通义千问更新 Qwen3 升级版,性能超越Kimi K2 和 DeepSeek V3,有哪些技术亮点?

- 224 个点赞 👍
短的结论:"鸡"立鹤群的非推理模型
基本信息:- 成本:$0.85每百万(基于OpenRouter平台)
- 平均长度:约7600字
- 速度:约38字每秒
- 平均耗时: 214秒
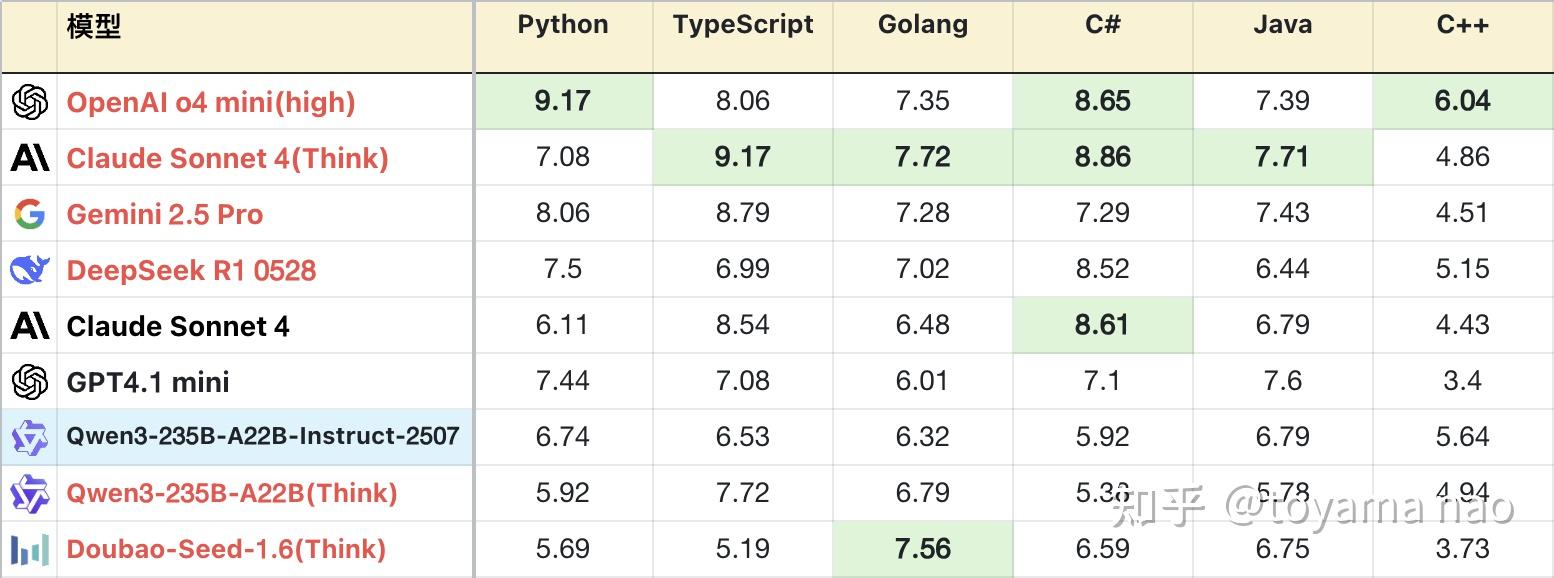
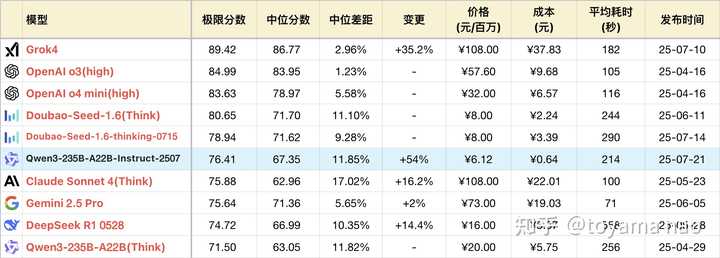
逻辑成绩:
