
就写一个答案就行了,简单揭露下网络上流行的文抄公式人物。

这个ID
,包括不少人应该都见过这一类ID,在什么苏联如何如何,前XX年如何如何一类问题下的回答,风格都很类似———中文英文俄文无所不包,资料详实,论据丰富,数据表格满满当当。给出来的结论当然基本都是些“历史真相”,比如苏联比你想象的牛逼多了,shi大淋时代就能开始明珠了,人人都能吃饱穿暖生活幸福,70年代就能造芯片了云云。这些文抄公的水平高明吗?其实低劣的可笑。随便什么人,只要有大学英语4级的水平,再有点正常上网的能力,翻翻喂鸡百科,找数据的脚注,如果是网站可以直接上,是书名就到电子书网站碰碰运气。甚至你也可以上俄文维基,反正现在翻译软件也做得很好。另外还可以经常去逛逛贴吧,再加几个所谓“大佬”的扣扣群,保存一下其他文抄公贴出来的截图,不用几个月你也就能成为“聚聚”、“大佬”中的一员。可以说,是一种很低成本满足虚荣心和自尊心的方式,非常适合各路闲的没事干的高中生、大学生or社会闲散人员在赛博空间里找存在感。
这么抄数据的问题在于,这类文抄公根本不可能读完那么多大部头著作,不知道这些数据是怎么产生的,更没有耐心仔细分析数据的含义,加上装13心切,往往是看到一张表格、几个数字就迫不及待拿出来炫耀,经常会犯下断章取义甚至南辕北辙的错误。
1.低劣可笑的障眼骗术
这位引用了Mark Harrison等人的The Economic Transformation of the Soviet Union, 1913-1945里的表格宣称,你们看,西方权威学者的科学估计,都说明了苏联粮食生产比沙俄强!你们不能再说苏联粮食生产不如沙俄了吧!这不是苏联自己的统计哦,是西方专家估的,你们没话讲了吧!
