM2B 的学术研究开放,大模型的算法架构基本上大家都差不多,都是Transformer打底的神经网络,其实更多是吃数据,吃应用场景,吃算力,谁的应用场景广泛,谁的模型收集到的调整反馈越多,谁的模型通用性就会越强,谁今后就更有可能成为大模型的事实标准,后续基于大模型的各类应用都在这上面开发,就像大家目前一提起来操作系统就想到windows,linux,一提起区块链就会想到以太坊一样,这是底层生态战场的争夺。
底层生态争夺的逻辑,就是要快速地扩大用户群体,用各种方式广泛触达支持所有用户,培养用户习惯,实现专业用户规模快速扩大,最终建立事实标准。
比照下matlab和以太坊,一个专业软件,一个开源生态,希望ChatGLM的清华智谱AI团队,在后续的大模型时代能够绝地反击,至少在国内,建立起中国自己的大模型生态。
编辑于 2023-07-16 22:12・IP 属地北京查看全文>>
知乎用户 - 20 个点赞 👍
对比一下Meta开源的LLaMA和清华发布的ChatGLM2,可以看得更清楚。
LLaMA开源的时候,并不公开权重,要获得权重要申请,而申请往往不通过,要不是有人『不小心』在github的PR中泄露了torrent种子,到现在大家也玩不起来LLaMA;ChatGLM2-6B完全开放,不开放不行啊,人家LLaMA泄露出来的权重最小都有7B参数,最多65B参数,6B参数要是还藏着掖着就无人问津了。
LLaMA的权重虽然泄露了,但是守法公民......不,守法公司还是要遵守Meta的要求,研究可以,不能用于商用,最后的结果就是,各种羊驼的变种很多,但是没人敢拿到商业应用上;ChatGLM2给了权重,也允许免费商用,可以把路子走宽,满足业界大模型商用的需求。
一句话,开放也是被逼的。
看了一下Huggingface上的下载趋势,ChatGLM2的数据当然一枝独秀,但是考虑中文环境下的人口基数,就好比github上中文的repo获得星星的优势,这个结果也不让人意外。
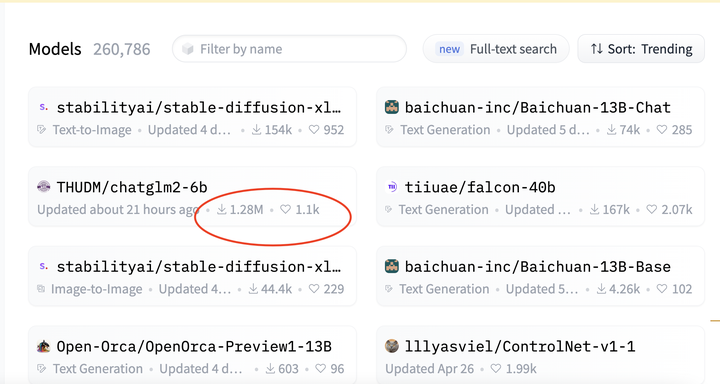
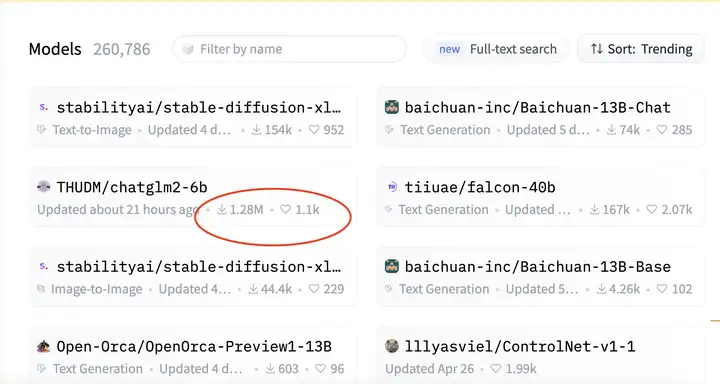
对于ChatGLM2的实际性能,我坦白说对于6B参数的结果信心不是很大,但是AI产品——和任何产品一样——应该看如何和场景结合的程度,而不要只盯着参数和跑分结果,所以,期待开放之后这个生态系统中会出现充分利用ChatGLM2做出贴合实际的AI应用吧。
总之,我觉得ChatGLM2完全开放式好事,这种好事,就好比消费者看到各电商大厂争相推出各种打折优惠活动一样,很好很好!
编辑于 2023-07-17 07:37・IP 属地美国真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
程墨Morgan - 18 个点赞 👍
7月17日更,除了商用领域chatglm的开源对于整肃开源在大模型领域的风气起到了非常好的表率作用,中文语料在用于训练的语料总数也不够多,如果今后基于chatglm形成的生态圈可以帮助建立起高质量的开源中文语料库,功德无量。
现在我们使用互联网产品在寻求人工客服帮助的时候往往需要忍受多轮基于关键字的敷衍客服,然后再忍耐长时间排队,最后找到人工客服要做的事情反而很简单。
中小型网店、以及各类中小服务型企业的福音,信息量不大的各型客服客服典型场景都可以受益于这个中文不错的6B模型。低成本部署、微调后不错的性能,只要能正常识别用户需求,往往小微类客服能做的操作非常有限,这类场景非常适合部署这类模型。
虽然6B的模型跑不了ReAct、解不了数学题、写代码也有困难,但是单张消费级显卡可以驱动的模型才是让这项技术走入千家万户最好的方式。
相比gpt高昂的价格,llama、falcon对商用并不友好的开源协议,chatglm很值得尝试。
编辑于 2023-07-17 13:06・IP 属地上海查看全文>>
xu ciro - 17 个点赞 👍
昨天已经申请商业使用,暂时还没有回复。
说实话虽然ChatGLM2-6B还比不上ChatGPT,但是它的推理能力和速度较之前的版本已有很大提升。它目前的效果,足以支撑其在部分的商业场景中使用了。
至于它产生幻觉方面的问题,目前最好的GPT4也是会有幻觉的问题,所以注定这些LLM只能用于特定的应用场景,例如,头脑风暴、会议总结等等。
最后用一句话来说就是:未来可期。
发布于 2023-07-17 05:37・IP 属地北京查看全文>>
月光晒谷 - 8 个点赞 👍
查看全文>>
白颐路观潮 - 3 个点赞 👍
背景:
基于chatglm构建agnet:https://zhuanlan.zhihu.com/p/644167758
