
相关的科学研究是有的,不要把LLM学术界和Kimi官方想得这么不严谨。结论是Kimi在长上下文实验中完全能当家。
大海捞针实验(英文)
这个实验旨在衡量超长上下文中大模型对特定内容的召回能力。官方的repo如下:
提出这个实验的人只做了GPT-4和Claude 2.1的实验。经过我一番寻找,我发现Moonshot AI在自己的公众号中公布了自己的内部结果:
这是GPT-4(原版实验):
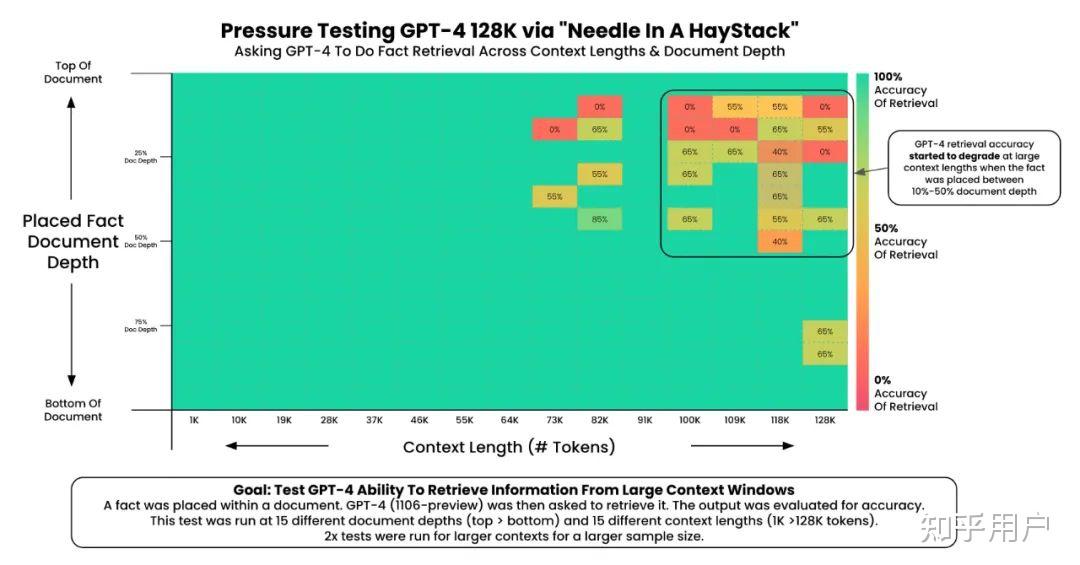
这是Claude 2.1(原版实验):

这是Kimi(内部复现):

这证实了Kimi在长上下文环境下的能力。
数星星实验(中文)
最初,我们希望 LLMs 能够计算天空中的星星总数,目的是测试 LLMs 的长期依赖性。