AI 生成写真照爆火,未来会替代海马体等写真照相馆吗?

- 232 个点赞 👍
本质上其实是一样的,人肉p图写真照相馆是1.0,AIGC写真照相馆是2.0,这是技术迭代的问题。
在信息时代,“社交网络”的崛起与发展,极大破坏了人们的正常社交能力。
在社交网络上,每个人都可能在伪装,只把自认更好的一面展现出去,并且还要使用各式各样的工具与手段刻意美化。
越来越多的人发现,大街上根本碰不到小X书上看到的风花雪月,那些把自己P的更漂亮更帅的人,他们欺骗的是别人。其实他们自己可能都不知道,他们欺骗的更多是自己,让自己真的相信被过度包装的自己就是自己。
这就是社交网络的一个极为重要的恶果。
随着时间的推移,人们普遍变得更不真诚了,绝大多数人甚至对自己都更不真诚了。
到了智能时代,这种现象只会更为严重。人们不仅可以美化自己的外表,包括P图还有整容,甚至连“智力”和“智慧”都可以低成本地随意美化了 。
比如在过去,很多话题一深入,很多人就无力参与了。现在不想看电影,可以看有快餐流水账电影讲解,不想看书,可以看听书总结,任何高深的话题,知乎搜一下看到个大概,都可以 “洋洋洒洒” 地 在其他短视频平台“高谈阔论”。
人们展现出来的“智慧”,可能不再是“积累”得到的,而是可以几个小时前“临时抱佛脚”获得的。
正如相由心生,没有丑女人只有懒女人,这些都是需要时间积累的,如今即使不用花钱花时间去沉淀维护容颜身材,也可以用几分钟临时加工出完美外观。
发布于 2023-08-01 07:00・IP 属地上海查看全文>>
孙悦礼 - 227 个点赞 👍
查看全文>>
画画的花噎菜 - 53 个点赞 👍
作者 :bubbliiiing , wuziheng
项目地址: https://github.com/aigc-apps/sd-webui-EasyPhoto
背景介绍
AIGC真实人像写真,妙鸭相机作为AIGC领域一款收费产品成功的为大家展示了,如何使用AIGC技术少量的人脸图片建模,快速提供真/像/美的个人写真,在极短的时间拥有了大量的付费客户。同时,随着StableDiffusion领域开源社区的快速发展,社区也涌现了类似 FaceChain 这样基于 Modelscope开源社区结合 diffusers 的开源项目,用于指导用户快速开发个人写真。然而对于大量使用SDWebUI的 AIGC 同学们,短时间内却没有一个效果足够好的开源插件,去适配真人写真这一功能。
作为FaceChain-Inpaint功能的开发团队,快速为社区开发了一款基于SDWebUI 插件生态的 EasyPhoto 插件,这款插件允许用户通过上传几张同一个人的照片,快速训练Lora模型,然后结合用户上传的模板图片,快速生成 真/像/美的写真图片。让我们先来快速看看效果


图.1
项目地址: https://github.com/aigc-apps/sd-webui-EasyPhoto
欢迎大家多多提ISSUE,一同优化,让每个AIGCer都拥有自己的AI写真相机!
原理介绍
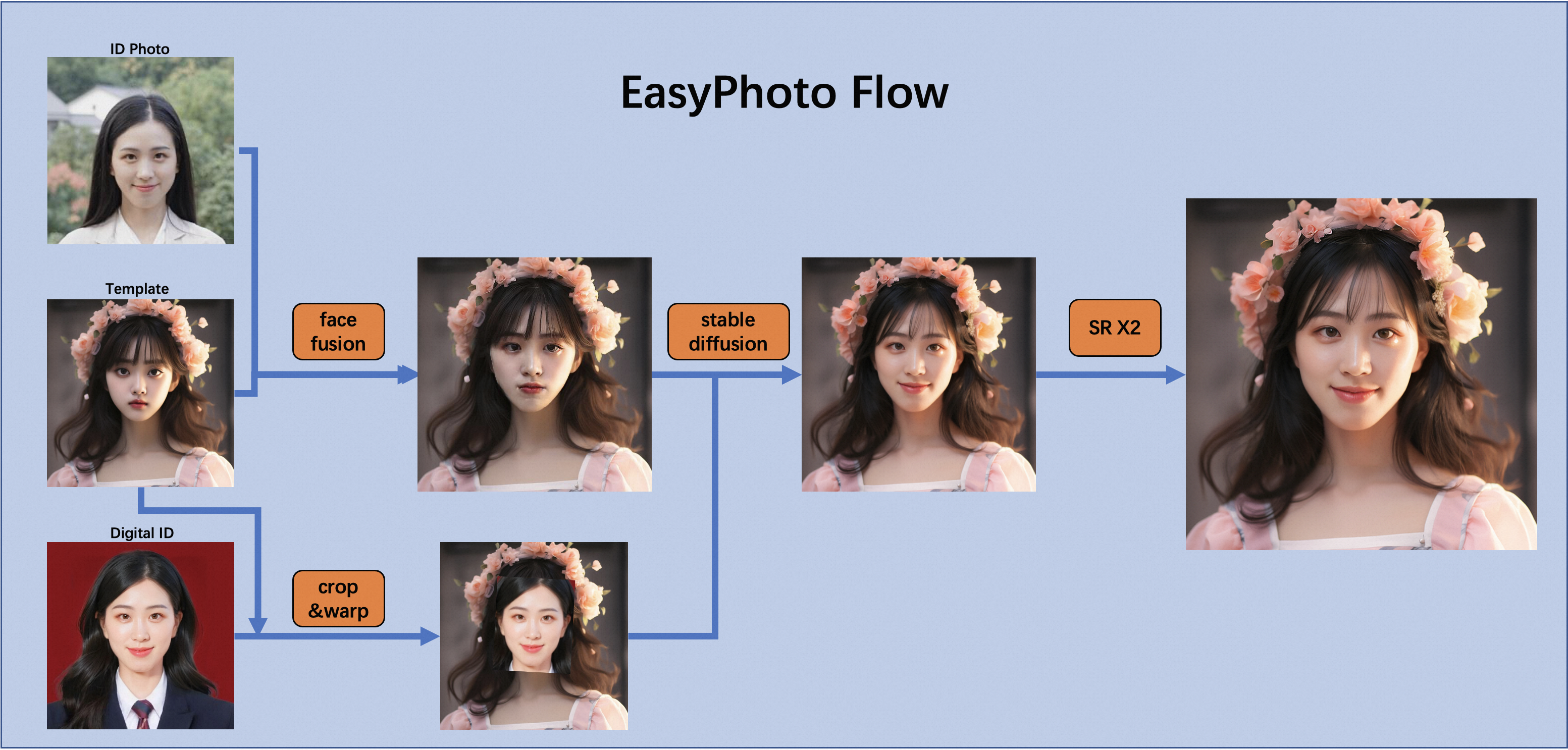
AI真人写真是一个基于 StableDiffusion和AI人脸相关技术,实现的定制化人像Lora模型训练和指定图像生成链路的集合,这里我们简单介绍我们在EasyPhoto中实现的相关技术,下图是EasyPhoto的生成链路介绍,我们将从在后续的章节简单介绍相关技术,更多细节也欢迎大家参考Repo的代码。(如果你已经对这一技术路线非常熟悉,欢迎直接跳到第三章 EasyPhoto & SDWebUI)
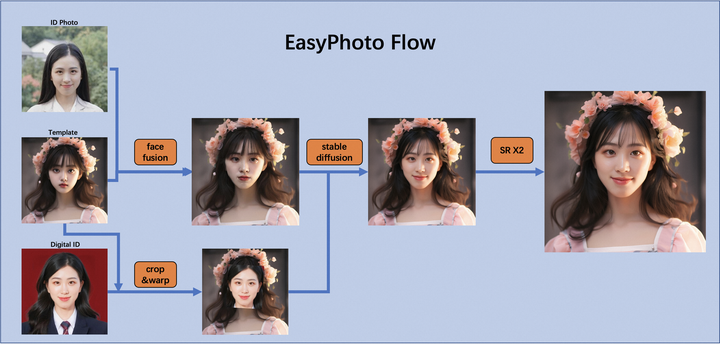

图.2
EasyPhoto整体分为训练和推理两个阶段, 下文图3详细展示了训练阶段,上图2展示了生成阶段。
EasyPhoto生成
EasyPhoto生成采用基于开源模型StableDiffusion + 人物定制Lora的方式 + ControlNet 的方式完成艺术照生成
- 使用人脸检测模型对输入的指定模板进行人脸检测(crop & warp)并结合数字分身进行模板替换。
- 采用FaceID模型挑选用户输入的最佳ID Photo和模板照片进行人脸融合(face fusion)。
- 使用融合后的图片作为基底图片,使用替换后的人脸作为control条件,加上数字分身对应的Lora,进行图到图局部重绘生成。
- 采用基于StableDiffusion + 超分的方式进一步在保持ID的前提下生成高清结果图。
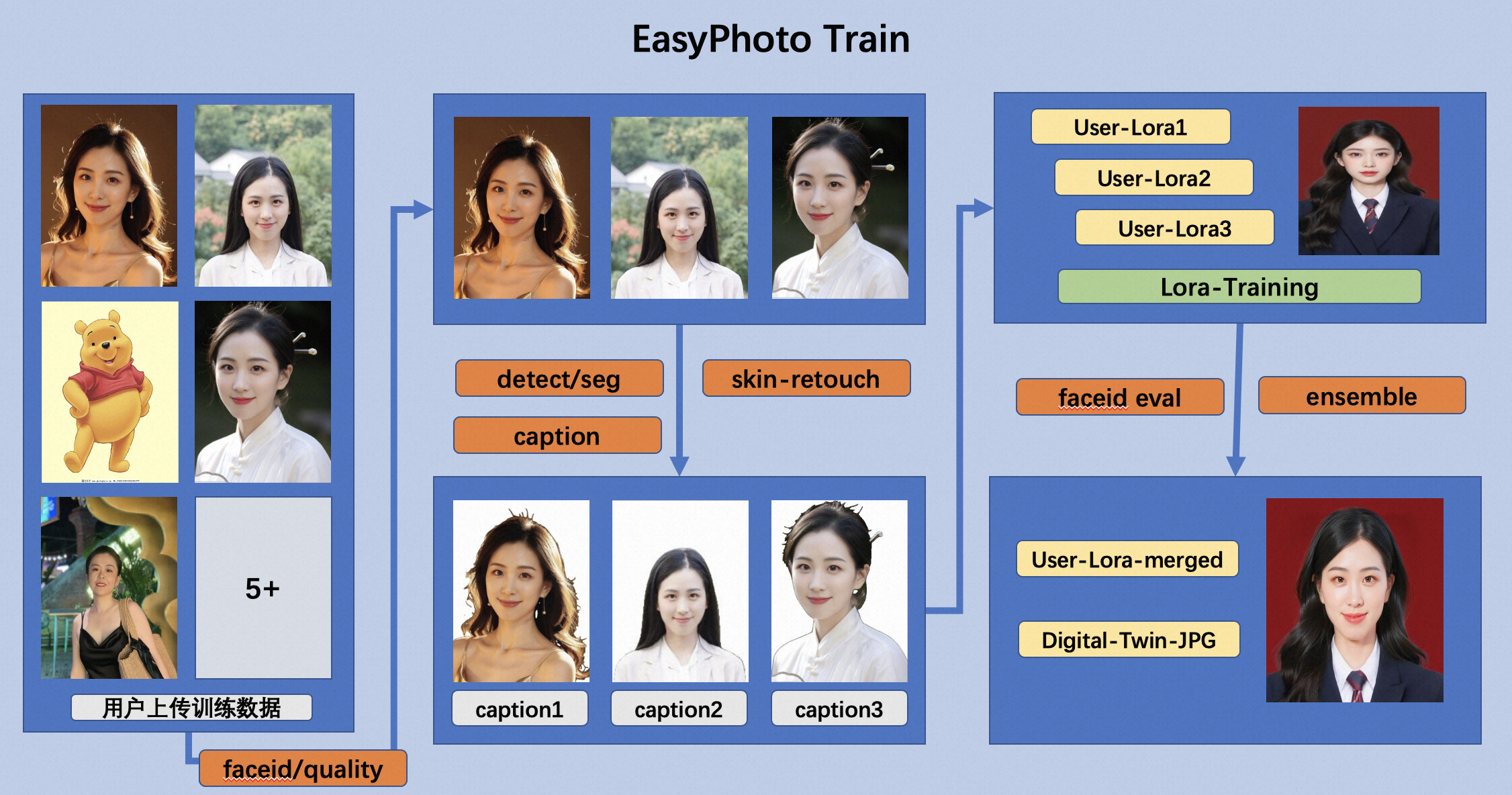
EasyPhoto训练


图3
EasyPhoto训练采用了大量的人脸预处理技术,用于把用户上传的图片进行筛选和预处理,并引入相关验证和模型融合技术,参考图3.
- 采用FaceID和图像质量分数对所有图片进行聚类和评分,筛选非同ID照片。
- 采用人脸检测和主体分割,抠出1筛选后的人脸图片进行人脸检测抠图,并分割去除背景。
- 采用美肤模型优化部分低质量人脸,推升训练数据的图片质量。
- 采用单一标注的方案,对处理后的训练图片进行打标,并使用相关的Lora 训练。
- 训练过程中采用基于FaceID的验证步骤,间隔一定的step保存模型,并最后根据相似度融合模型。
我们将从在后续的章节简单介绍涉及到的相关技术的原理,更多细节也欢迎大家参考Repo的代码。(如果你已经对这一技术路线非常熟悉,欢迎直接跳到第三章 EasyPhoto & SDWebUI)
文图生成(SD/Control/Lora)
StableDiffusion
StableDiffusion作为Stability-AI开源图像生成模型,通常分为SD1.5/SD2.1/SDXL等版本, 是通过对海量的图像文本(LAION-5B)对进行训练结合文本引导的扩散模型(DiffusionModel),使用训练后的模型,通过对输入的文字进行特征提取,引导扩散模型在多次的迭代中生成高质量且符合输入语义的图像。感兴趣的同学可以参考 《stable diffusion原理解读通俗易懂,史诗级万字爆肝长文,..》, 下面的图像就是 stablediffusion 官网 Repo 贴出来的他们的效果。