前面一篇文章已经介绍了如何去搭建LLM Agent控制系统,也简单介绍了如何去构建Toolset和构建Action。但是在上篇文章中Toolset其实是基于搜索api构建的,从这篇文章开始后面几篇文章会围绕具体的工具展开介绍如何搭建专业工具。这篇文章介绍的是如何构建临时文件填充工具:向量检索。
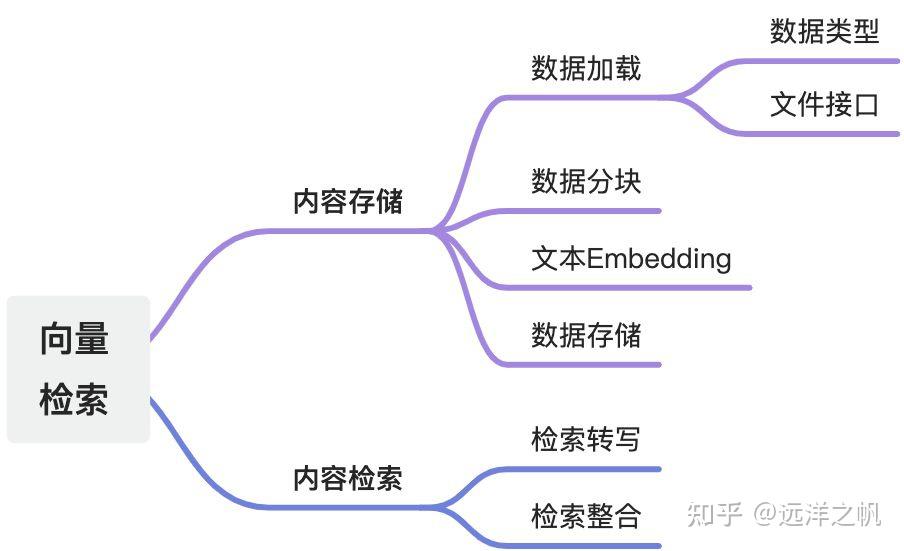
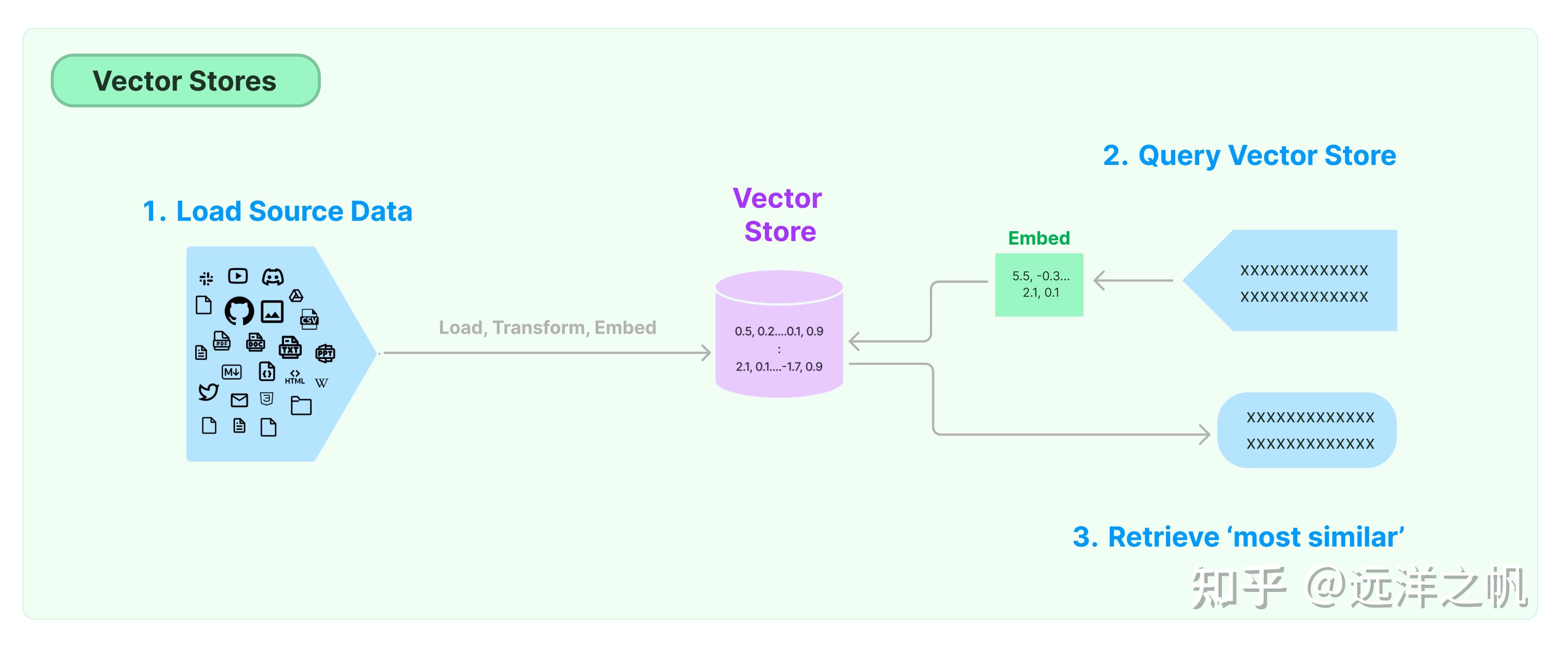
向量检索有两大部分:内容存储部分、内容检索部分。
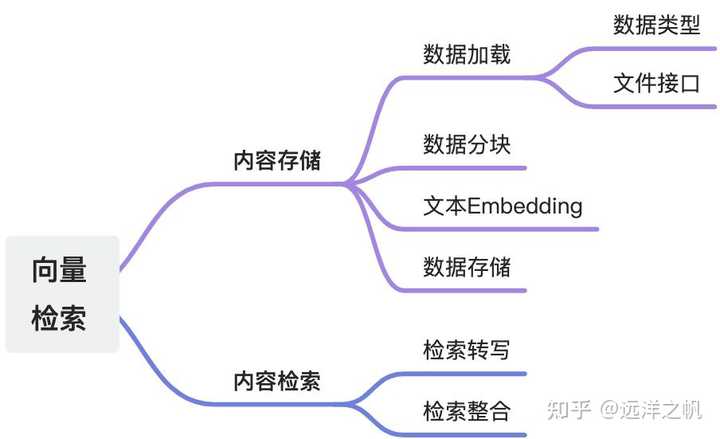

开始细节讲解之前,先来一个整体例子介绍:何谓向量化:
## # 导入分割文本的工具,并把上面给出的解释分成文档块 from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size = 100, chunk_overlap = 20, ) explanation = '''Autoencoder(自动编码器)是一种非常有趣的数学模型,就像一个魔法盒子,可以帮助我们理解数据是如何在空间中转换和变换的。 这个魔法盒子里有两个部分:编码器(Encoder)和解码器(Decoder)。 首先,让我们来看一下编码器。它是一个把输入数据(比如一张图片、一段视频或者一篇文章)变得更容易看懂的神奇机器。它将输入数据压缩成一个更小的空间,这样原始数据中的信息就会更加强烈地保留下来。 接下来是解码器。它是一个把编码器压缩后的结果恢复成原始数据的神奇机器。它将编码器得到的结果还原成输入数据(也就是我们刚刚压缩过的数据),这样解码器就得到了和原始数据完全一样的输出。 那么,为什么说Autoencoder能够提高数据处理的效率呢? 因为通过有效的数据压缩和恢复,Autoencoder能够减少数据量,从而更快地处理和分析数据。这就好像把一个大箱子变成了一个更小的箱子,虽然里面东西的总量没有变,但是可以更轻松地拿取和移动箱子。 所以,Autoencoder是一个非常有趣的数学模型,它可以帮助我们更好地理解数据在空间中的转换和变换。 ''' texts = text_splitter.create_documents([explanation])切割完后数据如下:


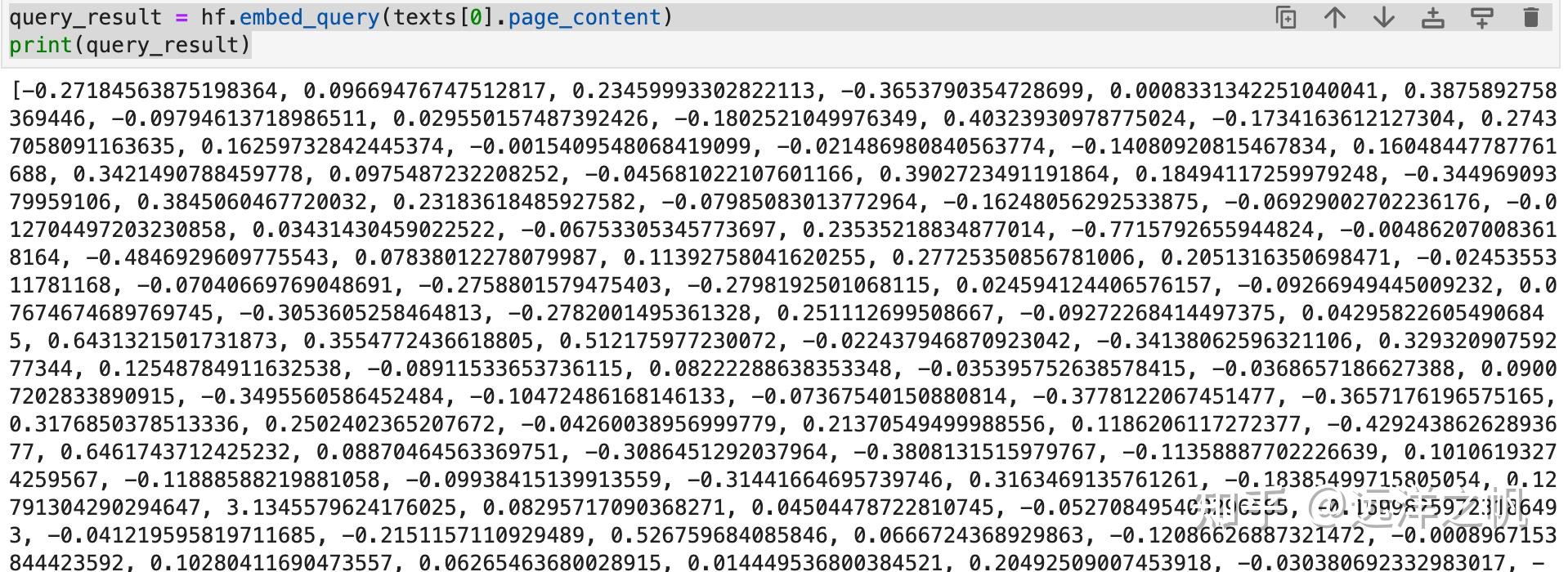
对切割完的数据embedding:
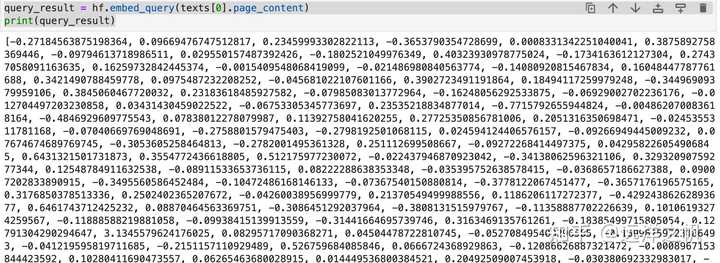
from langchain.embeddings import HuggingFaceEmbeddings model_name = "nghuyong/ernie-3.0-xbase-zh" #model_name = "nghuyong/ernie-3.0-nano-zh" #model_name = "shibing624/text2vec-base-chinese" #model_name = "GanymedeNil/text2vec-large-chinese" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': False} hf = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, cache_folder = "/root/autodl-tmp/ChatGLM2-6B/llm_model" ) query_result = hf.embed_query(texts[0].page_content) print(query_result)embbding后的数据如下:

技术点:
数据加载
使用文档加载器从文档源加载数据。 文档是一段文本和关联的元数据。 例如,有一些文档加载器可以加载简单的 .txt 文件、加载任何网页的文本内容,甚至加载 YouTube 视频的脚本。
文档加载器公开了一个“加载”方法,用于从配置的源将数据加载为文档。 它们还可以选择实现“延迟加载”,以便将数据延迟加载到内存中。
数据类型
txt
from langchain.document_loaders import TextLoader loader = TextLoader("./index.md") loader.load()pdf
#pip install pypdf from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf") pages = loader.load_and_split() pages[0]数据分块
RecursiveCharacterTextSplitter:对于一般文本,推荐使用此文本分割器。 它由字符列表参数化。 它尝试按顺序分割它们,直到块足够小。 默认列表为 ["\n\n", "\n", " ", ""]。 这样做的效果是尝试将所有段落(然后是句子,然后是单词)尽可能长时间地放在一起,因为这些通常看起来是语义相关性最强的文本片段。
