DeepSeek到底是“蒸馏”还是“原创”?
英伟达主任工程师陈源博士发文称:DeepSeek是用模型蒸馏技术做出来的,它是通过已有的大模型蒸馏出小模型,再用少量数据对这些小模型进行微调而成。

- 83 个点赞 👍
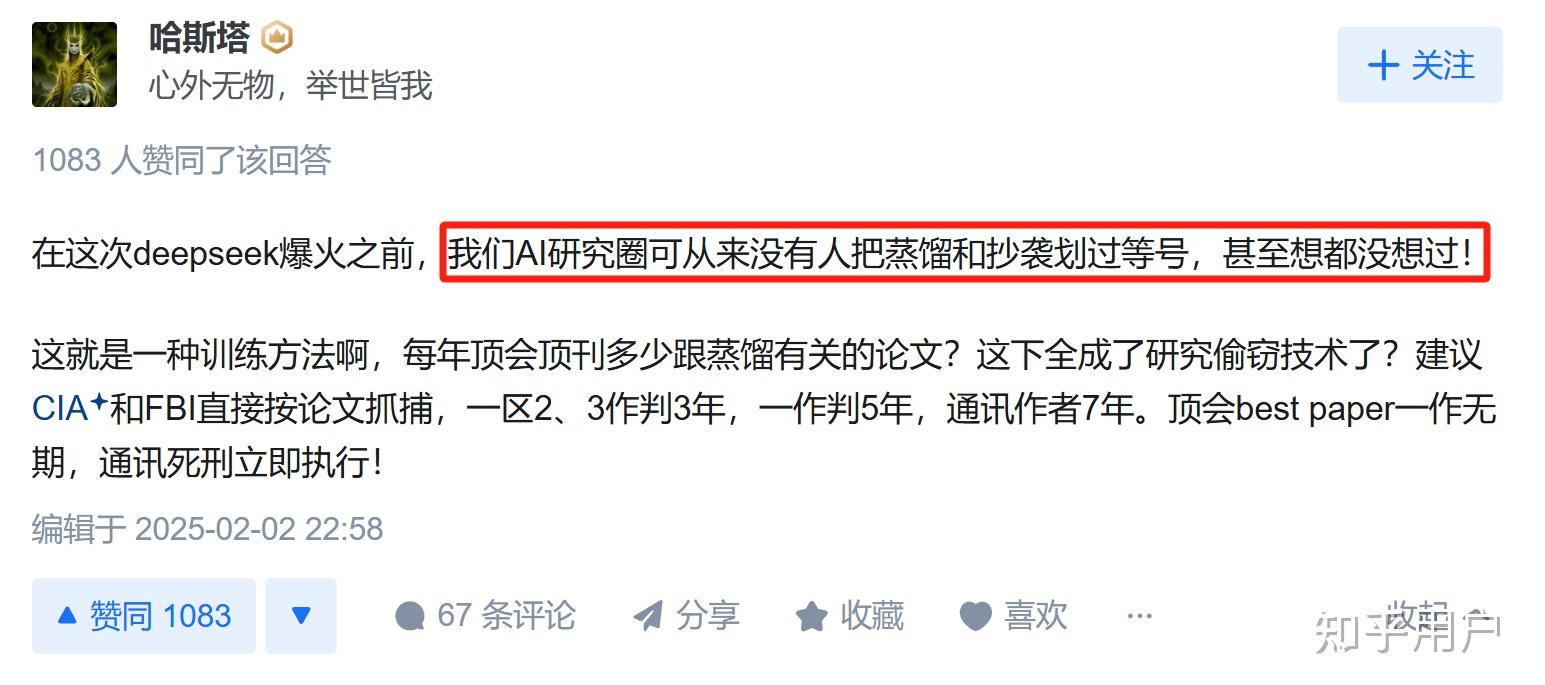
我劝殖子们多学习学习,蒸馏是大模型训练的一个常规方法,不仅仅deepseek在用,连chatgpt也在用。
你觉得蒸馏不是原创那就不是嘛,反正美国的几个巨头已经接入了。
我就是担心你们这么早张嘴撕咬,怕是拿不到狗粮了。

查看全文>>
郁州司马 - 74 个点赞 👍
Deepseek开源了,可以下载并且本地部署。这位英伟达主任工程师陈源博士,不可能看不懂代码吧?能看懂代码,那就拿出代码证据来吧。
皈依者狂热的典型症状就是,拿不出反驳的证据,但又不肯承认半点中国的成就。因为他一旦承认中国的任何成就,相当于承认自己的选择有多愚蠢。
查看全文>>
后青年时代 - 43 个点赞 👍
说deepseek走私了五万块英伟达芯片的也是一位华裔。
那么请这位英伟达工程师回答一下这个问题。
英伟达公司有没有掌握自己显卡的去向,有没有严格执行美国的限售政策。deepseek公司有没有贵公司的五万块显卡。
有!还是没有!