图.3
ControlNet/Lora
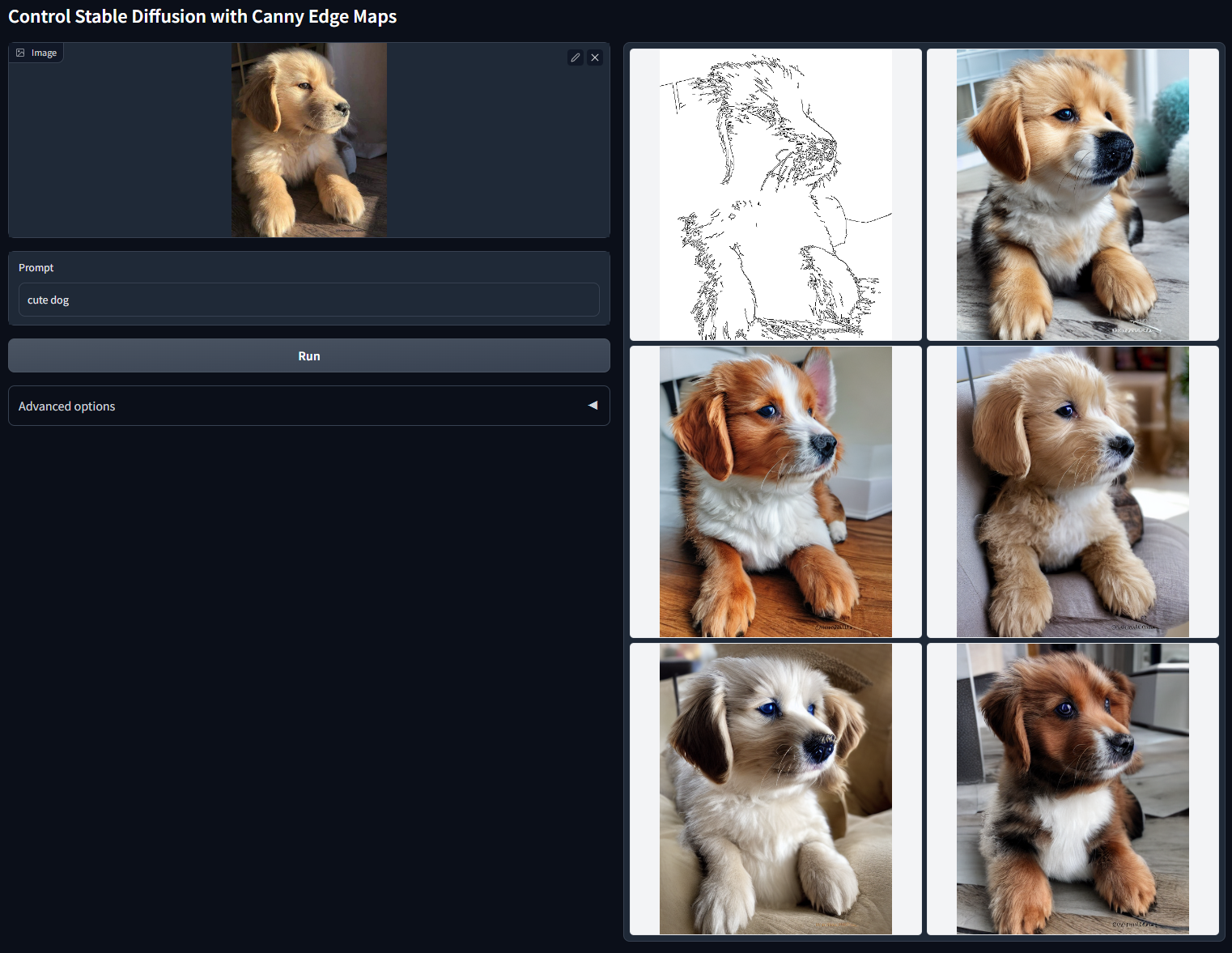
针对使用文本控制的StableDiffusion模型,如何对生成的图像内容进行更好的控制,一直是学术界和工业界试图解决的问题,本小节介绍的ControlNet和Lora就是常用的两种技术。也是图.2中使用的部分技术,用于控制边缘连贯性和指定ID生成。
ControlNet : 由《Adding Conditional Control to Text-to-Image Diffusion Models》提出的通过添加部分训练过的参数,对StableDiffsion模型进行扩展,用于处理一些额外的输入信号,例如骨架图/边缘图/深度图/人体姿态图等等输入,从而完成利用这些额外输入的信号,引导扩散模型生成与信号相关的图像内容。例如我们在官方 Repo 可以看到的,使用Canny边缘作为信号,控制输出的小狗。而我们在图中
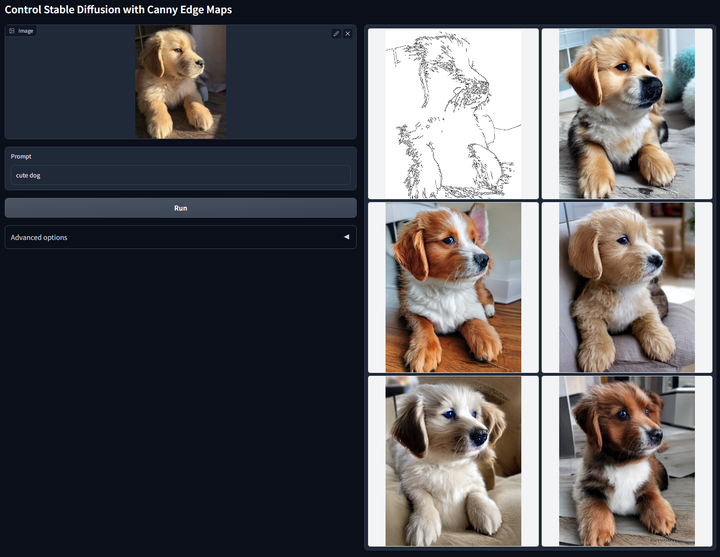

图.4
我们在图.2中看到 StableDiffusion有2个输入,其中一个部分就是用于控制边缘连贯性和脸型提示的ControlNet,我们使用了部分的Canny边缘和OpenPose人体姿态。
Lora :由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。AI真人写真需要保证最后生成的图像和我们想要生成的人是相像的,这就需要我们使用Lora 技术,对输入的少量图片,进行一个简单的训练,从而使得我们可以得到一个小的指定人脸(ID)的模型。当然这一技术也可以广泛用于,风格,物品等其他指定形象的Lora模型训练,大家可以在civitai.com等相关网页上寻找自己想要的Lora模型。
人脸相关AI模型
针对AI写真这一特定领域,如何使用尽量少的图片,快速的训练出又真实又相像的人脸Lora模型,是我们能够产出高质量AI写真的关键,网络上也有大量的文章和视频资料为大家介绍如何训练。这里我们介绍一些在这个过程中,我们使用的开源AI模型,用于提升最后人脸Lora训练的效果。
在这个过程中我们大量的使用了 ModelScope 和其他Github的开源模型,用于完成如下的人脸功能
人脸模型 模型卡片 功能 使用 FaceID insightface 对矫正后的人脸提取特征,同一个人的特征距离会更接近 EasyPhoto图片预处理,过滤非同ID人脸EasyPhoto训练中途验证模型效果EasyPhoto预测挑选基图片 人脸检测 cv_resnet50_face 输出一张图片中人脸的检测框和关键点 训练预处理,处理图片并抠图预测定位模板人脸和关键点 人脸分割 cv_u2net_salient 显著目标分割 训练预处理,处理图片并去除费劲 人脸融合 cv_unet-image-face-fusion 融合两张输入的人脸图像 预测,用于融合挑选出的基图片和生成图片,使得图片更像ID对应的人 人脸美肤 cv_unet_skin_retouching_torch 对输入的人脸进行美肤 训练预处理:处理训练图片,提升图片质量预测:用于提升输出图片的质量。 EasyPhoto & SDWebUI
SDWebUI [Repo]是社区最常用的StableDiffusion开发工具,从年初开源至今,已在Github 拥有100k 的star,我们提到的文图生成/ControlNet/Lora等功能,都被社区开发者贡献到这一工具中,用于大家快速部署一个可以调试的文图生成服务,所以我们也在SDWebUI下实现了EasyPhoto插件,将上述原理提到的 人脸预处理/训练/艺术照生成全部集成到了这一插件中。
项目地址:https://github.com/aigc-apps/sd-webui-EasyPhoto
用户可以参考SDWebUI的插件使用方式进行安装使用。
EasyPhoto插件简介
EasyPhoto是一款Webui UI插件,用于生成AI肖像画,该代码可用于训练与用户相关的数字分身。
- 建议使用 5 到 20 张肖像图片进行训练,最好是半身照片且不要佩戴眼镜(少量可以接受)。
- 训练完成后,EasyPhoto可以在推理部分生成图像。
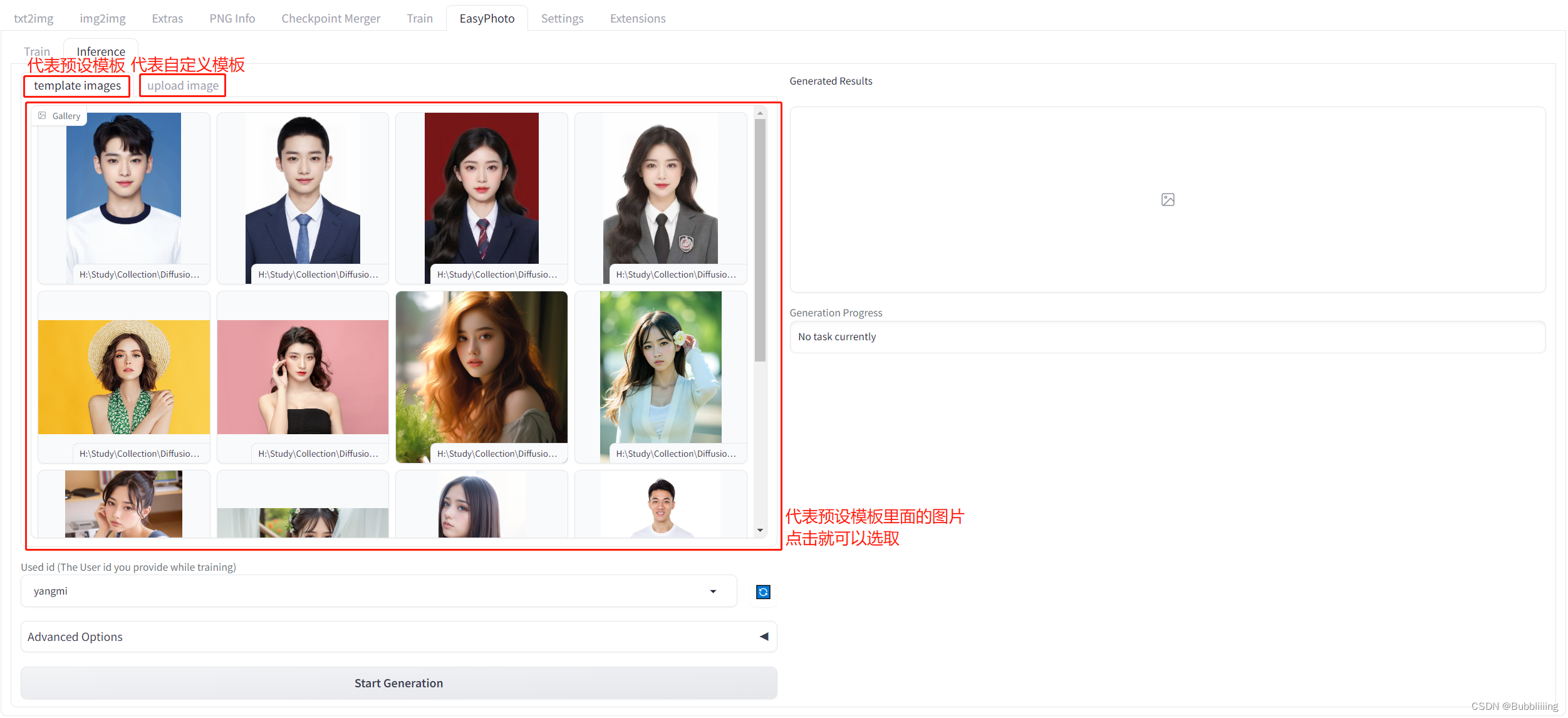
- EasyPhoto支持使用预设模板图片与上传自己的图片进行推理。
图.1, 图.6这些是插件的生成结果,从生成结果来看,插件的生成效果还是非常不错的:


图.6
每个图片背后都有一个模板,EasyPhoto会对模板进行修改使其符合用户的特征。在EasyPhoto插件中,Inference侧已经预置了一些模板,可以用插件预置的模板进行体验;另外,EasyPhoto同样可以自定义模板,在Inference侧有另外一个tab页面,可以用于上传自定义的模板。如下图所示。
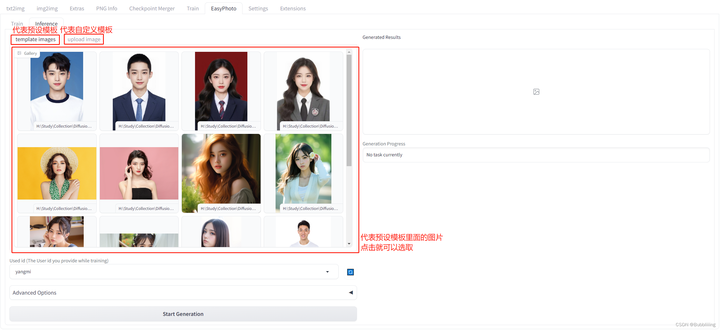

图.7
而在Inference预测前,我们需要进行训练,训练需要上传一定数量的用户个人照片,训练的产出是一个Lora模型。该Lora模型会用于Inference预测。
总结而言,EasyPhoto的执行流程非常简单:1、上传用户图片,训练一个与用户相关的Lora模型;2、选择模板进行预测,获得预测结果。
安装方式一: SDWebUI界面安装
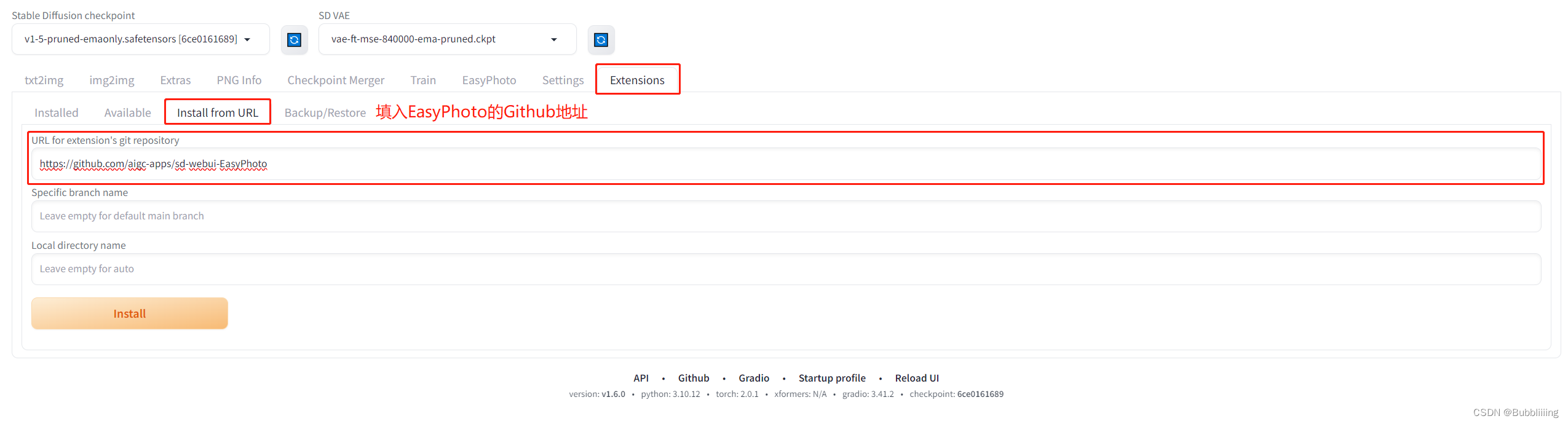
网络良好的情况下!!!在SDWebUI中跳转到Extentions,然后选择install from URL。输入https://github.com/aigc-apps/sd-webui-EasyPhoto,点击下方的install即可安装。
在安装过程中,会自动安装依赖包,这个需要耐心等待一下。安装完需要重启WebUI。


安装方式二:源码安装
如果你想要使用项目源码安装,直接进入到Webui的extensions文件夹,打开git工具,git clone即可。下载完成后,重新启动webui,便会检查需要的环境库并且安装。


图.8
其他安装项:ControlNet
EasyPhoto需要SDWebUI支持ControlNet,具体使用的相关插件是Mikubill/sd-webui-controlnet。在使用 EasyPhoto 之前,您需要安装这个软件源。
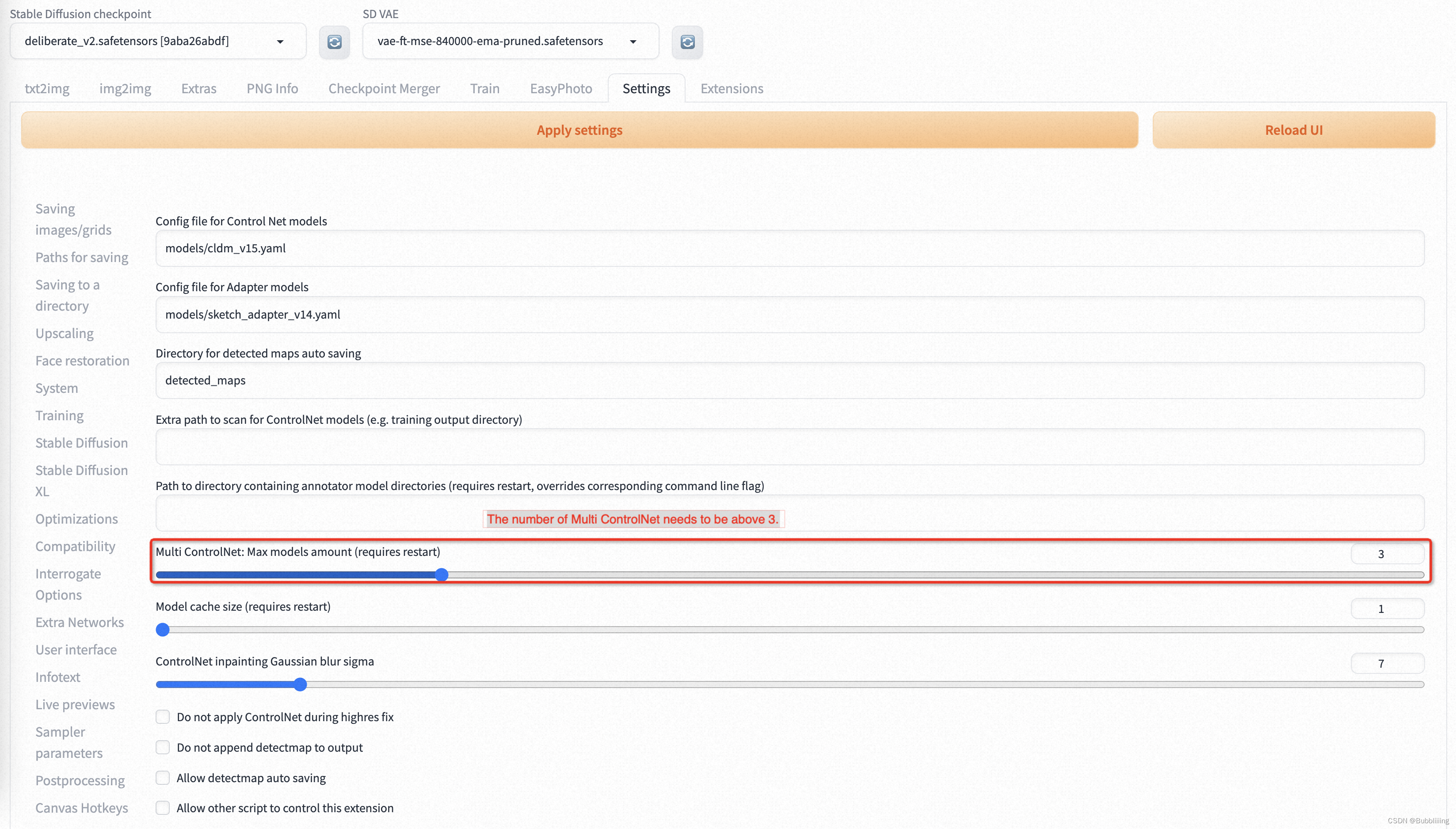
- 此外,我们至少需要三个 Controlnets 用于推理。因此,您需要设置 Multi ControlNet: Max models amount (requires restart)。
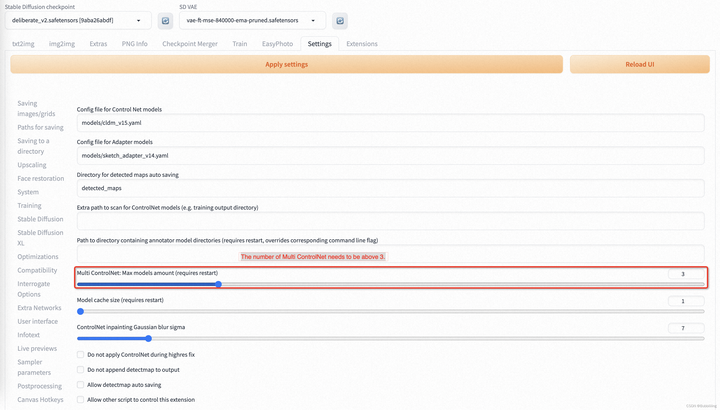