文本如何分割:按字符列表
如何测量块大小:按字符数
实现代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show. chunk_size = 100, chunk_overlap = 20, length_function = len, ) texts = text_splitter.create_documents([explanation]) print(texts[0])CharacterTextSplitter:是最简单的方法。 这基于字符(默认为“\n\n”)进行分割,并按字符数测量块长度。
文本如何分割:按单个字符
如何测量块大小:按字符数
from langchain.text_splitter import CharacterTextSplitter from langchain.document_loaders import TextLoader loader = TextLoader("/root/autodl-tmp/ChatGLM2-6B/read.txt") documents = loader.load() text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) docs = text_splitter.split_documents(documents)文本embbeding处理
embbeding的作用就是对上面切好块的数据块,用预训练好的文本模型来做一道编码转换,压成有语意的向量。后面在检索的时候,就是通过对检索的问题做Embbding向量化,然后通过问题向量和存储的数据做相似度计算;把相关的数据捞出来做后续处理。
from langchain.embeddings import HuggingFaceEmbeddings model_name = "nghuyong/ernie-3.0-xbase-zh" #model_name = "nghuyong/ernie-3.0-nano-zh" #model_name = "shibing624/text2vec-base-chinese" #model_name = "GanymedeNil/text2vec-large-chinese" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': False} hf = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, cache_folder = "/root/autodl-tmp/ChatGLM2-6B/llm_model" )数据存储向量库

存储到本地:
from langchain.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import FAISS # 导入分割文本的工具,并把上面给出的解释分成文档块 from langchain.text_splitter import RecursiveCharacterTextSplitter loader = TextLoader("/root/autodl-tmp/ChatGLM2-6B/read.txt") documents = loader.load() text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) docs = text_splitter.split_documents(documents) db = FAISS.from_documents(docs, hf)如果数据量大,且数据是需要长期使用的,而不是临时使用用完就丢,数据可以存储到es:
import os import shutil from elasticsearch import Elasticsearch from langchain.vectorstores import ElasticKnnSearch from langchain.