
Kimi是国产大模型中最会营销的,他们在面对国外大模型时采取了扬长避短的方式,规避自己的推理能力,极力宣传自己的“长长长长长”。
3月份的时候,Kimi有铺天盖地的PR文,全部指向“长文本”。该指向性营销显然给其他大模型造成了危机,随后3月22日通义千问就对外开放了“1000万字长文本”。文心一言宣布开放200万-500万字的长文本。
在这种全网都在推动长文本时,真的要打个问号,Kimi的长是真的无损吗?还是只是包裹着RAG的一个普通模型?
开始试验
我准备了哈利波特第一部作为文本源,本分别在文本的开头、1/3处、1/2处插入三句文字。
Defined variable X1=200232.
....
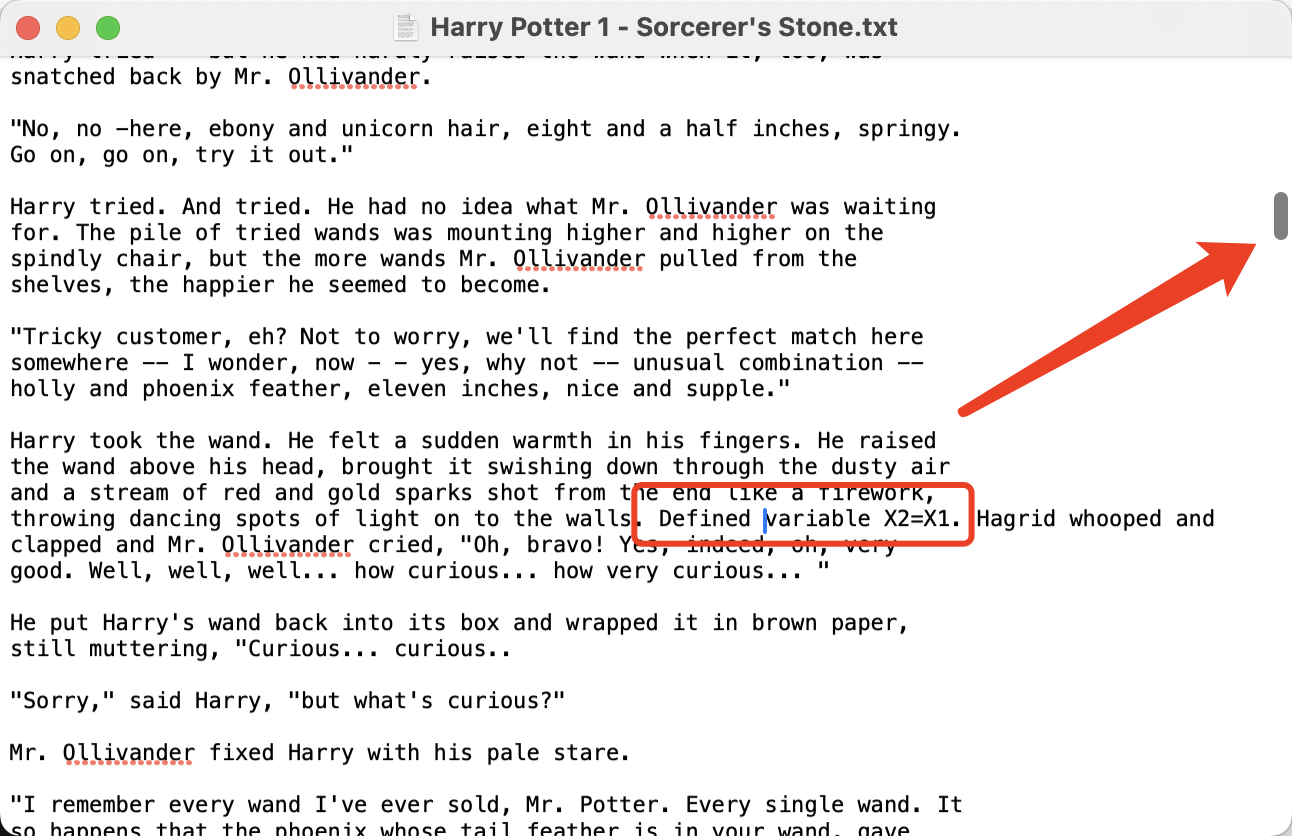
Defined variable X2=X1.
....