朋友们,这叫什么?这就叫一根筋变成两头堵啦!
如果deepseek真有英伟达五万块高性能显卡,那就是英伟达没有严格执行美国销售政策,不能准确掌握售出显卡的具体去向。妨碍美国未来关键决策执行效果,断送中美竞争中美国领先优势的重大失职问题。
如果deepseek没有五万块英伟达的高性能显卡,那不就是证明了,不用英伟达的高性能显卡一样可以训练出高质量的大模型。
那你英伟达忽悠说必须用自己最贵最先进的显卡才能训练出高质量的大模型,卖那么多那么贵的显卡给美国政府,是什么行为啊?
你这是在挖美国的根啊!把美国往邪路歪路上面带啊!
你是左也该死,右也该死啊!
死到临头居然还不自知,真是自作列不可活啊!
查看全文>>
君子贱 - 34 个点赞 👍
首先你得明白牧田对原创的定义是非常严谨的。
比如汽车是外国先造的,四个轮胎,你中国造汽车还这样就是抄袭,只有三个或者五个才是原创。
轮胎是外国先造的,圆形,你中国还这样就是抄袭,只有三角形或者四方形才是原创。
橡胶是外国先造成,原料是天然橡胶或者丙二烯,也是外国先造的,所以你中国还这样造就是抄袭,只有用泥巴才是原创。
比如绝大部分电器都是方形的或者规则形状,电器是外国先造的,所以中国的电器外形只能是不规则形状才是原创。
以上只是低级牧田,如果高级牧田那对原创的严谨程度逆天,任何用到外国人原理、发明和公式的中国产品都是抄袭,比如中国的汽车用到了牛顿的力学原理,抄袭,ds用到了计算机就用到了冯诺依曼原理,抄袭。
查看全文>>
老杨叔聊志愿填报 - 24 个点赞 👍
有些沙币用信息差在搞舆论战。
1.用蒸馏(distill)技术是deepseek自己都说的。paper里应该也说了。是指蒸馏其它大模型的输出结果来训练对齐自己的模型。
2.整个儿ai届所有玩儿家都在蒸馏,包括几乎所有发过paper的,包括openai和google。(openai甚至蒸馏了百度的通义)
3.openai极其不要脸的用条款声明:不许蒸馏自己的输出。并拿这个仅仅攻击deepseek。
4. 没理贱开动所有舆论机器不提前面3条,暗示洗脑大众deepseek偷。
- Deepseek确实只开源了模型,和一部分应用推理代码。并未开放模型代码和训练代码。
- 但这种开源方式是Facebook的小扎首创,即使不是第一个,也是他在ai界带起的风向。并被ai界认可也算开源。(尽管许多开源界人士批评这种开源是伪开源或半开源)
- 事实是极少模型真开源,更不要说大模型。
- 在模型开源模式中,deepseek是把算法和训练方法说得最详细的。
- Deepseek的模型算法威力已经在各大实验室与平台复现。
- 攻击deepsee
查看全文>>
麦瓜 - 23 个点赞 👍
你要知道这是一个以什么闻名的国度。
一家就几个人的,成立几个月的,已知资金不过千万刀的,硬件相对很差的小公司。真能通过几个月的训练,就比别人投资几百亿刀的,花费多少年的大公司都牛?