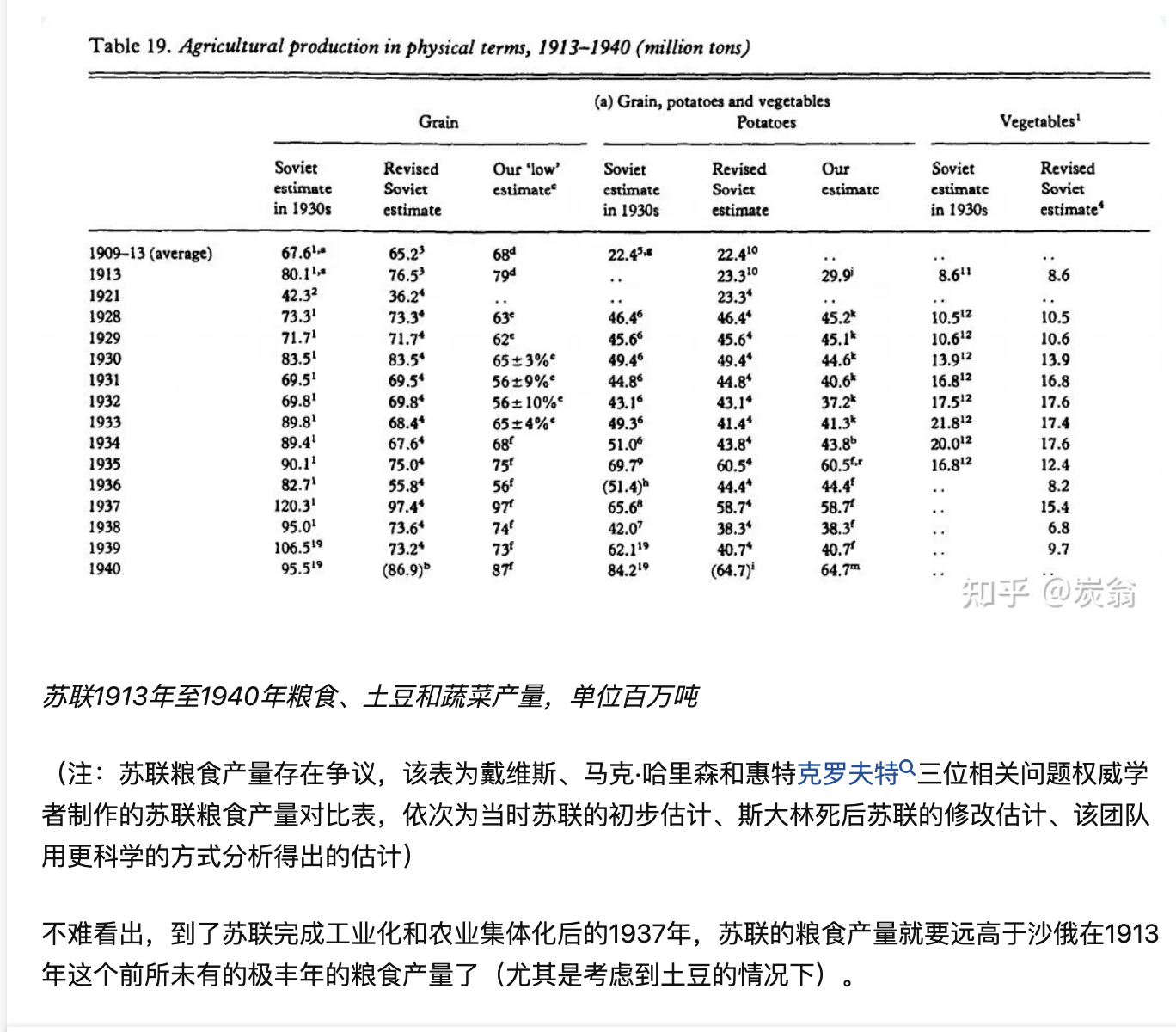
然而你稍微抬抬眼往下、往上看看,立刻就能发现——1913年当然是沙俄粮食生产的“极丰值”,而1937年的苏联粮食生产则更是个苏联粮食生产的“极丰值”,远高于之前和之后的1936和1938年。用马前卒的话来讲,这就是假设自己的读者是傻子。
实际上,我们简单做个计算就能发现,以二战/一战前的五年平均对比,1936-1940里第三列的平均值是7740万吨,仅仅比1909-1913的平均值高出了14%,远低于1937之于1913高出22%的“辉煌成绩”低得多。
2.南辕北辙的断章取义。
当然了,我知道有人要说了:凭什么多14%就不算说明苏联的粮食生产比沙俄优越?多14%也是多!多了就赢了!苏维埃万岁!这位也是这么回应的:1938以后的苏联粮食产量也都超过沙俄了!

(记住
反复宣称的“这张表告诉我们,1938年及之后苏联完成工业化以后粮食产量就已经超过沙俄了”)那这张表能证明苏联的粮食生产比沙俄强么?真的像
告诉告诉你们的一样,说明了苏联的“完成工业化的1937年”和以后,苏联的粮食产量比沙俄高了吗?非常遗憾,依然不能。
其实你再仔细看看这张表,就能感觉到不对劲——作者估计苏联粮食产量的这一列,1928-1933的产量数字跟苏联官方和俄联邦官方的统计结果均不相同,怎么到了1934年以后,就变成了跟第二列官方数据一致?
如果你眼神再好一点,1928-1933这几行的下角标是e,而1934-1940年这几行的下角标是f。那这两个下角标告诉了我们什么呢?

