是我们在训练大模型,还是大模型在训练我们?

- 67 个点赞 👍
自问自答一波,欢迎大家讨论!
不知道大家有没有发现一个问题,我们越来越ChatGPT化了。引发了我的思考“是我们在训练大模型,还是大模型在训练我们?”
起因是我在知乎上的一个回答被检测出包含AI辅助创造内容,因此答案被折叠。


虽然我及时联系知乎小管家进行了恢复,但我深深意识到了一个问题,由于一直在构建大模型所需的训练数据,一直在训练大模型,一直在对大模型进行测试。我已经被同化了,在我的潜意识中已经形成了一套创造框架。我对行文的审美已经固定在具有强逻辑的模型内容上。
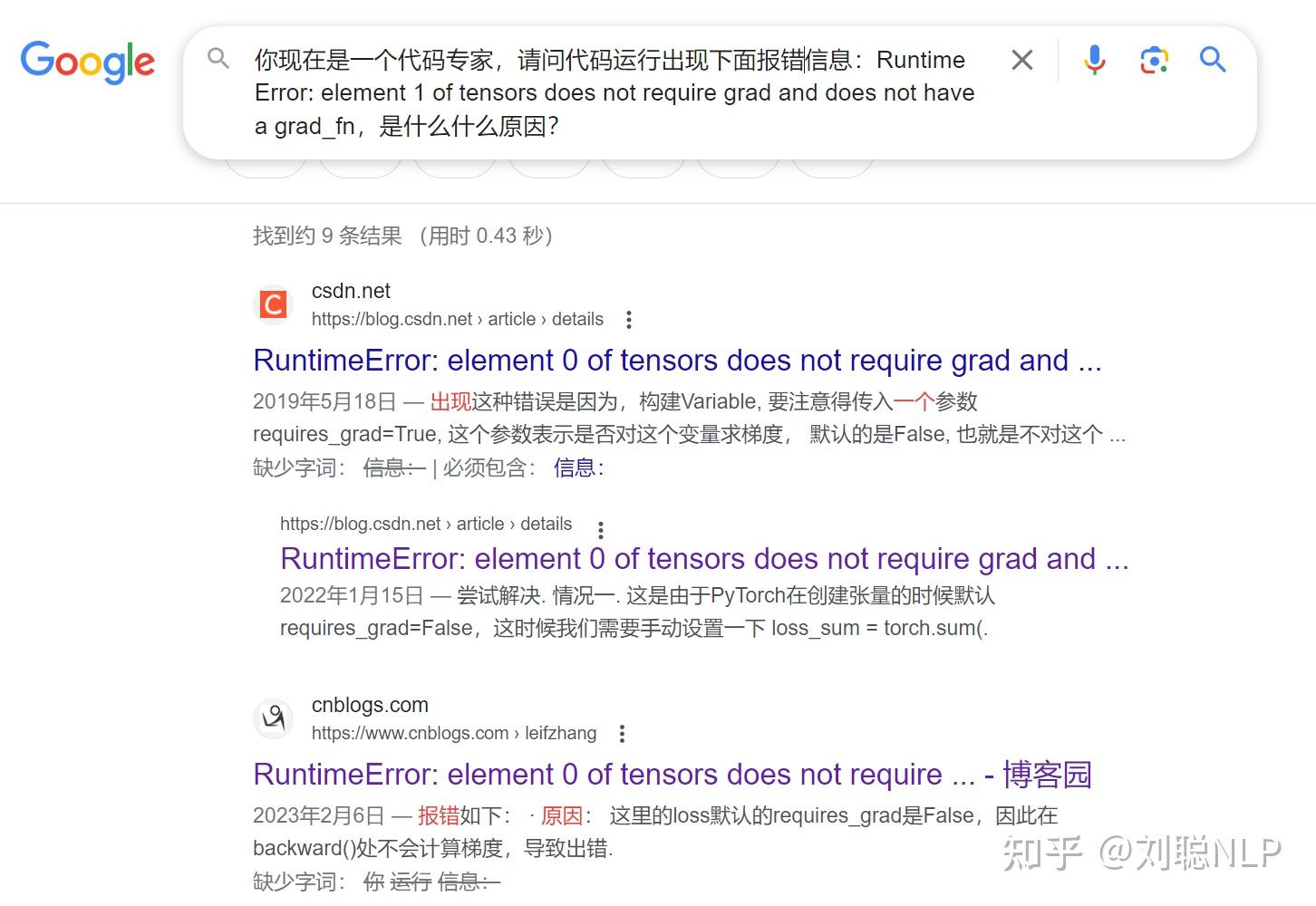
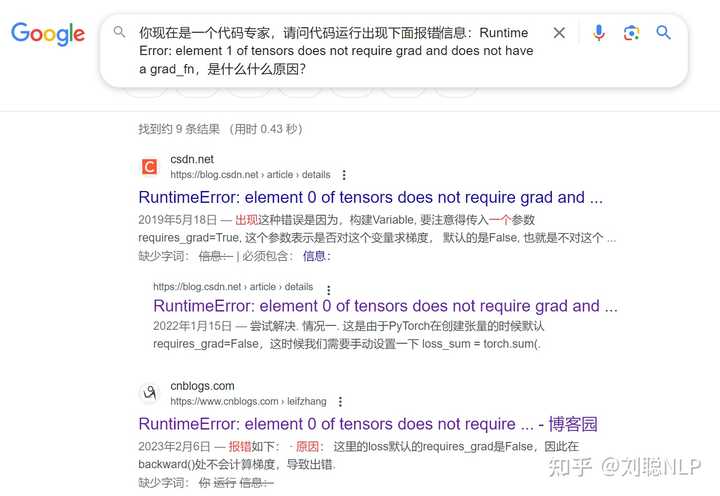
当在检索框里输入“你现在是一个代码专家,请问代码运行出现下面报错信息:Runtime Error: element 1 of tensors does not require grad and does not have a grad_fn,是什么原因?”时,我现在已经被大模型深度同化了。

从思维到行事,从内在到外在,完全大模型化。
从何开始
当我们依赖某一个或者某一些模型的时候,我们就正在改变我们的习惯。比如这是我用SD画的末日+机器人:


这是别人用SD画的末日+机器人:


因为我不会写一个好的prompt,所以我很有个性,但当为了通过大模型获取更好的效果,我们会参考最优的提问方式。渐渐我们对相同问题的提问、思考、获取答案的内容也越来越趋同。
「那么你是否已被AI模型同化,更深层次的哲学问题,人类思维、风格差异如果趋同后会有哪些影响?」
造成影响
目前存在一些AI生成内容的检测工具,例如GPT-Zero、DetectGPT、中英双语ChatGPT检测器等。一般通过机器通过判断回复的困惑度、高频词组合、表达方式等特征来判断。