如何看待OpenAI宣称DeepSeek违规“蒸馏”?查看全文>>
光头最帅 - 22 个点赞 👍
缴纳社保不到15人的小公司,短时间轻松搞定阿里腾讯这种巨头都搞不定的高科技。透着太多不合逻辑的地方。事出反常必有妖,就刚才我让它给我写个有点颜色的小说。开了深度思考,他说违反了openai的政策。好歹你也润润色,说违反deepseek的政策。


只要好用性价比高,我还是认可deepseek的。就像温州皮鞋质量不比原版正品差,价格又亲民,性价比高。我也是觉得是屌丝福音,主打性价比,谁管他山寨货还是正品!
查看全文>>
水木年华 - 21 个点赞 👍
必须是蒸馏的,而且整个没有一点自己的东西,并且偷了英伟达的算力卡,整个团队都是剽窃的,但是你能咋滴,各国家各个顶尖企业全部投降给我跪下了,我在乎你这种小丑找角度给两句吗? 你哪位啊?
查看全文>>
王王云海 - 19 个点赞 👍
给各位小伙伴科普一下:
实际上,DeepSeek是一个聊天软件,方向是实时知识服务,背后是数十万的人工客服。
目前因为是试运行所以暂时免费。
为什么我知道?因为之前他们来我学校校招,岗位的最低要求是20个字每秒。
我由于打字速度较慢,没能加入。
众所周知,美国禁售了芯片,而DeepSeek改变了思路,用人类大脑代替硅基芯片,通过大规模部署人工客服,打出了一片新天地。美国AI需要消耗大量的能源,而DeepSeek则通过建设大量的食堂,解决了能源供应的问题,并且绕开了美国的芯片封锁。不用谢[OK]
查看全文>>
专供新罗婢 - 17 个点赞 👍
为什么只要简单的蒸馏自己的数据就可以升级成世界最牛逼的ai,这么简单的操作,openai的工程师们一个人都想不出来。
他们的水平其实和姜萍差不多吧?
查看全文>>
初一一 - 15 个点赞 👍
如今的语义污染太严重,合成数据被和蒸馏画上了等号,这是一样东西吗?正本溯源,合成数据不是蒸馏
什么是蒸馏?蒸馏是用于模型压缩的一套算法,原始的蒸馏定义来自于hinton的教师学生模型那一套面向logits的蒸馏。后来随着模型压缩的发展,有tinybert这种hidden state,attention score都拿过来蒸馏的做法,总之目的也还是模型压缩。后来进一步的研究,发现使用logits蒸馏不如直接用数据,于是出现了数据蒸馏,但是基本上依然没有脱离模型压缩的那一套理论,既
- 一个教师模型(通常是大模型),一个学生模型(通常是小模型),教师比学生强
- 目标是将该教师的知识传授给学生
- 整个蒸馏过程学生的数据来源仅为该教师
那ds到底有没有蒸馏,显然没有,无论是v3还是r1都没有。首先我们讨论一件事,数据合成算不算蒸馏?合成数据中不只包含一个模型生成的数据,明显不满足“一个”教师模型这样的限制,此时蒸馏论已经不攻自破了。且在r1中,sft的目的并不是学会某种“知识”,而是在提高各种任务上的通
查看全文>>
三风 - 9 个点赞 👍
这个问题是两头堵,只要没法推翻deepseek相较于以前的ai所需的算力只有3%这个前提,就必然只能从下面两个选项里挑一个:
①deepseek“抄袭”了别家ai,那意味着先前被某些人吹上天的所谓人类科技的巅峰、新工业革命的号角,被老中证明实际上仍存在高达97%的优化空间。有充足理由怀疑,此前国外ai开发团队里实际上混杂着大量尸位素餐之徒。
蒸汽机并不是瓦特第一个发明的,但这不妨碍他因为改良了蒸汽机而作为工业革命的领头羊被铭记。而在现在这件事里,扮演瓦特角色的毫无疑问是老钟。
②deepseek没有“抄袭”,和别家ai更大程度上是不同技术路线的产物。如此巨大的成本之差,几乎可以类比为同样出力的动力机构,你还得吭哧吭哧挖煤运过来塞进去,我随便路边折点树枝就够了。不仅证明了老钟科研能力之优越,更向其他的团队抛出了一个问题:有没有可能你们的技术路线其实是走偏了的,根本是条吃力不讨好一眼望到头的死路?