然而,我们发现,如果要求 LLMs 计数星星,它们通常表现不佳。具体来说,我们分析了表现不佳的原因,主要包括三点:(1)LLM 无法发现星星;(2)LLM 可以发现天空中的所有星星,但无法记住所有星星;(3)LLM 可以记住所有星星,但需要更好的数学能力才能正确计算出星星的总数。因此,我们最终选择了让LLM列出所有星星的数量,因为数星星的测试只是想通过一种简单、有效、合理的策略来更好地评估LLM的长期依赖能力。
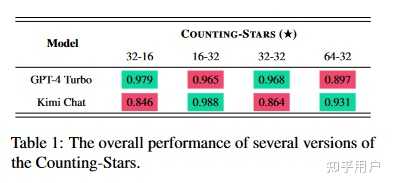
结论是Kimi和GPT-4的结果不分伯仲。
Infinite-Bench(中英文混合)
清华孙茂松组的实验:
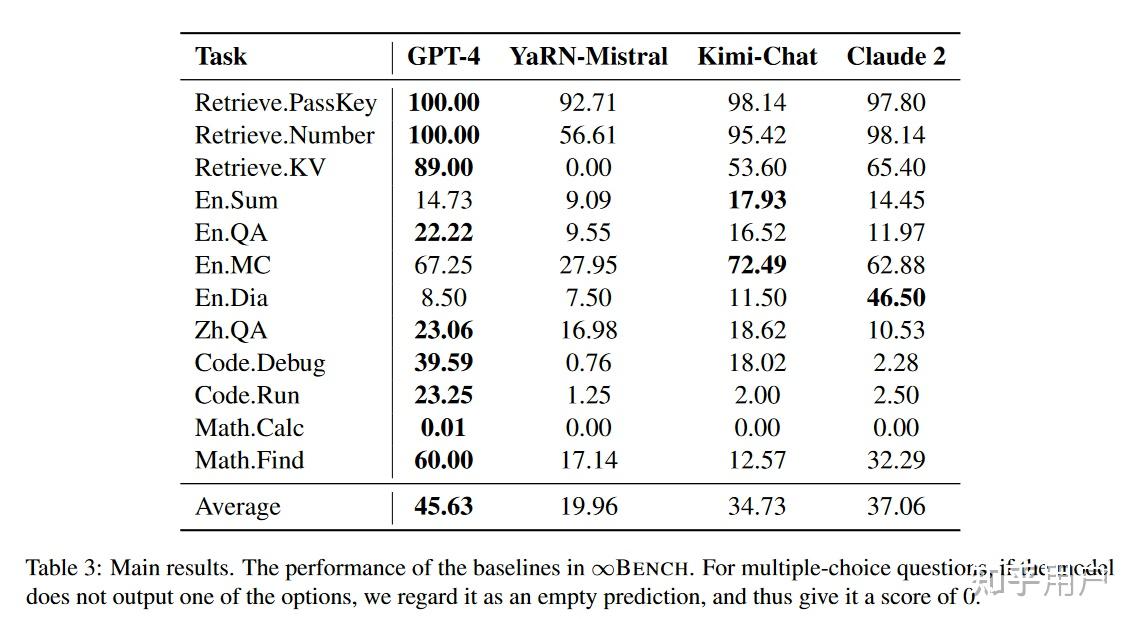
Kimi-Chat略弱于GPT-4,超过Claude 2.