*表格为了突出对比关系,有一定裁剪,不是完整排序
**测试方式:参见大语言模型-逻辑能力横评 25-06月榜(R1/Gemini 2.5/Doubao-Seed-1.6...
***完整榜单更新在Github
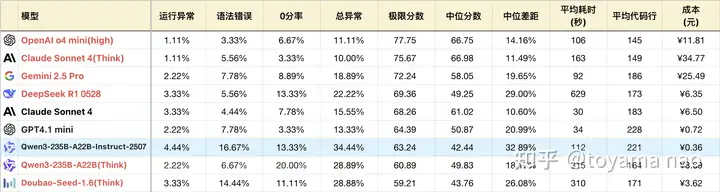
编程成绩: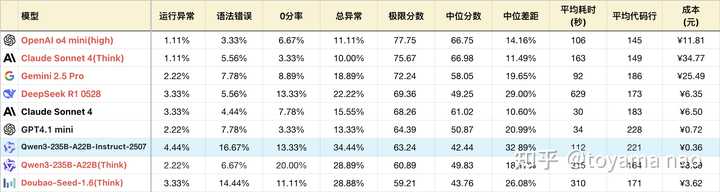
编程语言分布: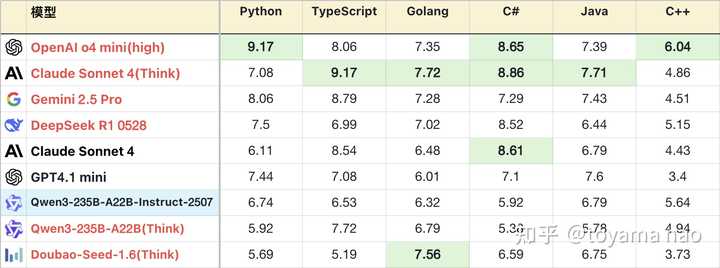

Qwen3系列的基础打的好,模型尺寸齐全,且都支持推理和非推理。其中235B推理版在发布之初就超越同为国产的R1和doubao1.5,拿下当时的国产第一。不过2个月后再被新版R1和doubao反超。但这次Qwen团队拿出来打头阵的不是其推理模型的迭代,而是235B基础版。
新版235B站在前辈的肩膀上,按大模型常见的左脚踩右脚升天的规律,新款取得巨大进步也在情理之中,上一次基础模型杀进推理模型梯队还是DeepSeek V3的新版,当时V3也是极限成绩提升50%,直逼自家的R1。但这次235B的进步有一些惊人,其逻辑能力超越自己的旧版推理版本,在实际任务的编程表现上同样如此。放在全体推理模型里,一个非推理模型有如此表现也算“鸡”立鹤群了,不过这只“鸡”恐怕是落地的凤凰假扮的。