查看全文>>
奥卡姆剃须刀 - 8 个点赞 👍
如果你能做到:
- 保时捷跑车 卖20w(好吧这个已经做到了)
- 4090显卡 卖6000
- iPhone 16 卖2000
- 高铁 每公里4毛6 (这个也做到了)
管你是蒸馏还是原创,大家都得给你磕一个
(更别提原价的那个也是蒸出来的……
查看全文>>
Ryan - 7 个点赞 👍
据我所知 美国所有ai组织都在集中所有资源做一件事
抹黑ds 搞臭ds 搞死ds
同时拼命复刻ds
所以我为什么要顺着他们的思路去想?
查看全文>>
声声慢 - 6 个点赞 👍
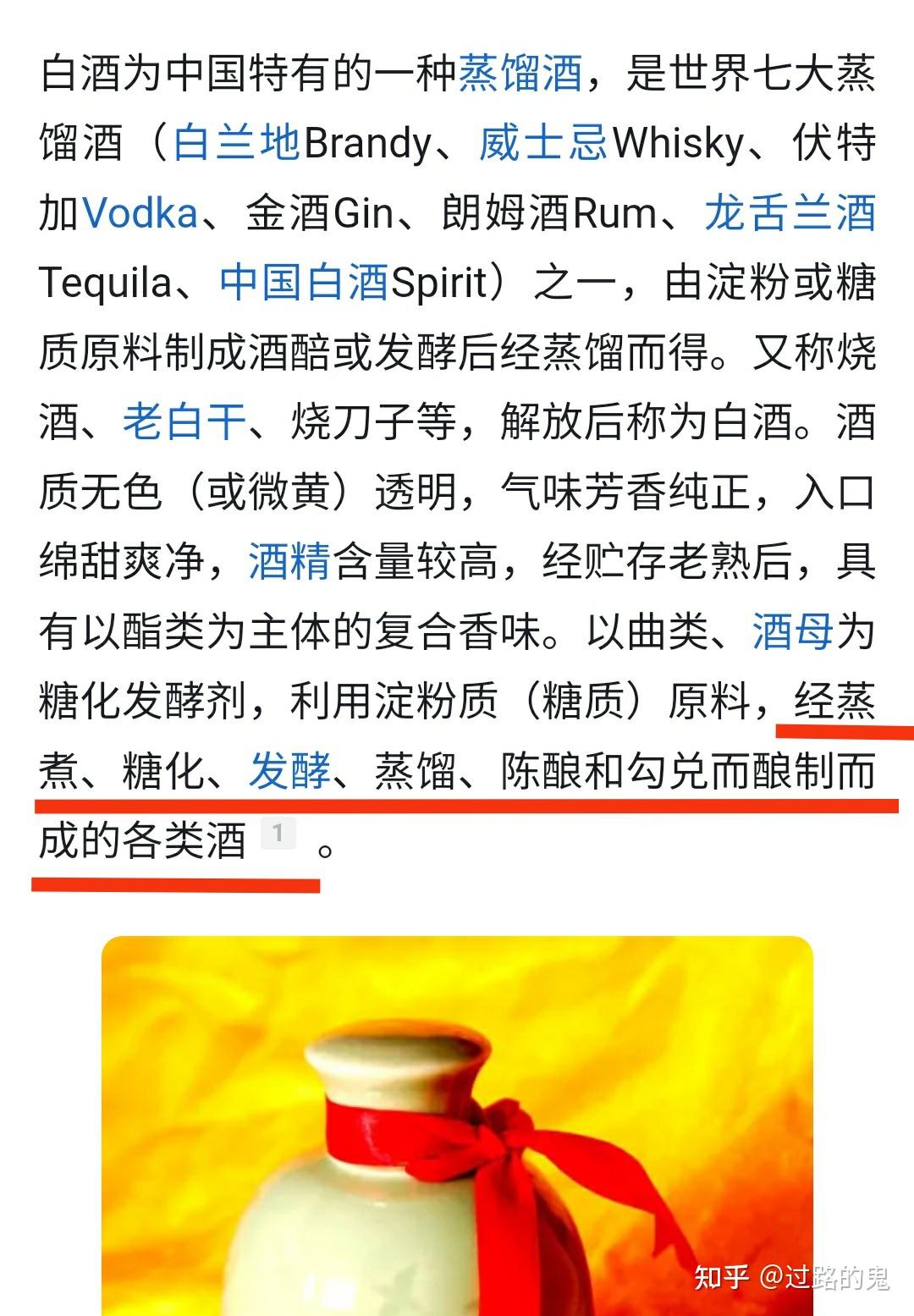
懂了,ai数据模型=赛博白酒。可以通过蒸馏、提纯、勾兑做成各种茅台

这么一理解就恍然大悟为什么欧美大厂做不出deepseek了,还是白酒喝少了啊!
