
已经加入 Waitlist 了,找朋友问了问,说现在内测名额很紧张,那就耐心等排队吧。虽然还没用上 2M Context,但看到一些讨论,所以来瞎扯几句,非软。
模型能力与使用场景
各种大模型测了一年,我有时会觉得,在具体的 case 上纠结没啥意义。之前 Kimi 的上下文是 20 万字,我测过一次,效果挺好的,里面的确是真实的场景,案例大家也可以去拿去测看效果:
但也有人说,我的哪哪个 case 他解决不掉,就是生成错误。我想说,就算一万个成功的案例,同样也依然有一万个失败案例,这两者不矛盾,也不能相互抵消吧?因为就算是一个活人,他也肯定有会的有不会的,有擅长的也有短板。
我之前推荐过王小川的一篇访谈,放到现在看依然有道理[1]:
王小川认为当前更需要寻找的是TPF(技术/产品契合度),「不是一群产品经理先去考察市场,而是应该先思考,当前不完美的(大模型)技术,适合用来做什么产品。」
大模型真的不完美,真的还不能包打天下,GPT-4 也有一大堆解决不了的问题。正常用户的使用逻辑都是找到模型能做什么,然后给自己提高效率。我寻思也没谁宣传的时候说自己的模型一定完美契合场景,生成准确无误吧。
当然,那些努力找到模型缺陷,和论证模型不能做什么的,也是有意义的。但这样的意义在于更好地督促公司去改进模型,而不是全盘否定公司已经实现并能做到的事情。
很多时候从模型到应用,其实是 trade-off 的选择问题。为什么很多 AI 产品都会有多个尺寸?也是因为效率/成本/效果不可兼得。比如 Mistral 的官方文档里就有专门的一章「模型选择」[2],告诉你如何为合适的场景选择合适的模型:

他们的建议就是:先用更好更大的模型验证某项任何能否用 AI 完成,如果可以,再一步一步地降级到更小、更便宜的模型看能否满足需要。
Long Context vs VectorDB/RAG
200 万上下文听上去夸张,但别忘了之前 Gemini 已经吹到 1000 万上下文了。国内像 Kimi 和百川就一直在磕上下文长度。我是觉得,AI 企业的方向,与创始人的愿景和 Vision 有很大关系。