简单来说,在1928-1932年,作者扣掉了官方数据中可笑的“修正系数”,重估了苏联的粮食产量,发现苏联的粮食生产数据大大高估了。而1934-1939的俄联邦官方数据中不包括“田野收获”,所以作者这里就直接摘抄过来了,但这里作者专门强调了,1937-1940年的粮食收获数据极有可能夸大了(probably exaggerated)。
实际上,与这位答主试图传达给我们的信息相反。Mark Harrison在探讨苏联农业产量数据的这一章节,详细论述了苏联当局是如何用可笑的手法系统性编造粮食产量数据的。
In the 1930s the authorities frequently announced that the 'problem of grain' had been solved. The official figures published at that time purported to show that, after a couple of poor harvests in 1931 and 1932, grain output rose by 1937 to a record 120 million tons, 64 per cent above the 1928 level and 50 per cent higher than the highest pre-revolutionary harvest in 1913. But these figures involved a deliberate distortion of the statistics. In official Soviet statistics from 1933 onwards grain output was measured — without any indication that this was the case — not as the harvest which reached the barns but in terms of 'biological' yield. This was the maximum possible yield of the standing crop in the field at time of maximum ripeness. It was estimated by taking samples from a variety of fields using a metrovka (a one-metre square device); the samples were threshed and the grain obtained was weighed. The total harvest was measured by multiplying this measured yield per square metre by the estimated sown area. Thus the 'biological' harvest made no allowance for losses between field and barn. But in reality losses amounted to 15 per cent or so at best; they rose to over 30 per cent in some years. Until 1936 some allowance was made for losses, though an inadequate one; from 1937 no harvest losses at all were deducted. It was not until 1956, three years after Stalin's death, that the Soviet authorities admitted that the harvest figure as published was measured without deduc-tion of losses. The new series for 1933-40 which has since been published is probably a reasonably accurate measurement of the barn harvest in 1933-6, but it is likely that the harvests for 1937-40 are still exaggerated in the new series (see Table 19, note f.)
20世纪30年代,当局频繁宣布“粮食问题”已经解决。当时公布的官方数据据称表明,在经历了 1931 年和 1932 年的几次歉收之后,粮食产量到 1937 年增加到创纪录的 1.2 亿吨,比 1928 年的水平高出 64%,比革命前的收成最好的1913年高了50%。但这些数字涉及故意歪曲统计数据。从 1933 年起,苏联的官方统计数据中,粮食产量的衡量标准——没有任何迹象表明情况确实如此——不是按照到达谷仓的收获量,而是按照“生物”产量来衡量。这是田间未收作物在最大成熟时的最大可能产量。它是通过使用metrovka(一种一米见方的设备)从各个田地采集样本来估算的;将样品脱粒并称重所获得的谷物。总收成通过将测量的每平方米产量乘以估计的播种面积来测量。因此,“生物”收获没有考虑田地和谷仓之间的损失。但实际上,损失在最好的情况下也只有 15% 左右;在某些年份,这一比例上升至 30% 以上。 1936 年之前,政府对损失进行了一定的冗余,尽管不足。从 1937 年起,根本没有扣除任何收成损失。直到1956年,即斯大林去世三年后,苏联当局才承认公布的收成数字是在没有扣除损失的情况下计算的。此后发布的 1933-40年新的统计数字序列可能是对 1933-6年谷仓收成的相当准确的测量,但新序列中 1937-40 年的收成可能仍然被夸大(见表 19,注 f。)
But the distortions from 1933 onwards are not the whole story. In the 1920s the statisticians preparing the grain data attempted to obtain an accurate figure for the barn harvest. The raw data obtained from the peasants were certainly underestimated, so 'correction coefficients' were applied, increasing the harvest as measured by the raw data from the peasants. From 1926 onwards these correction coefficients were almost certainly too large. They were estimated under the influence of Gosplan, which believed that both pre-revolutionary and post-revolutionary grain output were higher than the estimates made by the rival Central Statistical Administration. And from 1929 onwards strong political pressure was brought to bear on the statisticians to 'improve' grain production by increasing the correction coefficients still further. In our opinion all the grain figures for 1926-1932 therefore need to be reduccd by an annual percentage which systematically increases over the period. Data in the archives for the harvest of 1932 reveal that both the yield per hectare in kolkhozy and the sown area actually harvested were substantially below the figures used to estimate grain production; the 1932 harvest probably amounted to only 50-55 million tons, a mere 72-9 per cent of the official figure." On our provisional estimate the exaggeration of grain production in 1930-2 had already reached some 20-30 per cent, so that the harvests in 1931 and 1932 were lower than in any post-revolutionary year except the famine year 1921. These reductions in the published figures have not been made in Soviet published data, but we have made them in our own estimates.