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from configs.params import ESParams from embedding import Embeddings from typing import Dict def _default_knn_mapping(dims: int) -> Dict: """Generates a default index mapping for kNN search.""" return { "properties": { "text": {"type": "text"}, "vector": { "type": "dense_vector", "dims": dims, "index": True, "similarity": "cosine", }, } } def load_file(filepath, chunk_size, chunk_overlap): loader = TextLoader(filepath, encoding='utf-8') documents = loader.load() text_splitter = CharacterTextSplitter(separator='\n', chunk_size=chunk_size, chunk_overlap=chunk_overlap) docs = text_splitter.split_documents(documents) return docs class ES: def __init__(self, embedding_model_path): self.es_params = ESParams() self.client = Elasticsearch(['{}:{}'.format(self.es_params.url, self.es_params.port)], basic_auth=(self.es_params.username, self.es_params.passwd), verify_certs=False) self.embedding = Embeddings(embedding_model_path) self.es = ElasticKnnSearch(index_name=self.es_params.index_name, embedding=self.embedding, es_connection=self.client) def doc_upload(self, file_obj, chunk_size, chunk_overlap): try: if not self.client.indices.exists(index=self.es_params.index_name): dims = len(self.embedding.embed_query("test")) mapping = _default_knn_mapping(dims) self.client.indices.create(index=self.es_params.index_name, body={"mappings": mapping}) filename = os.path.split(file_obj.name)[-1] file_path = 'data/' + filename shutil.move(file_obj.name, file_path) docs = load_file(file_path, chunk_size, chunk_overlap) self.es.add_documents(docs) return "插入成功" except Exception as e: return e def exact_search(self, query, top_k): result = [] similar_docs = self.es.similarity_search_with_score(query, k=top_k) for i in similar_docs: result.append({ 'content': i[0].page_content, 'source': i[0].metadata['source'], 'score': i[1] }) return result def knn_search(self, query, top_k): result = [] query_vector = self.embedding.embed_query(query) similar_docs = self.es.knn_search(query=query, query_vector=query_vector, k=top_k) hits = [hit for hit in similar_docs["hits"]["hits"]] for i in hits: result.append({ 'content': i['_source']['text'], 'source': i['_source']['metadata']['source'], 'score': i['_score'] }) return result def hybrid_search(self, query, top_k, knn_boost): result = [] query_vector = self.embedding.embed_query(query) similar_docs = self.es.knn_hybrid_search(query=query, query_vector=query_vector, knn_boost=knn_boost, query_boost=1 - knn_boost, k=top_k) hits = [hit for hit in similar_docs["hits"]["hits"]] for i in hits: result.append({ 'content': i['_source']['text'], 'source': i['_source']['metadata']['source'], 'score': i['_score'] }) result = result[:top_k] return result from configs.params import ESParams from elasticsearch import Elasticsearch es_params = ESParams() index_name = es_params.index_name # %% 初始化ES对象 client = Elasticsearch(['{}:{}'.format(es_params.url, es_params.port)], basic_auth=(es_params.username, es_params.passwd), verify_certs=False) # %% 连通测试 client.ping() # %% 检查索引是否存在 index_exists = client.indices.exists(index=index_name) # %% 新建索引 response = client.indices.create(index=index_name, body=mapping) # %% 插入数据 response = client.index(index=index_name, id=document_id, document=data) # %% 更新 rp = client.update(index=index_name, id=document_id, body={"doc": data}) # %% 检查文档是否存在 document_exists = client.exists(index=index_name, id=document_id) # %% 根据ID删除文档 response = client.delete(index=index_name, id=document_id)用户检索
检索转写
基于距离的向量数据库检索在高维空间中嵌入(表示)查询,并根据“距离”查找相似的嵌入文档。 但是,如果查询措辞发生细微变化,或者嵌入不能很好地捕获数据的语义,检索可能会产生不同的结果。 有时会进行及时的工程/调整来手动解决这些问题,但这可能很乏味。
MultiQueryRetriever 通过使用 LLM 从不同角度为给定的用户输入查询生成多个查询,从而自动执行提示调整过程。 对于每个查询,它都会检索一组相关文档,并采用所有查询之间的唯一并集来获取更大的一组潜在相关文档。 通过对同一问题生成多个视角,MultiQueryRetriever 或许能够克服基于距离的检索的一些限制,并获得更丰富的结果集。
from langchain.retrievers.multi_query import MultiQueryRetriever llm = ChatGLM(model_path="/root/autodl-tmp/ChatGLM2-6B/llm_model/models--THUDM--chatglm2-6b/snapshots/8eb45c842594b8473f291d0f94e7bbe86ffc67d8") llm.load_model() retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm ) query = "chatglm是什么?" len(retriever_from_llm.get_relevant_documents(query=query))从多个角度去生成了可能的提问方式:


这部分功能是怎么实现的呢,其实很简单就是让LLM大模型对输入的问题从多个角度来生成可能的问法。你可以通过下面的代码来按自己要求生成自己的问法。把下面代码中 QUERY_PROMPT的template改成你自己的控制约束就行了。