图.9
EasyPhoto训练
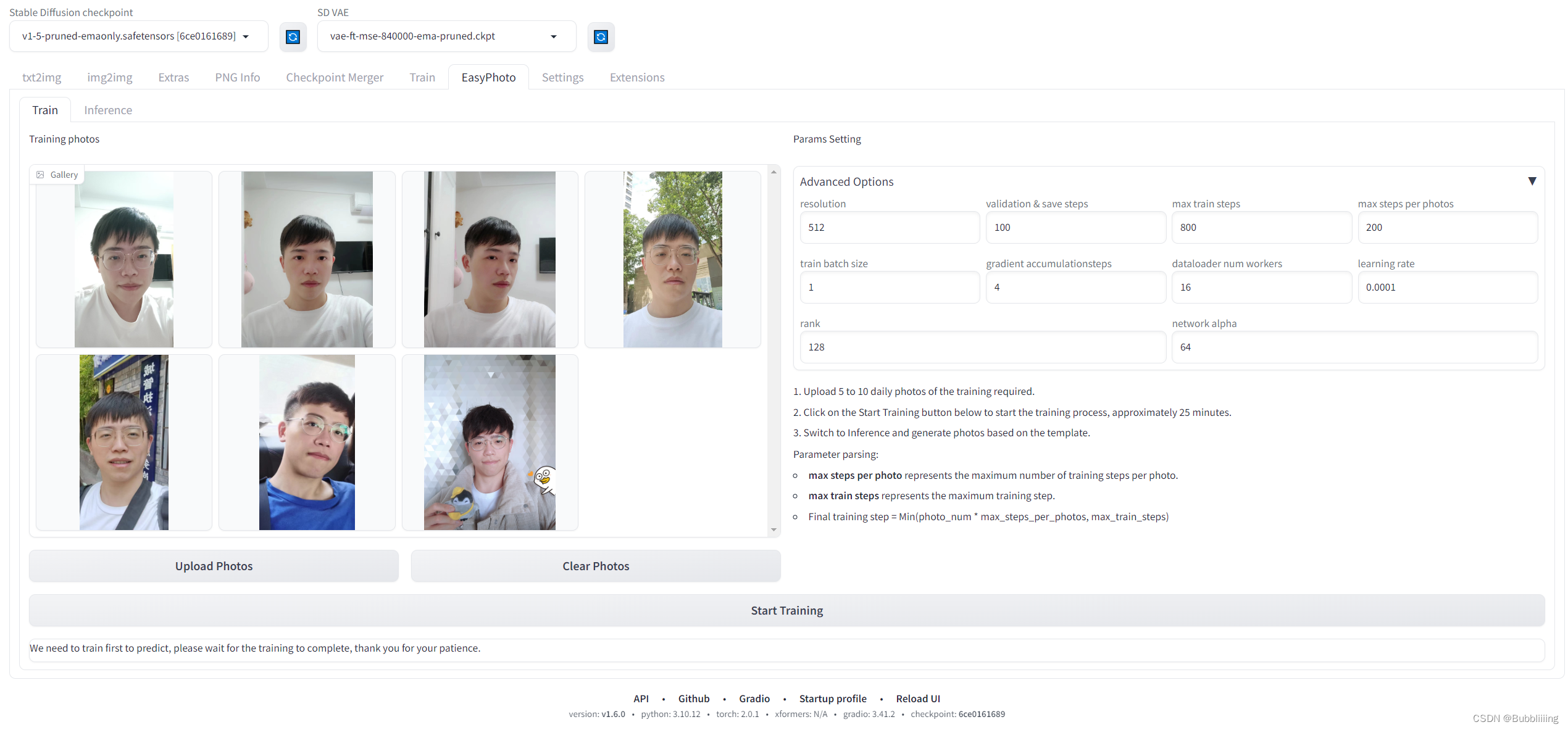
EasyPhoto训练包含如下2个步骤 1. 上传个人图片 2. 调整训练参数 3点击训练并设置ID, 整体界面如下
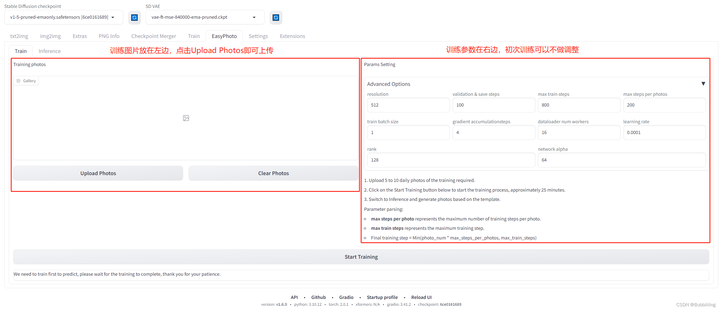

图.10
上传训练图片
左边是训练图片,点击Upload Photos即可上传图片,点击Clear Photos可以删除已经上传的图片
调整训练参数
上传完图片后,右边是训练参数,初次训练可不做参数调整。
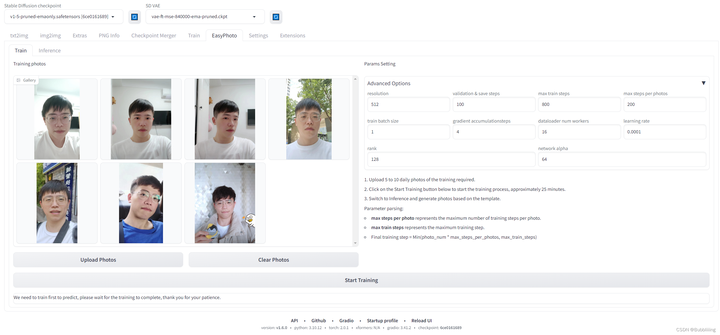

图.11
这里我们也对参数进行一个介绍
参数名 含义 resolution 训练时喂入网络的图片大小,默认值为512 validation & save steps 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重 max train steps 最大训练步数,默认值为800 max steps per photos 每张图片的最大训练数,默认为200,与max train steps结合取小。 train batch size 训练的批次大小,默认值为1 gradient accumulationsteps 进行梯度累计,默认值为4,train batch size=1的时候,每个step相当于喂入四张图片 dataloader num workers 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置 learning rate 训练Lora的学习率,默认为1e-4 rank Lora 权重的特征长度,默认为128 network alpha Lora训练的正则化参数,一般为rank的二分之一,默认为64 根据上述表格最终训练步数的计算公式也比较简单。
FinalTrainingStep=min(photo_num×max_steps_per_photos,max_train_steps)
简单来理解就是:图片数量少的时候,训练步数为photo_num * max_steps_per_photos。图片数量多的时候,训练步数为max_train_steps。
训练&设置ID
完成设置后,点击下方的开始训练,此时需要在上方填入一下User ID,比如 用户的名字,然后就可以开始训练了。


图.12
观察训练
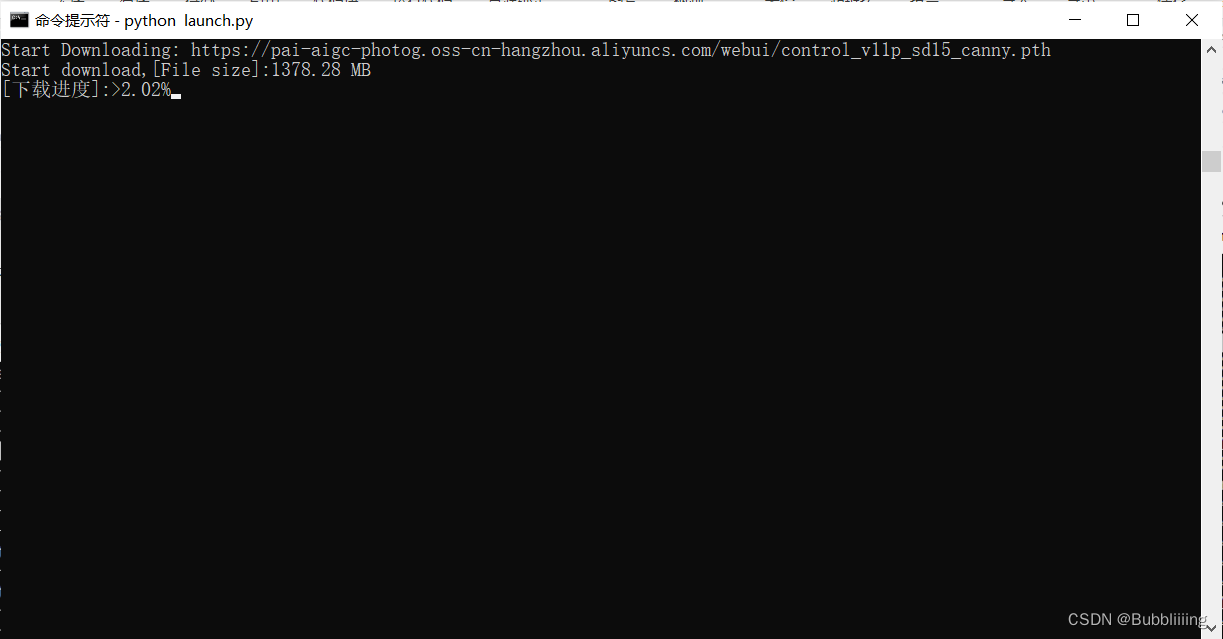
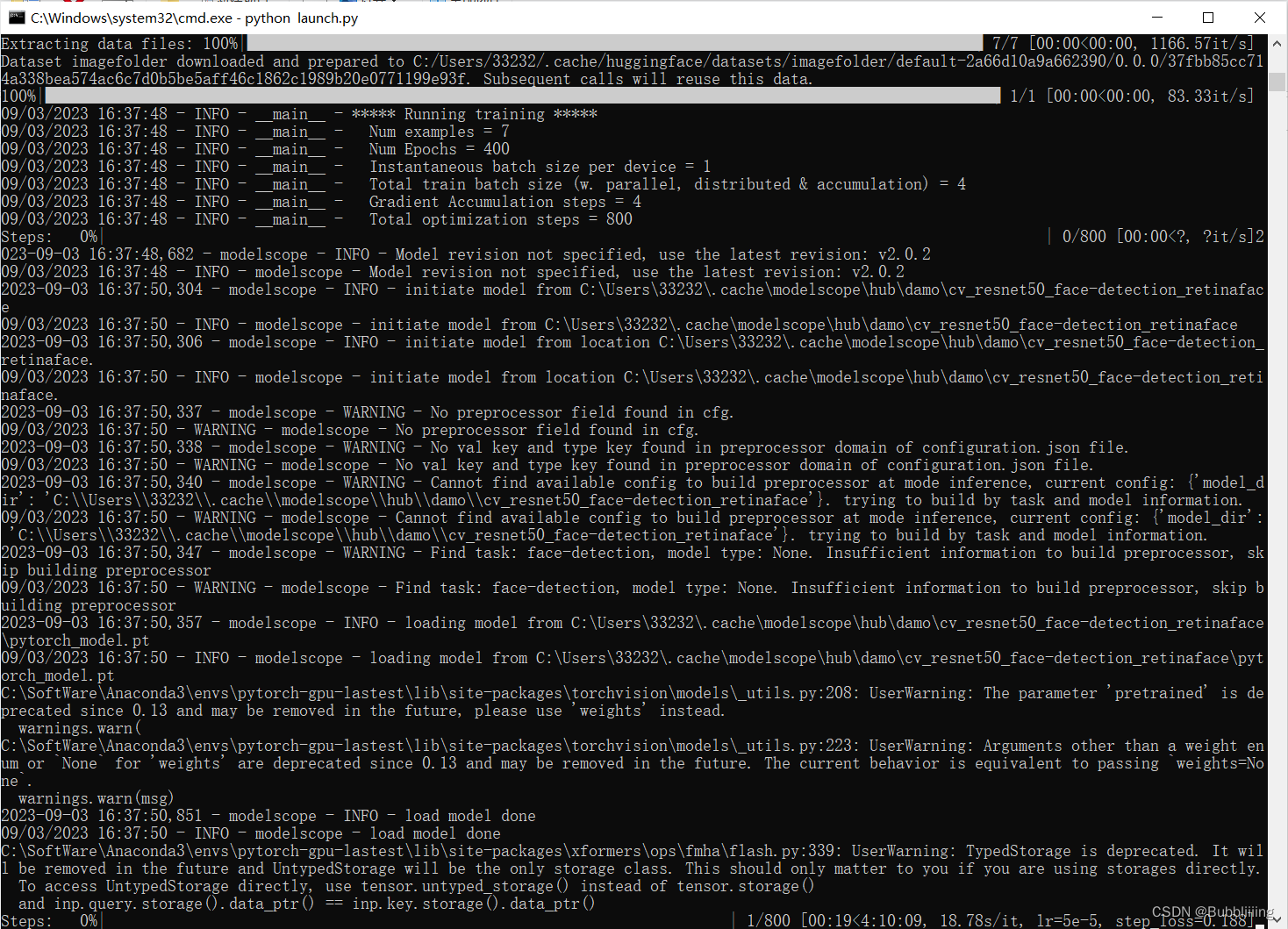
!!初次训练时会从我们预备的oss(公用)上下载一部分预训练模型的权重,我们耐心等待即可,下载进度需要关注终端。
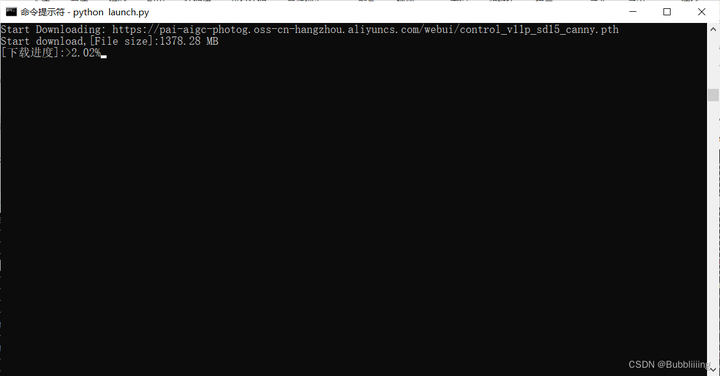