但 1933 年以来的扭曲并不是故事的全部。 20 年代,准备谷物数据的统计学家试图获得谷仓收成的准确数据。 从农民那里获得的原始数据肯定被低估了,因此应用了“校正系数”,增加了根据农民的原始数据衡量的收成。 从 1926 年开始,这些修正系数几乎肯定太大了。 这些估计是在国家计划局的影响下进行的,该计划局认为革命前和革命后的粮食产量都高于竞争对手中央统计局的估计。 从 1929 年起,统计人员受到强大的政治压力,要求通过进一步提高修正系数来“改善”粮食生产。 因此,我们认为 1926 年至 1932 年的所有粮食数据都需要按年度百分比减少,并在此期间系统地增加。 1932 年收成档案中的数据显示,集体农庄的每公顷产量和实际收割的播种面积都大大低于用于估计粮食产量的数字; 1932年的收成可能只有50-55百万吨,仅占官方数字的72-9%。”根据我们的临时估计,1930-2年的粮食产量已经夸大了约20-30%,因此 1931年和1932年的收成低于除1921年饥荒之外的任何革命后年份。苏联公布的数据中并未对公布的数字进行这些减少,但我们在自己的估计中进行了减少。
简而言之,苏联官方的数据中包含两项造假方式:因为农民可能低报粮食生产数据逃避官方粮食征购,故引入了“修正系数”来高估粮食生产水平,但这反而可能夸大粮食产量;而从1934年开始,官方开始逐渐使用田里的生产数据直接当成“粮食产量”而非正常国家统计中的谷仓收纳量,那些散落在地里未收割或者沿途撒落无法利用的粮食也被计算在内。第二项造假在shi大淋去世以后被重估了,然而由于1937年以后苏联官方的夸大相当过分,因而后来的修正数据很可能也未能反映真实的粮食产量。
顺便我们也就回答了这个问题——唯生产力论对还是不对?
当然不对,苏联就向我们证明了,1913年过去了20多年后,苏联人兴修了许多水利设施、广泛运用拖拉机和开始施用化肥以后(1938年苏联化肥施用320万吨,相当于半个四三方案),苏联粮食生产仍然不能明显胜过沙俄。这还不足以说明糟糕的制度能对生产力造成多大破坏吗?
3.结语:无视文抄公
这类ID其实没必要特意针对,以前不少,以后也不会少。他们详细的数据、复杂的表格并不是为了说明和证明任何东西,而仅仅是为了唬晕读者,让你误认为他们很有能力。你如果认真分析几个类似的ID的回答帖子,就会发现,他们资料很多,但大多数都是在东拉西扯、与主题无关,涉及到最关键地方的时候论据和逻辑其实相当薄弱。
实际上,当你看到纷繁复杂表格的时候就要去想一个问题——这个作者现实中的身份是什么?他真的有能力驾驭这些资料吗?如果他能啃下那么多大部头、积累那么多专业知识,他为什么不到专业刊物上去投稿?为什么不拿现实中大学的教职,而是要跑到知乎上发网帖?
如果这些问题不能辨别,你也没有精力去分辨这些数据和表格的真假,那直接无视他们就好了。因为要审查他们的答案太费时间了,要真的想读专业论文,出门右转知网比较好。
比如我这个答案,仅仅说明为了一张表格的真实含义是什么,就需要一个几千字的回答。而这位洋洋洒洒,东抄西编的数据,表格拿起来就用,造假成本与审查成本完全不成正比,这类人士还是不要搭理便好。