
不知道前几年中国内地挖矿的场景,大家还记得不?那时候,内地耗电出奇的高,特别是深山老林里面,电费便宜的地方,到后面很多挖工都开始自建水力发电了。
所以,能耗一真是算力过不去的坎。
1、GPU的春天
我去年刚换了4070ti的显卡,同样的,也我得上1000W的电源。早些年,AI一直是在用CPU进行计算,而GPU,只能用来挖矿,为什么?因为GPU的性能,真不行。
这样吧,你如果把CPU比喻成博士生的话,GPU就相当于小学生。
为什么后来可以了呢?因为GPU量大呀,加上AI处理,并不一定需要CPU那么高性能,你看,如果去板砖,一个博士生搬一万块砖,和一万个小学生搬一万块砖,谁快?
一个显卡,就相当于一万个小学生。
我记得,老黄宣传显卡时,做了两台机械,进行颜料喷溅,一台是外面写着CPU,一发一发的喷射,画了个emoji,而另一台写着Nvidia的,一发入魂,直接秒出蒙娜丽莎。

不得不说,老黄这个广告打得好,让人家感觉,CPU好垃圾。
2、性能缺陷且能耗过高
AI发展已经有70年了,为什么现在才突然牛起来?也是因为GPU介入后,算力提升,带来了质的飞跃。但为什么我们还是感觉现在的AI,还是有点问题,而且有时候会胡说八道?
算力永远是不够的,随着训练数据的增长,上下文的增大,人工智能对GPU性能的要求也不断的增加。软件公司只能通过堆显卡来解决。
堆显卡,显卡产量就那么多,你有钱也买不到。堆多了,电费也够呛。
所以你看,现在除了算力,电力也成了AI卡脖子的地方
3、未来的方向
但话说回来,GPU性能提升缓存,一直是AI发展的一个瓶颈,所以更高的单芯能力,更节约的能耗,已经成为未来GPU的一个奋斗目标,别看你老黄用CODA建了护城河,但如果这块不改进,迟早是要黄的。
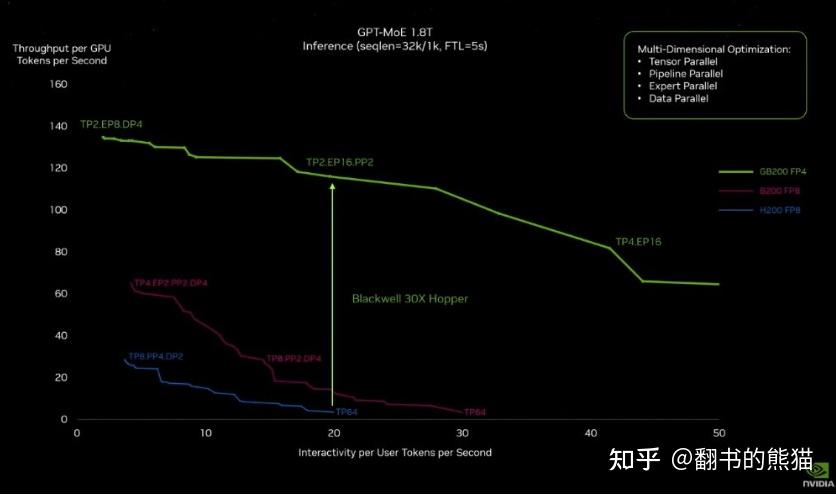
这次的GB200的发布,很大的提升了性能和功耗,堪称完美。
这个GB200新系统提升在哪里呢?如果要训练一个1.8万亿参数量的GPT模型,需要8000张Hopper GPU,消耗15兆瓦的电力,连续跑上90天。但如果使用Blackwell GPU,只需要2000张,同样跑90天只要消耗四分之一的电力。当然不只是训练,生成Token的成本也会随之降低。把芯片做大的好处是单GPU每秒Token吞吐量翻了30倍。
同样的工作,降了3/4的设备,也降了3/4的电力,吞吐量还翻了30倍。如果真能这样,估计真的会让AI飞入寻常百姓家。
最后
悲催的是,国内应该买不了……国人当自强啊