图.13
训练正常开始的相关log
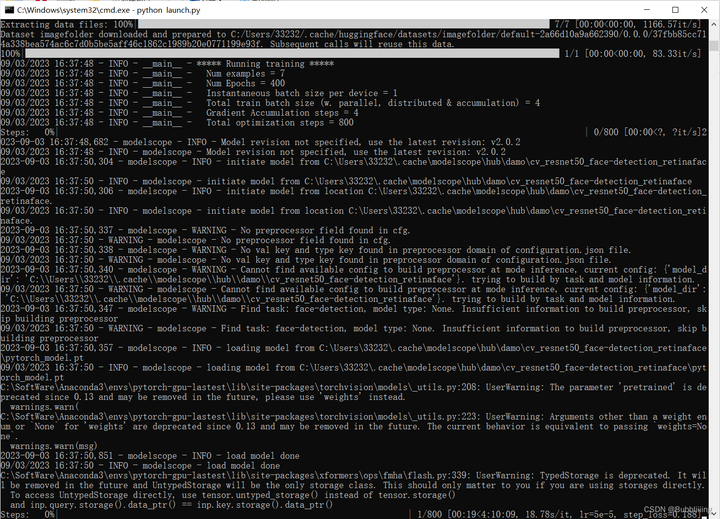

图.14
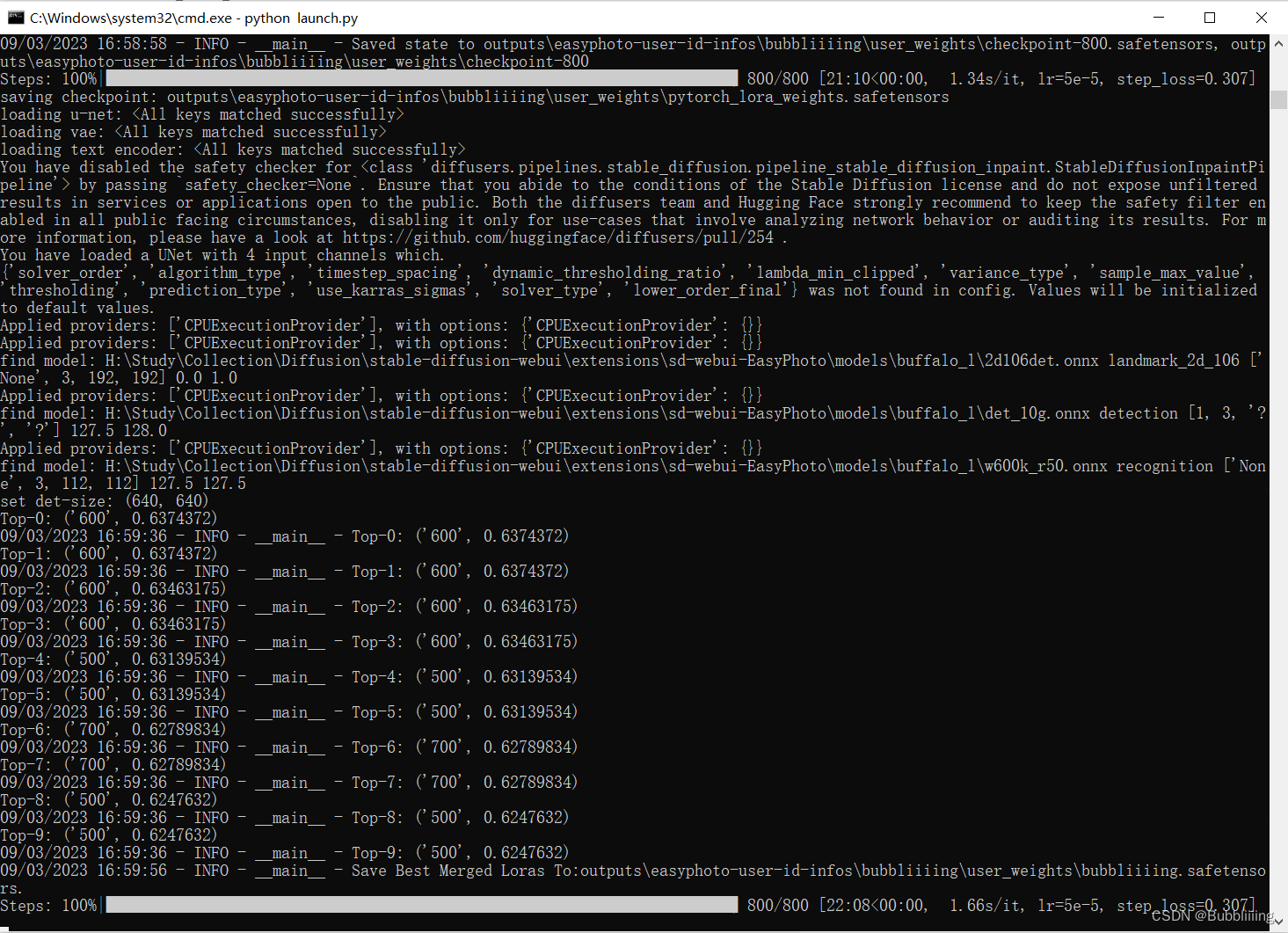
终端显示成这样就已经训练完了,最后这步是在计算验证图像与用户图像之间的人脸 ID 差距,从而实现 Lora 融合,确保我们的 Lora 是用户的完美数字分身。
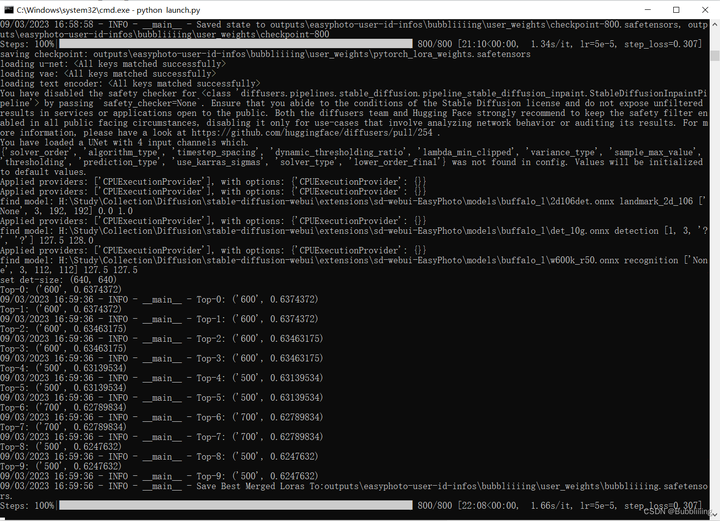

图.15
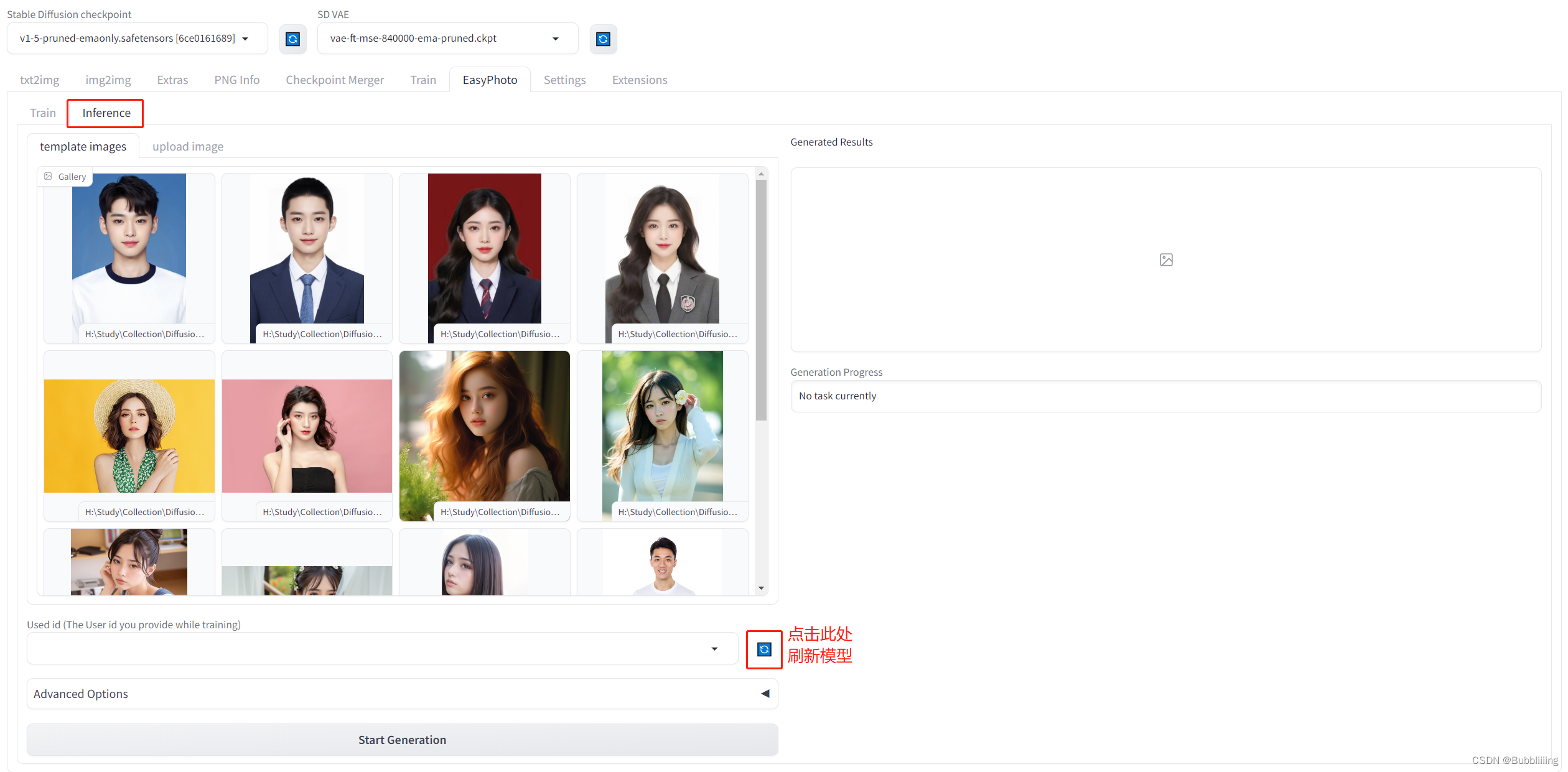
EasyPhoto预测
训练完后,我们需要将tab页转到Inference。由于Gradio的特性,刚训练好的模型不会自动刷新,可以点击Used id旁的蓝色旋转按钮进行模型刷新。


图.16
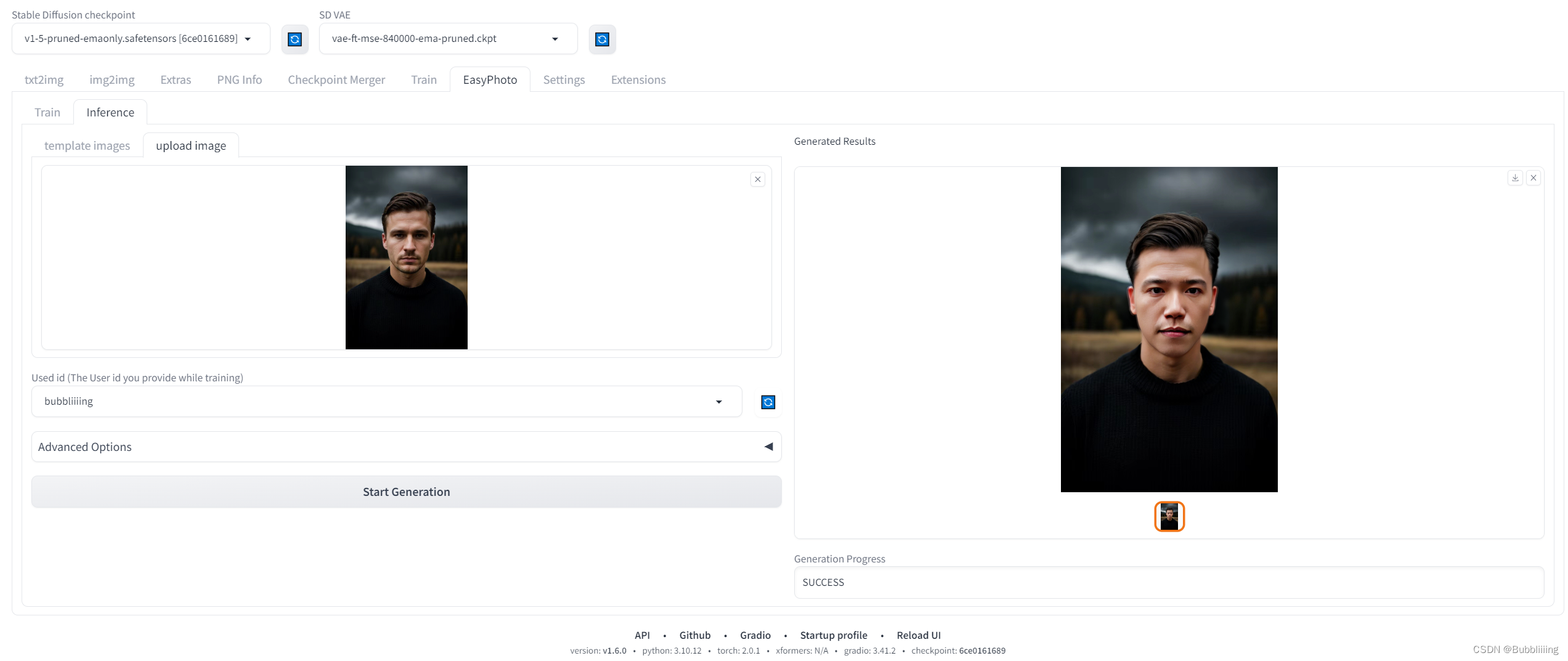
- 刷新完后选择刚刚训练的模型,然后选择对应的模板即可开始预测。
- 初次预测需要下载一些modelscope的模型,耐心等待一下即可。
预置了部分模板,也可以切到upload image,直接自己上传模板进行预测。然后我们就可以获得预测结果了。
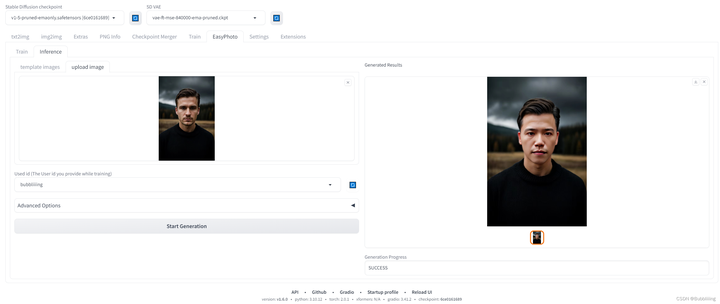

图.17
预测参数说明
关于预测界面的部分参数说明
参数名 含义 After Face Fusion Ratio 第二次人脸融合的比例,越大代表越像 First Diffusion steps 第一次Stable Diffusion的步数 First Diffusion denoising strength 第一次Stable Diffusion重建的比例 Second Diffusion steps 第二次Stable Diffusion的步数 Second Diffusion denoising strength 第二次Stable Diffusion重建的比例 Crop Face Preprocess 是否先裁剪人脸后再进行处理,适合大图 Apply Face Fusion Before 是否进行第一次人脸融合 Apply Face Fusion After 是否进行第一次人脸融合 写在最后
EasyPhoto全部使用来自开源社区的模型和相关技术,旨在探讨StableDiffusion在AIGC X 真人写真领域的技术和相关应用,文章所有涉及的图片仅做演示使用,如有侵权请及时联系我们,也请大家引用时表明转载!!!。
非常欢迎大家下载试用,并参与开发,共建真像美的AI写真!
编辑于 2023-09-04 15:51・IP 属地浙江查看全文>>
陀飞轮 - 32 个点赞 👍
别,这些软件收费也就算了,还要上传自己的照片。上传时是正经的,之后就不知道了。Ai有你素材,就很大问题,因为隐私问题就是个大问题。
写真?还不如看SD.大模型训练的都不知道谁是谁!Maj出了新版本,这张不是我画的,风格正在复现,绝绝子。你看他用的黑科技!
这是tag:
1girl, seaside, waves, sunrise, backlighting, lens flare, wind,(upper body:1.5), <lora:MengX girl_Mix_v30:1>,
Negative prompt: ng_deepnegative_v1_75t, (badhandv4), realisticvision-negative-embedding, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)), mural,
这是参数:
Steps: 30, Sampler: DPM++ 2M alt Karras, CFG scale: 7, Seed: 3150609882, Size: 768x512, Model hash: d7e2ac2f4a, Model: majicmixRealistic_v25, Denoising strength: 0.3, Clip skip: 2, Token merging ratio: 0.2, Token merging ratio hr: 0.2, ADetailer model: face_yolov8m.pt, ADetailer confidence: 0.3, ADetailer dilate/erode: 32, ADetailer mask blur: 4, ADetailer denoising strength: 0.3, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer model 2nd: hand_yolov8s.pt, ADetailer prompt 2nd: beautiful hand, ADetailer confidence 2nd: 0.3, ADetailer dilate/erode 2nd: 32, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.3, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 32, ADetailer version: 23.7.10, ControlNet 0: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.5, starting/ending: (0, 0.8), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (512, 1, 64)", Hires upscale: 2, Hires steps: 15, Hires upscaler: 4x-UltraSharp, Lora hashes: "MengX girl_Mix_v30: 565a167a240d", TI hashes: "ng_deepnegative_v1_75t: 54e7e4826d53, badhandv4: 5e40d722fc3d, realisticvision-negative-embedding: 5511b02e263f", Version: v1.5.0


