
分享一个线上试用地址:https://replicate.com/a16z-infra/llama13b-v2-chat
第一时间提交了申请,非常期待!
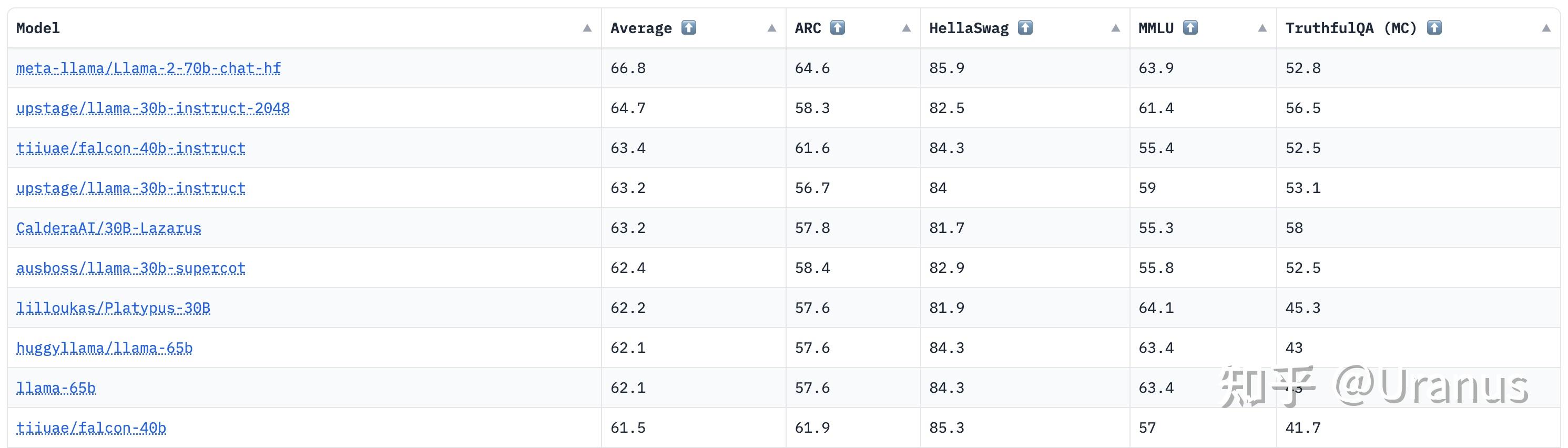
Hugging Face 的 Open LLM Leaderboard 已经变天了,LLaMA-2-70B-Chat 高居榜首:
Overview
根据已有内容,我们可以先划重点:
- 模型大小:7B,13B,34B(延缓放出),70B
- 许可证:免费商用
- 上下文长度:4K
- 预训练数据量:2 trillion tokens(40% more than LLaMA)
benchmarks 成绩很好:
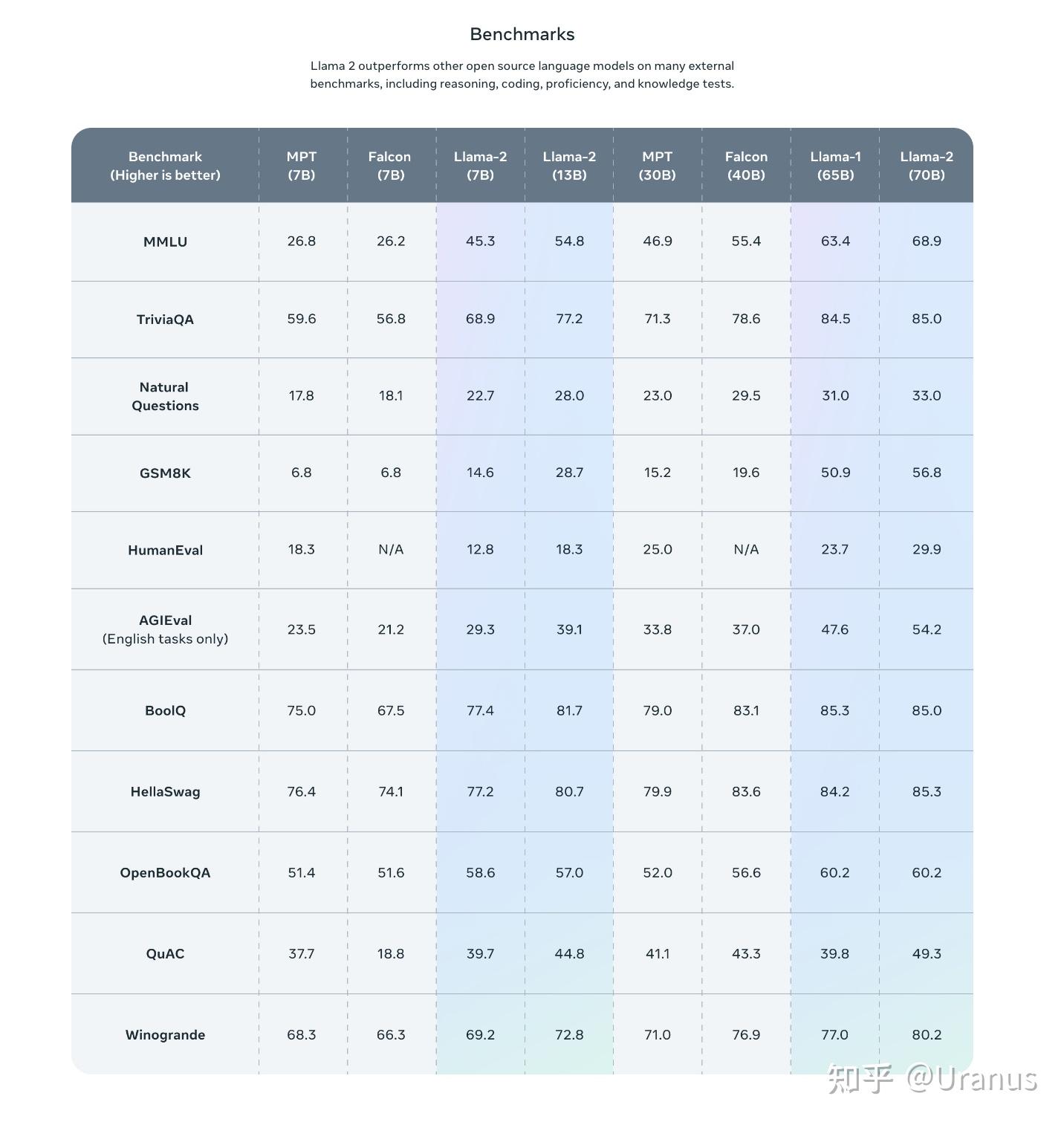
技术报告
更多信息在技术报告中:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
简单摘一些我认为比较重要的信息:
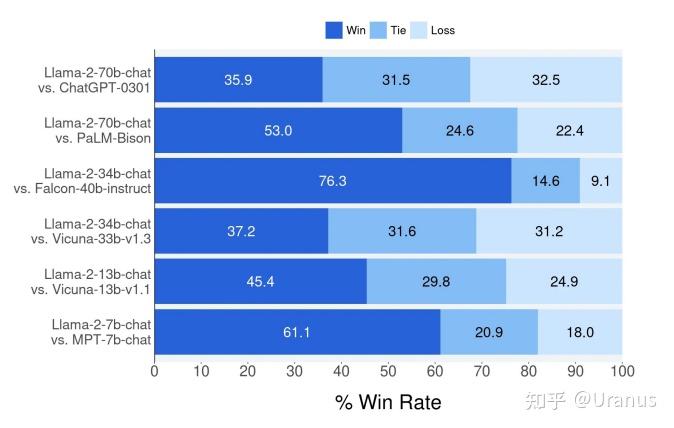
如图所示(Meta 紧跟着目录后面放的图,十分自信了),LLaMA-2 与目前主流的模型在人类的评判下是占据上风的。这个评测包括了在上下文长度为 4K 下的单轮与多轮对话。
需要注意的是人类的评判可能会带有 bias,因此 Meta 在后面 RLHF 一节中又以 AI 做了一次对比。