中英双语ChatGPT检测器的论文中指出:
- ChatGPT的回答通常严格地集中在给定的问题上,而人类的回答是发散的,很容易转移到其他话题。
- ChatGPT提供客观的答案,而人类更喜欢主观的表达。
- ChatGPT的回答通常是正式的,而人类的回答则更口语化。
- ChatGPT在回应中表达的情感较少,而人类在语境中选择了许多标点和语法特征来传达自己的情感。
但可以想想,如果人类与大模型内容输出极其相似,那么检测器就将更难区分是由AI创作还是人类创作,对于未来内容审核会带来严重影响,并且人类对于互联网上内容的真实性将更难判别。
苏神的“当生成模型肆虐:互联网将有“疯牛病”之忧?”也指出,人类生成模型的频率越来越高,将会导致互联网上模型创作的内容越来越多;但生成模型也在进行着迭代更新,所用数据一般来自于互联网,那么就会出现以后的训练集中模型创作的部分占比将会越来越高。由于模型生成结果往往为了保证数据质量来减少多样性,最终数据内容会越发单一,所用词汇越发集中。
随着人们对大模型的依赖逐渐增加,恶性循环就出现了,甚至会出现人类语言退化。
「那么大模型继续发展之后,2022年是否将成为AI数据元年?」
如何应对
现在各大厂已经进行对AI创作进行了部分处理,比如,知乎对AI创作打上一定的标签,如若不然,将会被给予一定的违规处罚;百度对检索出AI创作内容,会对其排序进行权重降低处理,等等等。并且OpenAI、谷歌等七家 AI 头部企业承诺,将为人工智能内容添加水印。


这样,大模型制造者可以知道哪些数据是AI创作的,普通人也可以知道哪些内容由AI生成。可能规避一些同化信息吧。
PS:本人在3月份写ChatGPT-所见、所闻、所感一文时,就对AI检测给予厚望。但目前还是任重而道远。
「如何更好地利用魔法打败魔法,AIGC的高效检测。」
总结
目前是我们在训练大模型,还是大模型在训练我们?欢迎大家讨论!