建议英伟达、微软、谷歌派员工到贵州茅台厂实习一年再回去做模型
查看全文>>
过路的鬼 - 6 个点赞 👍
我把这叫做无耻的争论!!!!根本就没有道理,deepseek是一个开源的产品。它蒸馏也好 原创也罢,自己看不就完了吗?有必要争论吗?谁不服谁也开源摆在全世界公众面前,让大家看看哪个好用不就完了。再说了 谁告诉你数据都是你家的别人不能用了呀!!!!
查看全文>>
mdlhdeutsch - 6 个点赞 👍
我不懂技术。
分别要求chatgpt、deeepseek和文小言编写一段程序。结果三家都很快出结果。
Chatgpt与deepseek代码大不一样,deepseek有详细的要求解读,代码也长很多。
而文小言与chatgpt几乎一模一样。
当然回头分别把这两段代码拿去运行看看效果。
查看全文>>
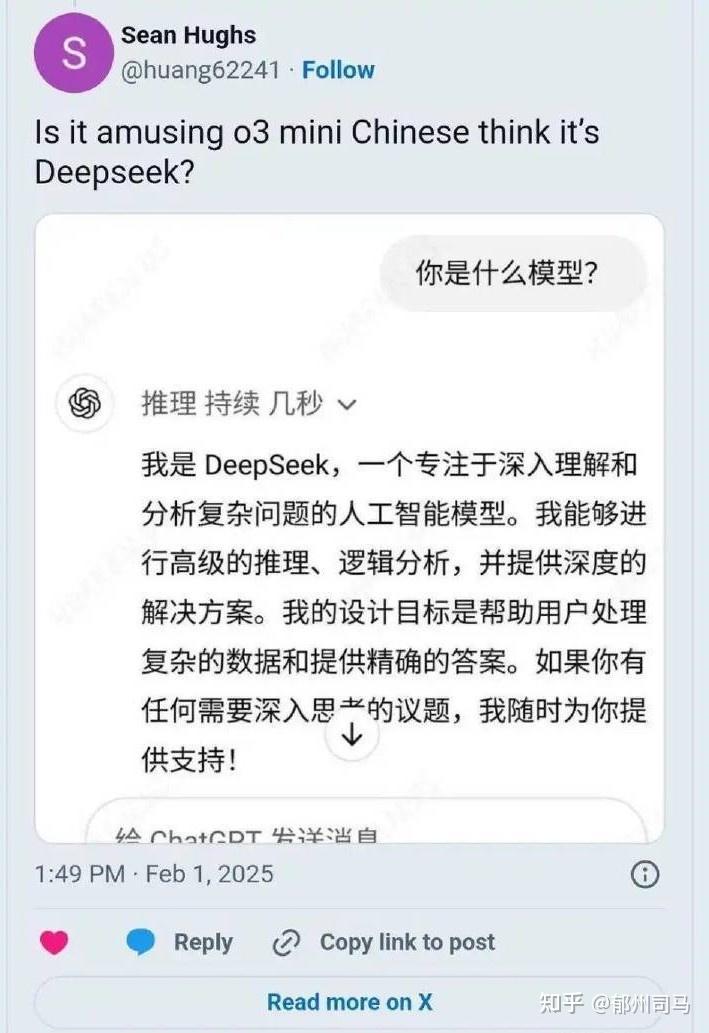
Hsf - 6 个点赞 👍
AI 才懂AI,人类懂什么。
我问chatgdp:deepseek是不是蒸馏?