以下图片均为自己Ai工具生成,不保真!
更新,快看有嗨丝。



这个话题,我最近发了好多。妈耶,科技的进步和人工智能的发展正逐渐改变着我们的生活方式,包括艺术创作和摄影行业。AI生成的写真照片确实在近些时间爆火,其高度还原真实感和表现力,令人惊叹不已。如果不是真实去尝试,我还是不敢相信。真,太真了。科技的进步果然是不可阻挡的,带来很多便利和创新!!
不知道这种算不算,利用胶片风格的绘画,算是摄影写真。用Ai绘画新赛道,真是假,假亦是真。主要是好看捏,太像了,科技改变生活。
工具是SD,主模型是MJ,Lora是film和ins两种。









现实生活中拍照又很麻烦,如果可以一键生成自己的,那么省钱省力。而且这对于一些没有专业摄影经验的人来说,AI生成的照片也能够轻松拥有优美的作品。但是由于这些照片完全是计算机算法生成的,缺乏人情味和个性化的特点。与传统写真照相馆相比,拍摄师通过镜头捕捉到的真实瞬间和情感更有灵动。
AI 生成写真,先训练模型,俗称“练丹。”网上有很多教程,准备好素材,再租个服务器。画个几小时就能出现自己的模型,然后用关键词乱杀,大概就是这么个流程。
为什么生出来的图逼真的太假了,因为网络上确实是虚拟的。早年修图软件就已经大杀四方,化妆+特效的素材,以至于训练的结果也很完美。然后在图生图素材,源源不断。
我觉得替代还是不要替代,Ai的算法大致一看可以过去,如果仔细看一些细节都会暴露。像使用Stable Diffusion进行绘画,一旦画full body,可能会出现脸崩的问题。因为Stable Diffusion算法在处理面部细节时可能会出现问题。但是解决这个问题现在应该有很多成熟的方案,比如用图生图对脸部重绘。当然还有很多好用的SD插件。
这玩意升级太快了,各种插件。昨天试了ADetailer 和Face Editor。Face Editor确实好,能够较好地修复Stable Diffusion或Web UI生成全身图时造成的脸部损坏,不会脸崩。
而ADetailer更更离谱,提供了诸多功能,有什么yolo8的脸部和手部修复,里面还能再次使用关键词,还能套用Lora,还有什么X轴,Y轴,Z轴,参数调半天。有人说什么可以用图片信息覆盖,但是像这些插件参数不会加上,我还是用的最新版,每次尝试各个参数的组合,需要花费较多时间进行手动调节。
以及Lycoris模型,属实没整明白和Lora模型有什么区别。放在同一个文件夹都能使用,难,太难了。可能需要深入了解插件的技术细节才能彻底搞清楚。
还有Roop换脸插件,得!直接换脸了。难评。
虽然AI会升级,但是缺乏人情味就是人情味,逼真的以至于太假了。无论是AI生成的照片还是AI绘画的作品,都不能替代人类的情感和温暖。
上传照片注意隐私,免费的很香,所以就是看着玩!!别替代了。







 编辑于 2023-08-01 13:04・IP 属地宁夏真诚赞赏,手留余香
编辑于 2023-08-01 13:04・IP 属地宁夏真诚赞赏,手留余香1 人已赞赏

查看全文>>
余与语 - 20 个点赞 👍
说明很多人看起来很在意隐私,
给他们一点点好处放弃的比谁都快。
免费送上标注,还倒贴9.9元。。。
发布于 2023-07-27 23:25・IP 属地上海真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
alucard - 9 个点赞 👍
不用等未来,现在就能替代。
我和我老婆在天真蓝和海马体都拍过照片,职业照、结婚登记照等等,多少有点发言权。
前段时间看到妙鸭相机的,本着花 9 块 9 打水漂的心态试了一下。
结果,输出质量炸裂,出品直接吊打海马体和天真蓝。




我老婆可满意了,第一时间把妙鸭生成的照片作为了头像…… 要知道女生把照片设为头像,是对一张照片质量的最高赞扬了。
我随便发了一条朋友圈,成功邀请了近 40 人,获得了近 200 钻石。说明这玩意真的有需求、有市场。
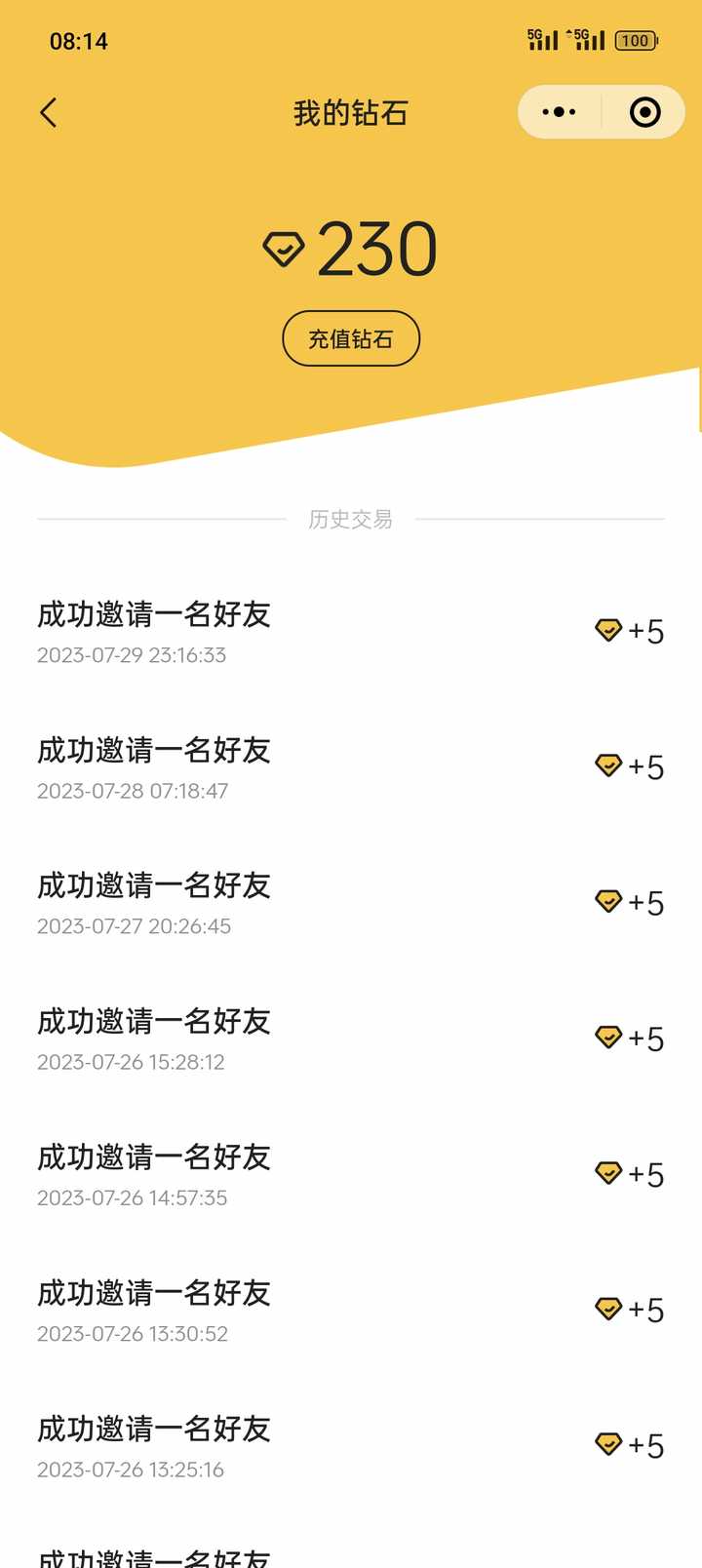

再者,按照 4 颗钻石可以下载一张高清图计算,我还能继续下载 50 张高清照片。
等于我们花了 9 块 9 可以无数次地使用模板预览效果,并下载 50 多张照片,这性价比还不是吊打海马体们?
诚然,当前的 AI 生成写真当前还有诸多弊病。
比如,模板单一、不像自己、不能生成多人合影、没有服务等等。
但解决这些很难吗?
模板单一就多加模板就是,起码根据我的观察,妙鸭相机现在每周都会新增几个模板。当模板多到一定程度,这个问题根本不会存在。

况且现在也支持一定程度的自定义,随着产品迭代,更多角度、光线、服装、表情、发型,又不是多难的事情。
况且,你去海马体难道就不是套模板吗?

实际上现在就是支持自定义的 “不像自己”,多半是上传的原始图片数量和质量有问题,比如上传了精修照片或者同一场景的照片,建议翻翻过往几年的相册,每年选几张上传。
至于说,没有服务。
拜托,海马体和天真蓝真的有服务吗?
反正,我过往去照相馆拍照的体验并不如何好。
排队、化妆、拍照、选片、取片,丝毫没感受到什么人文服务,只有流水线式的交差。
退一步来说,你真的需要这种来自照相馆的服务吗?你真正需要的是一张符合你需要的照片,而不是这种额外的服务。
有这个时间和钱,去饭店、去按摩(正规的),服务不更好?
当然,我也不认为 AI 写真照一定会完全替代海马体们。
前提是海马体们要努力求变,寻找差异化的竞争。时代抛弃你时,连一声再见都不会跟你。
再不济,打不过就加入。
海马体们做了这么多年,积累了海量的图片数据、拍摄模板、用户偏好等等,也完全也可以再造一个 AI 版的写真馆。
当然,船大难掉头,革掉自己的命也是件不易的事情。
最后,现在阻止我尝试妙鸭相机的最大门槛是:我翻遍相册也没有 20 张半身照片 orz
编辑于 2023-08-01 08:56・IP 属地浙江真诚赞赏,手留余香还没有人赞赏,快来当第一个赞赏的人吧!查看全文>>
书荒菌 - 8 个点赞 👍
随着现在 AI 发展越来越快,AI 写真越来越真实,效果也越来越好,照相拍不出的,AI 只需要上传一张照片,几行提示词就可以生成完美的照片。
虽然说不会完全代替照相馆,毕竟有时候仪式感还是要有的嘛。
但是大多数情况下,可以足不出户就拍出写真大片,还便宜,那大多数人也是会愿意接受的。
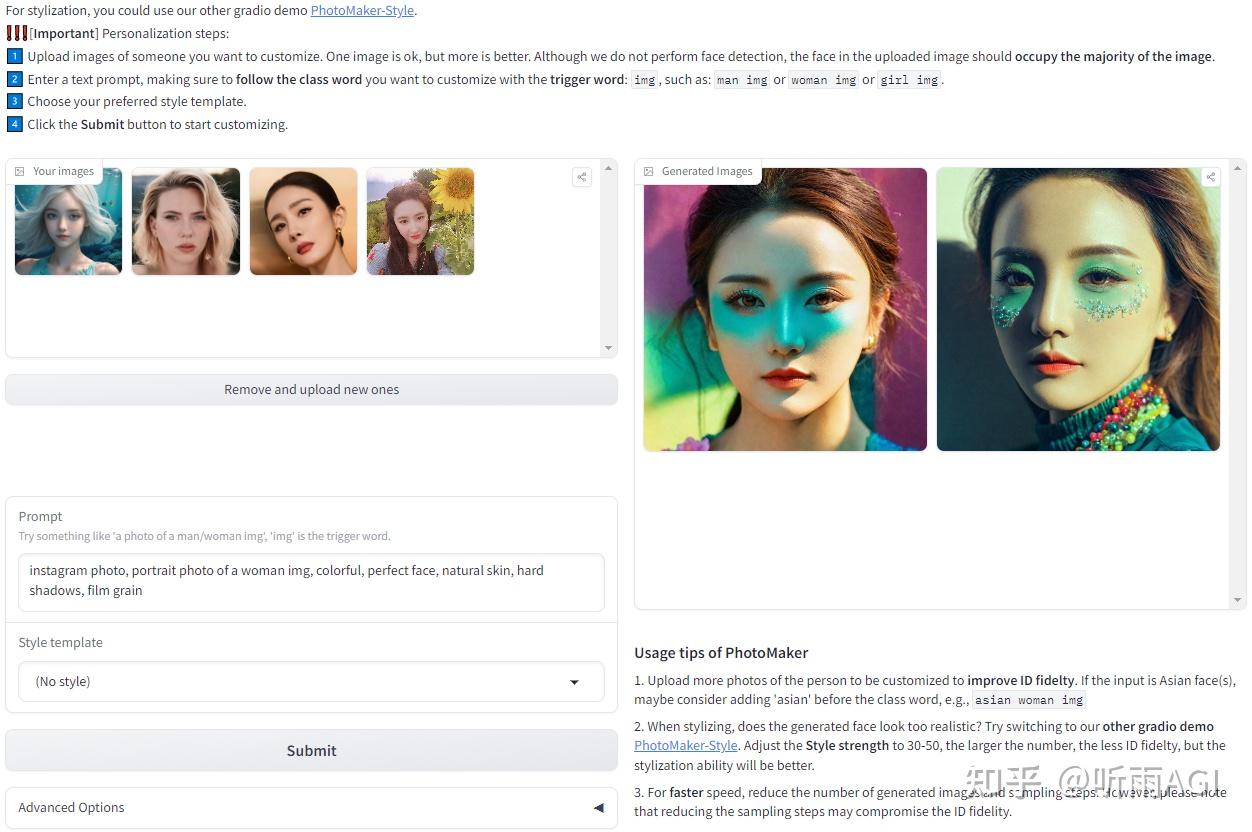
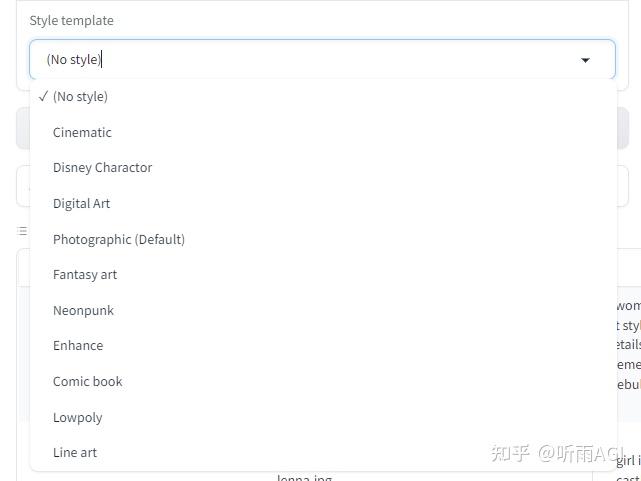
今天顺便也来介绍一个创造个性化人物形象的 AI 写真工具:PhotoMaker。
PhotoMaker 主要是利用多张照片作为身份ID,获取人物特征,然后创造出一个新的、个性化的人物图像。
PhotoMaker 正好也提供了 demo 版本供我们体验,我们就来试试效果吧!体验网址听雨会放在文末哦。
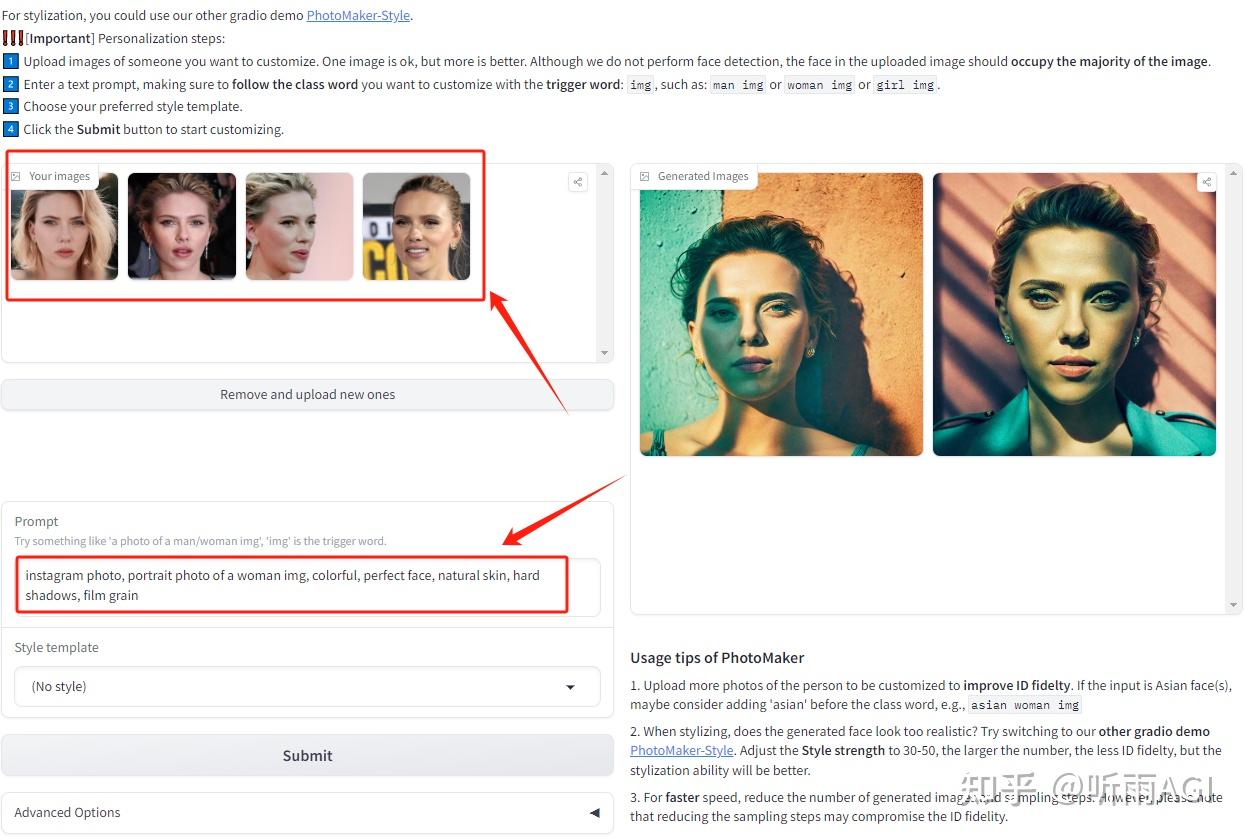
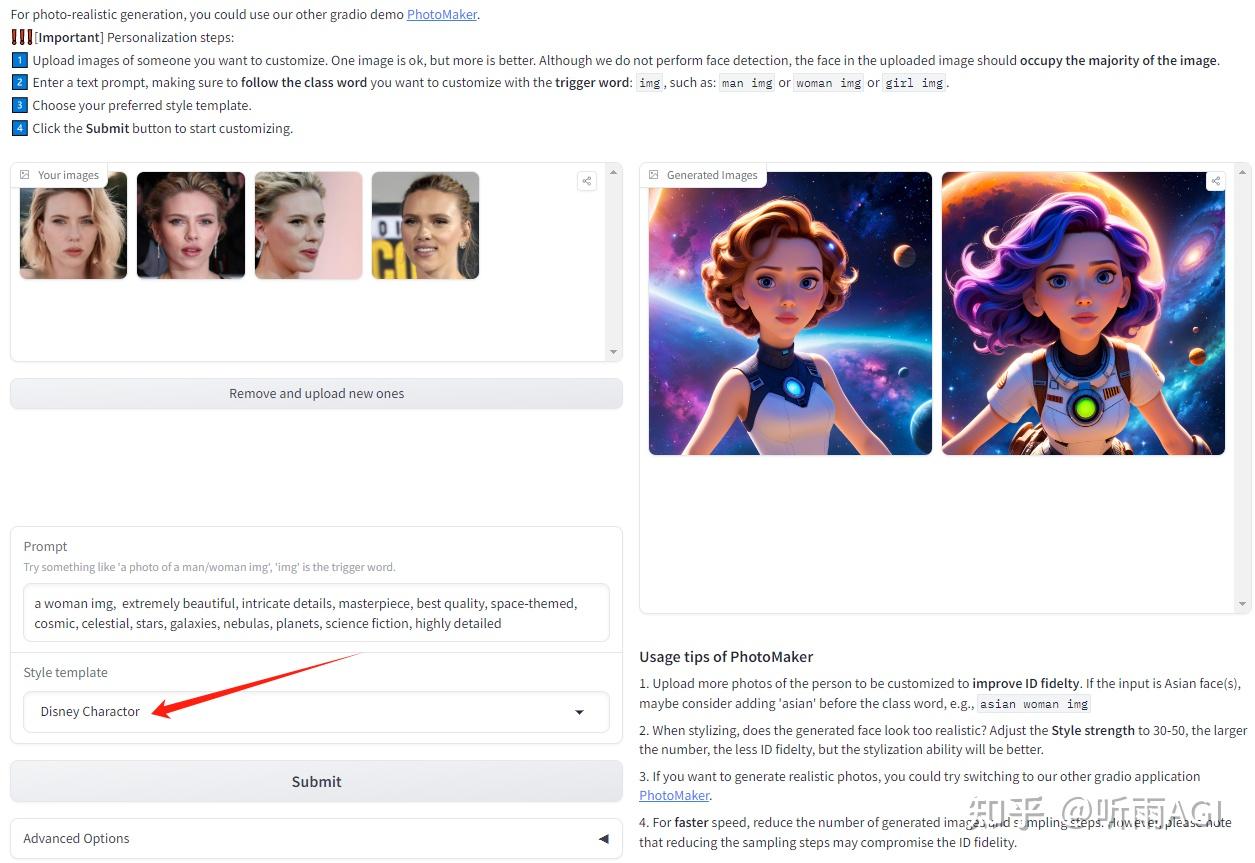
不知道小伙伴们用过妙鸭相机没有,就是上传多张自己的照片然后生成个人艺术照。这个功能 PhotoMaker 也有,而且不需要妙鸭相机上传多张照片,理论上上传一张照片就可以了,而且没有模板一说,想要生成什么样的图片,自己写提示词就可以了。
下边的操作也很简单,上传图片,输入提示词,然后我们就可以根据描述生成我们想要的人物照片了。然后点击 Submit 提交,等待图片生成。
这里写提示词的时候需要注意, 输入文字提示,确保在自定义的类词后面加上触发词: img ,例如:man img 或 woman img。
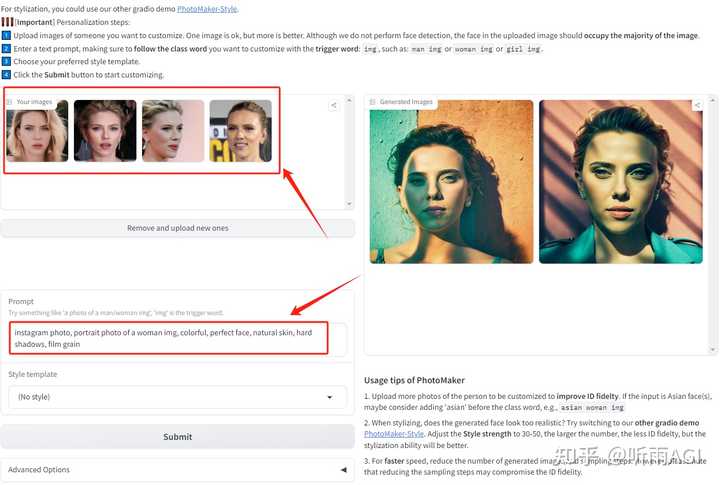

