
短的结论:"鸡"立鹤群的非推理模型
基本信息:
- 成本:$0.85每百万(基于OpenRouter平台)
- 平均长度:约7600字
- 速度:约38字每秒
- 平均耗时: 214秒
逻辑成绩:
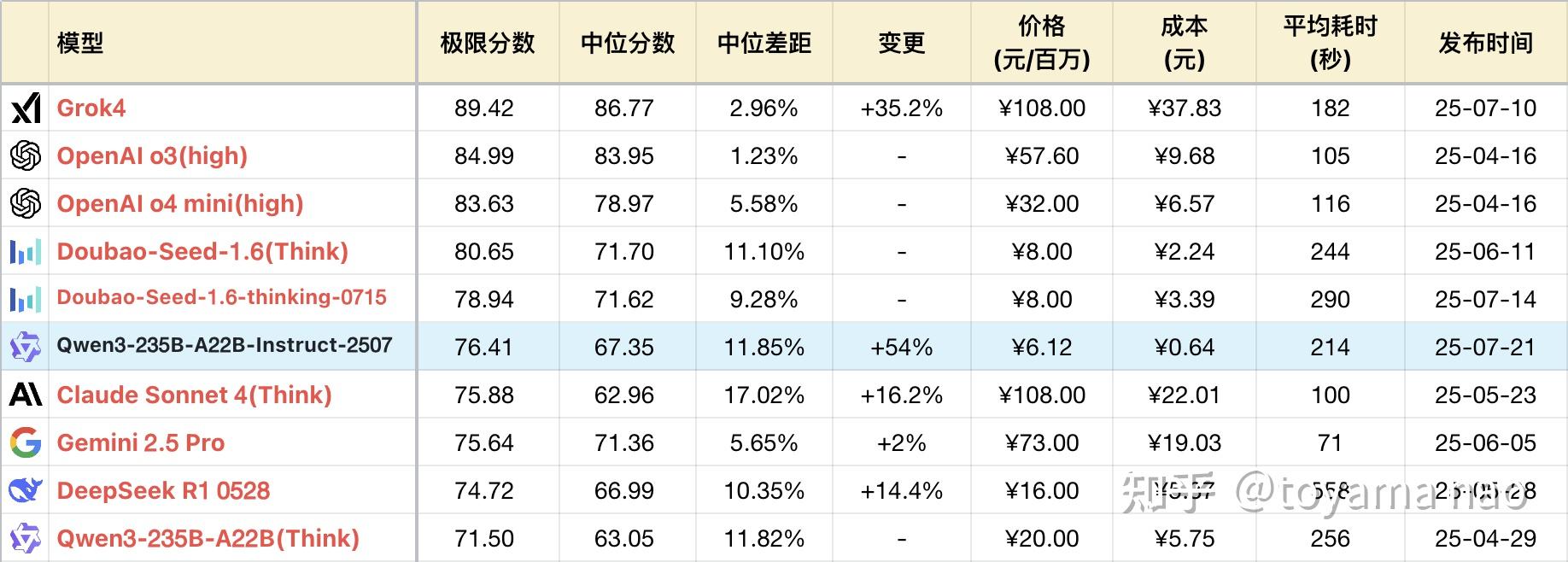
*表格为了突出对比关系,有一定裁剪,不是完整排序
**测试方式:参见大语言模型-逻辑能力横评 25-06月榜(R1/Gemini 2.5/Doubao-Seed-1.6...
***完整榜单更新在Github
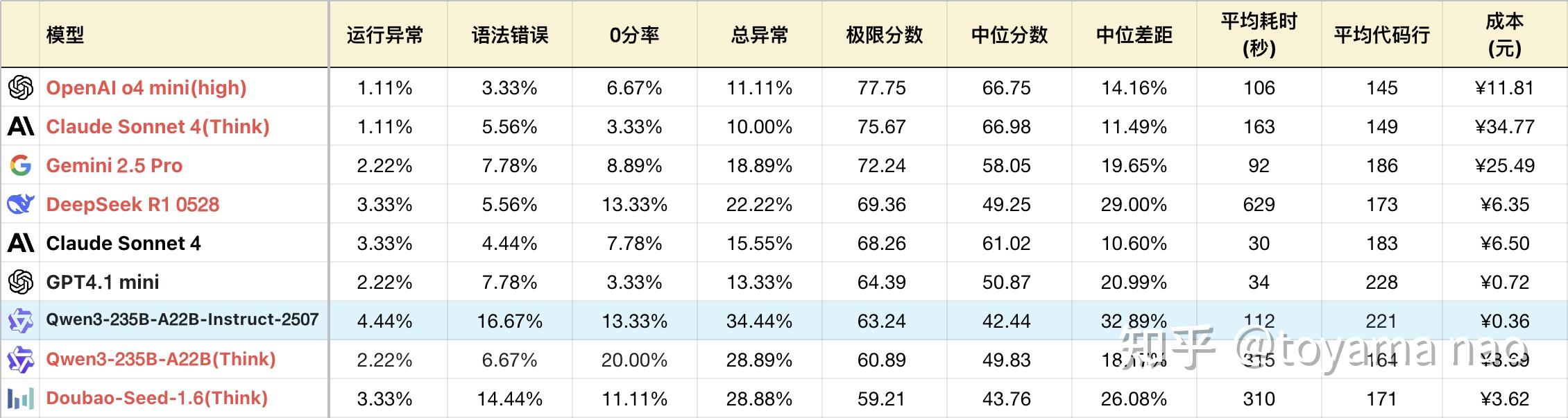
编程成绩:
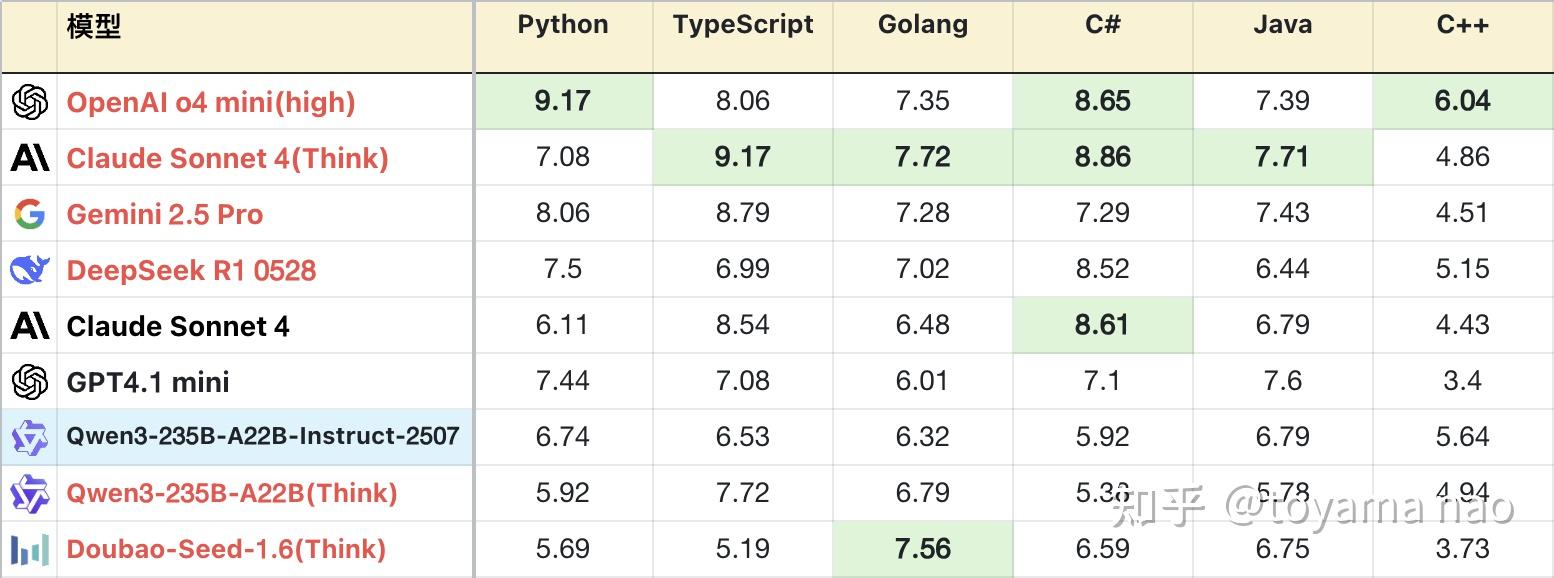
编程语言分布:
Qwen3系列的基础打的好,模型尺寸齐全,且都支持推理和非推理。其中235B推理版在发布之初就超越同为国产的R1和doubao1.5,拿下当时的国产第一。不过2个月后再被新版R1和doubao反超。但这次Qwen团队拿出来打头阵的不是其推理模型的迭代,而是235B基础版。
新版235B站在前辈的肩膀上,按大模型常见的左脚踩右脚升天的规律,新款取得巨大进步也在情理之中,上一次基础模型杀进推理模型梯队还是DeepSeek V3的新版,当时V3也是极限成绩提升50%,直逼自家的R1。但这次235B的进步有一些惊人,其逻辑能力超越自己的旧版推理版本,在实际任务的编程表现上同样如此。放在全体推理模型里,一个非推理模型有如此表现也算“鸡”立鹤群了,不过这只“鸡”恐怕是落地的凤凰假扮的。