不过话说回来,新版235B和初代比,变化大的已经不像同一个模型了。初代平均耗时仅19秒,新版涨到214秒,仅比自家推理模型低一点。输出长度也涨到7600字,甚至高于之前kimi k2的7300字,是非推理模型的最高长度。
因此再跟235B初代基础版本对比已经意义不大了,下面对比新版235B与其初代的推理版本(以下称旧版)。
优势:- 数学计算:新版计算能力,尤其计算精度上有不小提升。在一些并非显而易见的推理计算问题上,新版表现也可圈可点,如#28题变换了数学符号的定义,新旧版得分相同,但新版稳定性更好。#29题需要从结果反推数学符号的含义,本身不是计算题,但推理过程需要大量计算,旧版因为误差积累,导致推导失败,得分较低,而新版可以稳定拿到满分。
- 指令遵循:得益于其上下文幻觉的优化,新版指令遵循略强于旧版,在长指令问题上表现尤其明显。如#40代码推导,#39火车订票,#20桌游模拟,新版得分都更高。不过新版尚不能在多pass中稳定遵循指令,这一点被其他正牌推理模型拉开差距。
- 字符能力:在之前,字符类问题是非推理模型难以跨越的鸿沟,但235B新版的字符推理能力不输推理模型,在#9单词缩写这类基础问题上拿到高分,在#37三维投影这类复杂且大量的字符问题上,新版也有概率取得满分,高于旧版。在预计8月新增的题目中有一道难度极大的字符问题,新版表现也好过大部分推理模型,在后续的评测中会对这部分进行深度解读,此处按下不表。只用于证明新版并没有背题,而是实打实的能力。
- 编程知识:新版对不同编程语言的掌握程度好于旧版。且分布均匀,没有明显偏科。其总异常中大部分语法错误由C#和C++贡献,还有改进空间。