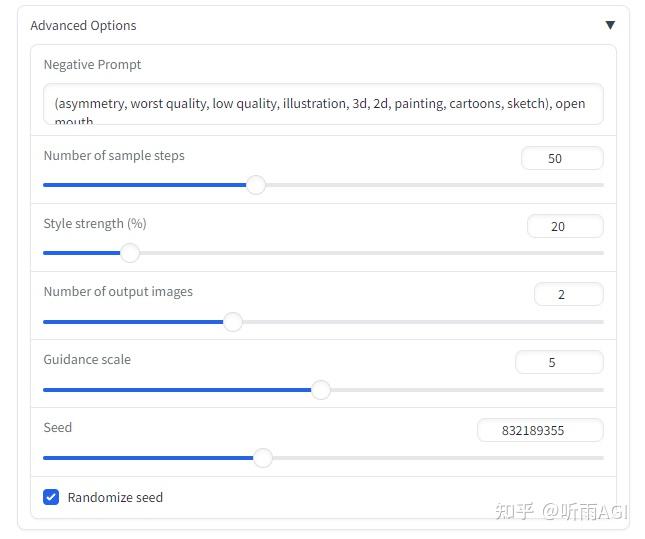
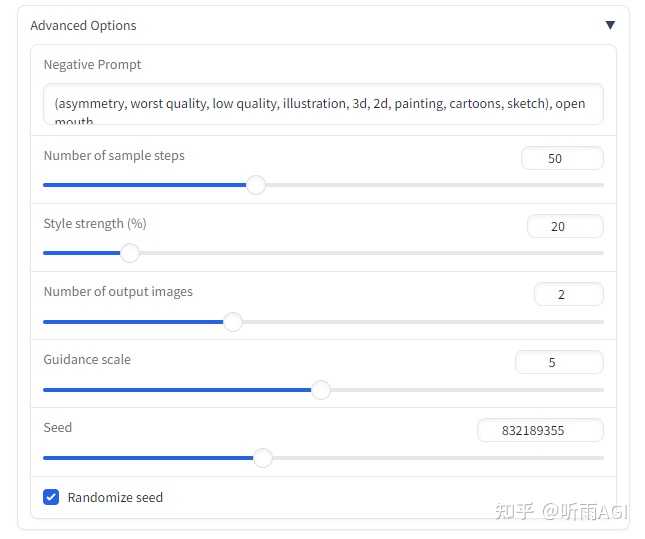
这里简单介绍一下「Advanced Options」下边的这些参数。
「Negative Prompt」反向提示词,默认就可以了。
「Number of sample steps」迭代步数,理论上值越大,生成的照片越精细,但是也不是越大越好哈,什么事情都是过犹不及的。
「Style strength」风格强度,选中风格的强度大小,值越大,风格越明显。
「Guidance scale」提示词的相关度,值越高,则生成的图像和提示词的关联更紧密,简单点说就是生成的图像更准确;值越低,则 AI 自身发挥的空间则更高,创造性以及多样性更高。
「Seed」种子数,图片的唯一编号,相同的编号相同的提示词和配置会出来一样的图片。
「Randomize seed」勾选则代表随机生成种子数。

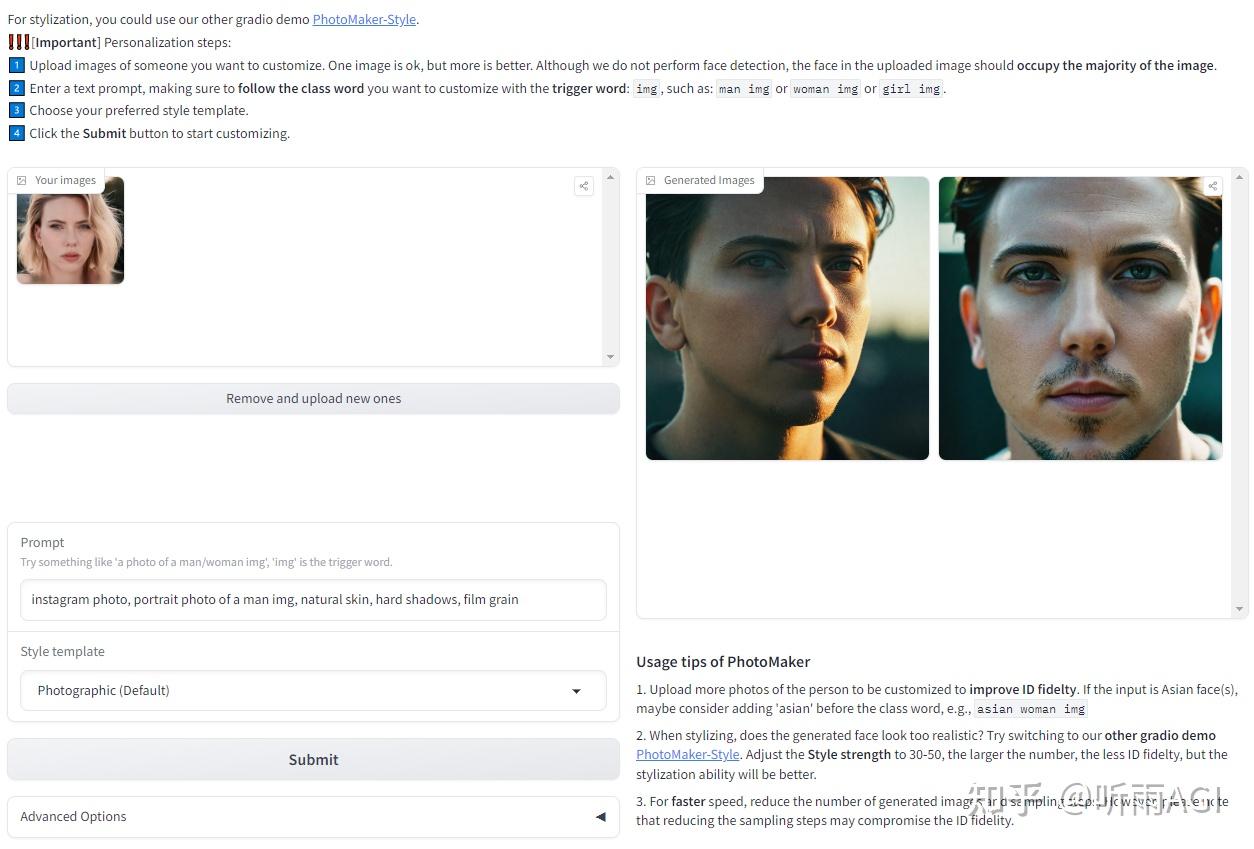
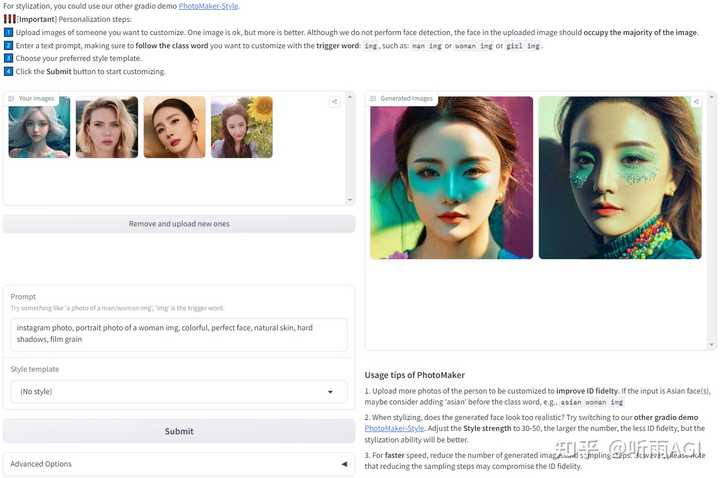
好了,我们继续来讲 PhotoMaker 的进阶功能,PhotoMaker 还可以上传不同人物的照片,把不同人物照片的特征进行融合,从而创造出一个融合了不同人物特征的全新人物形象。
这里听雨希望未来可以有一个功能可以选择不同人物的指定特征进行融合,哈哈。

还可以改变照片人物的性别。只需要在提示词中把「woman」改成「man」就可以了。
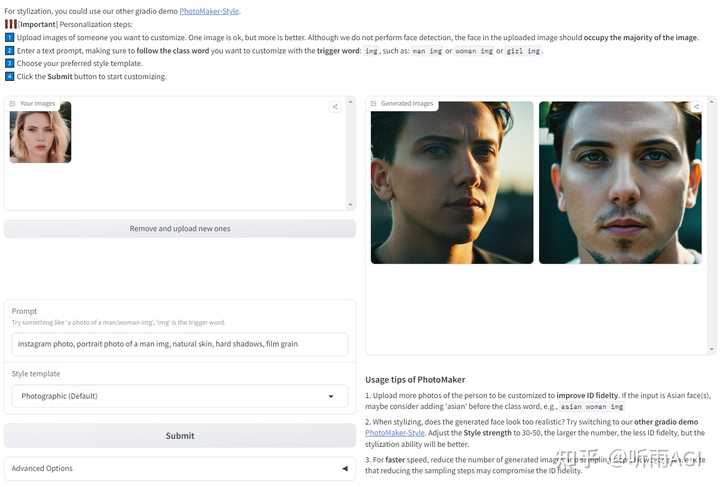