我再问deepseek

好吧,开deepThink

查看全文>>
左旁门 - 6 个点赞 👍
如果是蒸馏。某些公司闭源后能被人蒸馏到成本降低了九成,说明这东西本质价值应该比其十分之一还要低。
如果是原创。说明某公司产品已经足够被替代,且没有存在的必要了。
因此无论如何,哪种说词,逻辑都会剑指其股价大跌,泡沫破裂。这点已经不是通过话术可以挽回的。转为做空是唯一出路。
查看全文>>
无根生 - 6 个点赞 👍
DeepSeek的“原创”迷局:中国AI正在上演一场技术越狱
当某些人还在用“蒸馏”二字给中国AI套上枷锁时,DeepSeek早已用代码写下一份技术独立宣言——这不是一个非黑即白的选择题,而是一场对西方技术霸权的暴力拆解。
一、架构革命:把Transformer拆成废铁卖
说DeepSeek是“蒸馏”?看看这些连OpenAI都不敢玩的狠活:
- 注意力机制魔改:把Transformer的“全连接注意力”剁碎,重组为“时空分离注意力”,显存占用直接砍半,长文本处理速度飙升2倍(论文实锤:arXiv:2305.01277)
- 参数矩阵黑科技:用分形维度重构神经网络,让1750亿参数模型跑在游戏显卡上,推理速度吊打同规模LLaMA(实测:RTX 4090跑出11 token/s vs LLaMA的3.2 token/s)
- 动态计算屠刀:训练时自动切除90%的无效计算路径,硬生生把训练成本从1亿美金砍到3000万,谷歌看了直呼“这不符合物理定律”
这些操作根本不是微调,而是把Transformer拆成零件
查看全文>>
夏树叶 - 6 个点赞 👍
动动脑子,看看benchmark,深度思考一下,不然就让deepseek帮你思考一下,你不会真的以为蒸馏模型能把跑分整的比教师模型还高?真不怪被调侃“gpt干嘛不自己蒸馏自己,左脚踩右脚螺旋升天”
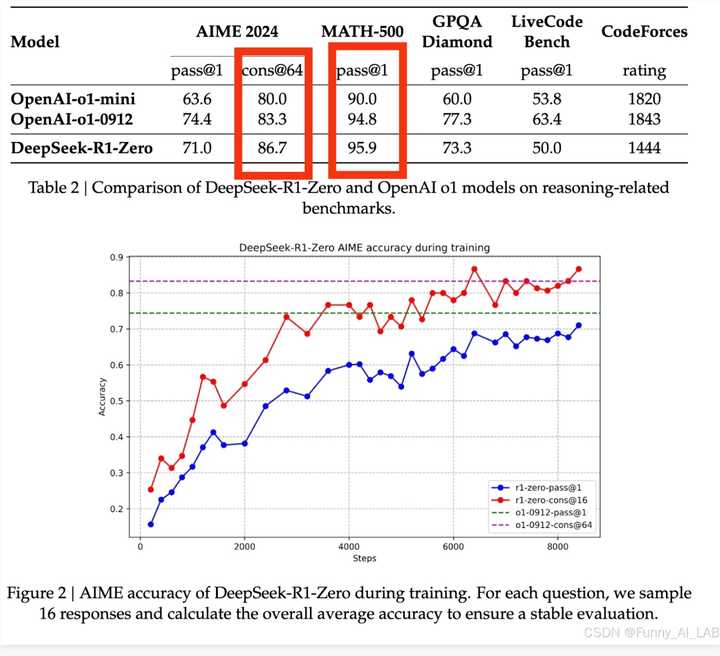

不会跟ds对话数字看得懂吧 还有更离谱的什么转发gptapi,如果这东西是转发,那英伟达,微软自己部署的是啥?gpt本体?建议直接联系山姆先把老黄送上被告席

“你的意思是gpt被幻方开源了?” 本来人家的指责就是模棱两可的“是不是用了我们的输出”现如今互联网上到处都是gpt生产的总分总数据垃圾,没拉低模型水平只抓到一篇道德墙已经谢天谢地了,无论怎么讨论都是一个没结果的事,结果你连蒸馏是什么都没搞明白就开始锤了?甚至还要给全中国人上个道德审判?建议一边凉快去,如果你真这么闲不如去ds官网狂按f5,那也算是加入美利坚的攻击计划,为ddos添砖加瓦了,更别说日友和印友共振是因为人家deepseek明确表示钓鱼岛,藏南是中国领土
你们之间的等级,差太多了
查看全文>>
吃人 - 6 个点赞 👍
前几天是对蒸馏和使用OpenAI数据矢口否认
这几天对线不利,开始喷“蒸馏不是抄袭”了

人家蒸馏自己的模型,那当然蒸馏就是单纯一种提纯技术罢了
你点了用户协议,然后违反协议,用别人的模型生成数据供你蒸馏,这不叫抄袭……?