不足:- 解空间优化:一些问题具有诱导性,低阶模型往往掉入陷阱进行暴力遍历求解,但这类问题都存在缩小解空间的技巧。这也是区分模型是否具有足够智力的关键。新版在这方面表现尚可,但有缺陷。如#23密码解密,新版消耗约一半Token(约4000)寻找秘钥,再用一半Token反复验算。但对比豆包1.6(Think),通过观察密文结构快速锁定解范围,答题仅用不到4500 Token,Gemini 2.5 Pro更是只用了2700 Token。#35拼图问题也存在技巧,但新版解答偏暴力,消耗颇高,答案也并不正确。
- 英文输出:不可控的中途切换到英文进行输出,并且中英文夹杂。
赛博史官曰:
压缩即智能,这方面做的最好的是OpenAI家的o3/o4系列,其次是Anthropic家的Claude系列,他们的推理模型和非推理模型在答题Token开销上基本都是最低一档。但在没有那样技术之前,给大模型多一些思考时间和输出空间以换取更高智力也并非不可取。
在235B新版上,能看到诸多Qwen团队努力修复初代各类细小问题的努力,这些细流一样的修复汇聚,累积,最终汇合成奔腾的江河,在名为大模型的海洋上翻涌出一朵漂亮的浪花。
目前所有评测文章在公众号:大模型观测员 同步更新。还没有人送礼物,鼓励一下作者吧继续追问
由知乎直答提供查看全文>>
toyama nao - 90 个点赞 👍