from typing import List from langchain import LLMChain from pydantic import BaseModel, Field from langchain.prompts import PromptTemplate from langchain.output_parsers import PydanticOutputParser # Output parser will split the LLM result into a list of queries class LineList(BaseModel): # "lines" is the key (attribute name) of the parsed output lines: List[str] = Field(description="Lines of text") class LineListOutputParser(PydanticOutputParser): def __init__(self) -> None: super().__init__(pydantic_object=LineList) def parse(self, text: str) -> LineList: lines = text.strip().split("\n") return LineList(lines=lines) output_parser = LineListOutputParser() QUERY_PROMPT = PromptTemplate( input_variables=["question"], template="""You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions seperated by newlines. Original question: {question}""", ) llm = ChatGLM(model_path="/root/autodl-tmp/ChatGLM2-6B/llm_model/models--THUDM--chatglm2-6b/snapshots/8eb45c842594b8473f291d0f94e7bbe86ffc67d8") llm.load_model() # Chain llm_chain = LLMChain(llm=llm, prompt=QUERY_PROMPT, output_parser=output_parser) # Other inputs question = "What are the approaches to Task Decomposition?"检索结果整理
如果只是把问题做embbding,然后通过相似度检索召回文本,代码实现如下。
query = "chatglm是什么?" docs = db.similarity_search(query)检索回来的结果如下:


如果是直接把召回的结果作为答案,那这个肯定达不到我们希望的效果。所以比然要对召回的结果做处理,一般的处理其实就是让LLM模型,利用召回的数据作为参考资料,回答我们的问题。其实这背后的逻辑就是对信息做了过滤,把相关的数据权重加重,然后让模型基于加重权重的数据做回答。
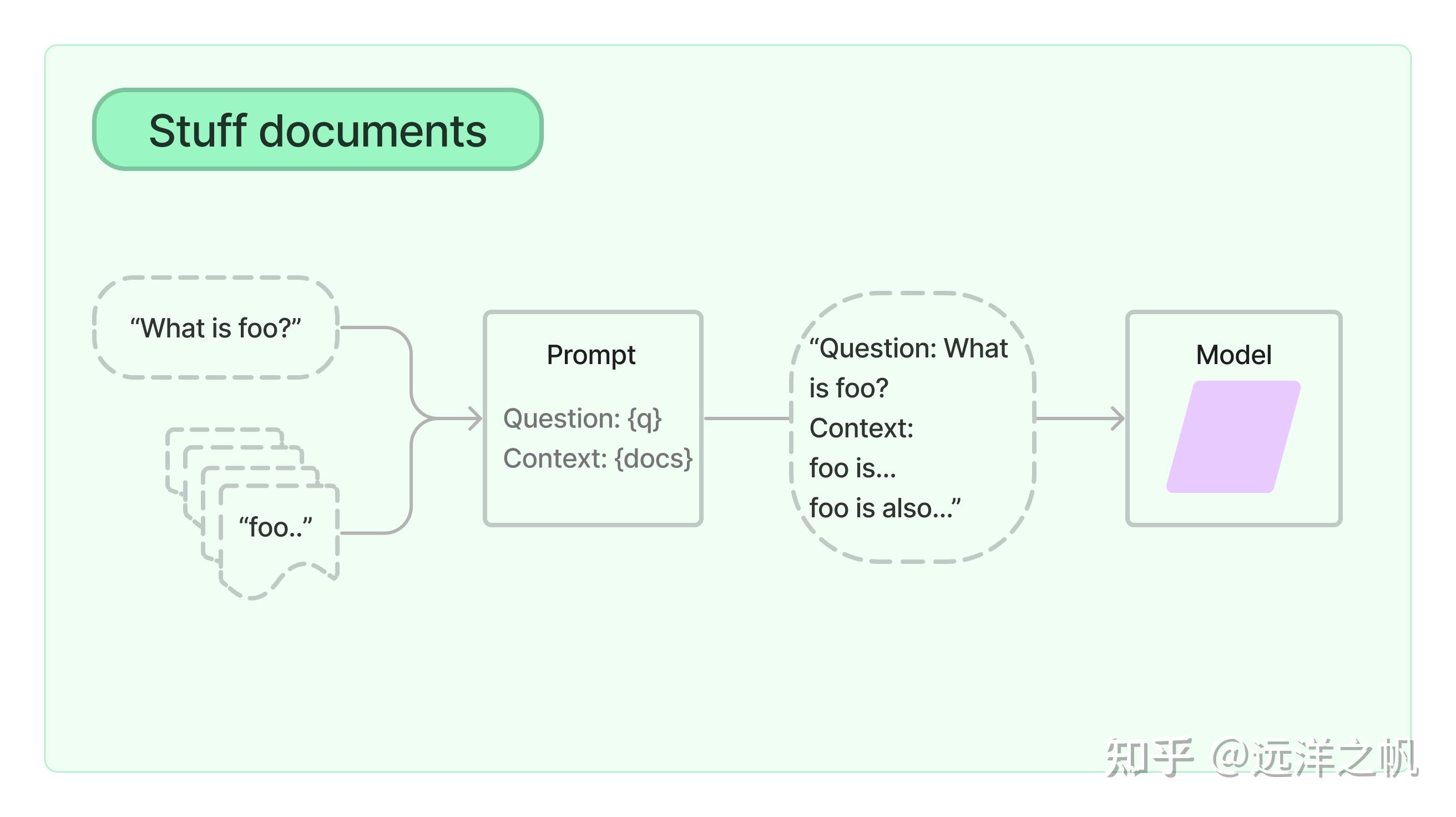
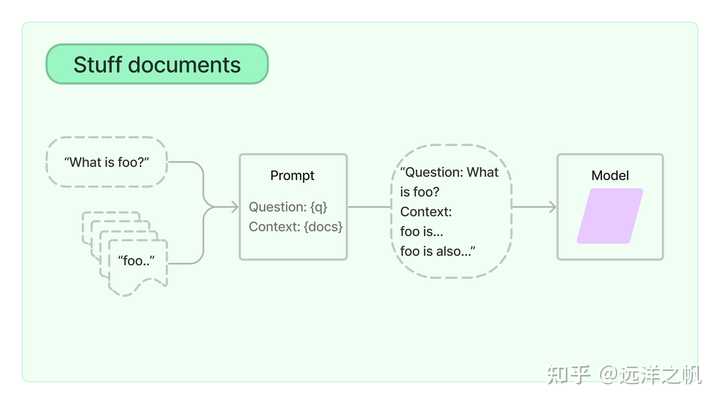
Stuff检索框架
填充文档链(“填充”如“填充”或“填充”)是最直接的文档链。 它需要一个文档列表,将它们全部插入到提示中,并将该提示传递给LLM模型。该链非常适合文档较小且大多数调用只传递少量文档的应用程序。

实现代码如下:
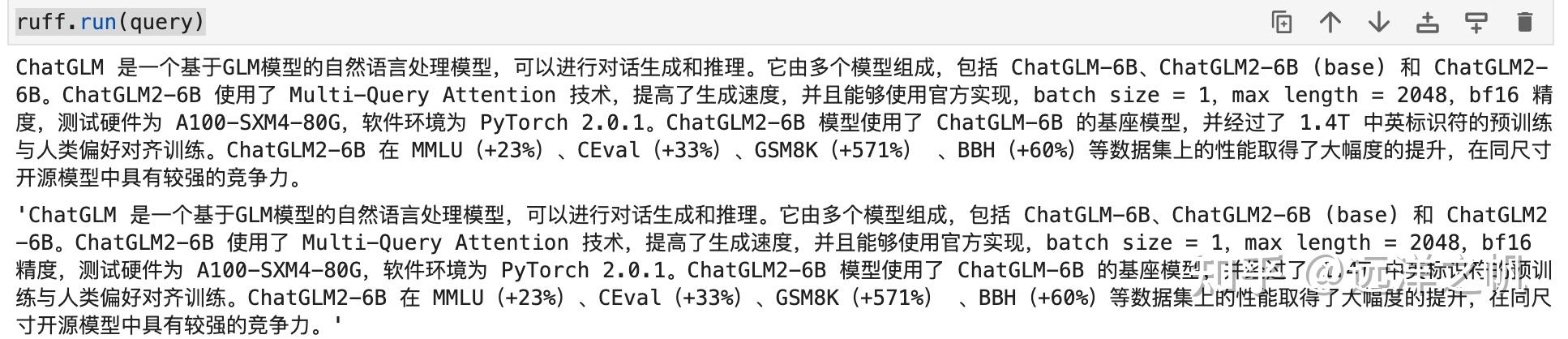
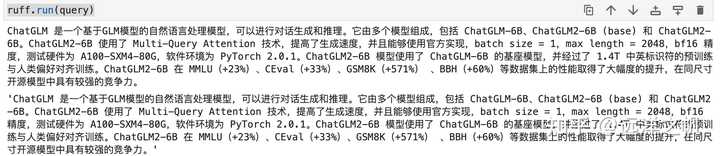
from langchain.chains import RetrievalQA ruff = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=db.as_retriever() ) ruff.run(query)生成结果如下:

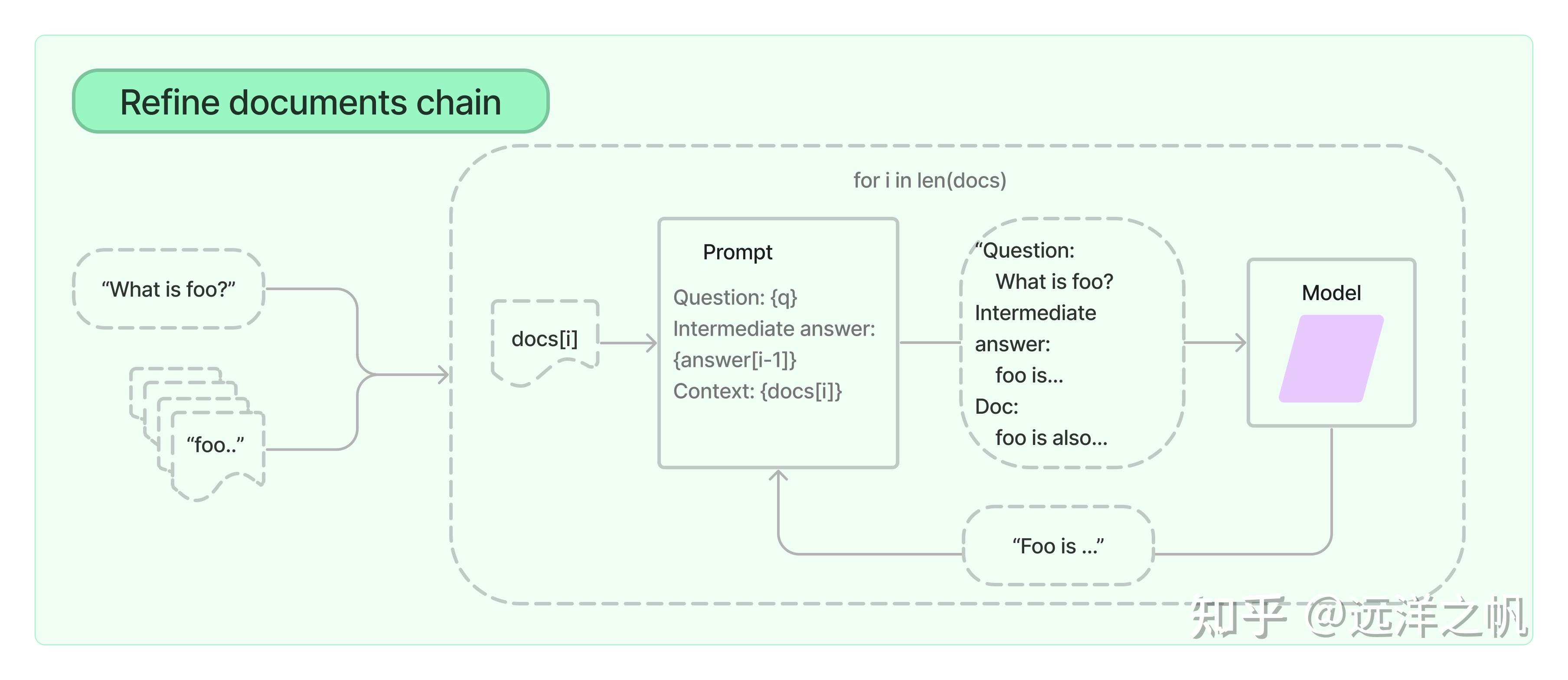
refine检索框架
细化文档链通过循环输入文档并迭代更新其答案来构建响应。 对于每个文档,它将所有非文档输入、当前文档和最新的中间答案传递给 LLM 链以获得新答案。
由于 Refine 链一次仅将单个文档传递给 LLM,因此它非常适合需要分析的文档数量多于模型上下文的任务。 明显的权衡是,该链将比 Stuff 文档链进行更多的 LLM 调用。 还有一些任务很难迭代完成。 例如,当文档频繁相互交叉引用或一项任务需要来自许多文档的详细信息时,Refine 链可能会表现不佳。