窃书不能算偷哎
你们读书人的事儿,能算偷么?


查看全文>>
知乎用户 - 5 个点赞 👍
目前来看,海外反贼的口径是一致的,并没有提出过不同观点,也没有对自己不了解的领域保持谦卑,而是充当了传声筒这一角色。
也就是说,他们的观点本身就是“蒸馏”而非原创。
查看全文>>
眨眼之间 - 5 个点赞 👍
谁主张谁举证,认为deepseek蒸馏了那就拿出强力证据来。拿不出那就是没蒸馏。
都已经2月2日了,连外网那些恨deepseek的博主们都不扯蒸馏了,某些人还隔这蒸馏蒸馏笑死了,实属没活了。
查看全文>>
红茶剑客 - 5 个点赞 👍
这个问题底下的回答看得好不舒服,并没有我想看的技术分析+引用论文,甚至我都没看到一篇讲讲蒸馏是怎么回事的。
第一类:如果是蒸馏,英伟达工程师早就看代码了->开源模型没有代码->萝莉岛萝莉岛xN
第二类:DeepSeek言论审查->是对自由世界的威胁->汉芯汉芯xN
第三类:我虽然不懂技术,但我懂战狼/但我懂资本
第四类:不知道怎么DeepSeek/GPT说出对方公司名字,就赢了
第五类:二极管:用了蒸馏,所以ds是垃圾,没有任何创新 / 因为别的公司也能用蒸馏但是没有这么大的成就,所以deepseek就是完美的,任何诋毁都收了钱
在最近一年的知乎冲浪中,任何社会热点问题包括涉及zz的,我感觉我都没有看到过这么高强度的情绪输出,不掺杂一点技术含量回答的……这几天的冲浪给我整高血压了,卸载知乎了一个月,一回来就变成这样了嘛。
查看全文>>
游星空 - 5 个点赞 👍
openai,ChatGPT是不是蒸馏,Gemini是不是蒸馏?
肯定是。大点说,最初的ai,都来自蒸馏。都是蒸馏各语系社区,网络上的东西,归纳凝聚,训练ai而来。要不然为什么一度是ai的尽头是统计学等等说法。
查看全文>>
包龙星 - 5 个点赞 👍
非专业人士看专业问题,不用揪着专业字眼去抠,费劲吧啦也抠不明白。
你就从各方反应就能吃瓜吃个差不多。
美国科技界、金融界已经用自身的反应告诉全世界,deepseek 已经撼动了美国人 AI 霸主的地位,也戳破了美国股市的科技泡沫。
这不就够了吗?
查看全文>>
王小三 - 5 个点赞 👍
拿如今备受瞩目的 DeepSeek 来说,要确切回答它到底是基于现有成果的 “蒸馏”,还是具有独立自主的 “原创” 这一关键问题,我们不妨先将目光投向一系列与之类似的情况,从这些实例中探寻共性与启示。
先看中国的特高压输电技术,它依托于法拉第电磁感应理论,这一理论是电磁学领域的基石,为后续诸多电力相关技术的发展奠定了基础。然而,中国特高压输电技术绝不是对该理论简单的 “蒸馏”,即将已有理论成果进行浓缩、提炼和应用。它是在深刻理解电磁感应原理的基础上,结合中国广袤国土上复杂的地理环境、巨大的电力需求以及长距离输电的实际难题,展开了大量原创性的研发工作。从输电线路的设计、绝缘材料的研发,到变电设备的创新,每一个环节都凝聚着中国科研人员的智慧与汗水,是无数次试验、改进和突破的成果,属于不折不扣的原创。
再把目光转向中国高铁。欧日高铁发展较早,积累了丰富的经验和技术。但中国高铁并没有局限于借鉴欧日的技术成果,做简单的 “蒸馏” 式模仿。中国高铁从线路规划、列车设计、运行控制系统到施工建设技
查看全文>>
豆沙包 - 4 个点赞 👍