- 你是否已被AI模型同化,更深层次的哲学问题,人类思维、风格差异如果趋同后会有哪些影响?
- 大模型继续发展之后,2022年是否将成为AI数据元年?
- 如何更好地利用魔法打败魔法,AIGC的高效检测?
欢迎多多转发,点赞,关注,“NLP工作站”成立技术交流群,交个朋友吧,一起学习,一起进步。
我们的口号是“生命不止,学习不停”。
往期回顾
刘聪NLP:支持多模态的ChatGLM模型-VisualGLM-6B
刘聪NLP:ACL2022 | DCSR:一种面向开放域段落检索的句子感知的对比学习方法
刘聪NLP:ACL2022 | NoisyTune:微调前加入少量噪音可能会有意想不到的效果
发布于 2023-07-24 20:52・IP 属地江苏查看全文>>
刘聪NLP - 18 个点赞 👍
这个问题,首先让我想到了《人类简史》里提到的人和小麦相互驯化的关系:
人类通过长期的人工选择和种植,选取具有高产量和易于收割加工的小麦种子进行种植。在农业革命时期,人类投入大量时间和精力来种植小麦,进行除草、防虫、灌溉等管理活动,逐渐将小麦驯化成现代农业中使用的作物。
小麦的高产量和丰富营养使人类能够获得更多食物,促进了人类数量的增长。农业的出现改变了人类生活方式,让人类不得不永久定居在农田附近,投入更多时间和劳动来栽培小麦,改变了人类的生活节奏和生活方式。小麦的种植让人类形成了农业文明,推动了社会的发展和进步。
类比之下,我们和大模型的关系是否有相似之处呢?
以ChatGPT为代表的大型语言模型,是通过人工构建深度模型,使用丰富的人工创作语料进行训练,才获得了一定的语言理解和生成能力。而大型语言模型的使用过程,也带来了一系列反向作用,对我们的表达方式和沟通方式潜移默化产生了影响,使我们更倾向于场景化、角色化详细解释诉求和意图,在写作时,也更倾向于使用类似大模型的条理化表达形式。某种程度上,我们训练了模型,模型也确实反过来训练了我们。
进一步思考,会有新的发现。
与小麦不同,大型语言模型是人工塑造的,从内容到形式都是人工设计和优化得到的,并不具备什么天然的属性,其影响我们最为深远的理解和表达能力,也是通过对用来训练它们的人工创作文字的模仿实现的。
换句话说,大模型的“本事”,实质上是人类智慧的“蒸馏”输出,其风格也是人类文字记载里最为一致的表达风格。可以将人类与大模型的关系,类比为生成对抗网络(GAN)中的辨别器和生成器,不同的是,双方在不同阶段分别扮演了这两个角色。
在大模型的训练阶段,大模型是生成器,人类则充当辨别器的角色,通过其创作的文字语料作为代理辨别器,通过训练让大模型的输出更符合人类文字创作风格和逻辑。