去年 4k 长度的时候,有一些公司就在拿私有知识库做 SFT,成本其实蛮高的,效果据我了解也很一般。后来有了 RAG,大家发现检索召回的效果还不错,可用。
再后来,GPT-4 做到 128k,Claude 卷到 200k 吃书,然后国内的百川和 Kimi 做到 200k,Gemini 1.5 说自己是 1M(最高 10M)。
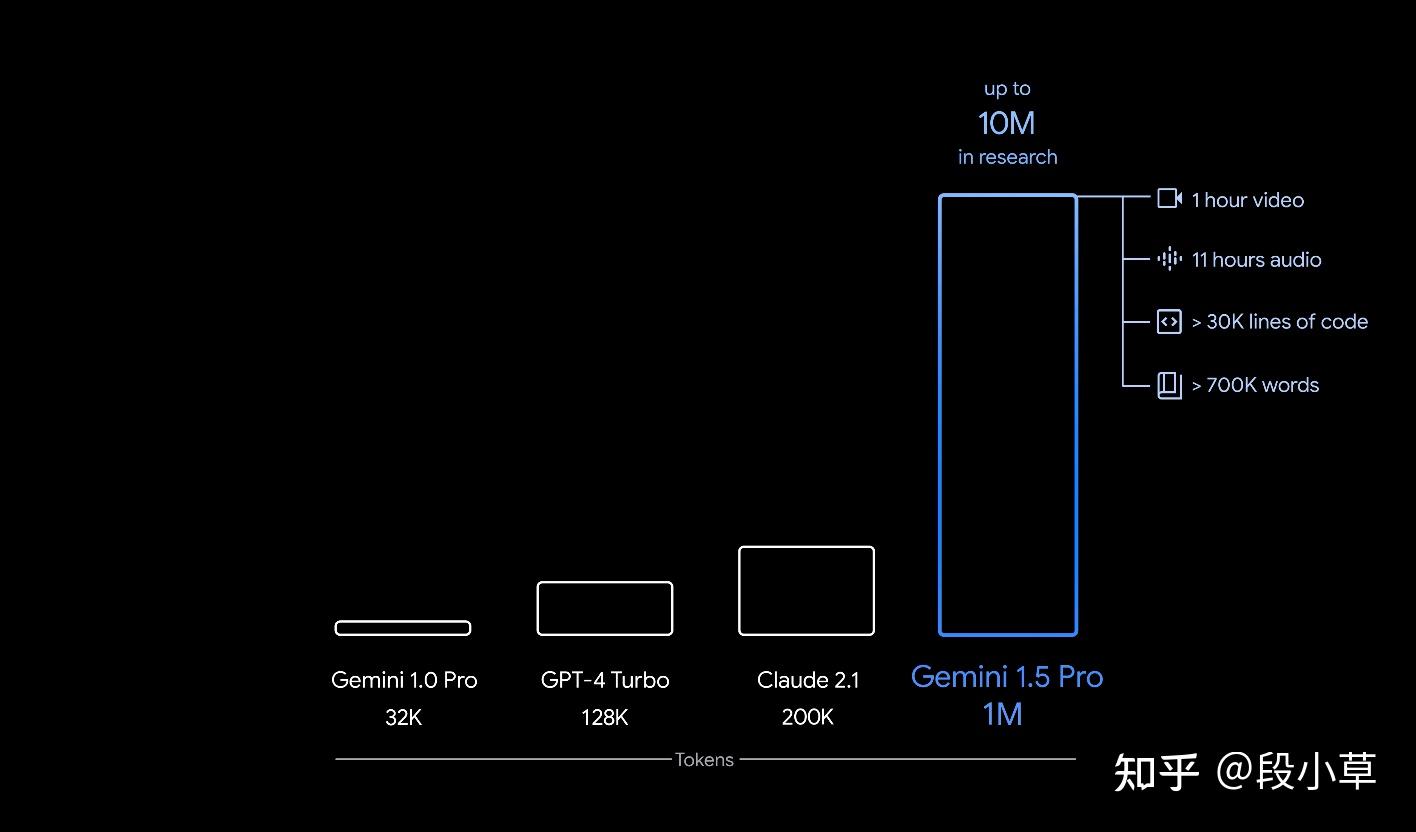
这其实和技术方向的判断有关系。说白了,多长的上下文才够用,上下文的扩充有尽头吗?有了更长的上下文,VectorDB、RAG 技术还有意义吗?
现阶段没人知道答案,答案交给未来。所以才会有技术路线的分化。这是好事,每种想法思路都要有人实践验证。
现在还在磕长度的,其实是信奉两条定律:数据上升,AI 智能上升;时间推移,算力成本下降。说白了,2M 的成本现在很高,但未来会降低;现在花很多精力用 RAG 解决的问题,未来上下文直接一口吃掉了。
Long Context 必然会解决很多问题,带来很多场景。大家如果真横向比过各家的 chat 就知道,Kimi 在产品和工程上是下了功夫的,我不拉踩别的产品,但 Kimi 的确是在文件解析方面支持的格式最多的一个(除了 ChatGPT,但 ChatGPT 是因为有 Code Interpreter,所以对文件格式根本没做限制),演示里有个 500 份简历的场景,看来下一步还会扩。
最后再扯几句别的。一个是套皮/抄袭,这种话我觉得…拿出证据吧,否则没讨论意义。
另一个是我看也有人在说 Kimi 最近做推广的事,但宣发不是原罪。Kimi 买量了吗?买了,我的 B 站首页一屏能刷到两个广告;但反过来,Kimi 好用吗?好用。
买量跟好用又不矛盾,好产品让更多的人用上不是好事吗?如果大家这么反感推广,那太多互联网企业的根基就崩塌了,互联网那么多网站业务的根基不就是广告和流量吗?
少些情绪,少些质疑,多实践多用多找场景,吵架没意义,国产 AI 产品的普及渗透才是实打实的。