
其他我不做评价,单纯评价一下这里面的知识点。
提到使用所有的实名手机号进行撞库的答主都是不了解彩虹表构造的。
本文将详细解释什么叫做彩虹表。(该处默认读者知道什么叫做hash,hash是一种单向函数,就是把一个手机号可以映射为一个hash值,但是知道hash值不能反推出手机号。至于单向函数为什么可以单向,请查看我这个回答:苏迟但到:为什么说 MD5 是不可逆的?)
我们要说明rainbow table,hash chain, hash set是三种不同的东西。
其他答主提到的是hash set,也是最容易想到的方法。
hashset在java,lua,python里面都有实现,叫做集合。
集合里面会保存很多对象,然后对对象取hash值,然后再使用hash作为索引。
这种好处就是知道一个元素的hash值,那么就可以快速的找到该索引。
因此在很多人对于该技术的概念如下:
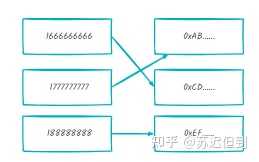
保存了所有的有效手机号码和它对应的hash值,从而我们知道了hash值就可以快速反推出手机号码。
但是有一个问题就是如果这样操作的话,会导致随着要hash的内容长度增加,从而要存储的空间指数增大。
例如假设手机号码库是1G,那么多一位的手机号码,就要存储10G.
这么做的结果就是导致存储空间太大了。
于是科学家们提出了hash chain(哈希链)。
hash chain顾名思义就是指运行很多次hash,然后生成一个hash链条。
你可能会问,这有啥用。
我来给你画个示意图你就明白了。
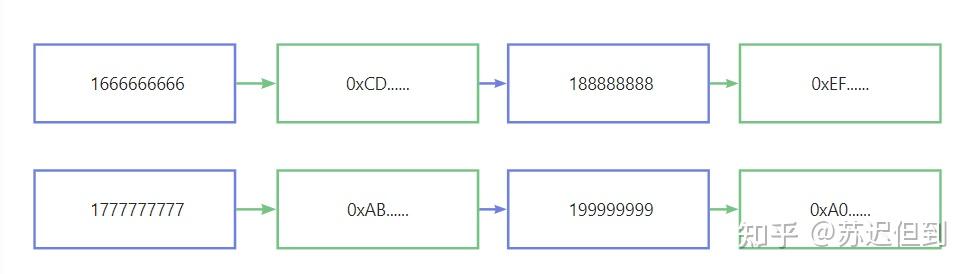
在这个示意图里面,我们画了两条hash链,其中我们可以看见有两种颜色的节点。
绿色的节点是被hash处理的结果,而蓝色的节点就是手机号。我们引入一个新的hash函数,根据不同的需要进行构造。这个新的hash函数完成的是一个简单任务,在这里的话就是完成输出的hash值 到 手机号或者邮箱的映射函数。
这样好处就是我们只需要存储开始输入的手机号和最后一个hash结果就可以完成查询。
因此hash链条的长度是固定的,假如我们设置为100。

假设我们获取的待查询hash值是0xA0.....。
那么我们将这个hash值按照上面的流程hash 100次。
然后分别这100个结果进行查询,假如查询到第69次hash的结果保存在数据库里面,是0xEF....。
那么我们就可以找到链条的起始端17777777777,并将它hash 31次,那么我们就找到用户的手机号16666666666。
通过这个方法的好处是什么呢?
就是只要你只需要保存hash链条的开始和结尾就可以了,可以极大地减少需要存储的体积,如果链条长度为100,那么原来需要1G的数据,现在只需要10M。(在实践中,往往将链条长度设置为2100。相当于需要保存的体积减小了2100倍)。
接下来,我们进入了最后一个概念,rainbow table,也就是大名鼎鼎的彩虹表。
彩虹表同样沿用了哈希链条的思想,它主要是解决了哈希链碰撞的问题。

假设数据库里面实际存储的是12371829289-->0xCD。
那么在查询0xA0这个hash值的时侯会产生一个奇怪的事情,就是我们从12371829289开始计算,会计算出17777777777这个手机号,而不是1666666666这个手机号,这就意味着我们产生了一个错误的结果。
也许我们可以继续搜索,但是这个方案在建立hash链条数据库的时侯还会损失算力。
因此科学家们想了一个天才的办法,就是将hash值到手机号的映射函数进行修改,从原来的一个函数修改为多个函数,然后让不同的映射函数交替使用。

在这里蓝色和橙色都代表的是手机号,但是他们是由不同的映射函数实现的。

这样做的好处是就是如果出现碰撞,如果它们的次序不相同,那么将会重新分散开来。
就如同爱情一般,他们只是短暂的相遇。只有当他们的步伐一致的时侯,才会一直走下去。
hash链条重合的概率,最终取决于映射函数的数量,当映射函数数量大的时侯,重合概率就很低。
我们回到第一句话,那么很显然这个映射函数是很难实现一个hash值到稀疏的手机号空间的映射关系的,更为关键的是同样也是没必要的。
至于加盐的作用,约等于zero,本文不列具体数据和证明,读者可以自行查阅。
当然相关的抵御办法也有很多,但是本文已经够长了,而且我要上飞机了,有兴趣的读者可以自行查阅。
好,本期视频到此结束,欢迎大家点赞 关注 评论 投币!
有up主看见且想做成科普视频的话,可以通知我一声,并在视频的结尾或者开头提到我的知乎ID(
)即可。