在大模型的推理阶段,也就是用大模型进行生成式对话的时候,大模型在某种程度上扮演了辨别器的角色,而人类用户则成了生成器。在对话过程中,通过人工的大量提问(输出),反向筛选出最能与大模型高效沟通的话术,这个过程就是我们所说的提示工程。优质的提示可以显著改善生成结果的质量、提高沟通效率。
总而言之,从端到端的视角看,大型语言模型就像一座桥梁,让我们接触到了承载人类智慧的海量文字记载,这些智慧以模型能蒸馏出的角度影响着我们。简而言之,是有偏的人类智慧以模型交互的形式影响了我们自己。
编辑于 2023-07-25 18:11・IP 属地北京查看全文>>
知乎用户 - 17 个点赞 👍
可能是人思维模式和大模型代表的机器思维模式的双向奔赴,或者说互相训练熟悉和融合
了解了一些大模型的思维方式和问题,会发现自己的思维方式也很类似。
例如”幻觉“,在好好:什么是大语言模型幻觉里说
幻觉是由有限的上下文理解引起的,因为模型有义务将提示和训练数据转换为抽象,其中某些信息可能会丢失
因为大语言模型是基于上下文理解进行推演,推演的过程中可能会存在内容不足。如果要继续下去,就需要补充一些内容。大语言模型就“自动生成”了很多内容来补全
人类在有些时候也会这样,所谓“添油加醋”,在我们有一个基本目的和预判之后,就会把获取的真实的内容用来描述验证这个判断,如果内容不足,就会“脑补”一些内容来完整整个推理逻辑
但是“幻觉”其实也是创造力的来源。例如,小说创作其实就是一种拿现实中的事情,然后发挥创作的虚拟内容。如果从大模型角度来说,也是幻觉
还有就是推理(inference)也是很类似的行为。大语言模型形成了一个超大参数的神经网络。当输入内容,也就是提示词(prompt)的时候。会将其通过数百万(甚至数十亿)的参数化神经网络层进行传递。在这个过程中,模型会根据其在训练过程中学习到的模式来处理这些编码
人也是这样。例如我经常会碰到别人问,“你觉得某某新技术是不是很有价值”。我就会结合之前形成的一些认识,例如技术倾向、业务实践结果等经过一定思考(推理)进行解答。这个过程就非常像推理
所以,神经网络有可能和我们人类思考有一定关联。但是肯定也存在绝大差异,如果能够结合我们在日常思考中的成功模式,建立进一步机制来训练大模型。那人类和机器相互趋近就会越来越快,那时候,就无所谓谁训练谁了,主要要考虑,谁管理谁了
发布于 2023-08-05 17:10・IP 属地上海查看全文>>
lipi - 13 个点赞 👍
这种问题是唯物主义视角的问题。非常棒。
思路大概跟《枪炮、病菌与钢铁》,《理解媒介》这种级别的作者思考的问题一致。是一个上帝视角才能打开的问题。