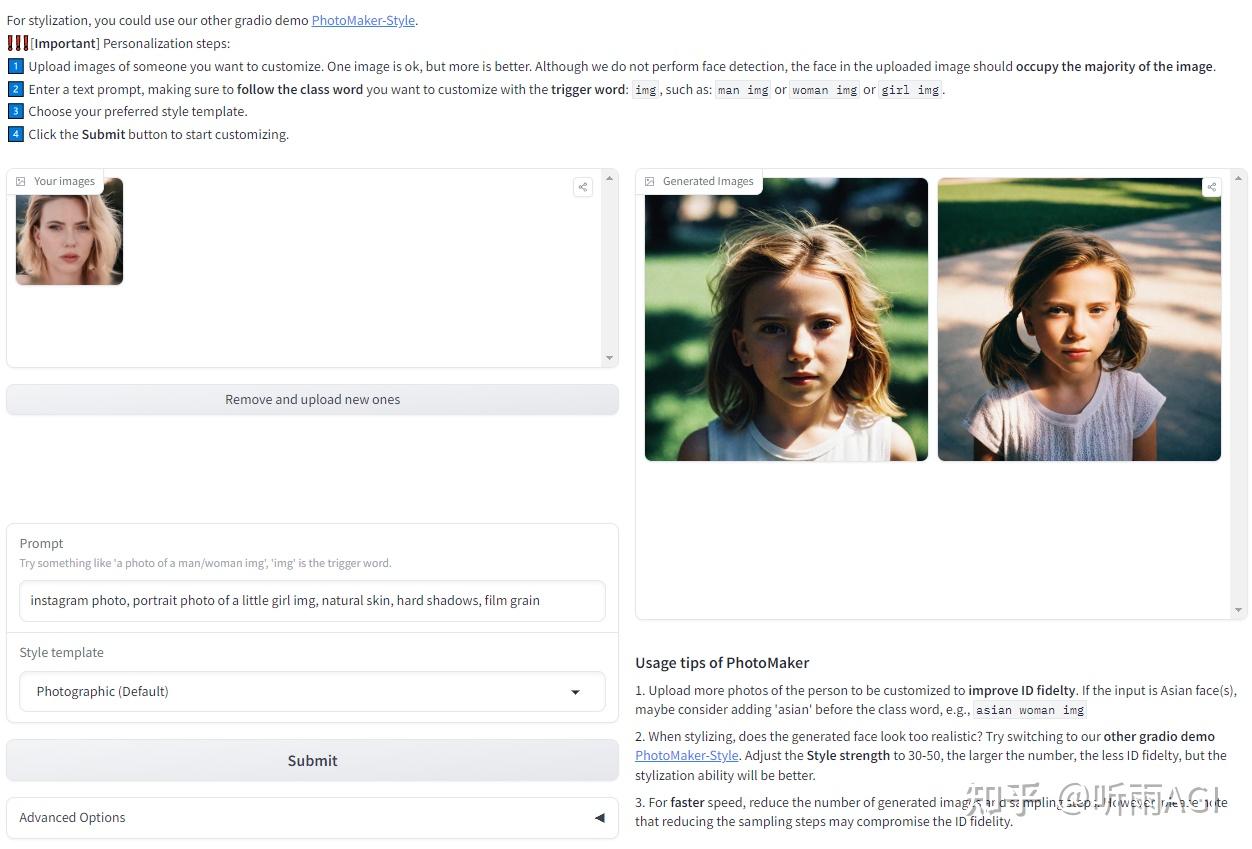
还可以改变照片人物的年龄。把提示词中的「woman」改成「girl」或者「little girl」就可以了。
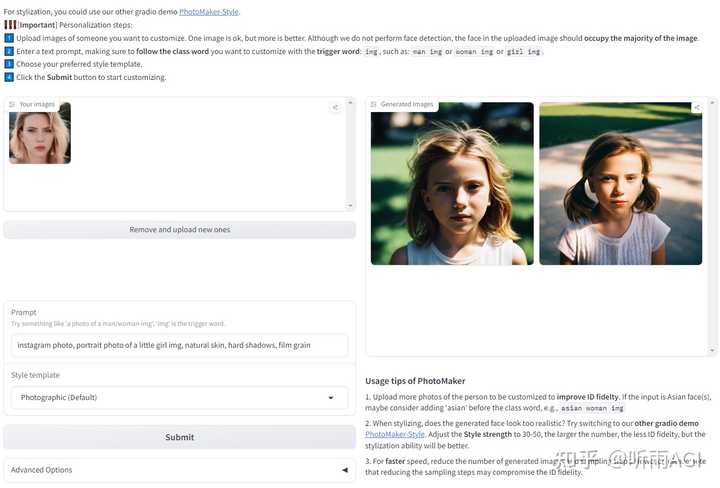

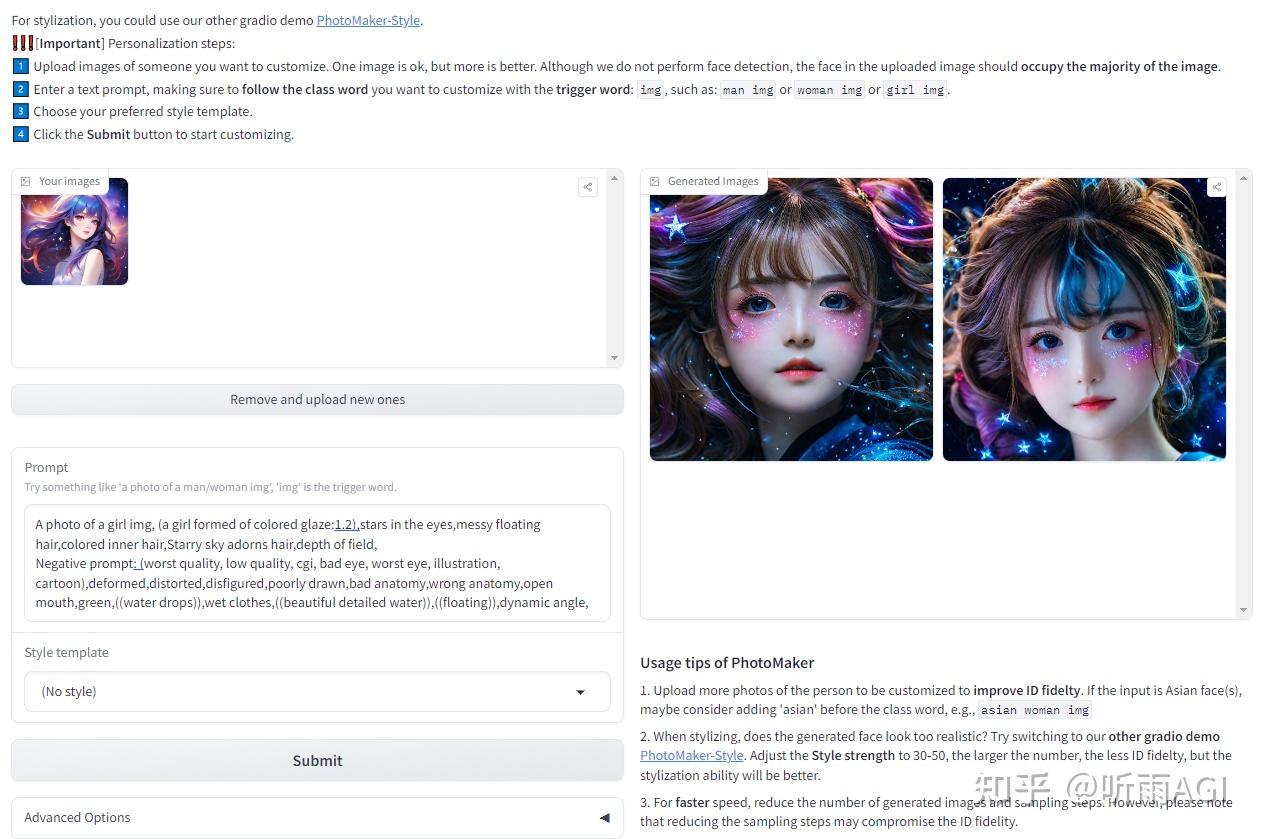
还可以动漫人物还原成真实人物哦!
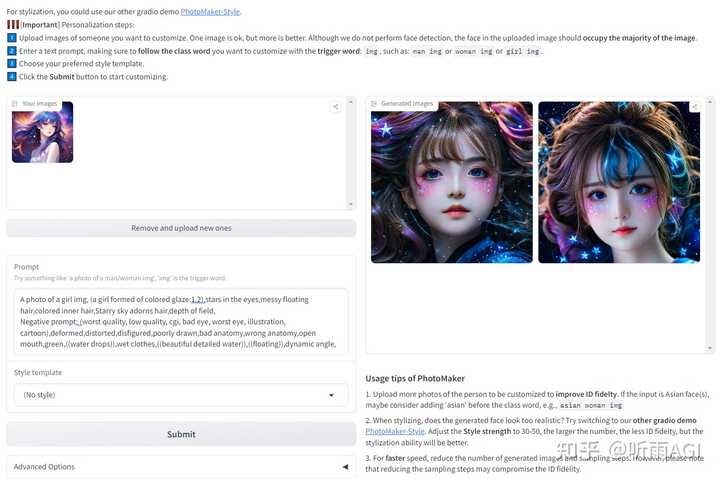

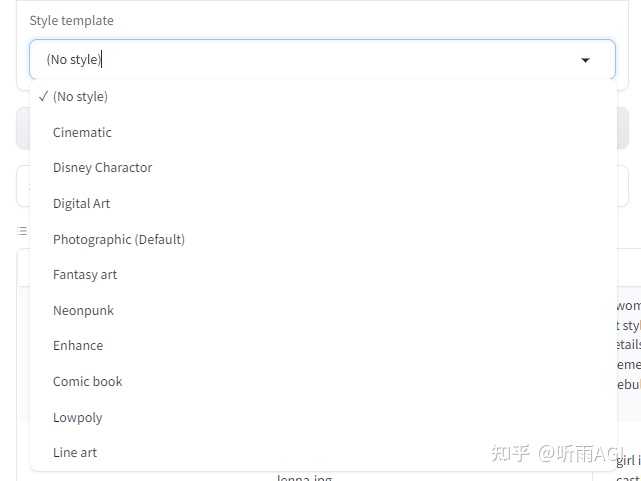
除了以上的功能以外,还可以生成风格化的照片。可以选择喜欢的风格进行创作。

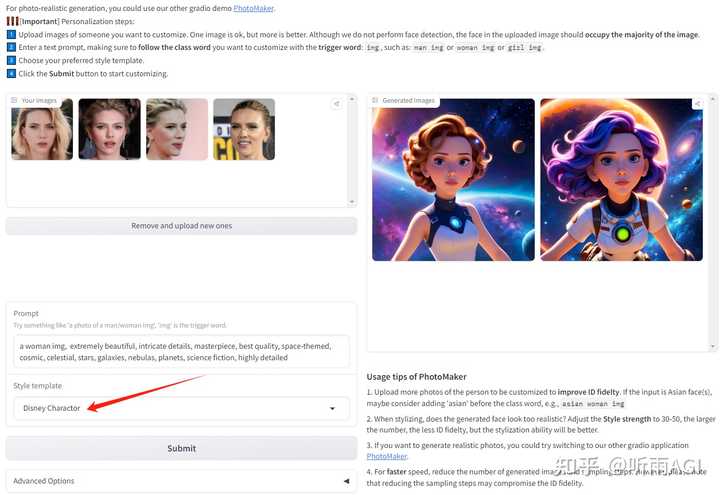

体验地址:https://huggingface.co/spaces/TencentARC/PhotoMaker
风格化效果体验地址:https://huggingface.co/spaces/TencentARC/PhotoMaker-Style感兴趣的小伙伴快去试试吧!
编辑于 2024-01-26 22:33・IP 属地浙江查看全文>>
听雨AGI - 7 个点赞 👍
查看全文>>
高山昙 - 3 个点赞 👍
天眼妹进入最近爆火的妙鸭相机小程序看了一下,妙鸭使用教程共分为制作数字分身、生成写真、精修写真三步。
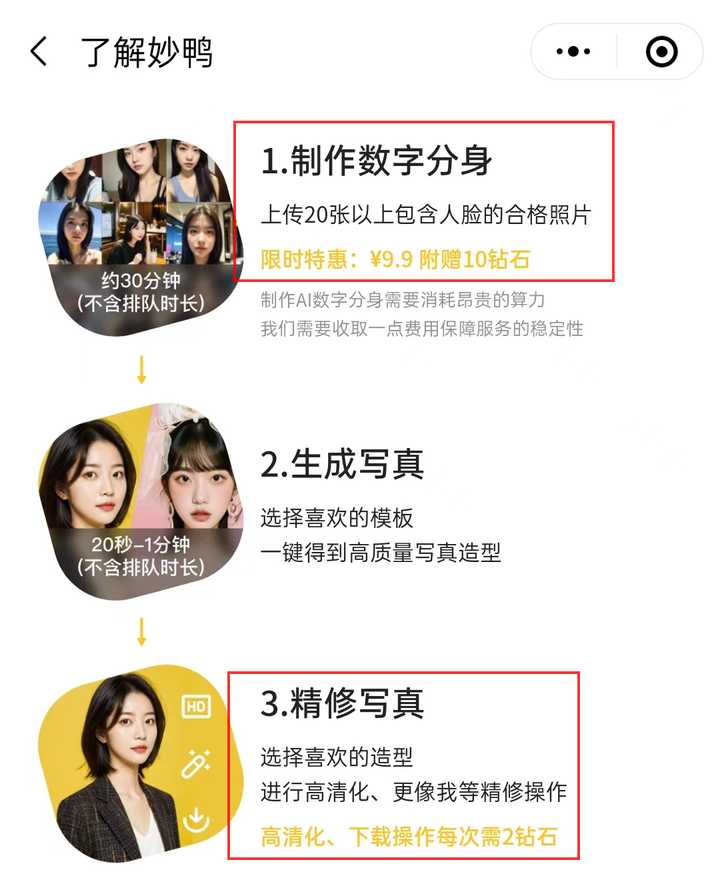
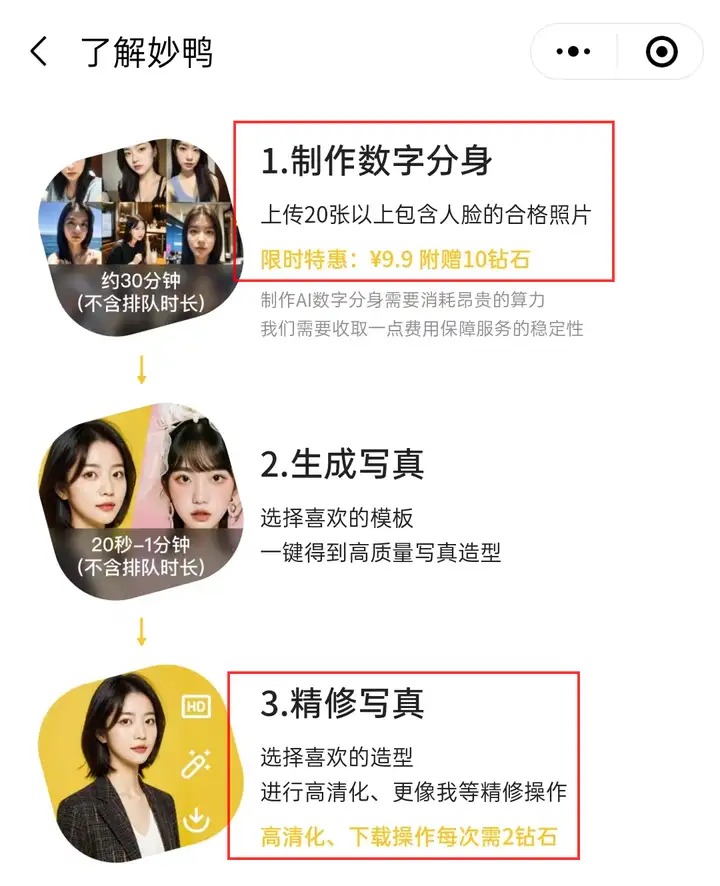
根据新闻报道,海马体线下写真店的出片再快也需要隔日取,虽然妙鸭相机需要排队等待,但是它的出片速度与之相比已经算快了。
除此之外,在价格方面,妙鸭相机需要支付29.9元(限时优惠为9.9元)费用才能制作数字分身,而海马体一张职业照标价399元,似乎妙鸭更划算一些。


8过,妙鸭的售后保障服务似乎并不健全,上海市消保委工作人员亲身体验后发现对照片不满意无法退款,因此上海市消保委发声称,妙鸭在付款页面以灰色小字标注的“一旦购买成功,不支持退款”涉嫌侵害消费者的公平交易权。
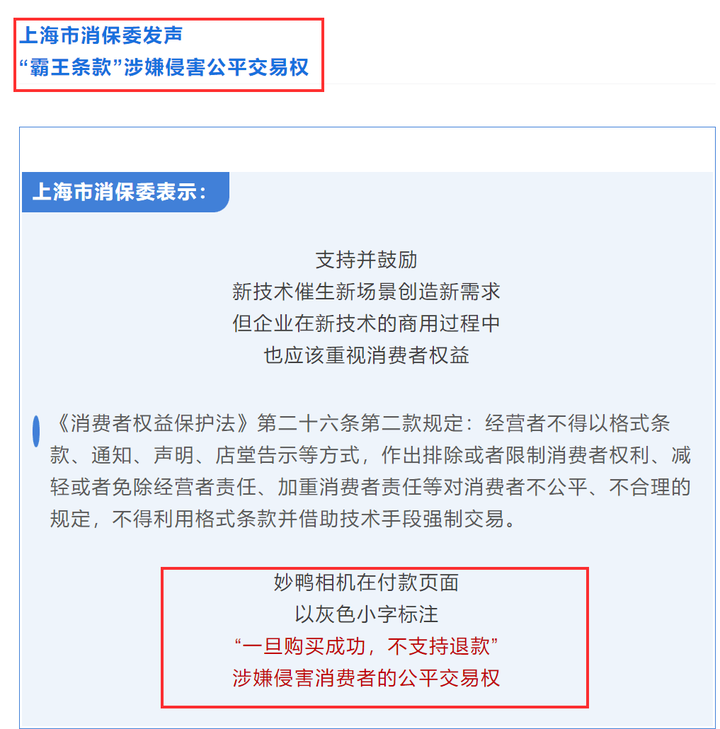

在用户隐私方面,妙鸭也曾遭受到网友的质疑。据该软件最初版本的用户协议显示,"妙鸭相机"可以任何形式、任何媒体或技术使用用户的内容。7月20日,妙鸭发布声明对协议内容进行了修改。