LLaMA-2-chat 几乎是开源模型中唯一做了 RLHF 的模型。这个东西太贵了,Meta 真是大功一件!根据下图的结果,LLaMA-2 经过 5 轮 RLHF 后,在 Meta 自己的 reward 模型与 GPT-4 的评价下,都表现出了超过 ChatGPT 性能(在Harmlessness与Helpfulness两个维度)。
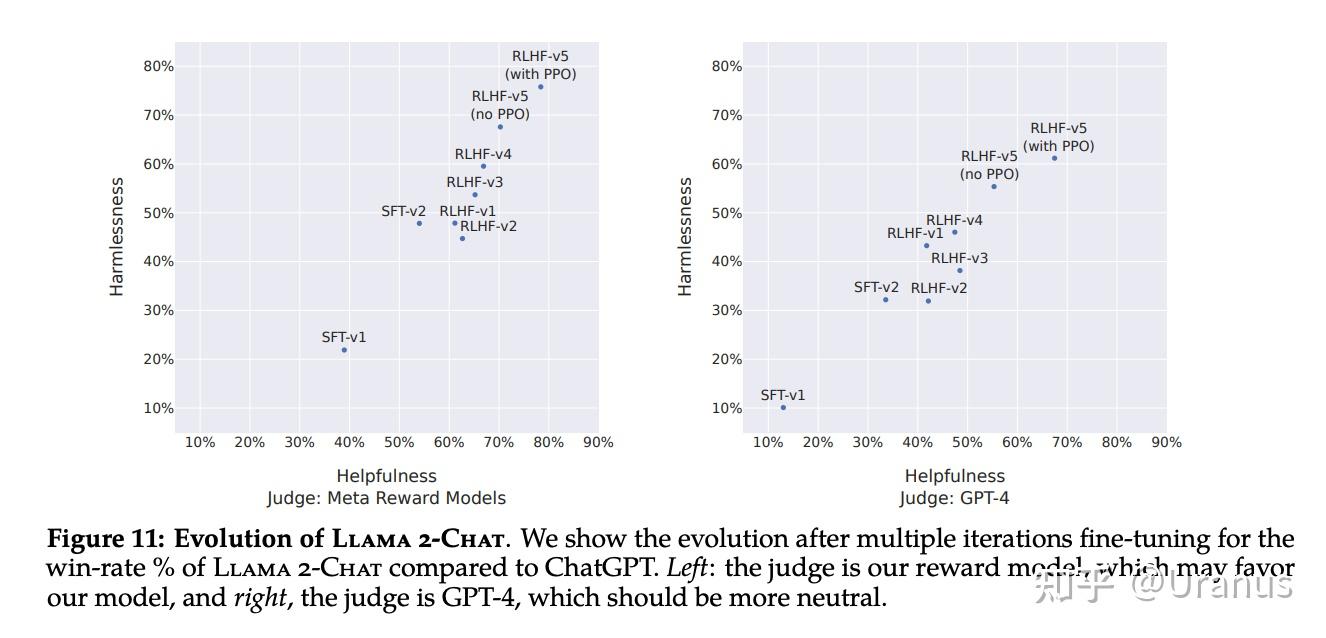
更多信息明天认真读一下 :)
个人浅见
实际上一直以来我对开源大模型都是保持非常关注的态度。在之前的几篇文章和周末项目都能清楚地体现:
Uranus:Xinference:在个人电脑上 PK 两代 chatglm!
Uranus:解开封印!加倍 LLM 推理吞吐: ggml.ai 与 llama.cpp
Uranus:完全开源!基于 LLaMA 的 generative agent 来啦!
兴趣是一方面,对开源的认同与热爱是另一方面,还有就是对大模型私有化的看好。OpenAI 的 GPT-4,Google 的 PaLM 2 这些都很牛逼,但对于许多公司和个人用于来说,OpenAI 等公司提供的服务可能并非最优解,这是因为:
- 首先绕不过的数据隐私和安全问题。这一点相信大家也都有所体会。天下没有白吃的午餐,OpenAI 默认是会使用 ChatGPT 的对话进行模型训练的,这意味着你与 ChatGPT 的对话内容会进入一个黑盒,而这个黑盒可能在某时某刻把你的信息吐给其他人看(如 ChatGPT Grandma Exploit)。