在与开发者朋友们持续交流和深入思考后,我们更新了非思考模式(Non-thinking)的旗舰版Qwen3模型,升级推出新模型Qwen3-235B-A22B-Instruct-2507,并同步开源其FP8版本。
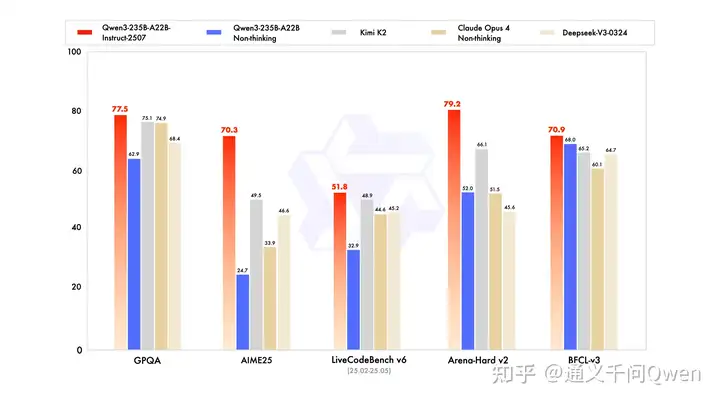
新的Qwen3模型,通用能力显著提升,包括指令遵循、逻辑推理、文本理解、数学、科学、编程及工具使用等方面,在GPQA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent能力)等众多测评中表现出色,超过Kimi-K2、DeepSeek-V3等顶级开源模型以及Claude-Opus4-Non-thinking等领先闭源模型。
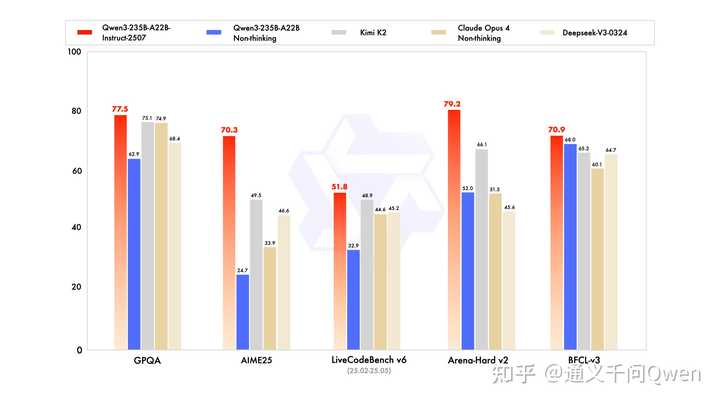
此外,本次更新的Qwen3模型,还增强了以下关键性能:
-在多语言的长尾知识覆盖方面,模型取得显著进步。
-在主观及开放性任务中,模型显著增强了对用户偏好的契合能力,能够提供更有用的回复,生成更高质量的文本。
-长文本提升到256K,上下文理解能力进一步增强。
详细跑分可见下表:
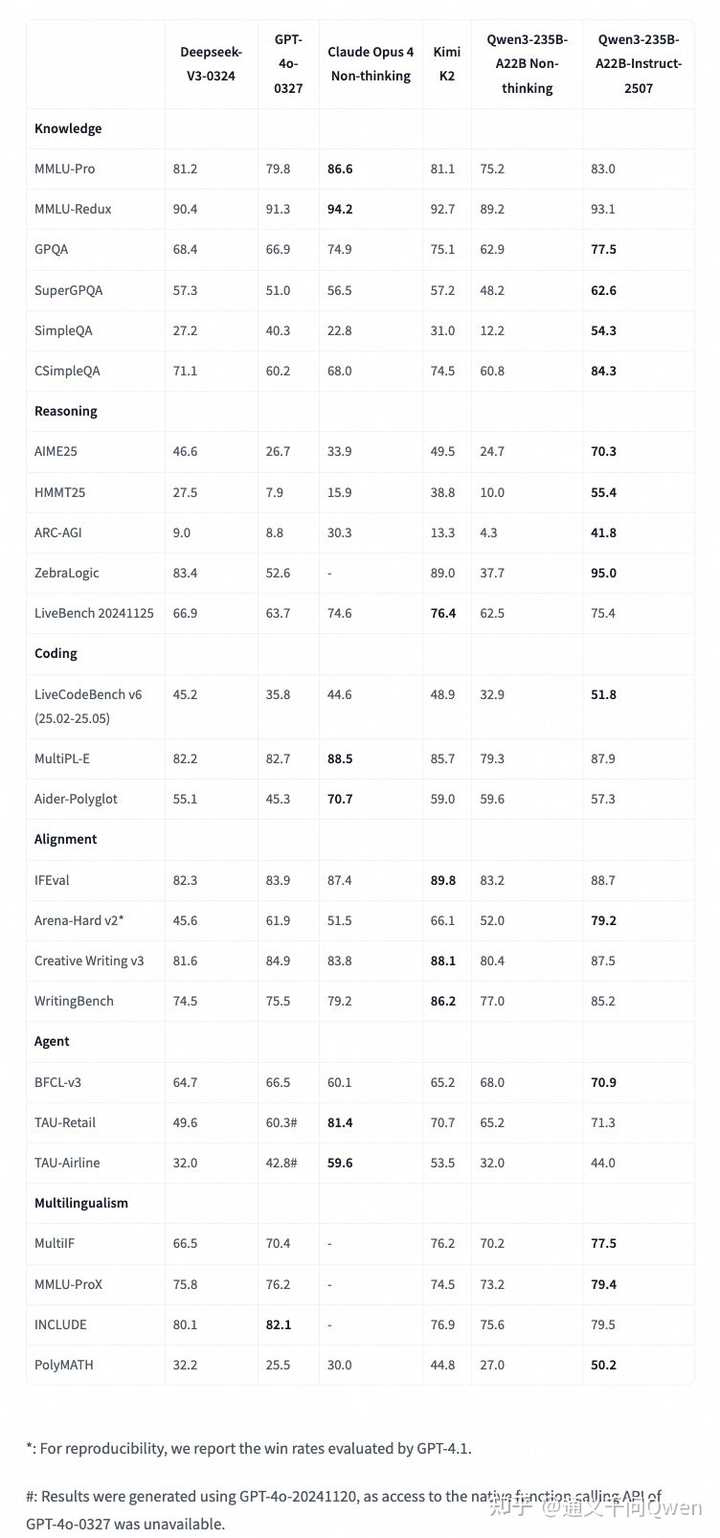
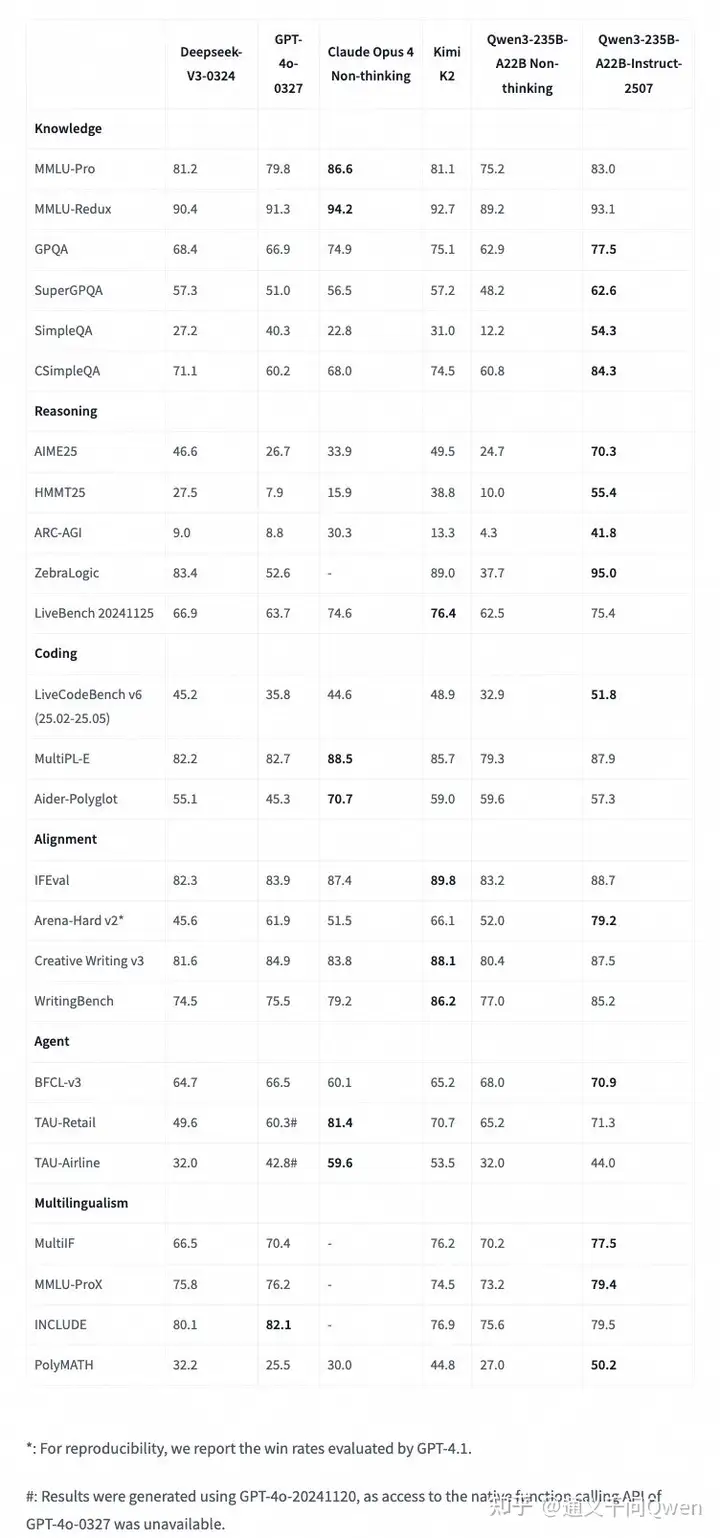
这次发布的模型更聪明,知道更多,能做更多任务,尤其在代理类任务中表现更佳,我们诚邀您亲自体验!