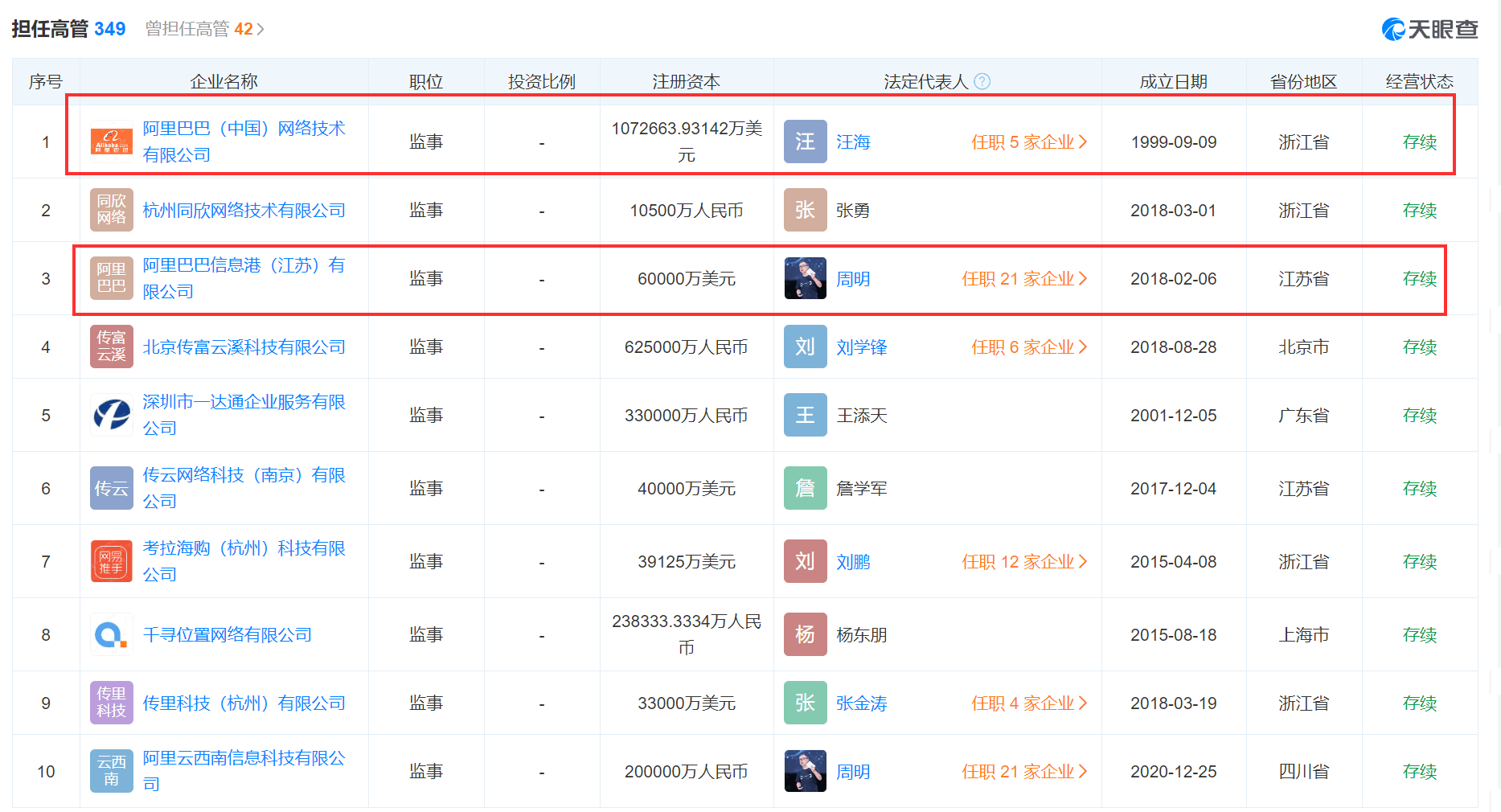
天眼妹查了一下,妙鸭相机关联的公司是未序网络科技(上海)有限公司,该公司成立于2006年1月,注册资本与实缴资本为5520万美元,经营范围包括网络信息系统软件的开发设计与制作、销售自产产品、市场营销策划等,由新南有限公司全资持股。
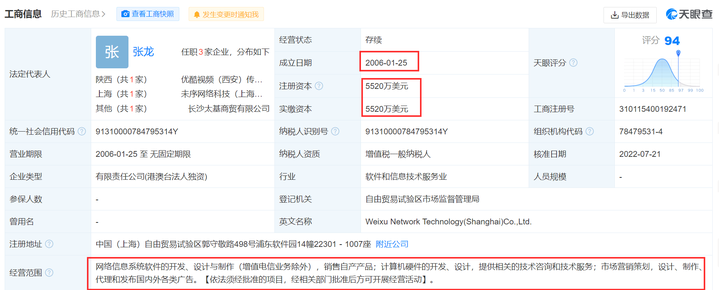



该公司的法定代表人张龙,同时也是优酷视频(西安)传媒科技有限公司的法定代表人、执行董事兼总经理。


而未序网络科技(上海)有限公司的监事冯云乐也同时担任了多家阿里系公司的监事。


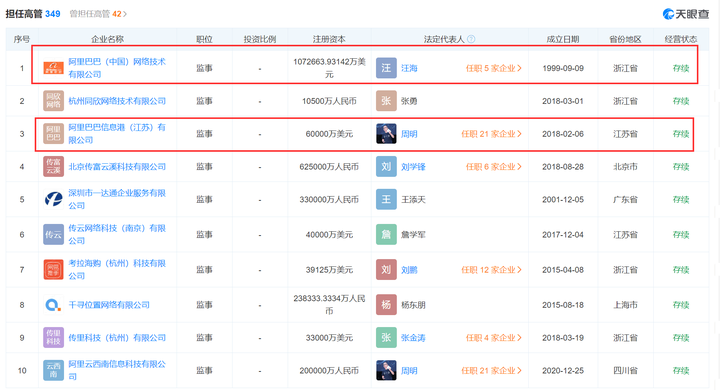

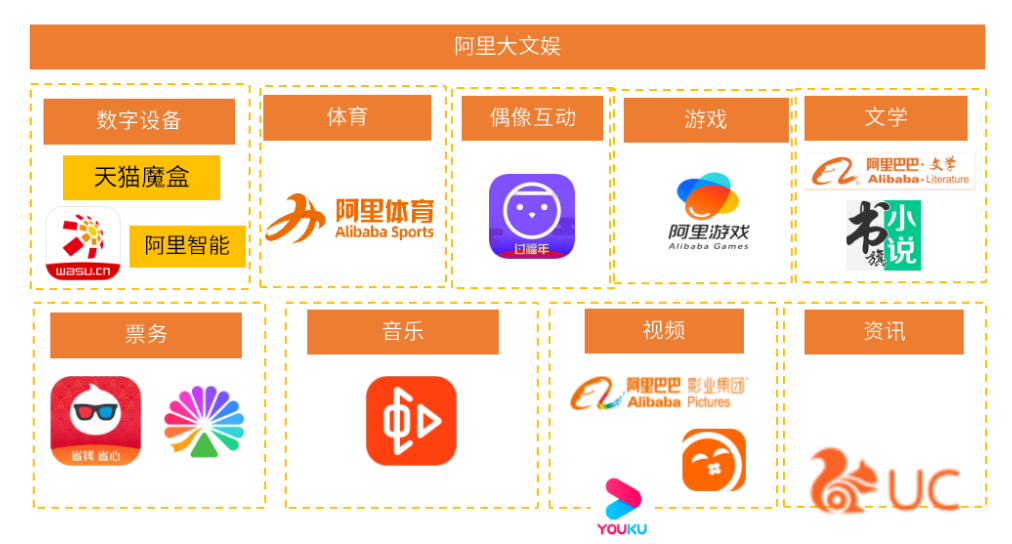
据天眼查显示,该公司2023年3月1日获得了阿里文娱的投资,有阿里大文娱的相关人士对记者表示,妙鸭是阿里文娱参投的一个创业项目。




2022年阿里大文娱的产业布局涵盖领域有数字设备、体育、游戏、偶像互动等……
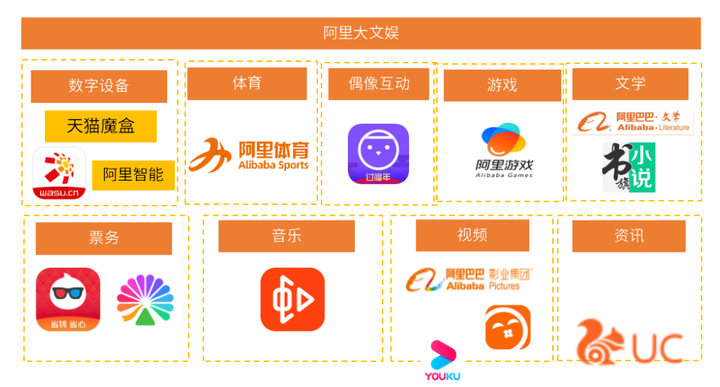

虽然阿里的布局看起来很庞大,但是阿里的大文娱板块一直处于亏损状态,阿里集团2023财年第一季度,数字媒体及娱乐部分经调整EBITA亏损人民币11.02亿元。


大家看好阿里此次参投的项目吗?
发布于 2023-08-01 15:16・IP 属地北京查看全文>>
天眼查 - 3 个点赞 👍
几周前有人给我看妙鸭相机,说这个产品会火的时候,我很不以为然的回了一句,这个东西我半年前就做过了。但后来妙鸭越来越火,和周边的人关于妙鸭的讨论也逐渐变多,虽然嘴上还是说这个东西没啥技术门槛,但是对于产品还是有了更多的思考。作为一个对产品很感兴趣的研究员,发现技术同学做产品还是有很大短板的。
同类型产品最先出道的是国外一个叫做Lensa的产品,在去年11月底推出了一个Magic Avatar的功能,用户上传8—10张只有自己的脸的自拍照,然后选择性别和主题(包括“宇宙”“仙女公主”“动漫”),Lensa就会根据你的脸生成不同艺术风格的图像。Lensa在12月的前5天,达到了400万次的安装量,登上了苹果和谷歌应用商店的排行榜第一。而这五天期间,消费者在Lensa上共花费了820万美元。后来高峰期甚至可以做到300-400万美元的日营收。


Lensa生成效果图 大概在今年1月份的时候,在大部分精力投入在Large Language Model的时候,我们团队的一个员工和两个实习生(研究院的研究员都是全栈工程师,能写后端也有做前端)花了不到一周的时间就做了一个和Lensa类似的小程序,我自己还客串了一下产品经理画了一些原型图。当时还没有Lora,大家用的都是Dreambooth的技术,之前也用Dreambooth做过孩子照片生成,广告生成等基本功能。小程序其实就是把之前折腾过的技术做了一下封装,更像一个产品。
 00:49
00:49大家很快完成开发以后发现这个东西想作为一个产品有一些无法解决的问题,简单讨论一下就放弃了。就留下了上面这一段产品流程的视频。当然,代码都还在,有人需要可以share出来给大家图一乐。当时我们认为的大问题主要有:
- 要求用户上传10-20张照片,对用户要求太高,用户不愿意
- 用户照片有很强的隐私性,政策可能不允许
- 上传照片后,训练模型需要10分钟以上,中间没有用户交互,用户很难回来
- 训练模型的成本不低(大几块钱),要求用户付费难度大
- 大多数用户是图新鲜,用户黏性差
回过头看,当时我们觉得这个产品没法做的问题妙鸭其实一个都没有解决,但是妙鸭还是火了。可见技术人员和产品的思维在两个世界,不禁感叹当时如果我们有一个不错的产品经理,可能做出妙鸭的就是我们了。
相信当时做过类似工作的团队有很多,但都没有做出爆款。联想到这个情况不只这一次,去年意间AI人物图片动漫化的功能爆火的时候,就吐槽说一点技术门槛都没有,我们一个月前就做了类似的功能(可以看http://flagstudio.baai.ac.cn)。这两天仔细复盘了一下发现技术人员做产品还是有很多天生的缺陷的,写一些比较明显的问题,想到更多之后再补充。
- 太重视技术门槛,想做别人没法复制的东西
当时团队讨论做什么应用的时候放在第一位的总是技术门槛在哪儿。像Stable Diffusion动漫模型,DreamBooth这种技术总觉得谁都能做,没有壁垒,就算做出来别人也能轻易模仿。当时我们想做个算法只需要上传一张图片,就可以出高质量的写真,这个才有技术门槛,结果捣鼓半天也没个头绪。当然,做技术门槛的想法没有错,过分强调技术的重要性就容易在死胡同里越走越深。很多短期内技术达不到的问题可以用巧妙的产品设计来解决(不过在我看来妙鸭并没有解决)。我相信现在随便找个学生,给两天时间都能把妙鸭背后的那个技术复现出来,真正形成壁垒的恰恰是产品本身。
- 想要的太多太全,不懂less is more
从上面的demo可以看到,我们做了人物、宠物、物品三个大的类别。觉得单一做人物太简单了,没啥难度。而且我们的技术是通用的,做宠物很有意思,做物品可以吸引广告主。技术人员想要强调的是技术的通用性。但产品往往就是需要一个点做透,打穿。功能越多,越说明没有想清楚目标用户是谁(拍写真的人、养宠物的人、广告主可能三者的overlap很小),相反,单一功能的爆火才是对用户需求的真正洞察。而且很多产品经理对细节的把控是技术人员完全不会去想的问题。
- 不会产品运营和流量增长
我相信不管是妙鸭相机还是意间AI,他们爆火的背后都缺不了产品运营和增长。如果说产品经理的工作某些技术人员还能兼职做一下,碰到产品运营和流量增长就真的两眼一摸黑了。所以,组建团队的时候一定要配备齐全。特别是当下,因为ChatGPT的强大功能给产品研发带了很大的不同。产品经理可以很简单地1. 基于ChatGPT,定制prompt来完成某些想到的功能点或是直接做个产品;2. 通过ChatGPT的帮助开发简易地程序。可以一两天就做成一个像模像样的小产品,如果有产品运营和流量增长的同学的加持,很快可以达到客观的用户规模。然后通过用户数据反馈可以不断迭代优化产品,慢慢形成技术壁垒。这波AI浪潮的前期,可能会有大量很轻的小应用出来,每个团队都可能只有几个人,但必须要有一个会产品运营的流量增长的。
到现在,我还是觉得妙鸭相机可能就是火一阵,和当时的意间AI一样,DAU瞬间缩水2-3个数量级。但还是希望通过仔细学习它爆火的原因和方法,给想做产品的技术人员一些启示。虽然,看到了技术人员做产品的很多问题,但我始终认为AI时代特别是LLM时代,最好的产品经理一定是技术人员。
发布于 2023-08-09 00:02・IP 属地北京查看全文>>
黄文灏 - 0 个点赞 👍
去呗取代不好说,但是10块钱更实惠,还不用出门。照相馆应该集体举报这些AI软件价格不正当竞争,强制要求涨价。至于最后是什么结果,可能连开始都不会有。
发布于 2023-08-01 07:42・IP 属地江苏查看全文>>
刘原 - 0 个点赞 👍
老俞是人物。从我还是小女孩开始,他就是曾是我崇拜的偶像。
后来有挺长一段时间,我又忘了他,因为后来我不学英语了。
直到去年,教培事件后,他捐了8万套课桌椅,并退还了所有学费。即使6万员工不得已离开,也全部按N+1结清了工资。我发自内心觉得,老俞是条汉子。当然,更重要的是,新东方也有这样的底气和实力。说明他没乱投资,现金流一直很好。


最近,董宇辉爆火。像我这种消费非常理性的人,也在直播间给孩子买了一大堆的书。别问我为啥不买吃的,因为我正在减肥。
辉辉老师确实有才,当别的直播间在“买它,买它,买它,现在最低价,只剩最后x份时。”
他说:我想把天空大海给你,把大江大河给你,没办法,好的东西就是想慷慨地给你
这是他在卖大米!
他说:“我没有带你去看长白山皑皑的白雪,没有带你去感受过十月田间吹过的微风,我没有带你去看过沉甸甸的弯下腰,犹如智者一般的谷穗,我没有带你去见证过这一切。但是,亲爱的,我可以让你品尝这样的大米。”
还是在卖大米!!
他说:“以前做老师的时候,我会穿白T恤,或者西服外套讲课,这样孩子们会觉得我很重视这节课,即使现在我的大脑不转很久了,但我上来之前还是做了30个俯卧撑,你不要让我坐着了,我愿意站在这里,让我知道我在意你……”
又是在卖大米!!!
很显然,新东方助农直播带货终于获得阶段性成功。
6月17日,很多报道都在说,东方甄选正在尝试自建供应链,未来将大力发展“东方甄选”自营产品。
转自采购供应链培训专家宫迅伟老师公众号“宫迅伟采购频道”,9.16号宫迅伟老师将在杭州开设《全品类间接采购管理》大课。
发布于 2023-08-01 09:55・IP 属地江苏查看全文>>
嚯嚯嚯哈哈 - 0 个点赞 👍
查看全文>>
和花花我的爱 - 0 个点赞 👍
查看全文>>
写bug的程序员