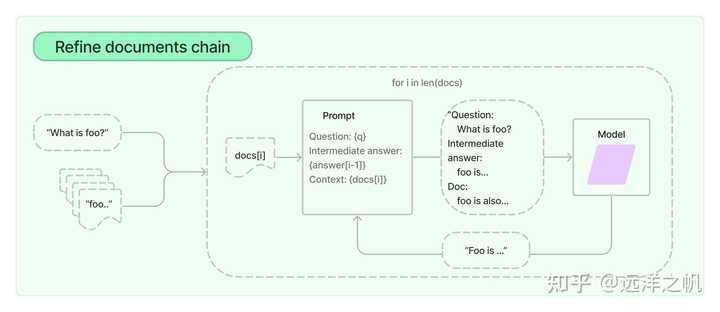

from langchain.chains import RetrievalQA ruff = RetrievalQA.from_chain_type( llm=llm, chain_type="refine", retriever=db.as_retriever() ) ruff.run(query)生成结果如下:


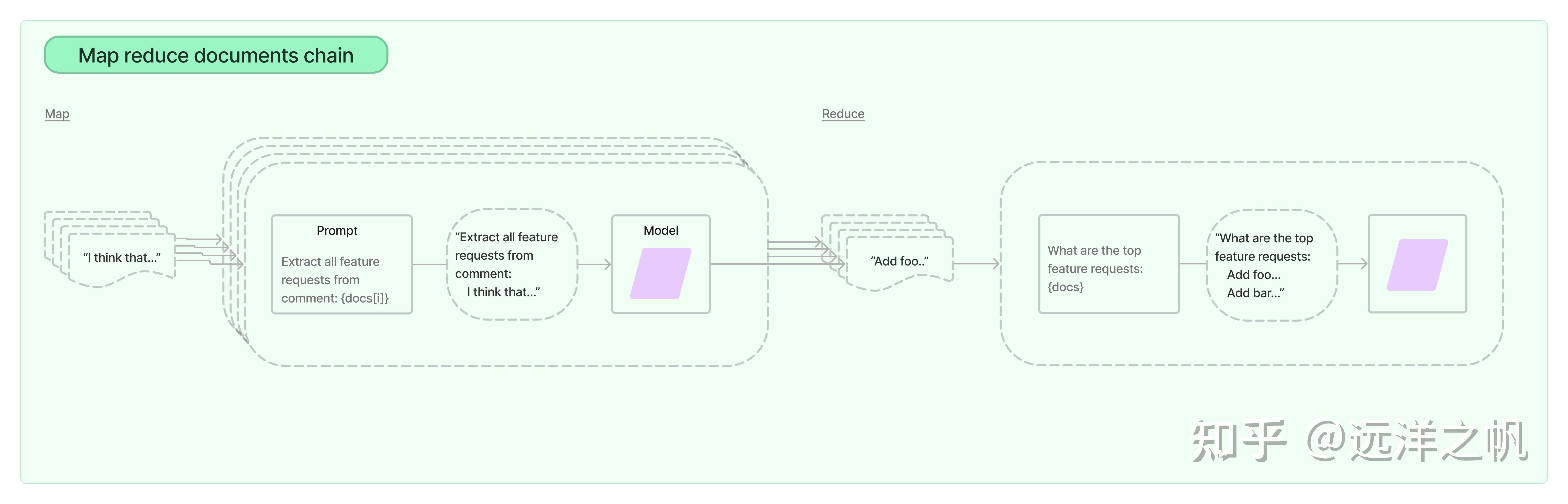
maprecude信息聚合检索框架
MapReduce 文档链首先将 LLM 链单独应用于每个文档(Map 步骤),将链输出视为新文档。 然后,它将所有新文档传递到单独的组合文档链以获得单个输出(Reduce 步骤)。 它可以选择首先压缩或折叠映射的文档,以确保它们适合组合文档链(这通常会将它们传递给LLM)。 如有必要,该压缩步骤会递归执行。
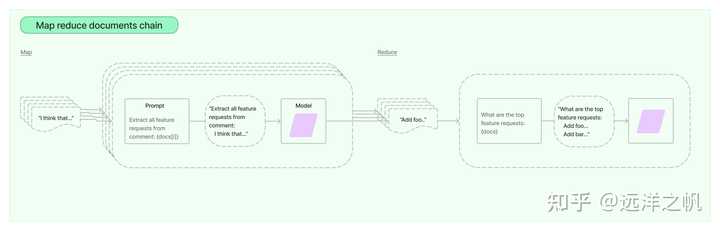

实现代码如下:
from langchain.chains import RetrievalQA ruff = RetrievalQA.from_chain_type( llm=llm, chain_type="map_reduce", retriever=db.as_retriever() ) ruff.run(query)生成效果如下:


用户自定义检索框架
上面介绍了几种端到端query向量数据库生成答案的方式,但往往这样的端到端生成方法无法满足我们需要。我们要如何去改进提高呢,要回答这个问题就要知道基于向量库生成答案到底做了什么事。拆看代码看其实就两部分:1.通过语意相似度召回相关资料 2.把召回的相关资料做了摘要总结生成答案。可以通过下面一个示例代码,看如何来把两个部分合成一个。
# 导入LLMChain并定义一个链,用语言模型和提示作为参数。 from langchain.chains import LLMChain chain = LLMChain(llm=llm, prompt=prompt) # 只指定输入变量来运行链。 print(chain.run("autoencoder")) # 定义一个第二个提示 second_prompt = PromptTemplate( input_variables=["ml_concept"], template="把{ml_concept}的概念描述转换成用500字向我解释,就像我是一个五岁的孩子一样", ) chain_two = LLMChain(llm=llm, prompt=second_prompt) # 用上面的两个链定义一个顺序链:第二个链把第一个链的输出作为输入 from langchain.chains import SimpleSequentialChain overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True) # 只指定第一个链的输入变量来运行链。 explanation = overall_chain.run("autoencoder") print(explanation)所以我们如果要定制化解决方案,其实只要把摘要生成答案部分加入策略就行了。具体代码如下,只要把你的约束策略放到prompt_template就定制化满足你的要求了。
from langchain.prompts import PromptTemplate prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. {context} Question: {question} Helpful Answer:""" PROMPT = PromptTemplate( template=prompt_template, input_variables=["context", "question"] ) chain = load_summarize_chain(llm, chain_type="stuff", prompt=PROMPT) chain.run(docs)把上面模块封装成Tool
#把基于向量库的检索生成封装成Tool ruff = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=db.as_retriever() ) tools = [ Tool( name="Ruff QA System", func=ruff.run, description="useful for when you need to answer questions about ruff (a python linter). Input should be a fully formed question.", ), ] #挂到Agent上测试效果 agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) agent.run( "What did biden say about ketanji brown jackson in the state of the union address?" )小结:
1.总体介绍了基于向量检索的框架,主要分为两大块:内容存储、内容检索
2.具体介绍了内容存储部分技术细节:数据加载模块、数据切块模块、数据embbeding模块、数据存储模块及代码实现
3.具体介绍了内容检索部分:向量相似度召回+基于上下文生成问题答案,实现原理和实现代码
4.介绍了如何把向量检索生成封装成tool供agnet使用
项目代码:https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/chatglm_agent
发布于 2023-07-19 18:14・IP 属地浙江查看全文>>
远洋之帆 - 2 个点赞 👍
这是好事,对社会对自身都是好事。chatglm是一众开源模型中表现不错的,但限于之前无法商业使用,大家不得不使用其他可以商业使用的。开源对自己也是好事,更多人使用,可以把生态做大,更多人使用也有更多人参与贡献,包括问答数据,框架优化,模型表现优劣都会更好暴露,更快完善。开源也会让更多在想从头训的人想一想要不要从头训,也减少了竞争对手。就像之前低价拉客一样,先把竞争对手干翻。
实际上,大模型本身没太大技术含量,拼的就是谁的算力多。百模大战,造成巨大财务浪费,唯一得利的是英伟达。
大模型应该国家发牌照搞,搞出来必须承诺全部开源。其他一律不准从头训。
发布于 2023-07-15 11:15・IP 属地上海查看全文>>
紫竹 - 2 个点赞 👍
这是跟我们走得最近的一家国内大模型了,去过他们总部很多次。
6B模型在测试阶段就一直在用,我始终觉得国内大模型不差在深度和基础之上,而是调教和管理的差距,可能是出于对这件事的不自信,GLM楼下那家我找人约了几次没约上,甚至直接生病卖公司了……
大家可以用这三种方式去试GLM,这是百试不爽的方法:
1,确认事实,
比如让他求证一些事实,你给他一些事实,让他对可疑的事实进行辨析。
2,数理分析,
从简单的数理推理到气象水文地理,甚至物理,请注意不能让他在黑盒中推理,必须依据数理,能算对那就继续复杂化。
3,人类社会不言自明的逻辑,
经典的爸爸能不能和妈妈结婚,可以派生出一系列的有趣提问。
这是我们社群统计出的三个最有效的可以深入提问的方法,
如果通过了,还有更狠的路子。
先这样。
发布于 2023-07-16 23:38・IP 属地北京查看全文>>
塔斯马尼亚雨林 - 1 个点赞 👍
这是一件好事,解除了开发者最大的顾虑,可以期待看到其生态的爆发。
首先,ChatGLM的中文表现在一众6B模型中中文表现还是不错的,这是其自身的实力部分。
其次,原来的商用价格并不低(群里有发过)。虽然用爱发电的人不在少数,但其中的中坚力量肯定是期望自己的努力未来能给自己带来收益的。商用限制一旦解除,那么大家在选择模型时就不用纠结太多了。
最后,ChatGLM虽然放弃了短期利益。但从长期来看,如果能保持其技术优势和性能,那么当前抢占市场的行为是合算的。毕竟“平台”和“生态”才是最大的商业价值点。无论是OpenAI还是HuggingFace,无外乎都想成为AI时代的基础设施。我相信ChatGLM团队也有这样的野心。
发布于 2023-07-15 13:07・IP 属地上海查看全文>>
Sleepy - 0 个点赞 👍
ChatGLM系列是这波ChatGPT热潮响应较早的一个开源LLM,今年3.14就发布了CG1. 相信很多小伙伴测试中文场景任务都是基于此入手的,效果再好,商用费用过高的话也不是谁都能玩的起。
后追上来的像百川智能,北京智源都分别发布了免费商用中英LLM baichuan系列. Aquila系列。开源的LLM之前拉开的性能差距并不大,对比之下,大都首选肯定还是能商用的。
LLM很重要,但更重要是用户,谁能更快速获取更多用户构建自家的生态,谁就更具主导优势。智谱AI&清华KEG这次调整促进社区LLM生态发展的同时,也极大提升自家LLM被选概率扩大其影响力。
发布于 2023-07-15 15:47・IP 属地北京查看全文>>
52AI - 0 个点赞 👍
查看全文>>
花甘者浅狐 - 0 个点赞 👍
查看全文>>
洪权 - 0 个点赞 👍
我有试用过几个大模型。chatglm表现算是比较优秀的。
不知道背后的团队对商业的支撑力度如何?毕竟他们的经济实力和一些顶尖大公司还是有差距。
发布于 2023-07-16 05:32・IP 属地湖北查看全文>>
白银时代