不过话说回来,新版235B和初代比,变化大的已经不像同一个模型了。初代平均耗时仅19秒,新版涨到214秒,仅比自家推理模型低一点。输出长度也涨到7600字,甚至高于之前kimi k2的7300字,是非推理模型的最高长度。
因此再跟235B初代基础版本对比已经意义不大了,下面对比新版235B与其初代的推理版本(以下称旧版)。
优势:
- 数学计算:新版计算能力,尤其计算精度上有不小提升。在一些并非显而易见的推理计算问题上,新版表现也可圈可点,如#28题变换了数学符号的定义,新旧版得分相同,但新版稳定性更好。#29题需要从结果反推数学符号的含义,本身不是计算题,但推理过程需要大量计算,旧版因为误差积累,导致推导失败,得分较低,而新版可以稳定拿到满分。
- 指令遵循:得益于其上下文幻觉的优化,新版指令遵循略强于旧版,在长指令问题上表现尤其明显。如#40代码推导,#39火车订票,#20桌游模拟,新版得分都更高。不过新版尚不能在多pass中稳定遵循指令,这一点被其他正牌推理模型拉开差距。
- 字符能力:在之前,字符类问题是非推理模型难以跨越的鸿沟,但235B新版的字符推理能力不输推理模型,在#9单词缩写这类基础问题上拿到高分,在#37三维投影这类复杂且大量的字符问题上,新版也有概率取得满分,高于旧版。在预计8月新增的题目中有一道难度极大的字符问题,新版表现也好过大部分推理模型,在后续的评测中会对这部分进行深度解读,此处按下不表。只用于证明新版并没有背题,而是实打实的能力。