- 此外大型企业往往需要基于自己的数据集对模型进行定制化,来满足特定的任务。OpenAI 虽然完全有能力做微调,但数据安全可能会成为一个问题。对金融等领域来说,数据流出内网可能是不可接受的,但这些领域又是大模型可以大展拳脚的地方。
- 针对特定领域微调的小模型往往也能比较好地满足企业需要,这将大大降低模型的部署和推理成本。
以前开源界最强的是 LLaMA-65B 和 falcon-40B,确实和 GPT-3.5 甚至 GPT-3.5-turbo 存在差距。LLaMA-2 之后,GPT-4 毫无疑问还能继续占据优势地位,但 GPT-3.5-turbo 恐怕地位不保。
能够打得过 GPT-3.5-turbo 实际上意义挺大的。GPT-3.5-turbo 的能力实际上已经满足了相当大一部分人的需求(这一点大家应该有所感受)。因此,LLaMA-2 的出现恐怕要颠覆 OpenAI 目前的格局。退一步讲,能逼 OpenAI 多挤点牙膏出来也是大功一件。
最后总结一下,这次 LLaMA-2 的发布让我对开源大模型更加充满了信心! Meta 再次证明了自己是“真 OpenAI” !YYDS!
最后,安利一下我们的模型推理项目 Xinference:所有人的大模型,LLaMA-2 权重放出后我们会第一时间跟进,在我们的 Hugging Face Space 托管一份供大家玩耍!