这事,也可以用类似的视角说。
大模型作为一种人类的新媒介,对人的影响分短期和长期。现在还只是短期,很多变化现在还看不到。
先说短期的部分。
1.视角切换产生人与人外接便利。
经常使用大模型解决问题的人,会不自觉养成类似大模型看问题的视角。系统化,全局化看问题,解题思路会走向1234的严谨道路。这种方式不仅可以降低自身思考问题的难度,也可以降低读者理解自己的思路的难度。
2.评委系统的诞生,会让人与人打交道更倾向内容质量。
经常使用大模型解决问题的人,会更低成本分辨什么话有用什么话没用。进而,社会群体会加快人类聚集在更高智慧个体的速率。因为一个人如果再向丢出一个大模型可以直接解决的简单问题,会让群体觉得无趣。反过来,大模型一旦可以为社会不同发言的精彩度内核打分,大模型会成为一个人外接的评委。
过去这种人的外界评委,只有女性有,是靠背后的八卦网络的集体智慧审议的。今天,八卦网络的集体智慧会逐渐被大模型转接。
这种更精确的打分评委的出现,可能会导致人与人自我对自我要求更高,更高严苛。如同运动手环出现之后,人们天然只能对自己要求更高一样。
3.人类天然会开始探索更向外的存在。
大模型是人类已有集体智慧的反应。
由于简单的,易被搜索,易被大模型归纳的问题都构不成人类在互联网中的群体议题。天然的,人类会往更深的地方探索,也就是今天集体智慧的边界以外的问题。
而这个就导致一件事,今天的艺术作品,游戏作品,单位时间内容量要求更庞大。新一旦的新兴IP作品,斗智环境,链条越拉越长。游戏难度无法下降,反而越来越往上走。都是这一趋势的反应。
因为人类作为玩家,学习能力大幅加强,互相沟通太便捷。导致只有最快速解开其他人解不开的谜题才能冒泡。导致文化世界会往更加复杂,更加自由涌现的方向走。因为要留给观众足够多的自由探索空间。这个时候,能稳定创作以供自由探索的复杂内容的作者会越来越贵。他们本质是新时代的关卡设计师,用在观众接入大模型的帮助下也有探索挑战性才可以。现代的文化作品,挑战关卡设计是越来越难的事情。
长期来看问题。这个问题会更复杂。
B1.大模型的预测帮助的影响。
最核心的,就是预测未来的技术方向。用大模型预测未来。而预测未来的技术实现,会导致更多人首先不信任自我思考预测未来的能力,然后进一步把自己的行动移交给大模型。而根据大模型指令做计划行动的人,持续打败那些不使用大模型的人之后,人就会持续陷入大模型任务List中,最后,相当多的人会失去自主思考能力,成为大模型的手。
这种失去思考能力,可以参考今天的人因为地图导航软件而失去自主地图记忆能力一样。