- 编程知识:新版对不同编程语言的掌握程度好于旧版。且分布均匀,没有明显偏科。其总异常中大部分语法错误由C#和C++贡献,还有改进空间。
不足:
- 解空间优化:一些问题具有诱导性,低阶模型往往掉入陷阱进行暴力遍历求解,但这类问题都存在缩小解空间的技巧。这也是区分模型是否具有足够智力的关键。新版在这方面表现尚可,但有缺陷。如#23密码解密,新版消耗约一半Token(约4000)寻找秘钥,再用一半Token反复验算。但对比豆包1.6(Think),通过观察密文结构快速锁定解范围,答题仅用不到4500 Token,Gemini 2.5 Pro更是只用了2700 Token。#35拼图问题也存在技巧,但新版解答偏暴力,消耗颇高,答案也并不正确。
- 英文输出:不可控的中途切换到英文进行输出,并且中英文夹杂。
赛博史官曰:
压缩即智能,这方面做的最好的是OpenAI家的o3/o4系列,其次是Anthropic家的Claude系列,他们的推理模型和非推理模型在答题Token开销上基本都是最低一档。但在没有那样技术之前,给大模型多一些思考时间和输出空间以换取更高智力也并非不可取。
在235B新版上,能看到诸多Qwen团队努力修复初代各类细小问题的努力,这些细流一样的修复汇聚,累积,最终汇合成奔腾的江河,在名为大模型的海洋上翻涌出一朵漂亮的浪花。
目前所有评测文章在公众号:大模型观测员 同步更新。