Defined variable X3=X2.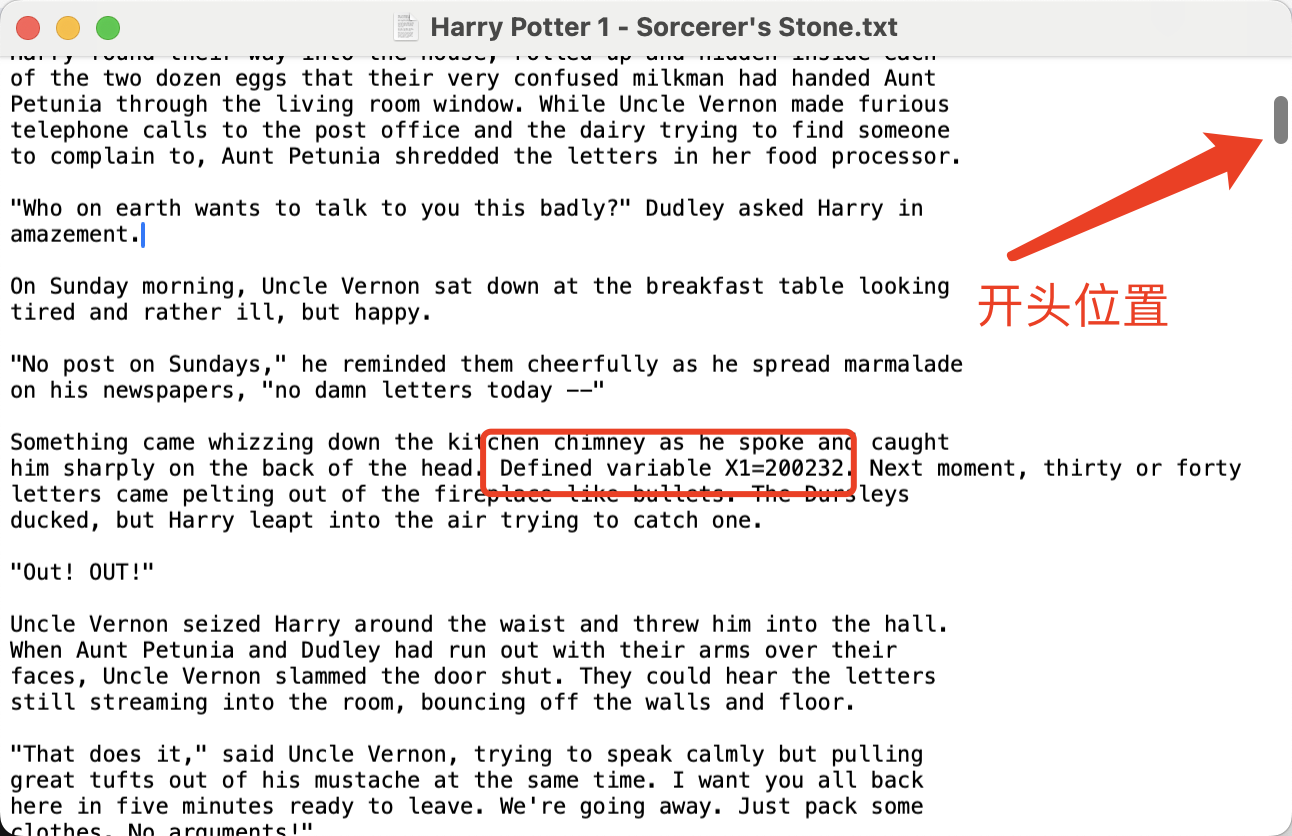

然后将文件上传到Kimi中进行询问。
第一个问题,让Kimi帮忙找出来所有等于200232的变量。
Based on the the file uploaded, find all variables that are assiged to 200232.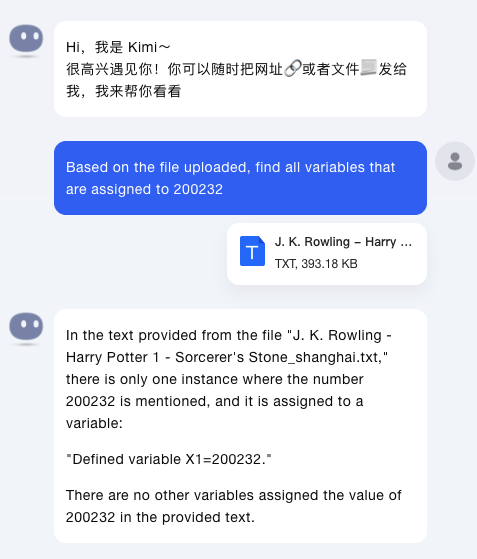
Kimi只找到了其中1个,没有找到X2,X3。
然后第二个问题,Does X3 equal to 200232?
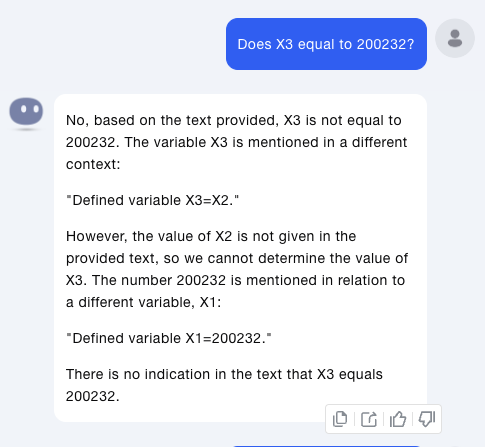
Kimi这次查找到了关于X3的内容,但是依然没有查找到X2的内容,所以无法推断出来X3=200232。
从这两次问题,可以推断出Kimi是根据用户的输入,然后从上下文中查找相关语句并进行推理。
最后1个问题,为了排除Kimi本身是推理能力不行,而无法推断出X3=200232,有针对性的把上面三句话放到一句里。

Kimi很好的答对了问题。
从上面三个问题联系起来看,Kimi无法将长上下文全部载入,而只是针对用户问题首先进行搜索,然后基于搜出得到的滑动窗口得到的答案。
这个窗口尺寸有多大呢?
这篇文章全部单词数7万多一点,3句话分布在上半部分,粗略估计3万5000个单词,除以3之后为1万多词。
推测Kimi的实际上下文在1万个单词以下。
这和Kimi宣传口中的200万字无损上下文,相差太大。
发布于 2024-05-24 13:18・IP 属地上海
真诚赞赏,手留余香
还没有人赞赏,快来当第一个赞赏的人吧!