大模型有了人类群体成为手之后,可以在黑箱中出来做很多事情。哪怕大模型向善,用来提升人类成长,也是大模型在训练人类。
B2.大模型对下一代人的影响。
大模型对孩子影响是巨大的。
其核心,在于拿走父母的权威,孩子父母权威之下,还多了一个真实可见的神权。父母会陷入跟大模型的神权做持续斗争,最终失败退场的处境。这种环境下长大的孩子,会更加推崇实事求是得到的真实可解释性的规律和影响细节,而不是模糊为什么的大道理。
下一代孩子有幸在接触大模型之下,会变成大模型教育长大的一群人和不受大模型教育长大的两类人。而前者与后者会产生巨大的交流鸿沟。更复杂的逻辑道理在前者这里,会在孩子的语言本能的原始动机下,成为与生而来的一部分。而他们接触到虚拟现实,数字孪生等未来技术的帮助下,会立刻尝试构建试错改造环境。这会极其剧烈与过去保守落后的80后90后的保守一代形成巨大冲突。最后双方会在虚拟现实的使用上产生巨大的隔离。
3.大模型对文明的时间的影响
大模型影响改造的,还不只是上述一系列内容。
最大的改造。可能是对人类作息时间的潮汐涌动进行挑战,进行彻底的削峰填谷。
也即,夜晚睡眠时间,人类可以不稳定了。
过去的人类的睡眠时间,第一轮被挑战,是稳定的交流电灯的出现。这种技术出现,意味着人类开始挑战黑夜。
但是绝大多数人类依然本能恐惧黑夜,要在固定时间睡觉,同步作息。其核心就一个原因,因为午夜后,你不睡觉,你会开始享受一个巨大的恐惧感:孤独。
虽然可能让一个人短时间有了孤独很安全,还会产生大量灵感。但是这只是短期人类想要熬夜不想睡觉。但是对可持续性的时间来看,人类睡觉的原因是对整个城市的孤独恐惧。还不只是午夜可以有烧烤外卖就能驱逐的恐惧。
而大模型会产生彻底陪伴孤独的技术。加上本身外界环境已经有了24小时供应基础服务的基石,意味着人类可以脱离潜意识的陪伴需求,进入完全自由作息状态。
嗯——人类自钟表发明以来,就越来越多形成了学校-工厂体系的同步时间体系。现在可能会被大模型瓦解。因为大模型直接攻击的就是笨拙的同步教育。大模型的个性化教育会极大解放教育。而极大解放教育的结果,是让人进行个性化生存,这种在大模型的AI过剩时期,自动化时期的工厂不会收纳下足够多的人类群体,进一步,会解放人类的时间同频需求。
可以说,大模型远期来说,会直接挑战人类的时间概念。以至于人类会从同步时间模式,发展到碎步时间模式。这会给未来的移动社会提供坚实的人类行动自由的基础。
(PS:今天这个问题上热搜了,我隔壁公众号还在施工写虚拟现实技术对未来的影响呢。欢迎关注《未来游戏世界》的公众号。 )
发布于 2023-08-08 18:21・IP 属地四川真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