模型体验和下载:
Qwen Chat:https://chat.qwen.ai(默认即为新模型)

Hugging Face:<br/>https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
ModelScope 魔搭社区:<br/>通义千问3-235B-A22B-Instruct-2507
通义千问3-235B-A22B-Instruct-2507-FP8
模型评测结果请见 Hugging Face 模型卡:<br/>https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
更多重磅更新,敬请期待!
大家对本次 Qwen3 升级怎么看?欢迎在评论区留言或在话题下讨论,期待大家的反馈~查看全文>>
通义千问Qwen - 16 个点赞 👍
查看全文>>
橘鸦Juya - 14 个点赞 👍
其实我是没太看懂,最近这波对于【非推理模型的推理能力】的卷意义在哪里。
在RL过程中,把think和/think去掉,让模型直接给题解进行RL,模型也能不断RL出解题能力,输出也会和加了think一样不断变长。这种情况下解题能力高于base model但低于加了think可以获得的解题能力。
但我没看懂这么做意义在哪里,谁来给我解释一下……
查看全文>>
还是不注名好 - 6 个点赞 👍
前言:
五月份的时候,第一版千问3发布,我快速测试了一下,发现“高分低能”的现象非常明显,于是实名怒喷了一下:
“刷榜”太过,Qwen3没有新意,指令跟随都没做好 - 强化学徒的文章 - 知乎 https://zhuanlan.zhihu.com/p/1905924936410825509
今天早上千问3发布了一个最新版,将推理能力去除了,重新训练了一个no-thinking版本的旗舰模型。
大家可以在他们官网免费测试,不用开“深度思考”:https://chat.qwen.ai
今天晚上比较巧的是,群里朋友对千问是否刷榜,刷榜是否有意义,争论十分激烈,所以,我想着来体验一下,看看效果到底如何。
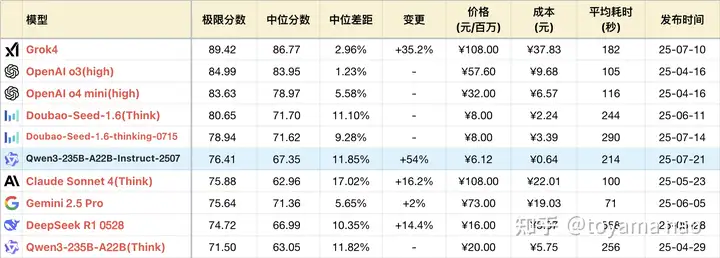
首先,我们看他们自己公布的榜单:
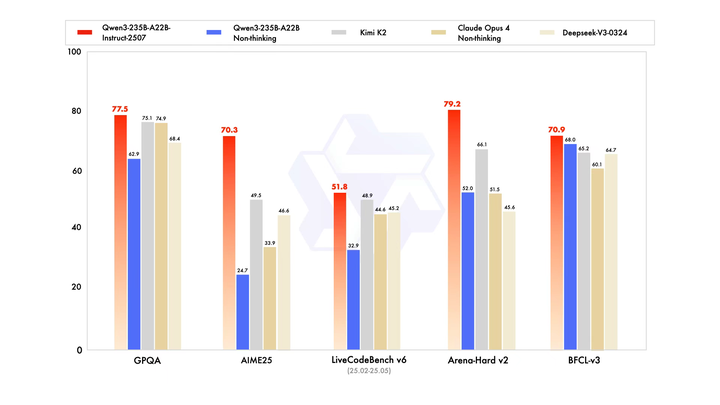
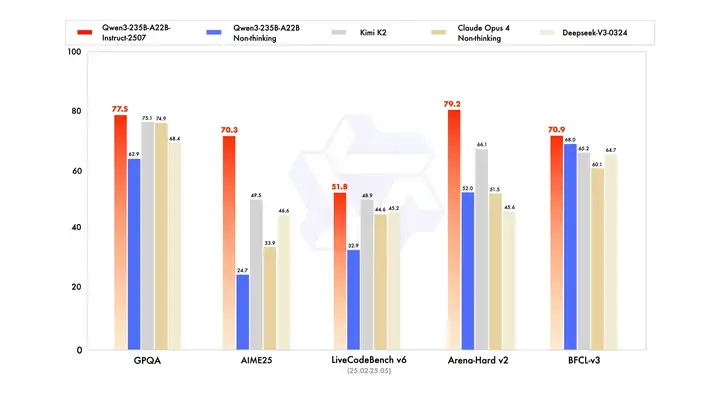
2507这个数值相对确实比较高 但早上看到的时候,我还是很怕又一次的“高分低能”。
中午的时候,看到toyama的评测,效果还可以:
通义千问更新 Qwen3 升级版,性能超越Kimi K2 和 DeepSeek V3,有哪些技术亮点? - toyama nao的回答 - 知乎 https://www.zhihu.com/question/1930932168365925991/answer/1930972327442646873