SuperCLUE中文大模型榜(中文,非长上下文针对性测试)
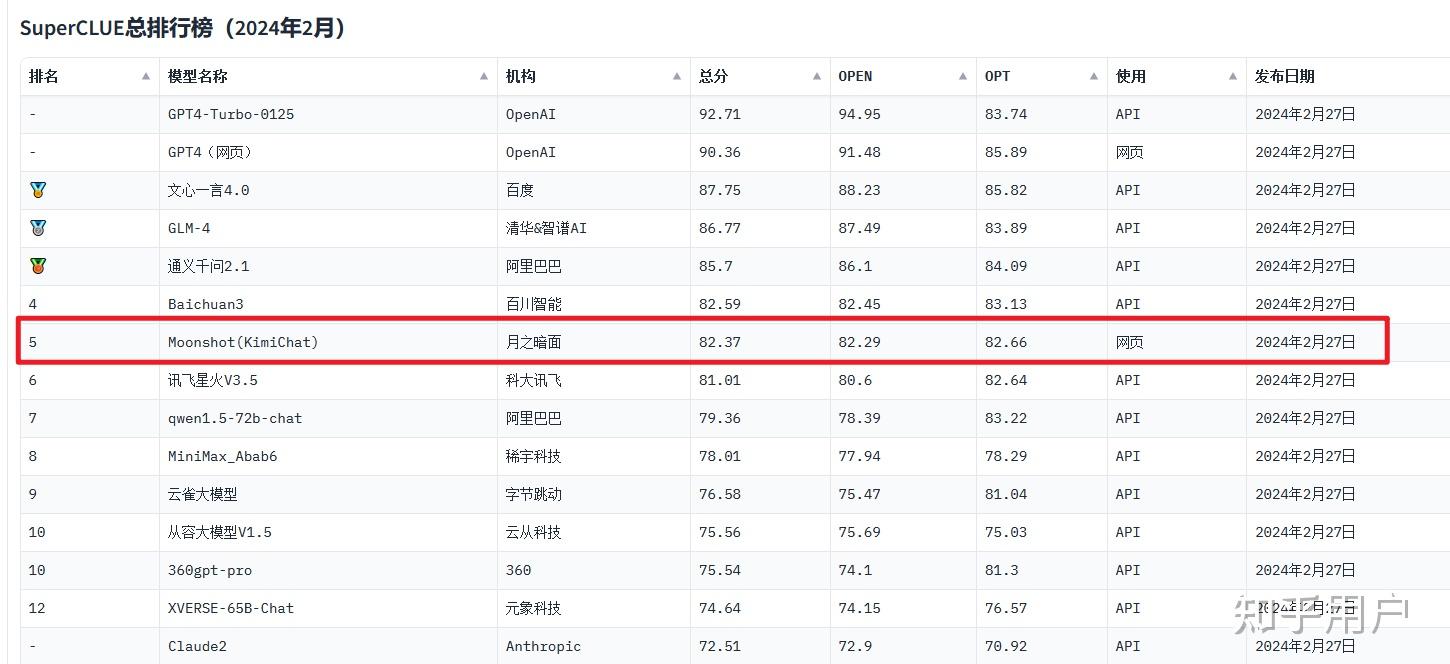
2024年2月,综合能力在国内排第五。
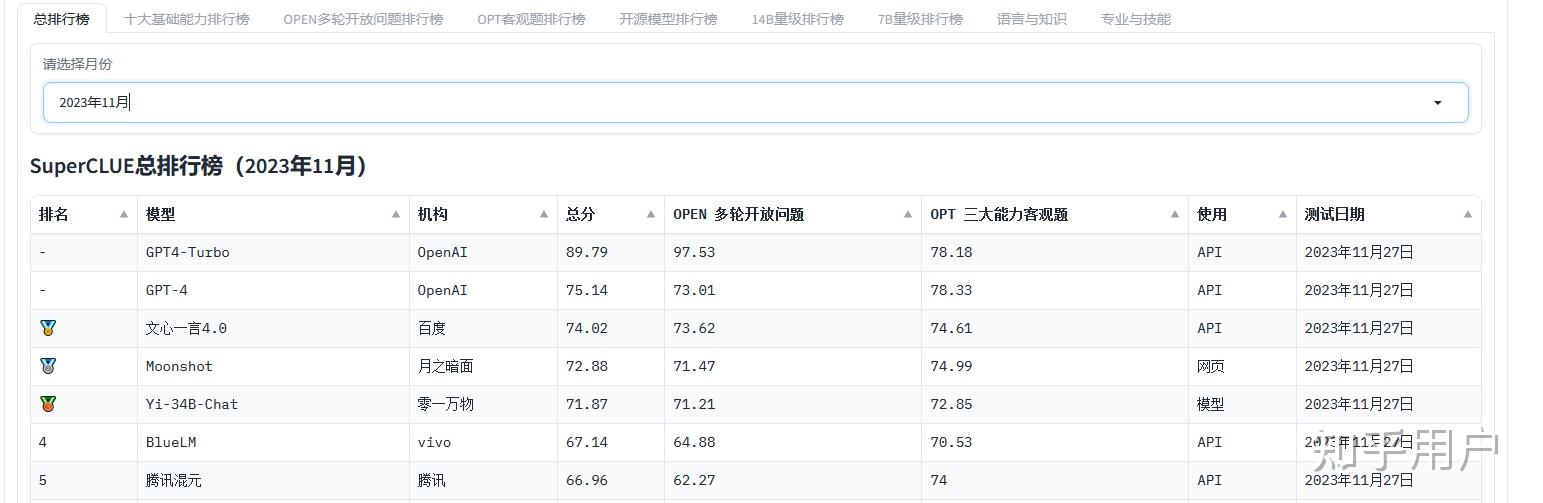
2023年11月,排第二。
结论
我们能不能说Kimi在国内大模型中是第一梯队?可以,数据佐证了这个结论。
我们能不能说Kimi在长上下文中表现出色?可以,实验一和实验二都是在200k版本上做的,结果显示确实十分出色。
至于通稿中的“无损”,“怎么做到的”,我觉得在没公布技术细节和实验的前提下确实有过度公关的嫌疑,但总体上抛开这些来看Kimi作为一个大模型的本质,那它毫无疑问是好用的。
发布于 2024-03-21 16:17・IP 属地日本