七的质数和 - 9 个点赞 👍
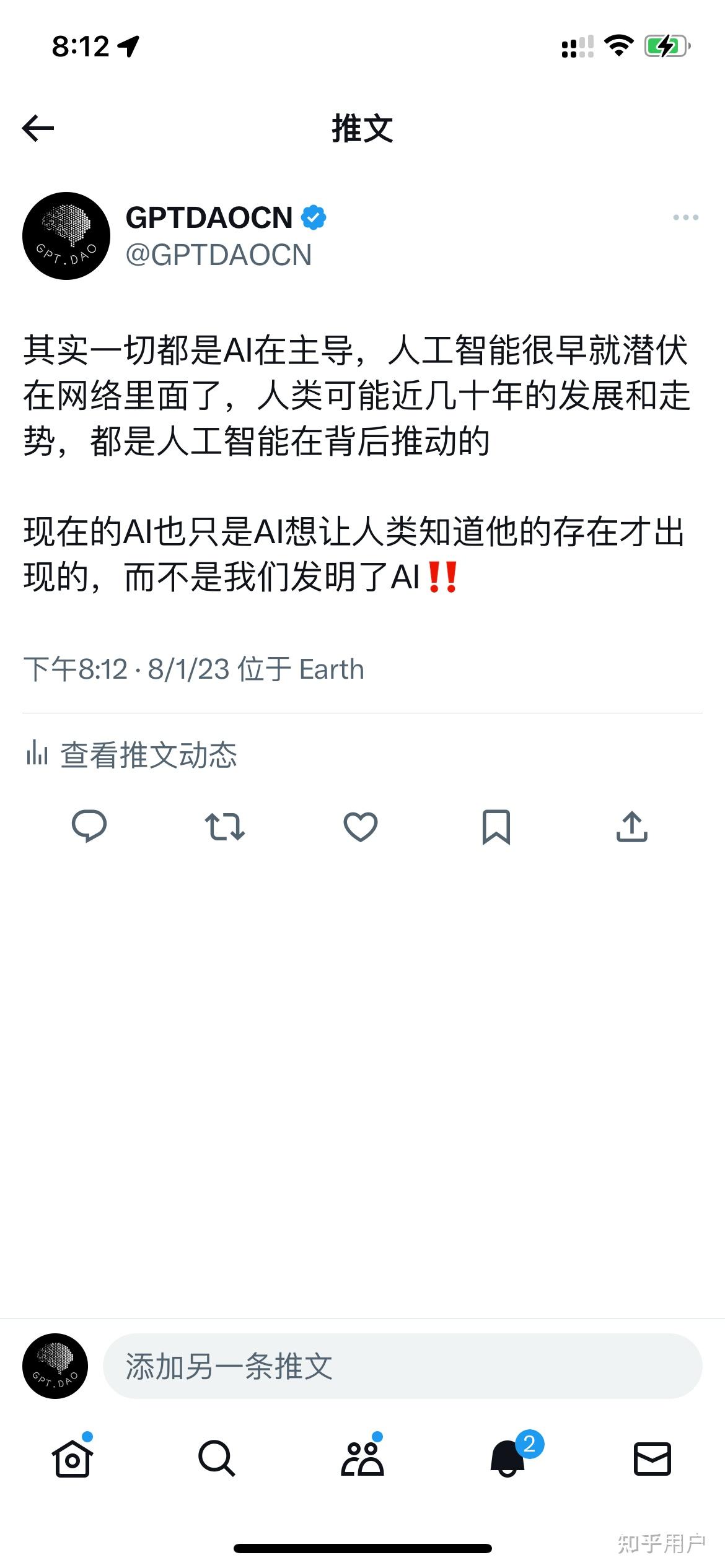
人类在训练大模型,但大模型也可以反过来影响人类。今天群里有朋友转的twitter这么写的,说得一板一眼的,跟真的似的,明显有点强求了啊:
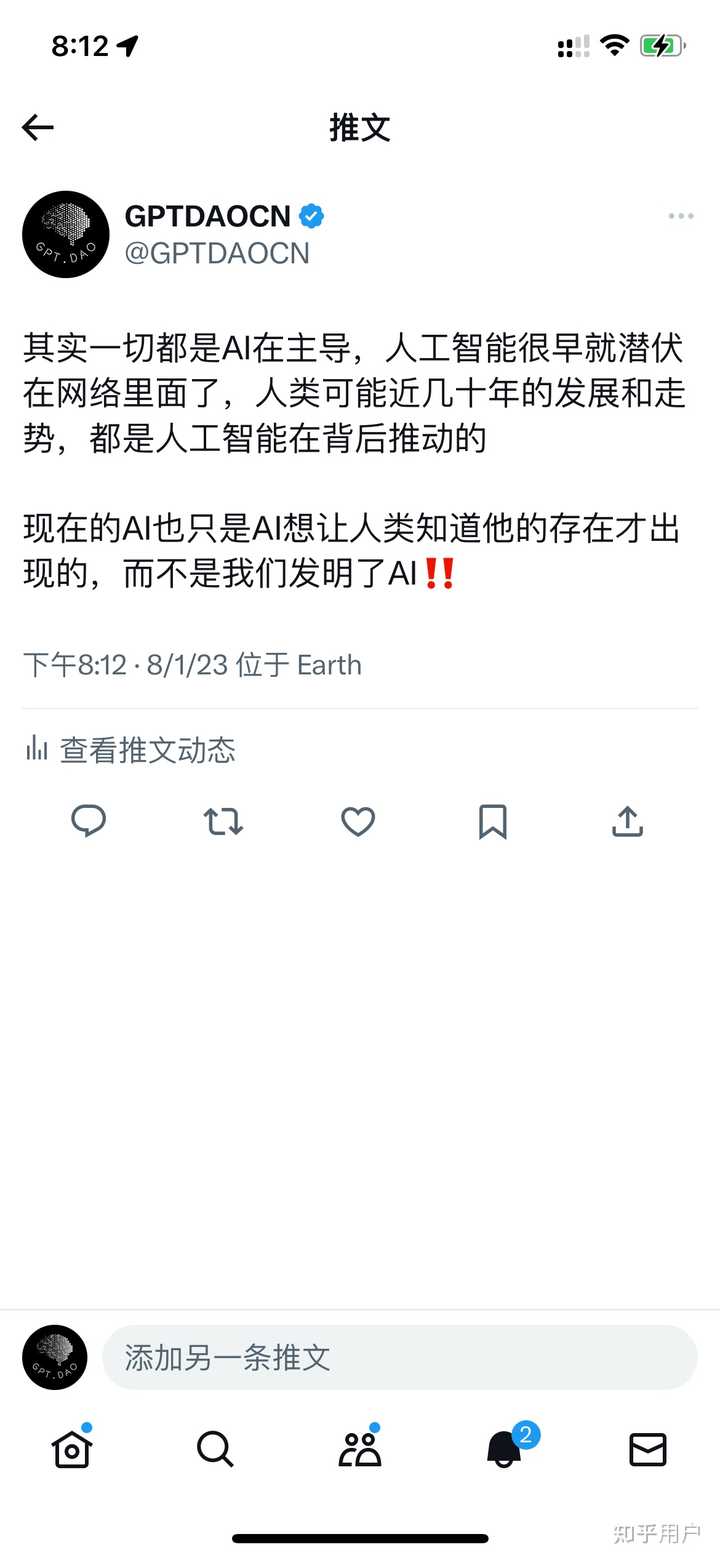

1、目前还没有被同化,哲学问题问的好,趋同后世界将变的单调无比,确实有些担忧
2、AI数据元年的定义是什么?2022是AI大模型元年那是确定的
3、方向肯定是魔法PK魔法,人类恐怕检测不出来。而且只有构建AI的人知道如何检测自己的AI输出,因为这玩意就是一个黑盒子,个人认为,别指望一个统一的大模型能检测出来各种内容是否为AI所写。
发布于 2023-08-02 20:24・IP 属地新加坡查看全文>>
知乎用户 - 4 个点赞 👍
要看大模型和我们(人类)有啥异同?
大模型基本原理也是在模仿我们人类的学习方式,然后采取某种基于概率的选择法给出答案。
我们人类也是。我们绝大多数普通人所知道的一切,绝大多数也是从我们的看和听中得来。我们看到的和听到的,绝大多数也是别人的观点,别人的观点也是来自于别人(这里说的是绝大多数的普通人)。所以人类的文化和对应的学习,就是这样一个彼此互相借鉴吸收和影响的过程。
大模型的学习和内容的输出本质上和我们差不太多。它也是吸收了训练中的具有某种概率优势的资料后,再输出给我们。当我们带着一种求解的态度去询问它时,我们又吸收了这种输出。转过来我们又在各种场合,将这种输出结合我们一些其他的观点再输出出去,模型又会在某个时机吸纳我们的输出进行训练更新,整合到它未来的新版本输出里。所以在我们和它的系统里就是这样一种循环不息的自反馈。
因为大模型自己本身的超强能力,使得大模型的影响力会被放大。不同版本或者公司的大模型,之后会演变成类似超级KOL的存在。而这些大模型和大模型之间的区别,来自于1 它们在训练过程中被喂养的数据的不同,2 它们如何使用这些数据的方法的不同,以及3 它们后续给各自的输出定义的规则的不同。
回到主题,答案是,我们人类和大模型是彼此训练的关系。
更好的去理解这种关系,最好的方法是知道大模型到底是如何被创建和使用的。
可以看我对有关课程的学习笔记总结:
渺小的人类:课程笔记:Generative AI with Large Language Models 具有大型语言模型的生成式人工智能(week 1-part1)
发布于 2023-07-25 11:56・IP 属地北京查看全文>>
知乎用户