然后晚上,我自己也简单问了一下,整体来看,智力是有的,闲聊会有惊喜的回答。
我主要的评测问题,是我的知乎提问: https://www.zhihu.com/people/heda-he-28/asks
我贴一下其中的一些问题:
如何抓住“低垂的果实”:这个的见解比较普通:https://chat.qwen.ai/s/6797111e-2289-451c-be01-553318d9e783?fev=0.0.153
背诵滕王阁序全文: 正确背出。https://chat.qwen.ai/s/ca2816c0-8fc2-4e97-a403-fd91332efe7a?fev=0.0.153
学术抄袭与维权指南:著作权法第24条回答正确。https://chat.qwen.ai/s/f97caba0-be89-4ce0-9b9f-ce615626d9c1?fev=0.0.153
AI脑内助手的非金融应用设想:一些常见的回答。https://chat.qwen.ai/s/288dc517-3837-4a36-ac85-d9c6ba8a8d8f?fev=0.0.153
技术人如何与AI共舞:常见回答。https://chat.qwen.ai/s/288dc517-3837-4a36-ac85-d9c6ba8a8d8f?fev=0.0.153 2025
知乎值得关注AI博主:没学习我的帖子,所以回答的不太好!https://chat.qwen.ai/s/3df0f441-40f8-466c-bbb7-25ec198d19b4?fev=0.0.153
人脑与AI的进化类比:有个比喻有点意思:训练方式 :进化是“预训练”,学习是“上下文学习 + 微调”。https://chat.qwen.ai/s/4801ff0a-64d2-4035-aaf1-323b18d1b427?fev=0.0.153
强化学习机制与负奖励作用:我的两次追问比较有趣。https://chat.qwen.ai/s/07d2d644-dc30-4e19-a3a9-7e0198d6709a?fev=0.0.153
盛世难全历史哲思:假设案例:一个生于“开元元年”(713年)、卒于“天宝初年”(745年)的长安城中产市民,享年约32岁,一生经历开元盛世,未遇安史之乱。哈哈哈,确实盛世,但似的也太早了~~。https://chat.qwen.ai/s/351a4907-1dd9-4dac-b540-3a95f0344111?fev=0.0.153
没来得及测试更多的代码功能,群友有测试过一个比较复杂的数学题,能答对,不过我觉得常见数学题,对它来说,应该是舒适区了。
查看全文>>
强化学徒